目标描述
给定RGB视频或图片,目标是分割出图像中的指定目标掩码。我们需要复现两个Zero-shot的开源项目,分别为IDEA研究院的GroundingDINO和Facebook的SAM。首先使用目标检测方法GroundingDINO,输入想检测目标的文字提示,可以获得目标的anchor box。将上一步获得的box信息作为SAM的提示,分割出目标mask。具体效果如下(测试数据来自VolumeDeform数据集):

其中GroundingDINO根据white shirt的文字输入计算的box信息为:"shirt_000500": "[194.23726, 2.378189, 524.09503, 441.5135]"。项目实测下来单张图片的预测速度GroundingDINO要慢于SAM。GroundingDINO和SAM均会给出多个预测结果,当选择置信度最高的结果时两个模型也会存在预测不准确的情况。
论文简介
GroundingDINO
GroundingDINO extends a closedset detector DINO by performing vision-language modality fusion at multiple phases, including a feature enhancer, a language-guided query selection module, and a cross-modality decoder. Such a deep fusion strategy effectively improves open-set object detection.

SAM
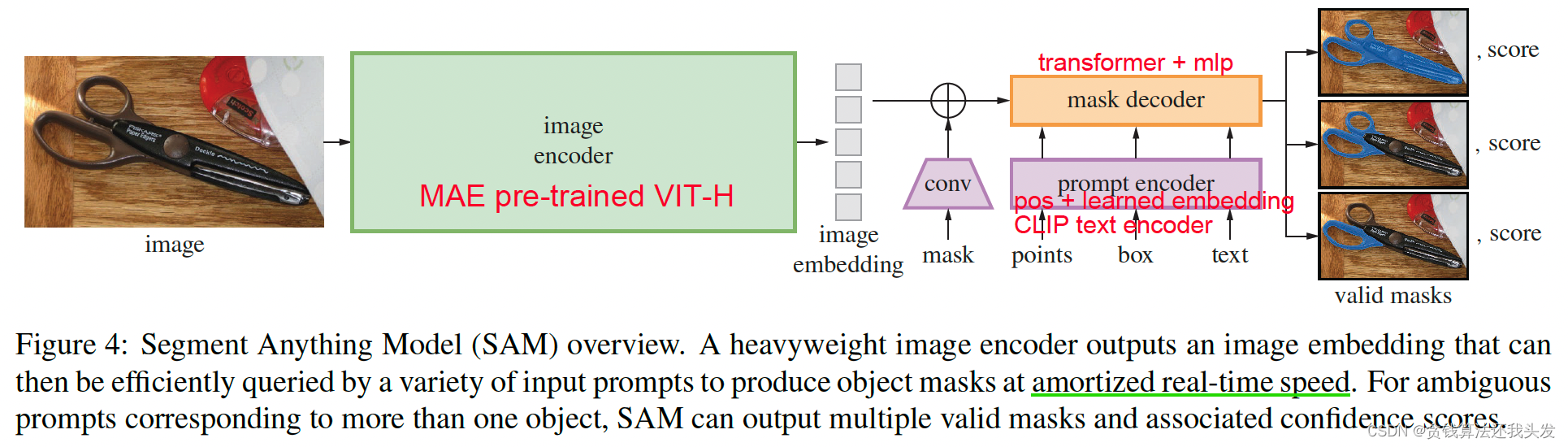
- 简介:使用三个组件建立图像分割的foundation model,解决一系列下游分割问题,可zero-shot生成
- 关键技术:
- promptable分割任务:使用prompt engineering,prompt不确定时输出多目标mask
- 分割模型:image encoder + prompt encoder -> mask decoder
- 数据驱动:SA-1B(1B masks from 11M imgs)手工标注->半自动->全自动
- Limitation:存在不连贯不精细的mask结果;交互式实时mask生成但是img encoder耗时;text-to-mask任务效果不鲁棒

