文章目录
- 图像超分辨率(Image Super-Resolution, ISR)
- 1 什么是图像超分辨率?
- 2 图像超分辨率通常有哪些方法?
- (1)基于插值的方法
- (2)基于重建的方法
- (3)基于学习的方法(LR image in, HR image out)
- (4)基于隐式神经表示的方法(coordinates in, corresponding intensity out)
- 1.基于坐标的表示
- 2.连续表示
- 3.INR的特点
- 4.一些基于INR的方法
图像超分辨率(Image Super-Resolution, ISR)
1 什么是图像超分辨率?
超分辨率(Super-Resolution)即通过硬件或软件的方法提高原有图像的分辨率,通过一系列低分辨率的图像来得到一幅高分辨率的图像过程就是超分辨率重建。
2 图像超分辨率通常有哪些方法?
(1)基于插值的方法
通过数学插值算法来估计高分辨率图像像素值。
- 双线性插值:计算四个邻近像素的加权平均值。
- 双三次插值:使用16个邻近像素进行加权平均,效果较双线性插值更好。
- Lanczos插值:通过更复杂的数学公式进行插值,能保留更多的细节。
(2)基于重建的方法
通过建立图像的先验模型,利用优化算法进行重建。
- 稀疏表示方法:假设图像可以用少数基向量表示,通过稀疏编码和字典学习进行超分辨率重建。
- 正则化方法:加入各种正则化项(如全变分、边缘保留等)来抑制噪声,恢复图像细节。
(3)基于学习的方法(LR image in, HR image out)
随着深度学习的发展,基于学习的方法在图像超分辨率中取得了显著的进展。主要包括:
-
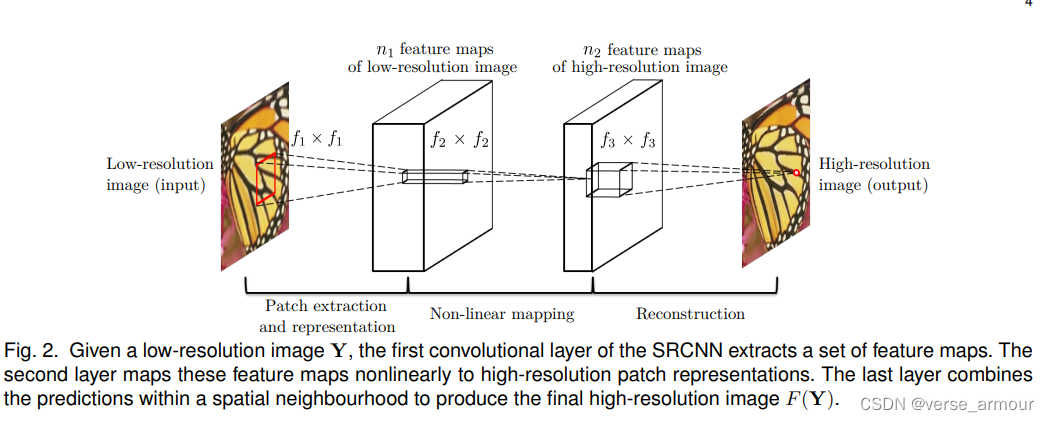
卷积神经网络(CNN):如(2015年)SRCNN(Super-Resolution Convolutional Neural Network),通过多层卷积网络提取特征,恢复高分辨率图像。
Image Super-Resolution Using Deep Convolutional Networks
