240630_昇思学习打卡-Day12-Transformer中的Multiple-Head Attention
以下为观看大佬课程及查阅资料总结所得,附大佬视频链接:Transformer中Self-Attention以及Multi-Head Attention详解_哔哩哔哩_bilibili,强烈建议先去看大佬视频,然后自己做笔记。
附上期Self-Attention链接:240629_昇思学习打卡-Day11-Vision Transformer中的self-Attention-CSDN博客,本文中用到了上期的思想,建议先看上期。

Multi-Head Attention和Self-Attention在前半部分是差不多的,只是在得到了对应的
q
i
q^i
qi,
k
i
k^i
ki,
v
i
v^i
vi之后,再把这三个进行均分,有多少个Head就均分多少份,这里的均分就是直接拆分,比如
q
1
q^1
q1是
(
1
,
1
,
0
,
1
)
(1,1,0,1)
(1,1,0,1),均分两份后就是
(
1
,
1
)
(1,1)
(1,1)和
(
0
,
1
)
(0,1)
(0,1),当然,这样说可能有点过于简单了,观察原公式,原公式中他是乘以一个矩阵
W
i
Q
W_i^Q
WiQ,我们可以其设置成对应值实现均分,比如
q
1
=
(
1
,
1
,
0
,
1
)
q^1=(1,1,0,1)
q1=(1,1,0,1)
W 1 Q = ( 1 0 0 1 0 0 0 0 ) W_1^Q=\begin{pmatrix} 1 & 0\\ 0 & 1\\ 0 & 0\\ 0 & 0\end{pmatrix} W1Q= 10000100
此时
q
1
,
1
=
q
1
∗
W
i
Q
=
(
1
,
1
)
q^{1,1}=q^1*W_i^Q=(1,1)
q1,1=q1∗WiQ=(1,1)
同理如果我们要求
q
1
,
2
q^{1,2}
q1,2,就给
W
2
Q
W_2^Q
W2Q赋值为:
W
2
Q
=
(
0
0
0
0
0
0
0
1
)
W_2^Q=\begin{pmatrix} 0 & 0\\ 0 & 0\\ 0 & 0\\ 0 & 1\end{pmatrix}
W2Q=
00000001
这样我们就可以通过乘法计算出
q
1
,
2
q^{1,2}
q1,2,但是要问这个矩阵是怎么确定的,我暂时还不知道,大佬文章中也暂时没提到,我只是通过直接拆分的方法知道他的目标值,然后逆推导出的这个矩阵。后面等搞明白了回来修复,如有大佬指正不胜感激。
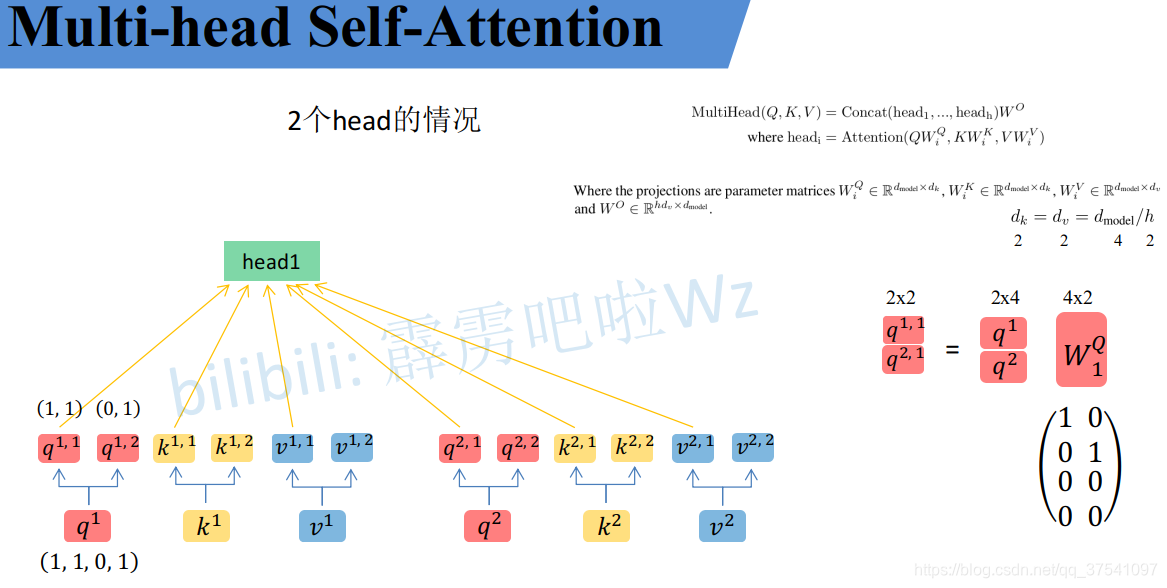
