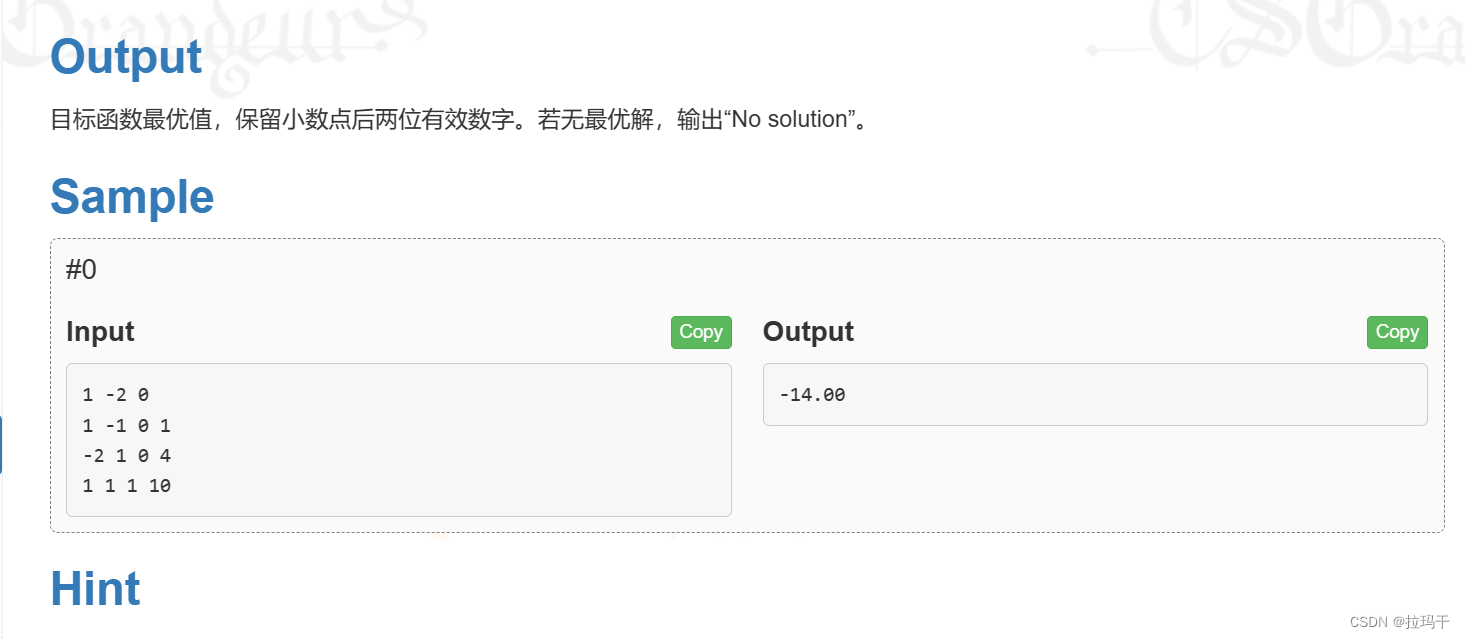
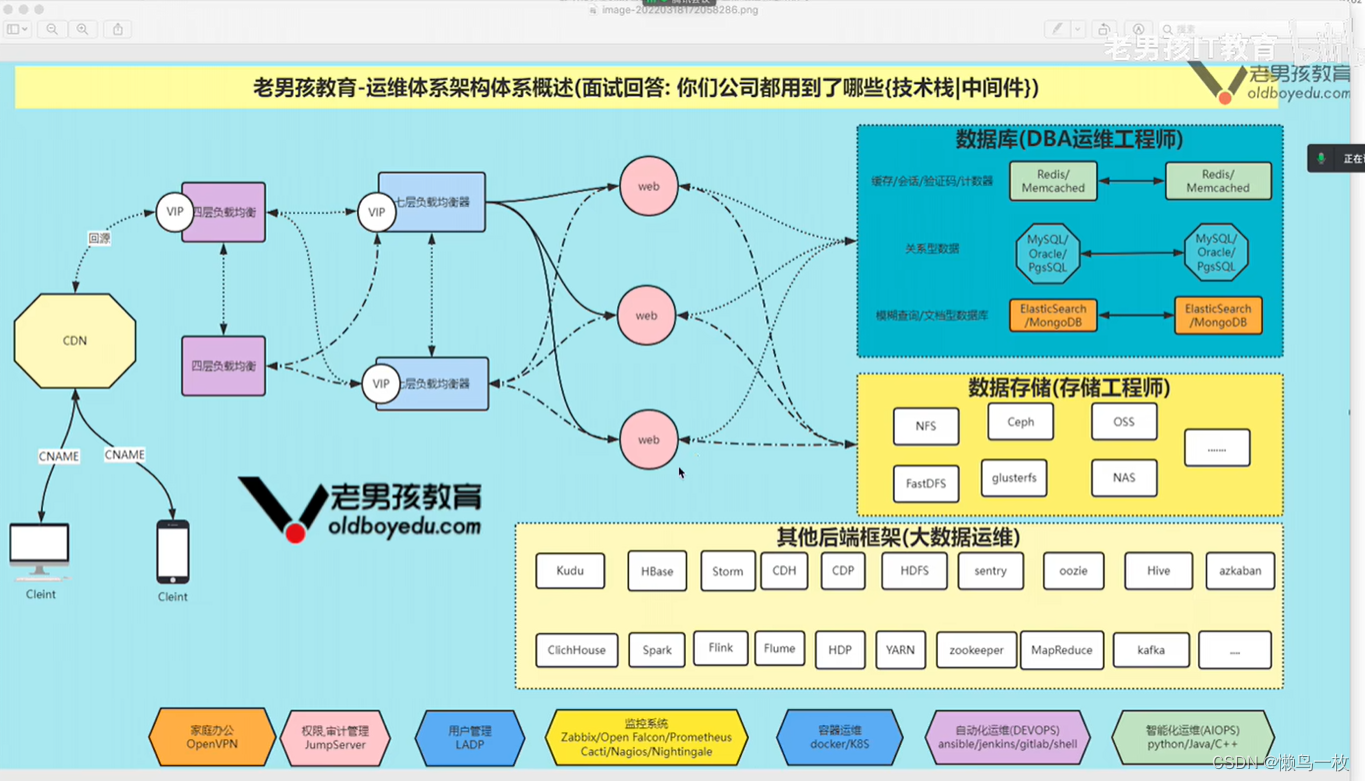
一、Elstic stack在企业的常⻅架构
https://www.bilibili.com/video/BV1x94y1674x/?buvid=XY705117E90F73A790429C9CFBD5F70F22168&vd_source=939ea718db29535a3847d861e5fe37ef
ELK 解决取得问题
- 痛点1: ⽣产出现故障后,运维需要不停的查看各种不同的⽇志进⾏分析?是不是毫⽆头绪?
- 痛点2: 项⽬上线出现错误,如何快速定位问题?如果后端节点过多、⽇志分散怎么办?
- 痛点3: 开发⼈员需要实时查看⽇志但⼜不想给服务器的登陆权限,怎么办?难道每天帮开发取⽇志?
- 痛点4: 如何在海量的⽇志中快速的提取我们想要的数据?⽐如:PV、UV、TOP10的URL?如果分析的⽇志数据量⼤,那么势必会导致查询速度慢、难度增⼤,最终则会导致我们⽆法快速的获取到想要的指标。
- 痛点5: CDN公司需要不停的分析⽇志,那分析什么?主要分析命中率,为什么?因为我们给⽤户承诺的命中率是90%以上。如果没有达到90%,我们就要去分析数据为什么没有被命中、为什么没有被缓存下来。
- 痛点6: 近期某影视公司周五下午频繁出现被盗链的情况,导致异常流量突增2G有余,给公司带来了损失,那⼜该如何分析异常流量呢?
- 痛点7: 上百台Mysql实例的慢⽇志查询分析如何聚集?
- 痛点8: docker,K8S平台⽇志如何收集分析?
