1、Netty框架是如何解决粘包、半包问题
关于粘包,半包问题,在前面几篇中都有提及,我们简单的复习一下。
- 粘包指的是客户端发出的多条消息,被服务端当做一条进行接收。
- 半包指的是客户端发出一条完整的消息,在传输的过程中被拆分成了多条零散的消息被服务端接收。
其根本原因在于TCP协议是没有明确消息边界的。
如果进行原因的细分,除了应用层的问题之外,还涉及到一种滑动窗口算法 和 MSS 限制、
Nagle 算法
1.1、滑动窗口算法
什么是滑动窗口算法 ?
我们都知道TCP是一种可靠的协议,确保消息可靠的方法在于确认应答处理:
图上相同颜色的箭头就是一次信息交互的过程。但是这样存在一个问题,如果每发送一次(一段)消息就要等待应答,如果通信的时间较长,则会影响效率。
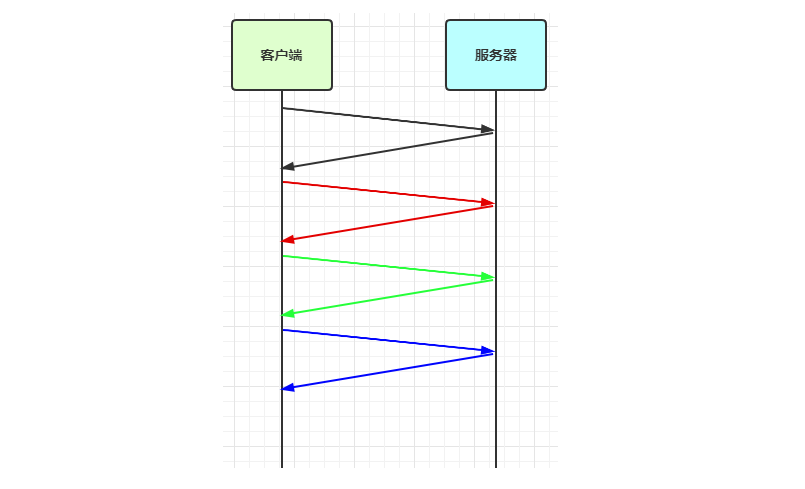
为了解决这样的问题,就引入了滑动窗口算法 ,既然每次发送消息都会有应答,那么能不能批量发送消息,批量等待应答?
例如原先客户端发送了A消息包到服务器,然后服务器接收到A后再给予客户端应答。应答完成后客户端再发送后续消息包,重复以上的过程。
但是现在客户端可以组合多个消息放在同一批次发送,例如将1, 2, 3, 4四条消息作为一个批次进行发送,此时窗口大小为4。服务器接受到了1、2两条消息向客户端确认后,客户端可以继续发送5、6消息给服务器。
发送方窗口: [ 1 2 3 4 ]
发送数据: [ 1 2 3 4 ]
接收方确认: [ 1 2 ] --> 发送ACK(3)
窗口滑动: [ 3 4 5 6 ]
发送数据: [ 5 6 ]
假设此时服务器没有接收到1、2两条消息,则客户端不可继续发送。
发送方窗口: [ 1 2 3 4 ]
发送数据: [ 1 2 3 4 ]
接收方没有收到数据,发送方等待确认ACK超时。
发送方重传数据包: [ 1 2 3 4 ]
那么如果接收方一直接收不到,发送方会无限制地重传吗?
答案是否定的:
TCP重传机制中的限制
-
重传次数限制:TCP协议通常会限制重传次数。如果重传次数超过某个阈值(通常由操作系统和网络堆栈实现指定),TCP连接会被认为已经失败,连接将被终止。
-
指数退避算法:TCP使用一种称为指数退避(Exponential Backoff)的算法来管理重传定时器。每次重传失败后,定时器的等待时间会按指数级别增长。这有助于减轻网络负载,避免拥塞。
-
超时和断开连接:如果重传多次失败,TCP协议会最终认为连接已经断开。这个机制防止了发送方无限制地重传数据。
发送方窗口: [ 1 2 3 4 ]
发送数据: [ 1 2 3 4 ]
接收方没有收到数据,发送方等待确认ACK超时。
第一次重传数据包: [ 1 2 3 4 ]
等待时间按指数退避算法增长。
第二次重传数据包: [ 1 2 3 4 ]
等待时间进一步增长。
...