具体细节:SRCNN直接处理图像数据。它接受低分辨率图像作为输入,通过一系列卷积层提取特征,最终生成高分辨率图像。SRCNN学习从低分辨率图像到高分辨率图像的映射关系,但这个映射关系是通过网络的权重和偏置存储的。每次超分辨率操作都需要输入具体的图像数据。
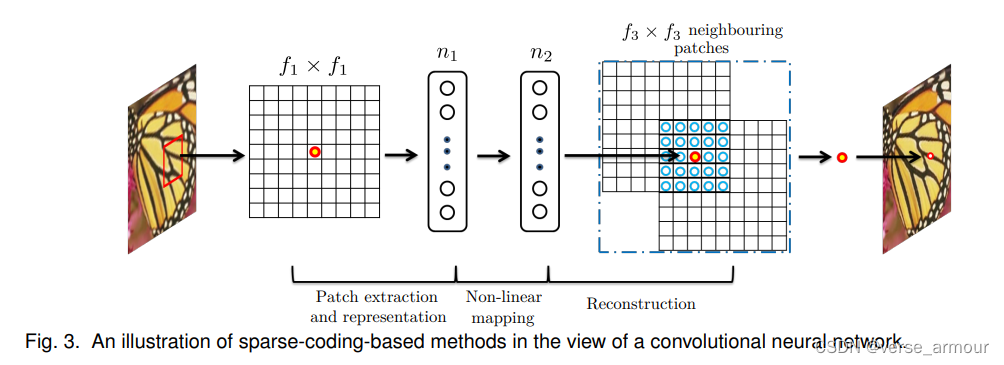
-
生成对抗网络(GAN):如SRGAN(Super-Resolution Generative Adversarial Network),通过生成器和判别器的对抗训练,生成更为逼真的高分辨率图像。
具体细节:SRGAN也直接处理图像数据。生成器接受低分辨率图像生成高分辨率图像,判别器则区分生成的图像与真实高分辨率图像。SRGAN学习从低分辨率图像到高分辨率图像的映射关系。生成器的权重和偏置参数存储了这个映射关系。
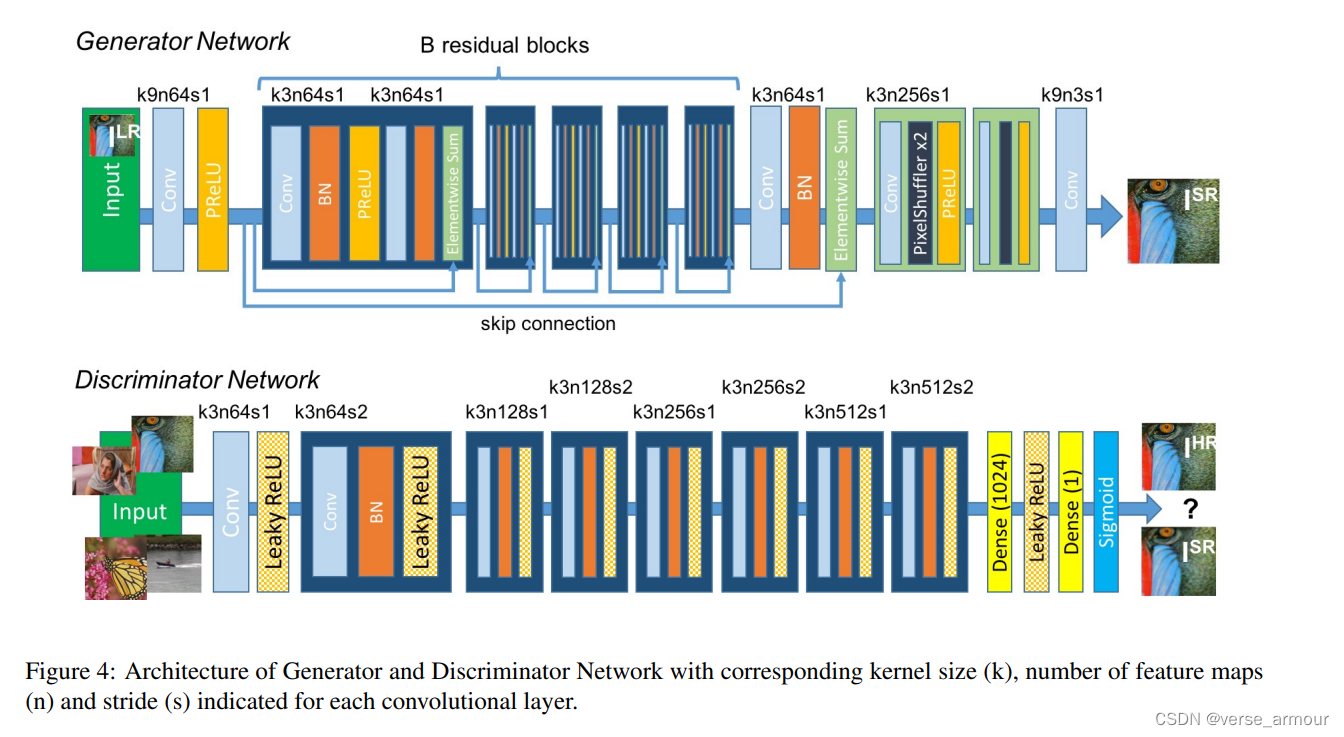
