Gaussian_model
讨论Gaussian_model这个类,是因为里面包含了三维高斯分布的基本信息,里面定义了各种参量的构建方式、用于优化学习的激活函数、学习率设置方法和高斯点优化过程中的增加与删除方式及对应优化器的处理方法。这个类定义在scene文件夹中的gaussian_module.py文件里。
scene/gaussian_model中进行函数构建
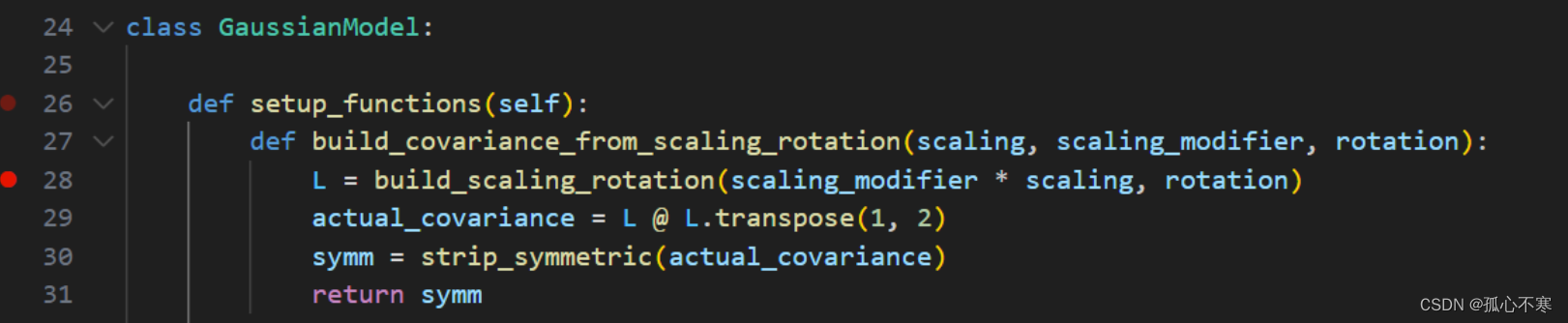
协方差矩阵和各种参数的激活函数
首先这个方法构建了协方差矩阵,而其中旋转、缩放矩阵在以下文件中:
utils/general_utils的build_rotation中构建旋转矩阵
'''
用来计算四元数表示的旋转矩阵(Rotation Matrix)的。。
首先,通过计算每个四元数的模长,来标准化它们。这是为了确保旋转向量(四元数)的单位长度,以便于正确地进行旋转计算。
接着,将标准化后的四元数应用到旋转矩阵上。这里,代码创建了一个大小为 (batch_size, 3, 3) 的零张量 R,然后,通过四元数的各个分量进行矩阵赋值,根据四元数到旋转矩阵的转换公式来填充这个张量。
最后,返回填充完的旋转矩阵 R。
需要注意的是,这段代码是针对批处理的,因此输入 r 是一个张量,其中每一行代表一个四元数。
'''
def build_rotation(r):
norm = torch.sqrt(r[:,0]*r[:,0] + r[:,1]*r[:,1] + r[:,2]*r[:,2] + r[:,3]*r[:,3])
q = r / norm[:, None]
R = torch.zeros((q.size(0), 3, 3), device='cuda')
r = q[:, 0]
x = q[:, 1]
y = q[:, 2]
z = q[:, 3]
R[:, 0, 0] = 1 - 2 * (y*y + z*z)
R[:, 0, 1] = 2 * (x*y - r*z)
R[:, 0, 2] = 2 * (x*z + r*y)
R[:, 1, 0] = 2 * (x*y + r*z)
R[:, 1, 1] = 1 - 2 * (x*x + z*z)
R[:, 1, 2] = 2 * (y*z - r*x)
R[:, 2, 0] = 2 * (x*z - r*y)
R[:, 2, 1] = 2 * (y*z + r*x)
R[:, 2, 2] = 1 - 2 * (x*x + y*y)
return R
utils/general_utils的build_scaling_rotation中构建缩放矩阵并将旋转矩阵和缩放矩阵合并
def build_scaling_rotation(s, r):
L = torch.zeros((s.shape[0], 3, 3), dtype=torch.float, device="cuda")
R = build_rotation(r)
L[:,0,0] = s[:,0]
L[:,1,1] = s[:,1]
L[:,2,2] = s[:,2]
L = R @ L
return L
scene/gaussian_model的setup_functions中用build_covariance_from_scaling_rotation中将旋转矩阵和缩放矩阵合并并处理成协方差矩阵。并在setup_functions中设定激活函数。
def setup_functions(self):
def build_covariance_from_scaling_rotation(scaling, scaling_modifier, rotation):
L = build_scaling_rotation(scaling_modifier * scaling, rotation)
actual_covariance = L @ L.transpose(1, 2)
symm = strip_symmetric(actual_covariance)
return symm
self.scaling_activation = torch.exp
self.scaling_inverse_activation = torch.log
self.covariance_activation = build_covariance_from_scaling_rotation
self.opacity_activation = torch.sigmoid
self.inverse_opacity_activation = inverse_sigmoid
self.rotation_activation = torch.nn.functional.normalize
'''
self.scaling_activation = torch.exp:这行代码将指数函数 torch.exp 赋值给了 self.scaling_activation。这意味着在网络中,会使用指数函数作为缩放操作的激活函数。
self.scaling_inverse_activation = torch.log:这行代码将对数函数 torch.log 赋值给了 self.scaling_inverse_activation。这表示在网络中,会使用对数函数作为缩放的逆操作的激活函数。
self.covariance_activation = build_covariance_from_scaling_rotation:这行代码将一个函数 build_covariance_from_scaling_rotation 赋值给了 self.covariance_activation。这可能是一个自定义的函数,用于构建协方差矩阵,该函数可能会使用了缩放和旋转操作。
self.opacity_activation = torch.sigmoid:这行代码将 sigmoid 函数 torch.sigmoid 赋值给了 self.opacity_activation。这表示在网络中,会使用 sigmoid 函数作为不透明度的激活函数。
self.inverse_opacity_activation = inverse_sigmoid:这行代码将一个函数 inverse_sigmoid 赋值给了 self.inverse_opacity_activation。这可能是一个自定义的函数,用于计算 sigmoid 函数的逆操作。
self.rotation_activation = torch.nn.functional.normalize:这行代码将归一化函数 torch.nn.functional.normalize 赋值给了 self.rotation_activation。这表示在网络中,会使用归一化函数作为旋转操作的激活函数。
'''
点云数据的处理
初始化参数的含义:
def __init__(self, sh_degree: int):
# 初始化球谐函数相关的度数
# 初始化当前活动的球谐函数度数为 0,并将最大球谐函数度数设置为传入的 sh_degree 参数。
self.active_sh_degree = 0
self.max_sh_degree = sh_degree
