⭐️前言:案例学习说明与案例建模流程
我们将围绕Kaggle中的电信用户流失数据集(Telco Customer Churn)进行用户流失预测。在此过程中,将综合应用此前所介绍的各种方法与技巧,并在实践中提炼总结更多实用技巧。

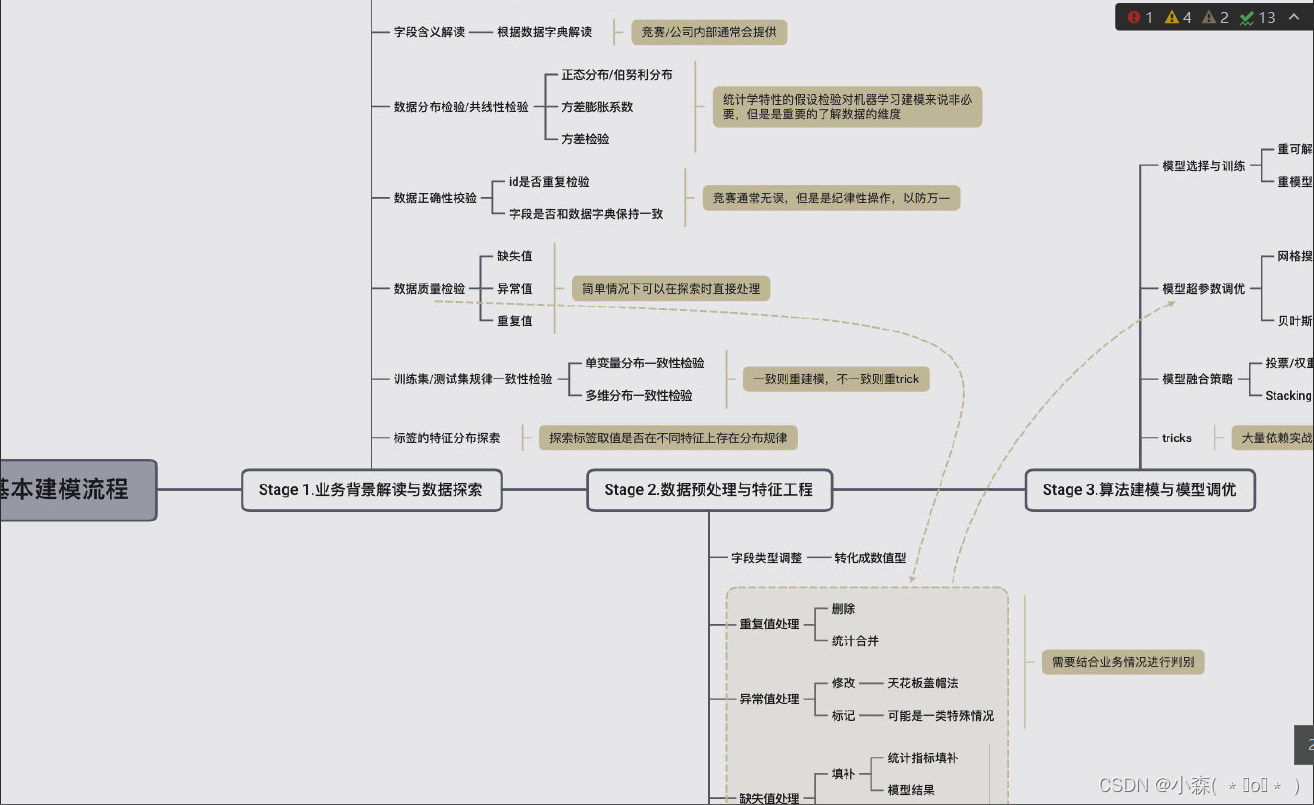
⭐️对于实战案例的讲解,我们将分为三个阶段进行,当然这也是我们在参与算法竞赛、或者在实际算法建模时的一般流程:
- Stage 1.业务背景解读与数据探索
在拿到数据(接受任务)的第一时间,需要对数据(也就是对应业务)的基本背景进行解读。由于任何数据都诞生于某业务场景下,同时也是根据某些规则来进行的采集或者计算得出,因此如果可以,我们应当尽量去了解数据诞生的基本环境和对应的业务逻辑,尽可能准确的解读每个字段的含义,而只有在无法获取真实业务背景时,才会考虑退而求其次通过数据情况去倒推业务情况。
当然,在进行了数据业务背景解读后,接下来就需要对拿到的数据进行基本的数据探索。一般来说,数据探索包括数据分布检验、数据正确性校验、数据质量检验、训练集/测试集规律一致性检验等。当然,这里可能涉及到的操作较多,也并非所有的操作都必须在一次建模过程中全部完成。但作为教学案例,我们将在后续的内容中详细介绍每个环节的相关操作及目的。 - Stage 2.数据预处理与特征工程
在了解了建模业务背景和基本数据情况后,接下来我们就需要进行实际建模前的“数据准备”工作了,也就是数据预处理(数据清洗)与特征工程。其中,数据清洗主要聚焦于数据集数据质量提升,包括缺失值、异常值、重复值处理,以及数据字段类型调整等;而特征工程部分则更倾向于调整特征基本结构,来使数据集本身规律更容易被模型识别,如特征衍生、特殊类型字段处理(包括时序字段、文本字段等)等。
当然,很多时候我们并不刻意区分数据清洗与特征工程之间的区别,很多时候数据清洗的工作也可以看成是特征工程的一部分。同时,也有很多时候我们也不会一定要求在不同阶段执行不同操作,例如如果在数据探索时发现缺失值比例较小,则可以直接对其进行均值/众数填补,而不用等到特征工程阶段统一处理,再例如很多特征工程的方法需要结合实际建模效果来判别,所以有的时候特征衍生也会和建模过程交替进行。 - Stage 3.算法建模与模型调优
在经过一系列准备工作后,就将进入到最终建模环节了,建模过程既包括算法训练也包括参数调优。当然,很多时候建模工作不会一蹴而就,需要反复尝试各种模型、各种调参方法、以及模型融合方法。此外,很多时候我们也需要根据最终模型输出结果来进行数据预处理和特征工程相关方法调整。
上述流程可以用如下流程图进行表示:
💬本节我们将先从数据集业务背景开始介绍,并简单讨论如何借助Kaggle平台获取更多帮助。同时我们也将围绕获取到的数据进行数据探索。
⭐️数据背景介绍与数据探索

💭本次案例的数据源自Kaggle平台上分享的建模数据集:[Telco Customer Churn](https://www.kaggle.com/blastchar/telco-customer-churn),该数据集描述了某电信公司的用户基本情况,包括每位用户已注册的相关服务、用户账户信息、用户人口统计信息等,当然,也包括了最为核心的、也是后续建模需要预测的标签字段——用户流失情况(Churn)。
💭需要注意的是,该数据并非竞赛数据集,而是Kaggle分享的一个高投票数据集(1788 votes),是Kaggle平台上非常经典的围绕偏态数据集建模的数据集。该数据源自IBM商业社区([IBM Business Analytics Community](https://community.ibm.com/community/user/businessanalytics/blogs/steven-macko/2019/07/11/telco-customer-churn-1113))上分享的数据集,用于社区成员内部学习使用。
