引言
当年读书的时候,真正学到数据库的操作之前,先学的内容是关系代数运算,以及相关的关系代数的定律。然后知道了当前比较主流的数据库都是关系型数据库,其底层依赖的是关系代数。
但是,当年考试的时候,只涉及到将SQL语句与关系代数表达式之间进行互相转换,却始终不知道关系代数有啥用,明明SQL语句已经很直观了。
随着对数据库的学习、使用的深入,终于知道了关系代数的用途,并体会到了其中的数学之美。
SQL执行前的准备工作
类似于Python、Java等高级编程语言,从代码到程序的执行,需要进行词法分析、语法分析、解释或者编译等处理工作。一条SQL语句的执行,其实也需要对应的分析与编译工作。
完整的步骤
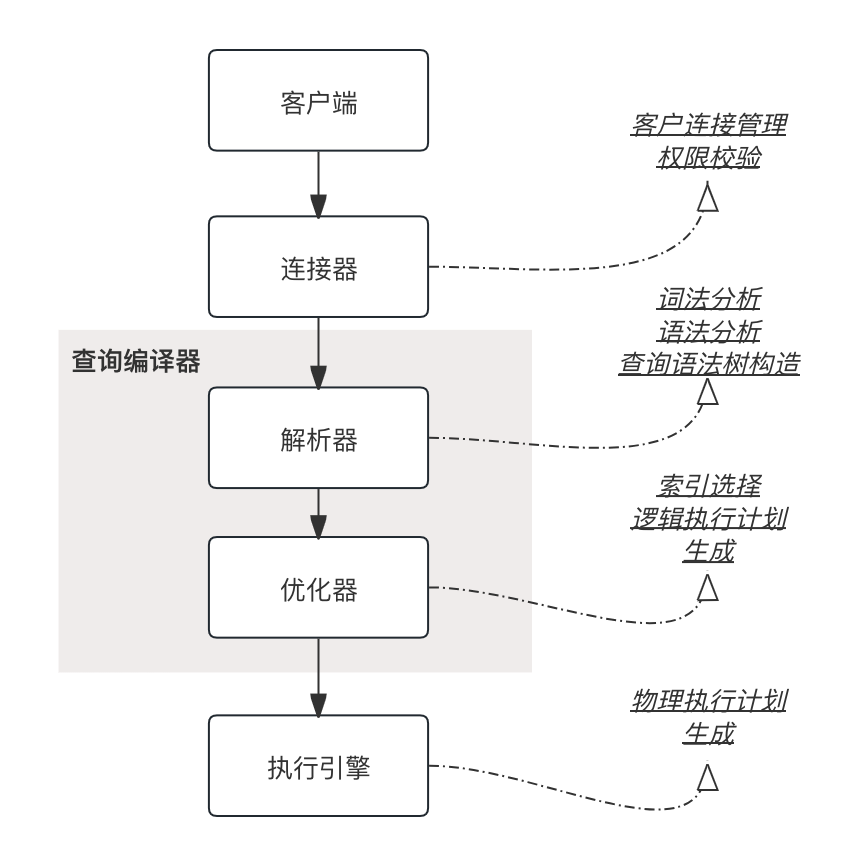
我们首先来看解析器和优化器的工作,这些工作主要涉及到:
-
词法分析,获取语法成分
-
语法分析,构造语法分析树
-
生成并选择相对更优的逻辑执行计划
-
生成物理执行计划
这些工作中,我们重点看这两个主要的环节:从SQL语句到语法分析树,以及从语法分析树到逻辑执行计划。
从SQL到语法分析树
基于数据库实现中相应的解析规则,解析器检查一条SQL语句,并将其转换为一个语法分析树:
语法分析树的节点主要有以下两种:
-
原子:词法成分或者其他模式成分,比如关键字(如SELECT)、表(关系)或者字段(属性)的名字、参数、括号、运算符等
-
语法类:一个查询中起相似作用的查询子成分所形成的族的名称,通常用尖括号括起来表示语法类,比如<Query>表示常用的select - from - where形式的查询、<Condition>表示属于条件的任何表达式等,每一个语法类一般会有多个语法规则。
比如,我们有这样一张表:
create table t_customer(
id int not null auto_increment comment '会员id',