# 初始化存储点、球谐函数系数、缩放、旋转、不透明度等的张量为空张量
self._xyz = torch.empty(0)
self._features_dc = torch.empty(0)
self._features_rest = torch.empty(0)
self._scaling = torch.empty(0)
self._rotation = torch.empty(0)
self._opacity = torch.empty(0)
# 初始化高斯分布投影后的最大二维半径、梯度累积器(用于辨别是否需要新增和删除高斯)和分母张量(表示统计了多少次累计梯度,最后要把这个分母张量除掉)为空张量
self.max_radii2D = torch.empty(0)
self.xyz_gradient_accum = torch.empty(0)
self.denom = torch.empty(0)
# 初始化优化器optimizer为 None
self.optimizer = None
# 初始化密度百分比和空间学习率缩放因子(用于处理不同参数对学习率的要求)
self.percent_dense = 0
self.spatial_lr_scale = 0
# 调用设置函数的方法进行必要的初始化
self.setup_functions()
scene/gaussian_model的create_from_pcd
def create_from_pcd(self, pcd : BasicPointCloud, spatial_lr_scale : float):
self.spatial_lr_scale = spatial_lr_scale
# 将点云数据中的点坐标转换为 PyTorch 张量,并放置在 GPU 上进行加速处理
fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda()
'''
球谐函数这一堆写在另一个文件里。
'''
print("Number of points at initialisation : ", fused_point_cloud.shape[0])
# 计算点云中每个点与原点的欧氏距离的平方,并将其限制在一个最小值以上,以避免出现除以零的情况
'''
这行代码使用了函数 distCUDA2 来计算点云中每个点之间的距离,并将结果存储在 dist2 变量中。
torch.from_numpy(np.asarray(pcd.points)).float().cuda() 将点云数据转换为 PyTorch 张量,并将其移到 GPU 上。
torch.clamp_min 函数用于将 dist2 中的所有元素的最小值限制为 0.0000001,以确保不会出现零距离。
'''
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)
'''
这行代码首先计算了 dist2 中每个元素的平方根,然后取其自然对数。
[..., None] 用于在张量的最后一个维度上添加一个新的维度。
repeat(1, 3) 表示沿着第一个维度将张量复制三次,以便将其扩展为与 fused_point_cloud 相同的形状,其中 fused_point_cloud 是点云的坐标。
最终,scales 是一个与 fused_point_cloud 具有相同形状的张量,用于存储每个点的缩放因子。
'''
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
'''
这行代码创建了一个形状为 (点数, 4) 的全零张量 rots,用于存储点云中每个点的旋转信息。
每个点的旋转信息是一个四维向量,其中第一个元素为1,其余元素为0,表示点云中的每个点都没有旋转。
'''
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
'''
这行代码将 rots 张量的第一列(即第一个元素)设置为1,以表示每个点的旋转信息中的第一个元素为1,其余元素为0,即单位四元数。
'''
rots[:, 0] = 1
# 计算每个点的不透明度,这里使用了一个 sigmoid 函数的逆函数
opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))
# 将点云的坐标、特征、尺度、旋转和不透明度分别存储为对象的参数,并设置为可训练
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(True))
self._opacity = nn.Parameter(opacities.requires_grad_(True))
# 初始化一个用于存储二维最大半径的张量,其形状与点云的数量相同
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
这里再放一个代码块说一下这个distCUDA2的函数是怎么定义的,在simple-knn/spatial.cu中
// 计算输入张量 `points` 中每个点到其他所有点的距离之和,并返回每个点的平均距离。
torch::Tensor distCUDA2(const torch::Tensor& points)
{
const int P = points.size(0); // 点的数量
auto float_opts = points.options().dtype(torch::kFloat32); // Float32 类型选项
torch::Tensor means = torch::full({P}, 0.0, float_opts); // 用于存储平均距离的张量
// 调用 SimpleKNN::knn 函数计算距离
SimpleKNN::knn(P, (float3*)points.contiguous().data<float>(), means.contiguous().data<float>());
return means; // 返回包含平均距离的张量
}
这就是点云文件ply以文本形式打开后的变量内容,里面的参量很好理解。重点说一下f_dc是球谐函数的直流分量,而f_rest是球谐函数的高阶分量。nx,ny,nz是每个高斯分布的法向量,但考虑到高斯分布的性质,这里的法向量都设置为0。

def training_setup(self, training_args):
# 保存训练参数中的 percent_dense 到对象的属性中,用于后续的训练。
self.percent_dense = training_args.percent_dense
# 创建一个全零张量 xyz_gradient_accum,用于累积 xyz 坐标的梯度,张量的形状与 self.get_xyz 的第一维度匹配,并将其放置在 GPU 上。
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
# 创建一个全零张量 denom,用于存储某种归一化或计数信息,张量的形状与 self.get_xyz 的第一维度匹配,并将其放置在 GPU 上。
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
