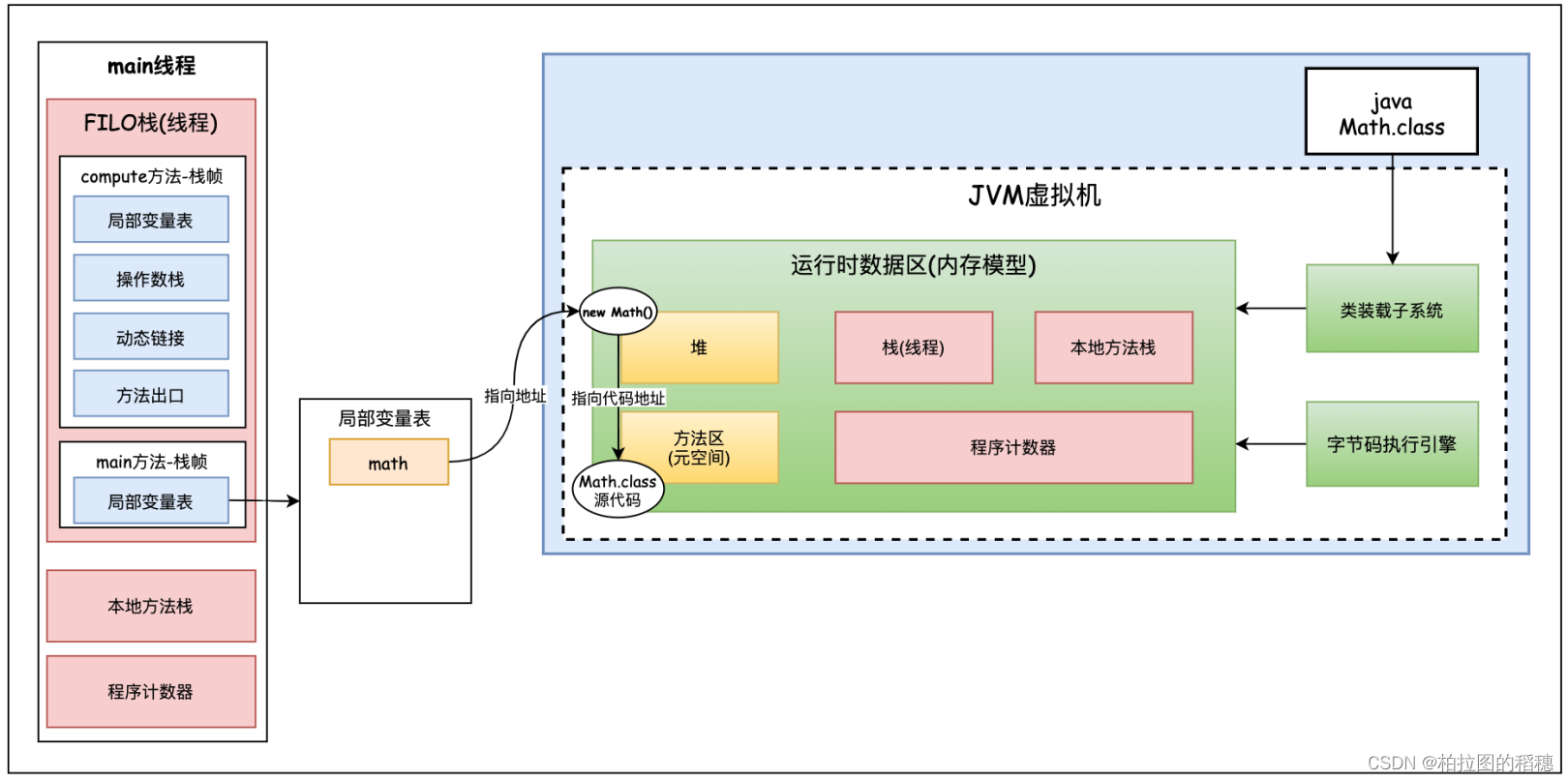
public static void main(String[] args) {
Math math = new Math();
math.compute();
}对于Math类来说,他还有一个类对象, 如下代码所示:
