python英文官方文档:https://docs.python.org/3.8/tutorial/index.html
比较不错的python中文文档:https://www.runoob.com/python3/python3-tutorial.html
1. 写在前面
这几周从实践角度又学习了一遍python,温故而知新,还是有蛮多心得的, 周末再看之前记的python笔记,总觉得零零散散, 未成体系,所以后面这段时间,陆续对之前的python笔记做一次整合, 使得内容更加清晰,成体系,做到简单可依赖,既是复习,也方便以后回看回练。希望能帮助到更多的伙伴啦。
这是第一篇文章,主要整理python的基础特性,数据类型(字符串,列表,字典等)、运算符、流程控制等,既有基础,又有新知识,这样更有意思一些。
文章很长,内容很多,各取所需即可 😉
大纲如下:
- 1. 写在前面
- 2. 变量与运算符
-
- 2.1 基础特性
- 2.2 变量
- 2.3 运算符
- 3. 数据类型
-
- 3.1 字符串
-
- 3.1.1 从编码开始
- 3.1.2 字符串常用函数
- 3.1.3 常用操作
- 3.2 列表
-
- 3.2.1 基础操作
- 3.3.2 经典使用案例
- 3.3 元组
- 3.4 字典
-
- 3.4.1 基本使用
- 3.4.2 dict.get()方法
- 3.4.3 关于dict的key要注意
- 3.4.4 字典格式化字符串输出
- 3.5 集合
-
- 3.5.1 基础操作
- 3.5.2 字典和集合的内部存储
- 3.6 其他细节
-
- 3.6.1 可变与不可变
- 3.6.2 深浅拷贝
- 3.6.3 数据的类型判断
- 3.7 回顾常用方法
- 4. 程序控制
-
- 4.1 条件判断
- 4.2 assert语法
- 4.3 循环结构
- 5. 小总
Ok, let’s go!
2. 变量与运算符
2.1 基础特性
# Python语句中一般以新行作为为语句的结束符。多行显示要通过 \
num1 = 1
num2 = 2
num3 = 3
total = num1 + \
num2 + \
num3
print("total is : %d"%total)
# 输入输出
name = input('please enter your name:');
print('hello,',name);
# 刷新荧幕,实时输出
import time
import sys
for i in range(5):
print(i, end=' '),
sys.stdout.flush() # 加这句就能每秒输出
time.sleep(1)
# 在Python里常量是可以改变的
PI = 3.14;
PI = 3.14159;
# 删除变量
del d
2.2 变量
python中的变量往往是采用动态语言的方式,所谓动态语言, 就是说变量本身类型不固定, 我们看一下python中的变量:
a = 123 # a是整数
a = 'ABC' # a变成字符串
与动态语言对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下
int a = 123; // a是整数类型变量
a = "ABC"; // 错误:不能把字符串赋给整型变量
变量在进行赋值的时候,python解释器到底在干什么?我们看下面的代码, 捋一捋计算机内部的逻辑:
a = 'ABC'
b = a
a = 'XYZ'
print(b) # ABC
我们可能一下子就知道结果, 但是你知道解释器到底在干什么事情吗? 也就是为什么会有这样的结果? 这个我直接引用廖雪峰老师画的图了:
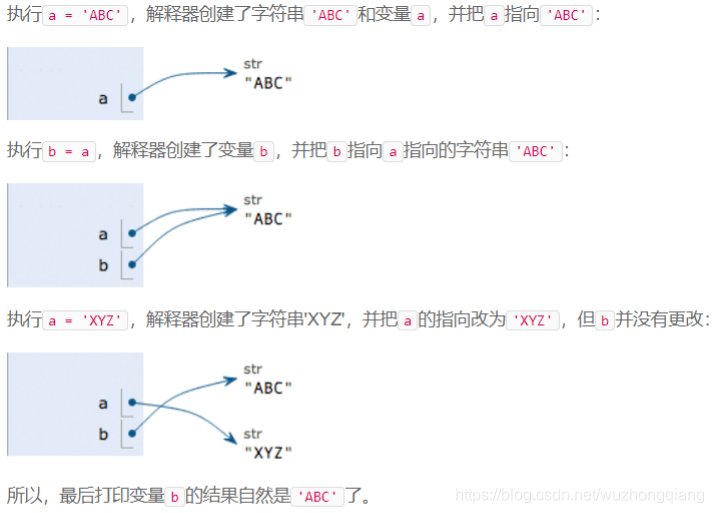
Python支持多种数据类型,在计算机内部,可以把任何数据都看成一个“对象”,而变量就是在程序中用来指向这些数据对象的,对变量赋值就是把数据和变量给关联起来。
对变量赋值x=y是把变量x指向真正的对象, 该对象是变量y所指向的。 随后对变量y的赋值不影响变量x的指向。
2.3 运算符
运算符的优先级:
#运算优先级由低到高
Lambda
逻辑运算符: or
逻辑运算符: and
逻辑运算符:not
成员测试: in, not in
