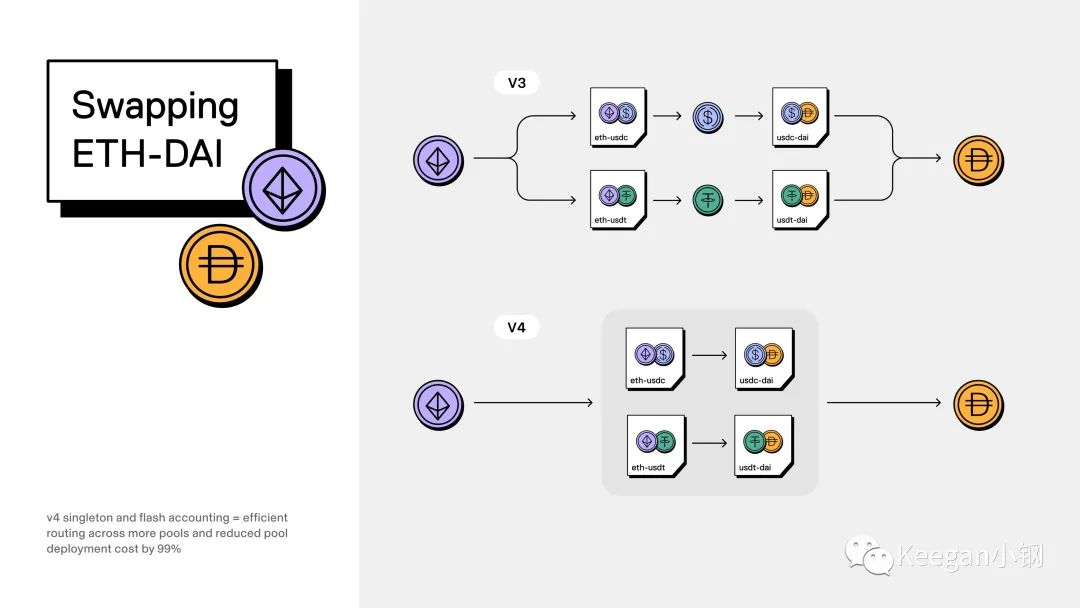
对于艾宾浩斯遗忘曲线和函数,我一直都有小小的迷思,总想实验下用艾宾浩斯函数来替换sigmoid函数作为激活函数,打造更接近人类的AI算法,这篇文章旨在讨论下

目录
3.10. 艾宾浩斯曲线
3.10.1. 定义
3.10.1.1. 曲线计算公式
3.10.1.2. 曲线计算的python实现
3.10.2. 历史发展
3.10.3. 应用场景
3.10.4. 优缺点
3.10.4.1. 基本优缺点优点:
3.10.4.2. 梯度消失
3.10.5. 与sigmoid函数对比
3.10.6. 代码实现
3.10.7. 与sigmoid函数的导函数异同
3.10.8. 艾宾浩斯遗忘曲线如何反映记忆保持率
3.10.9. 艾宾浩斯曲线作为激活函数
3.10.9.1. 可行性
3.10.9.2. 弱点
3.10.9.3. 与Sigmoid函数的对比
3.10.9.4. 小结论
3.10. 艾宾浩斯曲线
3.10.1. 定义
艾宾浩斯遗忘曲线(Ebbinghaus Forgetting Curve)是描述人类记忆遗忘规律的一种曲线,由德国心理学家赫尔曼·艾宾浩斯(Hermann Ebbinghaus)通过大量实验得出。
艾宾浩斯遗忘曲线描述了人们在学习后随时间推移对信息的记忆保持程度。
它表明,人们在初次学习后,记忆会迅速遗忘,但随着时间的推移,遗忘速度会逐渐减慢。
3.10.1.1. 曲线计算公式
艾宾浩斯遗忘曲线通常可以通过指数衰减函数来近似表示。虽然艾宾浩斯本人没有提供一个具体的数学公式,但我们可以使用类似下面的公式来描述这一曲线:
其中:是记忆保持率(即还记得的信息比例)。
是经过的时间。
是稳定性或遗忘速度的一个参数,它决定了记忆随时间衰减的速度。
注意:这个公式是一个简化的模型,并不完全准确地反映艾宾浩斯的实际发现,但它提供了一个有用的近似。
3.10.1.2. 曲线计算的python实现
艾宾浩斯遗忘曲线描述的是人类大脑对新获取知识的遗忘规律,通常用一个指数衰减函数来近似模拟。下面是一个简单的Python代码示例,用来模拟艾宾浩斯遗忘曲线
import numpy as np
import matplotlib.pyplot as plt
# 假设时间间隔(单位:天)
time_intervals = np.arange(0, 31, 1) # 从第0天开始到第30天,每天记录一次
# 艾宾浩斯遗忘曲线通常用一个指数衰减函数来近似,这里我们假设一个简化的指数衰减模型
# 遗忘率(保留率)可以根据实际情况调整
retention_rate = 0.95 # 每天保留95%的记忆
# 计算每个时间点的记忆保留量
retention = retention_rate ** time_intervals
# 绘制艾宾浩斯遗忘曲线
plt.plot(time_intervals, retention, label='Retention')
plt.xlabel('Time (days)')
plt.ylabel('Retention Rate')
