如今,大型语言模型的使用方式有以下几种:
- 作为 OpenAI、Anthropic 或主要云提供商托管的专有模型的 API 端点
- 作为从 HuggingFace 的模型中心下载的模型工件和/或使用 HuggingFace 库进行训练/微调并托管在本地存储中
- 作为针对本地推理优化的格式的模型工件,通常为 GGUF,可通过 llama.cpp 或 ollama 等应用程序访问
- 作为 ONNX,一种优化后端 ML 框架之间共享的格式
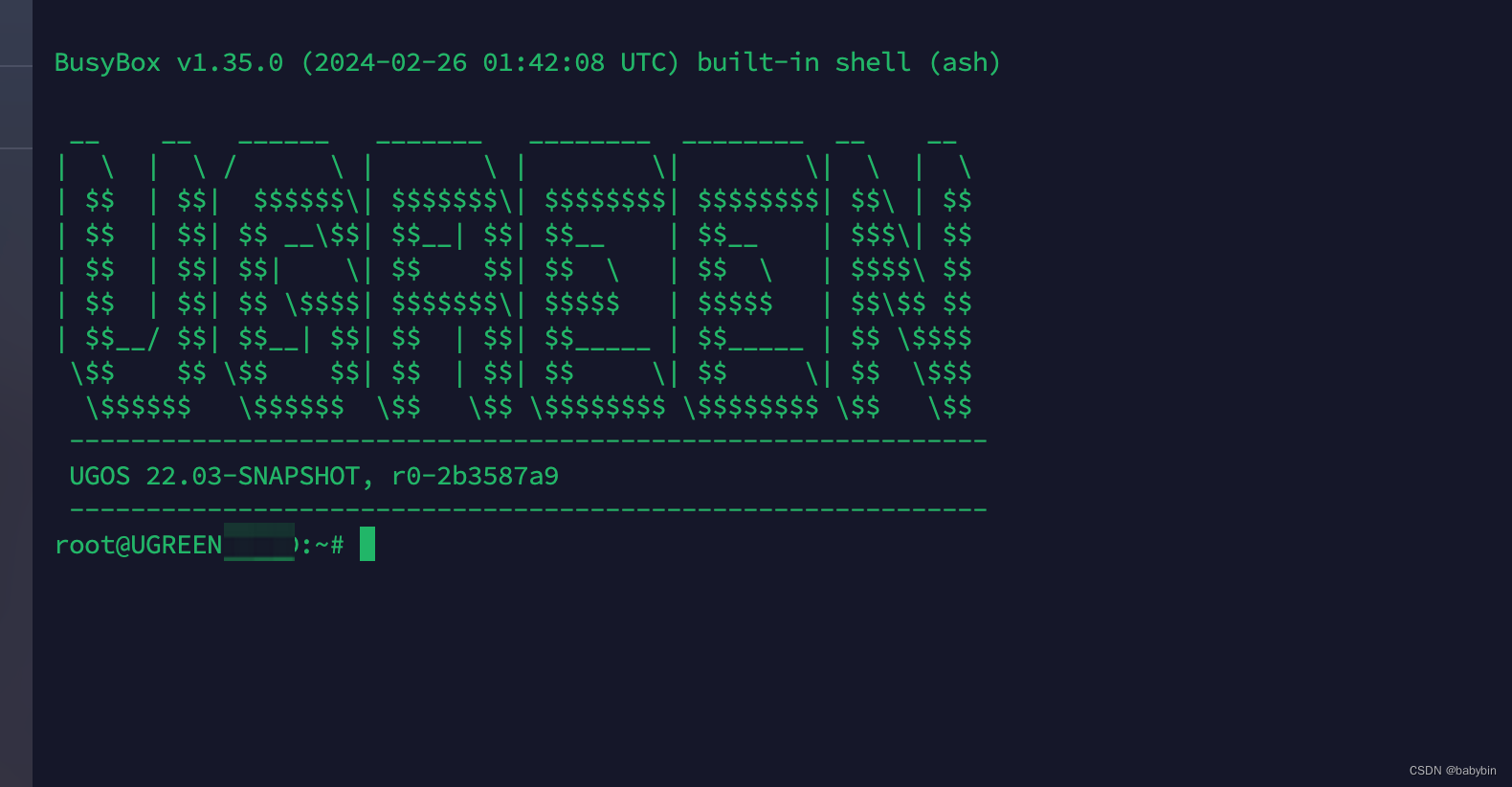
对于一个附带项目,我使用 llama.cpp,这是一个基于 C/C++ 的 LLM 推理引擎,针对 Apple Silicon 上的 M 系列 GPU。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
运行 llama.cpp 时,你会得到一个长日志,主要包含有关模型架构及其性能(没有杂音)的元数据的键值对:
make -j && ./main -m /Users/vicki/llama.cpp/models/mistral-7b-instruct-v0.2.Q8_0.gguf -p "What is Sanremo? no yapping"
Sanremo Music Festival (Festival di Sanremo) is an annual Italian music competition held in the city of Sanremo since 1951. It's considered one of the most prestigious and influential events in the Italian music scene. The festival features both newcomers and established artists competing for various awards, including the Big Award (Gran Premio), which grants the winner the right to represent Italy in the Eurovision Song Contest. The event consists of several live shows where artists perform their original songs, and a jury composed of musicians, critics, and the public determines the winners through a combination of points. [end of text]
llama_print_timings: load time = 11059.32 ms
llama_print_timings: sample time = 11.62 ms / 140 runs ( 0.08 ms per token, 12043.01 tokens per second)
llama_print_timings: prompt eval time = 87.81 ms / 10 tokens ( 8.78 ms per token, 113.88 tokens per second)
llama_print_timings: eval time = 3605.10 ms / 139 runs ( 25.94 ms per token, 38.56 tokens per second)
llama_print_timings: total time = 3730.78 ms / 149 tokens
ggml_metal_free: deallocating
Log end这些日志可以在 Llama.cpp 代码库中找到。在那里,你还会找到 GGUF。GGUF是用于在 Llama.cpp 和其他本地运行器(如 Llamafile、Ollama 和 GPT4All)上提供模型的文件格式。
要了解 GGUF 的工作原理,我们首先需要深入研究机器学习模型及其生成的工件类型。
1、什么是机器学习模型
让我们从描述机器学习模型开始。最简单的说,模型是一个文件或一组文件,其中包含模型架构以及从训练循环生成的模型的权重和偏差。
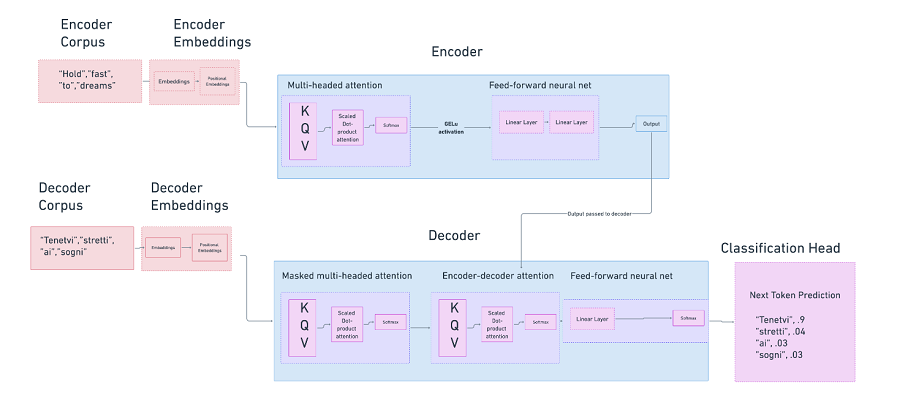
在 LLM 领域,我们通常对 Transformer 风格的模型和架构感兴趣。
在 Transformer 中,我们有许多活动部件。
对于输入,我们使用从人类生成的自然语言内容中聚合的训练数据语料库