同一性测试: is, is not
比较: <,<=,>,>=,!=,==
按位或: |
按位异或: ^
按位与: &
移位: << ,>>
加法与减法: + ,-
乘法、除法与取余: *, / ,%
正负号: +x,-x
短路运算符:
a=1
b=2
c1 = a and b # 前面为false就一定为false,不必执行第二个
c2 = a or b # 前面为true就一定为true,不必执行第二个
print(c1,c2)
三目运算符(三元表达式): python不支持三目运算符,但有三元表达式:
# x if condition else y
# 为真时的结果 if 判断条件 else 为假时的结果(注意,没有冒号)
# 斐波那契数列
def fn(n):
return n if n < 2 else fn(n-1)+fn(n-2)
# np.where(判断条件,为真时的处理,为假时的处理)
# np为numpy对象 pip install --upgrade numpy
# x = np.where(x%2==1, x+1, x)
import numpy as np
x = 0
x = np.where(x%2==1, x+1, x)
Python中的两种除法: / 和 //
/计算结果是浮点数,即使两个整数恰好整除, 结果也是浮点数//表示地板除法, 两个整数的除法依然是整数, 浮点数相除最后也是整数
9/3 = 3.0
10 // 3 = 3
PS: Python的整数没有大小限制,而某些语言的整数根据其存储长度是有大小限制的,例如Java对32位整数的范围限制在-2147483648-2147483647。Python的浮点数也没有大小限制,但是超出一定范围就直接表示为inf(无限大)。
3. 数据类型
Python的核心数据类型有如下几种:
- 数字
(1234, 3.14, 3+4j) - 字符串
('apple', '1234') - 列表
([1, [1, 2], 2], list(range(10)) - 字典
({'food':'spam', 'taste':'yum'}, dict(hous=10)) - 元组
((1, 'apam', 4, 'U'), tuple('spam')) - 集合
(set('abc'))
这些对象可以归类为可变的和不可变的。 数字,字符串和元组是不可变的, 列表,字典,集合是可变的, 这个可变和不可变理解起来,就是可变对象建立之后是可以修改的,即内部的内容是可以变化的, 这个后面介绍每一种类型的时候会整理到。
基础数据类型就不整理了和其他语言基本上都一样, 下面主要是整理字符串,容器相关的一些类型和常用操作。
3.1 字符串
3.1.1 从编码开始
字符串是一种数据类型,但是字符串比较特殊的是一个编码问题, 因为计算机只能处理数字, 如果要处理文本, 就需要先把文本转换成数字。
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节, 两个字节可以表示的最大整数是65535。
计算机是美国人发明的, 因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号, 这个编码表被称为ASCII编码。 比如大写字母A的编码时65, 小写字母z的编码时122。
但是要处理中文,显然一个字节是不够的, 至少需要两个字节, 而且还不能和ASCII编码冲突, 所以中国制定了GB2312编码,用来把中文编进去。
但是全世界有上百种语言, 像中国一样,每个国家有各国的标准, 那很容易就乱了套, 出现冲突,也就是在多语言混合的文本中,会出现乱码的问题。因此, Unicode应运而生, Unicode把所有语言都统一到一套编码里,就不会再有乱码问题了, 看这个名字也能看出来
现在就可以来看看ASCII编码和Unicode编码的区别:ASCII编码是1个字节, 而Unicode编码通常2个字节
- 字母
A用ASCII编码是十进制的65, 二进制的01000001; - 字符
0用ASCII编码是十进制的48,二进制的00110000, 注意字符'0'和整数0是不同的; - 汉字
中已经超出了ASCII的编码范围,用Unicode编码是十进制的20013, 二进制的01001110 00101101.