这里的HR指的是真实的高分辨率图像(real image),SR指的是生成器生成的高分辨率图像(fake image) -
自编码器和变分自编码器(VAE):利用编码器和解码器结构学习图像的低维表示,并重建高分辨率图像。
Image Super-Resolution With Deep Variational Autoencoders
具体细节:VAE通过编码器将输入图像编码为一个低维潜在变量,然后通过解码器将潜在变量重新生成高分辨率图像。VAE存储的是从输入图像到潜在变量的编码映射,以及从潜在变量到生成图像的解码映射。这些映射关系通过网络的权重和偏置参数表示。
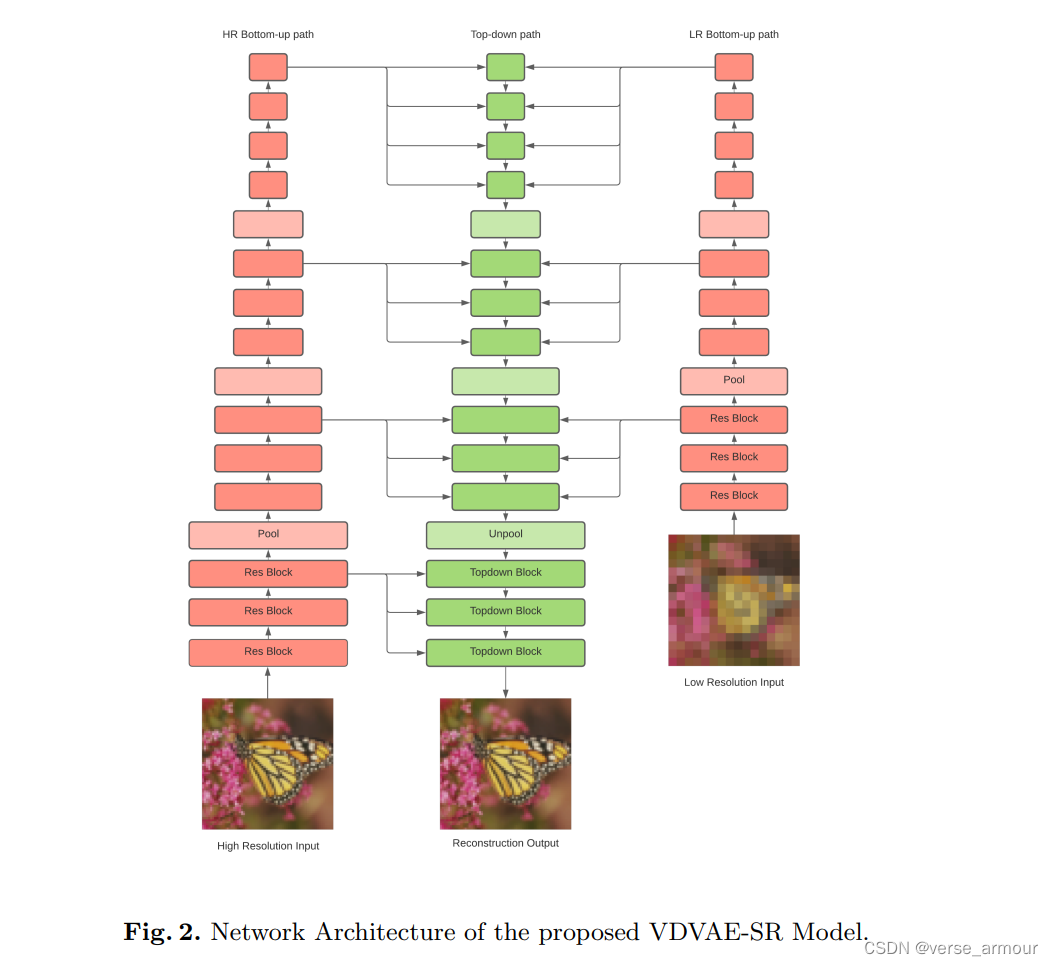
(4)基于隐式神经表示的方法(coordinates in, corresponding intensity out)
隐式神经表示(Implicit Neural Representations, INRs)是一种新兴的技术,在图像超分辨率及其他计算机视觉任务中表现出色。INRs使用神经网络来表示连续函数,可以用于表示图像、3D形状等数据。
