论文分享:IntelliLight | Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining https://dl.acm.org/doi/10.1145/3219819.3220096摘要
https://dl.acm.org/doi/10.1145/3219819.3220096摘要
智能交通灯控制对于高效的交通系统至关重要。目前现有的交通信号灯大多由手动制定的规则来操控,但智能交通信号灯控制系统应进行动态地调整以适应实时交通。使用深度强化学习技术来进行交通灯控制是一个新兴的趋势,其最近的研究也展现出一些具有前景的结果。然而,现有的研究还没有在现实世界的交通数据上测试其方法,他们只专注于研究奖励而没有解释政策。在本文中,我们提出了一个更有效的深度强化学习模型的交通灯控制。我们在基于监控摄像头获取的一个大规模的真实的交通数据集上测试了我们的方法。我们还展示了一些有趣的从真实数据中学习到的案例研究策略。
概括
使用深度强化学习来进行交通信号灯控制 现有的研究没有在真实数据上进行测试,也没有解释其运行策略
本文贡献
1.提出的方法在交通信号灯控制上更为有效
2.使用的数据集是基于监控摄像头获取的大规模真实交通数据
3.展示了从真实数据中学习到的案例策略
本文框架
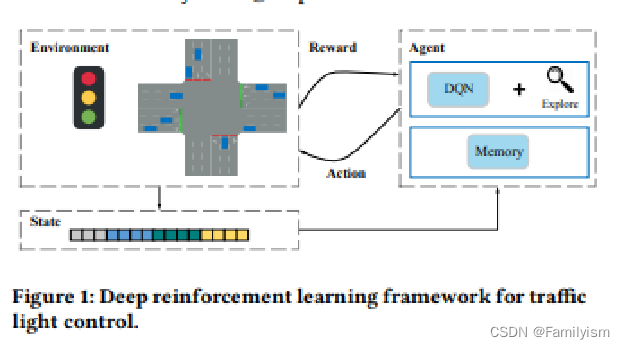
图1展示了本文强化学习框架的基本思想。
Environment由交通灯相位和交通状况两个方面组成,环境根据智能代理的行动进行变化。
State是环境的特征表示。
1.每个车道的排队长度,表示为车辆数。
2.每个车道上的车辆总数。
3.车辆的更新等待时间,即车辆在车道上等待的时间,该时间会根据车辆的速度进行更新。
4.车辆位置的图像表示,通过摄像头捕获并作为CNN模型的输入。
5.当前信号灯的相位和下一个可能的信号灯相位。
Agent是深度强化学习模型的执行者,它通过与环境交互来学习如何控制交通信号灯。代理使用一个深度Q网络(DQN)来评估在给定状态下采取特定行动的潜在回报,并基于这个评估来选择行动。在每个时间间隔内,代理会观察当前交通状态,选择是保持当前信号灯相位还是切换到下一相位,并根据这个决策对交通流产生影响。
Action智能体可以执行的操作,即决定是否改变交通信号灯的阶段(例如,从绿色变为红色或反之)。
Reward是智能代理采取行动后从环境中获得的反馈,用于量化行动对交通流的正面或负面影响。奖励的具体计算方式是多个因素的加权和。
DQN
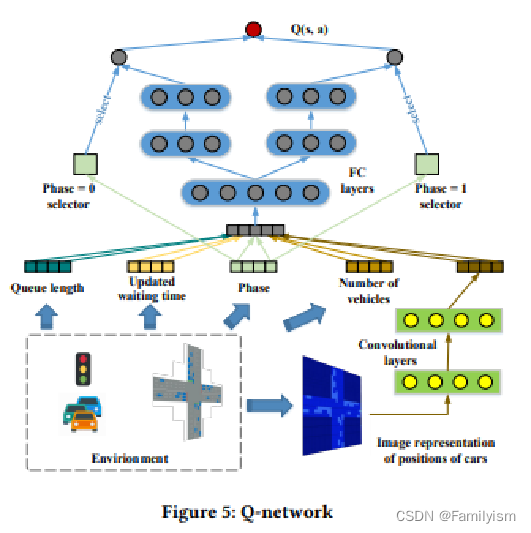
输入层: 1.图像特征:来自交通摄像头的图像数据,表示车辆的位置和数量。 2.队列长度(Queue Length):表示每个车道上等待车辆的数量。 3.更新等待时间(Updated Waiting Time):表示车辆在车道上等待的时间。 4.车辆数量(Number of Vehicles):每个车道上的车辆总数。 5.阶段选择器(Phase Selector):指示当前交通信号灯的相位
卷积层(Convolutional Layers): 卷积层用于从输入的图像数据中提取特征。这些层能够识别图像中的模式和对象,例如车辆的位置。
