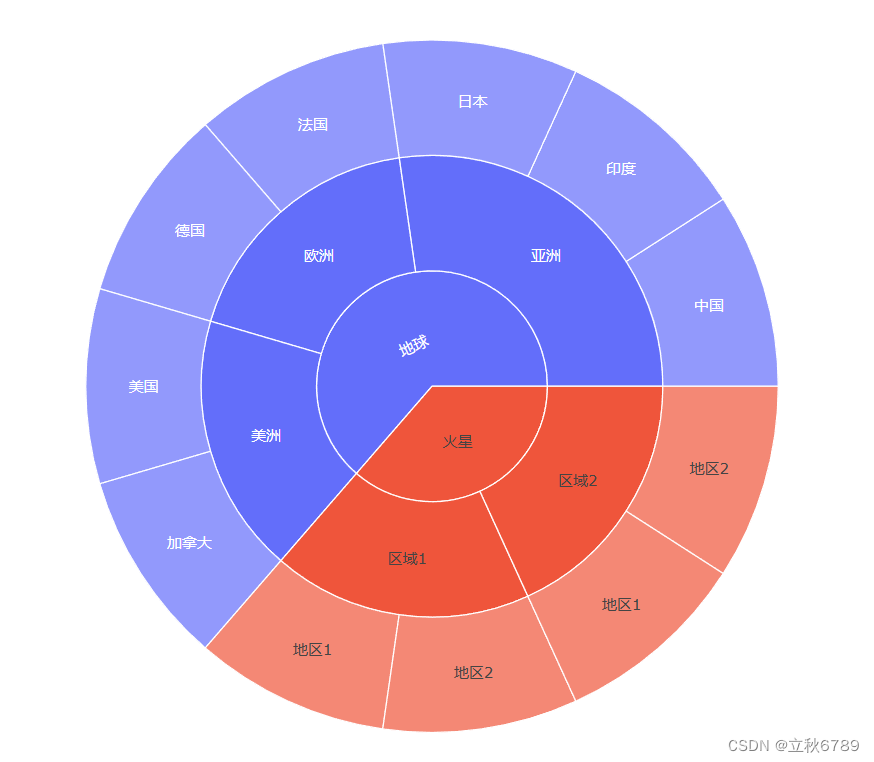
第一周学习周报
- 摘要
- 一、机器学习基础理论
- 1. 什么是机器学习?
- 2. 机器学习“寻找”的函数有哪些类型?
- 3. 机器学习中机器如何“寻找”函数?三步走
- 3.1 第一步:设定函数的未知量(Function with Unknown Parameters)
- 3.2 第二步:从训练集定义损失函数(Define Loss from Training Data)
- 3.3 第三步:最佳化(Optimization),确定最佳的未知数值
- 4. 总结以及模型优化问题
- 二、 深度学习
- 1. 线性模型的劣势
- 2. 全分段线性曲线(all piecewise linear curve)
- 2.1 sigmoid函数
- 2.1.1 用线性代数去理解复杂的模型的三步走
- 2.2 ReLu函数
- 2.3 深度学习的本质
- 2.4 深度学习的过拟合现象(overfitting)
- 3. 深度学习的三步骤
- 3.1 第一步:定义一组函数(define a set of function)
- 3.1.1 neural network(神经网络)
- 3.1.2 neural networkfully connected feedforward network(全连接前馈神经网络)
- 3.1.3 Matrix Operation(矩阵运算)
- 3.2 第二步:模型评估(goodness of function)
- 3.3 第三步:选择最优函数(Pick the best function)
- 三、PyTorch 学习
- 1. PyTorch环境配置
- 2. PyTorch学习的两大重要法宝
- 3. PyCharm及Jupyter使用以及区别
摘要
这周主要学习了机器学习的一些基础知识,比如:机器的基本概念、training三步骤,并在最后进行了总结。此外,还学习了深度学习的知识,了解了sigmoid函数和ReLU函数这两个重要的激活函数,并且学习了深度学习的三个步骤。最后观看视频完成了pytorch的环境配置,并了解到了dir()与help()这两个对pytorch学习最为重要的函数。
一、机器学习基础理论
1. 什么是机器学习?
machine learning ≈ looking for a function
机器学习实际上并没有我们想象中的那么复杂,其实际上就是寻找一个函数输入的过程。
在我们学习数学的过程中所接触到的函数,一般都是可以通过人为的推导出来的。但是我们的世界是多样的,很多函数单凭我们人类有限的脑力是无法推导出来的。

如上图中,我们给出一段语音可以推断出语音的内容,在这个构造的函数中,语音作为函数输入的变量,“how are you”就是输出的结果,以及下面的图像识别,围棋落子等举例,显然我们想通过人为去推导这样一个函数,是几乎不可能的,因此我们需要借助计算机高性能的算力来帮助我们寻找一个合适的函数去解决我们实际的问题,这就是机器学习的通俗理解。
2. 机器学习“寻找”的函数有哪些类型?
承接上文所提到的机器学习中“寻找”到的函数,对于这个函数肯定是多种多样的,那在我们的学习研究中,怎么判别这个函数的功能以及作用呢?于是我们就对机器学习进行了分类
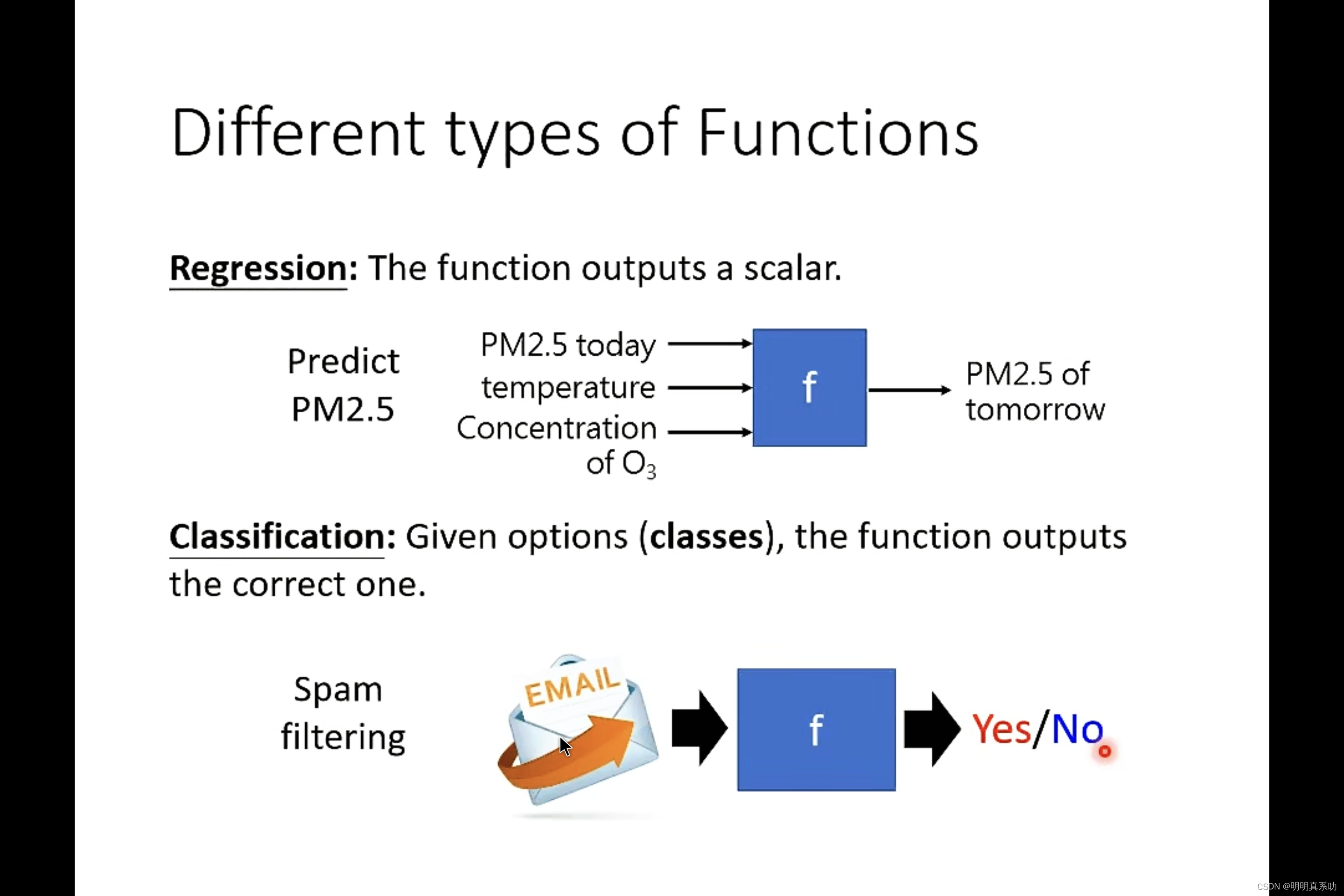
如上图,我们通常将函数分为以下几类:
1、回归
回归类函数可以用多种数据作为输入的参数,最后输出一个结果。
例如想要预测明天的PM2.5是多少,一般我们可以通过结合今日的PM2.5、温度、和臭氧浓度作为输入参数,经过函数处理后得出。
2、分类
分类类型函数一般是用于给定一个判别选择类型的输入函数,然后给到正确或者最佳的结果
例如给定一封电子邮件,让其判断是否为垃圾邮件。或者给定一个围棋局面,推出下一个落子的最佳位置(需要在19*19的选择里做出最优解)
3、structured learning
当然,上述只是常见的情况。正如我们人类一样,只是茫茫宇宙中的沧海一粟,Regression和Classification只是机器学习函数中的一小部分,还有一个很常见的类别就是结构化学习函数
其负责创建一些结构,例如图片和文件等

3. 机器学习中机器如何“寻找”函数?三步走
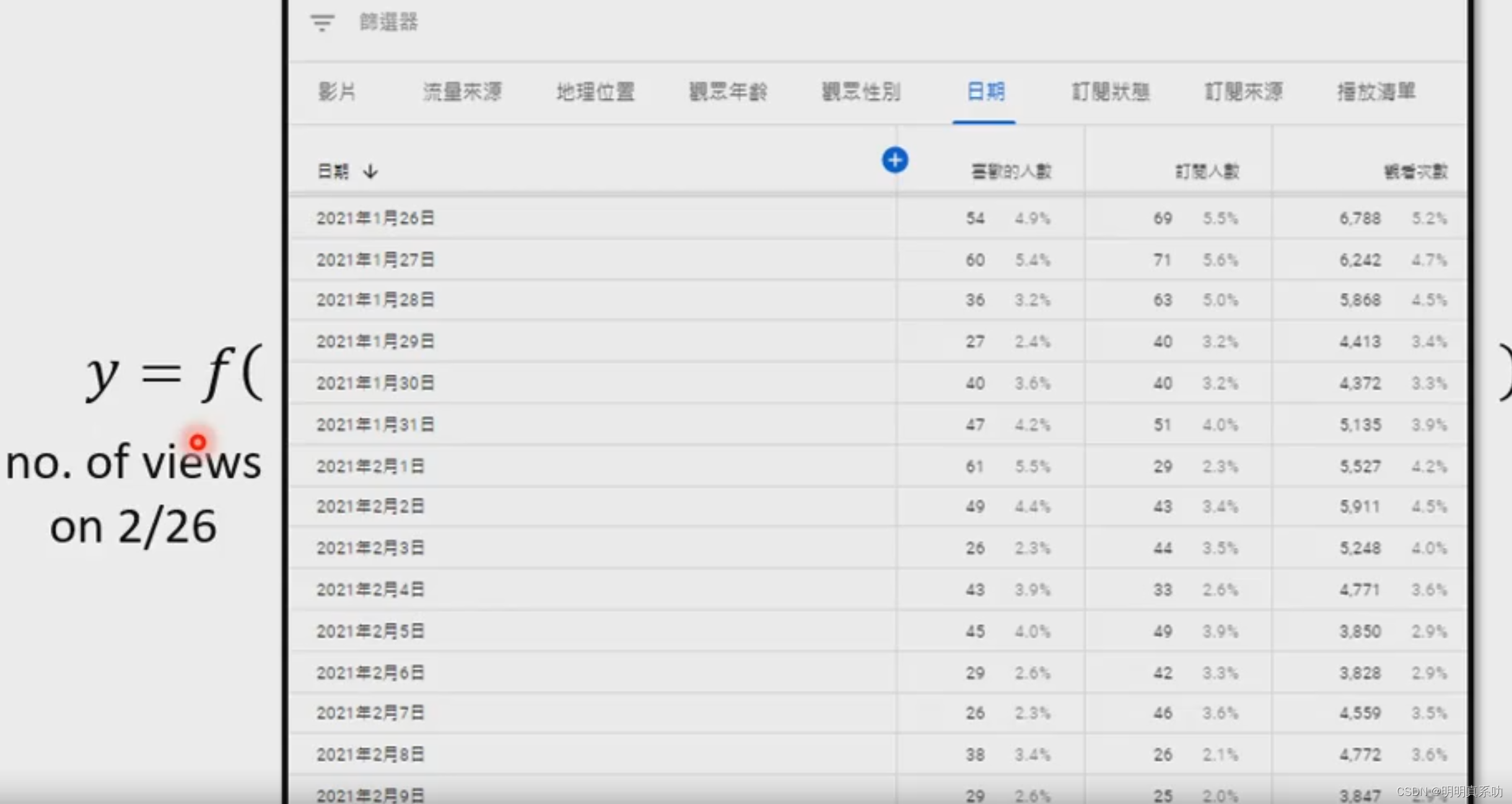
假设我们是一个网络博主,为了我的视频效益,我肯定需要关注我视频的关注度。所以需求是通过机器学习寻找到这样一个函数,帮助我实现预测我明天视频的观看人数,帮助我更好的找到自己视频的定位。
基于这个背景,我们就可以提前得知,视频的观看量怎么说都是跟前一天或者前几天的订阅数有关系,所以我们可以把这些作为我们这个函数的输入。
那么我们如何找出这个函数呢?
分为以下三步
3.1 第一步:设定函数的未知量(Function with Unknown Parameters)
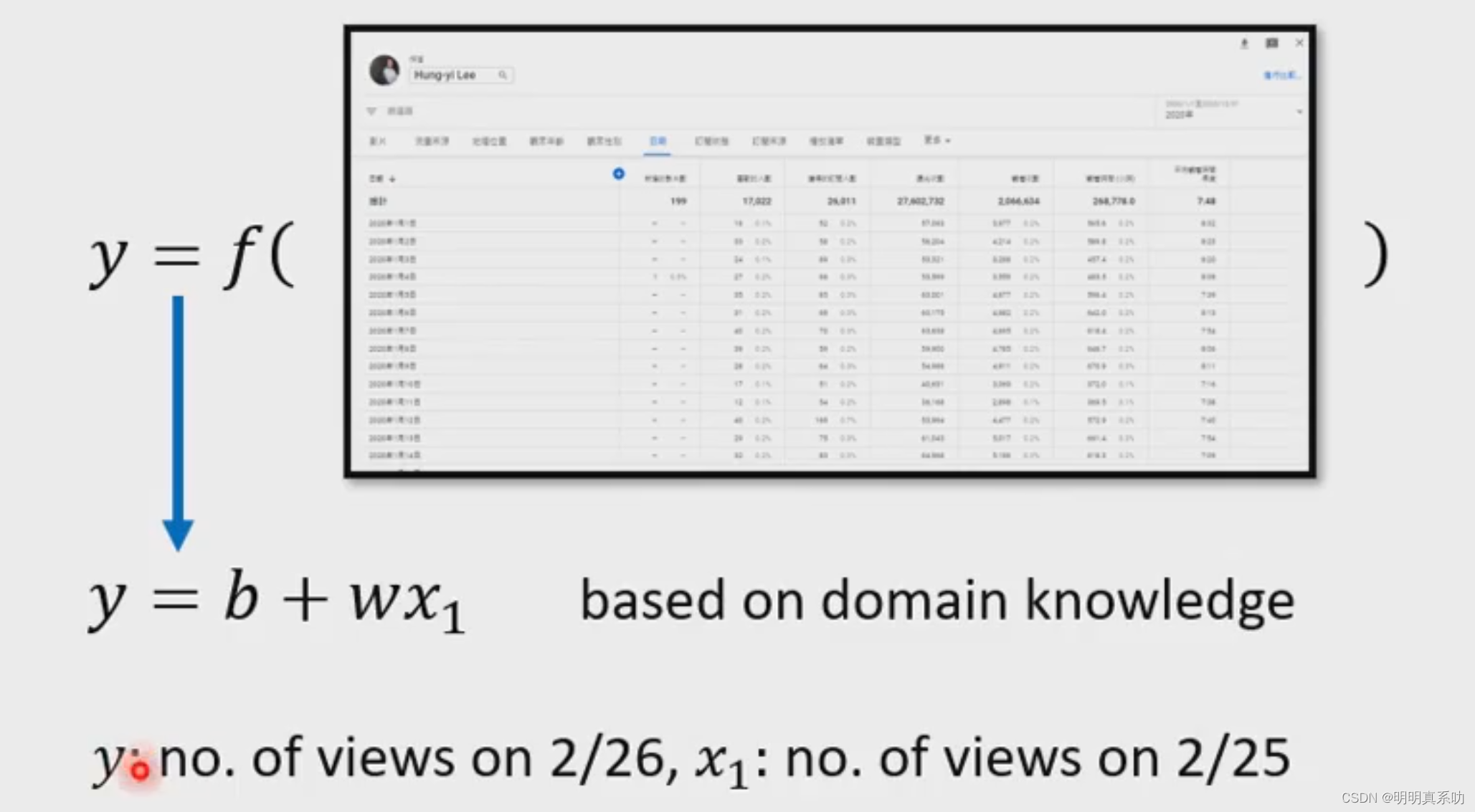
为了方便理解,我们可以把上述函数假定为y = b + w*x₁,一个线性的函数,称之为一个Model(带有未知数的方程)
假设我们用2.25日的订阅量作为输入,需要输出2.26的订阅量
那么函数各个变量的意义:
- x₁:作为输入结果,表示2.25日的观看人数,称之为feature(特征,一般是方程已知的的参数)。
- y:作为输出的结果,表示2.26日的观看人数。
- b与w:作为我们假设这个函数的未知量,称之为domain knowledge(领域知识,用于解析b和w这些未知数)。w称为weight(权重),b称之为bias(可以理解为斜率)
那么为什么方程要设定为这样呢?
视频的观看量怎么说都是跟前一天或者前几天的观看人数有关
所以我们这个函数的x₁作为输入,再乘上一个未知数w。
但是这不一定是倍数关系,所以我们加一个未知数b作为调整,这是大致的思路。
3.2 第二步:从训练集定义损失函数(Define Loss from Training Data)
何为损失函数?
损失函数,用来衡量误差大小函数。其作用简单明了来说就是帮助我们找到最佳的未知数的值,其用我们上面的未知数(b与w)作为输入,即为L(w,b),L越小证明数值越佳。

损失函数如何确定最佳值?
我们的第二步标题所说,要从训练集中定义我们最佳的损失函数,就比如我们的猜测一个东西,只有足够多的提示我们猜的结果才能尽可能准确,因此我们需要大量的训练集(也就是所谓的提示数据)来帮助我们确定未知数的最佳值。
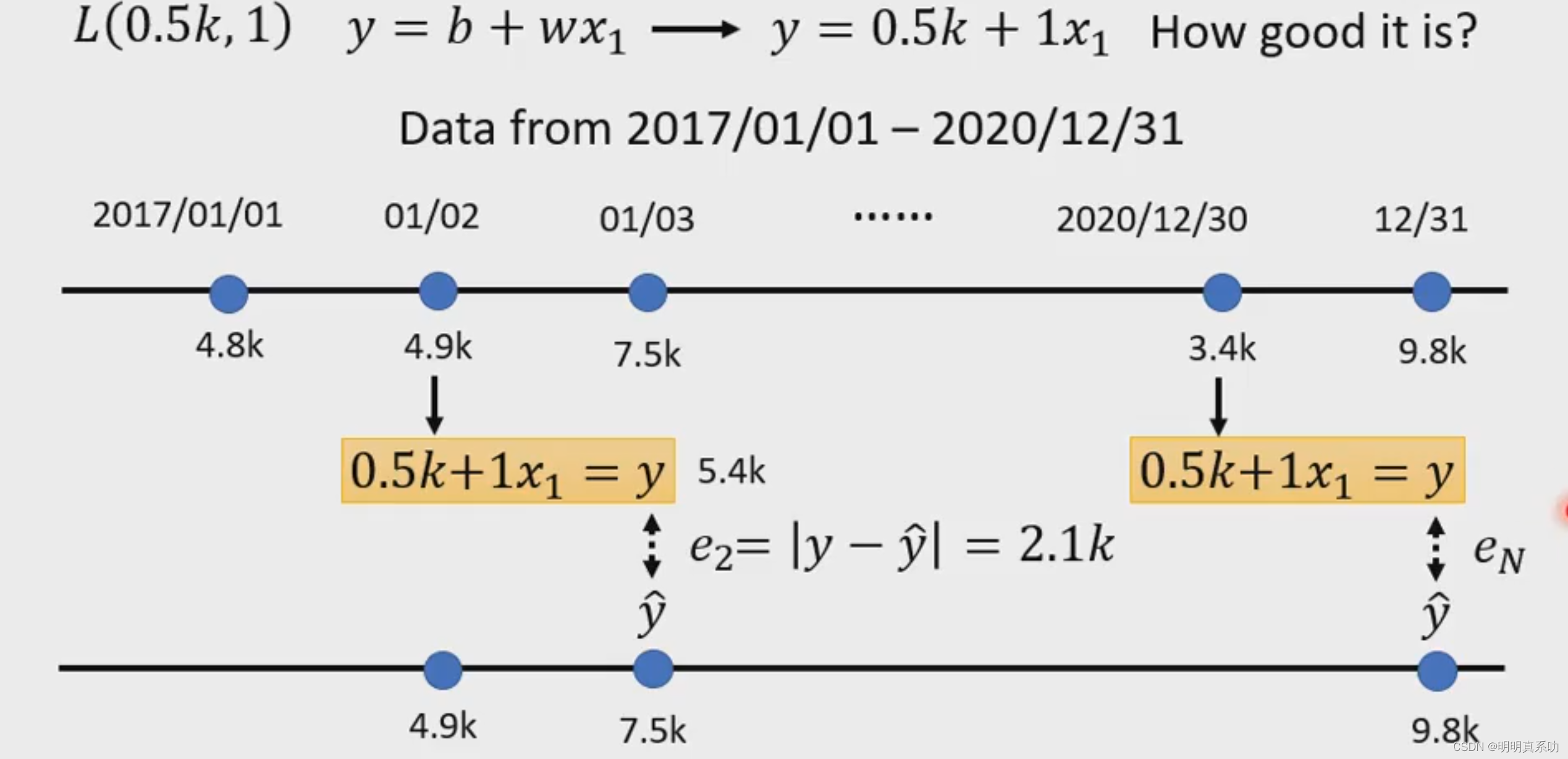
如上图所示,我们有3年来的数据(从2017.1.1-2020.12.31的训练集),作为训练参考。
我们假设w为1,b为0.5k。
那么我们想要以2017.1.2日的数据为参考,预测2017.1.3日的数据,我们就可以套公式得2017.1.3日的预测值为5.4k,但是我们实际值ŷ(称之为lable)为7.5k,很显然预测值与实际值存在的| 5.4 - 7.5 | = 2.1k的绝对值误差,我们标记为e₁。