plt.title('Ebbinghaus Forgetting Curve Simulation')
plt.legend()
plt.grid(True)
plt.show()上述代码首先定义了一个时间间隔数组,然后设定了一个每天的记忆保留率(这里是95%)。接着,使用NumPy库计算了每个时间点的记忆保留量,并用Matplotlib库绘制了艾宾浩斯遗忘曲线。请注意,这个模拟是非常简化的,实际的艾宾浩斯遗忘曲线可能会因为个体差异、记忆材料类型、复习方式等多种因素而有所不同。
3.10.2. 历史发展
艾宾浩斯在1885年发表了他的研究成果,他使用自己作为实验对象,通过记忆无意义的音节来测试记忆随时间的变化。

他的实验揭示了记忆遗忘的规律,为后来的记忆研究奠定了基础。
3.10.3. 应用场景
- 学习策略:学生可以利用艾宾浩斯遗忘曲线来制定更有效的复习计划,以便在关键时间点上回顾和巩固知识。
- 市场营销:在广告和品牌宣传中,了解消费者的记忆遗忘规律有助于制定更有效的广告投放策略。
- 产品设计:在用户界面设计中,考虑用户的记忆遗忘曲线可以帮助设计师创建更直观、更易于记忆的用户界面。
3.10.4. 优缺点
3.10.4.1. 基本优缺点
优点:
- 提供了对人类记忆遗忘规律的深刻见解。
- 有助于制定更有效的学习和复习策略。
缺点:
- 艾宾浩斯的研究是基于无意义音节的记忆,可能与实际生活中的有意义信息记忆有所不同。
- 个体差异可能导致遗忘曲线有所不同,因此该曲线可能并不适用于所有人。
- 梯度消失问题相对出现较快
3.10.4.2. 梯度消失
艾宾浩斯曲线本身并不直接涉及梯度消失问题,因为它不是一个用于神经网络训练的激活函数。然而,当我们在讨论神经网络中的梯度消失问题时,这通常与激活函数的选择和网络的结构设计有关。
梯度消失问题主要发生在深度神经网络中,特别是在使用某些激活函数(如sigmoid或tanh)时。这些函数在输入值的极端情况下(接近正无穷或负无穷)的梯度接近于零,导致在反向传播过程中,梯度在逐层传递时迅速减小,甚至接近于零,从而使得网络无法有效学习。
为了解决梯度消失问题,可以采取以下几种方法:
- 选择合适的激活函数:使用ReLU(Rectified Linear Unit)及其变种(如Leaky ReLU、PReLU等)作为激活函数,这些函数在输入值大于零时有非零梯度,从而有助于缓解梯度消失问题。
- 使用批归一化(Batch Normalization):批归一化可以帮助网络更好地学习,通过规范每一层神经元的激活值,使得它们的分布更加稳定,从而有助于防止梯度消失。
- 优化网络结构:采用残差网络(ResNet)等结构,通过添加跨层连接(shortcuts),使得梯度能够直接回传到较浅的层,从而缓解梯度消失问题。
- 使用梯度裁剪:当梯度过大时,将其限制在一个合理的范围内,以防止梯度爆炸和由此引起的梯度消失问题。
- 权重正则化:使用L1或L2正则化来限制网络权重的增长,从而有助于防止过拟合和梯度消失问题。
3.10.5. 与sigmoid函数对比
