期刊:CVPR
年份:2024
代码:http://https: //github.com/THU-MIG/RepViT
摘要
最近,与轻量级卷积神经网络(CNN)相比,轻量级视觉Transformer(ViTs)在资源受限的移动设备上表现出了更高的性能和更低的延迟。研究人员已经发现了轻量级ViT和轻量级CNN之间的许多结构联系。然而,它们之间在块结构、宏观和微观设计上的显著差异并没有得到充分的研究。在本研究中,我们从ViT的角度重新审视轻量级CNN的高效设计,并强调其在移动设备上的广阔前景。具体来说,我们通过集成轻量级vit的高效架构设计,逐步增强了标准轻量级CNN(即MobileNetV3)的移动友好性。这就产生了一个新的纯轻量级CNN家族,即RepViT。大量的实验表明,RepViT优于现有的最先进的轻型ViT,并在各种视觉任务中表现出良好的延迟。值得注意的是,在ImageNet上,RepViT在iPhone 12上以1.0 ms的延迟实现了超过80%的top-1精度,据我们所知,这是轻量级模型的第一次。此外,当RepViT遇到SAM时,我们的RepViT-SAM的推理速度比先进的MobileSAM快近10倍。
Introduction
轻量级CNN的发展:过去十年中,研究人员主要关注轻量级CNN,并取得了显著进展。提出了许多高效设计原则,如可分离卷积、反向残差瓶颈、通道洗牌和结构重参数化等,这些原则促成了MobileNets、ShuffleNets和RepVGG等代表性模型的发展。
轻量级ViTs的探索:尽管直接减小ViT模型的大小以适应移动设备的约束是可能的,但这样做往往会降低性能,使其不如轻量级CNN。因此,研究人员开始探索轻量级ViTs的设计,目标是超越轻量级CNN的性能。
轻量级ViTs和CNNs的比较:尽管轻量级ViTs和轻量级CNNs在某些结构上具有相似性,例如都采用卷积模块来学习空间局部表示,但它们在块结构、宏观/微观设计上存在显著差异,这些差异尚未得到充分的检查。
主要贡献:
-
新的轻量级CNN架构RepViT:提出了一种新的轻量级CNN架构,名为RepViT,它通过整合轻量级ViTs的高效架构设计,旨在为资源受限的移动设备提供高性能的模型。
-
性能与延迟的优化:RepViT在保持低延迟的同时,实现了超越现有最先进轻量级ViTs和CNNs的性能,特别是在ImageNet数据集上达到了超过80%的top-1准确率,且在iPhone 12上的延迟仅为1.0毫秒。
-
架构设计的创新:文章详细介绍了RepViT架构的设计过程,包括块设计、宏观设计和微观设计,这些设计决策共同促进了模型性能的提升和延迟的降低。