如上图所示,我们以此类推可以算出,e₂、e₃…en。我们再通过对这些e₁到en求和,除以365*3(三年每天的数据),就可以得到一个平均的误差,这个就是我们的Loss(当然这是我们定义的Loss)。
此外,我们定义e可以使用绝对值误差(MAE),还可以使用平方差(MSE) 但不止这两种,具体按照场景使用。
结合上面所说的,我们得到了L(b,w)的图像,w作为横坐标、b为纵坐标,这个图像称之为Error Surface(误差曲面)
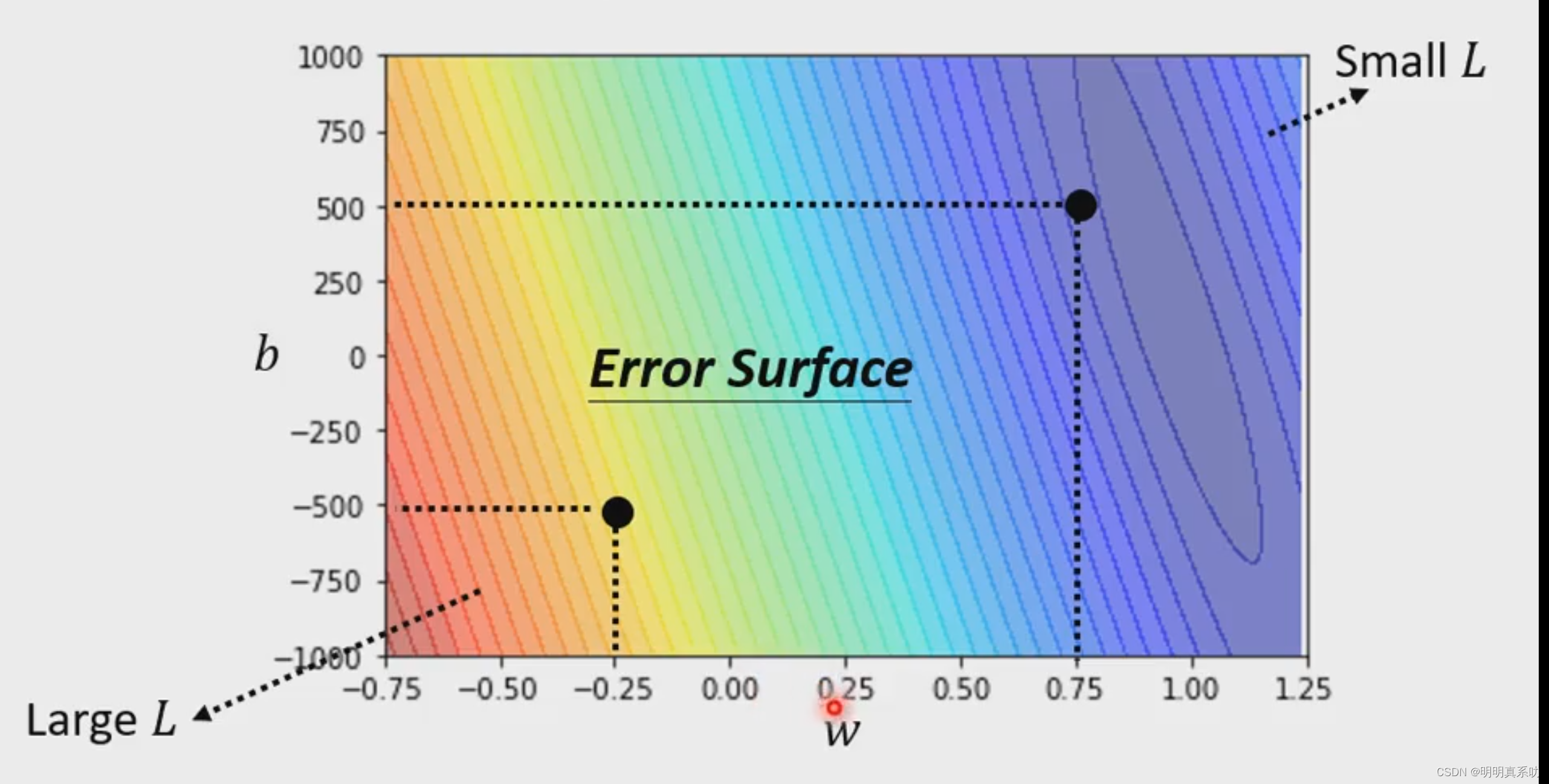
在这个曲面中,我们可以看出最大的L值和最小的L值,然后挑选出最佳的b和w值。
3.3 第三步:最佳化(Optimization),确定最佳的未知数值
上面两个步骤中,我们设定了未知数和损失函数,但是最后我们的目的是找到最佳的未知值代入Model中给我们预测,所以第三步我们需要把这个未知值找出来,我们记为最佳的未知数为w与b,就是带入进L (b,w)中使得平均的L最小。
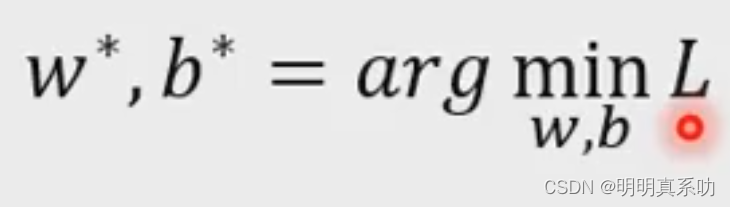
那么我们如何寻找呢?
在学高等数学的时候,我们学习过一个东西叫做导数,其表现在图像上就是斜率。斜率可以反映函数的趋势(递增递减),既然有两个未知数,我们就可以导数的概念找到L的最小值。
如果我们学习过高数,就会学到一个梯度的概念(梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)),而这里的gradient descent(梯度下降),就是往反方向找到最小值的。
为了方便理解,我们暂时以偏导来理解。
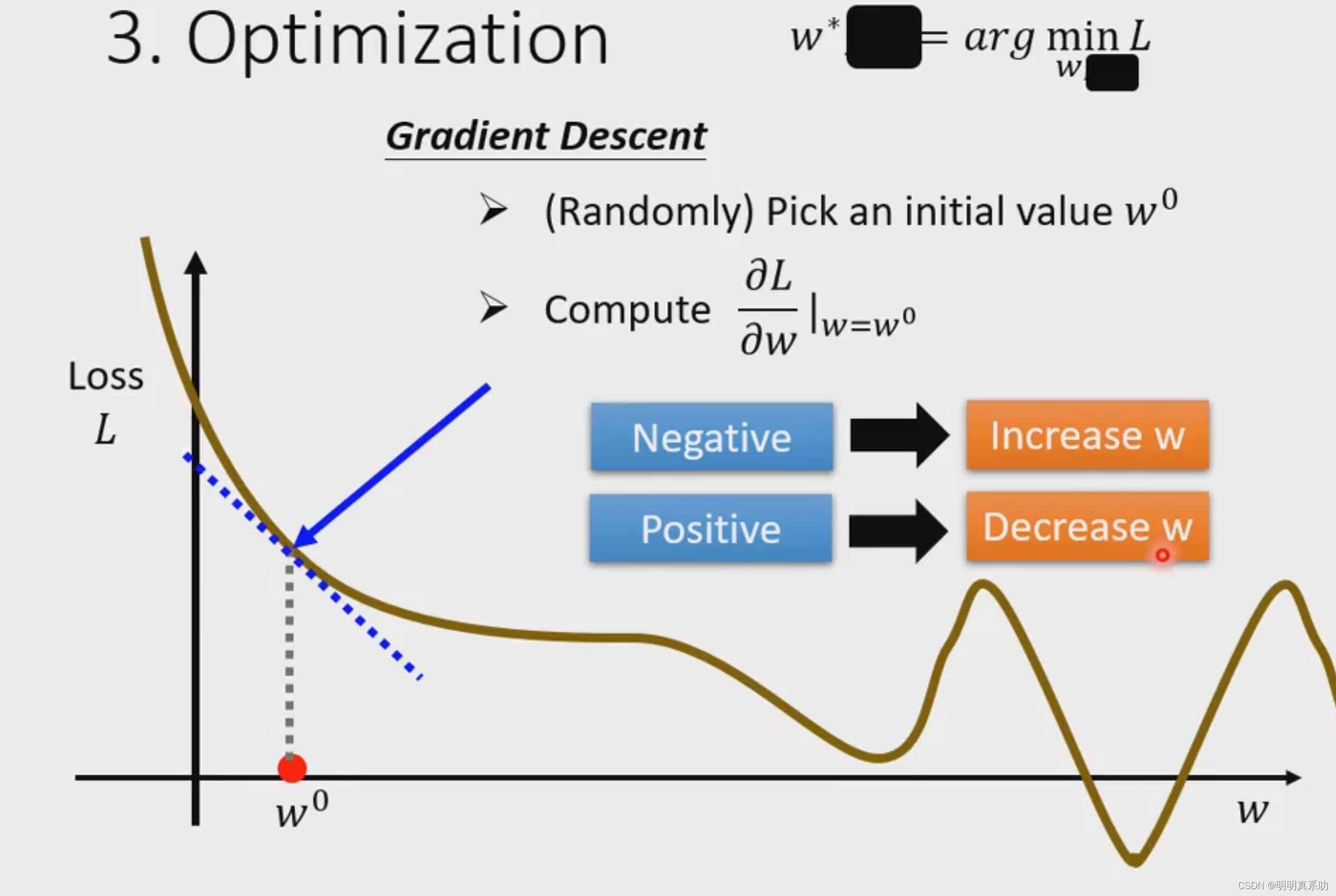
在上面图中,我们先遮住b*,求w*,于是我们得出了w关于L(b,w)的图像。
接着步骤如下:
1. 先随机找一个点w⁰
2. 然后求L对w的偏导,并带入w⁰。如果结果为负数(斜率向下),证明函数在该点不是最小值,可以再往右边隔段取点,如果为正数(斜率向上)则往左边取点
3. 取到一个新的点更新w的值为w₁,其值为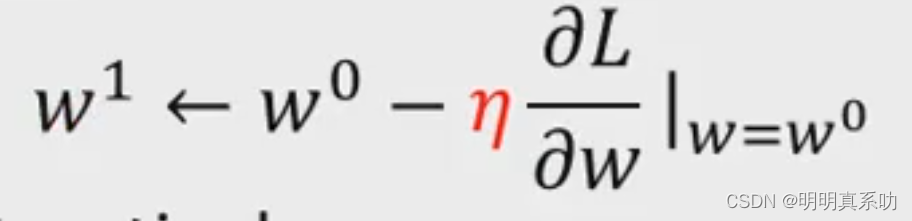
然后重复2,找到w²,以此类推,知道偏导带入wn为0时候(斜率为0取得极值),证明找到了最小值。
此外,在步骤2中的隔线段取点问题是重中之重,可以说我们取大了会丢到最佳点,取小了又效率低下。所以我们给这个取的距离叫做步长。
步长的计算公式如下:
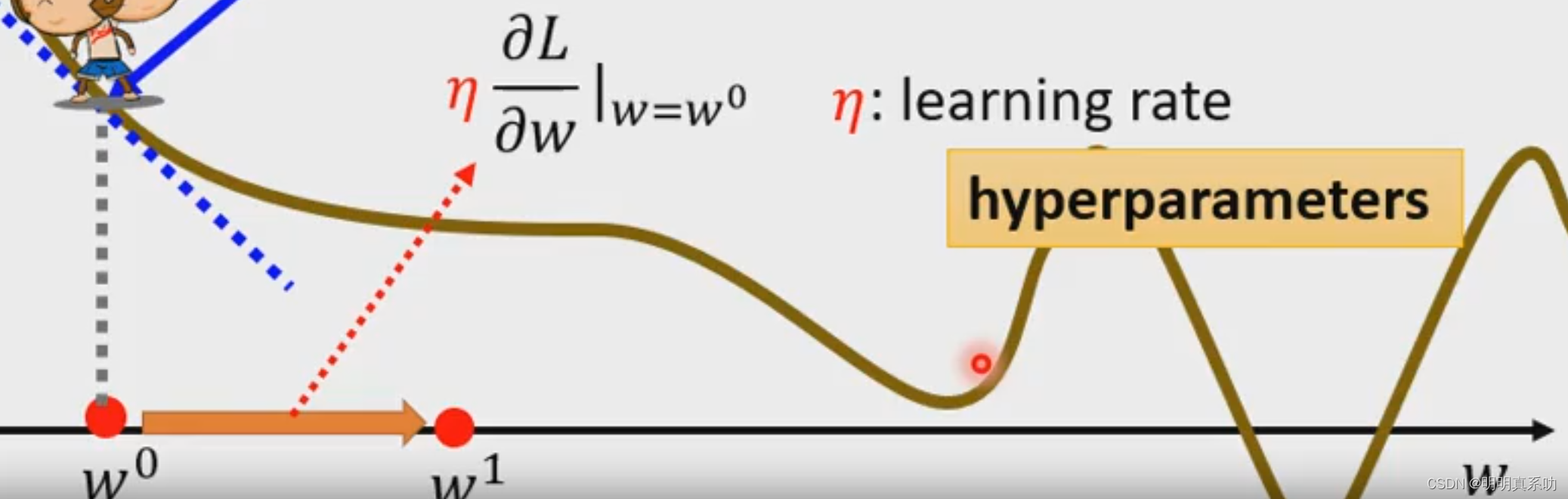
其中ŋ称为学习率(Learning Rate),是我们人为定义的,这种人为定义的参数又叫做超参数(hyperparameters)。
所以要想确定最佳的步长,需要我们人工的去调试,这就比较麻烦了。这就是最佳值难找的原因。
此外,我们的最佳点位也跟我们的起点取点有关。
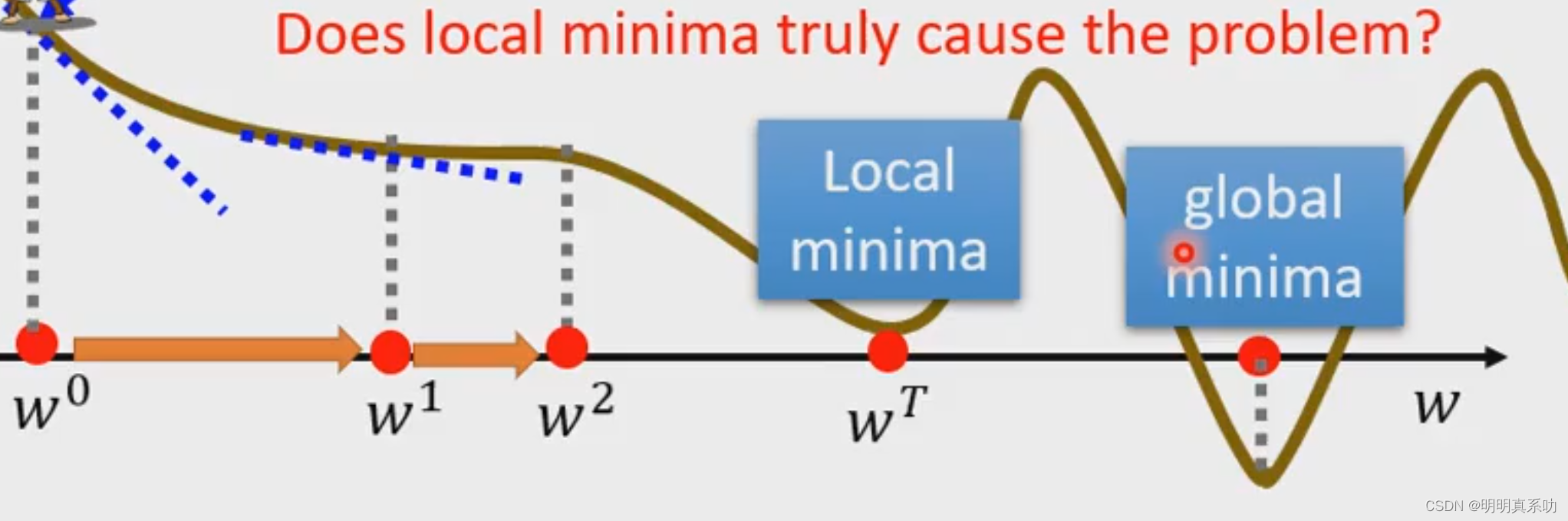
如图,如果我们w⁰在,我们最佳值只能找到wT(称之为local minima),但实际上我们的最佳值是在w轴下方的那个点(称之为global minima),因为我们现在看图说的都是马后炮的事情,实际上我们面对未知的问题是很难找的,所以最佳值实际找起来很难找。
所以有了以上的思路,我们按照下图步骤

并得到这个Error Surface(误差曲面)
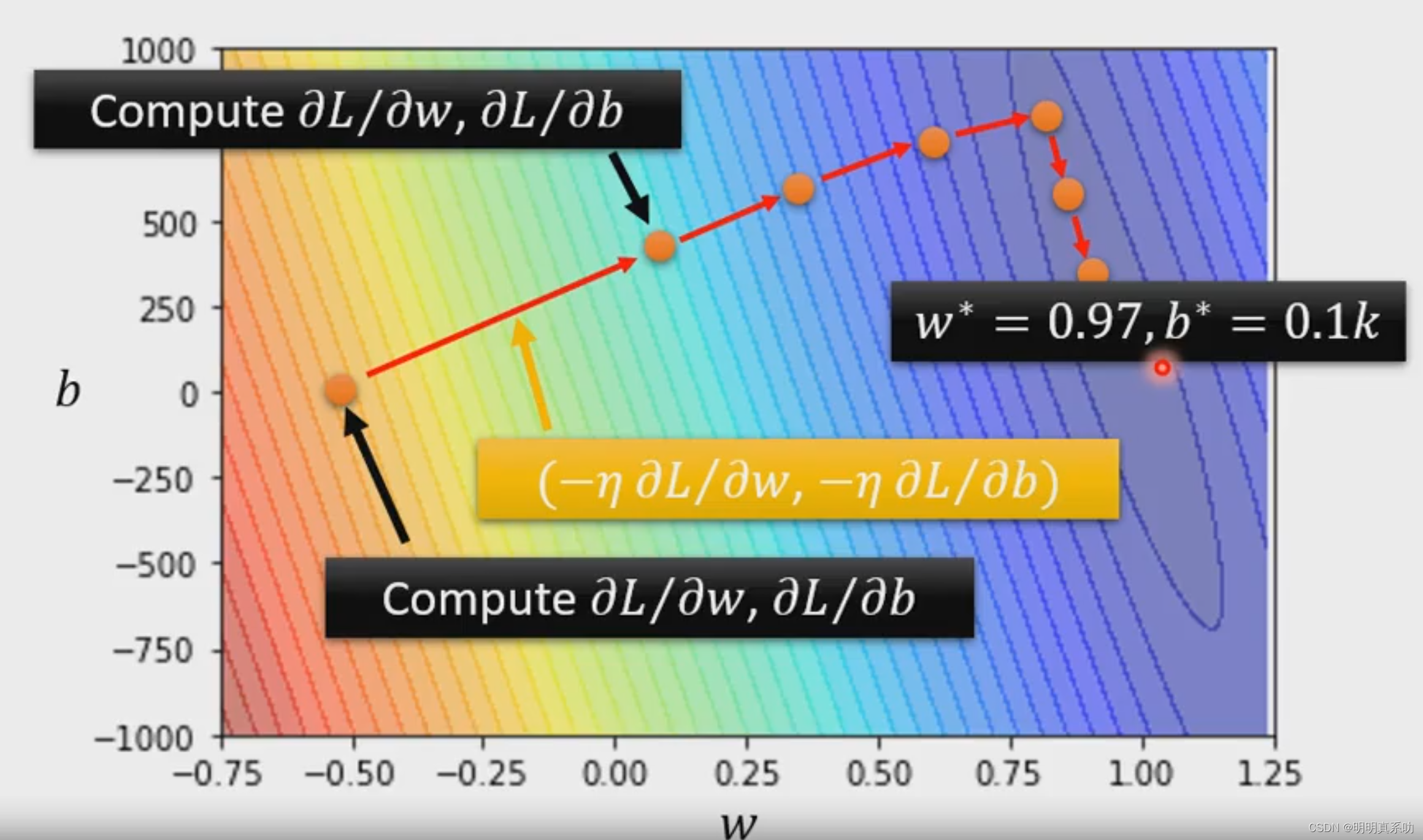
最后就可以得出我们的最佳值。
4. 总结以及模型优化问题
寻找函数分为三步,分别是:
1. 设定函数未知量
2. 从训练集中定义损失函数
3. 寻找未知数最佳值

那么我们就提出一个疑问,这个函数模型处理真的就是最佳的吗?