Class<? extends Math> mathClass = math.getClass();这个类对象是存储在哪里的呢?这个类对象是方法区中的元数据对象么?不是的。这个类对象实际上是jvm虚拟机在堆中创建的一块和方法区中源代码相似的信息。如下图堆空间右上角。
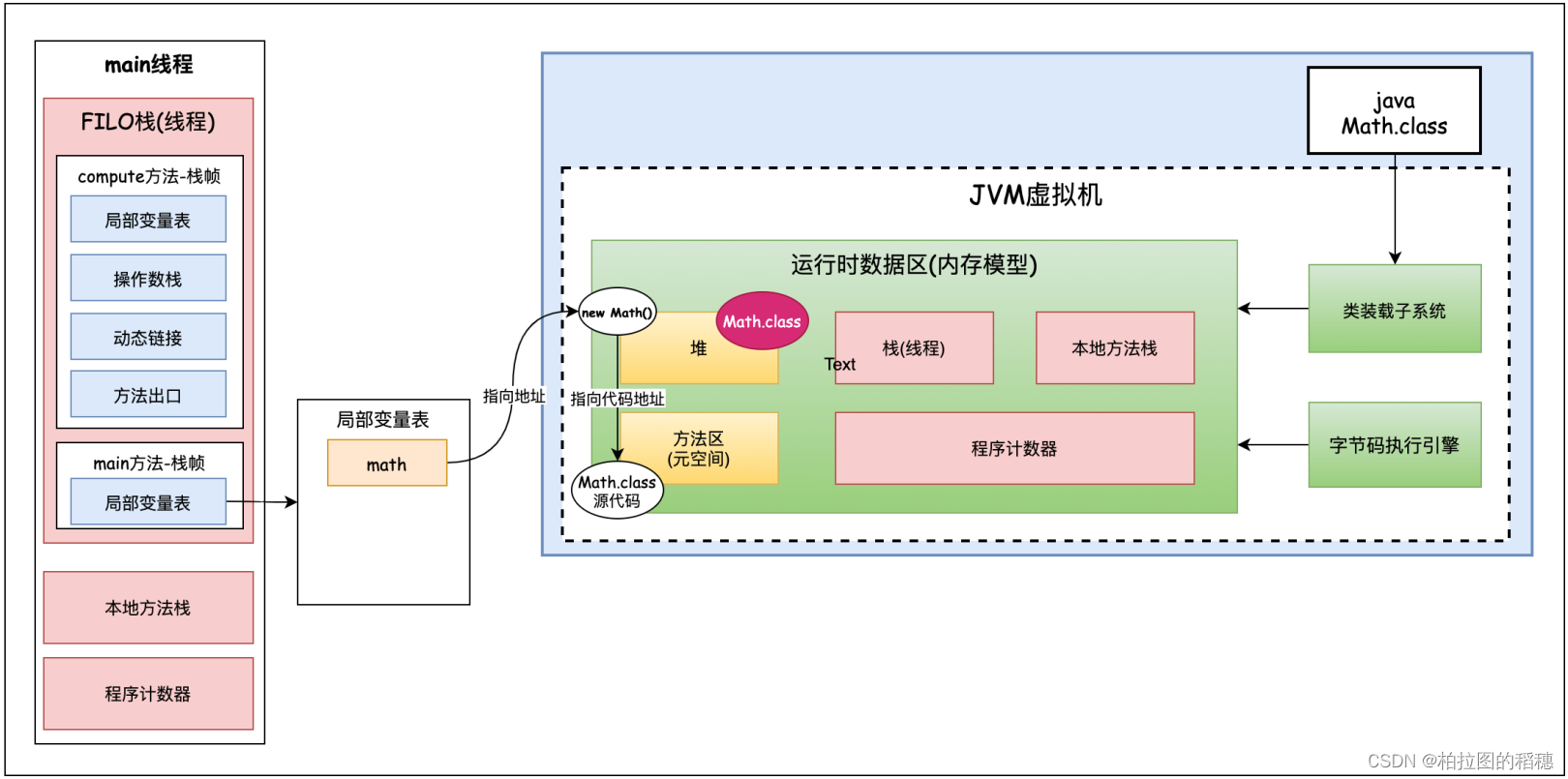
堆中的类对象和在方法区中的类元对象有什么区别呢?