对于算法,我们:
- 将这些数据转换为嵌入
- 对嵌入进行位置编码,以提供有关单词在序列中彼此相对位置的信息
- 基于初始化的权重组合,为序列中每个单词相对于其他单词创建多头自注意力
- 通过 softmax 对层进行规范化
- 通过前馈神经网络运行生成的矩阵
- 将输出投影到所需任务的正确向量空间中
- 计算损失,然后更新模型参数
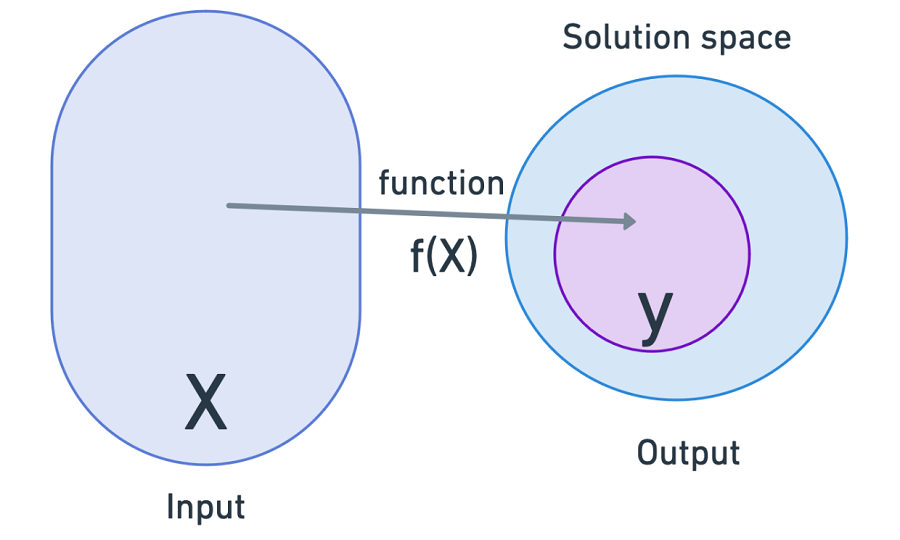
输出:通常对于聊天完成任务,模型返回任何给定单词完成短语的统计可能性。由于其自回归性质,它会对短语中的每个单词一次又一次地执行此操作。
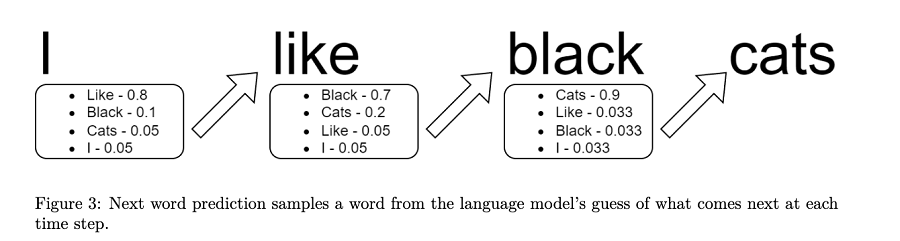
如果该模型作为消费者最终产品,它仅根据最高概率返回实际文本输出,并带有多种选择该文本的策略:
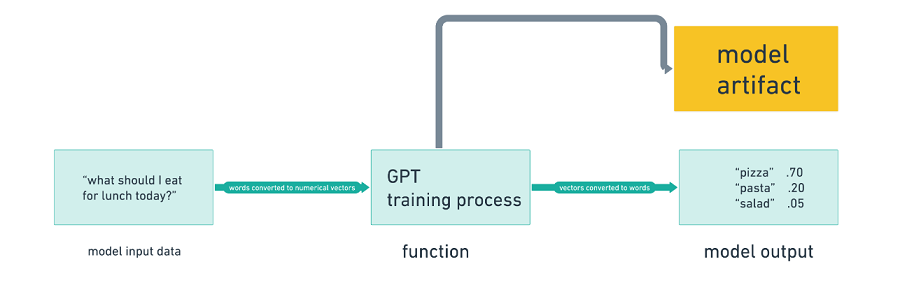
简而言之,我们使用方程将输入转换为输出。除了模型的输出,我们还有模型本身,它是建模过程的产物:
2、从一个简单的模型开始
让我们从转换器的复杂性中退一步,在 PyTorch 中构建一个小型线性回归模型。幸运的是,线性回归也是一个(浅层)神经网络,因此我们可以在 PyTorch 中使用它,并使用相同的框架将我们的简单模型映射到更复杂的模型。
线性回归接受一组数值输入并生成一组数值输出。(与转换器相反,转换器接受一组文本输入并生成一组文本输入及其相关的数值概率。)
例如,假设我们为统计学家生产手工榛子酱,并希望预测我们在任何一天将生产多少罐 Nulltella。假设我们有一些可用的数据,即我们每天有多少小时的日照,以及我们每天能够生产多少罐 Nulltella。

事实证明,天气晴朗时,我们更有灵感生产榛子酱,我们可以清楚地看到数据中输入和输出之间的这种关系(我们不会在周五至周日生产 Nulltella,因为我们更喜欢花那些时间编写有关数据序列化格式的内容):
| day_id | hours | jars |
|--------|---------|------|
| mon | 1 | 2 |
| tues | 2 | 4 |
| wed | 3 | 6 |
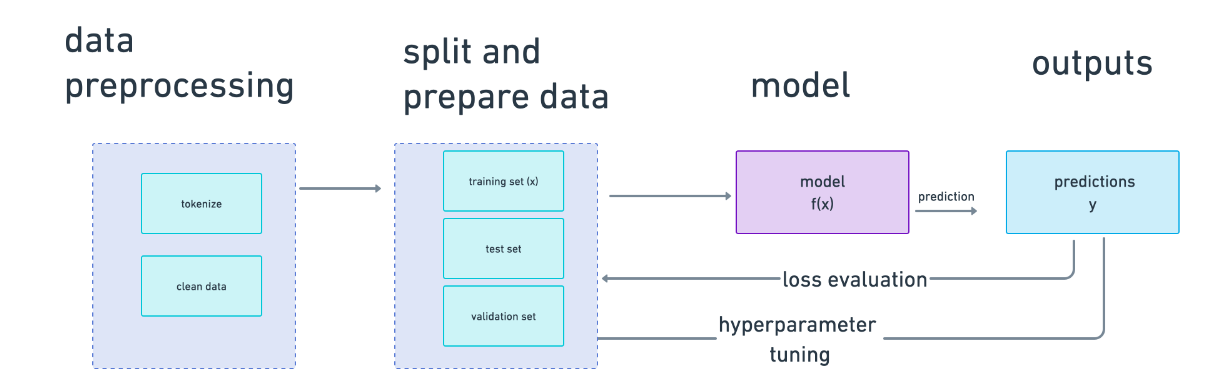
| thu | 4 | 8 |这是我们用来训练模型的数据。我们需要将这些数据分成三部分:
- 用于训练模型(训练数据)
- 用于测试模型的准确性(测试数据)
- 用于在模型训练阶段调整超参数、模型的元方面,如学习率(验证集)。
在线性回归的特定情况下,技术上没有超参数,尽管我们可以合理地认为我们在 PyTorch 中设置的学习率为 1。假设我们有 100 个这样的数据点值。
我们将数据分为训练、测试和验证。通常接受的分割是使用 80% 的数据进行训练/验证,20% 用于测试。我们希望我们的模型能够访问尽可能多的数据,以便它学习更准确的表示,所以我们将大部分数据留给训练。
现在我们有了数据,我们需要编写算法。线性回归中从输入X获得输出Y的公式为:
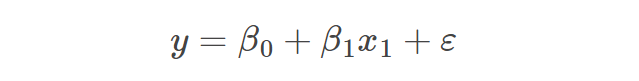
这告诉我们,输出 y(Nulltella 罐子的数量)可以通过以下公式预测:
- x1:一个输入变量(或特征),(日照时数)
- β1:给定权重,也称为参数,(该特征的重要性)
- 加上误差项 ξ,即捕获模型噪声的群体中观测值与实际值之间的差异
我们的任务是不断预测和调整权重,以最佳地解决该方程,以求出数据所表示的实际 y 与基于算法预测的 ŷ 之间的差异,从而找到每个点与直线之间最小的平方差和
。换句话说,我们希望最小化 ξ ,因为这意味着,在每个点,我们的 ŷ
都尽可能接近我们的实际 y (考虑到其他点)。
我们通过梯度下降来优化这个函数,从零或随机初始化的权重开始,继续重新计算权重和误差项,直到达到最佳停止点。我们知道我们成功了,因为我们的损失(由 RMSE 计算)应该在每次训练迭代中逐渐减少。
这是整个模型学习过程的端到端(除了标记化,我们只对特征为文本且我们想要进行语言建模的模型进行标记化):
3、编写模型代码
现在,让我们更具体一点,用代码描述这些想法。当我们训练模型时,我们用一组特征值初始化我们的函数。
让我们通过将 x1 和y 初始化为 PyTorch Tensor 对象,将数据添加到模型中。
# Hours of sunshine
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