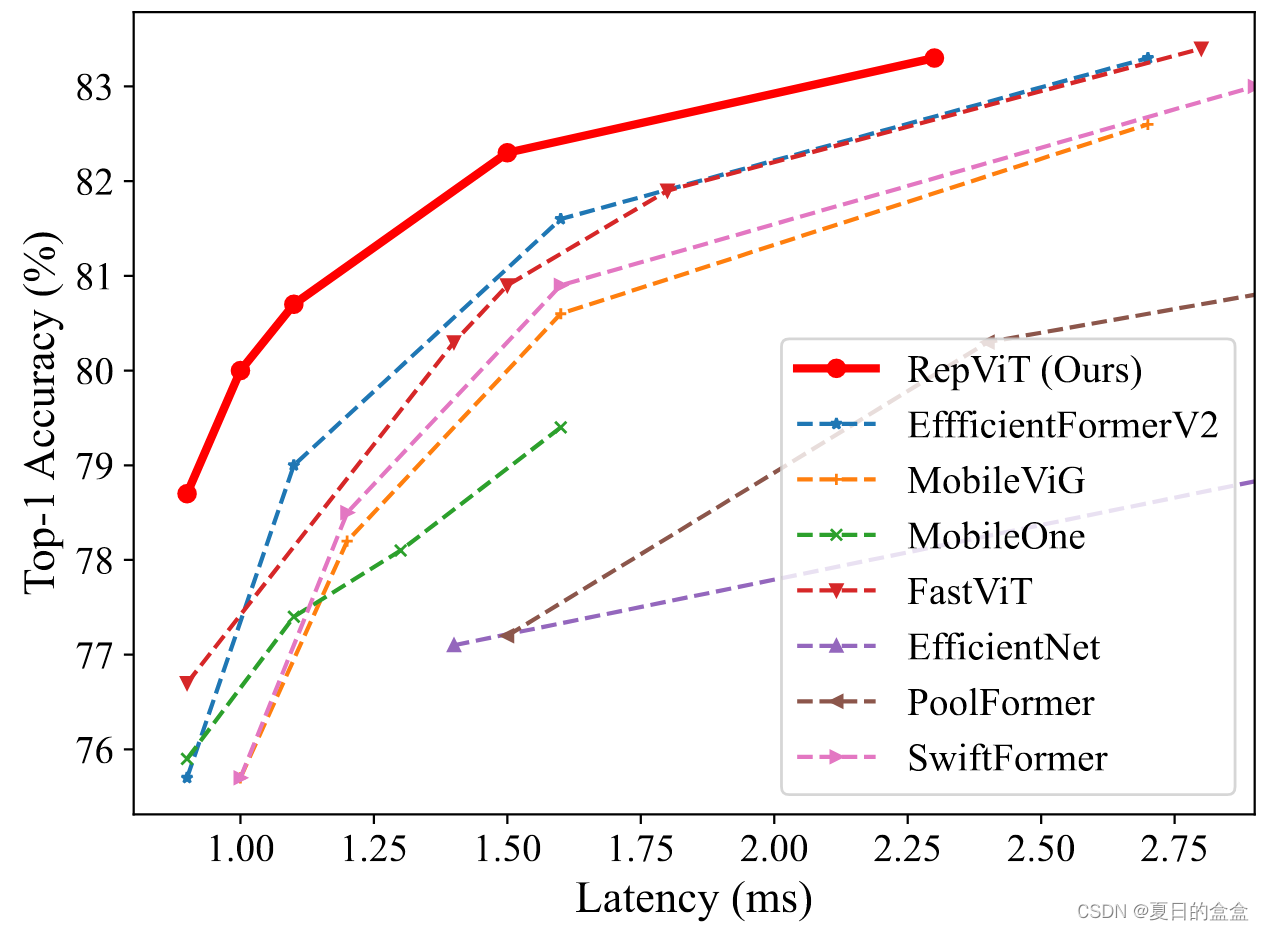
延迟 vs 准确性:
Method
2.1 预备知识
延迟度量:作者选择在移动设备上的实际延迟作为模型性能评估的基准,而不是传统的FLOPs或模型大小,因为这些指标与移动应用中的实际延迟相关性不高。
训练对齐:为了公平比较,作者将MobileNetV3-L的训练与现有的轻量级ViTs对齐,包括使用AdamW优化器、余弦学习率调度器、数据增强技术如Mixup、自动增强和随机擦除,以及标签平滑作为正则化方案。
2.2 块设计
2.2.1 Separate token mixer and channel mixer
动机:轻量级ViTs的一个关键设计特征是将Token Mixer和Channel Mixer分开。这种分离基于MetaFormer架构,已被证明对ViTs的有效性至关重要。

如图2(a)所示:
- 在MobileNetV3-L中,原始的块结构采用1×1扩展卷积和1×1投影层来实现通道间的交互(即Channel Mixer),并在1×1扩展卷积之后使用3×3深度卷积(DW)来融合空间信息(即Token Mixer)。这种设计将Token Mixer和Channel Mixer耦合在一起。
- 为了分离它们,作者首先将DW卷积上移,并在DW之后放置可选的Squeeze-and-Excitation(SE)层,因为SE层依赖于空间信息的交互。(通过将DW卷积移动到1×1扩展卷积之前,我们可以首先对每个通道进行空间混合,然后再通过1×1卷积进行通道混合。这样,空间信息的混合和通道信息的混合就不再是顺序依赖的,而是可以独立进行。)
- 采用结构重参数化技术来增强模型在训练期间的学习能力。这种技术允许在推理过程中消除跳跃连接带来的计算和内存成本,这对移动设备尤其有利。
扩展阅读:
扩展卷积(Expansion Convolution):处理通道信息
- 扩展卷积通常用于CNN中的“扩展层”或“瓶颈层”,其目的是在不显著增加参数数量的情况下增加特征图的维度。
- 在MobileNetV2和MobileNetV3等架构中,扩展卷积通过1×1的卷积操作来实现通道数的增加,这有助于在后续的深度卷积层中捕获更丰富的特征。
深度卷积(Depthwise Convolution):处理空间信息
- 深度卷积是一种对输入特征图的每个通道分别应用的卷积操作,每个通道的卷积核独立于其他通道。
- 这种卷积方式可以增加特征图的空间维度,同时保持较低的计算成本,因为它允许每个输入通道独立地学习空间特征。