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以, 因此A的Unicode编码是00000000 01000001
但是这样统一成Unicode编码,乱码问题从此消失, 但是,如果你写的如果全是英文, 用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上都会造成一种浪费。所以本着节约的精神, 又出现了把Unicode编码转换成“可变长”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
所以这个就是这几种编码之间的关系了,之前遇到编码问题总是心态一崩, 现在终于搞清楚了这些编码之间的逻辑了。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码, 比如用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
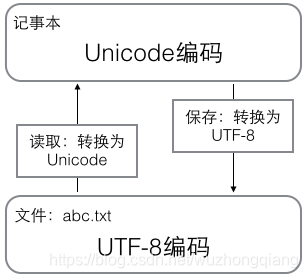
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
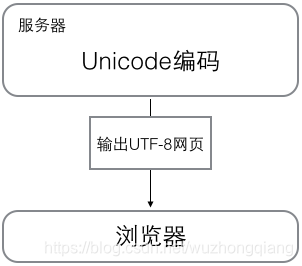
所以你看到很多网页的源码上会有类似 <meta charset="UTF-8" /> 的信息,表示该网页正是用的UTF-8编码
# 在最新的Python 3版本中,字符串是以Unicode编码的,
# 也就是说,Python的字符串支持多语言, 可以使用ord()函数获取字符的整数表示, chr()函数把编码转成对应的字符:
ord('A') # 65
ord('中') # 20013
chr(25991) # 文
# 由于Python的字符串类型是str, 在内存中以Unicode表示, 一个字符对应若干个字节。
# 如果要在网络上传输, 或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
# Python中bytes类型的数据用b前缀的单引号或者双引号表示:
X1 = 'ABC'
X2 = b'ABC'
# 注意,这两个是不一样的, X1是个字符串, X2虽然和X1显示的内容一样,但bytes的每个字符都只占用一个字节。
# 以Unicode表示的str通过encode()方法可以编码为指定的bytes
'ABC'.encode('ascii') # b'ABC'
'中文'.encode('utf-8') # b'\xe4\xb8\xad\xe6\x96\x87'
'中文'.encode('ascii') # 这个会报错, 中文不能转成ASCII编码
# 如果我们从网络或磁盘上读取了字节流, 那么读到的数据就是bytes。
# 要把bytes变为str, 就需要用decode()方法。
b'ABC'.decode('ascii') # 'ABC'
b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') # 中文
# 如果bytes中包含无法解码的字节,用decode()方法会报错, 如果只有一小部分是无效的字节, 可以传入errors='ignore'忽略错误的字节。
b'\xe4\xb8\xad\xff'.decode('utf-8') # 会报错
b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore') # ‘中’
3.1.2 字符串常用函数
| 方法 | 用法示例 |
|---|---|
| 拼接 | str1 + str2, str1+str(int), str1str2 |
| 截取 | str1[], str2[start: end: step] |
| 获取长度 | len(str) |
| 分割与合并 | str1.split(’/’), ‘,’.join(list1) |
| 统计次数 | str1.count(’-’, start,end), start,end可选,控制字符串范围 |
| 查找子串 | str1.find(’-’, start), start是开始索引的位置,可选, 找到返回字符第一次出现的位置,rfind()从右边开始找, str.index(’-’)这个方法也可以, 不同点是index方法如果找不到字符会抛出异常 |
| 填充 | s.ljust(35, ‘*’)往字符串右边填充字符凑到总长度35, 文本左对齐, rjust右对齐, center 文本居中 |
| 判断开始和结束字符 | s.startswith(’p’), s.endwith(’m’) |
| 大小写转换 | s.title()首字母大写, s.lower() 全部小写, s.upper()全部大写 |
| 去除无用字符 | s.strip()去除两边的空格和特殊字符, s.lstrip()左边,s.rstrip()右边 |
| 格式化字符串 | s.fotmat()指定字符串样式, 统一格式常用,比如35→’00035’这种, "{:05d}".format(num), str(num).zfill(5),f"{num:05d}” |