类的元数据信息是放在方法区的。堆中的类信息,可以理解为是类装载后jvm给java开发人员提供的方便的访问类的信息。
通过类的反射我们知道,我们可以通过Math的class拿到这个类的名称,方法,属性,继承关系,接口等等。我们知道jvm的大部分实现是通过c++实现的,jvm在拿到Math类的时候,他不会通过堆中的类信息(上图堆右上角math类信息)拿到,而是直接通过类型指针找到方法区中元数据实现的,这块类型指针也是c++实现的。在方法区中的类元数据信息都是c++获取实现的。
而我们java开发人员要想获得类元数据信息是通过堆中的类信息获得的,堆中的class类是不会存储元数据信息的。我们可以把堆中的类信息理解为是方法区中类元数据信息的一个镜像。
Klass Pointer类型指针的含义:Klass不是class,class pointer是类的指针;而Klass Pointer指的是底层c++对应的类的指针
JVM大对象(直接在老年代分配)定义
- 大对象到底多大:
-XX:PreTenureSizeThreshold=n(仅适用于DefNew/ParNew新生代垃圾回收器 ) G1回收器的大对象判断,则依据Region的大小(-XX:G1HeapRegionSize)来判断,如果对象大于Region50%以上,就判断为大对象Humongous Object。
TLAB 分配
TLAB,全称Thread Local Allocation Buffer, 即:线程本地分配缓存。这是一块线程专用的内存分配区域。TLAB占用的是eden区的空间。在TLAB启用的情况下(默认开启),JVM会为每一个线程分配一块TLAB区域。
为什么需要TLAB?
这是为了加速对象的分配。
由于对象一般分配在堆上,而堆是线程共用的,因此可能会有多个线程在堆上申请空间,而每一次的对象分配都必须线程同步,会使分配的效率下降。
考虑到对象分配几乎是Java中最常用的操作,因此JVM使用了TLAB这样的线程专有区域来避免多线程冲突,提高对象分配的效率。
- 局限性: TLAB空间一般不会太大(占用eden区),所以大对象无法进行
TLAB分配,只能直接分配到堆Heap上。
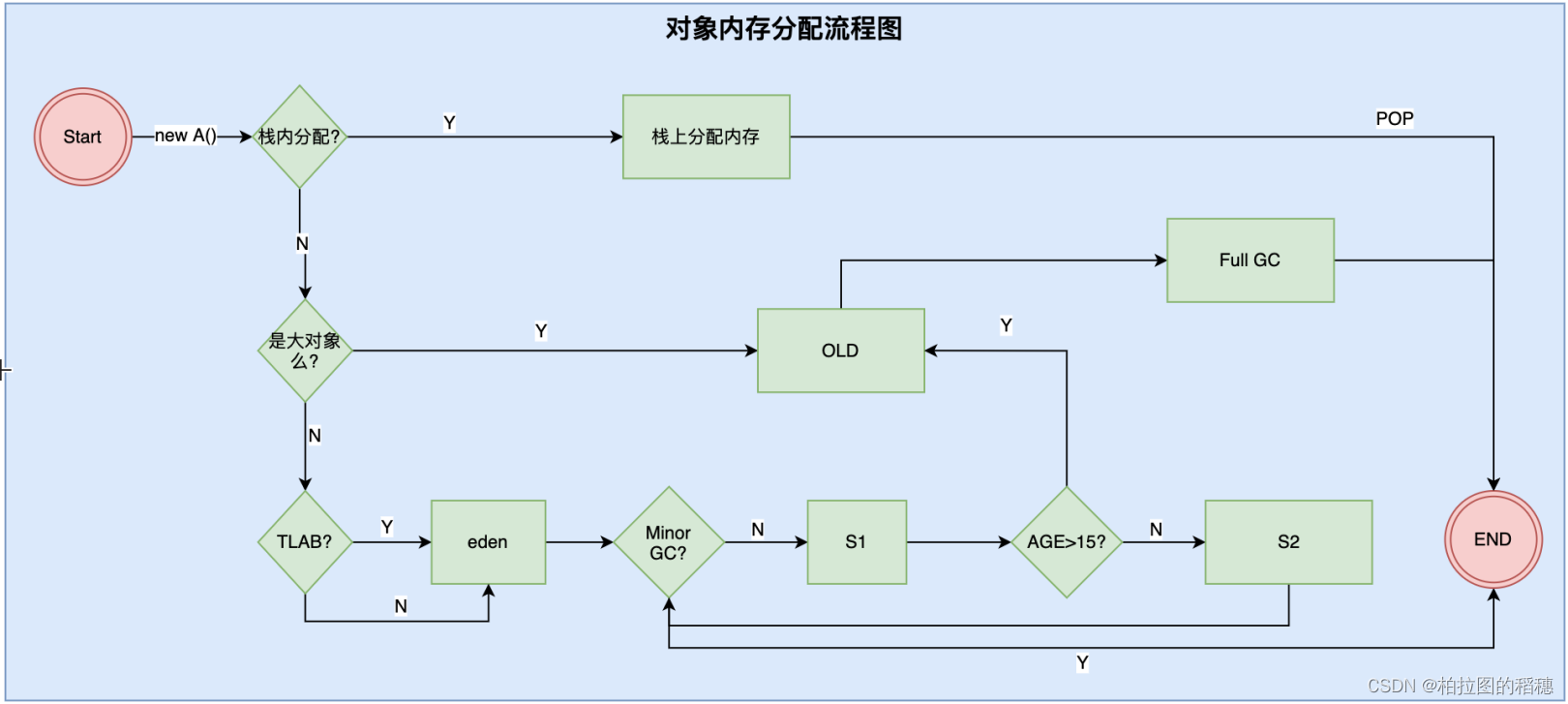
什么是逃逸
判断一个对象是否是逃逸对象,就看这个对象能否被外部对象访问到。
public class Test {
public User test1() {
User user = new User();
user.setId(1);
user.setName("张三");
return user;
}
public void test2() {
User user = new User();
user.setId(2);
user.setName("李四");
}
}Test里有两个方法,test1()方法构建了user对象,并且返回了user,返回回去的对象肯定是要被外部使用的。这种情况就是user对象逃逸出了test1()方法。
而test2()方法也是构建了user对象,但是这个对象仅仅是在test2()方法的内部有效,不会在方法外部使用,这种就是user对象没有逃逸。
逃逸分析
定义:逃逸分析(Escape Analysis)简单来讲就是,Java Hotspot 虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术。