name varchar(32) comment '会员姓名',
gender tinyint not null default 0 comment '会员性别:0未知,1男,2女',
city varchar(32) comment '会员所在城市',
primary key(`id`),
key `idx_city` (`city`)
) comment '会员信息表';我们将要执行的是这样一条SQL语句:
select
id,name
from
t_customer
where
city = '合肥'
and gender = '1'
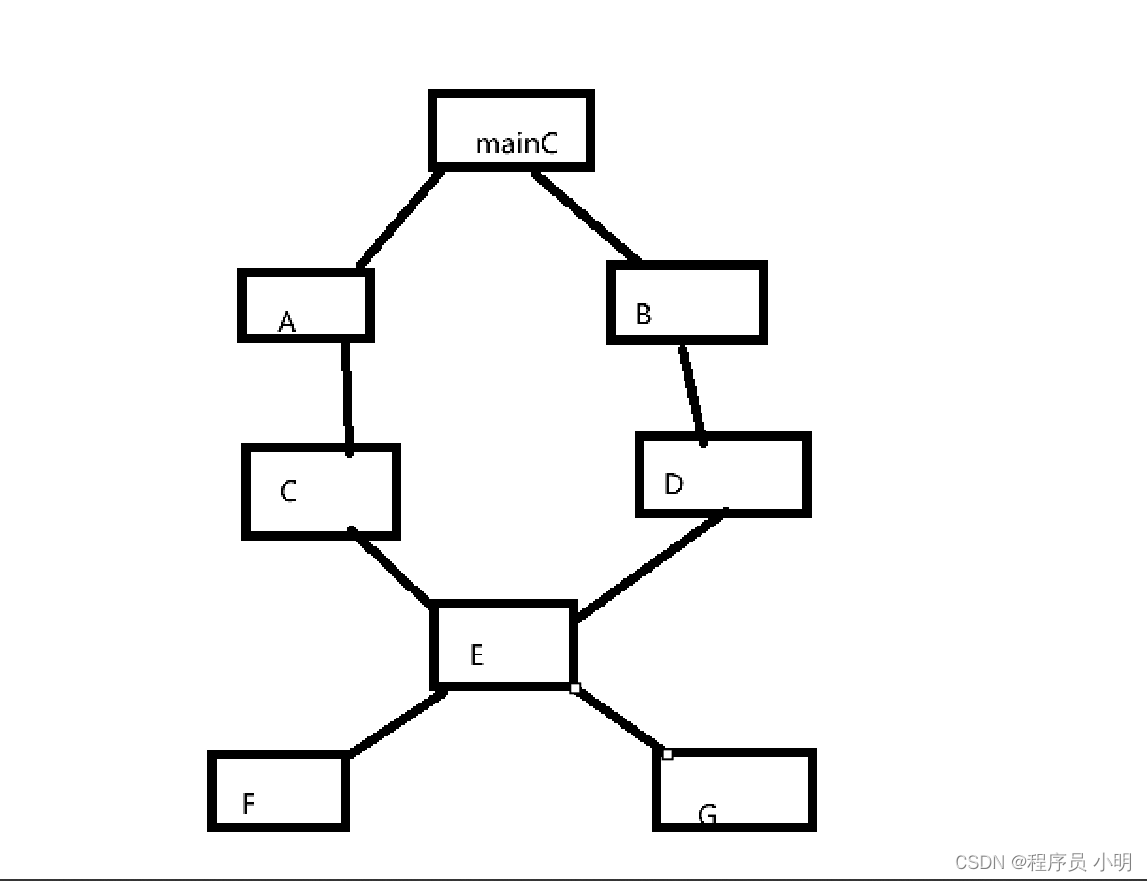
则经过相应的词法分析、语法分析,我们会得到大概这样一棵语法分析树:
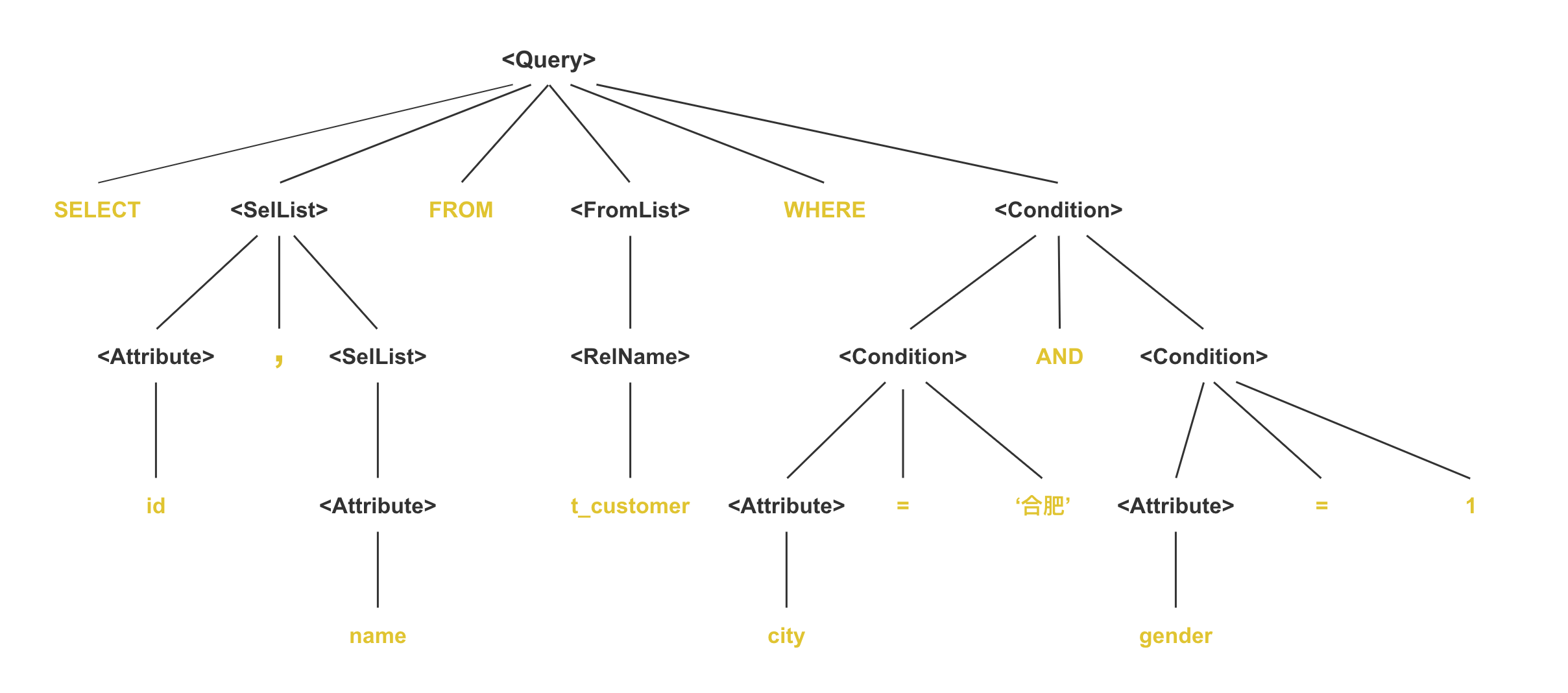
其中,以尖括号<>括起来的部分是语法类,黄色的部分为原子。由上面这棵语法分析树可以看出,所有的叶子节点都是原子。对这棵树从左向右,依次遍历各个子树的叶子节点,拼接起来,就是完整的SQL语句。
构造语法分析树的过程,是应用、检查各条语法规则的过程,出现了所有语法规则都不适用的情况时,则说明该SQL语句存在语法错误。
从语法分析树到逻辑执行计划
到这里,就可以回答我在引言中抛出的问题,关系代数将要登场。从语法分析树到逻辑执行计划要分为两步:
-
将语法分析树转换为对应的关系代数表达式,比如<SelList>要做的其实是关系代数中的投影操作,<Condition>要做的是关系代数中的选择操作
-
应用关系代数的定律,将基于语法分析树得到的关系代数表达式,转换为任何等价的关系代数表达式,然后基于统计信息,评价各个关系代数表达式的执行代价,从而选出代价最小的关系代数表达式,作为相对最优的逻辑执行计划。
