目录
前言
二、前期准备
2.1 设置GPU
2.2 导入数据
2.2.1 数据介绍
2.2.2 导入代码
2.2.3 检查数据
三、数据预处理
3.1 划分训练集与测试集
3.2 标准化
四、构建RNN模型
4.1 基本概念
4.2 搭建代码
五、编译模型
六、训练模型
七、模型评估
总结
前言
🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)
说在前面
本周目标:本地读取并加载数据、了解循环神经网络(RNN)的构建过程、调整代码是的测试机acuuracy达到87%;拔高目标——测试集accuracy达到89%
我的环境:Python3.8、Pycharm2020、tensorflow2.4.0
数据来源:[K同学啊](https://mtyjkh.blog.csdn.net/)
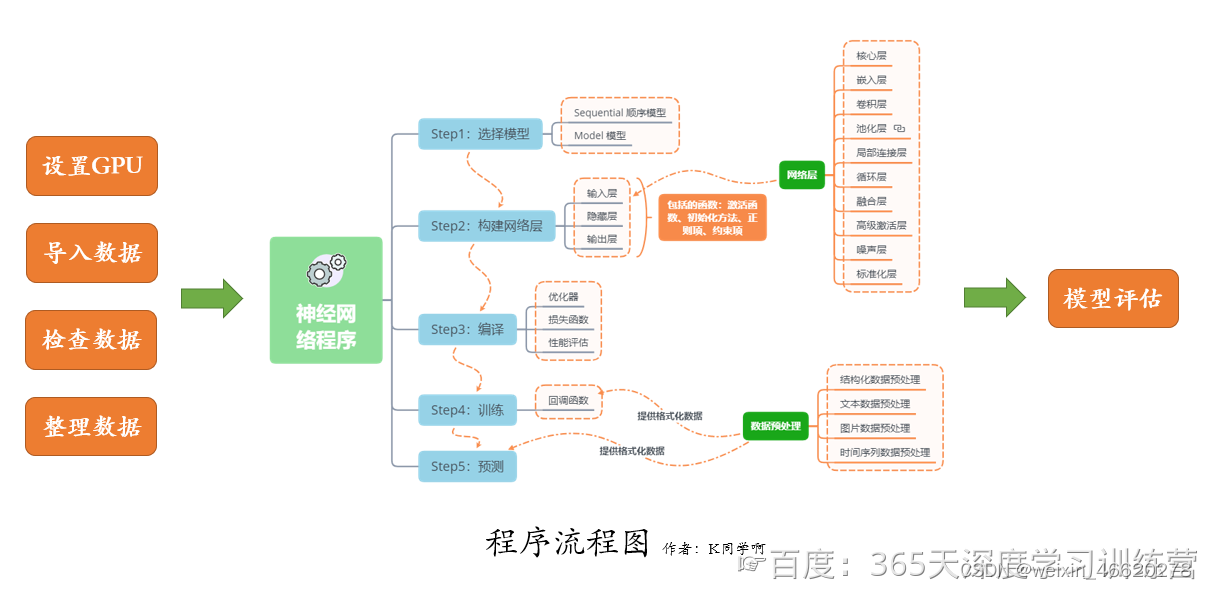
代码的流程图如下:
一、RNN简介
传统神经网络结构比较简单是输入层——隐藏层——输出层,而RNN与传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。如下图所示,左图为传统神经网络,右图为RNN
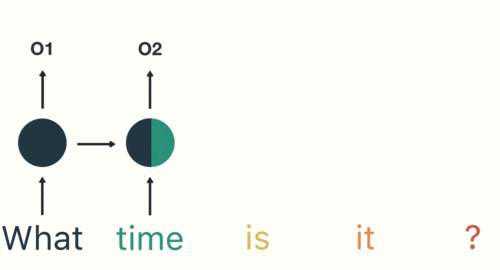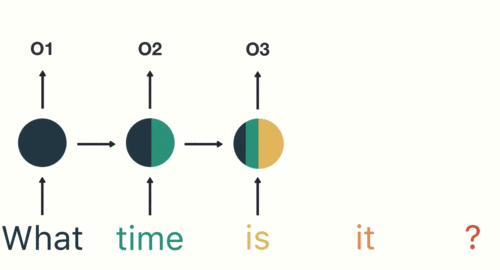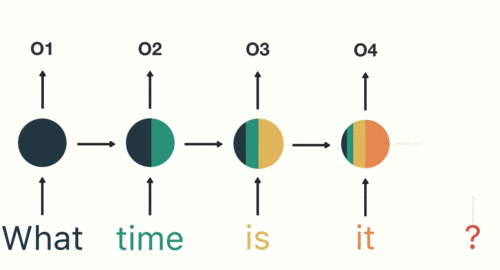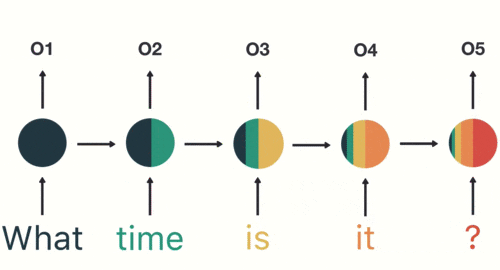
