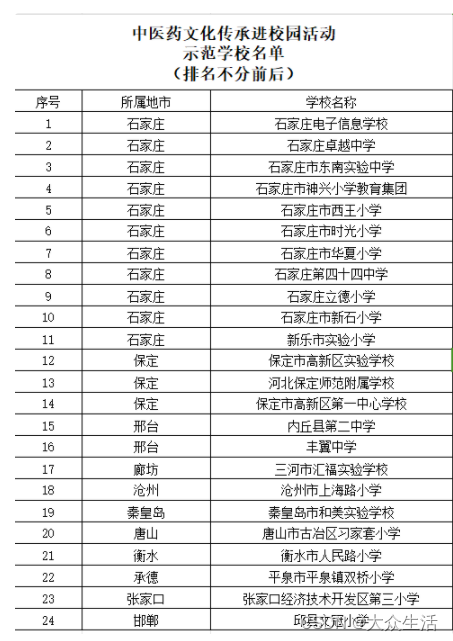
前言
最近在学习Python爬虫的知识,既然眼睛会了难免忍不住要实践一把。
不废话直接上主题
代码不复杂,简单的例子奉上:
import requests
from lxml import etree
cookie = '浏览器F12网络请求标头里有'
user_agent = '浏览器F12网络请求标头里有'
# 具体的方法网上有很多这里不是叙述的重点
headers= {
'User-Agent': user_agent,
'Cookie': cookie,
'Host': 'fanqienovel.com',
'Connection': 'keep-alive'
}
url = "https://****"
# 使用get方法请求网页
resp = requests.get(url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
content = resp.content.decode('utf-8')
# 将文本内容创建为可解析元素
html = etree.HTML(content)
# 获取1
title1 = html.xpath('//*[@id="app"]/div/div[2]/div/div[1]/div/div[2]/div[2]/div[1]/h1/text()')[0]
# 获取2
title2 = html.xpath('//*[@id="app"]/div/div/div/div[1]/div/div[2]/div[2]/div[1]/h1/text()')[0]
“获取1”是页面打开后直接复制的XPath路径,但根据这个路径获取不到数据,见截图。
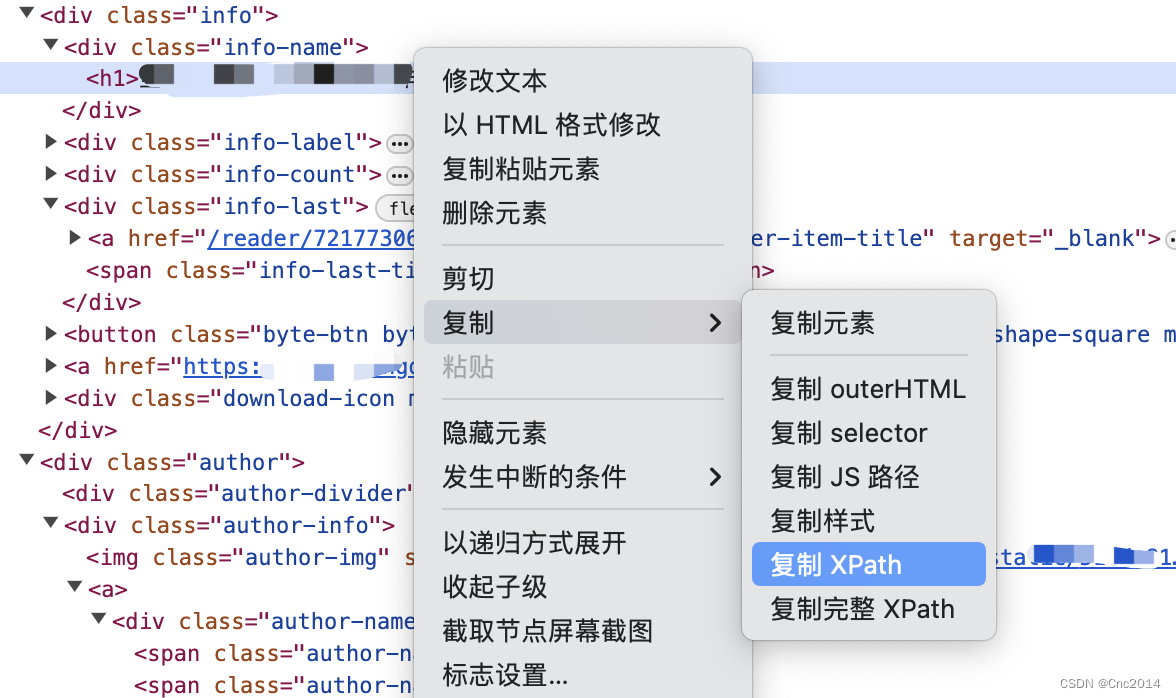
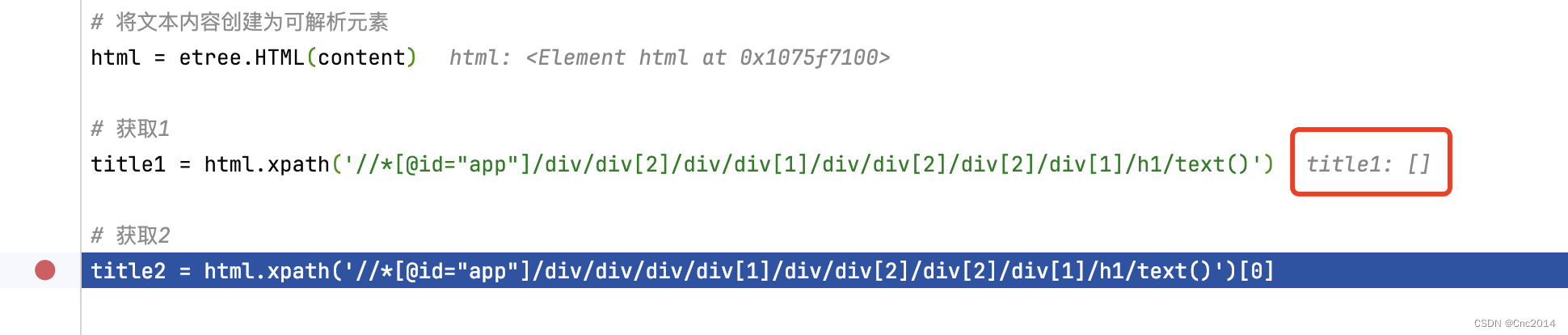
但content是有内容的,参阅网上的方案都未决解,但提供了思路。
是网站做了反爬虫处理,复制的XPath不准确导致的,想了个办法将content的内容复制到txt文档,然后修改为html的后缀用浏览器打开,在新的网页下重新复制XPath就得到了“获取2”的路径,可以发现1和2路径是有差异的。
问题到这就解决了。