项目实战
两个项目的复现很简单,按照github的readme配置相关环境并运行程序。当然也可以直接使用一站式项目Grounded Segment Anything等。当需要分割的图片较多时,可以修改GroundingDINO的demo.sh和demo/inference_on_a_image.py文件将检测结果保存至json文件。
demo/inference_on_a_image.py文件
# 修改plot_boxes_to_image函数输出box信息
image_with_box, mask, box_coor = plot_boxes_to_image(image_pil, pred_dict)
# obj为目标名称,i为当前图片的索引
obj = 'shirt'
data = {f'{obj}_{str(i).zfill(6)}': str(list(box_coor.cpu().detach().numpy()))}
with open("box.json", "r", encoding="utf-8") as f:
old_data = json.load(f)
old_data.update(data)
with open("box.json", "w", encoding="utf-8") as f:
json.dump(old_data, f, indent=4)
# f.write(json.dumps(old_data, indent=4, ensure_ascii=False))
f.close()
然后SAM再读取json文件获取box信息,将SAM的输入提示改为box。
测试代码
import os
import numpy as np
import matplotlib.pyplot as plt
import cv2
import glob
import json
coords = []
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
def on_click(event):
global coords
if event.button == 1:
x, y = event.xdata, event.ydata
print(f"鼠标左键点击:x={x:.2f}, y={y:.2f}")
coords.append([x, y])
# if len(coords) == 2:
# fig.canvas.mpl_disconnect(cid)
elif event.button == 3:
print("鼠标右键点击")
def get_mask(image, mask_id=1, click_coords=False, choose_mask=False, box=None):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# plt.figure(figsize=(10, 10))
# plt.imshow(image)
# plt.axis('on')
if click_coords:
global coords
fig, ax = plt.subplots() # 创建画布和子图对象
fig.set_size_inches(30, 20) # 设置宽度和高度,单位为英寸(inch)
ax.imshow(image)
cid = fig.canvas.mpl_connect('button_press_event', on_click)
plt.show()
else: # 如果使用 必须全局
coords = []
from segment_anything import SamPredictor, sam_model_registry
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)
input_point = np.array(coords)
input_label = np.array([1] * len(coords))
# plt.figure(figsize=(10, 10))
# plt.imshow(image)
# show_points(input_point, input_label, plt.gca())
# plt.axis('on')
# plt.show()
input_box = box
if len(coords) == 0:
input_point = None
input_label = None
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box[None, :],
multimask_output=True)
if choose_mask:
plt.figure(figsize=(60, 20))
plt.subplot(1, 3, 1)
plt.imshow(image)
show_mask(masks[0], plt.gca())
# show_points(input_point, input_label, plt.gca())
plt.title(f"Mask 0, Score: {scores[0]:.3f}", fontsize=18)
plt.subplot(1, 3, 2)
plt.imshow(image)
show_mask(masks[1], plt.gca())
# show_points(input_point, input_label, plt.gca())
plt.title(f"Mask 1, Score: {scores[1]:.3f}", fontsize=18)
plt.subplot(1, 3, 3)
plt.imshow(image)
show_mask(masks[2], plt.gca())
# show_points(input_point, input_label, plt.gca())
plt.title(f"Mask 2, Score: {scores[1]:.3f}", fontsize=18)
plt.show()
mask_id = int(input()) # 通过输入idx或者设置特定的idx输出
mask = masks[mask_id]
mask = np.tile(np.expand_dims(mask, axis=-1), 3)
mask_data = np.where(mask, 255, 0)
# mask_image = np.where(mask, image/255, 0.)
# plt.figure(figsize=(10, 10))
# plt.imshow(mask_image)
# plt.show()
if click_coords: coords.clear()
return mask_data
if __name__ == '__main__':
obj = 'shirt'
color_path = f'/Data/VolumeDeformData/{obj}/data/'
mask_path = f'/Data/VolumeDeformData/{obj}/mask/'
if not os.path.exists(mask_path):
os.makedirs(mask_path)
img_paths = []
for extension in ["jpg", "png", "jpeg"]:
img_paths += glob.glob(os.path.join(color_path, "*.{}".format(extension)))
json_path = 'GroundingDINO-main/box.json'
with open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
for i in range(len(img_paths) // 2):
img_name = f'frame-{str(i).zfill(6)}.color.png'
img = cv2.imread(color_path + img_name)
id = f'{obj}_{str(i).zfill(6)}'
box = np.array(list(map(float, data[id][1:-1].split(','))))
mask = get_mask(img, mask_id=2, click_coords=False, choose_mask=False, box=box)
cv2.imwrite(mask_path + str(i).zfill(6) + '.png', mask)
print(img_name)
f.close()
相关链接
- GroundingDINO github arXiv
- SAM Demo github arXiv
- Grounded Segment Anything github