就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为参数传递到其他地方中。
逃逸分析的 JVM 参数如下:
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
逃逸分析技术在 Java SE 6u23+ 开始支持,并默认设置为启用状态,可以不用额外加这个参数。
逃逸分析优化
针对上面第三点,当一个对象没有逃逸时,可以得到以下几个虚拟机的优化。
1) 锁消除
我们知道线程同步锁是非常牺牲性能的,当编译器确定当前对象只有当前线程使用,那么就会移除该对象的同步锁。
例如,StringBuffer 和 Vector 都是用 synchronized 修饰线程安全的,但大部分情况下,它们都只是在当前线程中用到,这样编译器就会优化移除掉这些锁操作。
锁消除的 JVM 参数如下:
- 开启锁消除:
-XX:+EliminateLocks - 关闭锁消除:
-XX:-EliminateLocks
锁消除在 JDK8 中都是默认开启的,并且锁消除都要建立在逃逸分析的基础上。
2) 标量替换
首先要明白标量和聚合量,基础类型和对象的引用可以理解为标量,它们不能被进一步分解。而能被进一步分解的量就是聚合量,比如:对象。
对象是聚合量,它又可以被进一步分解成标量,将其成员变量分解为分散的变量,这就叫做标量替换。这样,如果一个对象没有发生逃逸,那压根就不用创建它,只会在栈或者寄存器上创建它用到的成员标量,节省了内存空间,也提升了应用程序性能。
标量替换的 JVM 参数如下:
- 开启标量替换:
-XX:+EliminateAllocations - 关闭标量替换:
-XX:-EliminateAllocations - 显示标量替换详情:
-XX:+PrintEliminateAllocations
标量替换同样在 JDK8 中都是默认开启的,并且都要建立在逃逸分析的基础上。
3) 栈上分配
当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能。
为什么要分配在栈上?
通过JVM内存模型中,我们知道Java的对象都是分配在堆上的。当堆空间(新生代或者老年代)快满的时候,会触发GC,没有被任何其他对象引用的对象将被回收。如果堆上出现大量这样的垃圾对象,将会频繁的触发GC,影响应用的性能。(分配在堆上,频繁GC,影响效率)
其实这些对象都是临时产生的对象,如果能够减少这样的对象进入堆的概率,那么就可以成功减少触发GC的次数了。我们可以把这样的对象放在堆上,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力(分配在栈上,随着栈帧销毁,不用垃圾回收,提高效率)。
什么情况下会分配在栈上?
为了减少临时对象在堆内分配的数量,JVM通过逃逸分析确定该对象会不会被外部访问。如果不会逃逸可以将该对象在栈上分配内存。随栈帧出栈而销毁,减轻GC的压力。
参考文献:
JVM 对象分配过程 - 掘金
8.JVM内存分配机制超详细解析 - 腾讯云开发者社区-腾讯云
原创|面试官:Java对象一定分配在堆上吗? - 腾讯云开发者社区-腾讯云
Java中的对象都是在堆上分配的吗? - 腾讯云开发者社区-腾讯云
面试问我 Java 逃逸分析,瞬间被秒杀了。。