痛点N: …
如上所有的痛点都可以使⽤⽇志分析系统"Elastic Stack"解决,将运维所有的服务器⽇志,业务系统⽇志都收集到⼀个平台下,然后提取想要的内容,⽐如错误信息,警告信息等,当过滤到这种信息,就⻢上告警,告警后,运维⼈员就能⻢上定位是哪台机器、哪个业务系统出现了问题,出现了什么问
Elstic stack分布式⽇志系统概述

The Elastic Stack, 包括Elasticsearch、Kibana、Beats和Logstash(也称为 ELK
Stack)。
-
ElaticSearch:
简称为ES, ES是⼀个开源的⾼扩展的分布式全⽂搜索引擎,是整个Elastic Stack技术栈的核⼼。 它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。 -
Kibana:
是⼀个免费且开放的⽤户界⾯,能够让您对Elasticsearch数据进⾏可视化,并让您在
Elastic Stack中进⾏导航。 您可以进⾏各种操作,从跟踪查询负载,到理解请求如何流经您的整个应⽤,都能轻松完成。 -
Beats:
是⼀个免费且开放的平台,集合了多种单⼀⽤途数据采集器。
它们从成百上千或成千上万台机器和系统向Logstash 或 Elasticsearch发送数据。 -
Logstash:
是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Elastic Stack的主要优点有如下⼏个:
(1)处理⽅式灵活: elasticsearch是实时全⽂索引,具有强⼤的搜索功能。
(2)配置相对简单: elasticsearch全部使⽤JSON 接⼝,logstash使⽤模块配置,kibana的配置⽂件部分更简单。
(3)检索性能⾼效: 基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
(4)集群线性扩展: elasticsearch和logstash都可以灵活线性扩展。
(5)前端操作绚丽: kibana的前端设计⽐较绚丽,⽽且操作简单。
使⽤elastic stack能收集那些⽇志:
容器管理⼯具: docker
容器编排⼯具: docker swarm,Kubernetes
负载均衡服务器: lvs,haproxy,nginx
web服务器: httpd,nginx,tomcat