从上图数据,我们可以看到。在已知的数据预测中(2017-2020),模型的其误差率是0.48k。但是在未知的数据(即预测2021的数据)的预测中则是0.58k。

如上图所示,红线为真实值,蓝线为预测值。
那么我们有办法让损失值更小让,使其预测值更贴近真实值吗?
其实我们可以思考一下,我们的观看数按每一天来算,浮动是很大的,那么我们是否可以考虑更换一个模型(换一个函数计算),让其计算7天为周期或者28天甚至56天呢?
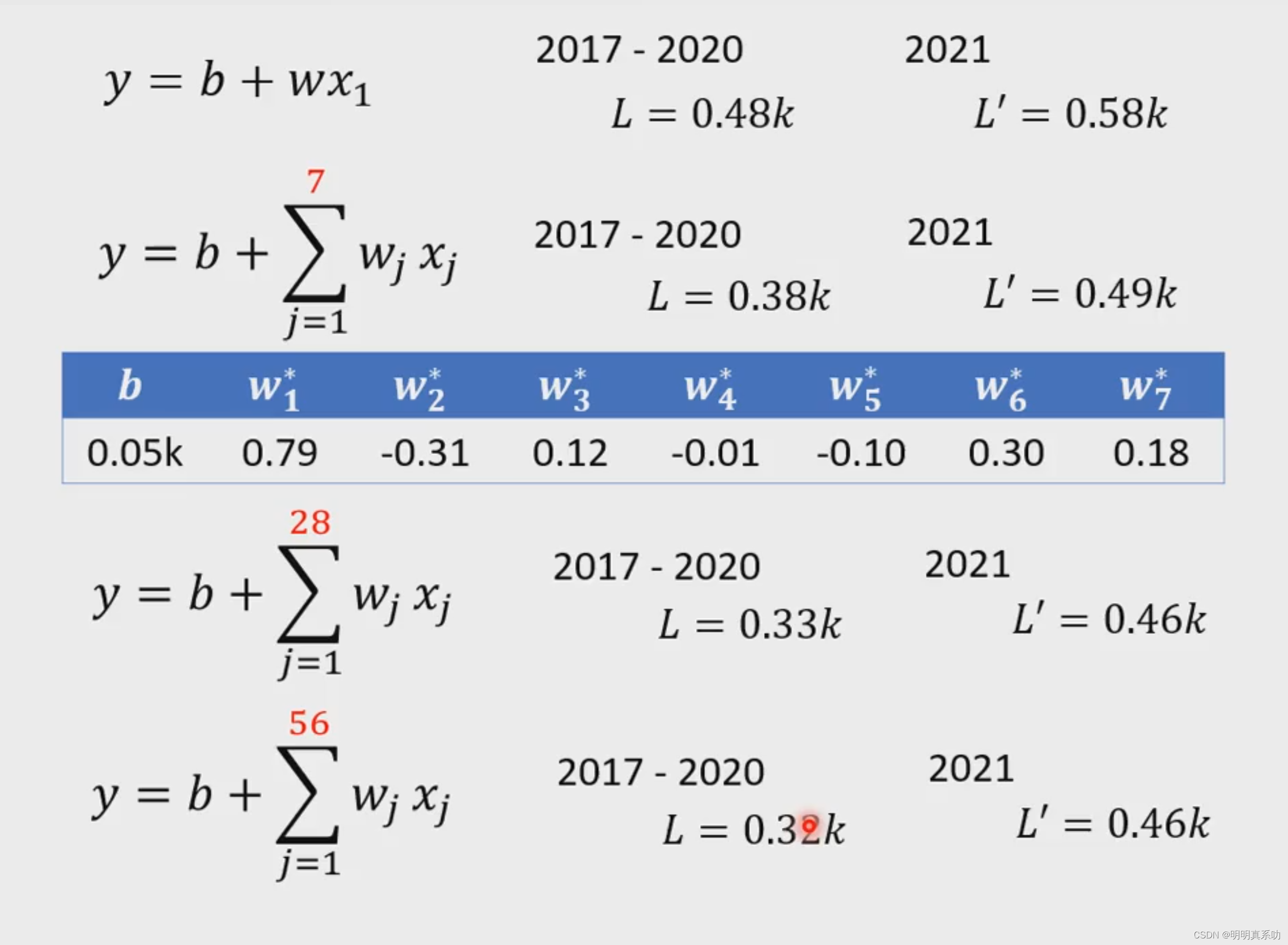
可以看到
更换为7天一个周期的模型,误差都变小了。
换成28天周期的模型又变小了,但是56天周期的模型基本上就和28天的误差相差无几
证明再增加周期天数,对误差的减小以及预测的精准度没有任何提升。
但是我们这个模型不仅仅局限于这种计算方法,还有更佳的值得我们探索。
二、 深度学习
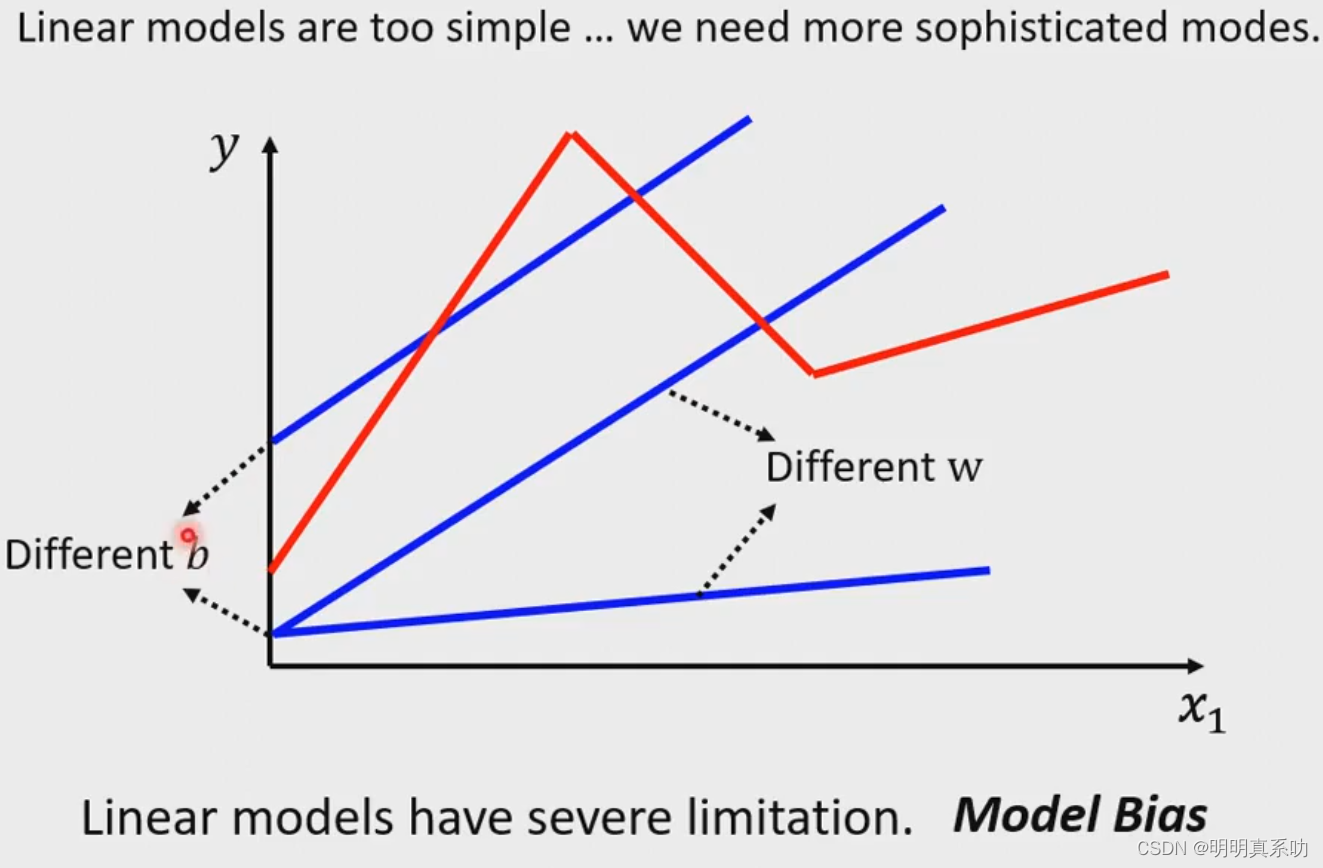
1. 线性模型的劣势
就拿我们的视频观看人数来说,每一天的观看人数相对与其前一天都是有升有降的。但是我们如果用单纯的线性方程表示,例如:y = b + w*x。在这个方程中,我的斜率和截点如何改变,线性的函数只可以递增或者递减,不能忽增忽减,这种函数我们称之为Linear model(线性模型)。
这种所谓的限制性我们称为Model Bias(模型偏差)。
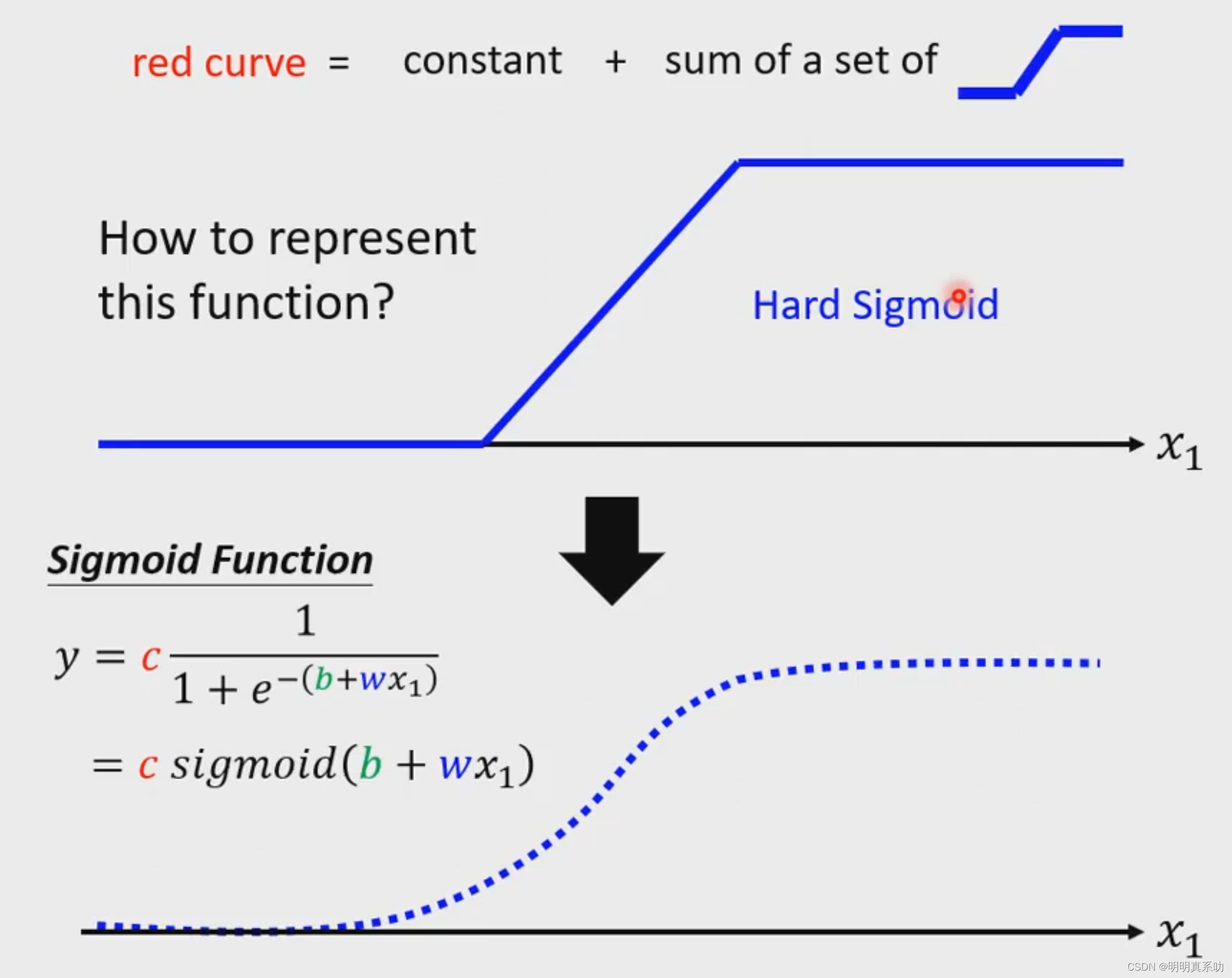
2. 全分段线性曲线(all piecewise linear curve)
但是在实际生活中,我们的事物肯定是又增有减的,如下图所示,那么我们遇到这种问题时,如何使用更加复杂模型呢?
我们可以使用最简单的思想———叠加法
在下面这张图中,我们可以用几条连续的线性模型拼接成一个更为复杂的红色曲线模型
我们可以把red curve起点设为0号, 然后red curve转折点前的线可以用1号代替
以此类推,红线的每个转折点前都设置与其平行(斜率相同的线)
再将0+1+2+3叠加,就可以表示我们的红线模型了。
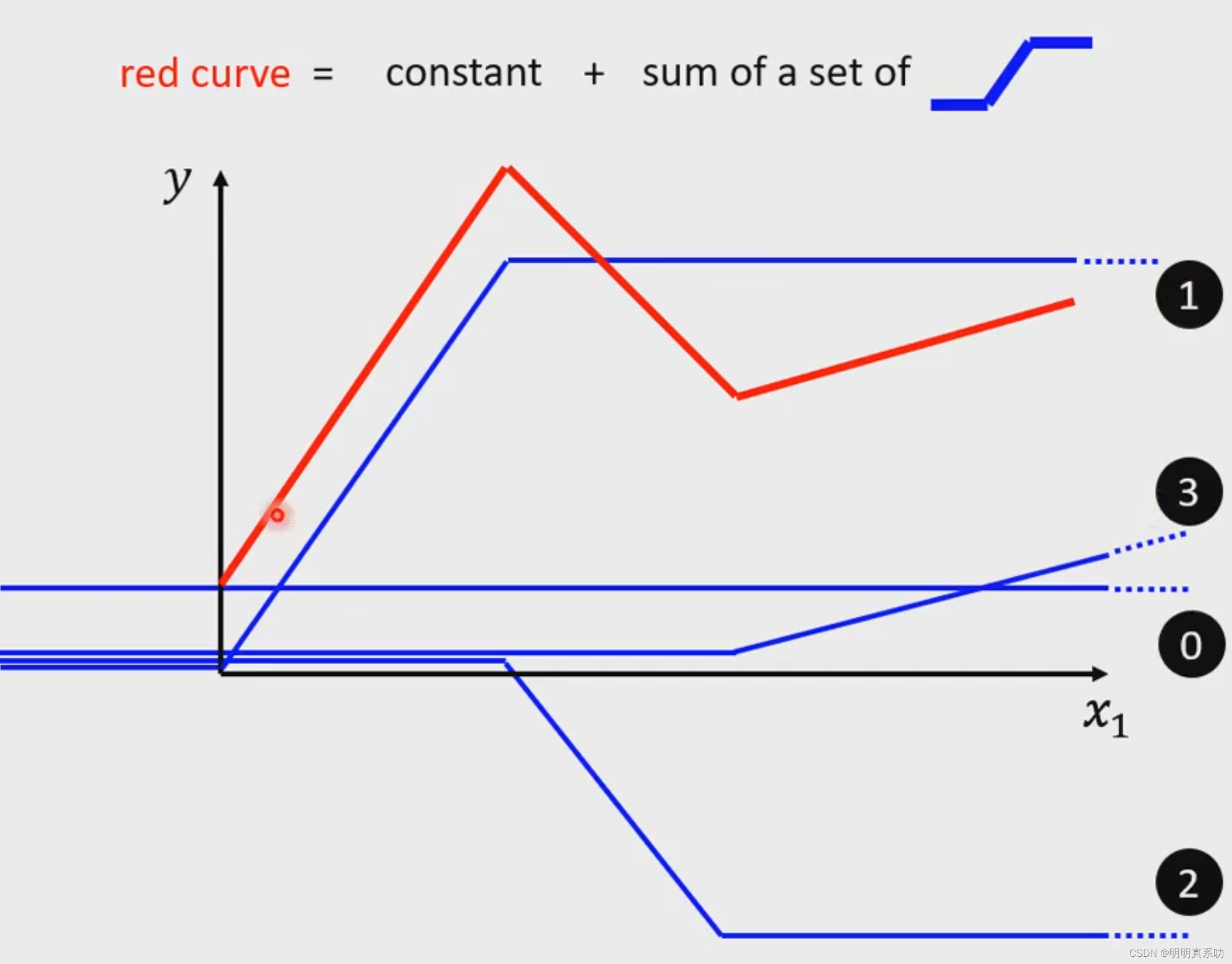
这种曲折的线端称之为all piecewise linear curve(全分段线性曲线),其实由连续的线段组成的

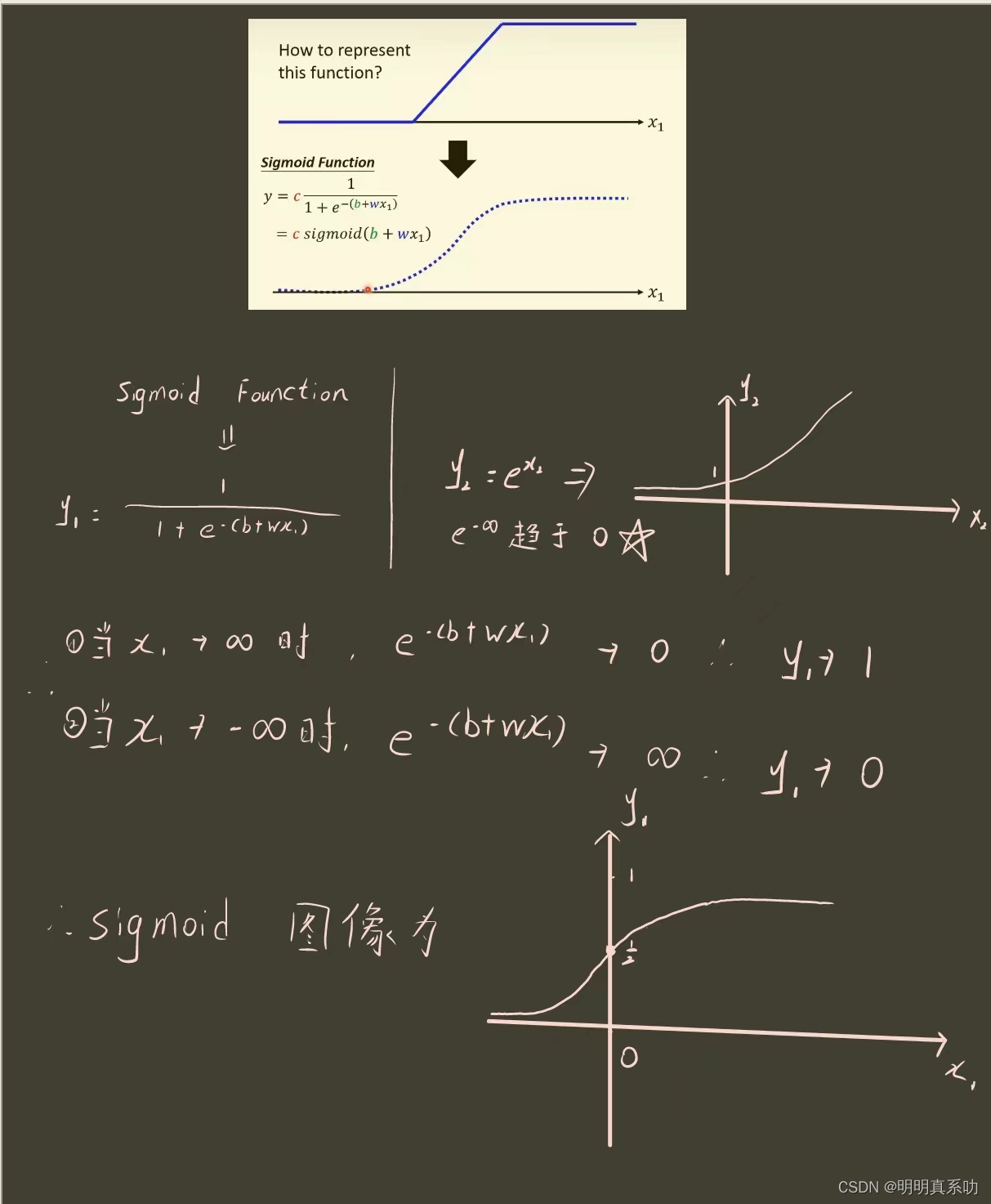
2.1 sigmoid函数
我们预测的时候终究需要模型,那么这些线段怎么表示出来呢?
于是在研究中,人们发现了一个可以很好表达这些线段的模型——sigmoid函数
其曲线形状逼近与我们想要的线段模型。
注意:sigmoid又分为hard sigmoid(线段型)和soft sigmoid(曲线型)
因为soft sigmoid可以简单地用函数表达,所以我们先对进行研究。
关于soft sigmoid的图像,我们可以对其敛散性进行分析,如下图所示。
然后我们可以通过对sigmoid进行一些小小的修改,乘上一些参数来调整我们的sigmoid的形状,来形成我们的线段模型。
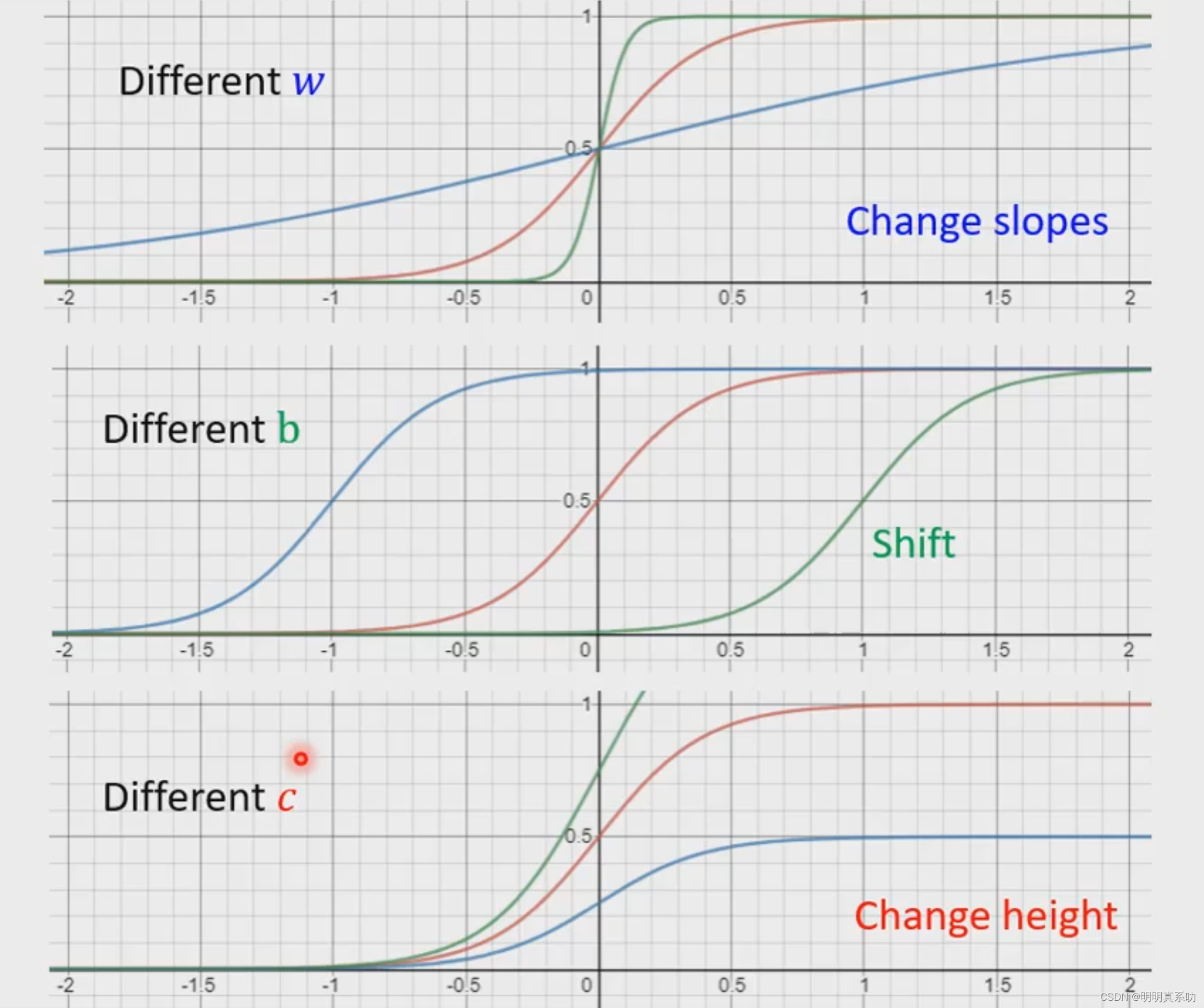
如下图所示,我们在上图的方程式中:
通过操控w参数可以改变函数的斜率
通过操控b可以对函数进行换位
通过操控c可以改变函数的高度
以此,我们可以形成任何形状的改良后的sigmoid模型。
最后我们再将这些不同的改良后的sigmoid按照上面的叠加法,得到我们的更加复杂的all piecewise linear curve。