根据IBM商业社区分享团队描述,该数据集为某电信公司在加利福尼亚为7000余位用户(个人/家庭)提供电话和互联网服务的相关记录。由于该数据集并不是竞赛数据集,因此数据集的下载方式相对容易,官网也只提供了网页下载一种选项(无法通过命令行直接下载)。我们可以在该数据集的Kaggle主页看到数据集的相关信息以及下载地址。此处我们简单介绍关于Kaggle数据集页面的基本功能,既Kaggle平台的基本使用方法,若是Kaggle案例,我们也将频繁借助Kaggle主页来获取帮助。当然,熟练使用Kaggle主页获取数据和挖掘信息(而不是借助第三方渠道),也是算法工程师必备技能之一。
 当然,在数据集主页上,我们可以直接点击下载按钮进行数据集下载。下载完成后将其放到当前操作主目录下进行读取:
当然,在数据集主页上,我们可以直接点击下载按钮进行数据集下载。下载完成后将其放到当前操作主目录下进行读取:
import numpy as np
import pandas as pd
tcc = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
pd.set_option('max_colwidth',200) # 调整每列显示的最大宽度
tcc.head(5)
tcc.info()
在其他一些情况下,我们可能需要借助命令行来进行数据集下载和建模结果提交,相关内容我们将在后续介绍竞赛数据集时详细讨论。
💢- Discussion页面
此外,我们还能够在Discussion页面中看到围绕该建模问题的相关讨论。值得一提的是,在很多场合下(尤其是在参加算法竞赛时),Discussion页面中的讨论帖都是重要的信息获取渠道,其中不乏一些官方给出的补充问答内容、一些竞赛大神给出的自己的赛题理解、以及一些参赛者独到的讨论和见解。而从中快速捕获信息,则能帮助你迅速建立信息优势。
💢- Code页面
此外,我们还能够在code页面看到其他用户分享的代码,其中也不乏一些精彩的思路和方法,也有很多可以借鉴和学习的内容。比如在该数据集的Code页面,就有很多同学会比较关注的处理样本不均衡的SHAP方法,以及该方法配合集成学习的使用方法。
⭐️用户流失业务背景与建模目标

在基本了解Kaggle平台使用方法以及获取到建模数据集之后,接下来我们需要围绕电信用户流失这一基本业务背景来进行介绍,同时解释本案例的最终建模目标。电信作为公共网络、数据传输、电话语音通信等基础服务提供方,一直以来都是国家支柱产业之一。而伴随着移动互联网的普及、数字经济蓬勃发展,网络这一基础设施也愈发重要。有个非常形象的比喻,在过去,断电会导致工厂停产、造成重大的经济损失,而现在,中断网络数字传输,则足以让某些企业一夜损失上亿。
而在此背景下,电信市场的竞争也愈发激烈。一般来说电信领域的运营商在3-4家时能保持一个健康的市场竞争状态,而在国内,5G的运营商牌照也颁发了四家,除了三大运营商外(电信、联通、移动),还有中国广电。而在数字时代,传统的大众营销已经失去优势,如何基于用户信息和行为,来进行更加精准的营销,从而满足用户更加多样化、层次化和个性化的需求,成为所有电信运营商必须面对的课题。而于此同时,电信的公共客户(个人或家庭用户)用户又同时具有易变性、发展性和替代性等特点,且用户需求弹性较小,外加普通用户购买电信产品周期较长,导致在实际的交易关系中,电信公司对公共客户获客较难、主动拓展新用户成本较高,因此维系既有用户、防止用户流失就成了重要的运营策略。