数据库: mysql,redis,MongoDB,Hbase,Kudu,ClickHouse,PostgreSQL
存储:nfs,gluterfs,fastdfs,HDFS,Ceph
系统: message,security
业务: 包括但不限于C,C++,Java,PHP,Go,Python,Shell等编程语⾔研发的App
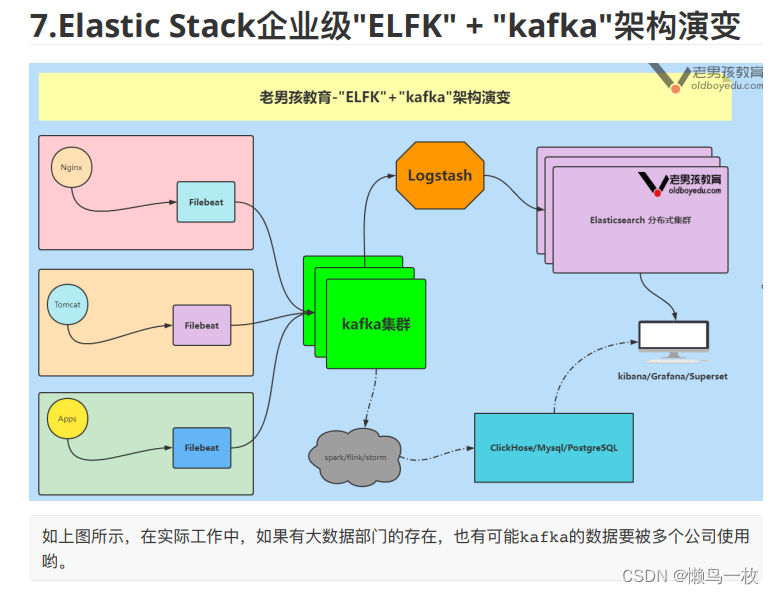
企业级架构图解
- 企业级"EFK"架构图解
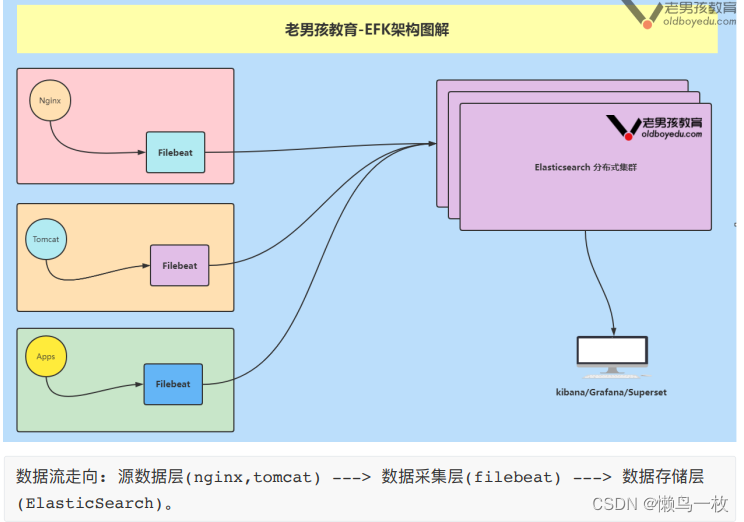
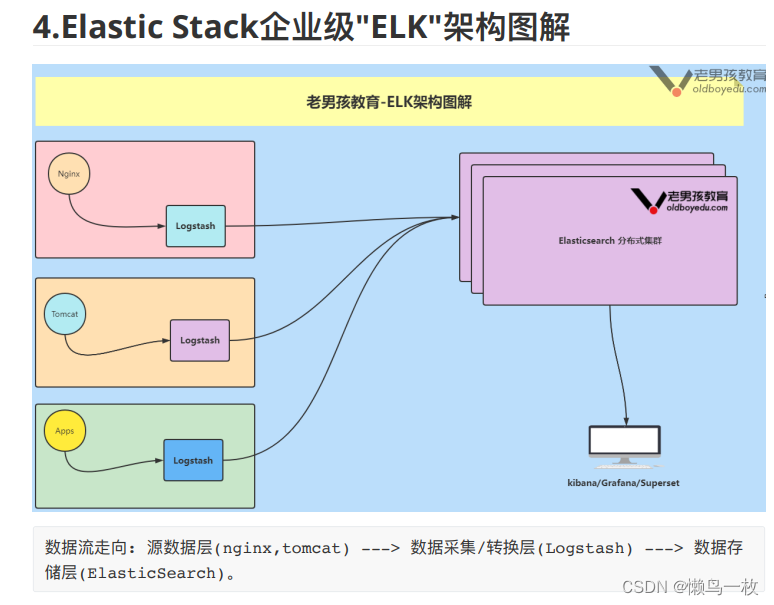
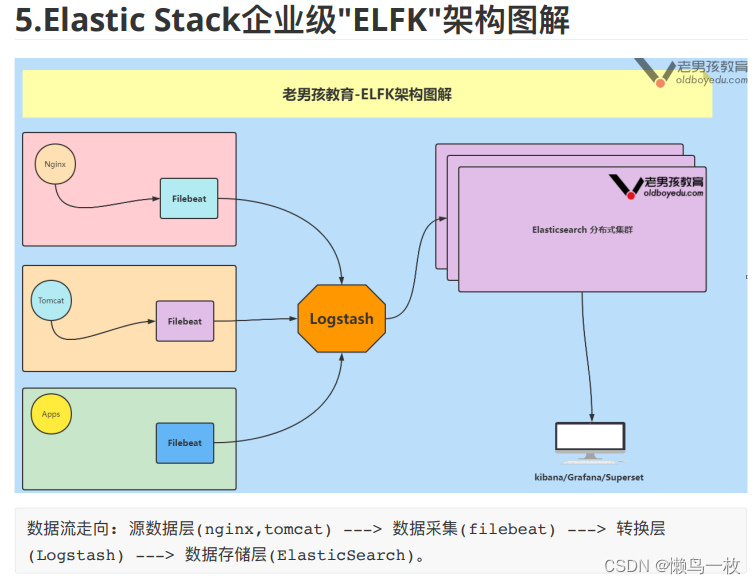
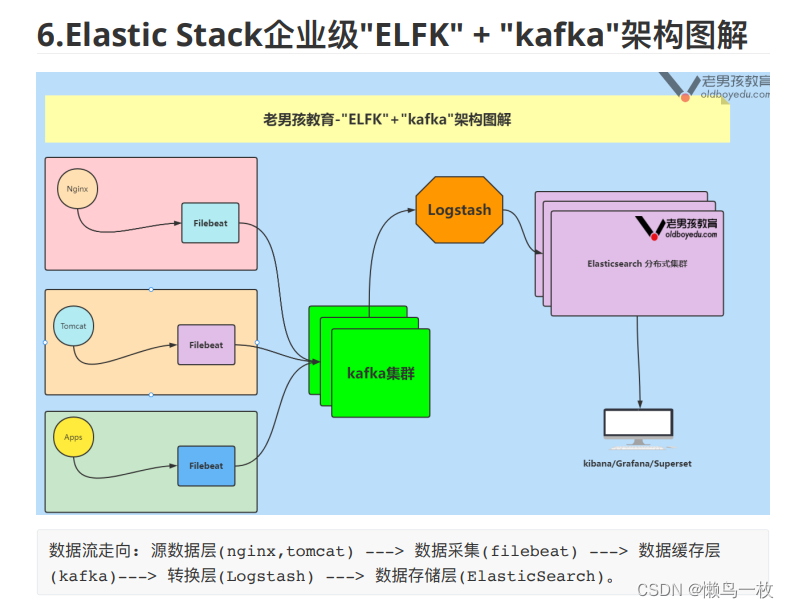
二、ElsticSearch 和 Solr的选择
ElsticSearc和Lucene的关系
Lucene的优缺点:
- 优点: 可以被认为是迄今为⽌最先进,性能最好的,功能最全的搜索引擎库(框架)。
- 缺点:
(1)只能在Java项⽬中使⽤,并且要以jar包的⽅式直接集成在项⽬中;
(2)使⽤很复杂,你需要深⼊了解检索的相关知识来创建索引和搜索索引代码;
(3)不⽀持集群环境,索引数据不同步(不⽀持⼤型项⽬);
(4)扩展性差,索引库和应⽤所在同⼀个服务器,当索引数据过⼤时,效率逐渐降低;
值得注意的是,上述的Lucene框架中的缺点,Elasticsearch全部都能解决ElasticSearch是⼀个实时的分布式搜索和分析引擎。它可以帮助你⽤前所未有的速度去处理⼤
ES可以⽤于全⽂搜索,结构化搜索以及分析,当然你也可以将这三者进⾏组合。
有哪些公司在使⽤ElasticSearch呢,全球⼏乎所有的⼤型互联⽹公司都在拥抱这个开源项⽬: https://www.elastic.co/cn/customers/success-stories
ElsticSearch 和 Solr的选择
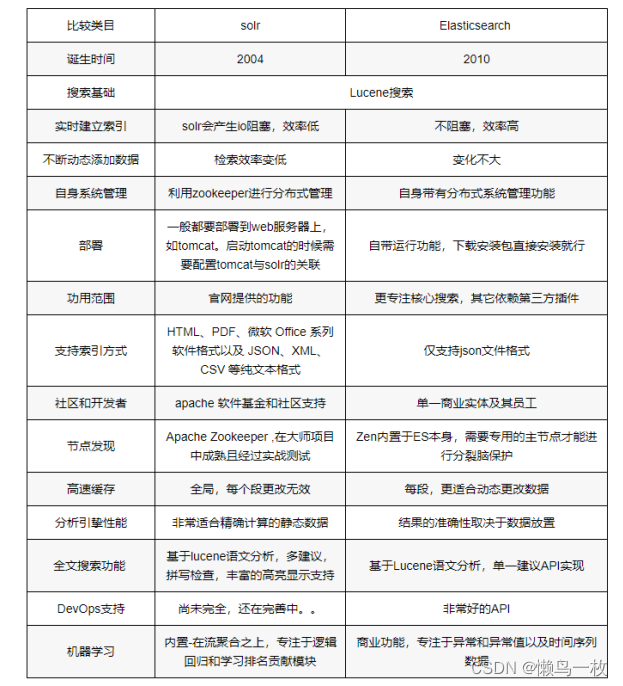
Solr是Apache Lucene项⽬的开源企业搜索平台。其主要功能包括全⽂检索、命中标示、分⾯搜索、动态聚类、数据库集成,以及富⽂本(如Word、PDF)的处理。