# Jars of Nulltella
y = torch.tensor([[2.0], [4.0], [6.0], [8.0]], dtype=torch.float32)在代码中,我们的输入数据是 X,它是一个 torch 张量对象,我们的输出数据是 y。我们初始化一个 LinearRegression,它是 PyTorch 模块的子类,有一个线性层,它有一个输入特征(阳光)和一个输出特征(Nulltella 罐子)。
我将包含整个模型的代码,然后我们将逐一讨论它。
import torch
import torch.nn as nn
import torch.optim as optim
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
y = torch.tensor([[2.0], [4.0], [6.0], [8.0]], dtype=torch.float32)
# Define a linear regression model and its forward pass
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 1 input feature, 1 output feature
def forward(self, x):
return self.linear(x)
# Instantiate the model
model = LinearRegression()
# Inspect the model's state dictionary
print(model.state_dict())
# Define loss function and optimizer
criterion = nn.MSELoss()
# setting our learning rate "hyperparameter" here
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop that includes forward and backward pass
num_epochs = 100
for epoch in range(num_epochs):
# Forward pass
outputs = model(X)
loss = criterion(outputs, y)
RMSE_loss = torch.sqrt(loss)
# Backward pass and optimization
optimizer.zero_grad() # Zero out gradients
RMSE_loss.backward() # Compute gradients
optimizer.step() # Update weights
# Print progress
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# After training, let's test the model
test_input = torch.tensor([[5.0]], dtype=torch.float32)
predicted_output = model(test_input)
print(f'Prediction for input {test_input.item()}: {predicted_output.item()}')一旦我们有了输入数据,我们就可以初始化我们的模型,即 LinearRegression,它是 Module 基类的子类,专门用于线性回归。
前向传递涉及将我们的数据输入神经网络并确保它传播到所有层。由于我们只有一层,我们必须将数据传递给单个线性层。前向传递就是计算我们预测的 Y 值的过程。
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 1 input feature, 1 output feature
def forward(self, x):
return self.linear(x)我们选择如何优化模型的结果,也就是其损失应如何收敛。在本例中,我们从均方误差开始,然后将其修改为使用 RMSE,即数据集中预测值与实际值之间的平均平方差的平方根。
# Define loss function and optimizer
criterion = torch.sqrl(nn.MSELoss()) # RMSE in the training loop
optimizer = optim.SGD(model.parameters(), lr=0.01)
....
for epoch in range(num_epochs):
# Forward pass
outputs = model(X)
loss = criterion(outputs, y)