当然,对于电信运营商来说,用户流失有很多偶然因素,不过通过对用户属性和行为的数字化描述,我们或许也能够在这些数据中,挖掘导致用户流失的“蛛丝马迹”,并且更重要的一点,如果能够实时接入这些数据,或许还能够进一步借助模型来对未来用户流失的风险进行预测,从而及时制定挽留策略,来防止用户真实流失情况发生。
- 机器学习建模目标:也就是说,在此背景下,实际的算法建模目标有两个,其一是对流失用户进行预测,其二则是找出影响用户流失的重要因子,来辅助运营人员来进行营销策略调整或制定用户挽留措施。
综合上述两个目标我们不难发现,我们要求模型不仅要拥有一定的预测能力,并且能够输出相应的特征重要性排名,并且最好能够具备一定的可解释性,也就是能够较为明显的阐述特征变化是如何影响标签取值变化的。据此要求,我们首先可以考虑逻辑回归模型。逻辑回归的线性方程能够提供非常好的结果可解释性,同时我们也可以通过逻辑回归中的正则化项也可以用于评估特征重要性。
根据Kaggle的数据集介绍,以及IBM商业分析社区中提供的解释,数据集中各字段解释如下:
| 字段 | 解释 |
|---|---|
| customerID | 用户ID |
| gender | 性别 |
| SeniorCitizen | 是否是老年人(1代表是) |
| Partner | 是否有配偶(Yes or No) |
| Dependents | 是否经济独立(Yes or No) |
| tenure | 用户入网时间 |
| PhoneService | 是否开通电话业务(Yes or No) |
| MultipleLines | 是否开通多条电话业务(Yes 、 No or No phoneservice) |
| InternetService | 是否开通互联网服务(No、DSL数字网络或filber potic光线网络) |
| OnlineSecurity | 是否开通网络安全服务(Yes、No or No internetservice) |
| OnlineBackup | 是否开通在线备份服务(Yes、No or No internetservice) |
| DeviceProtection | 是否开通设备保护服务(Yes、No or No internetservice) |
| TechSupport | 是否开通技术支持业务(Yes、No or No internetservice) |
| StreamingTV | 是否开通网络电视(Yes、No or No internetservice) |
| StreamingMovies | 是否开通网络电影(Yes、No or No internetservice) |
| Contract | 合同签订方式(按月、按年或者两年) |
| PaperlessBilling | 是否开通电子账单(Yes or No) |
| PaymentMethod | 付款方式(bank transfer、credit card、electronic check、mailed check) |
| MonthlyCharges | 月度费用 |
| TotalCharges | 总费用 |
| Churn | 是否流失(Yes or No) |
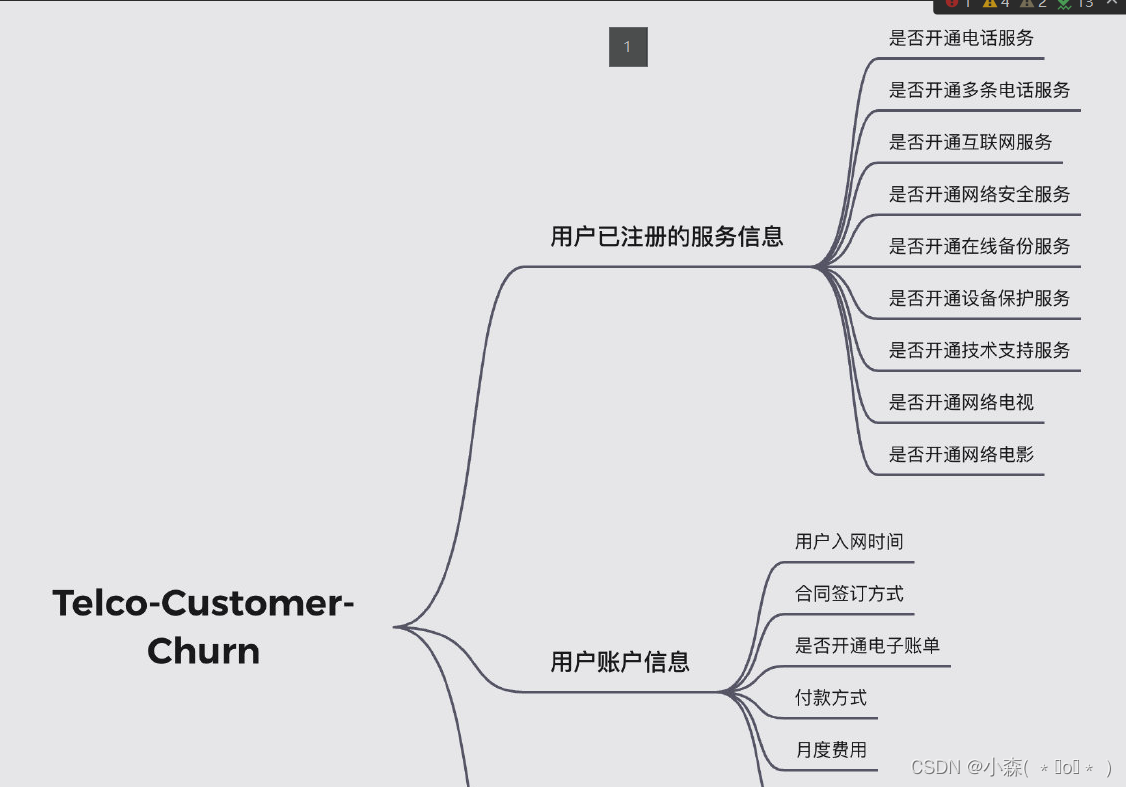
💯同时,根据官方给出的数据集说明,上述字段基本可以分为三类,分别是用户已注册的服务信息、用户账户信息和用户人口统计信息,三类字段划分情况如下:
# tcc["customerID"]
# pd.Series()
# len(tcc["customerID"].unique())
len(tcc["customerID"].unique()) # UUID