以一个案例具体分析RNN工作过程,用户说了一句“what time is it?”,我们的神经网络首先会将这句话分为五个基本单元(四个单词➕一个问号);然后按照顺序将5个基本单元输入RNN网络,what作为RNN的输入得到输出01,按照顺序将“time”输入RNN网络,得到输出02,这个过程中可以看到输入“time”的时候,前面“what”的输出也会对02的输出产生了影响(如下图中所示,隐藏层中有一半是黑色的),依次类推,前面所有的输入产生的结果都对后续的输出产生了印象(下图中最后的圆形中就包含了前面所有的颜色)
当神经网络判断意图的时候,只需要最后一层的输出05,如下图所示
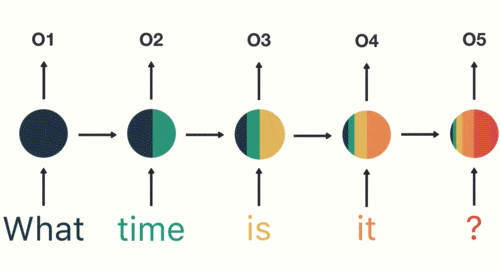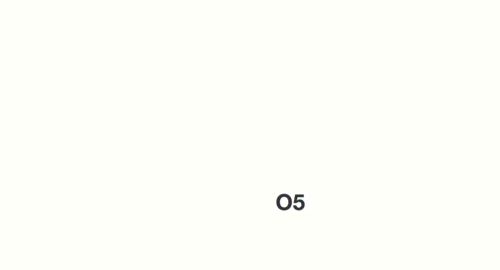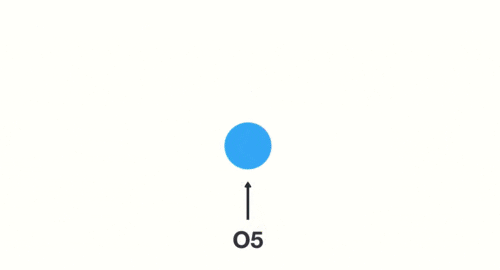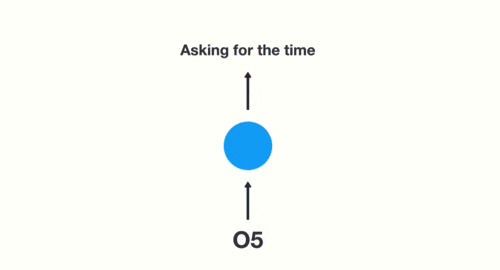
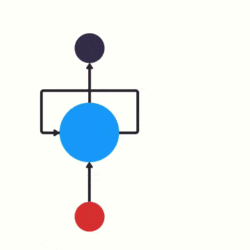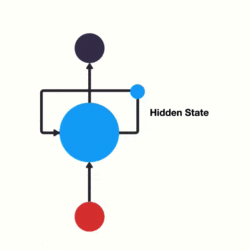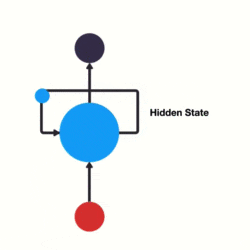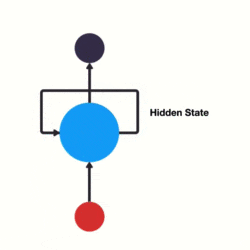
循环神经网络(RNN)是一类用于处理序列数据的神经网络。不同于传统的前馈神经网络,RNN 能够处理序列长度变化的数据,如文本、语音等。RNN 的特点是在模型中引入循环,使得网络能够保持某种状态,从而在处理序列数据时表现出更好的性能。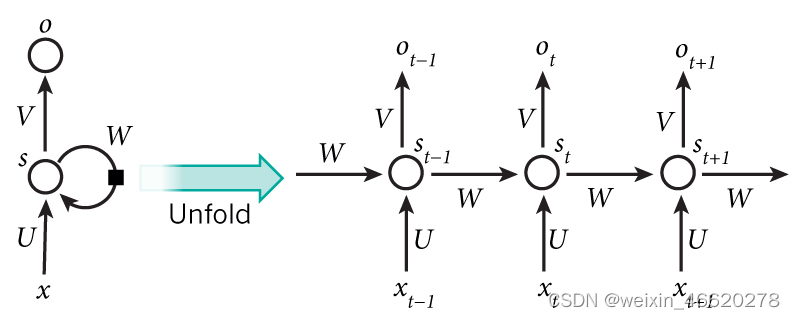
上图左边简单描述 RNN 的原理,x 是输入层,o 是输出层,中间 s 是隐藏层,在 s 层进行一个循环,右边表示展开循环看到的逻辑,其实是和时间 t 相关的一个状态变化,也就是说神经网络在处理数据的时候,能看到前一时刻、后一时刻的状态,也就是常说的上下文