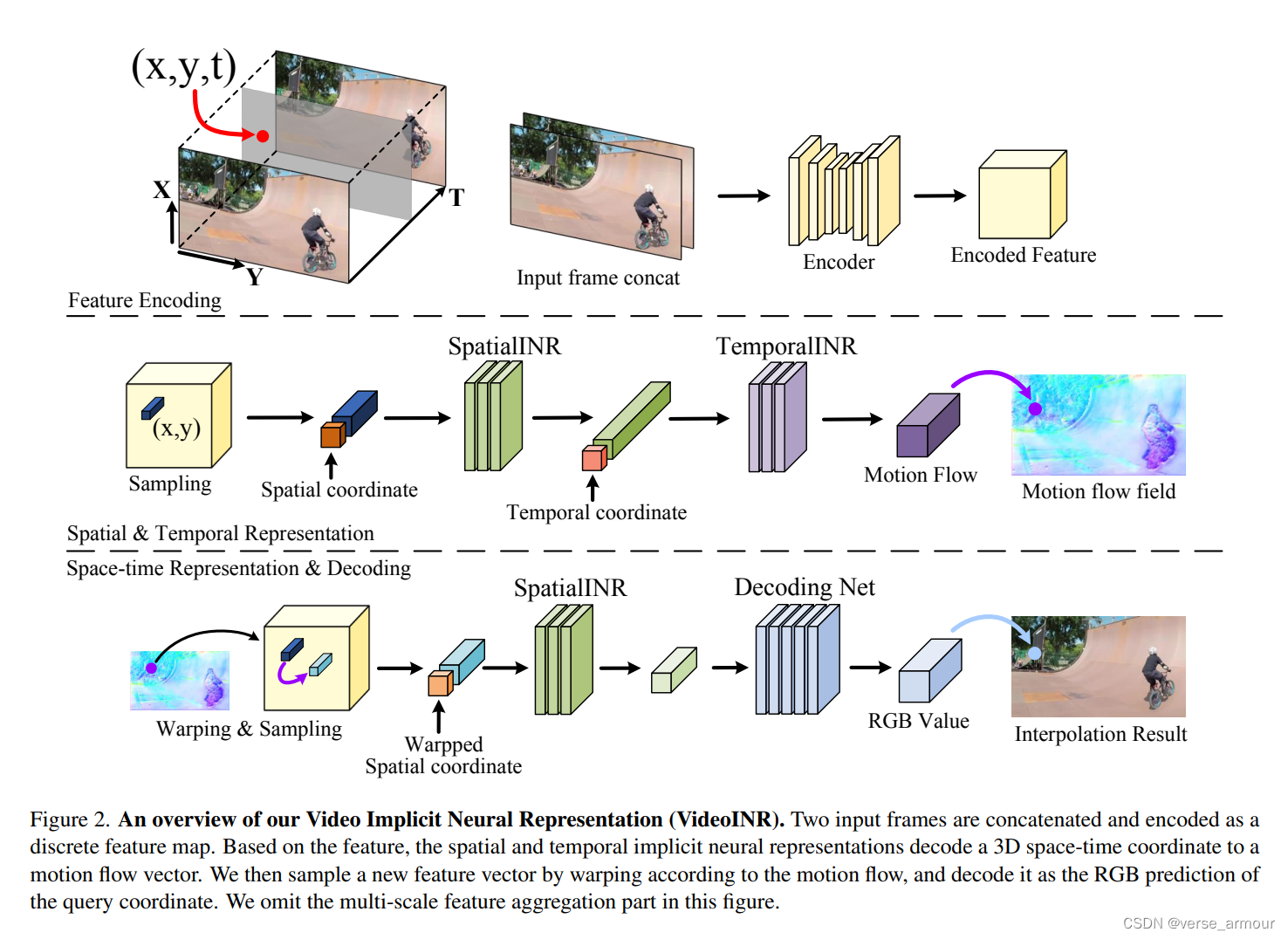
VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution
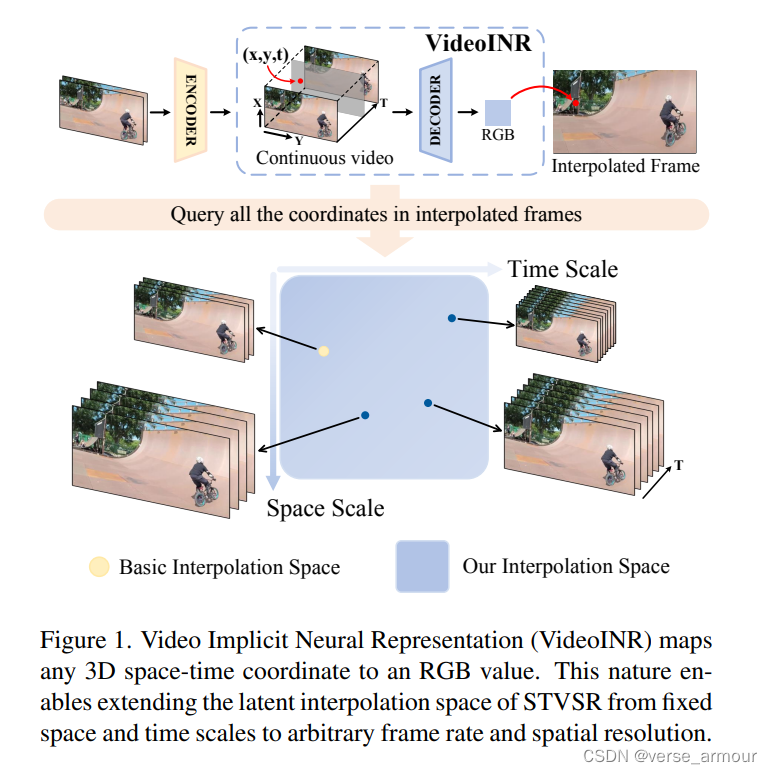
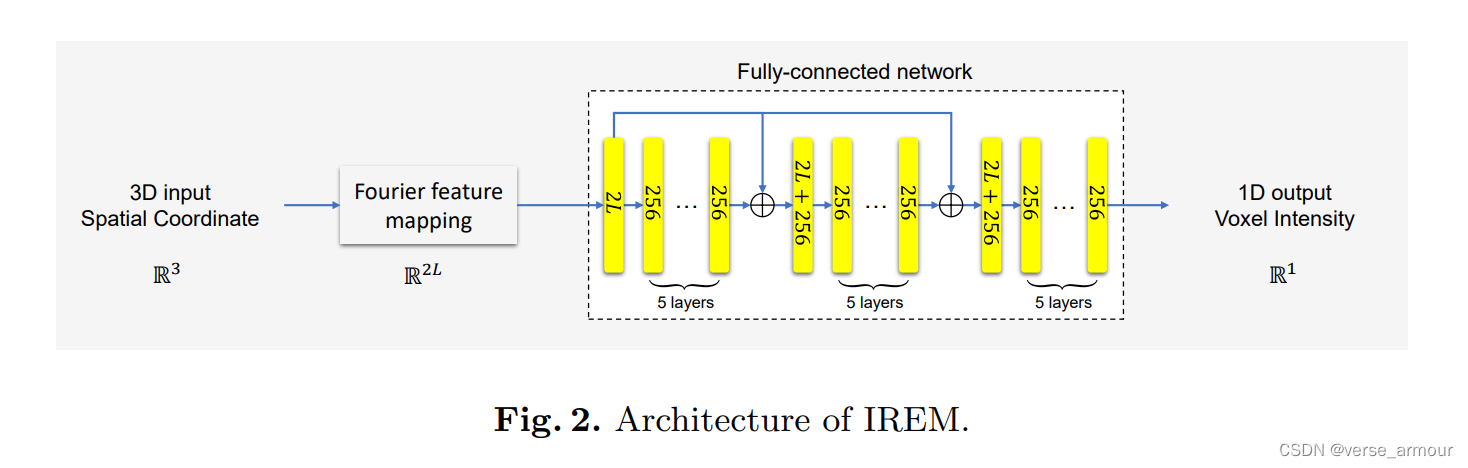
IREM: High-Resolution Magnetic Resonance Image Reconstruction via Implicit Neural Representation
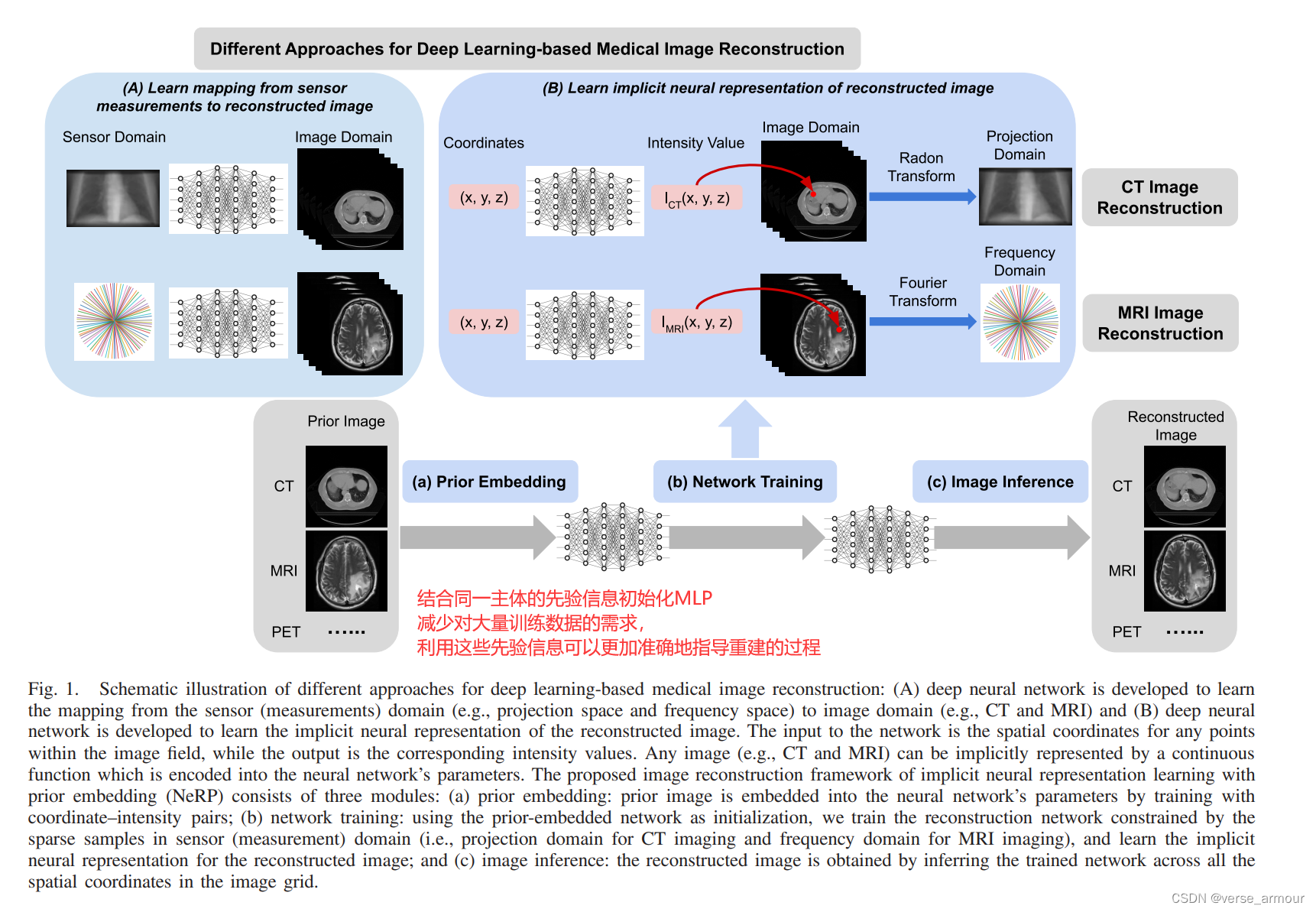
NeRP: Implicit Neural Representation Learning With Prior Embedding for Sparsely Sampled Image Reconstruction
1.基于坐标的表示