# 7043
tcc["customerID"].value_counts().sum()
# 7043
tcc['customerID'].nunique() == tcc.shape[0]
# True接下来进一步检查数据集缺失情况,我们可以通过isnull来快速查看数据集缺失情况:
tcc.isnull().sum()
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
dtype: int64temp_data = pd.DataFrame(data={"A列":[1,np.nan,3,4,np.nan],"B列":["a",np.nan,np.nan,np.nan,"e"]})
temp_data
# temp_data.isnull().sum()
# # temp_data.isnull().sum()
temp_data.isnull().sum()/temp_data.isnull().count()
A列 0.4
B列 0.6
dtype: float64此外,我们也可以通过定义如下函数来输出更加完整的每一列缺失值的数值和占比:
def missing (df):
"""
计算每一列的缺失值及占比
"""
missing_number = df.isnull().sum().sort_values(ascending=False) # 每一列的缺失值求和后降序排序
missing_percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False) # 每一列缺失值占比
missing_values = pd.concat([missing_number, missing_percent], axis=1, keys=['Missing_Number', 'Missing_Percent']) # 合并为一个DataFrame
return missing_values
missing(tcc)⭐️字段类型探索

根据数据集info我们发现,大多数字段都属于离散型字段,并且object类型居多。对于建模分析来说,我们是无法直接使用object类型对象的,因此需要对其进行类型转化,通常来说,我们会将字段划分为连续型字段和离散型字段,并且根据离散字段的具体含义来进一步区分是名义型变量还是有序变量。不过在划分连续/离散字段之前,我们发现数据集中存在一个入网时间字段,看起来像是时序字段。需要注意的是,从严格意义上来说,用时间标注的时序字段即不数据连续型字段或离散型字段(尽管可以将其看成是离散字段,但这样做会损失一些信息),因此我们需要重点关注入网时间字段是否是时间标注的字段:
tcc['tenure']
# 简单查看我们发现,该字段并不是典型的用年月日标注的时间字段,如2020-08-01,而是一串连续的数值。当然,我们可以进一步查看该字段的取值范围:
也就是说,在第三季度中,这些用户的行为发生在某73天内,因此入网时间字段有73个取值。不过由于该字段是经过字典排序后的结果,因此已经损失了原始信息,即每位用户实际的入网时间。而在实际的分析过程中,我们可以转化后的入网时间字段看成是离散变量,当然也可以将其视作连续变量来进行分析,具体选择需要依据模型来决定。此处我们先将其视作离散变量,后续根据情况来进行调整。
# 离散字段
category_cols = ['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure',
'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup',