二、前期准备
2.1 设置GPU
代码如下:
#一、前期准备
#1.1 导入所需包和设置GPU
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 不显示等级2以下的提示信息
import tensorflow as tf
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,LSTM,SimpleRNN
import matplotlib.pyplot as plt
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
print(gpus)2.2 导入数据
2.2.1 数据介绍
- age:1)年龄
- sex:2)性别
- cp:3)胸痛类型(4 values)
- trestbps:4)静息血压
- chol:5)血清胆甾淳(mg/dl)
- fbs:6)空腹血糖>120mg/dl
- restecg:7)静息心电图结果(值0,1,2)
- thalach:8)达到的最大心率
- exang:9)运动诱发的心绞痛
- olddpeak:10)相对静止状态,运动引起的ST段压低
- slope:11)运动峰值ST段的斜率
- ca:12)荧光透视着色的主要血管数量(0-3)
- thal:13)0=正常,1=固定缺陷;2=可逆转的缺陷
- target:14)0=心脏病发作的几率较小,1=心脏病发作的几率更大
2.2.2 导入代码
#1.2 导入数据
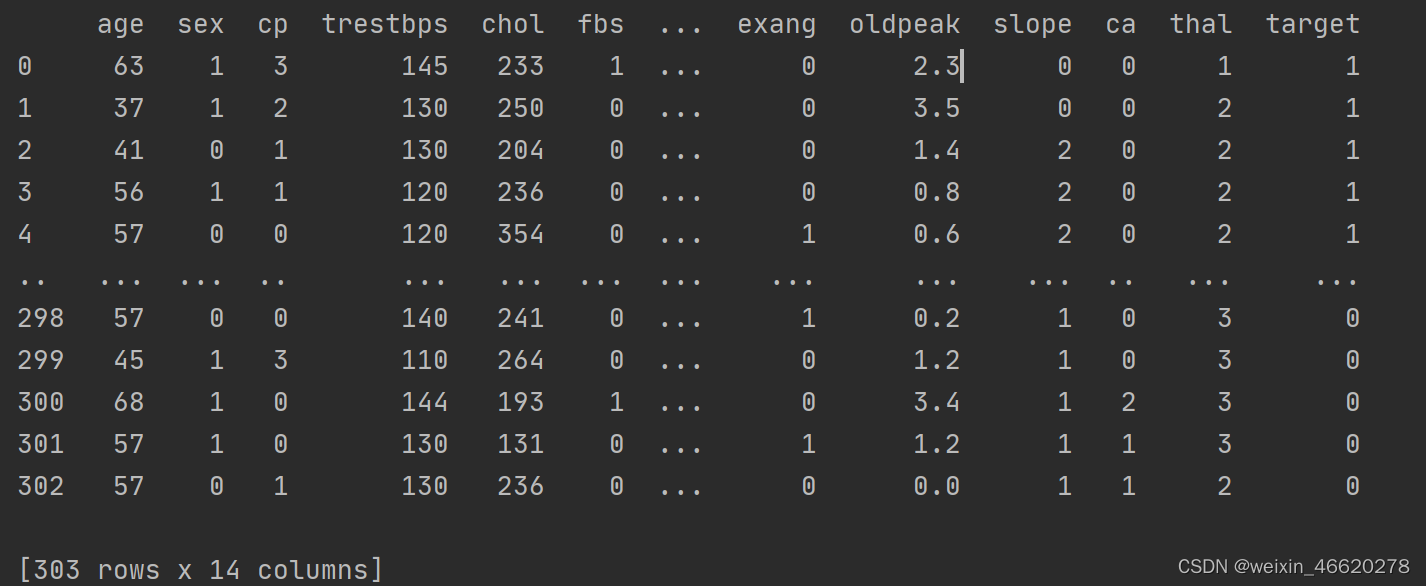
df = pd.read_csv('heart.csv')
print(df)2.2.3 检查数据
检查是否存在空值
df.isnull().sum() #检查是否有空值数据打印显示如下