| 编码和解码 | s.encode(encoding=’utf-8’, errors=’strict’)字符串编码成bytes类型,bytes.decode([encoding="utf-8"][,errors="strict"]) 解码成字符串, 编解码的格式要一样 |
再来深入看下”字节串”和”字符串”的区别:
- 字符串由若干个字符组成,以字符为单位进行操作;字节串由若干个字节组成,以字节为单位进行操作。
- 字节串和字符串除了操作的数据单元不同之外,它们支持的所有方法都基本相同。
- 字节串和字符串都是不可变序列,不能随意增加和删除数据。
bytes 只负责以字节序列的形式(二进制形式)来存储数据,至于这些数据到底表示什么内容(字符串、数字、图片、音频等),如何使用,完全由程序的解析方式决定- bytes 类型的数据非常适合在互联网上传输,可以用于网络通信编程;
- bytes 也可以用来存储图片、音频、视频等二进制格式的文件。
len()函数计算字符串长度
我们知道, 如果len(str)会计算包含多少个字符, 但是你知道吗? 如果len(bytes)呢, 就会计算字节数:
len('中文') # 2
len(b'\xe4\xb8\xad\xe6\x96\x87') # 6
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
现在终于知道为啥需要加这两行了, 第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
要学会用dir()和help()函数
dir(): 列出某个类或者某个模块中的全部内容,包括变量、方法、函数和类等help(): 用来查看某个函数或者模块的帮助文档
掌握这两个函数,就能自行查阅python里面的方法、函数、变量和类的用法和功能。
# 代码演示
str_funcs = sorted([s for s in dir(str) if not s.startswith('__')])
for str_func in str_funcs:
if str_func == "startswith":
print(f"******************{
str_func} 使用方法 *************************")
help(getattr(str, str_func))
print()
3.1.3 常用操作
# 字符串占位符替换,如果字符串里面有%,就要用%%来表示
# %2d,不足2位,前面补空格;%02d,不足2位,前面补0;
# 其他的还有%s,%f,%r
str = '%2d-%02d' % (3, 1)
print(str)
print('%.2f' % 3.1415926)
# %r
text = "I am %d years old." % 22
print("I said: %s." % text) # I said: I am 22 years old.. %s用str()方法处理对象
print("I said: %r." % text) # I said: 'I am 22 years old.'. %r用rper()方法处理对象
import datetime
d = datetime.date.today()
print("%s" % d) # 2018-06-12
print("%r" % d) # datetime.date(2018, 6, 12) %r打印时能够重现它所代表的对象
# 转义与不转义
print('\\\t\\');
print(r'\\\t\\'); # r''表示''内部的字符串默认不转义
# ''' : 多行字符串
str = '''line1
line2 \\
line3
''';
print(str);
# r: 非转义的原始字符串
str = r'''line1 we \\
line2
line3
''';
print(str);
# u: 表示unicode字符串,后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。在python3中可以忽略
str = u"我是含有中文字符组成的字符串。"
# b: bytes Python3里默认的str是(Python2里的)unicode, bytes是(Python2)的str, b前缀代表的就是bytes。 Python2里, b前缀没什么具体意义, 只是为了兼容Python3的这种写法。
# 字符串repeat
'str1'*10 # str1str1str1str1str1str1str1str1str1str1
# format 格式化函数
"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
"{0} {1}".format("hello", "world") # 设置指定位置
"{1} {0} {1}".format(








![Spring学习01-[Spring实现IOC的几种方式]](https://img-blog.csdnimg.cn/direct/3f138876749d44a289a60d4050cd2db7.png)