'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling',
'PaymentMethod']
# 连续字段
numeric_cols = ['MonthlyCharges', 'TotalCharges']
# 标签
target = 'Churn'
# 验证是否划分能完全
assert len(category_cols) + len(numeric_cols) + 1 == tcc.shape[1]
tcc.select_dtypes('object').columns
#
Index(['customerID', 'gender', 'Partner', 'Dependents', 'PhoneService',
'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup',
'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies',
'Contract', 'PaperlessBilling', 'PaymentMethod', 'TotalCharges',
'Churn'],
dtype='object')我们也可以通过如下方式查看每个离散变量的不同取值:
for feature in tcc[category_cols]:
print(f'{feature}: {tcc[feature].unique()}')需要注意的是,如果是连续变量,则无法使用上述方法进行检验(取值水平较多),但由于往往我们需要将其转化为数值型变量再进行分析,因此对于连续变量是否存在其他值表示缺失值的情况,我们也可以观察转化情况来判别,例如如果是用空格代表缺失值,则无法直接使用astype来转化成数值类型。
tcc[numeric_cols].astype(float)
ValueError: could not convert string to float: ''发现在连续特征中存在空格。则此时我们需要进一步检查空格字符出现在哪一列的哪个位置,我们可以通过如下函数来进行检验:
def find_index(data_col, val):
"""
查询某值在某列中第一次出现位置的索引,没有则返回-1
:param data_col: 查询的列
:param val: 具体取值
"""
val_list = [val]
if data_col.isin(val_list).sum() == 0:
index = -1
else:
index = data_col.isin(val_list).idxmax()
return index查看空格第一次出现在哪一列的哪个位置:
for col in numeric_cols:
print(find_index(tcc[col], ' '))
#
-1
488
tcc["TotalCharges"][480:490]
#
480 225.75
481 2145
482 1671.6
483 8003.8
484 680.05
485 6130.85
486 1415
487 6201.95
488
489 74.35
Name: TotalCharges, dtype: objectplt.figure(figsize=(16, 6), dpi=200)
plt.subplot(121)
plt.boxplot(tcc['MonthlyCharges'])
plt.xlabel('MonthlyCharges')
plt.subplot(122)
plt.boxplot(tcc['TotalCharges'])
plt.xlabel('TotalCharges')
