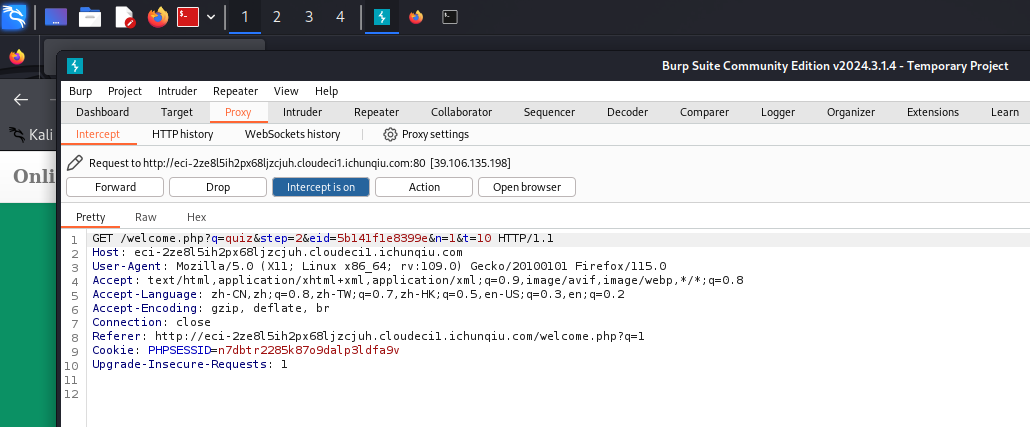
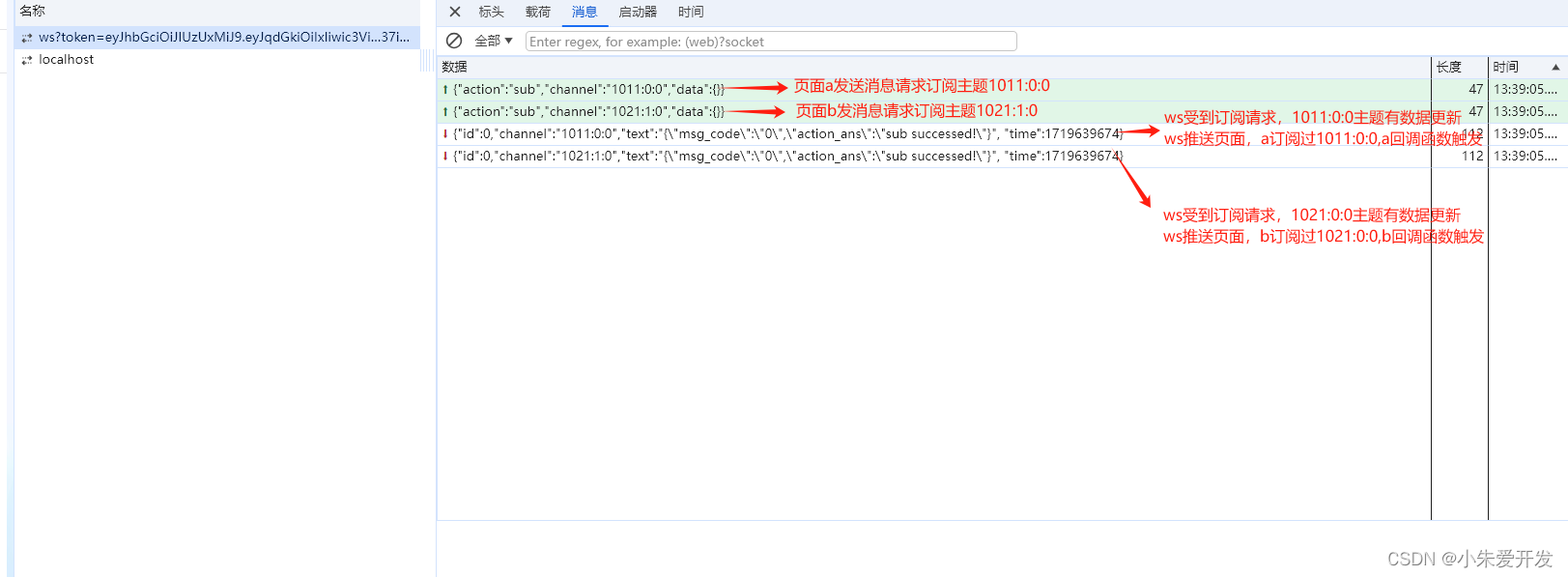
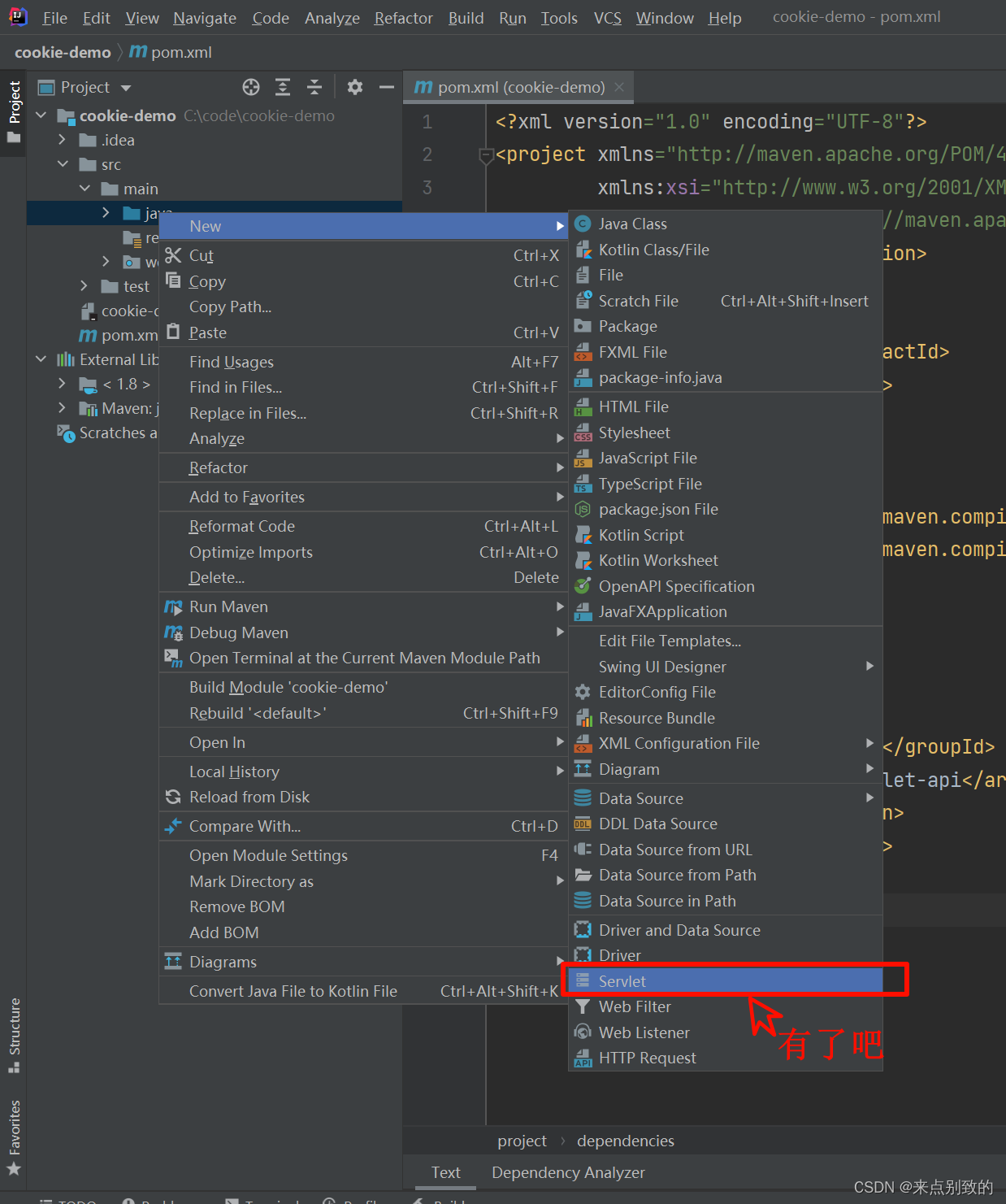
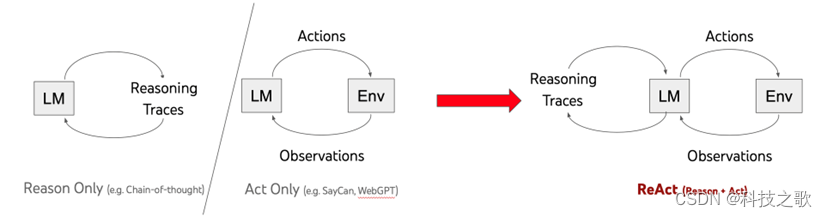
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、算法项目落地经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
《大模型面试宝典》(2024版) 发布!

喜欢本文记得收藏、关注、点赞。更多实战和面试,欢迎文末加入与我们交流
这两天面试群太热闹了,2025届忙着暑期实习和秋招,2024届的小伙伴已陆续分享了经验和心得,准备奔赴新的城市和新的生活了。
我们也整理了很多大厂的算法岗面试真题(暑期实习结束了,校招陆续开启),前几天整理了比亚迪的最新面试题,今天整理一位星球小伙伴面试英伟达的最新面试题,希望对大家有所帮助。喜欢记得收藏、点赞、关注。参与我们的讨论。
1. LN和BN
2. 介绍RLHF
3. 介绍MoE和变体
4. 介绍LoRA和变体
5. LoRA 参数更新机制
6. 如何减轻LLM中的幻觉现象?
7. MLM和MIM的关系和区别?
8. Stable Diffusion的技术原理
9. 解決LLM Hallucination的方法
10. Occupancy预测的出发点是什么?
11. 介绍RWKV、Mamba和Mamba-2
12. 2D图像预训练怎么迁移到3D点云任务