通过以上方法(直接拆分)可以得到每个Head对应的 q i q^i qi, k i k^i ki, v i v^i vi参数,接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。(以下为Self-Attention公式)
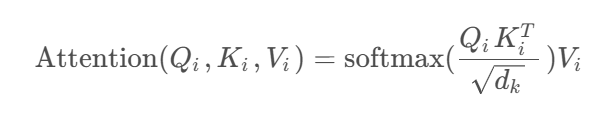
接下来就要将每个head的结果进行拼接,此时还是以两个head举例:
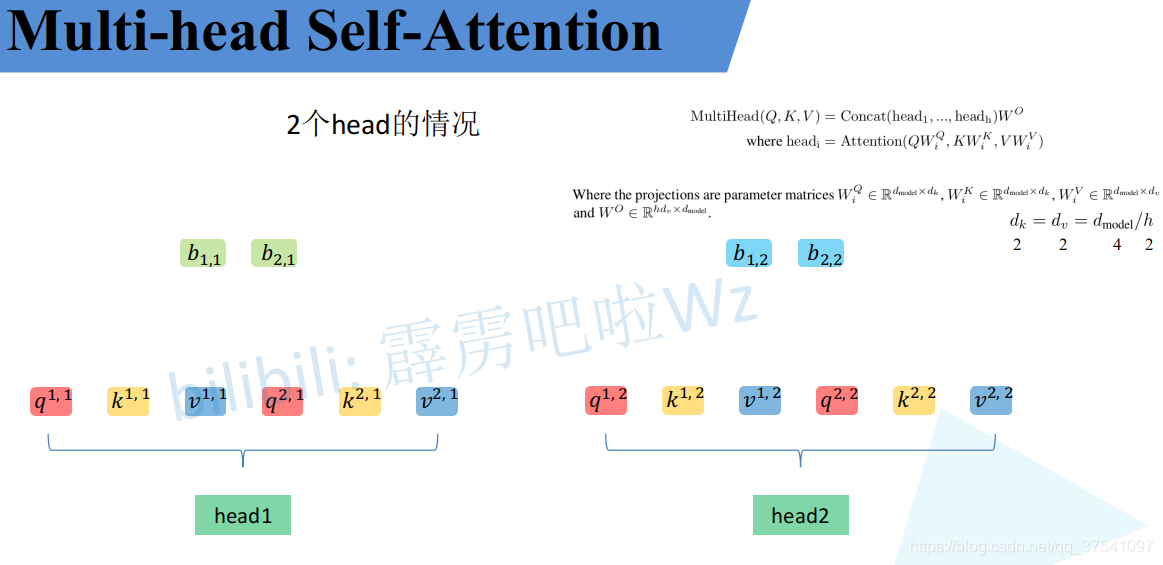
这个图里面的b大家可能忘了,这个b就是Self-Attention中求得的最后结果,在多头注意力这边,这个结果还要再进行计算。
将每个head得到的结果进行concat拼接,比如下图中的 b 1 , 1 b_{1,1} b1,1( h e a d 1 head_1 head1得到的 b 1 b_1 b1)和 b 1 , 2 b_{1,2} b1,2( h e a d 2 head_2 head2得到的 b 1 b_1 b1)拼接在一起。
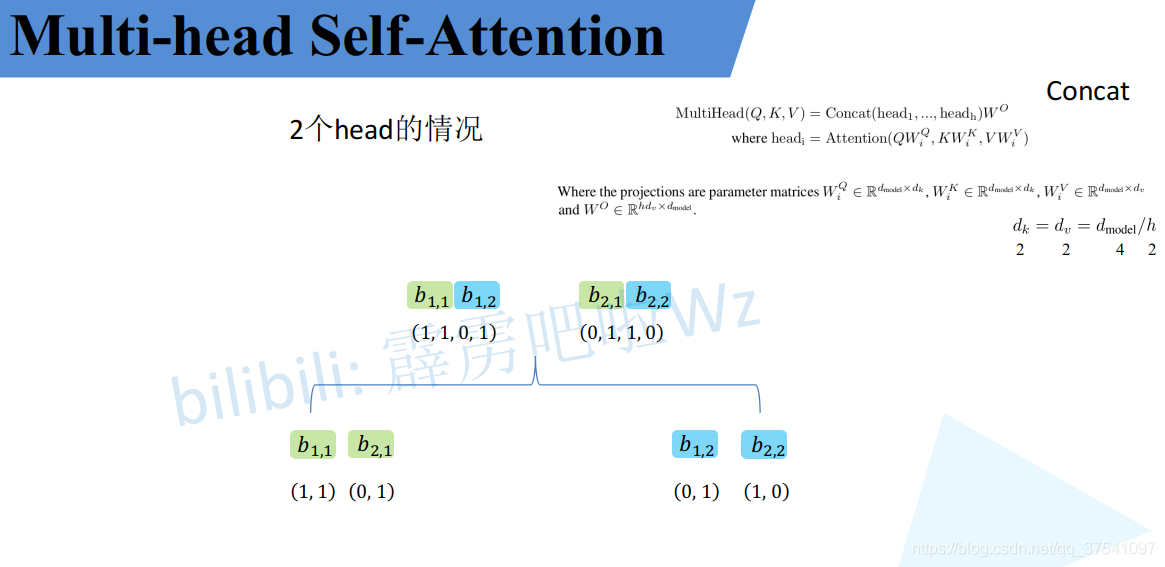
根据原公式,我们这里拼接完了之后还要给一个参数 W 0 W^0 W0和他相乘进行融合,这里这个 W 0 W^0 W0是可学习的参数,其维度参考拆分前的 q 1 q^1 q1, q 1 q^1 q1是4,这里 W 0 W^0 W0是4X4。融合后得到最后的结果。
注意这里是拼接两次,分别把 b 1 , 1 b_{1,1} b1,1和 b 1 , 2 b_{1,2} b1,2, b 2 , 1 b_{2,1} b2,1和 b 2 , 2 b_{2,2} b2,2在列上进行拼接后,还要把他两的结果进行在行上拼接(我也不知道我的措辞用反了没有,大家看图,上面是第一次拼接,下面图右下角是第二次拼接),然后在和 W 0 W^0 W0进行运算

至此结束,大家记得去看大佬的视频,我的记录肯定不太详尽。
另外,我真的很好奇,csdn这个md编辑器到底是什么情况,为什么有时候行内公式就能显示,有时候行间公式都显示不了。
打卡图片:
参考博客:
11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
详解Transformer中Self-Attention以及Multi-Head Attention_transformer multi head-CSDN博客
Vision Transformer详解-CSDN博客
一文搞定自注意力机制(Self-Attention)-CSDN博客
以上图片均引用自以上大佬博客,如有侵权,请联系删除