本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 盘古演进过程
- 盘古2.0 第一阶段
- Append-Only File System
- 统一持久化层与Client
- Client 获取元数据优化
- Client 访问Chunkserver优化
- Chunkserver USSOS(user-space storage file system)
- 盘古2.0 第二阶段
- 网络带宽为瓶颈
- 内存带宽为瓶颈
- CPU为瓶颈
- 盘古运营经验
- 结束语
引言
作者水平有限,如果读者在阅读过程中发现任何不足之处,欢迎您提出宝贵的意见和建议。
存算分离中统一存储层最核心的驱动因素是吞吐量足够的情况下iops/gb足够高(低成本的情况下提供强大的性能)。这意味着要在高密存储机型下达到内存/cpu/网络吞吐/io吞吐 的平衡,以此增加总体资源利用率,降低总成本。
在[3]的评论区中张威大佬提到BG3的存储层已经从kv更换为类似盘古的append only blob系统,其本质原因是LSM类系统一般为了稳定运营需要预留cpu/内存/存储IO带宽,这会造成qps/gb非常有限,存储利用率无法提升,横向扩展成本较高;其次分布式kv系统并非对计算没有要求,公有链路编解码,一致性协议,wal(写文件系统),memtable,cache等对于磁盘之外的资源消耗也不能小觑。
这就导致使用持久化kv类系统作为其他系统的共有存储层存在成本问题。其次kv系统的优势在于接口的易用性和相对较优性能,并不是成本和吞吐量。
清楚系统的边界尤为重要,AWS在kv模型提供三个产品ElastiCache,MemoryDB和DynamoDB,分别占据性能/可靠性/成本效益。而阿里云提供Redis社区版,Tair性能增强性和Tair容量存储型,聚焦性能。
很多人往往高估了SSD kv能提供的能力,按照纯写 1kb qps/core来算,qps 1w/min,set平均时延2ms,p999 5ms左右的系统已经了不起了(往往系统内部组件存在多可用区,而且也没有接入RDMA)。而盘古给出的双11峰值写平均时延可以低至280us,读平均时延在11ms以下。而关于吞吐量,盘古2.0的一个核心设计原则就是使存储层服务器的有效吞吐量接近其容量。
这样令人惊叹的数据可以浓缩为一句话,盘古的存储层的资源就只做一件事情,在append only优化的用户态文件系统上读写数据。高可靠,高可用,那是client和master要做的事。
如此来看,如果有这样一套强大的blob storage,块存储,文件存储,对象存储,关系型数据库,nosql都可以构建在其上,节省公司的总体成本,阿里云确实也是这样做的[5]。
换个角度看这也是一种很好的商业模式,与其每个团队搞一套,不如搞个吊的大家一起用,这也是为什么盘古不惜舍得投入20个人/两年去做FPGA卸载CPU计算的原因,当然也最终得到很好效果;这也许也是盘古如此成功的原因之一。
盘古演进过程
总体可以分为四个步骤,在不同的阶段遇到因为不同的因素遇到不同困难,使用工程方法逐步解决,这种逐步推进的经验值得每个从业者学习,很多点都是各种系统之间通用的。
- 引入2 × 25-Gbps network and 4-TB SSDs,需要重新设计盘古以适应固态硬盘和RDMA
- 自主研发大容量存储机型(2×24 core Skylake CPUs, 12×8 TB commodity SSDs, 128 GB DDR memory),引入100-Gbps network,内存带宽为瓶颈
- 引入 2×100 Gbps network,网络带宽为瓶颈
- EC和压缩消耗大量CPU,CPU为瓶颈
盘古2.0 第一阶段

与HDD和TCP相比,SSD和RDMA大幅度降低了存储和网络的IO延迟,但是将这些技术引入盘古系统并不容易。
Append-Only File System
统一持久化层与Client
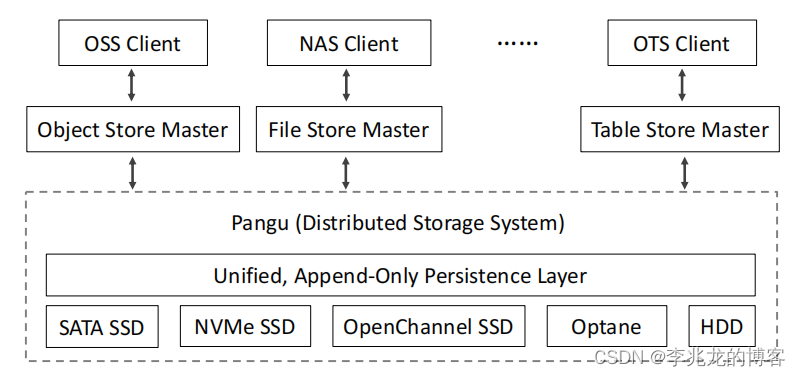
盘古的持久层为盘古的所有存储服务(如 EBS、OSS 和 NAS)提供接口。为了简化盘古的开发和管理,引入了一种名为 FlatLogFile 的统一文件类型(类似对象存储)。这是一个非常重要的抽象,将整个阿里的存储堆栈组件化了。
Client 获取元数据优化