- 在MobileNet系列架构中,深度卷积通常与扩展卷积结合使用,以实现有效的特征提取和降维。
投影(Projection Layer):
- 投影层通常指的是1×1的卷积层,它用于调整特征图的通道数,而不会改变其空间维度。
- 在某些CNN架构中,如MobileNetV1,投影层用于在深度卷积后减少特征图的通道数,以降低后续层的计算负担。
- 在Transformer架构中,投影层也可以用于将多头自注意力(Multi-Head Self-Attention, MHSA)模块的输出投影回原始维度,以准备进行下一轮的自注意力计算。
拓展阅读2:
Token Mixer:
- 在ViT中,Token Mixer通常指的是多头自注意力机制(MHSA),它允许模型在不同位置的输入特征(tokens)之间建立联系,通过注意力权重来强调某些特征。这种机制有助于模型捕获全局上下文信息。
Channel Mixer:
- Channel Mixer通常指的是在特征的通道维度上进行混合的操作,如1×1的卷积,它允许模型在保持空间位置不变的同时,重新分配和组合不同通道的特征信息。
分开的原因:
- 在一些传统的ViT架构中,Token Mixer和Channel Mixer可能是结合在一起的,这意味着它们在同一个操作中同时发生。然而,这种耦合可能不利于模型的效率和灵活性,尤其是在需要处理不同分辨率或在资源受限的设备上运行时。
效果:将 MobileNetV3-L 的延迟降低到 0.81 ms,以及临时性能下降到 68.3%。
2.2.2 Reducing expansion ratio and increasing width
扩展比(Expansion Ratio):扩展比是指在网络中的某些层,特别是卷积层或前馈网络(Feed Forward Network, FFN)中,输出通道数与输入通道数的比例。例如,如果一个层的扩展比是4,那么它的输出通道数是输入通道数的4倍。
扩展比的调整:
在传统的ViT中,FFN模块的扩展比通常设置为4,这意味着FFN的隐藏维度是输入维度的4倍。这种设计虽然有助于捕获复杂的特征,但也导致了计算资源的大量消耗。
网络宽度(Width):网络宽度指的是网络中通道的数量。增加网络宽度可以提供更多的特征表示能力,有助于提高模型的性能。
宽度的调整:
为了补偿降低扩展比带来的参数减少,作者提出增加网络的宽度。例如,在每个阶段之后加倍通道数,从而在保持或提高性能的同时,减少模型的延迟。
方案:
RepViT在通道混合器中为所有阶段设置扩展比为 2,随着扩展比较小,我们可以增加网络宽度来弥补较大的参数减少。我们在每个阶段之后对通道进行双重处理,每个阶段最终得到48,96,192和384个通道。
效果:在 0.91 ms 的类似延迟下获得了 73.0% 的 top-1 准确率的较差性能。
2.3 宏观设计
2.3.1 Early convolutions for stem
动机:
Stem是CNN中的第一个卷积层,它负责从原始图像中提取初步的特征表示。在ViT和一些轻量级CNN中,Stem通常使用patchify操作,将输入图像分割成小块。Patchify操作虽然简单,但可能导致优化问题和对训练配置的敏感性。这是因为它将图像分割成固定大小的非重叠块,这可能不利于模型学习有效的特征表示。
为了解决上述问题,引入了早期卷积的概念。这种方法使用几个stride为2的3×3卷积层作为Stem,以替代传统的patchify操作。
早期卷积的优势:使用早期卷积可以提高优化稳定性和性能。这是因为较小的卷积核可以更好地捕捉局部特征,并且多层堆叠可以逐渐增加感受野,从而有助于模型学习更丰富的特征表示。
实现细节:在RepViT架构中,作者采用了两个3×3卷积层,步长为2,作为Stem。第一个卷积层的过滤器数量设置为24,第二个卷积层设置为48。

效果:整体延迟降低到 0.86 ms。top-1 准确率提高到 73.9%。
2.3.2 Deeper downsampling layers
动机:在CNN中,下采样层负责减少特征图的空间维度,同时增加特征的深度,这有助于模型捕获不同尺度的特征并减少计算量。在标准的ViT和一些轻量级CNN中,下采样通常由单独的层完成,例如通过步长大于1的卷积或池化操作。然而,这种简单的下采样可能会导致信息丢失,影响模型性能。
深化下采样层的策略:
通过增加下采样层的深度来提高网络的性能。这包括使用多个连续的卷积层来逐步降低特征图的分辨率,同时增加特征的深度。
具体实现:
- 在RepViT中,作者首先使用一个步长为2的深度卷积(DW convolution)进行空间下采样,然后使用一个1×1的逐点卷积(pointwise convolution)来调整通道维度。
- 为了进一步加深下采样层并捕获更多的信息,作者在逐点卷积后添加了一个前馈网络(FFN)模块,以记忆更多的潜在信息。

MobileNetV3-L仅通过步长为 = 2 的 DW 卷积,可能缺乏足够的网络深度,导致信息丢失和对模型性能的负面影响。因此,为了实现单独和更深的下采样层,我们首先使用stride = 2和pointwise 1 × 1卷积的DW卷积分别进行空间下采样和调制通道维度。