全连接层(Fully Connected Layers, FC Layers): 卷积层的输出与显式提供的特征(队列长度、等待时间和车辆数量)一起被送入全连接层。这些层负责学习从交通条件到潜在回报的映射。
阶段门(Phase Gate): 阶段门是一个特殊的结构,用于区分不同交通灯相位下的决策过程。根据当前的交通灯相位(例如,0或1),不同的路径会被激活。
输出层: 对于每个可能的行动(例如,保持当前相位或切换到下一相位),网络都会输出一个Q值。这些Q值表示在当前状态下,采取每个可能动作的预期回报。
动作选择: 根据当前状态和Q网络的输出,智能代理将选择一个动作,这个动作是预期能带来最高回报的动作。
Explore
图 1 中的 "Explore" 是指智能体在强化学习过程中的一个关键步骤,即探索(Exploration)。在这个阶段,智能体会采取一些随机动作,而不是总是选择当前策略下预期奖励最大的动作。这样做的目的是为了发现新的行为策略,可能会带来更高的长期回报。
在强化学习中,探索与利用(Exploitation)是两个基本的决策策略:
- 利用(Exploitation):智能体选择当前已知的最佳动作来最大化即时奖励。
- 探索(Exploration):智能体以一定的概率选择非最佳或随机的动作,以便学习更多关于环境的信息。
探索是必要的,因为:
- 在学习初期,智能体对环境了解有限,需要通过探索来收集信息。
- 即使在学习过程中,也可能存在当前策略未覆盖的更优解,探索有助于发现这些潜在的更优策略。
在交通信号控制的上下文中,探索可能意味着智能体在某些时间点不选择最优的信号灯变化动作,而是尝试其他动作,以观察这些动作对交通流量的长期影响。通过这种方式,智能体可以学习到在不同交通条件下如何更有效地控制交通信号灯。
Memory

智能体将定期从内存中获取样本,并使用它们更新网络。通过偶尔添加新的数据样本并删除旧的样本来维护这种内存。这种技术被称为经验回放,并已广泛应用于强化学习模型。 然而,在真实的交通环境中,不同车道上的交通是非常不平衡的。以往的方法将所有的状态-行为-奖励训练样本存储在一个记忆中,这个记忆将被不平衡环境中出现最频繁的阶段和行为所支配。然后,智能体将学会估计这些频繁相作用组合的奖励,但忽略其他较不频繁的相作用组合。这将导致学习智能体对不常见的相位-动作组合做出错误的决策。因此,当不同车道的交通差异较大时,这些不平衡的样本会导致在不太频繁的情况下性能较差。 根据认知心理学中的记忆宫殿理论,我们可以通过使用不同的记忆宫殿进行不同的相位-动作组合来解决这种不平衡。如图6所示,不同相位-动作组合的训练样本存储在不同的内存宫殿中。然后从不同的宫殿中选取相同数量的样本。这些均衡的样本可以防止不同的相位-动作组合干扰彼此的训练过程,从而提高网络的拟合能力,准确预测奖励。
Reward
如等式3所示,奖励被定义为以下因素的加权和: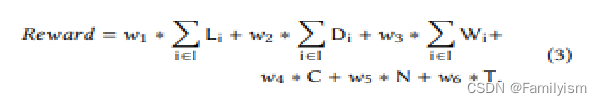
Li:所有进场车道上的车辆排队长度L之和,其中L计算为给定车道上等待车辆的总数。车速小于0.1m/s的车辆可以视为等待。
Di:所有进场车道上的延迟D之和,其中车道i的延迟Di在等式1中定义,其中lane speed是车道i上车辆的平均速度,speed limit是车道i上允许的最大速度。