- Parallel metadata processing:namespace 和 stream services 都采用并行化处理(论文中简单带过,细节需要看 InfiniFS的实现 [9])
- Big chunks with variable lengths:盘古2.0使用Big chunks。优点如下
1. 减少元数据的数量。2. 避免因客户端频繁请求分块而造成不必要的 I/O 延迟。2. 提高固态硬盘的使用寿命。简单地增加块大小会增加碎片风险,可变的分块长度降低了碎片发生的概率。 - Caching chunk information at clients:每个client维护一个本地元数据缓存池,
以减少元数据查询请求的数量。该池采用基于 LRU 的机制进行更新。 - Chunk information request batching:clitnt 允许在短时间内汇聚多个chunk信息请求,并将其批量发送给master,以
提高查询效率。 - Speculative chunk information prefetching:当master收到读取请求时,它们会向客户端回应相关数据包的元数据和其他数据包的元数据,
以减少对 Chunkserver 请求的数量。 - Data piggybacking to reduce one RTT:受 QUIC[8]和 HTTP3 的启发,将chunk创建请求和要写入的数据合并为一个请求,
减少一个RTT。
Client 访问Chunkserver优化
- Chasing:写入存在小部分失败时进入 Chasing 模式,即随时保证三份存储。此时 Client 把数据留在内存里,然后等待 t 时间,如果t时间收到 Success,就依然认为写入成功。如果未完成部分大于 k个请求 client请求master在后台从其他Chunkserver拷贝数据。
chasing 可以在不增加数据丢失风险的情况下大幅减少写尾延迟。 - Non-stop write:写入失败时client保存没有写入的数据,并向master上报,随后client持续写入未完成的数据。如果内存保存的数据因为重启丢失,会使用其他副本在后台流量中复制一份数据到新的数据块。
为了在chunk write写入失败时减少写入延迟。 - Backup read:
为了减少读取延迟,读取时同时读取备份,该机制有两个关键参数,即发送备份读请求的次数和等待时间,盘古会计算不同磁盘类型和 I/O 大小的延迟时间,并利用这些信息动态调整发送备份读取请求的时间;其次还会限制备份读取请求的数量,以控制系统的负载。具体算法没有提供。 - Blacklisting:分为deterministic blacklist 和 non-deterministic blacklist;non-deterministic blacklist可以被释放出来,取决于基于 TCP 和 RDMA 的定期探测。
Chunkserver USSOS(user-space storage file system)
对于特定应用重新设计存储,网络堆栈已经不是新颖的概念[10],chunkserver就采用了bypass kernel的实现,这不仅减少用户空间和内核空间之间造成不必要的数据拷贝,而且不需要中断。数据量大,开发人多的情况下确实一个可行的精益求精的路子。
- 一般文件系统以块为单位存储文件,文件及其元数据通过两个 SSD 写操作分别写入存储介质,这不仅会增加文件写入的延迟,还会缩短固态硬盘的使用寿命。盘古选择将文件存储在基于 FlatLogFile 的仅有追加语义的块服务器上,设计了一个独立的块布局,每个块都存储数据和元数据。这样一个数据块就可以通过一次操作而不是两次操作写入存储介质,从而大大减少了写入延迟,提高了存储介质的使用寿命。
- USSOS不像 Ext4 那样在 inodes 和文件目录之间建立层次关系。对文件的所有操作都会记录到日志文件中。在挂载文件系统时,可以通过重放日志重建相应的元数据。这样看起来就没有ext4在文件较大时查询文件靠后的需要几跳的问题了。
- run-to-completion thread model:请求自始至终都在一个线程上运行,