l = [
{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},
{'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"},
{'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"},
{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},
{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},
{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"}
]
# 使用 Adam 优化器,将参数列表 l 传递给优化器,并设置优化器的全局学习率为 0.0(具体学习率在每个参数字典中指定),以及非常小的 eps 值 1e-15。
self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15)
# lr_init: 初始学习率,按 self.spatial_lr_scale 进行缩放。lr_final: 最终学习率,按 self.spatial_lr_scale 进行缩放。lr_delay_mult: 学习率延迟倍数。max_steps: 最大训练步数。
self.xyz_scheduler_args = get_expon_lr_func(lr_init=training_args.position_lr_init*self.spatial_lr_scale, lr_final=training_args.position_lr_final*self.spatial_lr_scale,
lr_delay_mult=training_args.position_lr_delay_mult,
max_steps=training_args.position_lr_max_steps)
def update_learning_rate(self, iteration):
''' Learning rate scheduling per step '''
# 遍历 self.optimizer 中的所有参数组。self.optimizer.param_groups 是一个包含多个字典的列表,每个字典包含了一组参数及其相关的优化信息(例如学习率)。
for param_group in self.optimizer.param_groups:
# 检查当前参数组的名称是否为 "xyz"。只有名称为 "xyz" 的参数组才会进行学习率更新。
if param_group["name"] == "xyz":
# 调用 self.xyz_scheduler_args 函数,并传入当前的迭代次数 iteration。self.xyz_scheduler_args 是一个学习率调度函数,根据当前的迭代次数计算并返回新的学习率 lr。
lr = self.xyz_scheduler_args(iteration)
# 将计算得到的新学习率 lr 更新到当前的参数组中,使其在接下来的训练步骤中使用新的学习率。
param_group['lr'] = lr
return lr
def construct_list_of_attributes(self):
# 初始化一个列表 l,包含一些固定的属性名称:'x', 'y', 'z' 表示点的坐标,'nx', 'ny', 'nz' 表示法线的分量
l = ['x', 'y', 'z', 'nx', 'ny', 'nz']
# All channels except the 3 DC
# 遍历 _features_dc 的通道和特征维度,生成特征属性名称
for i in range(self._features_dc.shape[1] * self._features_dc.shape[2]):
l.append('f_dc_{}'.format(i))
# 遍历 _features_rest 的通道和特征维度,生成特征属性名称
for i in range(self._features_rest.shape[1] * self._features_rest.shape[2]):
l.append('f_rest_{}'.format(i))
# 添加透明度属性
l.append('opacity')
# 遍历 _scaling 张量的所有通道,生成缩放因子属性名称
for i in range(self._scaling.shape[1]):
l.append('scale_{}'.format(i))
# 遍历 _rotation 张量的所有通道,生成旋转信息属性名称
for i in range(self._rotation.shape[1]):
l.append('rot_{}'.format(i))
return l
def save_ply(self, path):
# 创建保存路径的目录,如果目录不存在
mkdir_p(os.path.dirname(path))
# 获取 xyz 坐标,并将其从 GPU 上移至 CPU,并转换为 numpy 数组
xyz = self._xyz.detach().cpu().numpy()
# 初始化法向量数组,大小与 xyz 坐标相同
normals = np.zeros_like(xyz)
# 获取并处理特征数据,将其从 GPU 移至 CPU,并转换为 numpy 数组
f_dc = self._features_dc.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()
f_rest = self._features_rest.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()
# 获取并处理不透明度数据
opacities = self._opacity.detach().cpu().numpy()
# 获取并处理缩放数据
scale = self._scaling.detach().cpu().numpy()
# 获取并处理旋转数据
rotation = self._rotation.detach().cpu().numpy()
# 构建 dtype,用于 numpy 的结构化数组,包含所有属性名称及其类型
dtype_full = [(attribute, 'f4') for attribute in self.construct_list_of_attributes()]
# 创建一个空的结构化数组,用于存储所有顶点的数据
elements = np.empty(xyz.shape[0], dtype=dtype_full)
# 将所有属性组合到一个二维数组中
attributes = np.concatenate((xyz, normals, f_dc, f_rest, opacities, scale, rotation), axis=1)