INRs通过神经网络将输入坐标(如图像的(x, y)坐标)映射到相应的像素值。这种方法不直接存储图像像素,而是存储一个映射函数。
2.连续表示
由于神经网络可以表示连续的函数,INRs可以自然地处理不同分辨率下的图像表示。通过查询任意坐标,INRs可以生成不同分辨率的图像。在图像超分辨率任务中,INRs通过学习一个低分辨率图像的隐式表示(这个隐式表示就是上面提到的一个从坐标到像素值的一个映射函数,通常是随机初始化一个MLP,然后通过学习得到一个参数化好的MLP就是该映射函数),可以生成高分辨率图像。例如,使用一个多层感知机(MLP)网络来映射输入坐标到像素值。
注:为什么使用多层感知机(MLP)作为隐式神经表示的基础结构?
- MLP作为一种通用的函数逼近器,能够表示任意连续函数。 通过适当的训练,MLP可以学习从输入坐标(如图像的(x, y)坐标)到输出值(如像素值)的复杂映射关系。这种能力使得MLP特别适合用于隐式表示数据,如图像或3D形状。
- 使用MLP来表示图像或其他数据,实际上是在存储一个函数而不是数据本身。 这种表示方式在存储空间上更加高效,尤其是对于高分辨率图像。此外,通过查询任意坐标,MLP可以生成对应的像素值,使得生成不同分辨率的图像变得更加灵活和方便。
- 在INRs中,激活函数的选择对网络性能有重要影响。MLP可以结合各种激活函数,如ReLU、正弦函数等,以适应不同的数据特性和任务需求。例如,SIREN使用正弦激活函数,能够更好地表示高频信号。
3.INR的特点
- 高效存储:相比于直接存储高分辨率图像,INRs可以显著减少存储空间。
- 灵活性:可以生成任意分辨率(任意上采样率) 的图像,无需重新训练模型。
- 细节保留:能够在图像放大时保留更多细节。
4.一些基于INR的方法
- SIREN(Sinusoidal Representation Networks):通过使用正弦激活函数的神经网络表示复杂的信号,包括图像。
- NeRF(Neural Radiance Fields):虽然主要用于3D场景表示,但其基本思想也可应用于图像超分辨率,通过隐式函数表示和查询生成高分辨率图像。