RMSE_loss = torch.sqrt(loss)现在我们已经定义了模型的运行方式,我们可以实例化模型对象本身:
4、实例化模型对象
model = LinearRegression()
print(model.state_dict())请注意,当我们实例化 nn.Module 时,它有一个名为“state_dict”的属性。这很重要。状态字典保存有关每个层以及每个层中的参数(即权重和偏差)的信息。
本质上,它是一个 Python 字典。
在这种情况下,LinearRegression 的实现返回一个有序字典,其中包含网络的每个层及其值。每个值都是一个张量。
OrderedDict([('linear.weight', tensor([[0.5408]])), ('linear.bias', tensor([-0.8195]))])
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
linear.weight torch.Size([1, 1])
linear.bias torch.Size([1])对于我们的小模型,它是一个小型的元组 OrderedDict。你可以想象,在大型网络(例如 transformer)中,这个张量集合会变得非常大,并且占用大量内存。如果每个参数(每个 Tensor 对象)在内存中占用 2 个字节,那么 70 亿个参数的模型在 GPU 中会占用 14GB。
然后,我们循环运行模型的前向和后向传递。在每个步骤中,我们进行前向传递以执行计算,进行后向传递以更新模型对象的权重,然后将所有这些信息添加到模型参数中。
# Define loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop
num_epochs = 100
for epoch in range(num_epochs):
# Forward pass
outputs = model(X)
loss = criterion(outputs, y)
RMSE_loss = torch.sqrt(loss)
# Backward pass and optimization
optimizer.zero_grad() # Zero out gradients
RMSE_loss.backward() # Compute gradients
optimizer.step() # Update weights
# Print progress
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')一旦完成这些循环,我们就训练了模型工件。一旦训练了模型,我们现在拥有的就是一个内存对象,它代表该模型的权重、偏差和元数据,存储在我们的 LinearRegression 模块实例中。
当我们运行训练循环时,我们可以看到我们的损失缩小了。也就是说,实际值越来越接近预测值:
Epoch [10/100], Loss: 33.0142
Epoch [20/100], Loss: 24.2189
Epoch [30/100], Loss: 16.8170
Epoch [40/100], Loss: 10.8076
Epoch [50/100], Loss: 6.1890
Epoch [60/100], Loss: 2.9560
Epoch [70/100], Loss: 1.0853
Epoch [80/100], Loss: 0.4145
Epoch [90/100], Loss: 0.3178
Epoch [100/100], Loss: 0.2974我们还可以看到,如果我们打印出 state_dict,参数就会随着我们计算梯度和更新反向传递中的权重而发生变化:
"""before"""
OrderedDict([('linear.weight', tensor([[-0.6216]])), ('linear.bias', tensor([0.7633]))])
linear.weight torch.Size([1, 1])
linear.bias torch.Size([1])
{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'differentiable': False, 'params': [0, 1]}]}
Epoch [10/100], Loss: 33.0142
Epoch [20/100], Loss: 24.2189
Epoch [30/100], Loss: 16.8170
Epoch [40/100], Loss: 10.8076