# 将属性数据逐个赋值到结构化数组中
elements[:] = list(map(tuple, attributes))
# 创建 PlyElement 并将其描述为 'vertex'
el = PlyElement.describe(elements, 'vertex')
# 将 PlyData 写入到指定路径
PlyData([el]).write(path)
def reset_opacity(self):
'''
获取当前透明度张量self.get_opacity。
将所有透明度值限制在不超过0.01。
对限制后的透明度值应用反Sigmoid函数。
将新的透明度张量opacities_new替换到优化器中,并更新对象的透明度属性self._opacity。
'''
opacities_new = inverse_sigmoid(torch.min(self.get_opacity, torch.ones_like(self.get_opacity) * 0.01))
optimizable_tensors = self.replace_tensor_to_optimizer(opacities_new, "opacity")
self._opacity = optimizable_tensors["opacity"]
def load_ply(self, path):
# 读取给定路径的PLY文件,并将数据加载到类的属性中。
# 使用PlyData.read方法读取PLY文件的数据。
plydata = PlyData.read(path)
# 从PLY文件中提取x, y, z坐标并堆叠成一个二维数组xyz。
xyz = np.stack((np.asarray(plydata.elements[0]["x"]),
np.asarray(plydata.elements[0]["y"]),
np.asarray(plydata.elements[0]["z"])), axis=1)
# 从PLY文件中提取opacity值,并添加一个新轴,以便与其他属性的维度一致。
opacities = np.asarray(plydata.elements[0]["opacity"])[..., np.newaxis]
# 创建一个形状为(顶点数, 3, 1)的零数组features_dc。
# 从PLY文件中提取f_dc_0, f_dc_1, f_dc_2特征,并分别填充到features_dc中。
features_dc = np.zeros((xyz.shape[0], 3, 1))
features_dc[:, 0, 0] = np.asarray(plydata.elements[0]["f_dc_0"])
features_dc[:, 1, 0] = np.asarray(plydata.elements[0]["f_dc_1"])
features_dc[:, 2, 0] = np.asarray(plydata.elements[0]["f_dc_2"])
# 提取所有以"f_rest_"开头的属性名,并按后缀数字排序。
# 断言这些属性的数量符合期望。
# 创建一个形状为(顶点数, 特征数)的零数组features_extra。
# 从PLY文件中提取相应的特征,并填充到features_extra中。
# 重新调整数组的形状,以便特征维度与SH系数一致。
extra_f_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("f_rest_")]
extra_f_names = sorted(extra_f_names, key=lambda x: int(x.split('_')[-1]))
assert len(extra_f_names) == 3 * (self.max_sh_degree + 1) ** 2 - 3
features_extra = np.zeros((xyz.shape[0], len(extra_f_names)))
for idx, attr_name in enumerate(extra_f_names):
features_extra[:, idx] = np.asarray(plydata.elements[0][attr_name])
features_extra = features_extra.reshape((features_extra.shape[0], 3, (self.max_sh_degree + 1) ** 2 - 1))
# 提取所有以"scale_"和"rot"开头的属性名,并按后缀数字排序。
# 创建零数组scales和rots,并从PLY文件中提取相应的属性值,填充到数组中。
scale_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("scale_")]
scale_names = sorted(scale_names, key=lambda x: int(x.split('_')[-1]))
scales = np.zeros((xyz.shape[0], len(scale_names)))
for idx, attr_name in enumerate(scale_names):
scales[:, idx] = np.asarray(plydata.elements[0][attr_name])
rot_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("rot")]
rot_names = sorted(rot_names, key=lambda x: int(x.split('_')[-1]))
rots = np.zeros((xyz.shape[0], len(rot_names)))
for idx, attr_name in enumerate(rot_names):
rots[:, idx] = np.asarray(plydata.elements[0][attr_name])
# 将所有提取的数据转换为PyTorch张量,并将其设置为可优化的参数(requires_grad_(True))。
# 使用transpose(1, 2)和contiguous()确保张量的内存布局适合后续计算。
self._xyz = nn.Parameter(torch.tensor(xyz, dtype=torch.float, device="cuda").requires_grad_(True))
self._features_dc = nn.Parameter(torch.tensor(features_dc, dtype=torch.float, device="cuda").transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(torch.tensor(features_extra, dtype=torch.float, device="cuda").transpose(1, 2).contiguous().requires_grad_(True))