于是我们基于前面视频播放量的预测模型进行改造,我们就可以得推出sigmoid化的模型关系,如下图所示。
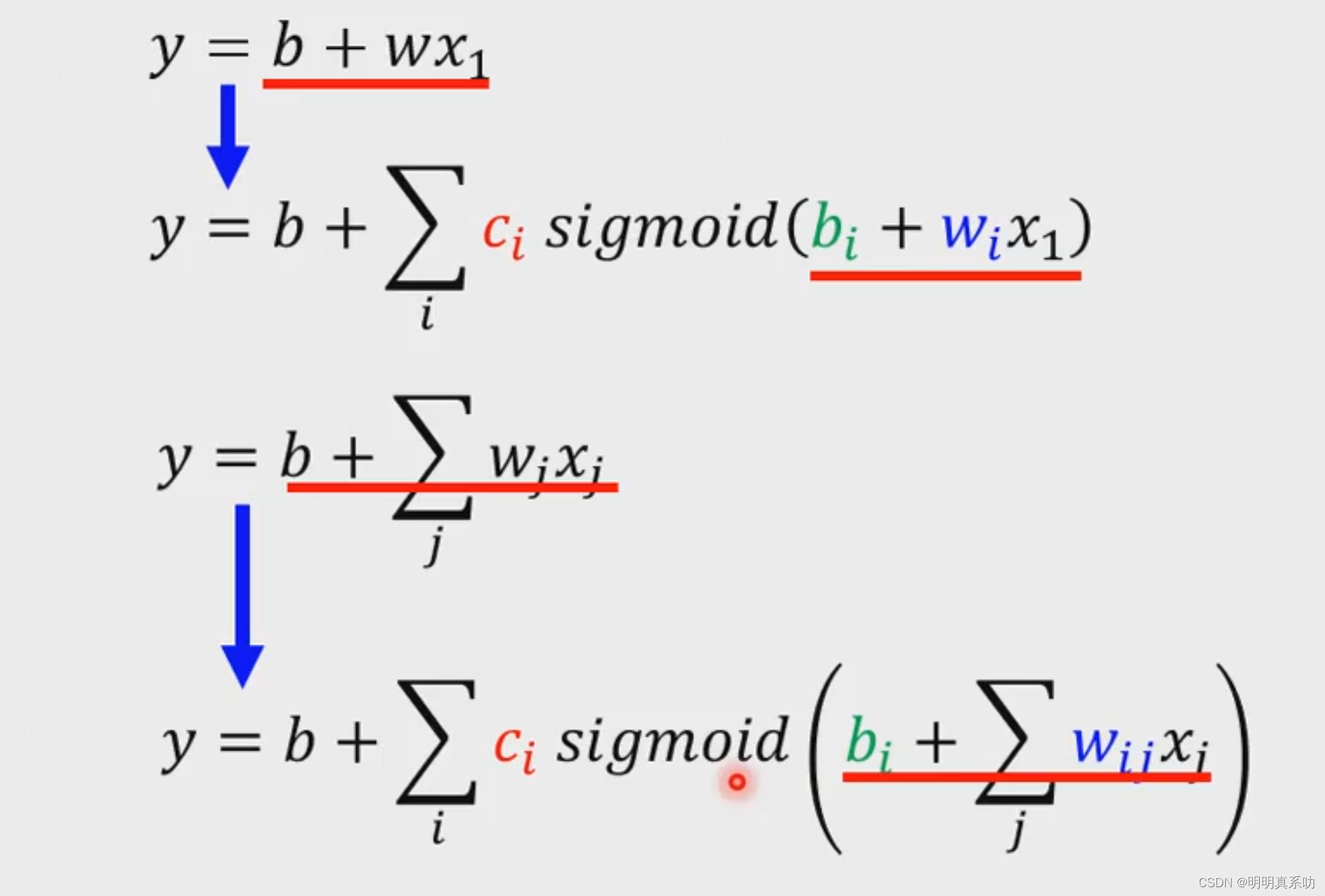
那么现在又产生了一个新的问题了,就如我们图上的第二条sigmoid化的函数,很显然,如果我们的i、j比较大的话,我们就可能多了很多个未知数,根据我们三步走的原则,这些未知数都是需要确定下来的,那么我们如何更好的表达这个模型,更加深入的理解,从而求最佳未知值呢?
2.1.1 用线性代数去理解复杂的模型的三步走
假设我们的i与j都设为1、2、3。
于是我们带入得到如下图的关系式,我们分别用r₁、r₂、r₃表示这些i、j不同运算式子。
w(i,j)表示xj对应的第i个sigmoid函数的权重
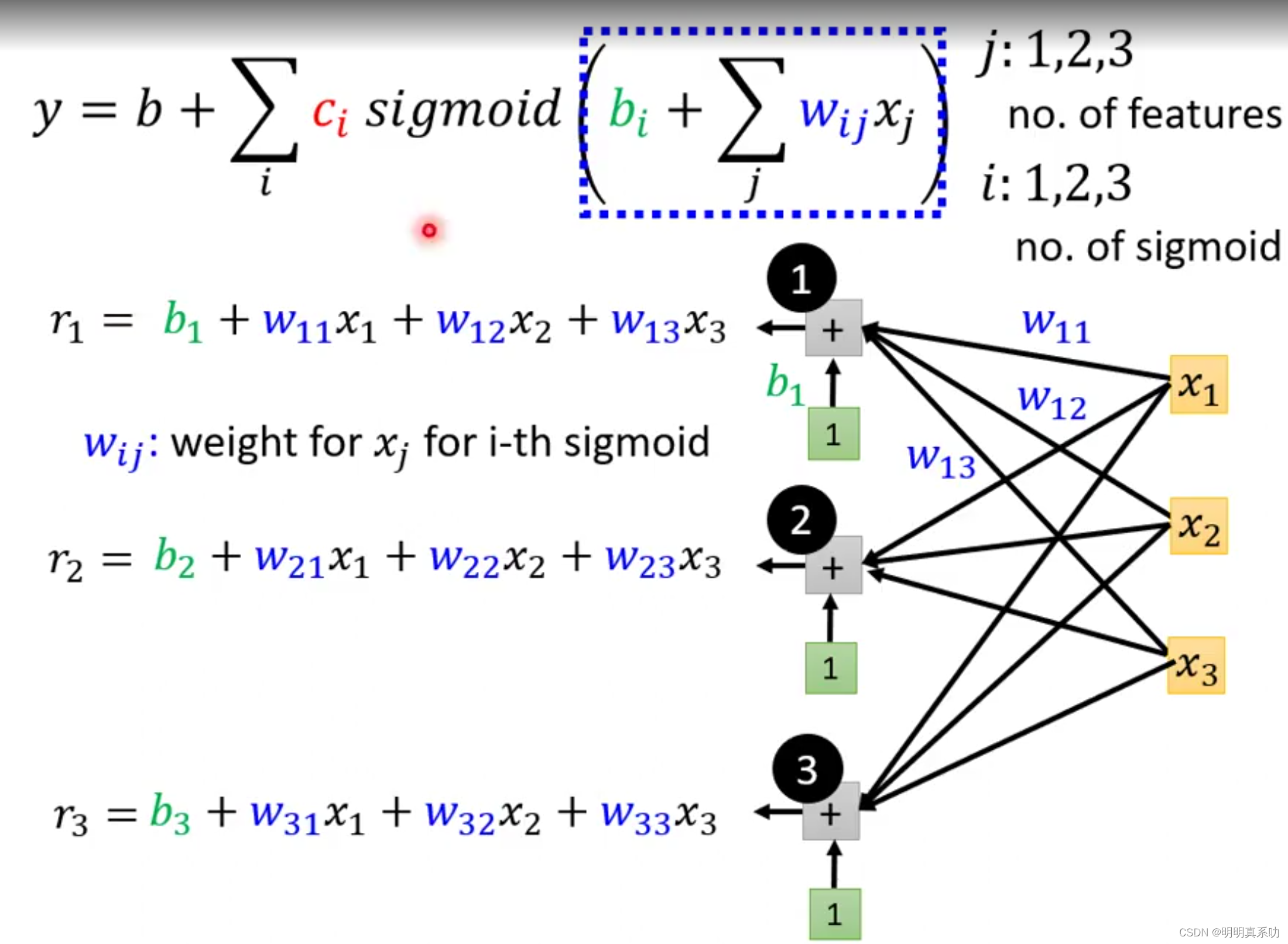
接着我们把r₁、r₂、r₃整理出来,学过线性代数的同学应该一眼就就可以看出来这是线性代数的运算。
根据这条式子我们可以看到我们的未知数是非常多了,我们可以把这几个行列式,用一个大写字母表示。

接着我们把r1、r2、r3 进行sigmoid运算,得到ɑ₁、ɑ₂、ɑ₃,再与ci中的c₁、c₂、c₃相乘,有得到一个线性代数的运算,C转置 乘 ɑ,最后再加上b,得出最后的模型y = b + c^T * ɑ。
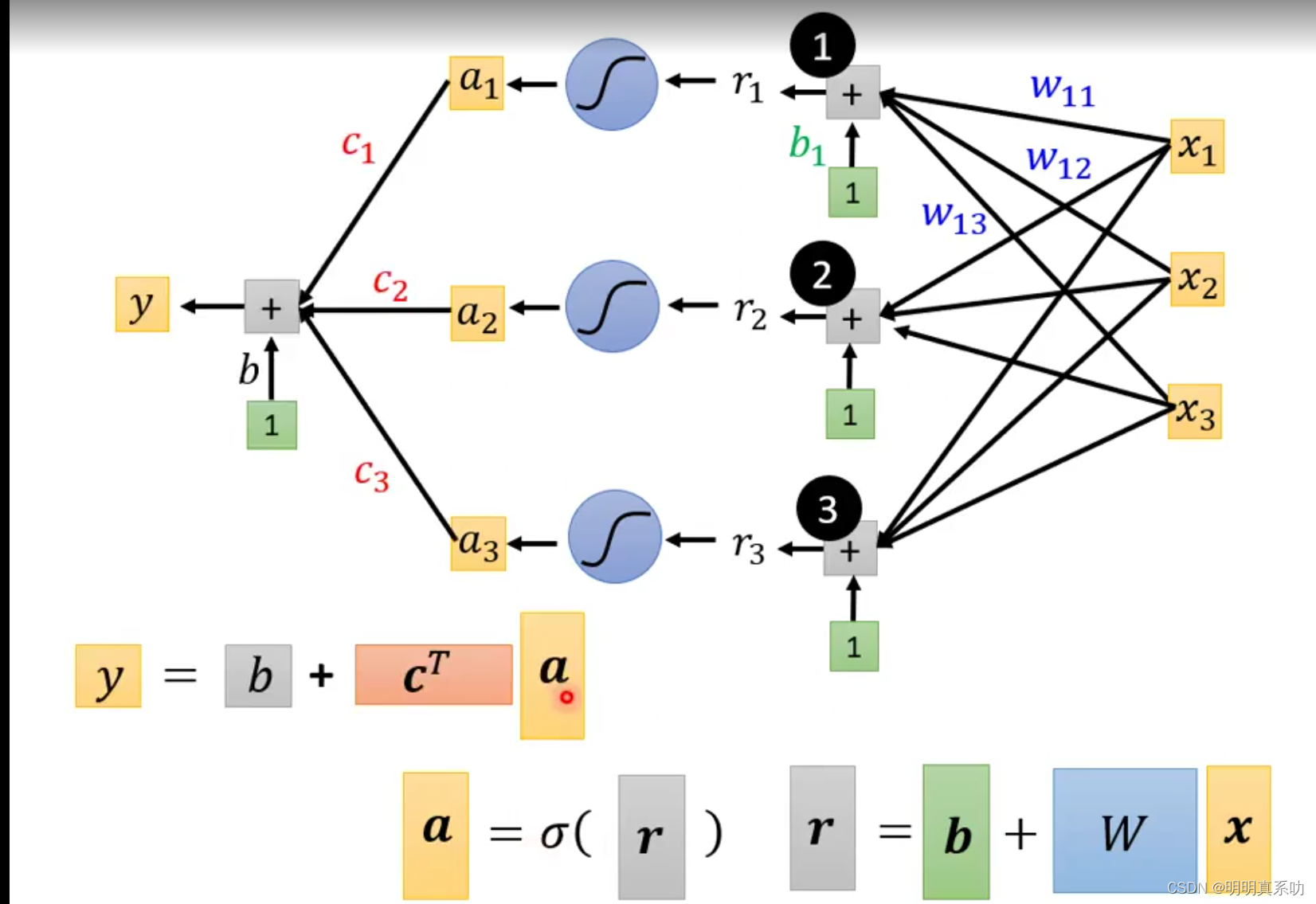
正如我们上面所说的三部曲中,我们的x是已经知道的输入量(称为feature),而我们的unknown parameters有如此之多,因此我们需要用一个字母来表示这些未知量为θ,其中θ是一个N行一列的的矩阵其中包括W、b矩阵(内)、b(外)、c^T。
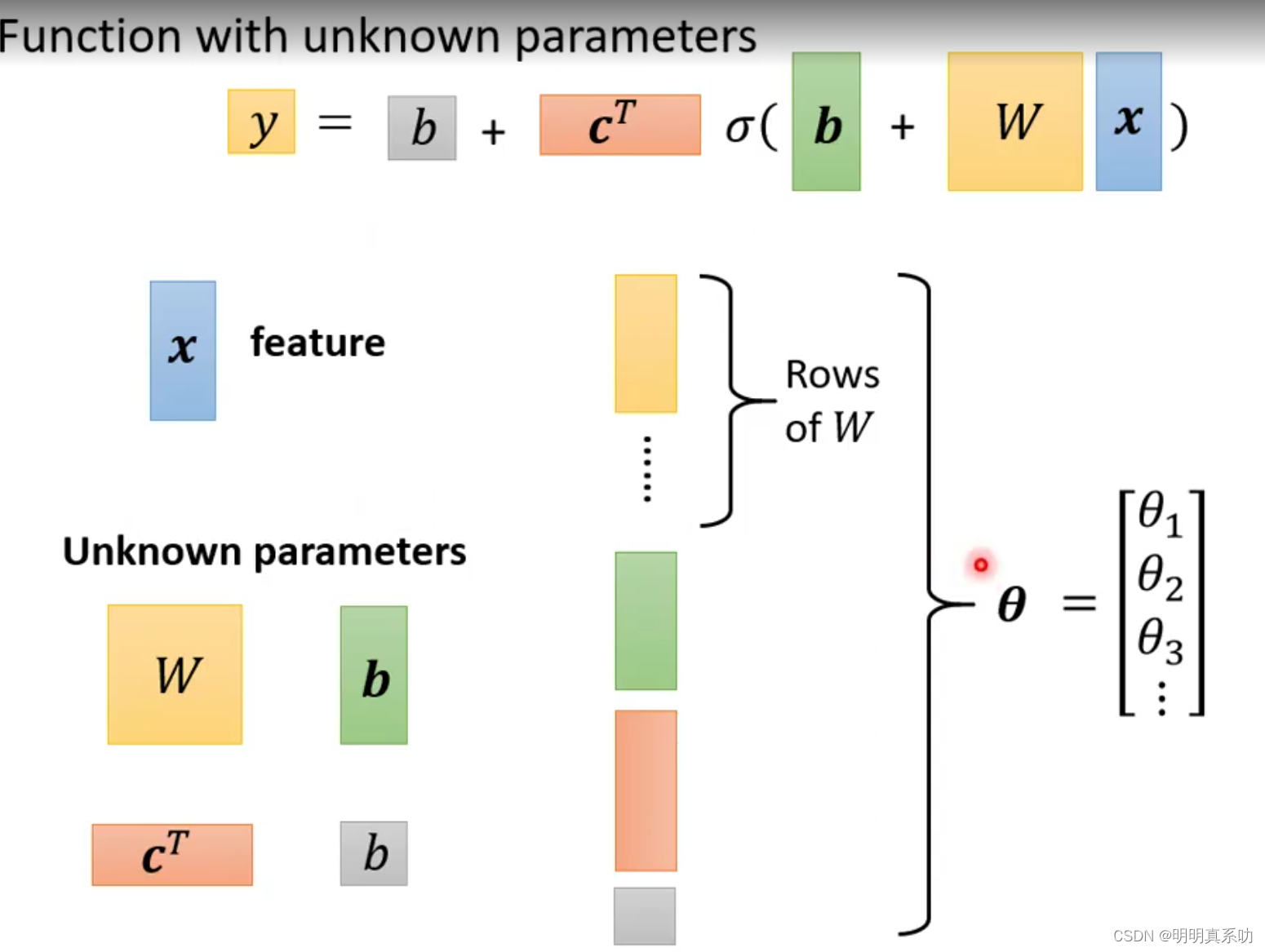
我们来到第二步求损失函数,我们将θ带入到Loss函数中,求出最佳的θ使得Loss的值最小。
这里我们需要用到一个梯度下降算法来完成(后面会补,先了解定义)
梯度的定义:
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f(x,y)或者▽f(x,y)。
对于在点(x0,y0)的具体梯度向量就是(∂f/∂x0, ∂f/∂y0)T.或者▽f(x0,y0),如果是3个参数的向量梯度,就是(∂f/∂x, ∂f/∂y,∂f/∂z)T,以此类推。
那么这个梯度向量求出来有什么意义呢?
他的意义从几何意义上讲,就是函数变化增加最快的地方。
具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0)T的方向是f(x,y)增加最快的地方。
或者说,沿着梯度向量的方向,更加容易找到函数的最大值。
反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0)T的方向,梯度减少最快,也就是更加容易找到函数的最小值。
于是以此类推,我们通过我们设置的学习率去一步一步和梯度,求得最小的θ(一般是算到我们不想算为止,因为这个不跟线性的一样会有导数为0的时候),最后我们就可以确定最佳的一组未知数了。


注意:update与epoch的区别
我们在训练模型时候,很多时候要将数据集进行分组,每一个组叫做一个batch
我们根据这个batch更新我们的未知数,叫做一次update。
当我们把这一个数据集训练完后更新出来的未知数,叫做epoch(纪元,可以想象成是一个纪元的更替)
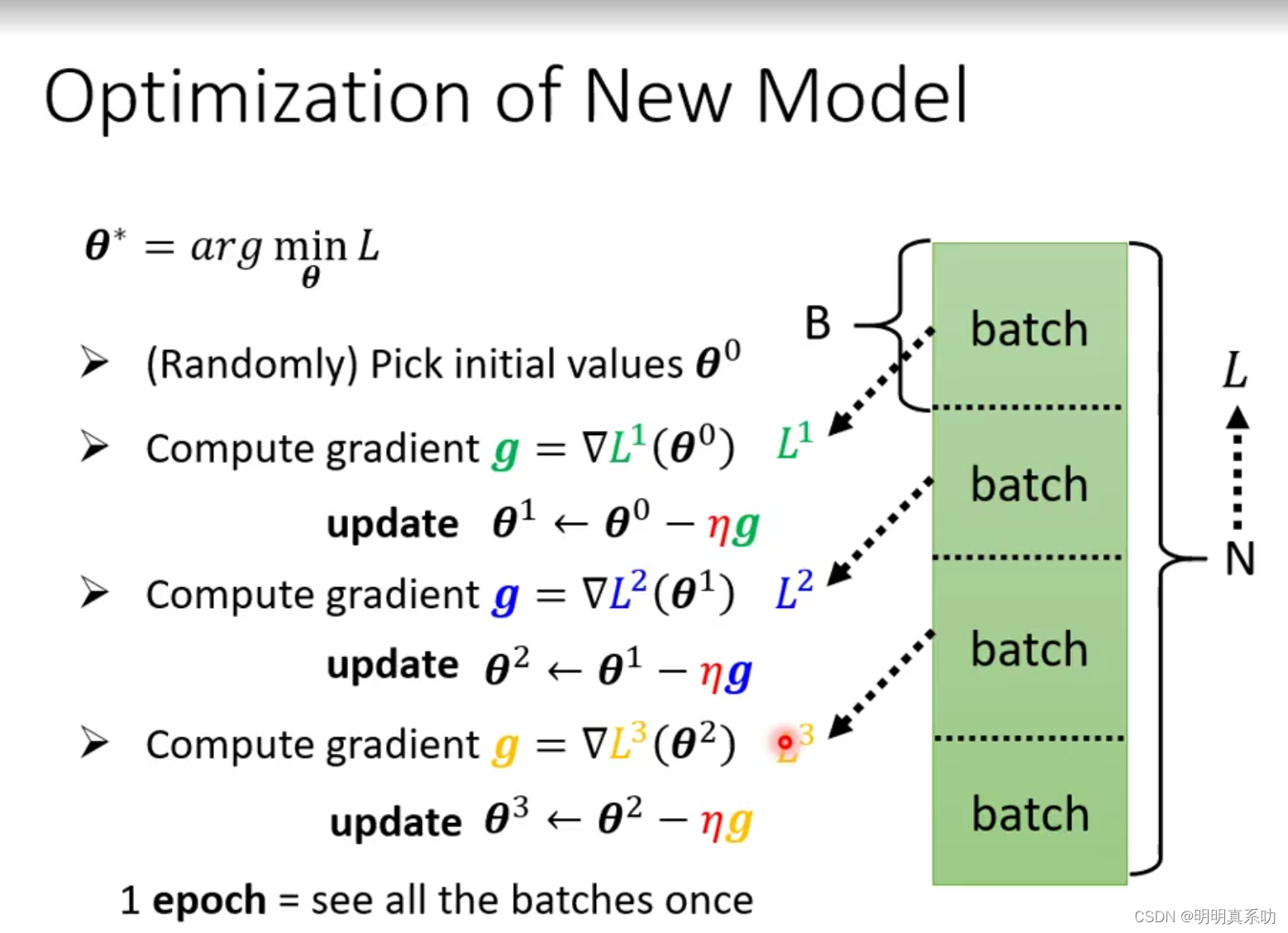
例如:我们有一万个数据集,将其分为10组。则需要进行一千次update。