能够发现,根据箱线图的判别结果,数据并没有异常值出现。当然,此外我们还能通过连续变量的分布情况来观察是否存在异常值:
plt.figure(figsize=(16, 6), dpi=200)
plt.subplot(121)
sns.histplot(tcc['MonthlyCharges'], kde=True)
plt.subplot(122)
sns.histplot(tcc['TotalCharges'], kde=True) 
当然,通过上述图像我们也能基本看出月消费金额和总消费金额的基本分布情况,对于大多数用户来说月消费金额和总消费金额都较小,而月消费金额所出现的波动,极有可能是某些套餐的组合定价。
需要知道的是,对于异常值的检测和处理也是需要根据实际数据分布和业务情况来判定,一般来说,数据分布越倾向于正态分布,则通过三倍标准差或者箱线图检测的异常值会更加准确一些,此外,在很多时候,异常值或许是某类特殊用户的标识,有的时候我们需要围绕异常值进行单独分析,而不是简单的对其进行修改。
⭐️变量相关性探索分析与探索性分析

在基本完成数据探索与处理之后,接下来我们可以通过探索标签在不同特征上的分布,来初步探索哪些特征对标签取值影响较大。当然,首先我们可以先查看标签字段的取值分布情况:
y = tcc['Churn']
print(f'Percentage of Churn: {round(y.value_counts(normalize=True)[1]*100,2)} % --> ({y.value_counts()[1]} customer)\nPercentage of customer did not churn: {round(y.value_counts(normalize=True)[0]*100,2)} % --> ({y.value_counts()[0]} customer)')
Percentage of Churn: 26.54 % --> (1869 customer)
Percentage of customer did not churn: 73.46 % --> (5174 customer)也就是在总共7000余条数据中,流失用户占比约为26%,整体来看标签取值并不均匀,但如果放到用户流失这一实际业务背景中来探讨,流失用户比例占比26%已经是非常高的情况了。当然我们也可以通过直方图进行直观的观察:
sns.displot(y)
💯变量相关性分析
接下来,我们尝试对变量和标签进行相关性分析。从严格的统计学意义讲,不同类型变量的相关性需要采用不同的分析方法,例如连续变量之间相关性可以使用皮尔逊相关系数进行计算,而连续变量和离散变量之间相关性则可以卡方检验进行分析,而离散变量之间则可以从信息增益角度入手进行分析。但是,如果我们只是想初步探查变量之间是否存在相关关系,则可以忽略变量连续/离散特性,统一使用相关系数进行计算,这也是pandas中的.corr方法所采用的策略。
当然,首先我们可以先计算相关系数矩阵,直接通过具体数值大小来表示相关性强弱。不过需要注意的是,尽管我们可以忽略变量的连续/离散特性,但为了更好的分析分类变量如何影响标签的取值,我们需要将标签转化为整型(也就是视作连续变量),而将所有的分类变量进行哑变量处理:
# 剔除ID列
df3 = tcc.iloc[:,1:].copy()
# 将标签Yes/No转化为1/0
df3['Churn'].replace(to_replace='Yes', value=1, inplace=True)
df3['Churn'].replace(to_replace='No', value=0, inplace=True)