self._opacity = nn.Parameter(torch.tensor(opacities, dtype=torch.float, device="cuda").requires_grad_(True))
self._scaling = nn.Parameter(torch.tensor(scales, dtype=torch.float, device="cuda").requires_grad_(True))
self._rotation = nn.Parameter(torch.tensor(rots, dtype=torch.float, device="cuda").requires_grad_(True))
# 将active_sh_degree设置为max_sh_degree,表示当前使用的SH度数。
self.active_sh_degree = self.max_sh_degree
接下来的内容是关于自适应密度控制
这些代码同样在scene/gaussian_model中。
def replace_tensor_to_optimizer(self, tensor, name):
# 将新的张量替换为优化器中的参数,同时保留优化器的状态。这个很重要,后面处理参数都要靠这个方法!!!
# 用于存储新的可优化张量。
optimizable_tensors = {}
# 优化器的参数组包含了所有要优化的参数和相关设置。
for group in self.optimizer.param_groups:
# 检查参数组的名字是否与给定的名字匹配。
if group["name"] == name:
# 获取当前参数的状态,包括动量项和二次动量项。
stored_state = self.optimizer.state.get(group['params'][0], None)
# 将动量项和二次动量项重置为与新张量相同形状的零张量。
stored_state["exp_avg"] = torch.zeros_like(tensor)
stored_state["exp_avg_sq"] = torch.zeros_like(tensor)
# 删除旧参数的状态。
del self.optimizer.state[group['params'][0]]
# 将参数组中的第一个参数替换为新的张量,并设置为需要梯度。
group["params"][0] = nn.Parameter(tensor.requires_grad_(True))
# 将存储的状态重新设置到新的参数上。
self.optimizer.state[group['params'][0]] = stored_state
# 将新的参数添加到字典中。
optimizable_tensors[group["name"]] = group["params"][0]
# 返回包含新的可优化张量的字典。
return optimizable_tensors
'''
后面做自适应密度控制的时候,所用的方法如果需要替换优化器中的参数,都需要使用这个replace_tensor_to_optimizer方法。这个方法可以确保新的参数替换后,优化器的状态(例如动量和二次动量)能够被正确保留,使得训练过程平稳进行。通过这种方式,可以有效地管理和更新优化器中的参数,而不会丢失已有的优化状态。
'''
def _prune_optimizer(self, mask):
# 通过应用掩码(mask)来选择需要保留的参数,并相应地更新优化器的状态。
# 初始化优化参数字典
optimizable_tensors = {}
# 遍历优化器参数组
for group in self.optimizer.param_groups:
# 如果有存储状态(例如动量和二次动量),则更新这些状态,使其只包含被掩码保留的部分。
stored_state = self.optimizer.state.get(group['params'][0], None)
if stored_state is not None:
stored_state["exp_avg"] = stored_state["exp_avg"][mask]
stored_state["exp_avg_sq"] = stored_state["exp_avg_sq"][mask]
# 删除旧参数并用掩码后的参数替换,无论是否有存储状态
del self.optimizer.state[group['params'][0]]
group["params"][0] = nn.Parameter((group["params"][0][mask].requires_grad_(True)))
# 如果有存储状态,则将其重新分配到新的参数上
self.optimizer.state[group['params'][0]] = stored_state
# 记录更新后的参数
optimizable_tensors[group["name"]] = group["params"][0]
else:
# 如果没有存储状态,仅更新参数组中的参数
group["params"][0] = nn.Parameter(group["params"][0][mask].requires_grad_(True))
optimizable_tensors[group["name"]] = group["params"][0]
# 返回更新后的参数字典
return optimizable_tensors
def prune_points(self, mask):
# 对输入掩码取反,得到有效点的掩码
valid_points_mask = ~mask
# 调用 _prune_optimizer 方法,使用有效点的掩码来更新优化器中的参数
optimizable_tensors = self._prune_optimizer(valid_points_mask)
# 更新类中的各个属性,使其只包含有效点
self._xyz = optimizable_tensors["xyz"]
self._features_dc = optimizable_tensors["f_dc"]
self._features_rest = optimizable_tensors["f_rest"]
self._opacity = optimizable_tensors["opacity"]
self._scaling = optimizable_tensors["scaling"]
self._rotation = optimizable_tensors["rotation"]
# 更新 xyz_gradient_accum 以仅包含有效点
self.xyz_gradient_accum = self.xyz_gradient_accum[valid_points_mask]
# 更新 denom 和 max_radii2D 以仅包含有效点
self.denom = self.denom[valid_points_mask]
self.max_radii2D = self.max_radii2D[valid_points_mask]