2.2 ReLu函数
前面我有提出了sigmoid分为soft sigmoid(曲线型)和hard sigmoid(线段型),因为我们的数据连接起来本来就是由多个线段组成的,那么肯定运用线段更加能够贴合我们实际,从而使预测更加的精准,那么我们就很有必要介绍一下我们的ReLU函数,因为其是hard sigmoid的重要组成部分。
ReLU,全称为:Rectified Linear Unit(整流线性单元)
通常意义下,其指代数学中的斜坡函数
x大于0则取x,x小于0时取0,即
f(x)=max(0,x)
那么我们如何用ReLu来表示hard sigmoid呢?
如下图,我们可以看到,我们利用两条不同的ReLU叠加就可以表示一个hard sigmoid了。
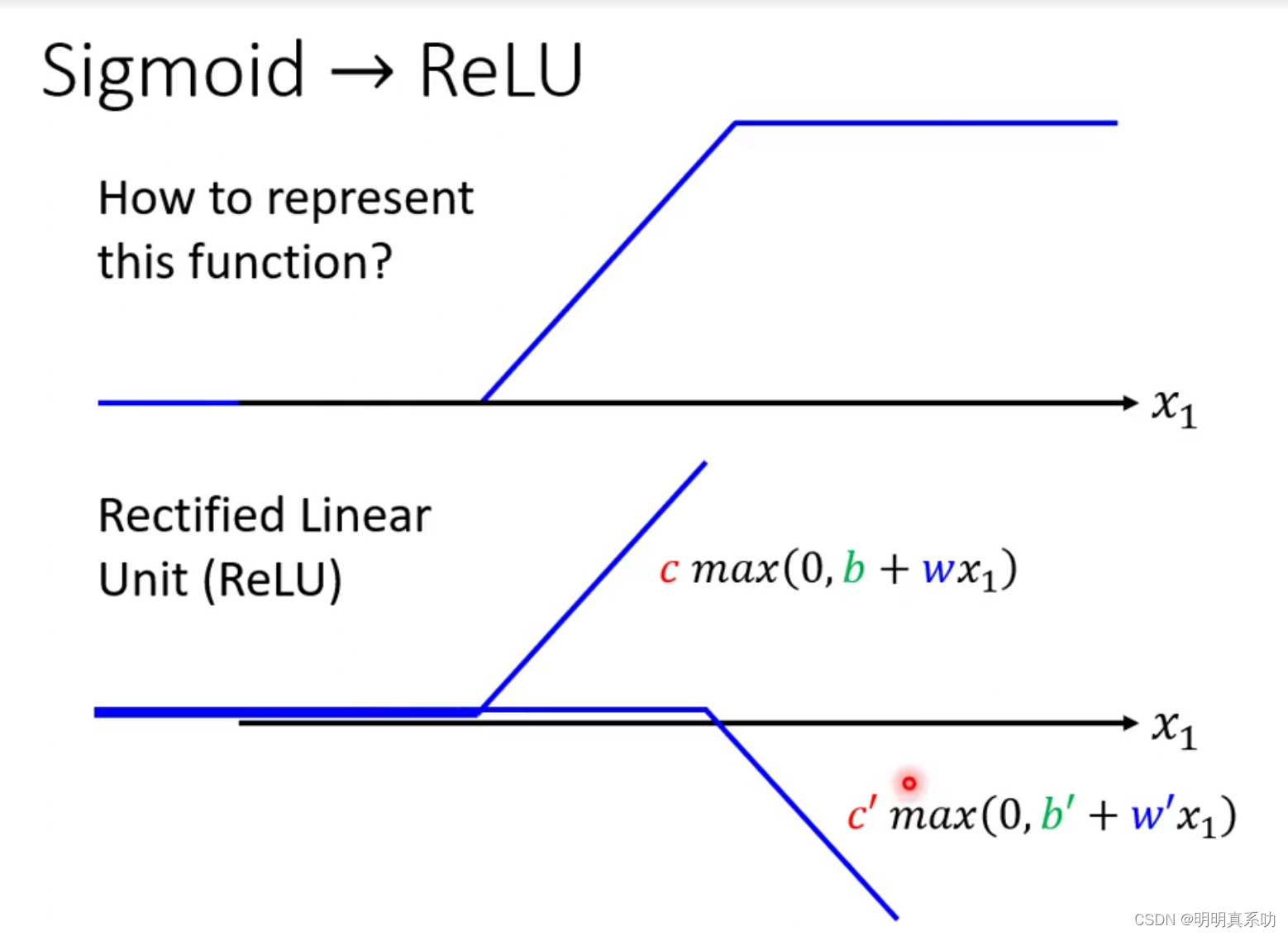
如下图2i表示,两条ReLU,其中sigmoid和ReLU都统称为激活函数。

2.3 深度学习的本质
有了上面的Relu函数,我们可以使用Relu来代替Sigmoid的运算。
除此之外,我们还可以利用套娃的模式,来不断将我们的模型复杂化,产生更多的未知数。
例如将我们第一次算出来的ɑ₁、ɑ₂、ɑ₃,作为下一次sigmoid运算的输入(相当于x),有代入去求更多的未知数,从而使模型更加复杂,预测更加精准(可以理解为一个线段,我取得点越多,就可以越逼近这个线段的形状)
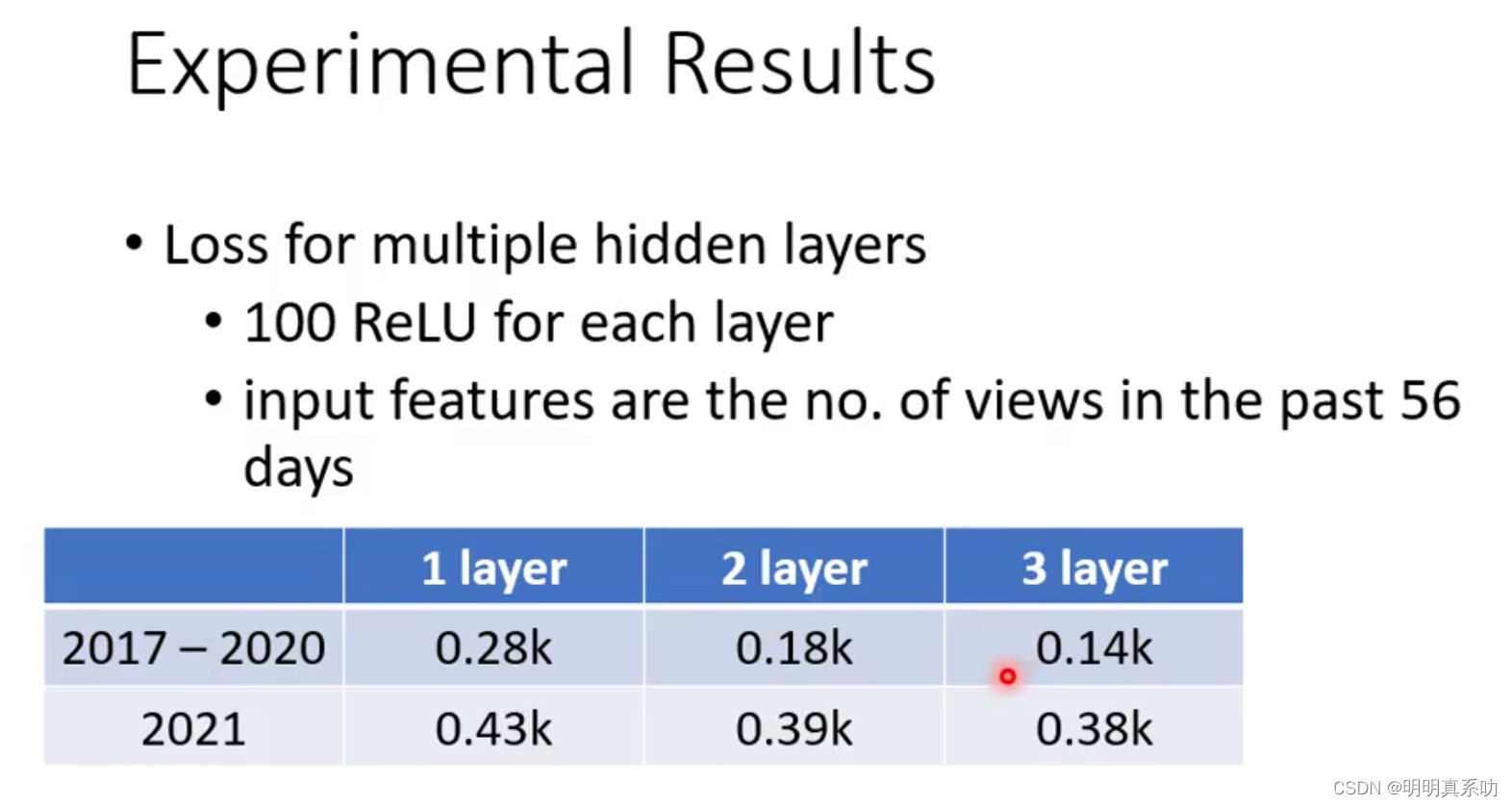
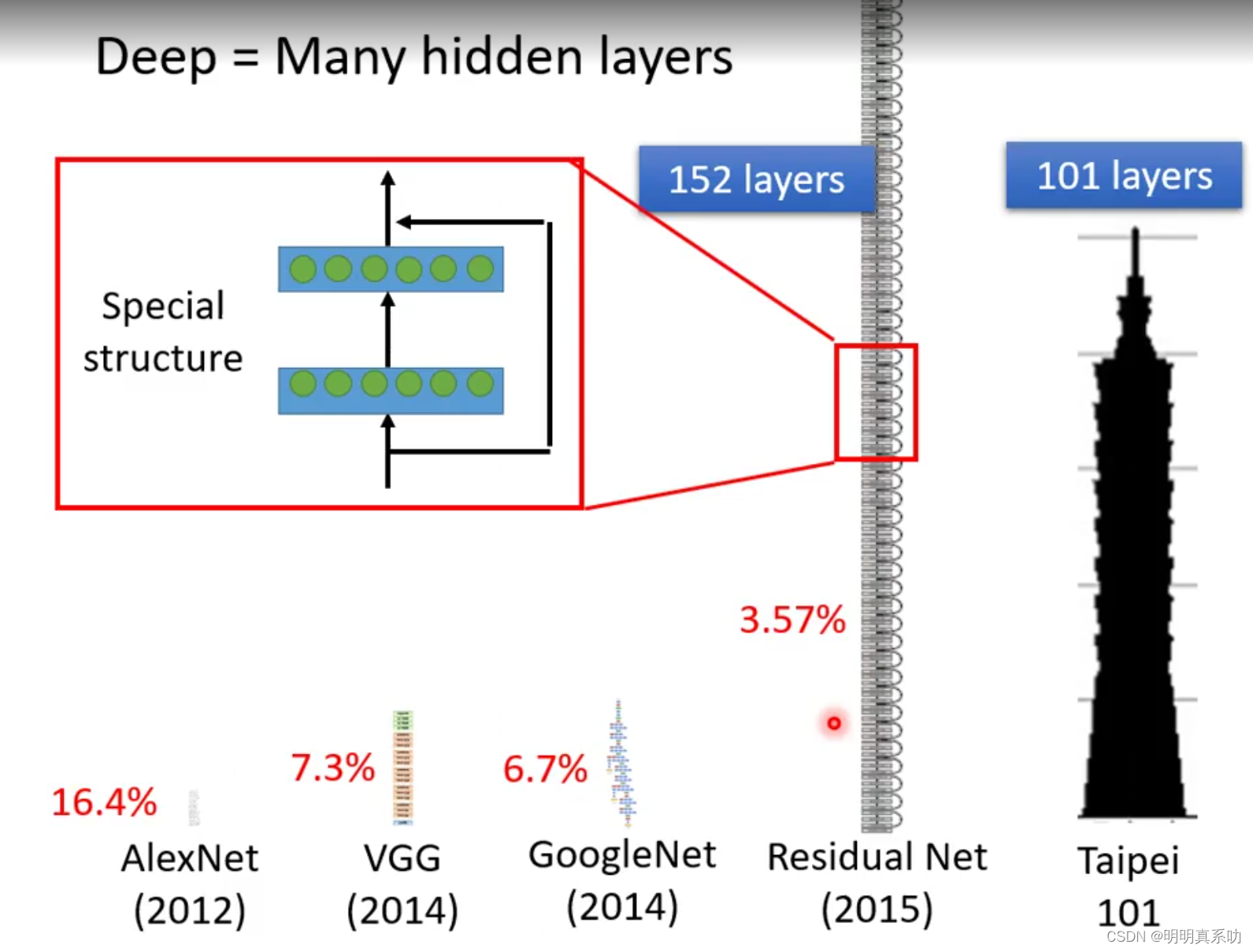
我们每层有100次ReLU的运算,于是进行视频观看量的预测,可以看到在1、2、3层layer中,随着层数的增加,我们模型对已知数据的误差越来越小,对未知数据的预测误差也越来越小,就是表明模型的预测越来越精准了。
像我们每一次进行激活函数的运算,同层一次的激活函数运算称之为一个hidden layer
很多layer叠加起来 就叫做deep,这个过程就叫做deep learning(深度学习),所以深度学习
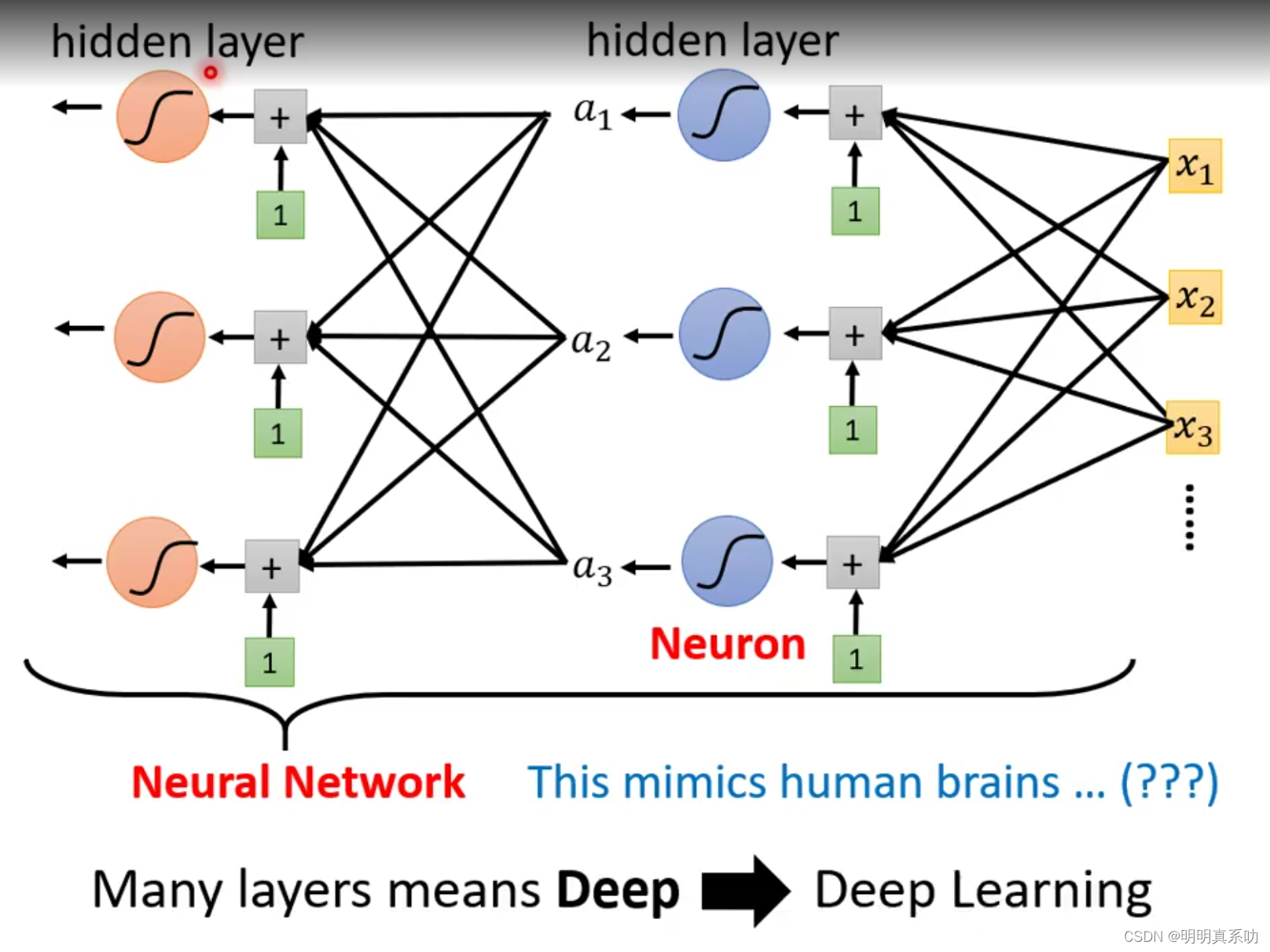
随着时代的发展,已经产生了152层的layers,其处理的错误率仅有3.57%,可见深度学习的力量强大之处。
2.4 深度学习的过拟合现象(overfitting)
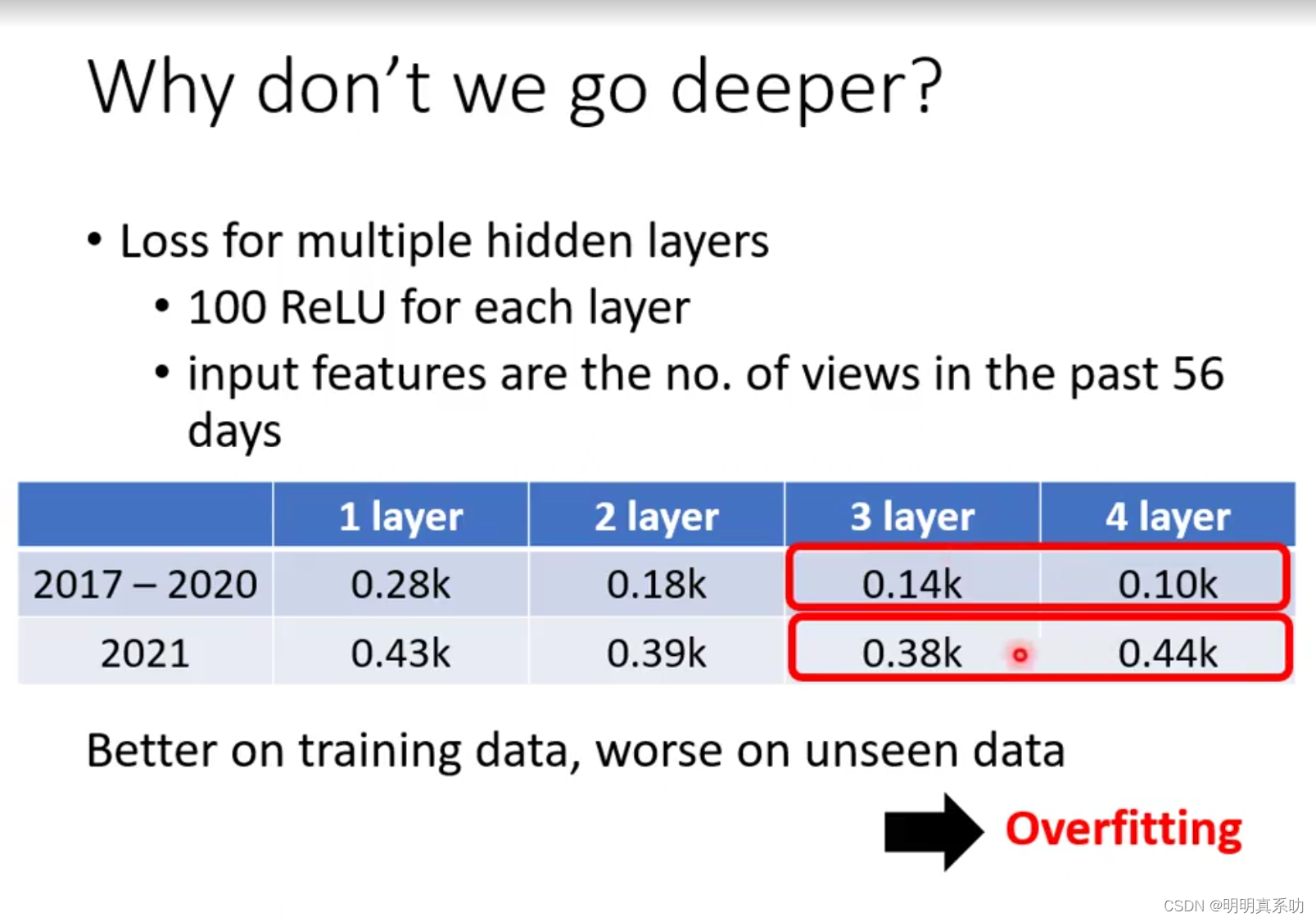
每一层有100次ReLU运算,但是当增加到4层的时候,我们的对未知数据的预测误差值却升高了,这是什么情况呢?
这是深度学习中的过拟合现象
过拟合现象是指模型在训练数据上表现良好,但在测试集或新数据上表现较差的现象。
过拟合的原因主要包括:
模型复杂度过高,当模型的复杂度过高时,它有足够的灵活性来捕捉训练集中的每个数据点,但也容易记住数据中的噪声和特定样本的细节,导致在新数据上的性能下降。
数据不足,如果训练集样本数量较少,模型难以捕捉到数据的整体分布,容易受到极端值的影响,从而导致过拟合问题。
特征选择不当,选择的特征过多或过少都可能导致过拟合。特征选择的关键是要选择那些与预测目标相关的特征,过多或过少都可能引入噪声或忽略重要信息。
很显然,模型过于复杂也会导致结果变差,因此我们的层数并不是一味的叠加就是好的,否则产生过拟合则得不偿失。
3. 深度学习的三步骤
我们上面学过的machine learning是三个step,那么Deep learing也是三个step(就好像把大象放入冰箱中需要三个步骤一样),下面我们开始学习这三个步骤。
3.1 第一步:定义一组函数(define a set of function)
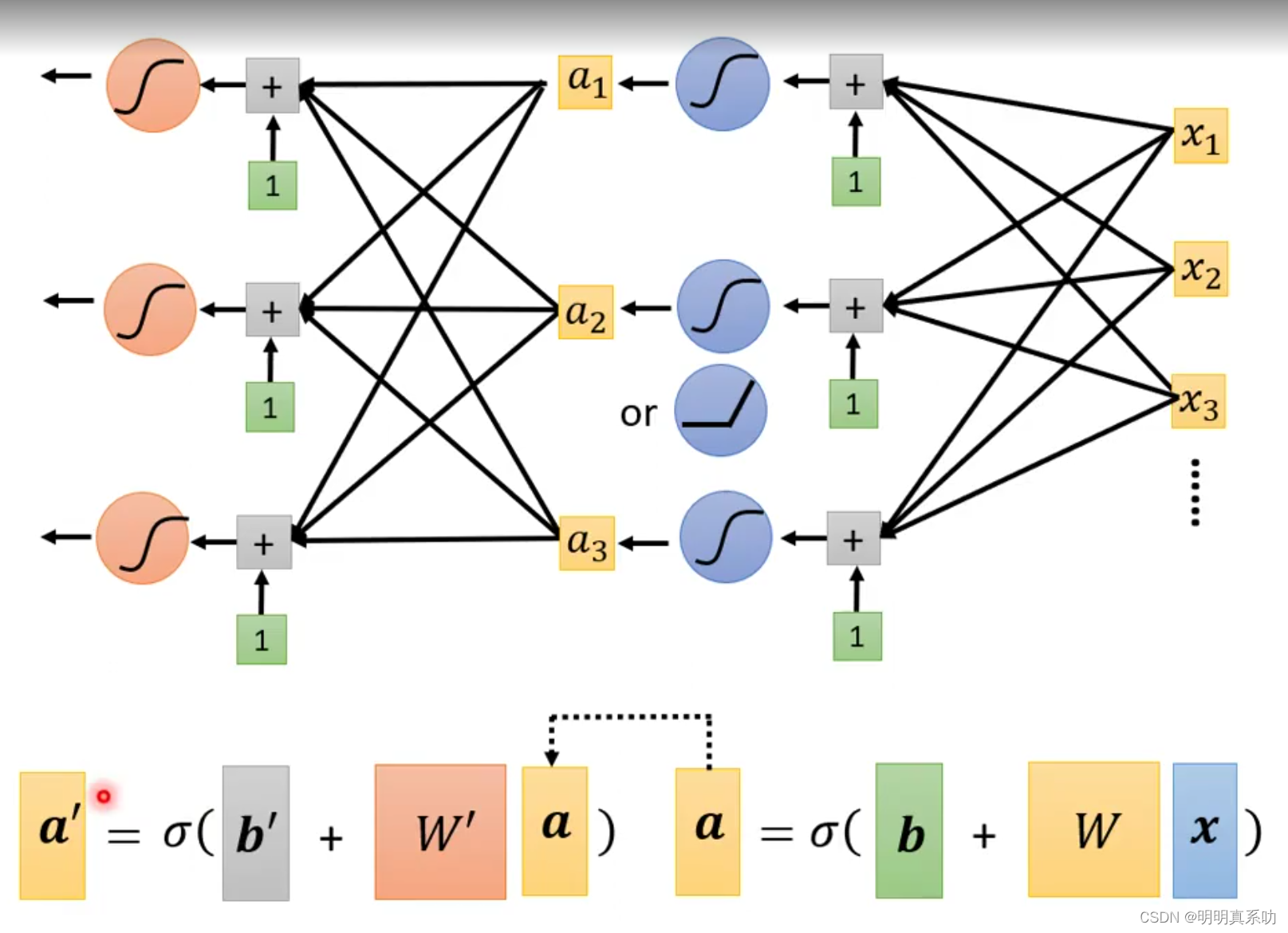
第一步定义一组函数,实际上就是找一个neural network。