Sigmoid函数通常用于机器学习中的逻辑回归和神经网络,其公式为:
与艾宾浩斯遗忘曲线相比,sigmoid函数在形状上有些相似,但两者的应用场景和含义完全不同。
Sigmoid函数用于将任意实数映射到0到1之间,常用于表示概率或激活函数的输出。
而艾宾浩斯遗忘曲线则描述了记忆随时间的衰减。
3.10.6. 代码实现
使用Python和C++实现艾宾浩斯遗忘曲线代码
Python实现
import numpy as np
import matplotlib.pyplot as plt
# 定义艾宾浩斯遗忘曲线函数
def ebbinghaus_forgetting_curve(t, S=10):
return np.exp(-t / S)
# 生成时间点
times = np.linspace(0, 100, 100)
# 计算每个时间点的记忆保持率
retention_rates = ebbinghaus_forgetting_curve(times, S=10)
# 绘制艾宾浩斯遗忘曲线
plt.plot(times, retention_rates)
plt.xlabel('Time')
plt.ylabel('Retention Rate')
plt.title('Ebbinghaus Forgetting Curve')
plt.show()C++实现(使用简单的控制台输出和绘图库,如GNUplot):
#include <iostream>
#include <cmath>
#include <vector>
// 如果你使用GNUplot或其他绘图库,请包含相应的头文件
// 定义艾宾浩斯遗忘曲线函数
double ebbinghaus_forgetting_curve(double t, double S = 10.0) {
return exp(-t / S);
}
int main() {
std::vector<double> times;
std::vector<double> retention_rates;
// 生成时间点并计算记忆保持率
for (double t = 0; t <= 100; t++) {
times.push_back(t);
retention_rates.push_back(ebbinghaus_forgetting_curve(t));
}
// 输出结果到控制台(或绘制图形,取决于你使用的库)
for (size_t i = 0; i < times.size(); ++i) {
std::cout << "Time: " << times[i] << ", Retention Rate: " << retention_rates[i] << std::endl;
}
// 如果你使用绘图库,请在这里调用相应的绘图函数来绘制曲线
// ... (绘图代码)
return 0;
}
注意:C++代码中的绘图部分取决于你使用的具体绘图库。上面的代码仅提供了计算和输出数据的基础框架。如果你希望绘制图形,你可能需要使用如GNUplot、Qt的图形界面或其他第三方图形库。
3.10.7. 与sigmoid函数的导函数异同