def cat_tensors_to_optimizer(self, tensors_dict):
# 初始化优化参数字典
optimizable_tensors = {}
# 遍历优化器参数组
for group in self.optimizer.param_groups:
assert len(group["params"]) == 1
# 从字典中获取要扩展的张量
extension_tensor = tensors_dict[group["name"]]
# 获取参数组的存储状态(例如动量和二次动量)
stored_state = self.optimizer.state.get(group['params'][0], None)
if stored_state is not None:
# 扩展动量和二次动量
stored_state["exp_avg"] = torch.cat((stored_state["exp_avg"], torch.zeros_like(extension_tensor)), dim=0)
stored_state["exp_avg_sq"] = torch.cat((stored_state["exp_avg_sq"], torch.zeros_like(extension_tensor)), dim=0)
# 更新参数组中的参数,并将其设置为需要梯度计算的模式
del self.optimizer.state[group['params'][0]]
group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))
self.optimizer.state[group['params'][0]] = stored_state
# 将扩展后的参数存储到优化参数字典中
optimizable_tensors[group["name"]] = group["params"][0]
else:
# 如果没有存储状态,只更新参数组中的参数
group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))
optimizable_tensors[group["name"]] = group["params"][0]
return optimizable_tensors
def densification_postfix(self, new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation):
# 将新的数据构建成一个字典
d = {
"xyz": new_xyz,
"f_dc": new_features_dc,
"f_rest": new_features_rest,
"opacity": new_opacities,
"scaling": new_scaling,
"rotation": new_rotation
}
# 使用 cat_tensors_to_optimizer 方法,将新的数据添加到优化器中
optimizable_tensors = self.cat_tensors_to_optimizer(d)
# 更新实例变量,使其指向新的优化张量
self._xyz = optimizable_tensors["xyz"]
self._features_dc = optimizable_tensors["f_dc"]
self._features_rest = optimizable_tensors["f_rest"]
self._opacity = optimizable_tensors["opacity"]
self._scaling = optimizable_tensors["scaling"]
self._rotation = optimizable_tensors["rotation"]
# 初始化梯度累积器和相关变量
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
def densify_and_split(self, grads, grad_threshold, scene_extent, N=2):
# 获取初始点数
n_init_points = self.get_xyz.shape[0]
# 初始化一个与初始点数相同大小的全零张量,用于存储梯度
padded_grad = torch.zeros((n_init_points), device="cuda")
# 将输入的梯度值填充到全零张量中
padded_grad[:grads.shape[0]] = grads.squeeze()
# 选取满足梯度阈值的点,生成布尔掩码
selected_pts_mask = torch.where(padded_grad >= grad_threshold, True, False)
# 进一步筛选,确保缩放因子大于特定比例的场景范围
selected_pts_mask = torch.logical_and(selected_pts_mask,
torch.max(self.get_scaling, dim=1).values > self.percent_dense * scene_extent)
# 获取选中的点的缩放因子,并重复 N 次
stds = self.get_scaling[selected_pts_mask].repeat(N, 1)
# 初始化均值为零的张量
means = torch.zeros((stds.size(0), 3), device="cuda")
# 生成符合正态分布的噪声采样
samples = torch.normal(mean=means, std=stds)
# 构建旋转矩阵,并重复 N 次
rots = build_rotation(self._rotation[selected_pts_mask]).repeat(N, 1, 1)
# 计算新的点的坐标
new_xyz = torch.bmm(rots, samples.unsqueeze(-1)).squeeze(-1) + self.get_xyz[selected_pts_mask].repeat(N, 1)
# 计算新的缩放因子,并进行缩放处理
new_scaling = self.scaling_inverse_activation(self.get_scaling[selected_pts_mask].repeat(N, 1) / (0.8 * N))
# 复制旋转信息
new_rotation = self._rotation[selected_pts_mask].repeat(N, 1)
# 复制特征信息
new_features_dc = self._features_dc[selected_pts_mask].repeat(N, 1, 1)
new_features_rest = self._features_rest[selected_pts_mask].repeat(N, 1, 1)
# 复制透明度信息
new_opacity = self._opacity[selected_pts_mask].repeat(N, 1)