减少了上下文切换、线程间通信和线程间同步所造成的开销。(惭愧的是我们的系统为了逻辑清晰,有很多的线程投递,这看起来也是task flow框架一个很大的问题) - shared huge-page achieve zero copy:可以使用 RDMA 协议将从网络接收到的数据存储在 shared huge page 中,随后通过 SPDK 框架直接将数据从 huge page 写入存储介质,这样就
实现了网络和存储栈之间的零拷贝。 - Priority scheduling to guarantee high QoS:USSOS 实现了优先级队列。任务可根据其 QoS 目标(用户请求分配高优先级目标,而 GC 请求分配低优先级目标)被放入相应的优先队列,
确保低优先级目标的请求不会阻塞稍后到达并分配给同一工作线程的高优先级请求。 - Polling and event-driven switching (NAPI):USSOS 采用polling 和 event-driven modes 的切换机制,以较低的 CPU 利用率减少大量中断处理的开销[30]。NIC 提供一个由应用程序监控的 fd,并通过 fd 事件通知应用程序数据到达。应用程序默认处于事件驱动模式。
当应用程序收到来自 NIC 的通知时,就会进入轮询模式。如果一段时间内没有收到任何 I/O 请求,应用程序就会切换回事件驱动模式并通知 NIC。做过网络编程的同学都知道和epoll看起来是一样的,所以我理解就是做了个用户态的epoll。
盘古2.0 第二阶段
2018 年开始,盘古开始从volume-oriented storage provider 转化为 performance-oriented provider。业务模式的转变和日渐庞大的规模发现现有的服务器很多方面不经济,所以盘古开发了自研服务器Taishan。基础配置为 2×24 core Skylake CPUs, 12×8 TB commodity SSDs,128 GB DDR memory,and 2×dual-port 100 Gbps NICs。这样一台机器的固态吞吐量可以达到20GB/s,但是文章似乎对盘古可以提供的iops刻意隐瞒,很多地方应该提及的地方都换着方法一笔带过。
技术设施的升级一般会遇到不少瓶颈导致无法吃满资源,进而影响性能和利用率。
网络带宽为瓶颈
当磁盘吞吐到20GB/s时,网络带宽25 Gbps( 3.12 GB/s) 就有些不够看了,而且这还是网络包整体的大小,并不是payload的大小,当然RDMA的目标是实现高效的内存到内存的数据传输,其协议头相比TCP会更加精简[11];当网卡给到 2×dual-port 100 Gbps NICs(25GB/s)时就可以把完全利用磁盘网络带宽了。
为了把网络带宽从25 Gbps 升级到 100 Gbps,需要在硬件和软件上分别作出改进,这方面我并不擅长,有兴趣的同学可以看看[12],阐述了盘古大规模部署RDMA的经验。
当带宽升级后,流量放大(网络中实际传输的数据量/用户实际上传数据大小)就成了一个不可忽略的问题。
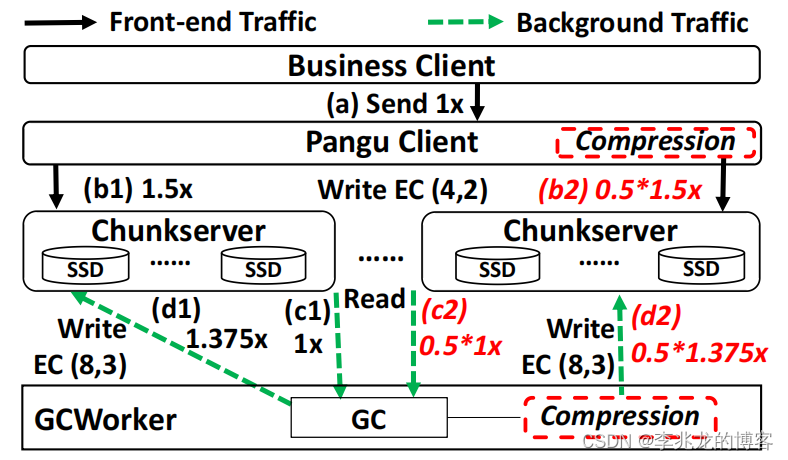
文章以EBS举例,正常的工作流程如下:
- EBS 客户端向盘古客户端发送一个文件(1x)
- 盘古客户端将文件传输到 3 个存储节点,写入 3 个副本(3x)
- GCWorker读取文件并对其执行垃圾回收(1x)
- 最后文件以 EC(8,3) (1.375x) 的形式写回存储节点,这至少提供了与 3-replica 相同的容错水平,但使用的存储空间更少。
从EBS看文件写入的流量放大比率可达 6.375 倍,换句话说,EBS 的最大数据访问带宽的最大数据访问带宽小于 16 Gbps,完全无法吃满磁盘带宽。
盘古使用EC[1][2]+压缩的算法解决此问题。
用 EC 取代三副本可以大幅降低网络流量放大率,同时提供和三副本相同的容错,如果使用 EC (4,2)
- EBS 客户端向盘古客户端发送一个文件(1x)
- EC (4,2)压缩率是1.5倍,相比于以前三副本需要写三倍,现在写六个存储节点只需要1.5倍的流量(1.5x)
- GCWorker读取文件并对其执行垃圾回收(1x)
- 最后文件以 EC(8,3)的形式写回存储节点 (1.375x)
使用EC(4,2)替换三副本可以把流量降低只4.875倍;
也可以在盘古客户端和 GCWorker 写入文件前对其进行压缩,盘古的经验平均压缩率可以在50%以上,流量放大可从 4.875 倍进一步降至 2.9375 倍。
在这个过程中还遇到了两个问题:
- EC 中存储小文件的成本很高:因为在长度固定的数据上执行 EC 时需要大量的零填充。使用小型写入请求聚合和 EC 与 3 个副本之间的动态切换解决。
- 计算 EC 会带来延迟:使用英特尔 ISA-L [13],后面会提到卸载计算的方式。
内存带宽为瓶颈
盘古的基本内存瓶颈在于网络进程(即执行 DMA 操作的网卡)和接收主机中的应用进程(data copy, data replication, and garbage collection)之间对内存带宽的高度争用。这里还是感叹盘古的工作确实值得敬佩,这里就可以看出他们的网络库也是自己做的,我们的现在做数据库能确保瓶颈在rpc框架已经可以认为做到头了,本质上是没有人力去驱动修改rpc框架的性能瓶颈,因为rpc框架是其他团队维护的。
盘古发现了一个内存带宽为瓶颈造成全局网络拥塞的情况,具体可以参考[14]。
Because NIC cannot acquire enough memory bandwidth, severe PCIe back-pressure is generated to the NIC. As a result, the NIC buffer is filled with in-flight packets. Eventually, it drops the overflowed ones, triggering the congestion control mechanism in the network and leading to overall performance degradation (i.e., 30% network throughput drop, 5%-10% latency increase and 10% IOPS drop per server).
盘古使用三个方案解决问题:
添加更多小容量 DRAM:以提高内存带宽将后台流量从 TCP 转为 RDMA:减少了75%的内存带宽消耗remote direct cache access (RDCA):因为观察到数据离开网卡后在内存中停留的时间非常短(即平均几百微秒)。假设网卡后的平均时间跨度为 200 微秒,那么对于双端口 100 Gbps 网卡,我们只需要 5 MB 就能暂时存储离开网卡的数据。 所以接收到数据后直接写入 LLC Cache,跳过内存。具体策略可以参考原文。
CPU为瓶颈
通过前面的优化盘古在 100-Gbps 网络中的吞吐量仍然只能达到理论值的 80%,这是因为数据序列化和反序列化、数据压缩和数据 CRC 计算等操作会消耗大量 CPU 资源,使 CPU 成为盘古的另一个瓶颈。
盘古使用如下策略解决:
Hybrid RPCs:数据链路使用FlatBuffer,控制链路仍旧使用Protobuf;节省30%的CPU。这样的问题其实比较容易发现,在我们的系统也遇到过,我们从Protobuf改为FlatBuffer,Json改为Msgpack,以节省序列化/反序列化开销。Supporting Hyper-Threading Using CPU Wait:发现HT存在性能问题。第一,一个物理核上的两个 HT 需要切换上下文;其次,当一个 HT 同时执行任务时,会影响另一个 HT 的执行,导致两个任务的延迟增加;盘古使用monitor 和 mwait 指令,网络空闲轮询线程将在被监控的内存地址处等待,直到其他线程写入内存地址后才会唤醒。网络吞吐量增加了 31.6%。Hardware and Software Co-design:数据压缩(节省10个物理核 Intel® Xeon® Platinum2.5 Ghz,但也没说几台机器可以省这么多)和CRC(节省30%CPU)卸载至FPGA计算
盘古运营经验
盘古给出了一些内部实践的经验,这类大成的工业论文一般经验极具价值。
盘古对于规划、开发、测试、部署不用提了,就算实际没那么好论文肯定也不能这么说。我更关心的是将监控的时间粒度从 15 秒提高到 1 秒,秒级监控是非常重要的,因为我现在负责时序数据库,对于公司内部监控业务的能力多少有点理解,绝大多数业务因为成本问题使用的是分钟级别监控,分钟级别监控在上报和实际可见之间至少75s(可以思考下为什么),一般监控产品给出的sla是120s;而秒级监控一般确保10s以内就可以看到,这首先让告警更敏感;其次分钟级别数据很多时候会把秒级别的突发掩盖。