超过最大重传次数,TCP连接终止。
1.2、MSS 限制
MSS(Maximum Segment Size,最大报文段长度)是TCP协议中一个重要的参数,它表示TCP报文段中数据部分的最大字节数。MSS的存在是为了确保每个TCP报文段可以在IP层的MTU(Maximum Transmission Unit,最大传输单元)范围内传输,而不会导致IP层的分片。
什么是IP层的分片
当IP数据包的大小超过网络传输路径中某个链路的最大传输单元(MTU)时,IP协议将这个数据包分成更小的片段,以便能够通过这个链路进行传输。每个片段都是一个独立的IP数据包,并且包含原始数据包的部分数据以及足够的信息,以便接收方能够将这些片段重新组装成原始的数据包。
网络中不同链路的MTU可能不同。MTU是指网络层在一次传输中能够承载的最大数据包大小。以太网的标准MTU为1500字节,但其他网络(如PPP、无线网络等)的MTU可能更小。当一个IP数据包的大小超过了某个链路的MTU时,必须进行分片,以确保数据包能够通过该链路。
在TCP连接建立过程中,通过三次握手(Three-Way Handshake)进行MSS协商。每一方在SYN包中声明自己愿意接受的最大MSS值。通常,发送方会根据接收方声明的MSS值来决定数据包的大小。
在IPV4和IPV6中,MSS的计算方式也是不同的:
MSS = MTU - IP头部长度 - TCP头部长度
- IPv4头部长度:20字节
- IPv6头部长度:40字节
- TCP头部长度:20字节
MSS = 1500 - 20 - 20 = 1460字节(IPV4)
MSS = 1500 - 40 - 20 = 1440字节(IPV6)
MSS与TCP的滑动窗口机制密切相关。滑动窗口决定了发送方在等待确认(ACK)之前可以发送的未确认数据量,而MSS决定了每个TCP段的数据大小。因此,两者共同影响TCP连接的吞吐量和性能。
假设两台主机通过TCP建立连接,并协商MSS值为1460字节。滑动窗口大小为4个段:
- 发送方发送数据:发送方按照MSS值和滑动窗口大小发送数据段,每个数据段大小为1460字节。
- 接收方确认:接收方按MSS值接收数据段,并发送ACK确认已接收的数据段。
- 窗口滑动:接收到ACK后,滑动窗口向前移动,释放已确认的数据段空间,允许发送方发送更多数据段。
发送方窗口大小:4个段,MSS=1460字节
发送数据:
第一个数据段:1460字节
第二个数据段:1460字节
第三个数据段:1460字节
第四个数据段:1460字节
接收方收到数据后发送ACK确认:
ACK确认第一个数据段
ACK确认第二个数据段
窗口滑动,发送方发送更多数据段。
简单的说,滑动窗口算法 和 MSS 限制 的关系:窗口中每个段的大小按照MSS决定。
1.3、Nagle 算法
Nagle算法的基本思想是:在未确认(unacknowledged)的数据包存在时,发送方不能发送新的小数据包,而是要将这些小数据包积累起来,直到可以组成一个较大的数据包或收到前一个数据包的确认。
当发送方有数据要发送时,Nagle算法会检查以下条件:
- 发送窗口中有未确认的数据包:如果发送窗口中存在未确认的数据包(即发送方还没有收到前一个数据包的ACK),则发送方会将新的数据缓存起来,直到可以组成一个最大报文段(MSS)大小的数据包。
- 发送窗口为空:如果发送窗口中没有未确认的数据包,则发送方可以立即发送数据包。
假设发送方有很多小数据包要发送,Nagle算法的执行流程如下:
- 初始发送:发送方发送第一个小数据包(比如10字节)。
- 等待确认:发送方等待接收方的ACK确认。如果ACK没有及时到达,发送方会继续积累后续的小数据包。
- 积累数据:如果有新的小数据包到来,发送方将这些数据累积起来,直到累积的数据大小达到MSS。
- 发送累积数据:一旦累积的数据大小达到MSS,发送方立即发送该数据包,即使没有收到前一个数据包的ACK。
回到最初的问题,那么滑动窗口算法 和 MSS 限制、Nagle 算法 是如何可能导致粘包,版本问题的呢?
粘包:
- 接收方处理不及时,滑动窗口又较大时,可能导致多个报文被放在缓冲区。
- 同样是接收方处理不及时,存在未确认的数据包,发送方就会利用Nagle算法将小数据包积累起来,直到可以组成一个较大的数据包或收到前一个数据包的确认,并且一旦累积的数据大小达到MSS,发送方立即发送该数据包,即使没有收到前一个数据包的ACK。
半包:
- 接收方的窗口小于发送方一次报文的大小,发送方只能将一个完整的报文切分一部分发送,等到接收方ACK后再发送剩下一部分。
- 发送的数据超过 MSS 限制后,会将数据切分发送。
1.4、框架解决方案
那么从Netty框架的层面,是如何解决半包、粘包问题的?