关于关系代数的定律,这里不做过多展开,简单类比为小学数学学过的数学定律就行,比如:交换律、结合律、分配律等。基于这些定律,我们可以交换一个关系代数表达式中的各个操作的顺序,从而得出等价的关系代数表达式。
这一步,也是优化器要做的至为关键的一个操作。
关于关系代数定律的应用,相对来说,比较直观的是在选择和投影中的下推优化。
从直观印象上,也就是提前进行条件的过滤以及字段的选择,从而从一开始就降低磁盘IO的工作量,而不是一股脑把所有的数据从磁盘上读一遍,然后才进行各种筛选过滤。
一个不可回避的问题
关于运算代价的估算,是优化器进行优化选择时的关键所在。
而优化器进行运算代价的估算,主要是基于数据库中的相关统计信息,这些统计信息更多的又主要是各个索引结构的统计信息。
但是,由于统计信息的计算不是实时的,毕竟数据量比较大的话,统计信息的实时更新也是一个成本很高的工作。所以,一般索引信息的更新,只有在insert和update操作中才有可能触发,而且,也不是没执行一条insert或者update语句就立马更新,而是有一个触发机制,比如,当前表中数据累计被更新的占比等。
由于统计信息不是实时的,有时候可能会误导优化器的选择,尤其表的更新、删除操作比较频繁时。
所以,当一条SQL执行效率比较慢时,我们需要分析对应的执行计划,发现某个索引结构如果生效的话,本可以更高效执行,但是数据库管理系统却没有应用时,则可能是统计信息不够及时,这时可以人工介入SQL执行计划的调整,比如MySQL中的force index来强制应用某个索引结构。
由于数学定律对大多数人来说比较生涩,对我也是,这里就不再费力的展开了。很多在读书时期,知其然,不知其所以然的东西,在日用中,能渐渐地变得更加清晰的感觉,很是美好,进一寸有一寸的欢喜!
计算机能解的问题,一定是可以转换为数学问题的问题。从数据库中优化器的优化决策中关系代数的应用,我们能稍微感知到一点点数学之美,从而不再对数学避之唯恐不及,就已经足够了。