# 调用函数,将新生成的数据传入
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacity, new_scaling, new_rotation)
# 构建修剪掩码,将新生成的点也包含在内
prune_filter = torch.cat((selected_pts_mask, torch.zeros(N * selected_pts_mask.sum(), device="cuda", dtype=bool)))
# 调用修剪函数,移除不需要的点
self.prune_points(prune_filter)
def densify_and_clone(self, grads, grad_threshold, scene_extent):
# 根据梯度值和场景范围,选取满足条件的点
selected_pts_mask = torch.where(torch.norm(grads, dim=-1) >= grad_threshold, True, False)
selected_pts_mask = torch.logical_and(selected_pts_mask,
torch.max(self.get_scaling, dim=1).values <= self.percent_dense * scene_extent)
# 克隆选中的点
new_xyz = self._xyz[selected_pts_mask]
new_features_dc = self._features_dc[selected_pts_mask]
new_features_rest = self._features_rest[selected_pts_mask]
new_opacities = self._opacity[selected_pts_mask]
new_scaling = self._scaling[selected_pts_mask]
new_rotation = self._rotation[selected_pts_mask]
# 调用函数,将克隆的数据传入
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation)
def densify_and_prune(self, max_grad, min_opacity, extent, max_screen_size):
# 计算每个点的梯度值
grads = self.xyz_gradient_accum / self.denom
grads[grads.isnan()] = 0.0
# 调用密化和克隆函数
self.densify_and_clone(grads, max_grad, extent)
# 调用密化和分裂函数
self.densify_and_split(grads, max_grad, extent)
# 根据透明度生成修剪掩码
prune_mask = (self.get_opacity < min_opacity).squeeze()
# 如果指定了最大屏幕尺寸,根据屏幕尺寸生成修剪掩码
if max_screen_size:
big_points_vs = self.max_radii2D > max_screen_size
big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent
prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws)
# 调用修剪函数,移除不需要的点
self.prune_points(prune_mask)
# 清理 CUDA 缓存
torch.cuda.empty_cache()
def add_densification_stats(self, viewspace_point_tensor, update_filter):
# 累积选中点的梯度值
self.xyz_gradient_accum[update_filter] += torch.norm(viewspace_point_tensor.grad[update_filter, :2], dim=-1, keepdim=True)
# 更新选中点的计数
self.denom[update_filter] += 1
Camera
以下代码定义在scene/cameras.py中。
class Camera(nn.Module):
def __init__(self, colmap_id, R, T, FoVx, FoVy, image, gt_alpha_mask, image_name, uid, trans=np.array([0.0, 0.0, 0.0]), scale=1.0, data_device="cuda"):
"""
初始化 Camera 类
:param colmap_id: Colmap 中相机的 ID
:param R: 旋转矩阵
:param T: 平移向量
:param FoVx: 水平方向的视场角
:param FoVy: 垂直方向的视场角
:param image: 图像数据 (torch.Tensor)
:param gt_alpha_mask: ground truth alpha mask (torch.Tensor)
:param image_name: 图像名称
:param uid: 相机的唯一标识符
:param trans: 平移向量,默认为 [0.0, 0.0, 0.0]
:param scale: 缩放因子,默认为 1.0
:param data_device: 数据存储设备,默认为 "cuda"
"""
super(Camera, self).__init__()
# 初始化相机参数
self.uid = uid
self.colmap_id = colmap_id
self.R = R
self.T = T
self.FoVx = FoVx
self.FoVy = FoVy
self.image_name = image_name
# 尝试将数据设备设置为指定的设备
try:
self.data_device = torch.device(data_device)
except Exception as e:
print(e)
print(f"[Warning] Custom device {data_device} failed, fallback to default cuda device")
self.data_device = torch.device("cuda")
# 将图像数据限制在 [0.0, 1.0] 范围内并移动到指定设备
self.original_image = image.clamp(0.0, 1.0).to(self.data_device)
self.image_width = self.original_image.shape[2]
self.image_height = self.original_image.shape[1]