3.1.1 neural network(神经网络)
neural network(神经网络),就是一个个Neuron即Logistic Regression(逻辑回归),连接而成的,可以想象成我们人脑中的神经,就是由一个一个的神经元连接而成。
逻辑回归也被称为广义线性回归模型,它与线性回归模型的形式基本上相同,都具有 wx+b
其中w和b是待求参数,多重线性回归直接将wx+b作为因变量,即y = wx+b
而logistic regression则通过函数S将wx+b对应到一个隐状态p,p = S(ax+b)
然后根据p与1-p的大小决定因变量的值。这里的函数S就是Sigmoid函数。
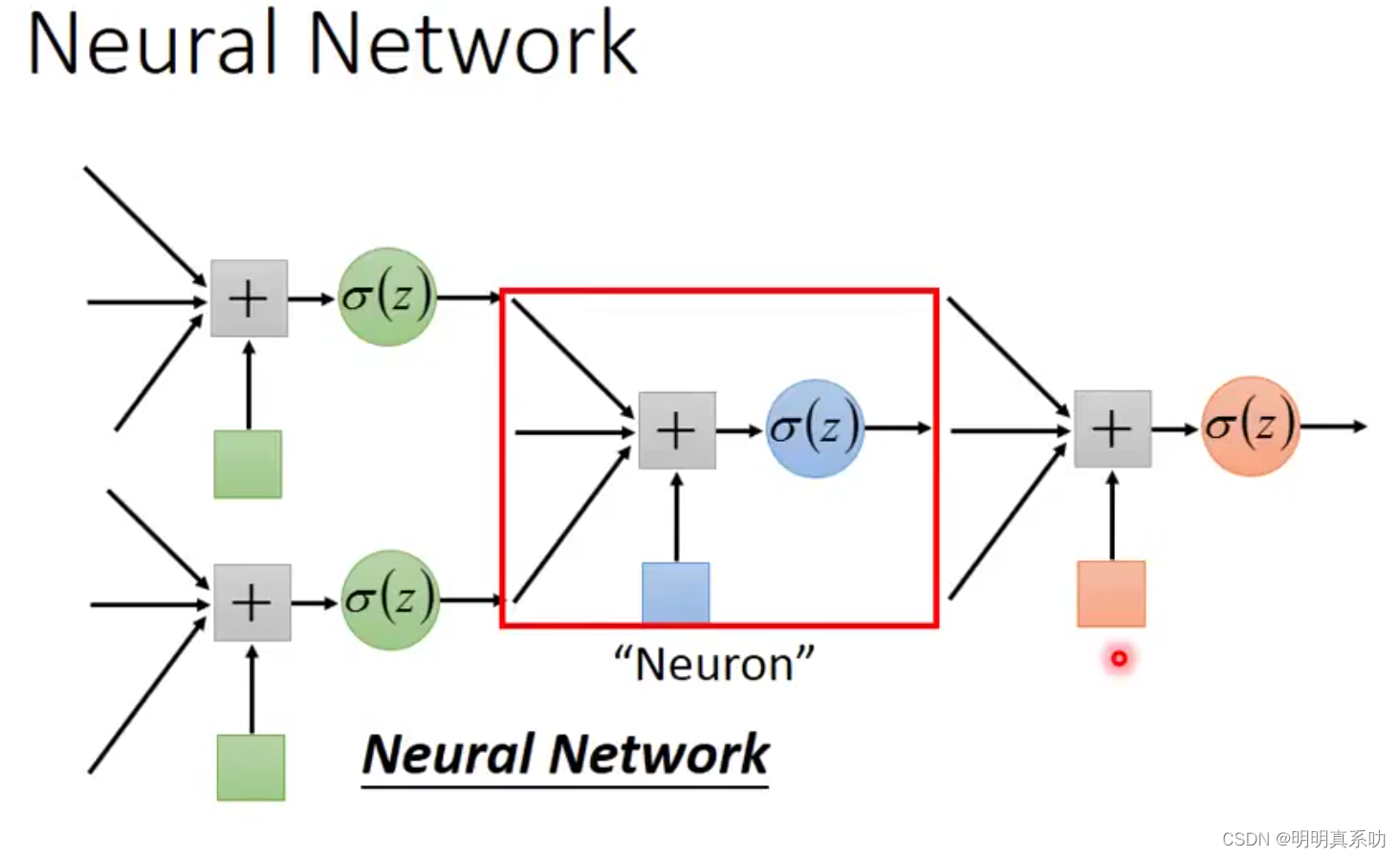
我们可以通过不同的连接方式去连接这些Neural,这样就可以获得不同结构的Neural network。
每个Neuron都有自己的bias(偏置值)和weight(权重),也就是未知数。
所有的Neutron的b和w就称为Neural Network parameter(神经网络参数)
那么我们如何将这些神经元连接在一起呢?
于是便有了以下结构
3.1.2 neural networkfully connected feedforward network(全连接前馈神经网络)
定义:
1.全连接神经网络:对n-1层和n层而言,n-1层的任意一个节点,都和第n层所有节点有连接。
即第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权,这个激活函数是非线性的。
2.前馈神经网络:是一种单向多层结构
其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。
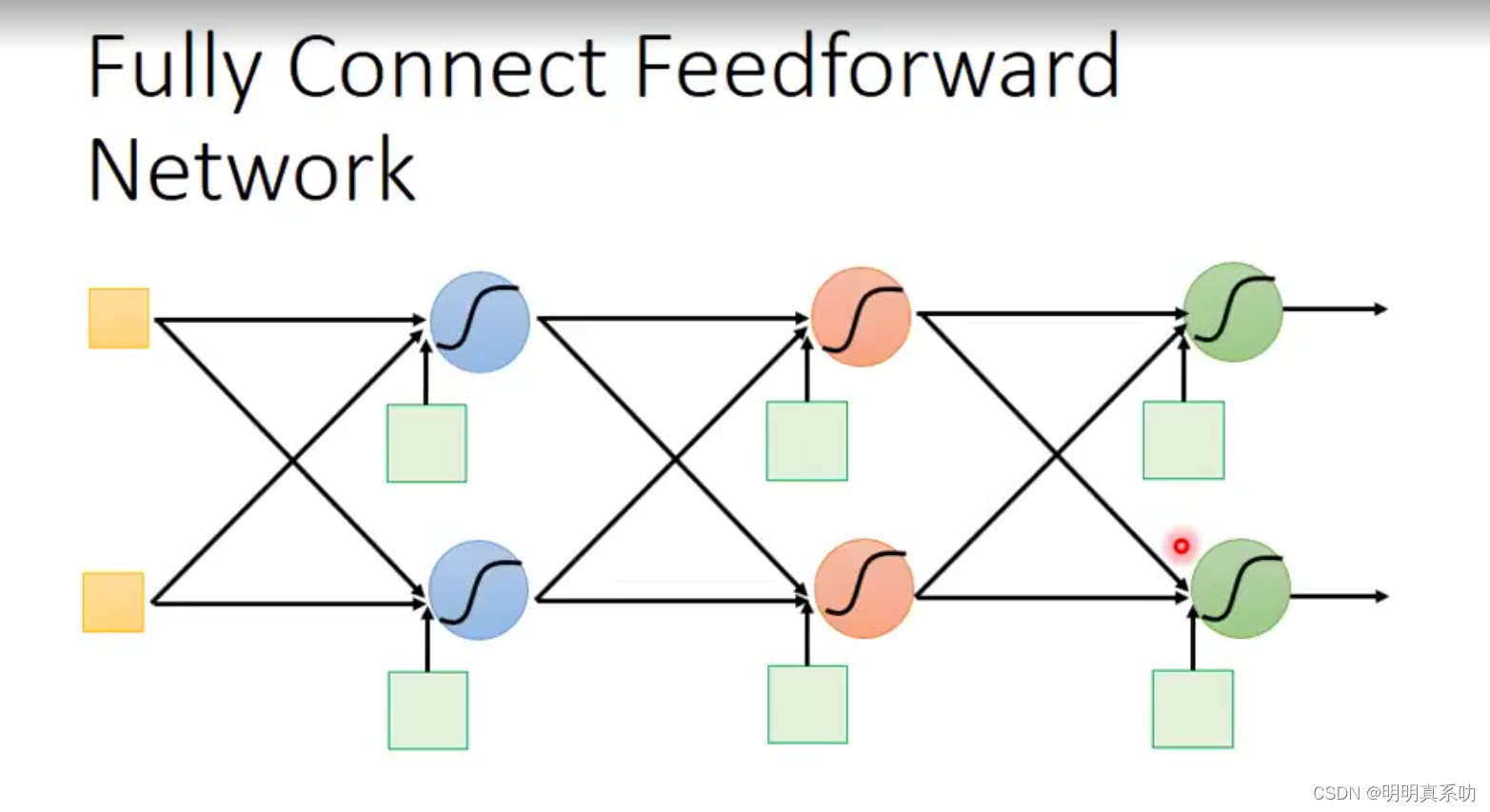
当我们给定一个输入,并且已知w和b的值时,我们就可以进行运算。
方式如下:
1、全连接计算
2、每一层的输入都来自上一层的输出(前馈神经网络定义)
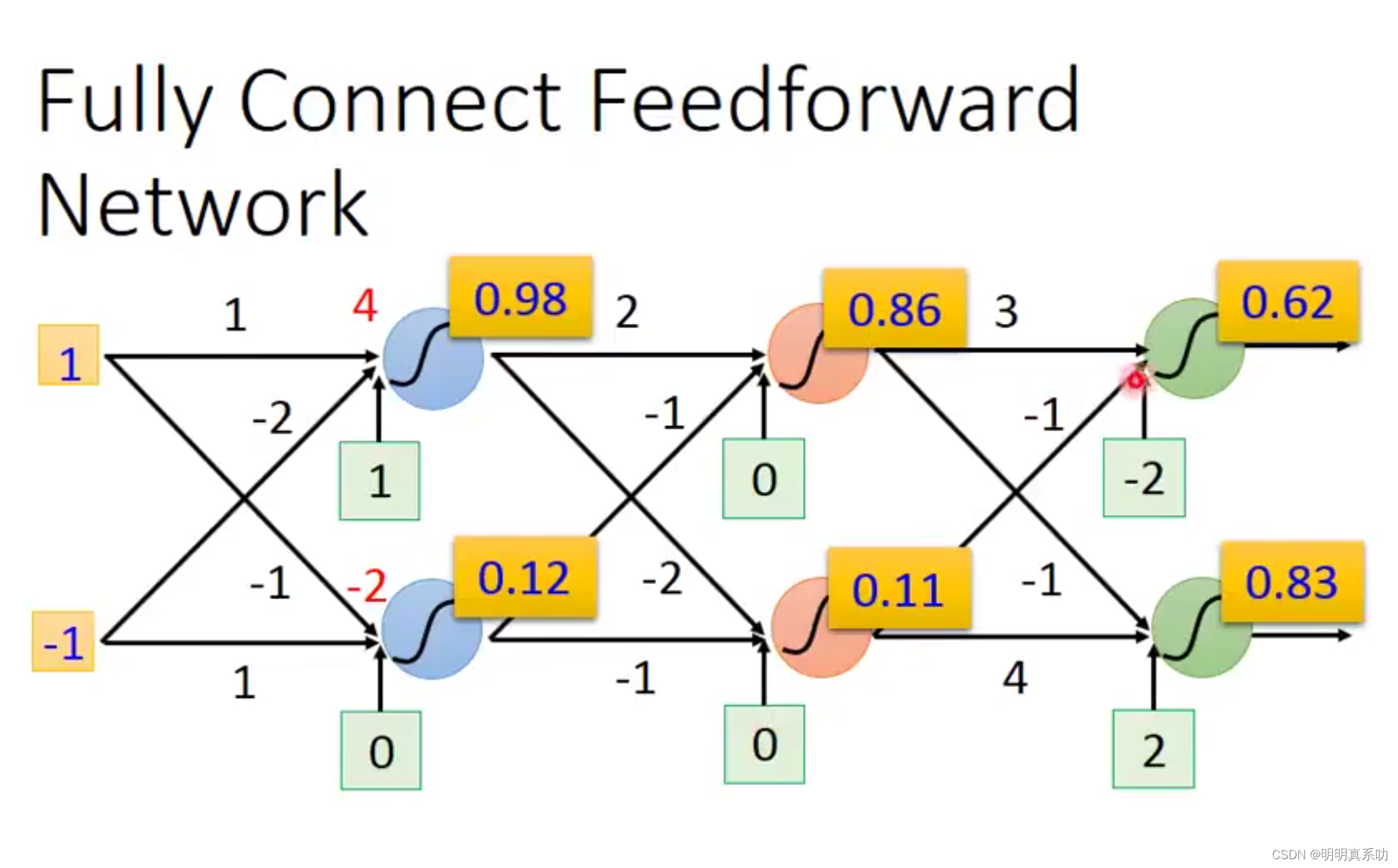
当输入为(1,-1)时,计算过程如下:
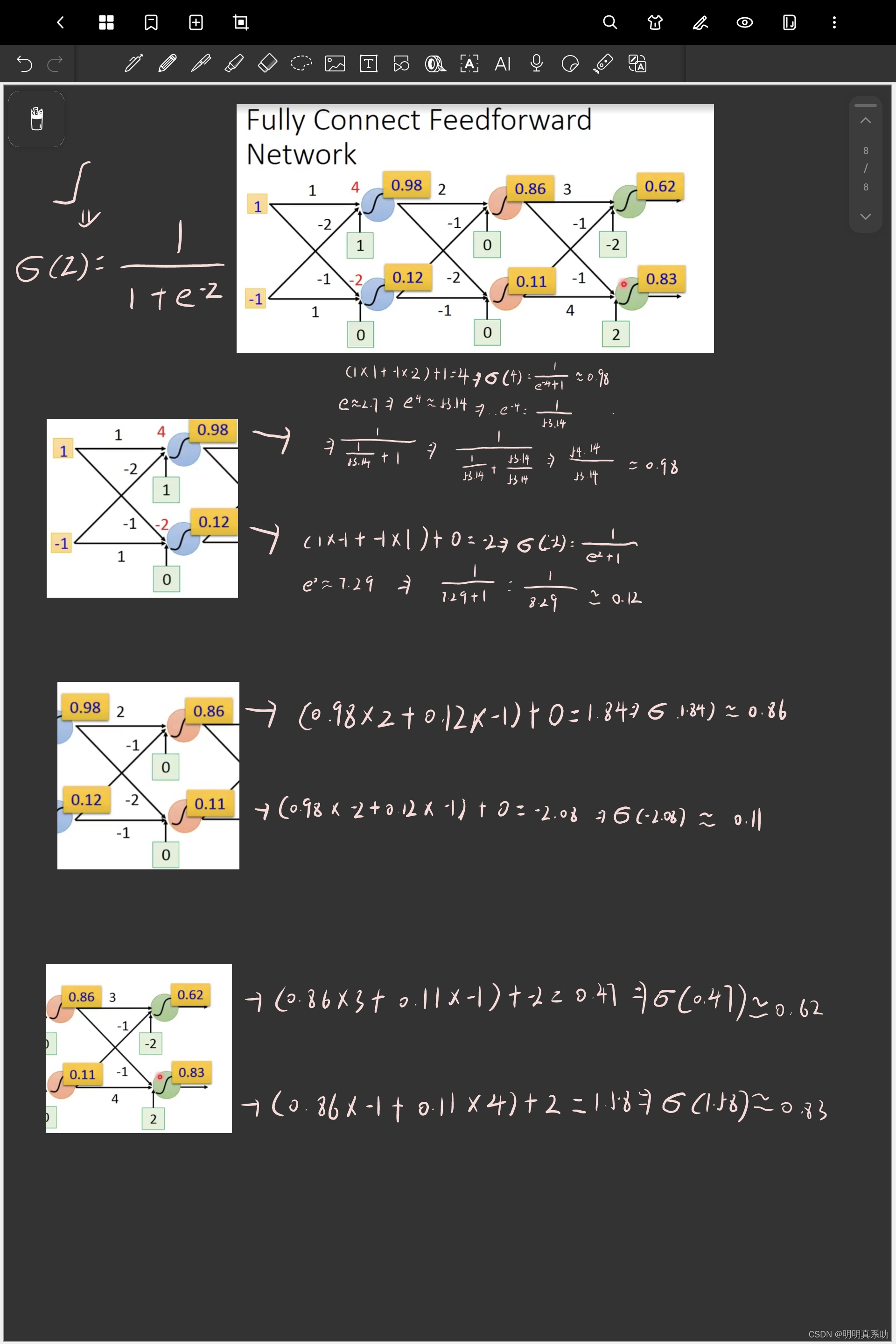
同理,当输入为(0,0)时,可以得到如下结果。
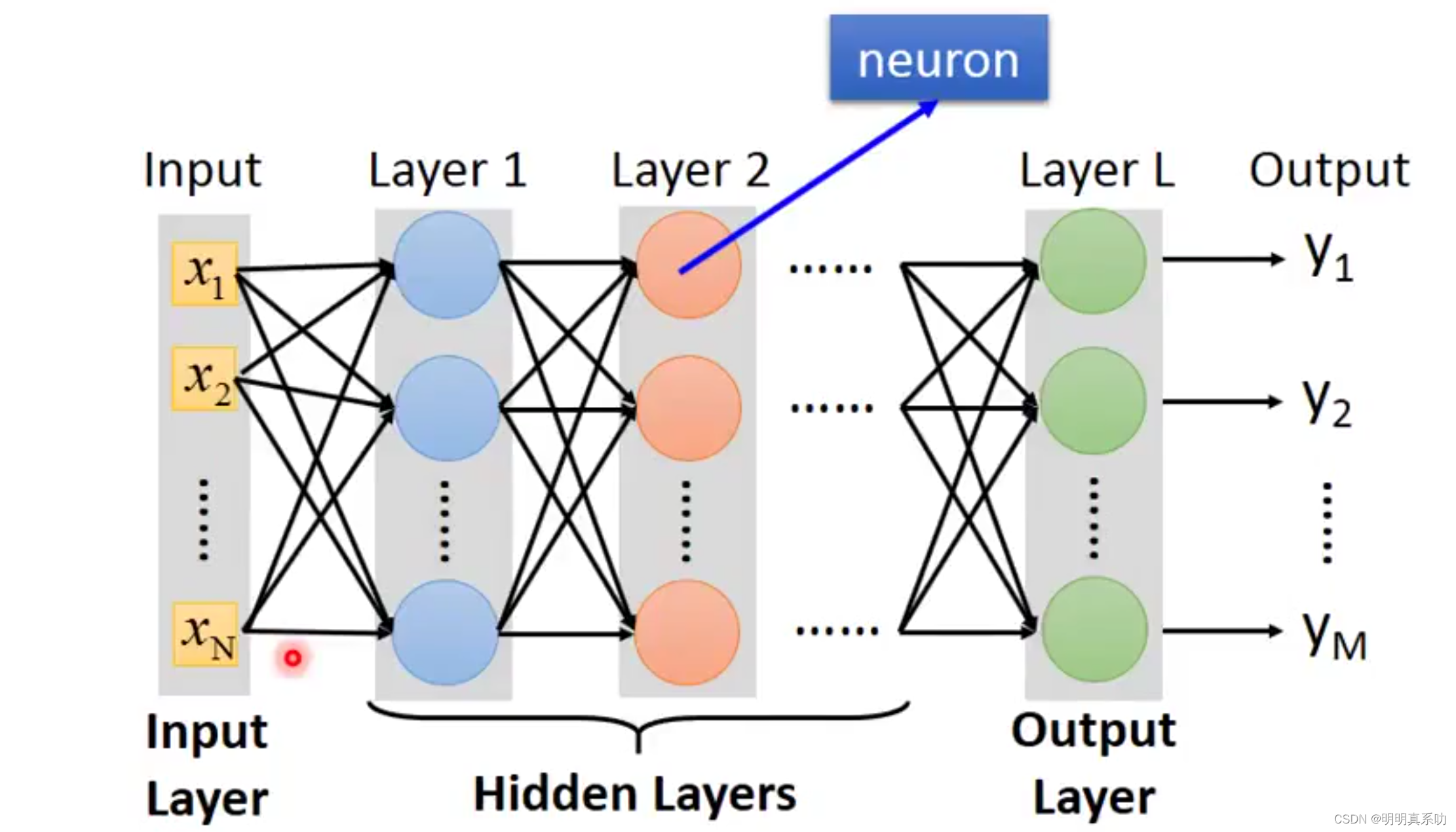
所以一个neural network就可以看作是一个function,其输入是一个vector(向量),output是另一个vector。