艾宾浩斯遗忘曲线与sigmoid函数的导数函数,在定义半衰期为1时的共同点和区别:
艾宾浩斯遗忘曲线与sigmoid函数的导数函数在定义和应用场景上存在显著差异,但当我们将两者的某些特性进行对比时,可以找出一些共同点和区别。
以下是在定义半衰期为1时,两者的共同点和区别的分析:
共同点:
- 数学特性:两者都是基于数学函数的表达。艾宾浩斯遗忘曲线可以通过指数衰减函数来近似表示,而sigmoid函数的导数则是一个具体的数学函数。
- 值域范围:在特定的条件下(如半衰期为1时),两者的函数值都可能在0到1之间变化。艾宾浩斯遗忘曲线表示记忆保持率,其值在0到1之间;sigmoid函数的导数在特定输入范围内也表现出类似的特性。
- 描述变化过程:两者都用于描述某种变化过程。艾宾浩斯遗忘曲线描述记忆随时间的衰减过程,而sigmoid函数的导数则描述sigmoid函数斜率的变化,即函数增减的速率。
区别:
- 应用场景:艾宾浩斯遗忘曲线主要应用于学习和记忆领域,用于描述人类记忆随时间的遗忘规律;而sigmoid函数的导数则主要应用于机器学习、神经网络等领域,用于描述函数的变化率。
- 函数形状:艾宾浩斯遗忘曲线通常呈现为指数衰减的形状,表示记忆随时间的快速遗忘后逐渐趋于稳定;而sigmoid函数的导数则呈现先增后减的趋势,反映了sigmoid函数在特定点上的斜率变化。
- 参数依赖:艾宾浩斯遗忘曲线的形状受时间参数的影响,表示不同时间点上的记忆保持率;而sigmoid函数的导数则受原函数输入值的影响,描述了在不同输入值下函数的变化速率。
- 物理意义:艾宾浩斯遗忘曲线具有明确的物理意义,即描述人类记忆的遗忘规律;而sigmoid函数的导数则更多地是数学意义上的变化率描述,虽然在神经网络中有其特定的应用意义,但相比之下其物理意义更为抽象。
艾宾浩斯遗忘曲线与sigmoid函数的导数函数在定义、应用场景、函数形状、参数依赖以及物理意义等方面存在显著差异。
尽管在某些数学特性上它们可能表现出相似性(如在特定条件下的值域范围),但两者的本质和应用领域是不同的。
3.10.8. 艾宾浩斯遗忘曲线如何反映记忆保持率
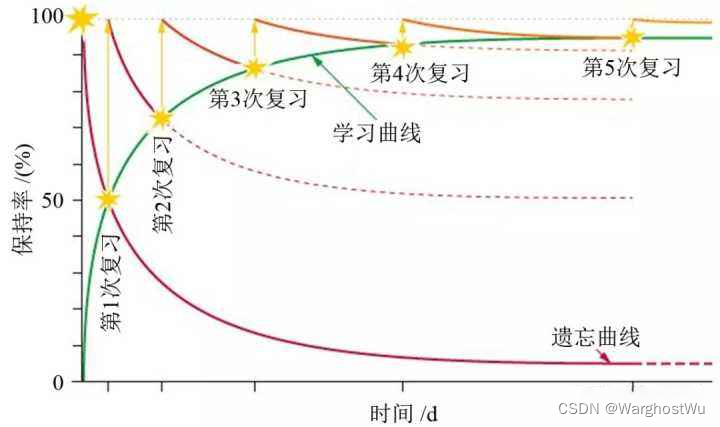
艾宾浩斯遗忘曲线通过一系列实验数据绘制而成,深刻地反映了人类记忆的保持率随时间的变化规律。以下是对艾宾浩斯遗忘曲线如何反映记忆保持率的详细解释:
- 初始遗忘速度快:
根据艾宾浩斯的实验,人们在初次学习后,记忆会迅速开始遗忘。例如,学习后的20分钟内,就有高达42%的信息被遗忘,只剩下58%被记住。这显示了人类记忆在初始阶段的快速遗忘特点。
- 遗忘速度逐渐减慢:
随着时间的推移,遗忘的速度会逐渐减慢。艾宾浩斯的实验数据显示,在学习后的1小时内,56%的信息被遗忘,而到了1天后,遗忘率增至74%。然而,从长时间尺度来看,遗忘的速度显著降低。比如,1周后遗忘率达到77%,1个月后达到79%,这表明随着时间的推移,遗忘的速度变得越来越慢。
- 记忆保持率的长期趋势:
艾宾浩斯遗忘曲线表明,虽然初始遗忘速度很快,但随着时间的推移,记忆保持率逐渐趋于稳定。这意味着在经历了一段时间的快速遗忘后,人们仍然能够保留相当一部分的记忆,并且这部分记忆在较长时间内相对稳定。
- 个体差异与曲线适用性:
艾宾浩斯遗忘曲线是基于对无意义音节的记忆实验得出的,因此它主要反映了机械记忆的遗忘规律。
对于有意义的信息或实际生活中的记忆情况,个体的记忆保持率可能会有所不同。
然而,艾宾浩斯遗忘曲线仍然提供了一个有价值的参考框架,帮助人们理解记忆随时间的变化趋势。
艾宾浩斯遗忘曲线通过展示记忆保持率随时间的变化规律,反映了人类记忆的遗忘特点。这条曲线提醒我们,在学习新知识后要及时复习以巩固记忆,因为初始阶段的遗忘速度非常快。同时,它也揭示了记忆保持的长期趋势和个体差异的重要性。
3.10.9. 艾宾浩斯曲线作为激活函数
艾宾浩斯曲线本身并不是一个典型的激活函数,因为激活函数通常在神经网络中使用,它们需要满足一些特定的数学特性,如可导性、非线性和输出值范围等。
然而,如果我们尝试从艾宾浩斯遗忘曲线的角度来设计一个类似的激活函数,可以探讨其可行性和潜在的弱点。
3.10.9.1. 可行性
艾宾浩斯遗忘曲线描述的是随着时间的推移,记忆保留率逐渐降低的过程。从这个角度看,我们可以设计一个随时间或输入值递减的激活函数,模拟类似遗忘效应的行为。这种设计在某些特定应用中可能是有意义的,例如需要模拟记忆衰减或注意力降低的系统。
3.10.9.2. 弱点
- 非线性不足:艾宾浩斯遗忘曲线虽然表现为下降趋势,但其下降速度可能相对平稳,不够非线性。在神经网络中,非线性是激活函数的一个关键特性,因为它允许网络学习复杂的数据表示。
- 输出范围限制:艾宾浩斯遗忘曲线描述的是记忆保留率,其输出范围通常在0到1之间。然而,在神经网络中,一些激活函数(如ReLU)的输出可以超过这个范围,从而提供更大的表示能力。
- 没有明确的数学公式:艾宾浩斯遗忘曲线是通过实验数据拟合得到的,没有明确的数学公式。这可能导致在神经网络中难以精确实现。
3.10.9.3. 与Sigmoid函数的对比
Sigmoid函数是神经网络中常用的激活函数之一。
Sigmoid函数将输入值映射到0到1之间的输出值,与艾宾浩斯遗忘曲线的输出范围相似。
然而,Sigmoid函数具有更好的非线性特性,能够在神经网络的训练过程中更好地学习数据表示。
在运行效率方面,Sigmoid函数由于其简单的数学形式,通常比复杂的自定义激活函数(如基于艾宾浩斯遗忘曲线的激活函数)更快。
此外,由于Sigmoid函数在深度学习框架中得到广泛支持,因此可以充分利用框架的优化来提高运行效率。
3.10.9.4. 小结论
虽然从概念上讲,我们可以尝试将艾宾浩斯遗忘曲线的思想应用于神经网络中的激活函数设计,但由于其非线性不足、输出范围限制以及没有明确的数学公式等弱点,这种设计在实际应用中可能面临挑战。相比之下,Sigmoid函数作为一种成熟的激活函数,在非线性、输出范围以及运行效率方面都具有更好的表现。
3.10.10. 结论
综合来说,艾宾浩斯遗忘曲线函数相对计算难度较大,非线性不足,同时,其还会快速陷入梯度消失。所以还是乖乖的使用sigmoid函数来搞激活函数吧。