Solr是⾼度可扩展的,并提供了分布式搜索和索引复制。Solr是最流⾏的企业级搜索引擎,Solr4 还增加了NoSQL⽀持。
Elasticsearch(下⾯简称"ES")与Solr的⽐较:
(1)Solr利⽤Zookeeper进⾏分布式管理,⽽ES⾃身带有分布式协调管理功能;
(2)Solr⽀持更多格式(JSON、XML、CSV)的数据,⽽ES仅⽀持JSON⽂件格式;
(3)Solr官⽅提供的功能更多,⽽ES本身更注重于核⼼功能,⾼级功能多有第三⽅插件提供;
(4)Solr在"传统搜索"(已有数据)中表现好于ES,但在处理"实时搜索"(实时建⽴索引)应
⽤时效率明显低于ES。
(5)Solr是传统搜索应⽤的有⼒解决⽅案,但Elasticsearch更适⽤于新兴的实时搜索应
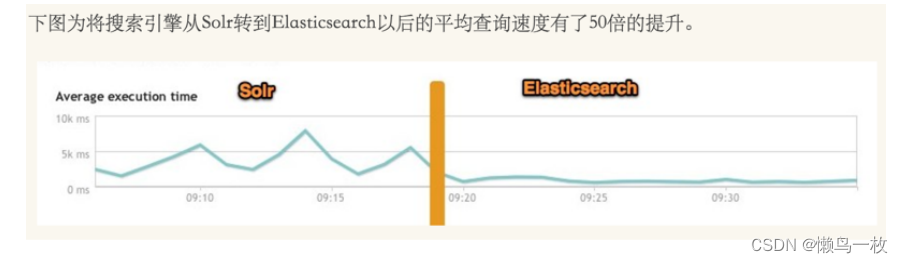
⽤。如下图所示,有⽹友在⽣产环境测试,将搜索引擎从Solr转到ElasticSearch以后的平均查询速度有了将近50倍的提升;
三、集群基础环境初始化
四、elasticsearch单点部署
参考链接: https://www.elastic.co/cn/downloads/elasticsearch
单点部署elasticsearch
(1)安装服务
yum -y localinstal elasticsearch-7.17.3-x86_64.rpm
(2)修改配置⽂件
egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml
cluster.name: oldboyedu-elk
node.name: oldboyedu-elk103
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.0.0.103
discovery.seed_hosts: ["10.0.0.103"]
相关参数说明:
cluster.name: 集群名称,若不指定,则默认是"elasticsearch",⽇志⽂件的前缀也是集群名称。
node.name: 指定节点的名称,可以⾃定义,推荐使⽤当前的主机名,要求集群唯⼀。
path.data: 数据路径。
path.logs: ⽇志路径
network.host: ES服务监听的IP地址
discovery.seed_hosts: 服务发现的主机列表,对于单点部署⽽⾔,主机列表和"network.host"字段配置相同即可