Epoch [50/100], Loss: 6.1890
Epoch [60/100], Loss: 2.9560
Epoch [70/100], Loss: 1.0853
Epoch [80/100], Loss: 0.4145
Epoch [90/100], Loss: 0.3178
Epoch [100/100], Loss: 0.2974
"""after"""
OrderedDict([('linear.weight', tensor([[1.5441]])), ('linear.bias', tensor([1.3291]))])如我们所见,优化器有自己的 state_dict,它由我们之前讨论过的超参数组成:学习率、权重衰减等等:
print(optimizer.state_dict())
{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'differentiable': False, 'params': [0, 1]}]}现在我们有了一个经过训练的模型对象,我们可以传入新的特征值供模型评估。例如,我们可以传入 5 小时日照的 X 值,看看我们预计会制作多少罐 Nulltella。
我们通过将 5 传递给实例化的模型对象来实现这一点,该模型对象现在是用于运行线性回归方程的方法和我们的状态字典、权重、当前权重集和偏差的组合,以给出新的预测值。我们得到了 9 个罐子,这非常接近我们的预期。
test_input = torch.tensor([[5.0]], dtype=torch.float32)
predicted_output = model(test_input)
print(f'Prediction for input {test_input.item()}: {predicted_output.item()}')
Prediction for input 5.0: 9.049455642700195为了清晰起见,我抽象出了大量细节,即 PyTorch 在将这些数据移入和移出 GPU 以及使用 GPU 高效数据类型进行高效计算方面所做的大量工作,这是库工作的很大一部分。为简单起见,我们现在将跳过这些。
5、序列化我们的对象
到目前为止,一切顺利。我们现在在内存中拥有状态 Python 对象,它们传达了我们模型的状态。但是,当我们需要持久保存这个非常大的模型(我们可能花了 24 多个小时进行训练)并再次使用它时会发生什么?
此场景在此处描述,
假设研究人员正在试验一种新的深度学习模型架构,或现有架构的变体。她的架构将有一大堆配置选项和超参数:层数、每层的类型、各种向量的维数、在哪里以及如何规范化激活、使用哪些非线性,等等。许多模型组件将是 ML 框架提供的标准层,但研究人员也会插入一些新逻辑。
我们的研究人员需要一种方法来描述特定的具体模型——这些设置的特定组合——这些模型可以序列化,然后稍后重新加载。她需要这样做有几个相关的原因:
她可能可以访问包含 GPU 或其他加速器的计算集群,她可以使用这些加速器来运行作业。她需要一种方法来向在该集群上运行的代码提交模型描述,以便它可以在该集群上运行她的模型。
在训练这些模型时,她需要保存它们的进度快照,以便在硬件发生故障或作业被抢占时可以重新加载和恢复它们。一旦模型训练完成,研究人员将希望再次加载它们(可能是最终快照和一些部分训练的检查点),以便对它们进行评估和实验。
我们所说的序列化是什么意思?它是将对象和类从我们的编程运行时写入文件的过程。反序列化是将磁盘上的数据转换为内存中的编程语言对象的过程。现在我们需要将数据序列化为可以写入文件的字节流。
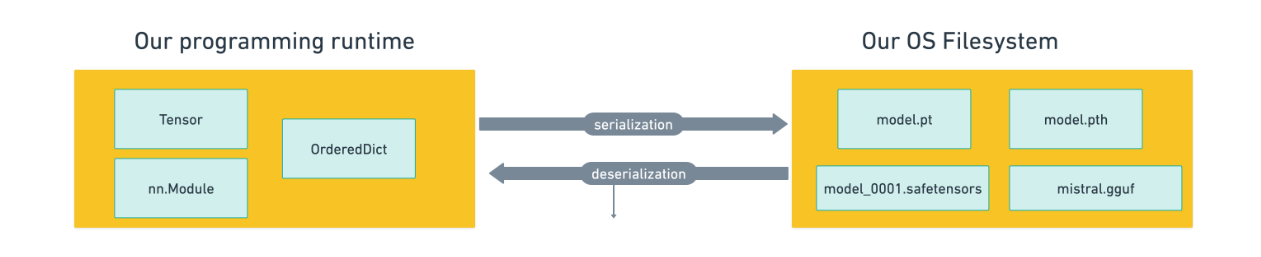
为什么要“序列化”?因为在过去,数据曾经存储在磁带上,这就要求位在磁带上按顺序排列。
由于如今许多 Transformer 样式的模型都是使用 PyTorch 进行训练的,因此工件使用 PyTorch 的保存实现将对象序列化到磁盘。
6、什么是文件
同样,为了简单起见,让我们抽象出 GPU,并假设我们在 CPU 中执行所有这些计算。Python 对象存在于内存中。此内存在其生命周期开始时分配在一个特殊的私有堆中,在由 Python 内存管理器管理的私有堆中,不同对象类型有专门的堆。
当我们初始化 PyTorch 模型对象时,操作系统通过默认内存分配器通过低级 C 函数(即 malloc)分配内存。
当我们使用 tracemalloc 运行代码时,我们可以看到 PyTorch 的内存实际上是如何在 CPU 上分配的(请记住,GPU 操作完全不同)。
import tracemalloc
tracemalloc.start()
.....
pytorch
...