# 将其他所有分类变量转化为哑变量,连续变量保留不变
df_dummies = pd.get_dummies(df3)
df_dummies.head()此处需要注意pd.get_dummies会将非数值类型对象类型进行自动哑变量转化,而对数值类型对象,无论是整型还是浮点型,都会保留原始列不变:
df_dummies[['Churn', 'tenure', 'MonthlyCharges', 'TotalCharges']] 
然后即可采用.corr方法计算相关系数矩阵:
df_dummies.corr()
当然,在所有的相关性中,我们较为关注特征和标签之间的相关关系,因此可以直接挑选标签列的相关系数计算结果,并进行降序排序:
df_dummies.corr()['Churn'].sort_values(ascending = False)💥需要知道的是,根据相关系数计算的基本原理,相关系数为正数,则二者为正相关,数值变化会更倾向于保持同步。例如Churn与Contract_Month-to-month相关系数为0.4,则说明二者存在一定的正相关性,即Contract_Month-to-month取值为1(更大)越有可能使得Churn取值为1。也就是在Contract字段的Month-to-month取值结果和最终流失的结果相关性较大,也就是相比其他条件,Contract取值为Month-to-month的用户流失概率较大,而tenure和Churn负相关,则说明tenure取值越大、用户流失概率越小。其他结果解读依此类推。
当然,我们也可以通过一些可视化的方式来展示特征和标签之间的相关性,例如可以考虑使用热力图进行相关性的可视化展示:
plt.figure(figsize=(15,8), dpi=200)
sns.heatmap (df_dummies.corr()) 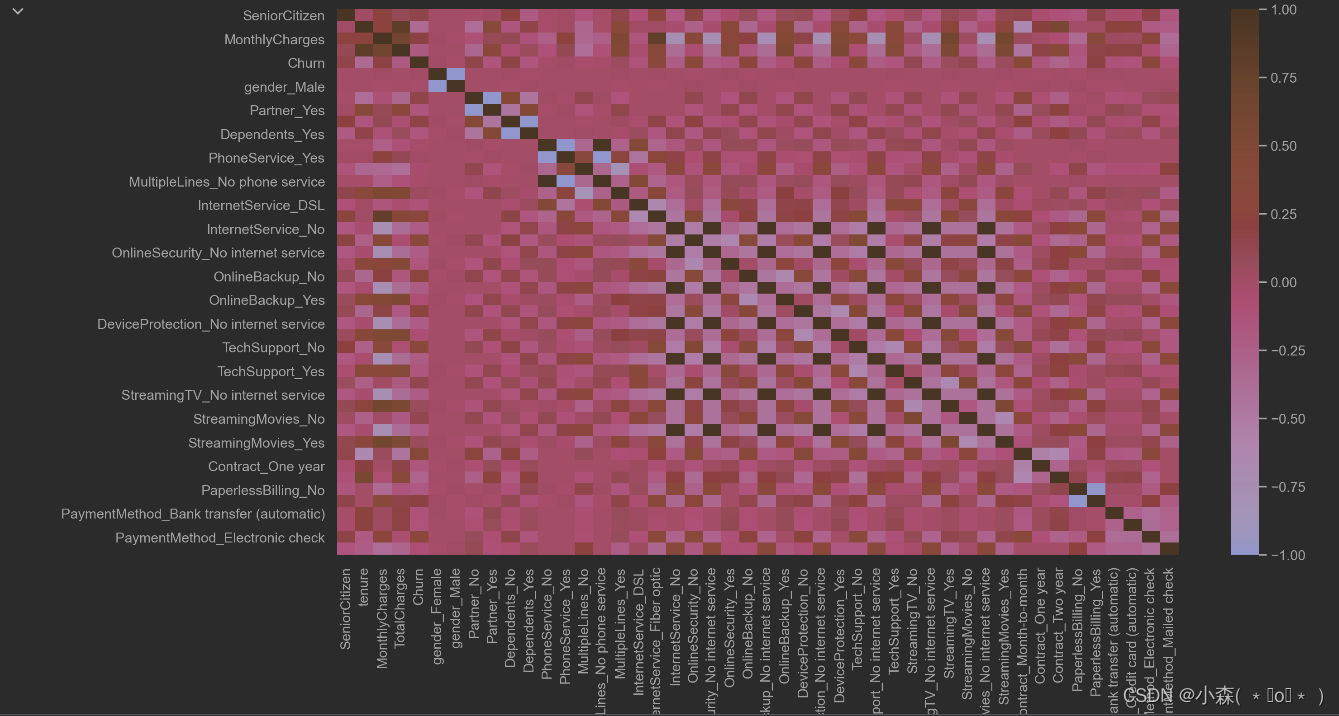
很多时候如果特征较多,热力图的展示结果并不直观,此时我们可以考虑进一步使用柱状图来进行表示:
sns.set()
plt.figure(figsize=(15,8), dpi=200)
df_dummies.corr()['Churn'].sort_values(ascending = False).plot(kind='bar') 
直接计算整体相关系数矩阵以及对整体相关性进行可视化展示是一种非常高效便捷的方式,在实际的算法竞赛中,我们也往往会采用上述方法快速的完成数据相关性检验和探索工作。不过,如果是对于业务分析人员,可能我们需要为其展示更为直观和具体的一些结果,才能有效帮助业务人员对相关性进行判别。此时我们可以考虑围绕不同类型的属性进行柱状图的展示与分析。当然,此处需要对比不同字段不同取值下流失用户的占比情况,因此可以考虑使用柱状图的另一种变形:堆叠柱状图来进行可视化展示:
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(12,6), dpi=100)
# 柱状图
plt.subplot(121)
sns.countplot(x="gender",hue="Churn",data=tcc,palette="Blues", dodge=True)
plt.xlabel("Gender")
plt.title("Churn by Gender")
# 柱状堆叠图
plt.subplot(122)
sns.countplot(x="gender",hue="Churn",data=tcc,palette="Blues", dodge=False)
plt.xlabel("Gender")
plt.title("Churn by Gender")