效果:将 top-1 准确率提高到 75.4%,延迟为 0.96 ms。
2.3.3 Simple classifier
动机:
分类器是CNN架构中的最后部分,负责将特征转换为最终的类别预测。在传统的CNN中,分类器通常包括全连接层、全局平均池化层或类似的结构。在一些现有的轻量级CNN中,分类器可能包含额外的卷积层和全连接层,这些设计虽然可以提高特征的表达能力,但也增加了计算复杂度和延迟。
简化分类器的设计:
使用更简单的分类器设计,以减少计算量并降低延迟。这种设计通常包括全局平均池化层(Global Average Pooling, GAP)后接一个线性层。
- 全局平均池化层可以有效地将特征图转换为一维特征向量,同时显著减少参数数量和计算量。这种操作对于减少模型大小和提高推理速度非常有益。
- 在全局平均池化之后,一个线性层(通常是一个全连接层)用于将池化后的特征映射到最终的类别上。这种设计简单且有效。
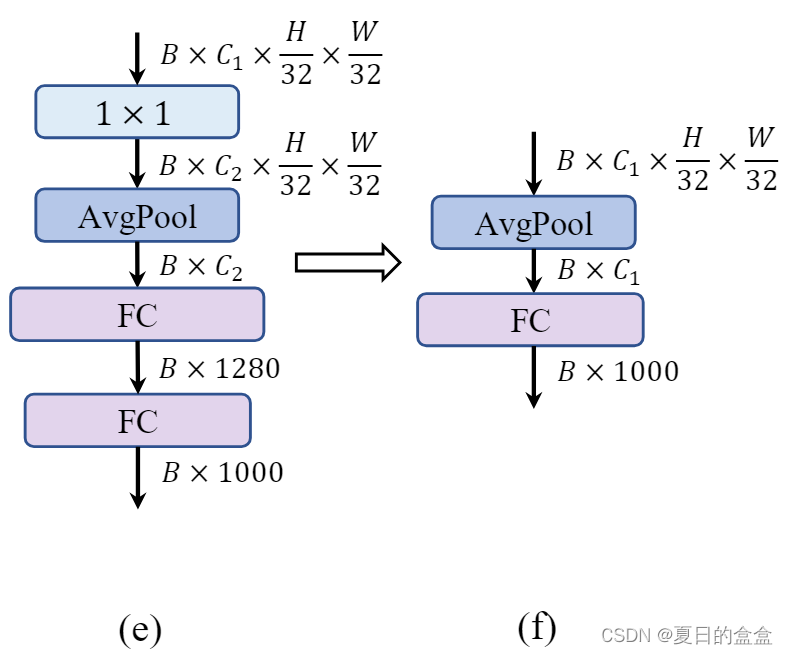
效果:精度下降 0.6%,但延迟降低到 0.77 ms。
2.3.4 Overall stage ratio
阶段比率(Stage Ratio):阶段比率是指网络中不同阶段的层数或块数的比例。这个比例对网络的性能和计算效率有重要影响。
动机:在第三阶段使用更多的层数可以带来准确性和速度之间的良好平衡。现有的轻量级ViTs通常在第三阶段应用更多的块,以实现更好的性能。
对网络采用 1:1:7:1 的阶段比率。然后,我们将网络深度增加到 2:14:2,实现更深的布局。
效果:将 top-1 准确率提高到 76.9%,延迟为 0.91 ms。
2.4 微观设计
2.4.1 Kernel size selection
动机:
- 卷积核的大小直接影响CNN的性能和计算效率。较大的卷积核可以捕获更广泛的上下文信息,但会增加计算复杂度和延迟,特别是在移动设备上。
- 一些研究工作,如ConvNeXt和RepLKNet,展示了使用大卷积核可以提高性能,但这些研究通常不针对移动设备优化。
在移动设备上,由于计算资源和内存访问成本的限制,大卷积核可能不是最优选择。此外,编译器和计算库通常对3×3卷积核有更高度的优化。
效果:保持76.9%的最高精度,同时延迟降低到0.89 ms。
2.4.2 Squeeze-and-excitation layer placement
动机:
- SE层作为一种通道注意力模块,可以弥补卷积在缺乏数据驱动属性方面的局限性,带来更好的性能。
- 尽管SE层能够提升性能,但它也会引入额外的计算成本。因此,在设计轻量级模型时,需要仔细考虑SE层的放置,以平衡性能增益和计算效率。