当我们不知道neural network里面的未知数值时,仅仅把Neuron按照自己的方式连接起来,即设置好连接的结构,我们就称这个为define a set of function(定义一组函数)
在全连接前馈神经网络结构中,
我们称输入为输入层,x1…xn是vector,n表示输入的Dimension(维度)
中间层称为hidden layer,其中每一个圆圈表示一个neuron,其结果都是类似我们上面的计算得来的。
输出层结果叫做输出层,即最后的计算得出的一组结果,其也是一个vector。
3.1.3 Matrix Operation(矩阵运算)
那么刚刚我们一直有提到vector这个词语,那么我们可以联想一下,我们这些运算是不是跟线性代数的矩阵相关呢?
其实是对的,我们可以把运算过程列成下面的形式,然后再进行计算,结果是完全一致的。
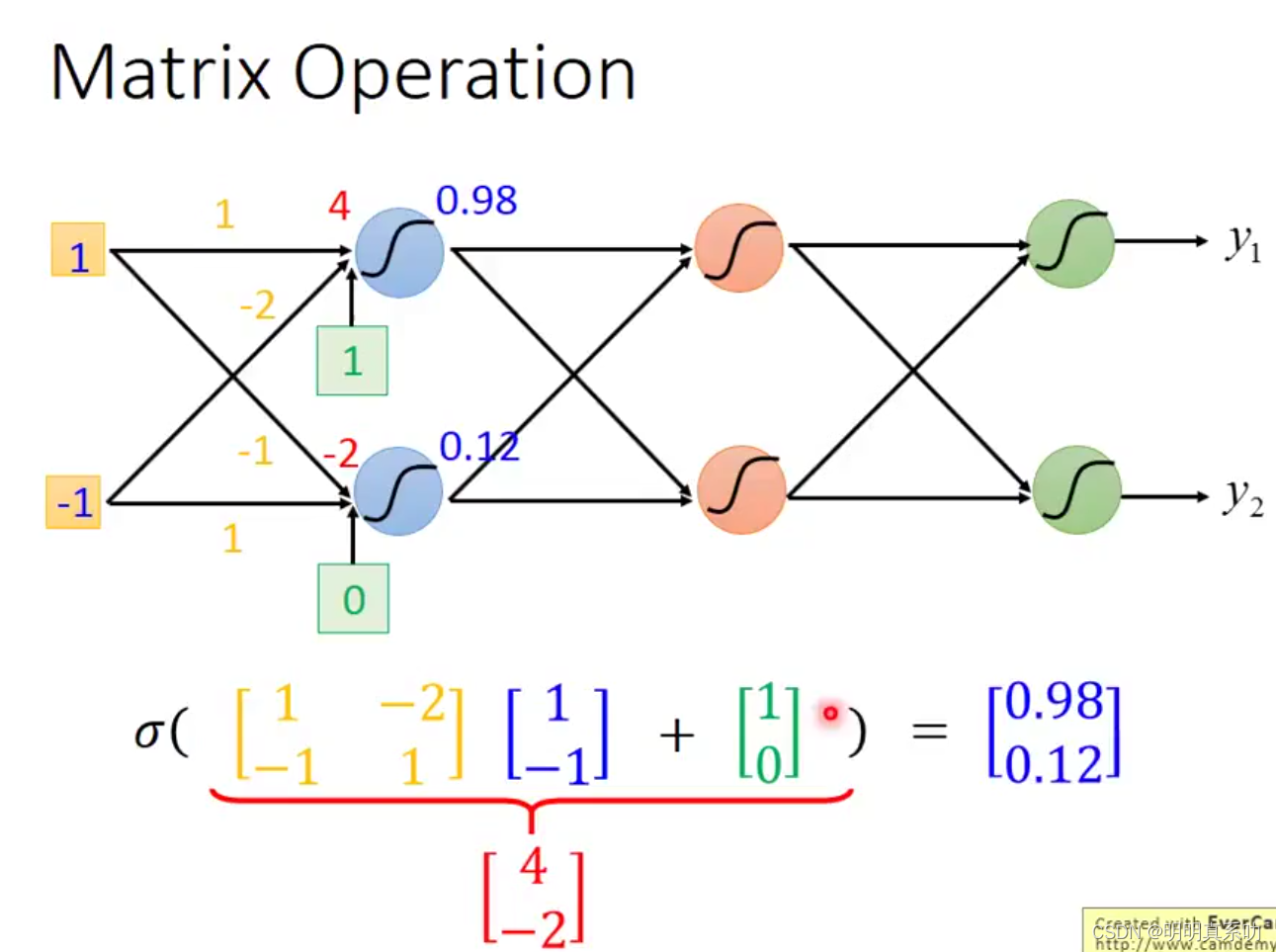
于是我们可以把这个过程用矩阵运算的形式去概括
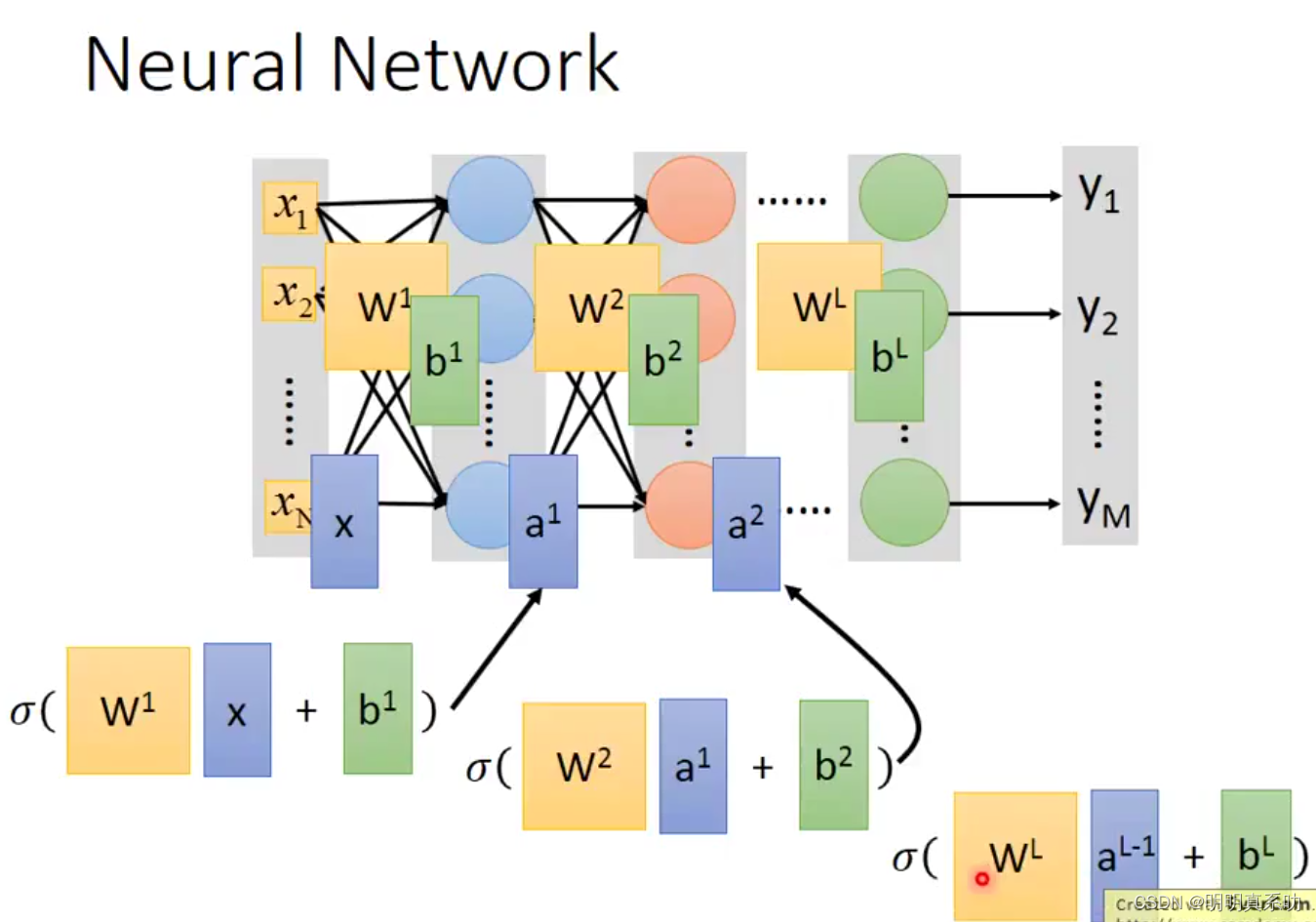
使用嵌套的表达方式如下:
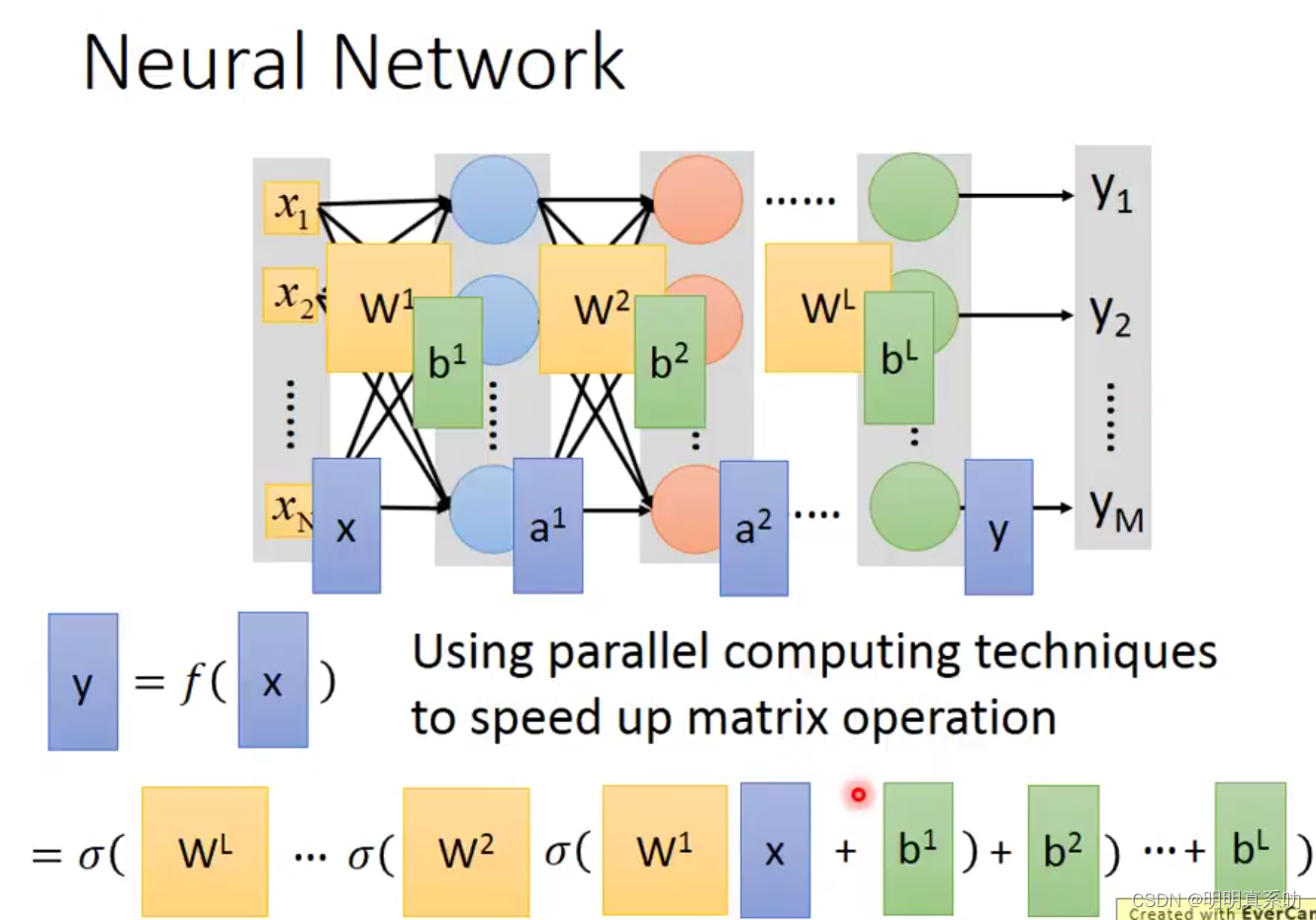
那为什么要用矩阵运算方式来计算呢?
因为这样可以发挥我们GPU的算力,使复杂的运算都交给机器完成,加速我们的训练过程。
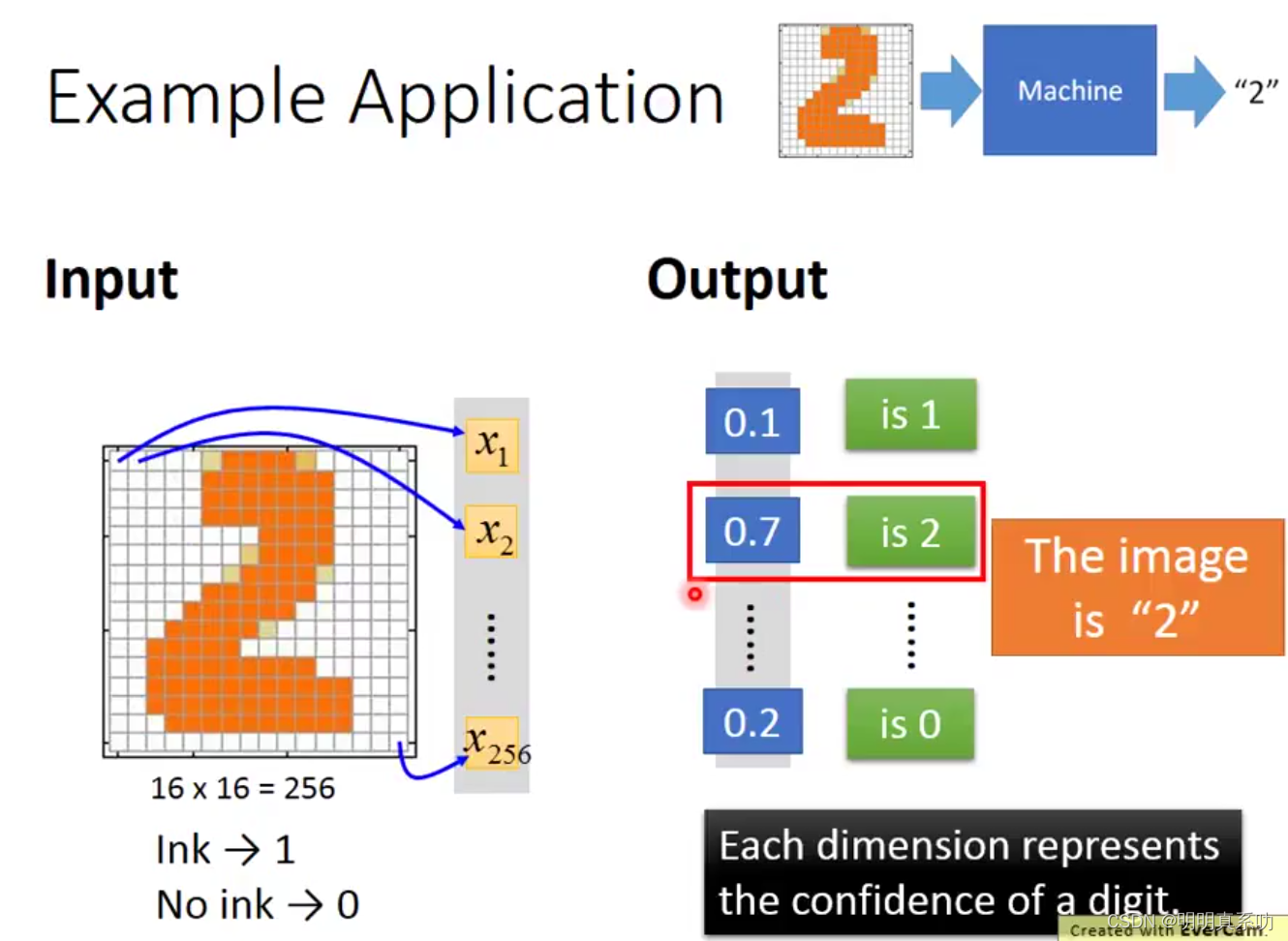
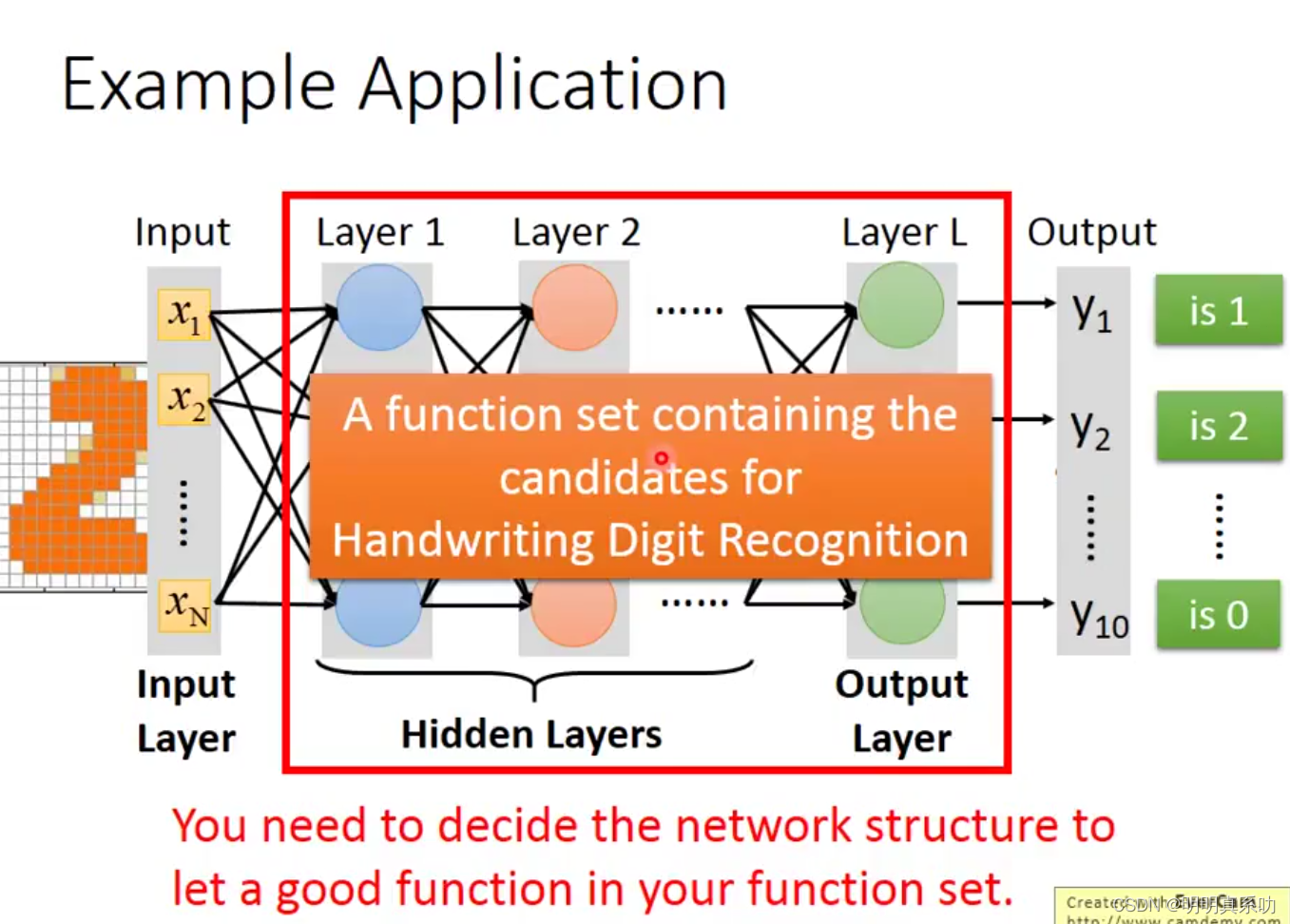
在我们的深度学习应用中,有一个应用的例子就是我们可以对图像进行预测,例如给出一个手写的2,让机器识别出数字2。
那么要怎么实现呢?
例如下图中,这个数字2共有256个pixel(像素),所以我们x1对应第一个pixel,x2对应第二个pixel以此类推,所以我们的输入层总共有256维。
其中可以把涂黑的表示为1,没有涂黑的表示为0
然后我们输出就只有10维,其中y1表示数字1,y2表示数字2…y10表示数字10.
经过一些列运算后,我们可以看到y2的值为0.7,所以机器会觉得是数字2的概率最大,于是便输出结果为2.
一般我们的output layer 都会加上softmax函数,其通过在hidden layer中选出最佳的feature,最后经过softmax从而更好的完成分类任务。
softmax函数,又称归一化指数函数。
它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
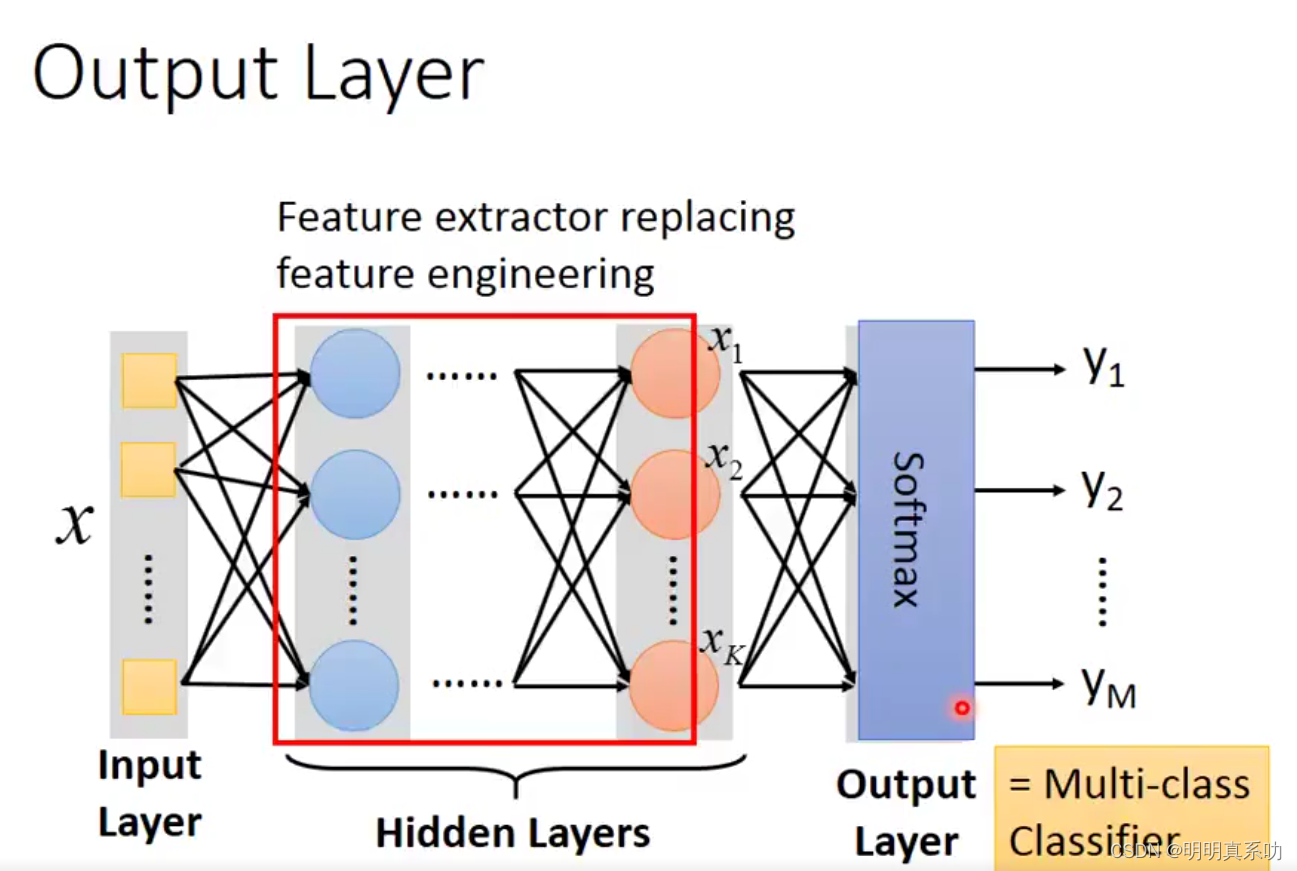
在我们这个例子中,我们设计出我们的输入层是256维,输出层是10维。但是我们的中间的神经网络构需要我们自己去设计,不同的结构会有不同的效果,如果我们的结构太差,就算参数再怎么好,都无济于事。所以我们一开始定义一个好的网络结构是非常重要的。
3.2 第二步:模型评估(goodness of function)
我们的模型结构设计完成后,就要对其进行评估。
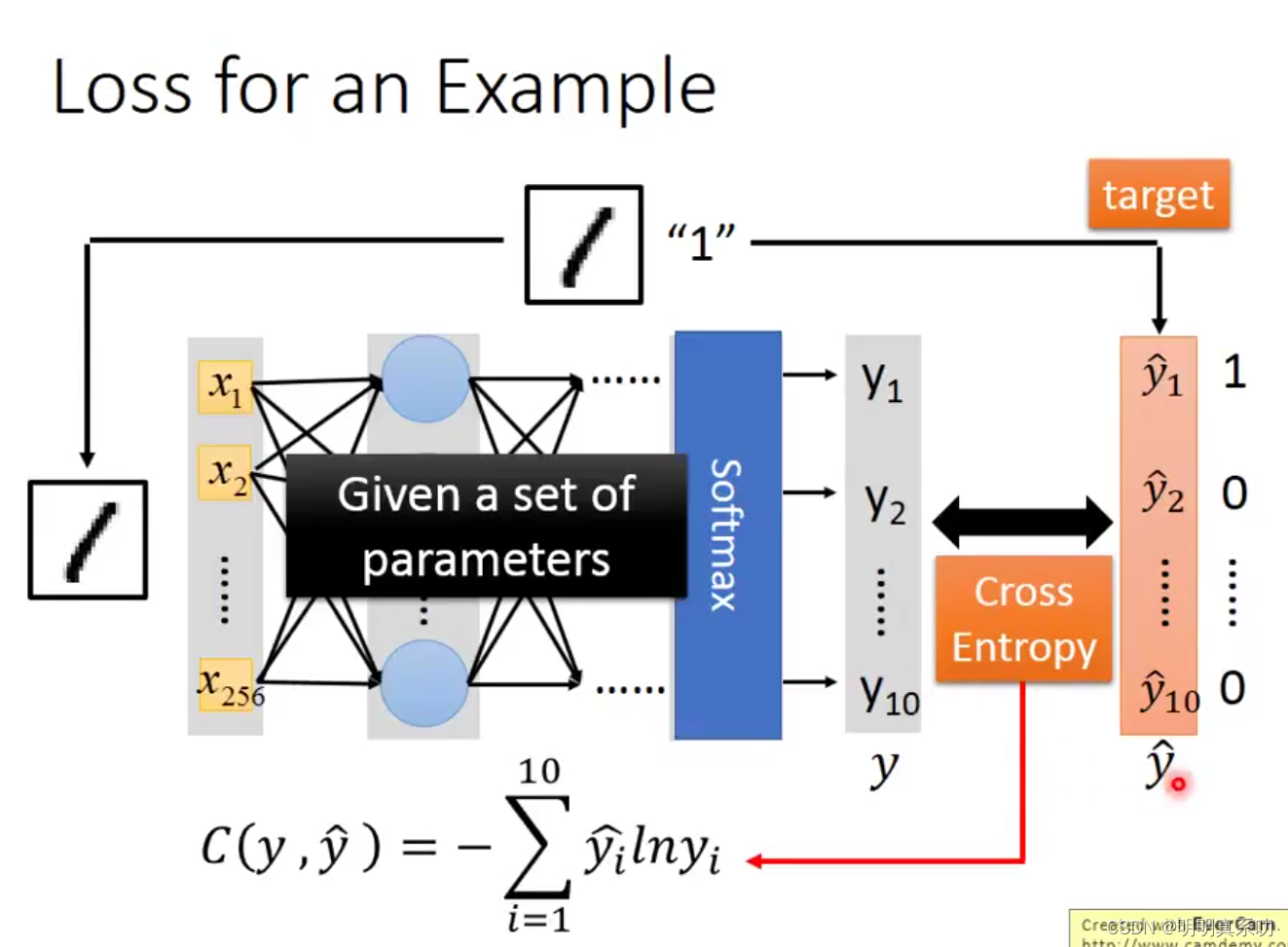
假设我们先输入一张手写的数字1,看看预测效果。步骤如下:
1.我们通过我们的neural network 算出我们y1…y10的值。
2.然后真实值中,只有ŷ₁对应的数字值是1,其他的ŷ₂…ŷ10都为0。
3.然后再对预测值和真实值进行交叉熵运算,得出结果。
交叉熵(cross entropy)
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。
交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
4.我们把数据集中所有的手写数字进行如上方式的计算,然后计算出total loss。后面就可以开始第三步了。
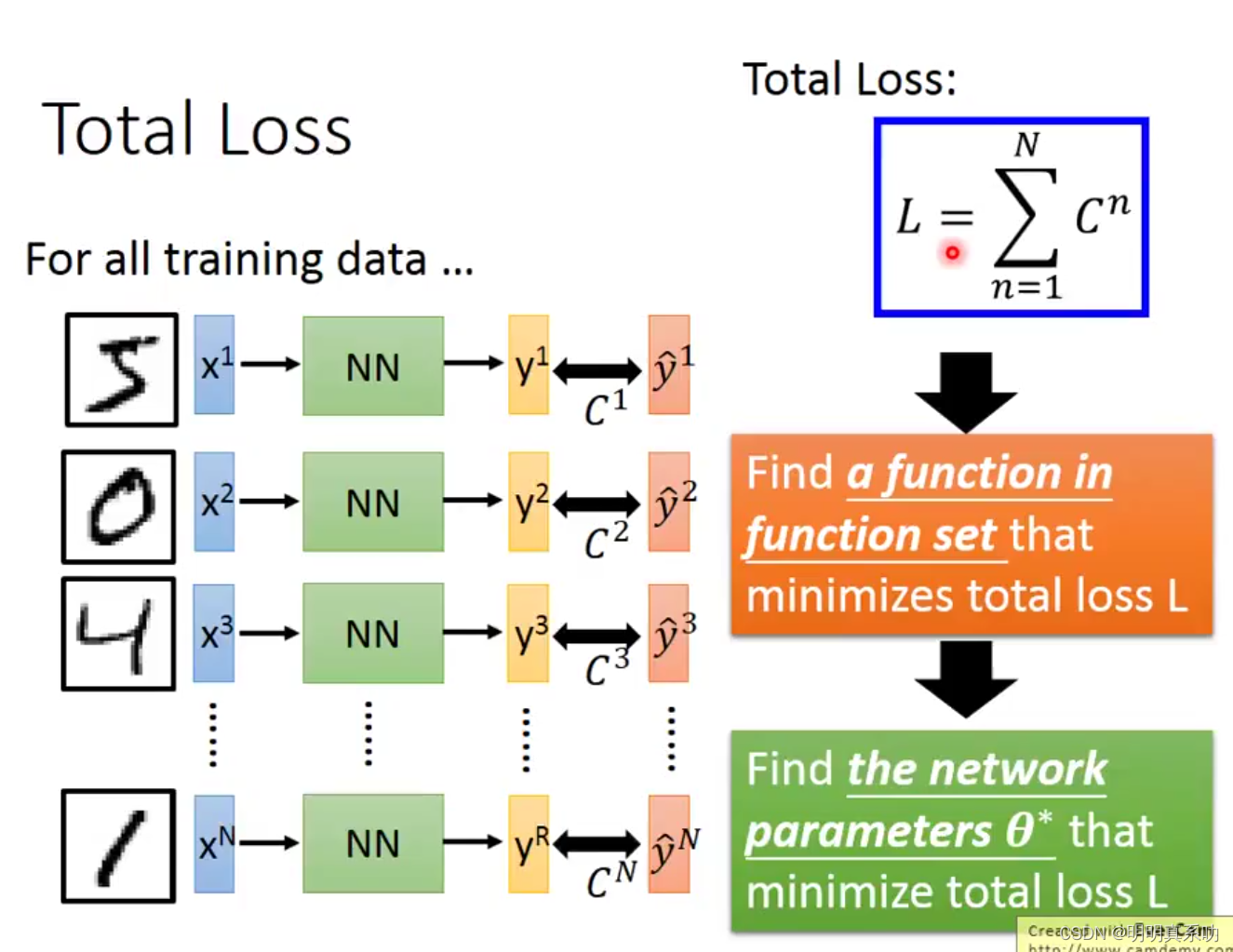
3.3 第三步:选择最优函数(Pick the best function)
怎么找到最佳的θ呢,从而使 total Loss最小呢?(即确定最佳的函数)这就是我们一直提到的的梯度下降算法。过程就不再赘述了,以后有机会要深究一下梯度下降算法的原理。
注意:下图中0.2、-0.1、0.3都是随机取得值,和前面的方式一致。
 之后使用初始值以及学习率和偏导值,通过减法运算,不断更新最佳的值,过程如下图所示:
之后使用初始值以及学习率和偏导值,通过减法运算,不断更新最佳的值,过程如下图所示:

三、PyTorch 学习
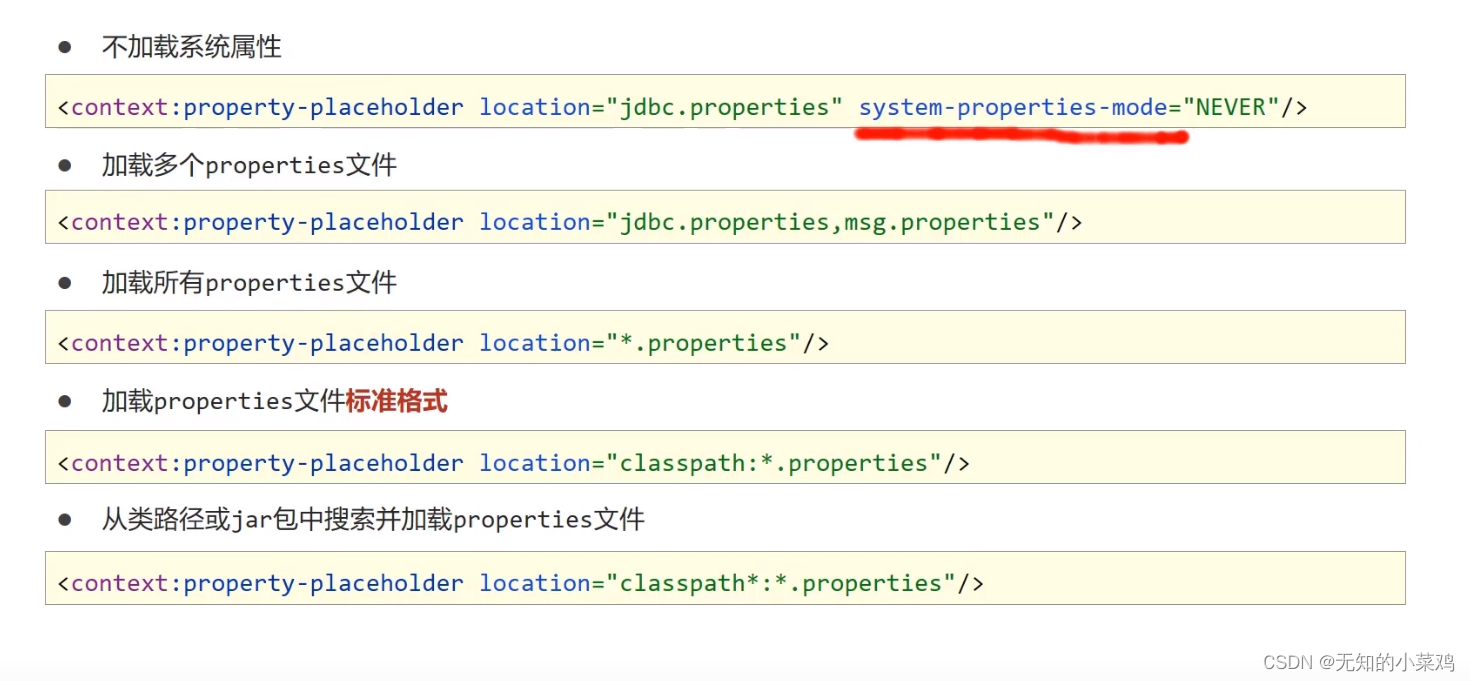
1. PyTorch环境配置
具体包括anaconda、pytorch、pycharm、juypter的安装与配置,可以看下方链接的视频
小土堆的PyTorch教学(环境配置看p1、p2)
最后在控制台(激活pytorch的情况下)、pycharm、juypter的环境中输入
import torch
torch.cuda.is_available()
若都返回true则都是正确的。
2. PyTorch学习的两大重要法宝
dir():打开工具箱,看看里面有什么工具。
help():工具的具体作用。
我们的pytorch就是一个工具箱,里面有许许多多的工具,一个大的工具箱又有包含小的工具箱和工具。
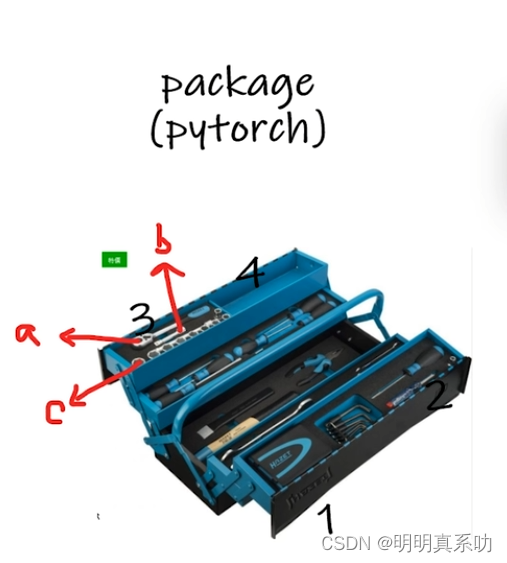
比如:
我使用dir(torch),输出了1、2、3(是工具箱里面的又一个小工具包)、4。
然后就可以使用help(1)、help(2)…看看1、2、4用法
或者又可以dir(3),看看3里面有什么,再去使用它。
实际应用:
接下来,我们到pycharm中,打开项目使用这两个函数。
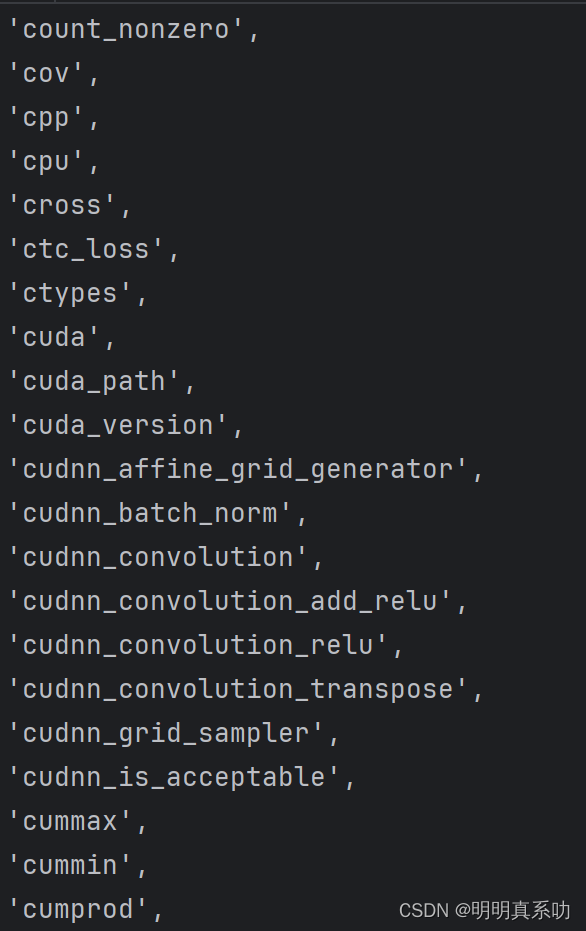
我们再dir(cuda),来对这个工具箱进行打卡,可以发现,我们之前验证的is_available函数就在这里
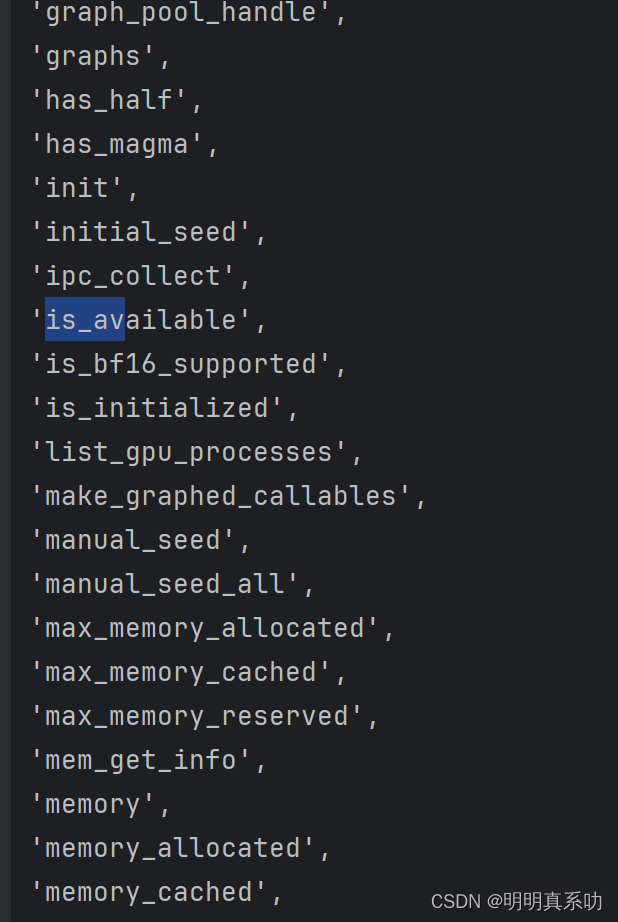
当我们在对is_available进行dir时,会发现其里面的内容都是双下划线
出现这种双下划线,证明这里面都是一些不可更改的变量,所以is_available就是一个可以使用的函数(相当于工具)

于是我们对其使用help函数,即可查看这个函数的用法
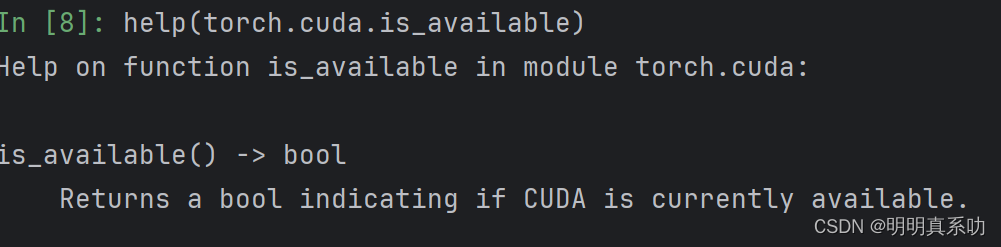
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。
这个help就是说明了cuda(显卡)是否可用的意思,返回一个bool类型。
3. PyCharm及Jupyter使用以及区别
当我们在pycharm、控制台、jupyter分别输入这几个函数时,我们可以发现如下规律:
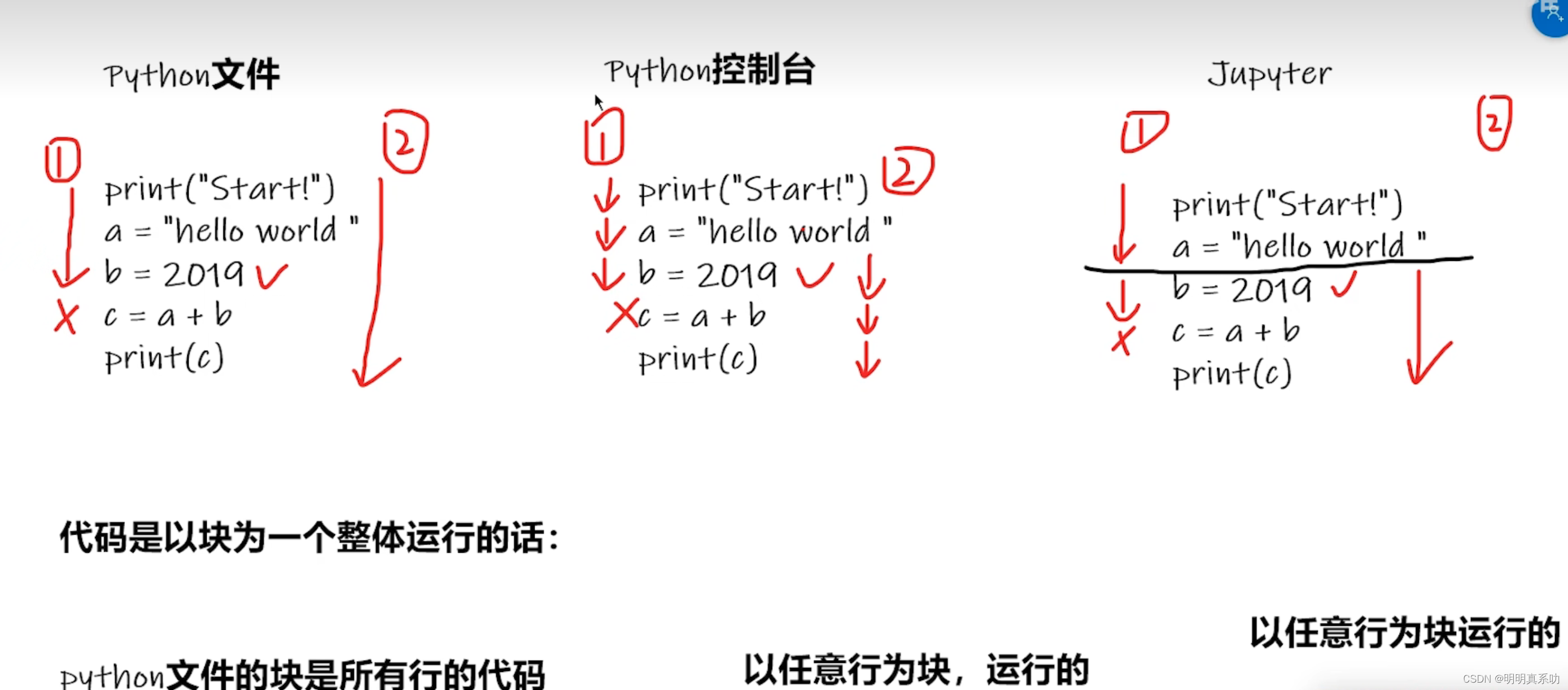
总结,这三种模式各有千秋,总结如下:
| 模式 | 优点 | 缺点 |
|---|---|---|
| python文件 | 通用,适用于大型项目,方便传输 | 需要从头开始运行(因为整个代码就是一个块) |
| pycharm控制台 | 以任意行为单位运行,且显示每个变量属性 | 不利于代码阅读以及修改 |
| jupyter | 利于代码阅读以及修改,一般用作小项目上 | 需要前期繁杂的环境配置 |