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
print("[ Top 10 ]")
for stat in top_stats[:10]:
print(stat)
[ Top 10 ]
<frozen importlib._bootstrap_external>:672: size=21.1 MiB, count=170937, average=130 B
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/inspect.py:2156: size=577 KiB, count=16, average=36.0 KiB
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/site-packages/torch/_dynamo/allowed_functions.py:71: size=512 KiB, count=3, average=171 KiB
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/dataclasses.py:434: size=410 KiB, count=4691, average=90 B
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/site-packages/torch/_dynamo/allowed_functions.py:368: size=391 KiB, count=7122, average=56 B
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/site-packages/torch/_dynamo/allowed_functions.py:397: size=349 KiB, count=1237, average=289 B
<frozen importlib._bootstrap_external>:128: size=213 KiB, count=1390, average=157 B
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/functools.py:58: size=194 KiB, count=2554, average=78 B
/Users/vicki/.pyenv/versions/3.10.0/lib/python3.10/site-packages/torch/_dynamo/allowed_functions.py:373: size=136 KiB, count=2540, average=55 B
<frozen importlib._bootstrap_external>:1607: size=127 KiB, count=1133, average=115 B在这里,我们可以看到我们从 imports 导入了 170k 个对象,其余分配来自 torch 中的 allowed_functions。
7、PyTorch 如何将对象写入文件?
我们还可以更明确地看到内存中这些对象的类型。在 PyTorch 和 Python 系统库创建的所有其他对象中,我们可以在这里看到我们的 Linear 对象,它具有 state_dict 作为属性。我们需要将此对象序列化为字节流,以便将其写入磁盘。
import gc
# Get all live objects
all_objects = gc.get_objects()
# Extract distinct object types
distinct_types = set(type(obj) for obj in all_objects)
# Print distinct object types
for obj_type in distinct_types:
print(obj_type.__name__)
InputKind
KeyedRef
ReLU
Manager
_Call
UUID
Pow
Softmax
Options
_Environ
**Linear**
CFunctionType
SafeUUID
_Real
JSONDecoder
StmtBuilder
OutDtypeOperator
MatMult
attrgePyTorch 使用 Python 的 pickle 框架并包装 pickle load 和 dump 方法将对象序列化到磁盘。
Pickle 遍历对象的继承层次结构,并将遇到的每个对象转换为可流式传输的工件。它以递归方式执行此操作以处理嵌套表示(例如,了解从 nn.Module 继承的 nn.Module 和 Linear),并将这些表示转换为字节表示,以便可以将它们写入文件。
作为示例,让我们采用一个简单的函数并将其写入 pickle 文件。
import torch.nn as nn
import torch.optim as optim
import pickle
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
with open('tensors.pkl', 'wb') as f:
pickle.dump(X, f) 当我们使用 pickletools 检查 pickle 对象时,我们了解了数据的组织方式。
我们导入一些函数,将数据加载为张量,然后是该数据的实际存储,然后是其类型。该模块在从 pickle 文件转换为 Python 对象时执行相反的操作。
python -m pickletools tensors.pkl
0: \x80 PROTO 4
2: \x95 FRAME 398
11: \x8c SHORT_BINUNICODE 'torch._utils'
25: \x94 MEMOIZE (as 0)
26: \x8c SHORT_BINUNICODE '_rebuild_tensor_v2'
46: \x94 MEMOIZE (as 1)
47: \x93 STACK_GLOBAL
48: \x94 MEMOIZE (as 2)
49: ( MARK
50: \x8c SHORT_BINUNICODE 'torch.storage'
65: \x94 MEMOIZE (as 3)
66: \x8c SHORT_BINUNICODE '_load_from_bytes'
84: \x94 MEMOIZE (as 4)
85: \x93 STACK_GLOBAL
86: \x94 MEMOIZE (as 5)
87: B BINBYTES b'\x80\x02\x8a\nl\xfc\x9cF\xf9 j\xa8P\x19.\x80\x02M\xe9\x03.\x80\x02}q\x00(X\x10\x00\x00\x00protocol_versionq\x01M\xe9\x03X\r\x00\x00\x00little_endianq\x02\x88X\n\x00\x00\x00type_sizesq\x03}q\x04(X\x05\x00\x00\x00shortq\x05K\x02X\x03\x00\x00\x00intq\x06K\x04X\x04\x00\x00\x00longq\x07K\x04uu.\x80\x02(X\x07\x00\x00\x00storageq\x00ctorch\nFloatStorage\nq\x01X\n\x00\x00\x006061074080q\x02X\x03\x00\x00\x00cpuq\x03K\x04Ntq\x04Q.\x80\x02]q\x00X\n\x00\x00\x006061074080q\x01a.\x04\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80?\x00\x00\x00@\x00\x00@@\x00\x00\x80@'