三、数据预处理
3.1 划分训练集与测试集
补充:测试集与验证集的关系——①验证集并没有参与训练中梯度下降的过程,狭义上来讲是没有参与模型的参数训练更新的;②但广义上来说,验证集存在的意义确实参与了一个“人工调参”的过程,我们根据每一个epoch训练之后的模型在vaild data上的表现来决定是否需要训练进行early stop,或者根据这个过程模型的性能变化来调整模型的超参数,如学习率,batch_size等等;③所以也可以认为,验证集也参与了训练,但是并没有使得模型去overfit验证集
代码如下:
#二、数据预处理
#2.1 数据集划分
x = df.iloc[:,:-1]
y = df.iloc[:,-1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=1)
print(x_train.shape, y_train.shape)打印输出:(272, 13) (272,)
3.2 标准化
代码如下:
# 将每一列特征标准化为标准正态分布,注意,标准化是针对每一列而言的
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
x_train = x_train.reshape(x_train.shape[0], x_train.shape[1], 1)
x_test = x_test.reshape(x_test.shape[0], x_test.shape[1], 1)
四、构建RNN模型
4.1 基本概念
函数原型:tf.keras.layers.SimpleRNN(units,activation='tanh',use_bias=True,kernel_initializer='glorot_uniform',recurrent_initializer='orthogonal',bias_initializer='zeros',kernel_regularizer=Noe,recurrent_regularizer=Noe,bias_regularizer=None,activity_regularizer=None,keenel_constraint=None,recurrent_constraint=None,bias_constraint=None,dropout=0.0,recurrent_dropout=0.0,return_sequences=False,return_state=False,go_backwards=False,stateful=False,unroll=False,**kwargs)
关键参数说明:
- units——正整数,输出空间的维度
- activation——要使用的激活函数,默认为双曲正切(tanh),如果传入None,则不使用激活函数(即线性激活a(x)=x)
- use_bias——布尔值,该层是否使用偏置向量
- kernel_initializer——kernel权值矩阵的初始化器,用于输入的线性转换
- recurrent_initializer——recurrent_kernel权值矩阵的初始化器,用于循环层状态的线性转换
- bias_initializer——偏置向量的初始化器
- dropout:在-0和1之间的浮点数,单元的丢弃比例,用于输入的线性转换
4.2 搭建代码
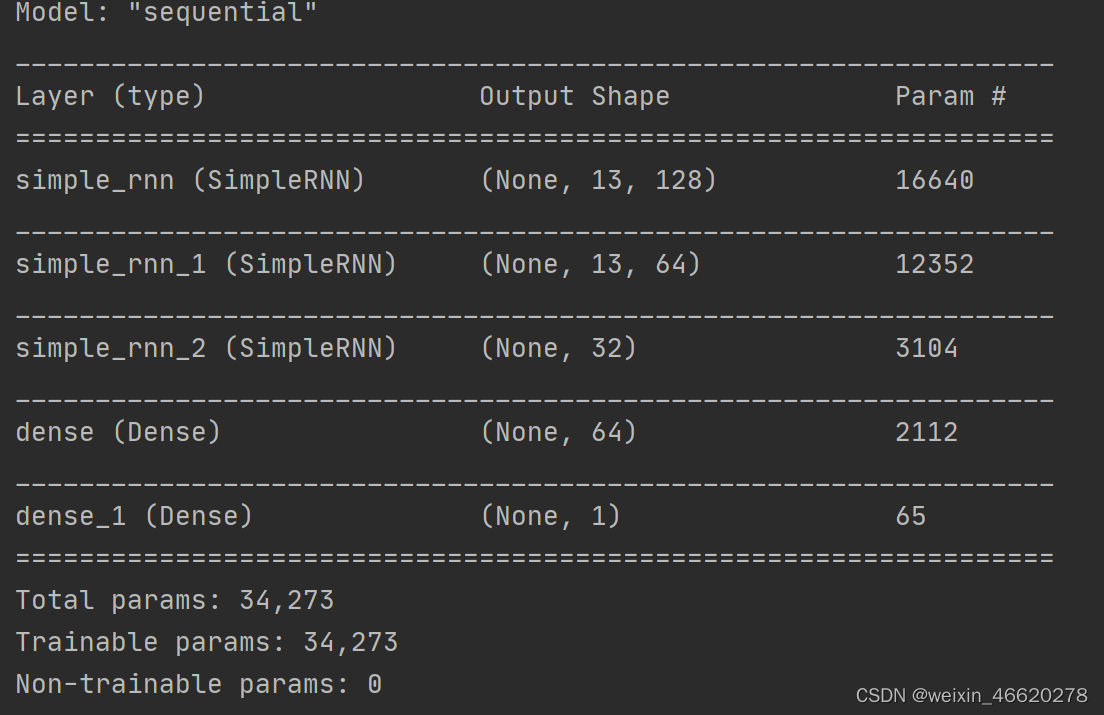
#三、构建RNN模型
model = Sequential()
model.add(SimpleRNN(128, input_shape= (13,1),return_sequences=True,activation='relu'))