依旧是通过定长消息,分隔符,消息头+消息体的思路解决:
1.4.1、定长消息
Netty中的定长消息是通过FixedLengthFrameDecoder 处理器实现的:
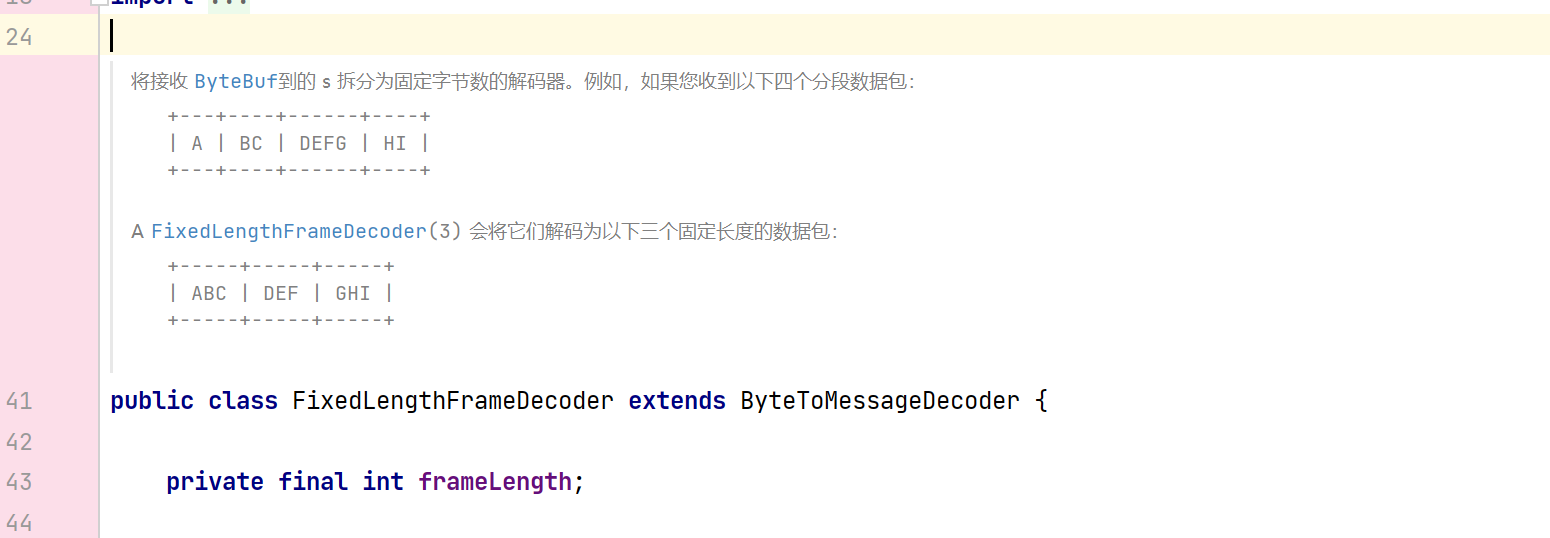
需要在服务器的流水线上加入:
pipeline.addLast(new FixedLengthFrameDecoder(8));目前指定的固定长度为8,我们在客户端生成随机长度的字符发送,以下是关键代码:
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
log.debug("sending...");
// 发送内容随机的数据包
Random r = new Random();
char c = 'a';
ByteBuf buffer = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
byte[] bytes = new byte[8];
for (int j = 0; j < r.nextInt(8); j++) {
bytes[j] = (byte) c;
}
c++;
buffer.writeBytes(bytes);
}
ctx.writeAndFlush(buffer);
}
});客户端发送出的数据,长度完全是随机的,有些是3个字节,有些是4个字节,但是不足的位置统一进行了补充:

服务器接收到的结果,会发现每条消息统一都占用了8个字节:

那如果发送的消息大于8个字节呢?