351: \x94 MEMOIZE (as 6)
352: \x85 TUPLE1
353: \x94 MEMOIZE (as 7)
354: R REDUCE
355: \x94 MEMOIZE (as 8)
356: K BININT1 0
358: K BININT1 4
360: K BININT1 1
362: \x86 TUPLE2
363: \x94 MEMOIZE (as 9)
364: K BININT1 1
366: K BININT1 1
368: \x86 TUPLE2
369: \x94 MEMOIZE (as 10)
370: \x89 NEWFALSE
371: \x8c SHORT_BINUNICODE 'collections'
384: \x94 MEMOIZE (as 11)
385: \x8c SHORT_BINUNICODE 'OrderedDict'
398: \x94 MEMOIZE (as 12)
399: \x93 STACK_GLOBAL
400: \x94 MEMOIZE (as 13)
401: ) EMPTY_TUPLE
402: R REDUCE
403: \x94 MEMOIZE (as 14)
404: t TUPLE (MARK at 49)
405: \x94 MEMOIZE (as 15)
406: R REDUCE
407: \x94 MEMOIZE (as 16)
408: . STOP
highest protocol among opcodes = 4pickle 作为文件格式的主要问题是它不仅捆绑了可执行代码,而且没有对正在读取的代码进行检查,并且没有架构保证,你可以将恶意内容传递给 pickle,
不安全性不是因为 pickle 包含代码,而是因为它们通过调用 pickle 中命名的构造函数来创建对象。任何可调用函数都可以代替你的类名来构造对象。恶意 pickle 将使用其他 Python 可调用函数作为“构造函数”。例如,危险的 pickle 可能会执行 os.system('rm -rf /'),而不是执行 models.MyObject(17)。unpickler 无法区分 models.MyObject和 os.system。两者都是它可以解析的名称,从而生成它可以调用的内容。unpickler 会按照 pickle 的指示执行其中任何一个。'
8、Pickle 的工作原理
Pickle 最初适用于基于 Pytorch 的模型,因为它也与 Python 生态系统紧密相关,而且初始 ML 库工件不是深度学习系统的主要输出。
研究的主要输出是知识,而不是软件工件。研究团队编写软件来回答研究问题并提高他们/他们的团队/他们的领域对某个领域的理解,而不是为了获得软件工具或解决方案而编写软件。
然而,随着 2017 年 Transformer 论文发布后基于 Transformer 的模型的使用增加,Transformer 库的使用也随之增加,它将加载调用委托给使用 pickle 的 PyTorch 的加载方法。
一旦从业者开始创建并将 pickle 模型工件上传到 HuggingFace 等模型中心,机器学习模型供应链安全就成为一个问题。
9、从 pickle 到 safetensors
随着使用 PyTorch 训练的深度学习模型的机器学习爆炸式增长,这些安全问题达到了顶峰,2021 年,Trail of Bits 发布了一篇关于 pickle 文件的不安全性的文章。
HuggingFace 的工程师开始开发一个名为 safetensors 的库作为 pickle 的替代品。Safetensors 被开发为高效,但也比 pickle 更安全、更符合人体工程学。
首先,safetensors 与 Python 的绑定不像 Pickle 那样紧密:使用 pickle,你只能用 Python 读取或写入文件。Safetensors 跨语言兼容。其次,safetensors 还限制了语言执行,序列化和反序列化上可用的功能。第三,由于 safetensors 的后端是用 Rust 编写的,因此它更严格地执行类型安全。最后,safetensors 针对将张量作为数据类型的工作进行了优化,而 Pickle 则没有。再加上它是用 Rust 编写的事实,使得它的读写速度非常快。
在 Trail of Bits 和 EleutherAI 的共同推动下,对安全张量进行了安全审核,并得到满意的结果,这使得 HuggingFace 将其作为 Hub 上模型的默认格式。
10、safetensors 的工作原理
safetensors 格式的工作原理是什么?与 LLM 中的大多数前沿技术一样,代码和提交历史将起到重要作用。让我们来看看文件规范。
- 8 个字节:N,一个无符号小端 64 位整数,包含标头的大小
- N 个字节:一个表示标头的 JSON UTF-8 字符串。标头数据必须以 { 字符 (0x7B) 开头。标头数据末尾可以填充空格 (0x20)。标头是一个字典,例如 {“TENSOR_NAME”: {“dtype”: “F16”, “shape”: [1, 16, 256], “data_offsets”: [BEGIN, END]}, “NEXT_TENSOR_NAME”: {…}, …},data_offsets 指向相对于字节缓冲区开头的张量数据(即不是文件中的绝对位置),BEGIN 为起始偏移量,END 为前一个偏移量(因此总张量字节大小 = END - BEGIN)。允许特殊密钥元数据包含自由格式的字符串到字符串映射。不允许使用任意 JSON,所有值都必须是字符串。
- 文件的其余部分:字节缓冲区。
这与 state_dict 和 pickle 文件规范不同,但添加 safetensors 遵循了从 Python 对象到成熟文件格式的自然演变。
文件是一种将编程语言对象生成的数据以字节为单位存储在磁盘上的方式。在查看不同的文件格式规范(Arrow、Parquet、protobuf)时,我们会开始注意到它们的布局方式的一些模式。
- 在文件中,我们需要一些指示符来表明这是一种文件类型“X”。通常,这由一个魔法字节表示。
- 然后,有一个表示文件元数据的文件头,在机器学习的情况下,我们有多少层、学习率和其他方面。
- 实际数据。在机器学习文件的情况下,张量
- 然后,我们需要一个规范来告诉我们在读取文件时会期望什么,文件中有哪些数据类型以及它们如何表示为字节。本质上,文件布局和 API 的文档,以便我们可以针对它编写文件读取器。
- 文件规范通常会告诉我们的一个特性是数据是小端还是大端,也就是说 - 我们是先存储最大数字还是最后存储最大数字。这变得很重要,因为我们期望在具有不同默认字节布局的系统上读取文件。
- 然后,我们实现专门读取和写入该文件规范的代码。
从之前查看过 statedicts 和 pickle 文件后,我们开始注意到的一件事是,机器学习数据存储遵循一种模式:我们需要存储:
- 大量向量集合,
- 关于这些向量的元数据
- 超参数