# 如果提供了 alpha mask,则将图像数据乘以 alpha mask
if gt_alpha_mask is not None:
self.original_image *= gt_alpha_mask.to(self.data_device)
else:
self.original_image *= torch.ones((1, self.image_height, self.image_width), device=self.data_device)
# 设置相机的近平面和远平面
self.zfar = 100.0
self.znear = 0.01
# 设置平移和缩放参数
self.trans = trans
self.scale = scale
# 计算世界坐标到视图坐标的变换矩阵,并将其移动到 GPU
self.world_view_transform = torch.tensor(getWorld2View2(R, T, trans, scale)).transpose(0, 1).cuda()
# 计算投影矩阵,并将其移动到 GPU
self.projection_matrix = getProjectionMatrix(znear=self.znear, zfar=self.zfar, fovX=self.FoVx, fovY=self.FoVy).transpose(0, 1).cuda()
# 计算完整的投影变换矩阵
self.full_proj_transform = (self.world_view_transform.unsqueeze(0).bmm(self.projection_matrix.unsqueeze(0))).squeeze(0)
# 计算相机中心位置
self.camera_center = self.world_view_transform.inverse()[3, :3]
# 这个不是很重要
class MiniCam:
def __init__(self, width, height, fovy, fovx, znear, zfar, world_view_transform, full_proj_transform):
"""
初始化 MiniCam 类
:param width: 图像宽度
:param height: 图像高度
:param fovy: 垂直方向的视场角
:param fovx: 水平方向的视场角
:param znear: 近平面
:param zfar: 远平面
:param world_view_transform: 世界坐标到视图坐标的变换矩阵
:param full_proj_transform: 完整的投影变换矩阵
"""
self.image_width = width
self.image_height = height
self.FoVy = fovy
self.FoVx = fovx
self.znear = znear
self.zfar = zfar
self.world_view_transform = world_view_transform
self.full_proj_transform = full_proj_transform
# 计算相机中心位置
view_inv = torch.inverse(self.world_view_transform)
self.camera_center = view_inv[3][:3]
其中的转换矩阵
def getWorld2View2(R, t, translate=np.array([.0, .0, .0]), scale=1.0):
"""
计算从世界坐标系到相机视图坐标系的变换矩阵。
:param R: 旋转矩阵 (3x3 numpy array)
:param t: 平移向量 (3-dimensional numpy array)
:param translate: 额外的平移向量,用于对相机中心进行平移 (默认为 [0.0, 0.0, 0.0])
:param scale: 缩放因子,用于对相机中心进行缩放 (默认为 1.0)
:return: 从世界坐标系到相机视图坐标系的变换矩阵 (4x4 numpy array)
"""
# 初始化一个 4x4 矩阵 Rt,全为零
Rt = np.zeros((4, 4))
# 将旋转矩阵的转置赋值给 Rt 的左上 3x3 子矩阵
Rt[:3, :3] = R.transpose()
# 将平移向量赋值给 Rt 的第4列的前3个元素
Rt[:3, 3] = t
# 将 Rt 的右下角元素赋值为 1.0
Rt[3, 3] = 1.0
# 计算相机从相机坐标系到世界坐标系的变换矩阵 C2W
C2W = np.linalg.inv(Rt)
# 提取相机中心坐标
cam_center = C2W[:3, 3]
# 对相机中心进行平移和缩放
cam_center = (cam_center + translate) * scale
# 更新 C2W 的第4列的前3个元素为新的相机中心坐标
C2W[:3, 3] = cam_center
# 计算从世界坐标系到相机坐标系的变换矩阵 Rt
Rt = np.linalg.inv(C2W)
# 返回浮点类型的变换矩阵 Rt
return np.float32(Rt)
其中的投影矩阵
def getProjectionMatrix(znear, zfar, fovX, fovY):
'''
投影矩阵用于将三维坐标变换为二维屏幕坐标。这通常涉及将相机坐标系中的点投影到一个称为规范化设备坐标(NDC)系的空间中,然后再映射到屏幕坐标系。
'''
# 计算垂直视场角的一半的切线值
tanHalfFovY = math.tan((fovY / 2))
# 计算水平视场角的一半的切线值
tanHalfFovX = math.tan((fovX / 2))
# 计算近平面的上边界位置
top = tanHalfFovY * znear
# 计算近平面的下边界位置
bottom = -top
# 计算近平面的右边界位置
right = tanHalfFovX * znear
# 计算近平面的左边界位置
left = -right
# 初始化一个 4x4 的投影矩阵 P,所有元素初始为零
P = torch.zeros(4, 4)
# 控制 z 方向的符号
z_sign = 1.0
# 设置投影矩阵中的元素
P[0, 0] = 2.0 * znear / (right - left) # x 方向上的缩放因子
P[1, 1] = 2.0 * znear / (top - bottom) # y 方向上的缩放因子
P[0, 2] = (right + left) / (right - left) # x 方向上的偏移量
P[1, 2] = (top + bottom) / (top - bottom) # y 方向上的偏移量
P[3, 2] = z_sign # 齐次坐标的 w 分量
P[2, 2] = z_sign * zfar / (zfar - znear) # z 方向上的缩放因子
P[2, 3] = -(zfar * znear) / (zfar - znear) # z 方向上的偏移量
# 返回计算好的投影矩阵
return P