先前研究的启示:引用了先前的研究,指出在低分辨率特征图的阶段使用SE层可能不会带来显著的准确率提升,而在高分辨率特征图的阶段使用SE层则可以更有效地提升性能。
具体方案:
在RepViT中,采用了一种跨块的SE层放置策略。具体来说,每个阶段中的第1、3、5...个块使用SE层,这种交错放置方式旨在最大化准确率的提升,同时控制延迟的增加。
效果:准确率达到77.4%,延迟为0.87 ms。
拓展阅读:
SE模块:
Squeeze:
- 这一步骤通过全局平均池化(Global Average Pooling, GAP)将特征图压缩成一个单一的通道。这意味着无论特征图的空间维度有多大,都会被压缩成一个包含所有空间信息的单一数值。
- 这种压缩操作生成了一个长度为1的全局特征向量,它捕获了输入特征图的全局空间信息。
Excitation:
- 接下来,这个全局特征向量通过几个全连接(FC)层进行非线性变换,通常包括一个ReLU激活函数和一个sigmoid激活函数。
- ReLU层引入非线性,而sigmoid层则将输出值压缩到0和1之间,生成一个与输入通道数相同长度的权重向量。

Result
如表所示,RepViT在各种模型大小上始终实现最先进的性能。在类似的延迟情况下,RepViTM0.9可以显著优于EfficientFormerV2-S0和fastvitt - t8,准确率分别提高3.0%和2.0%。与EfficientFormerV2-S1相比,repviti - m1.1还可以获得1.7%的性能提升。值得注意的是,repviti - m1.0在iPhone 12上以1.0 ms的延迟实现了超过80%的top-1精度,据我们所知,这是轻量级机型的第一次。我们最大的模型,repviti - m2.3,获得83.7%的准确率,只有2.3毫秒的延迟。以上结果很好地表明,通过结合高效的架构设计,纯轻量级cnn可以在移动设备上优于现有的最先进的轻量级vit。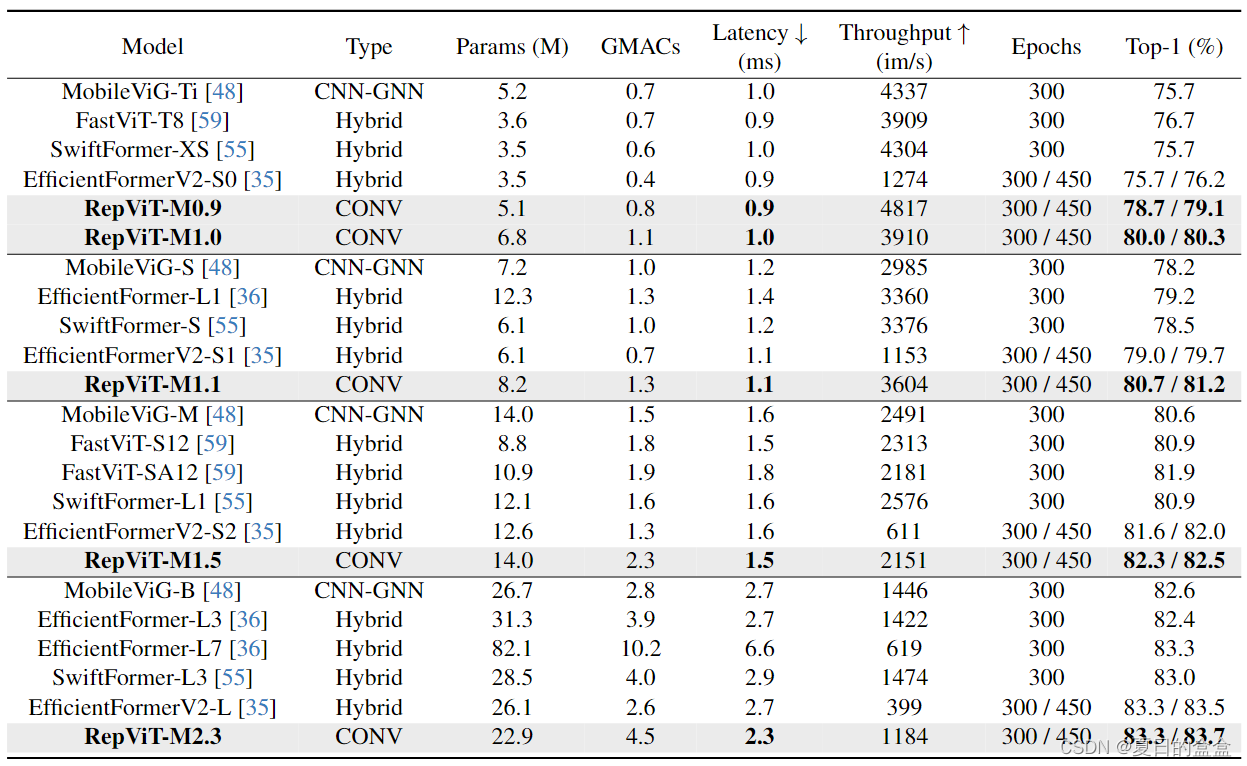 Conclusion
Conclusion
在本文中,我们通过结合轻量级vit的架构设计来重新审视轻量级cnn的高效设计。这就产生了RepViT,这是一个针对资源有限的移动设备的新型轻量级cnn系列。在各种视觉任务上,RepViT优于现有的最先进的轻量级vit和cnn,表现出良好的性能和延迟。这凸显了面向移动设备的纯轻量级cnn的前景。我们希望RepViT可以作为一个强大的基线,并激发对轻量级模型的进一步研究。