Wi:所有进场车道的最新等待时间W的总和。这等于所有车辆在进场车道上等待时间W的总和。车辆j在时间t的最新的等待时间W在等式2中定义。请注意,车辆每次移动时,最新的等待时间将重置为0。例如,如果车辆的速度从0 s到15 s为0.01m/s,从15 s到30 s为5 m/s,并且从30 s到60 s为0.01m/s,则当t = 15 s、30 s和60 s时刻,Wj相对地为15秒、0秒和30秒。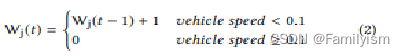
C:信号灯的切换指示器C,其中C = 0用于保持当前相位,C = 1用于改变当前相位。
N:在上一个动作a之后的时间间隔Δ t内通过交叉口的车辆总数N。
T:在最后一个动作a之后,车辆T在时间间隔∆T通过交叉口的总行驶时间T ,定义为车辆在驶近车道上花费的总时间(分钟)。
给定交通状况的当前状态s, agent 的任务是根据Bellman方程(等式4),找到可能导致长期最大回报r的动作a(改变或保持当前阶段)。在这种情况下,时间t的动作值函数q是下一个时间戳t + 1的奖励和最大潜在未来奖励的总和。通过这种对未来的推测,行为主体可以选择更适合长期奖励的行为.
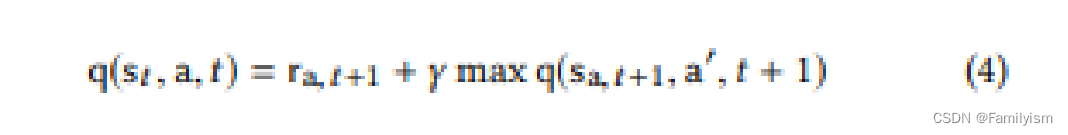

总结
状态:状态是对当前交通环境的描述,包括交通信号灯的相位、车道的车辆排队长度、车辆数量、车辆的更新等待时间以及车辆位置的图像表示等。状态是智能代理(Agent)做出决策的基础。
动作:动作是智能代理在给定状态下所采取的决策,通常表示为是否改变交通信号灯的相位。
奖励:奖励的具体计算方式是多个因素的加权和。
策略:在本文的模型中,策略是由深度Q网络(DQN)学习的,它映射从状态到动作的期望回报。
数据集: 1.时间戳(Time):记录数据收集的具体时间点。 2.摄像头ID(Camera ID):标识安装在特定位置的交通监控摄像头。 3.车辆信息(Vehicle Information):包括车辆的轨迹、位置、速度等信息。 4.车辆记录数(Vehicle Records):数据集中记录的车辆总数,论文中提到有超过405百万条车辆记录。 5.唯一车牌数(Unique Vehicle Plates):数据集中记录的不同车辆的数量,超过1100万个。 6.交通流量(Traffic Flow):每个方向上车辆到达的速率,可能以车辆每秒(cars/s)为单位。 7.车道排队长度(Queue Length):每个车道上等待车辆的数量。 8.车辆等待时间(Waiting Time):车辆在车道上等待的时间。 9.车辆位置的图像表示(Image Representation of Vehicles' Position):通过摄像头捕获的图像数据,用于表示车辆的位置。 10.当前信号灯相位(Current Phase):交通信号灯的当前状态,例如东西向绿灯(Green-WE)或南北向绿灯。 11.下一信号灯相位(Next Phase):交通信号灯的下一个状态。 12.车辆通过交叉口的数量(Number of Vehicles Passed):在特定时间间隔内通过交叉口的车辆总数。 13.车辆的总时间(Total Travel Time):车辆在接近车道上花费的总时间。






![洛谷 P1548 [NOIP1997 普及组] 棋盘问题](https://img-blog.csdnimg.cn/img_convert/61cb86eb2909f76f11400c52c25f03e5.png)