(3)启动服务
systemctl start elasticsearch.service
五、elasticsearch分布式集群部署
elk101 修改配置⽂件
egrep -v "^$|^#" /etc/elasticsearch/elasticsearch.yml
...
cluster.name: oldboyedu-elk
node.name: elk101
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["elk101","elk102","elk103"]
cluster.initial_master_nodes: ["elk101","elk102","elk103"]
温馨提示:
"node.name"各个节点配置要区分清楚,建议写对应的主机名称
2.同步配置⽂件到集群的其他节点
(1)elk101同步配置⽂件到集群的其他节点
data_rsync.sh /etc/elasticsearch/elasticsearch.yml
(2)elk102节点配置
vim /etc/elasticsearch/elasticsearch.yml
...
node.name: elk102
(3)elk103节点配置
vim /etc/elasticsearch/elasticsearch.yml
...
node.name: elk103
3.删除所有节点删除之前的临时数据
pkill java
rm -rf /var/{lib,log}/elasticsearch/* /tmp/*
ll /var/{lib,log}/elasticsearch/ /tmp/
4.启动所有节点启动服务
(1)所有节点启动服务
systemctl start elasticsearch
(2)启动过程中建议查看⽇志
tail -100f /var/log/elasticsearch/oldboyedu-elk.log
5.验证集群是否正常
curl elk103:9200/_cat/nodes?v

六、部署kibana服务
- 部署kibana服务
yum -y localinstall kibana-7.17.3-x86_64.rpm
- kibana的配置⽂件
vim /etc/kibana/kibana.yml
...
server.host: "10.0.0.101"
server.name: "oldboyedu-kibana-server"
elasticsearch.hosts:
["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:92
00"]
i18n.locale: "zh-CN"
- 启动kibana服务
systemctl enable --now kibana
systemctl status kibana
4.访问kibana的webUI
systemctl enable --now kibana
systemctl status kibana
七、 FileBeat部署及基础使用
1. 部署FileBeat环境
yum -y localinstall filebeat-7.17.3-x86_64.rpm
2. 修改FileBeat的配置⽂件
(1)编写测试的配置⽂件
mkdir /etc/filebeat/config
cat > /etc/filebeat/config/01-stdin-to-console.yml <<'EOF'
# 指定输⼊的类型
filebeat.inputs:
# 指定输⼊的类型为"stdin",表示标准输⼊
- type: stdin
# 指定输出的类型
output.console:
# 打印漂亮的格式
pretty: true
EOF
(2)运⾏filebeat实例
filebeat -e -c /etc/filebeat/config/01-stdin-to-console.yml
(3)测试
⻅视频。
3. input的log类型
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
output.console:
pretty: true
4. input 的通配符案例
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
- /tmp/*.txt
output.console:
pretty: true
5. input 的通⽤字段案例
filebeat.inputs:
- type: log
# 是否启动当前的输⼊类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输⼊类型搭上标签
tags: ["oldboyedu-linux80","容器运维","DBA运维","SRE运维⼯程师"]
# ⾃定义字段
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python","云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
# 将⾃定义字段的key-value放到顶级字段.
# 默认值为false,会将数据放在⼀个叫"fields"字段的下⾯.
fields_under_root: true
output.console:
pretty: true
6. ⽇志过滤案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test/*.log
# 注意,⿊⽩名单均⽀持通配符,⽣产环节中不建议同时使⽤,
# 指定⽩名单,包含指定的内容才会采集,且区分⼤⼩写!
include_lines: ['^ERR', '^WARN','oldboyedu']
# 指定⿊名单,排除指定的内容
exclude_lines: ['^DBG',"linux","oldboyedu"]
output.console:
pretty: true
7. 将数据写入ES
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80","容器运维","DBA运维","SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python","云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
hosts:
["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:92
00"]
8.自⾃定义ES索引名称
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80","容器运维","DBA运维","SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python","云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
enabled: true
hosts:
["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:92
00"]
index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