其次文章提到利用人工智能来更好地捕捉异常事件与其根本原因之间的因果关系。推断出的根本原因由运行团队进行评级,并反馈给训练有素的模型。听起来有点赛博朋克,真的那么有用不是早发论文了23333。
全链路CRC:例如数据路径上的端到端 CRC、所有副本上的月度 CRC、随机抽样副本上的 CRC 以及 EC 构建过程中一个额外副本上的 CRC。依托于腾讯云存储团队这样10EB级别的盘子,入职不到两年已经见到了三例CPU/内存静默错误,确实感慨CRC校验的重要性。不同厂商的CPU实际带宽不同:盘古发现三个不同供应商提供的 128 GB 内存的可实现带宽分别为 94 GB/s、84 GB/s 和 60 GB/s(即相差 57%),这件事情告诉我们某类硬件可能就是容易出错,或性能差,在出现问题时这一个排查方向。当时在维护对象存储索引层时发现性能问题经常可以定位是三星的某个型号的盘开始变慢。在 USSOS 中处理可修正的机器检查异常(MCE): USSOS 的 MCE 监控守护进程中添加了一个处理程序。一旦发现的可修正 MCE 数量超过阈值,文章提到会通知内核migrate memory修复,据目前我看到的资料MCE错误分为可修复和不可修复的,为什么要再介入呢?Lessons on user-space systems:用户态操作系统修复问题更快Lesson on performance-cost tradeoff:根据TCO来看,增加硬件是最优方式,在加机器无法解决时用人力解决Lesson on hardware offloading:最大的矛盾就是投入产出比,文章提到FPGA卸载CRC和压缩投入20个人/两年才完成,当然文章中给出的效果确实是很不错的。之前公司内部有个团队在推RocksDB卸载硬件,一般只有把这样的能力推往全公司才能平衡,给盘古用当然间接给全公司用了。
结束语
这篇文章的内容极为丰富且深入,尽管知识点紧密交织,但每一句话都承载着不可或缺的价值。对于分布式存储领域的从业者而言,这篇论文无疑是近几年必读论文之一,我愿称之为工业论文大成之作。
看完盘古的实现,我认为想自己做存储层的都可以省省了,因为绝大多数情况下你做的再好也没有专门做的团队强,我们应该将精力聚集在产品核心竞争力的打造。
虽然我司没有盘古这样开箱即用的产品,但是对象存储也足够优秀了。尤其作为兄弟部门,我们拿的价格比公有云便宜的多。
在[16]中提到InfluxDB3.0,GreptimeDB使用DataFusion,Lindorm TSDB,IotDB使用Apache Calcite,Db2 Event Store使用内部维护的成熟计算引擎,这些业界知名的项目向我们宣告了模块化组件正在推动高性能基础架构领域的发展。而成熟的存储层也可以作为公司内部的各大项目的基础堆栈,就像盘古之于阿里云。
这样各个数据库项目要做的事情就清晰很多了,即只需要开发方言查询语言相关的计算引擎适配开源执行引擎,模态相关的存储引擎和专用功能就够了,专业的事情交给专业的人去做。
时代已经变了,很多东西没必要从从到脚自己全部开发一遍了,乐,又是一个多模数据库存在的现实意义。
参考:
- 分布式存储工程师的自我修炼 (13)-ec和副本的差异
- Hadoop3.0时代,怎么能不懂EC技术增删码?
- 从一到无穷大 #29 ByteGraph的计算,内存,存储三级分离方案是否可以通用化为多模数据库
- 从一到无穷大 #27 从Amazon MemoryDB视角看稳定binlog带来的无限可能性
- 对象存储实现分析
- 阿里云块存储计费
- More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba fast2023
- 一文读懂QUIC 协议:更快、更稳、更高效的网络通信
- InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems fast2022
- 把Qos扯到排队论上去
- rdam 原理解析
- When Cloud Storage Meets RDMA nsdi 2021
- https://github.com/intel/isa-l
- Understanding Host Interconnect Congestion
- 什么是MCE(Machine Check Error)?
- 从一到无穷大 #25 DataFusion:可嵌入,可扩展的模块化工业级计算引擎实现