model.add(SimpleRNN(64,return_sequences=True, activation='relu'))
model.add(SimpleRNN(32, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()模型输出如下:
五、编译模型
代码如下:
#四、编译模型
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss='binary_crossentropy', optimizer=opt,metrics=['accuracy'])
六、训练模型
代码如下:
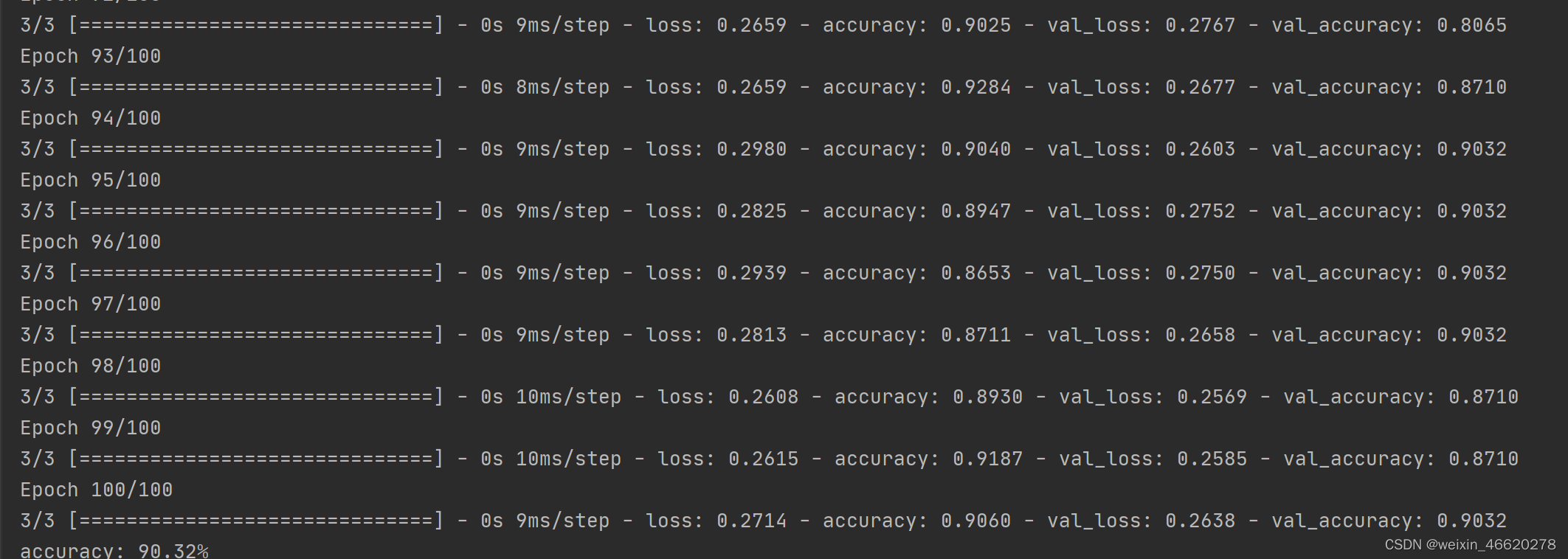
#五、训练模型
epochs = 100
history = model.fit(x_train, y_train,
epochs=epochs,
batch_size=128,
validation_data=(x_test, y_test),
verbose=1)训练过程:
七、模型评估
代码如下
#六、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
scores = model.evaluate(x_test,y_test,verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))打印结果:
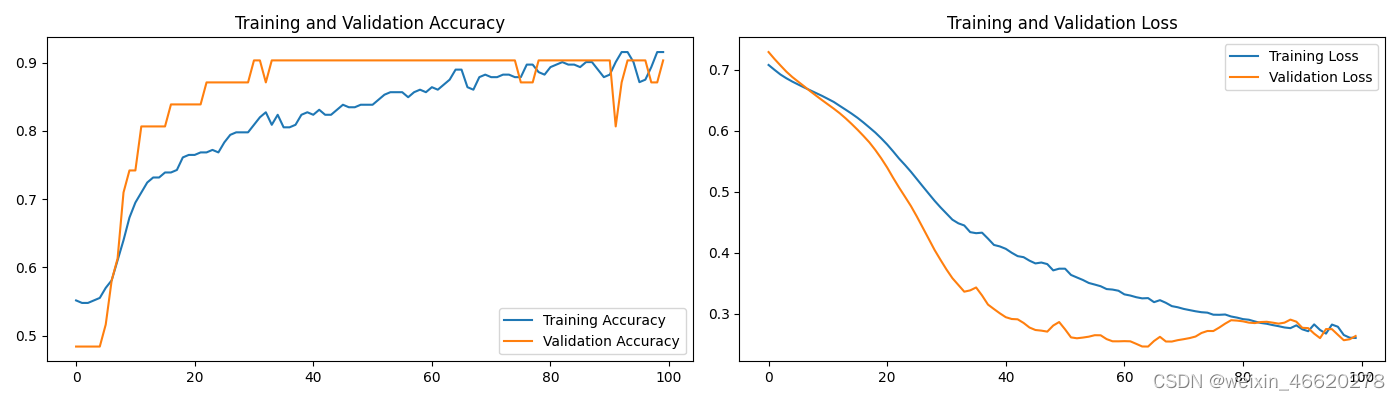
accuracy: 90.32%
总结
RNN实战应用,是一种用于处理序列数据的神经网络,了解了基于Tensorflow搭建RNN的过程;学习了对于文本类数据,是怎么将其数字化。