# 禁⽤索引⽣命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "oldboyedu-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "oldboyedu-linux*"
9.多个索引写⼊案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80","容器运维","DBA运维","SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python","云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
enabled: true
hosts:
["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:92
00"]
# index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
# 匹配指定字段包含的内容
when.contains:
tags: "oldboyedu-linux80"
- index: "oldboyedu-linux-python-%{+yyyy.MM.dd}"
when.contains:
tags: "oldboyedu-python"
# 禁⽤索引⽣命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "oldboyedu-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "oldboyedu-linux*"
10.⾃定义分⽚和副本案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80","容器运维","DBA运维","SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python","云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
enabled: true
hosts:
["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:92
00"]
# index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
# 匹配指定字段包含的内容
when.contains:
tags: "oldboyedu-linux80"
- index: "oldboyedu-linux-python-%{+yyyy.MM.dd}"
when.contains:
tags: "oldboyedu-python"
# 禁⽤索引⽣命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "oldboyedu-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "oldboyedu-linux*"
# 覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板
setup.template.settings:
# 设置分⽚数量
index.number_of_shards: 3
# 设置副本数量,要求⼩于集群的数量
index.number_of_replicas: 2
11. fileBeat实现⽇志聚合到本地
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.file:
path: "/tmp/filebeat"
filename: oldboyedu-linux80
# 指定⽂件的滚动⼤⼩,默认值为20MB
rotate_every_kb: 102400
# 指定保存的⽂件个数,默认是7个,有效值为2-1024个
number_of_files: 300
# 指定⽂件的权限,默认权限是0600
permissions: 0600
12. fileBeat实现⽇志聚合到ES集群
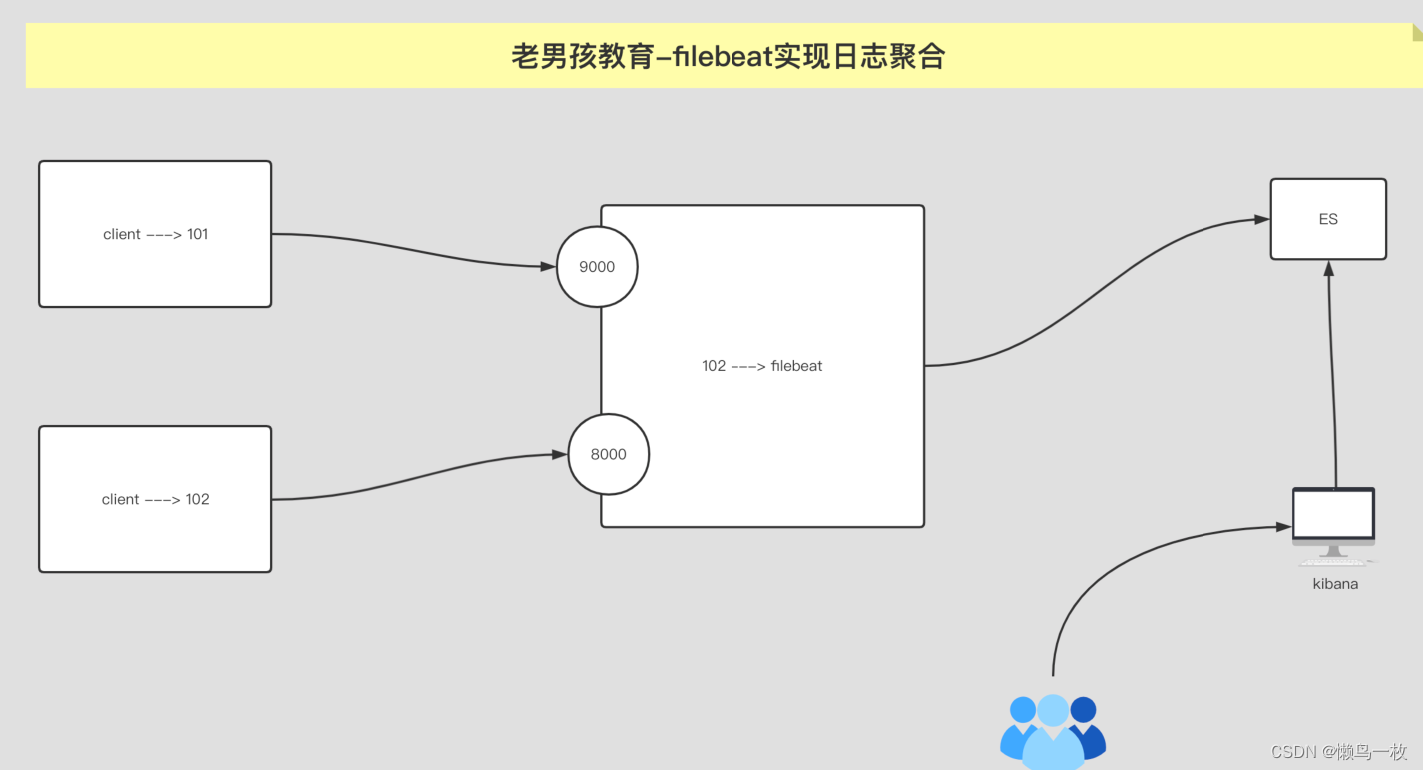
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
tags: ["aaa"]
- type: tcp
host: "0.0.0.0:8000"
tags: ["bbb"]
output.elasticsearch:
enabled: true
hosts:
["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:92
00"]
indices:
- index: "oldboyedu-linux80-elk-aaa-%{+yyyy.MM.dd}"
when.contains:
tags: "aaa"
- index: "oldboyedu-linux80-elk-bbb-%{+yyyy.MM.dd}"
when.contains:
tags: "bbb"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-linux80-elk"
setup.template.pattern: "oldboyedu-linux80-elk*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 0