13. 为什么现在的LLM都是Decoder only的架构?
14. 把Transformer模型训深的问题有哪些?怎么解决
15. 现在车道线检测的主流的loss是什么?你有哪些想法?
16. 为什么GAN中经常遇到mode collapse,而Diffusion比较少?
我还特别整理15道 Transformer 高频面试题
-
介绍Transformer和ViT
-
介绍Transformer的QKV
-
介绍Layer Normalization
-
Transformer训练和部署技巧
-
介绍Transformer的位置编码
-
介绍自注意力机制和数学公式
-
介绍Transformer的Encoder模块
-
介绍Transformer的Decoder模块
-
Transformer和Mamba(SSM)的区别
-
Transformer中的残差结构以及意义
-
为什么Transformer适合多模态任务?
-
Transformer的并行化体现在哪个地方?
-
为什么Transformer一般使用LayerNorm?
-
Transformer为什么使用多头注意力机制?
-
Transformer训练的Dropout是如何设定的?
用通俗易懂的方式讲解系列
-
重磅来袭!《大模型面试宝典》(2024版) 发布!
-
重磅来袭!《大模型实战宝典》(2024版) 发布!
-
用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
-
用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
-
用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
-
用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
-
用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
-
用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
-
用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
-
用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
-
用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
-
用通俗易懂的方式讲解:大模型训练过程概述
-
用通俗易懂的方式讲解:专补大模型短板的RAG
-
用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
-
用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
-
用通俗易懂的方式讲解:大模型微调方法总结
-
用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
-
用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
-
用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了