然后,我们需要能够实例化模型对象,我们可以用该数据对其进行填充并对其运行模型操作。
作为文档中 safetensors 的一个示例:我们从 Python 字典(又称状态字典)开始,保存并加载文件:
import torch
from safetensors import safe_open
from safetensors.torch import save_file
tensors = {
"weight1": torch.zeros((1024, 1024)),
"weight2": torch.zeros((1024, 1024))
}
save_file(tensors, "model.safetensors")
tensors = {}
with safe_open("model.safetensors", framework="pt", device="cpu") as f:
for key in f.keys():
tensors[key] = f.get_tensor(key)我们使用 save_file(model.state_dict(), 'my_model.st') 方法将文件渲染为 safetensors
在从 pickle 到 safetensors 的转换过程中,我们也从状态字典开始。
Safetensors 迅速成为共享模型权重和架构的主要格式,用于进一步微调,在某些情况下,用于推理
11、检查点文件
到目前为止,我们已经研究了简单的 state_dict 文件和单个 safetensors 文件。但是,如果你正在训练一个长期运行的模型,那么你可能不仅仅需要保存权重和偏差,而且你希望时不时地保存你的状态,以便在开始看到训练运行中的问题时可以恢复。
PyTorch 有检查点。检查点是一个包含模型 state_dict 的文件,但也包含优化器的 state_dict,因为它包含在模型训练时更新的缓冲区和参数。你可能想要保存的其他项目包括上次中断的时期、最新记录的训练损失、外部 torch.nn.Embedding 层等。这些内容也会保存为字典并进行 pickle,然后在需要时进行 unpickle。所有这些内容也会保存到字典中,即 optimizer_state_dict,与 model_state_dict 不同。
# Additional information
EPOCH = 5
PATH = "model.pt"
LOSS = 0.4
torch.save({
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
}, PATH)此外,大多数大型语言模型现在还包括附带文件,如 tokenizer、HuggingFace、元数据等。因此,如果您使用 PyTorch 模型作为通过 Transformers 库生成的工件,您将获得一个如下所示的存储库。
12、GGML
随着从 pickle 迁移到 safetensors 以进行通用模型微调和推理的工作不断进行,Apple Silicon 继续变得更好。因此,人们开始将建模工作和推理从大型基于 GPU 的计算集群带到本地和边缘设备。
Georgi Gerganov 的项目使用 Whisper.cpp 使 OpenAI 的 Whisper 在本地运行。取得了成功,并成为后续项目的催化剂。 Llama-2 作为一个开源模型发布,再加上 LoRA 等模型压缩技术的兴起,大型语言模型通常只能在实验室或工业级 GPU 硬件上访问(我们在这里运行的小型 CPU 示例除外),也成为思考在本地使用和运行个性化模型的催化剂。
基于 whisper.cpp 的兴趣和成功,Gerganov 创建了 llama.cpp,这是一个用于处理 Llama 模型权重的包,最初是 pickle 格式,GGML 格式,用于本地推理。
GGML 最初是一个库,也是专门为 whisper 的边缘推理创建的补充格式。你也可以使用它进行微调,但通常它用于读取在基于 GPU Linux 的环境中在 PyTorch 上训练的模型,并转换为 GGML 以在 Apple Silicon 上运行。
例如,以下是 GGML 脚本,它将 PyTorch GPT-2 检查点转换为正确的格式,读取为 .bin 文件。这些文件是从 OpenAI 下载的。
生成的 GGML 文件将所有这些压缩为一个,并包含:
- 带有可选版本号的魔法数字
- 特定于模型的超参数,包括有关模型的元数据,例如层数、头数等。描述大多数张量类型的 ftype,对于 GGML 文件,量化版本在 ftype 中编码,除以 1000
- 嵌入词汇表,即带有长度前缀的字符串列表。
- 最后,带有长度前缀的名称、类型和张量数据的张量列表
有几个元素使 GGML 在本地推理方面比检查点文件更有效。首先,它使用模型权重的 16 位浮点表示。通常,torch 默认以 32 位浮点数初始化浮点数据类型。16 位或半精度意味着模型权重在计算和推理时使用的内存减少了 50%,而不会显著降低模型准确性。其他架构选择包括使用 C,它提供比 Python 更高效的内存分配。最后,GGML 是针对 Silicon 优化构建的。
不幸的是,在提高效率的过程中,GGML 包含了许多重大更改,这些更改给用户带来了问题。
最大的问题是,由于所有内容(包括数据、元数据和超参数)都写入同一个文件中,如果模型添加了超参数,它将破坏新文件无法接收的向后兼容性。此外,文件中不存在模型架构元数据,并且每个架构都需要自己的转换脚本。所有这些都导致了性能不稳定和 GGUF 的产生。
13、GGUF
GGUF 具有与 GGML 相同的布局类型,元数据和张量数据位于单个文件中,但此外还设计为向后兼容。关键区别在于,新文件格式不使用超参数的值列表,而是使用键值查找表来适应移位值。
我们花费时间建立的机器学习模型的工作方式和文件格式的布局现在使我们能够理解 GGUF 格式。
首先,我们知道 GGUF 模型对于特定架构默认为小端,我们记得当最低有效字节在前时,它针对不同的计算机硬件架构进行了优化。
然后,我们有 gguf_header_t,它是标题
它包含告诉我们这是一个 GGUF 文件的魔法字节:
Must be `GGUF` at the byte level: `0x47` `0x47` `0x55` `0x46`. 以及键值对:
// The metadata key-value pairs.
gguf_metadata_kv_t metadata_kv[metadata_kv_count];该文件格式还提供版本控制,在这种情况下,我们看到这是该文件格式的版本 3。
// Must be `3` for version described in this spec, which introduces big-endian support.
//
// This version should only be increased for structural changes to the format.然后,我们有张量
gguf_tensor_info_t整个文件看起来像这样,当我们与 llama.cpp 和 ollama 等读取器一起工作时,他们会采用这个规范并编写代码来打开这些文件并读取它们。

14、结束语
我们经历了一场旋风般的冒险,以建立我们对机器学习模型如何工作、它们产生什么工件、机器学习工件存储故事在过去几年中如何变化的直觉,并最终进入 GGUF 的文档,以更好地理解在 GGUF 中对工件进行本地推理时呈现给我们的日志。
原文链接:从Pickle到GGUF - BimAnt