客户端发送出的数据9个字节
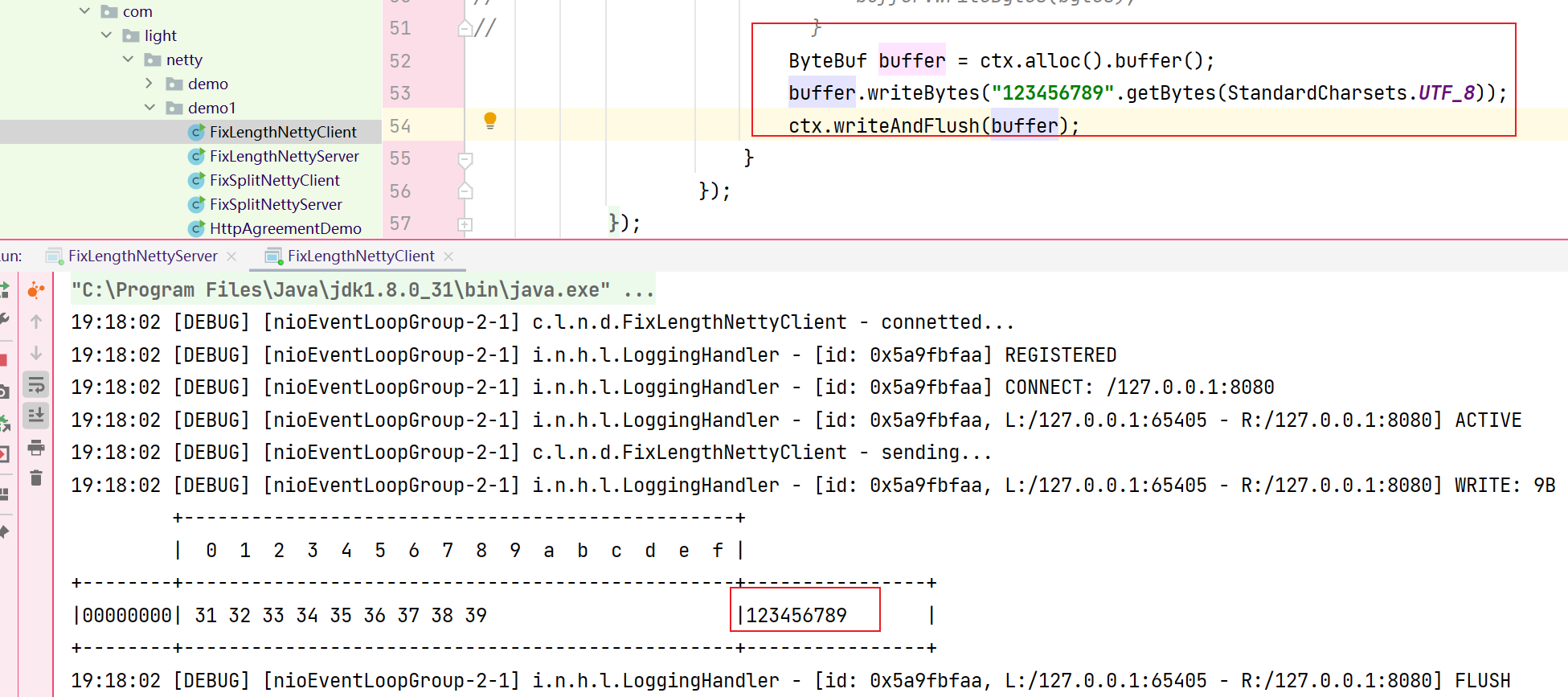
服务器接收到的数据只有8个字节:
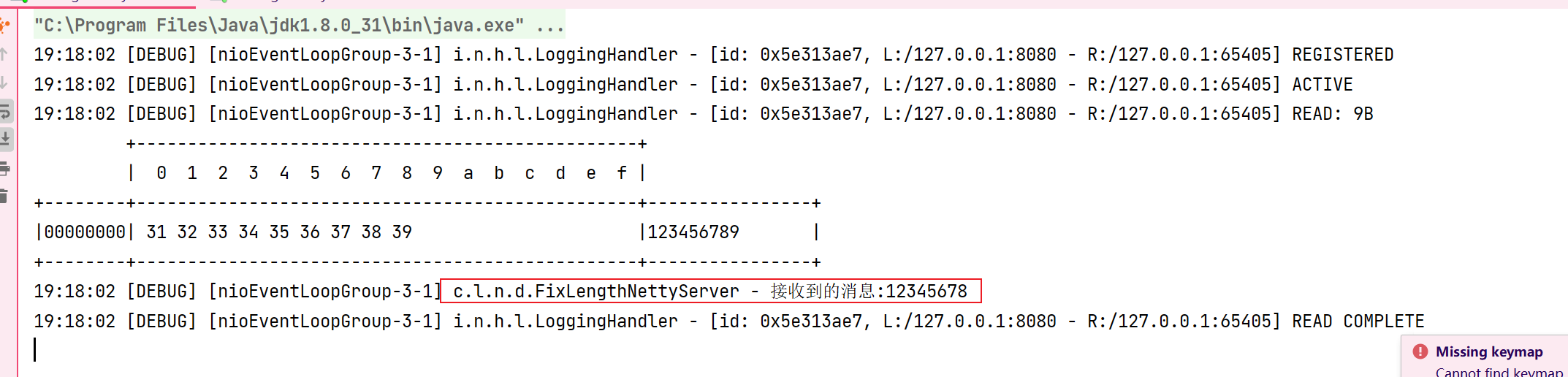
由此可见这种方案的弊端还是比较多的,如果发送消息的长度不足定长就会补充多余的空数据,如果大于定长则会丢失,所以如果要使用必须要把定长设置成为单条消息的最大长度,只适合于消息长度较为平均的场景下。
我们再点进FixedLengthFrameDecoder 类的内部去简单地看一看:
它的内部包含了decode解码的方法
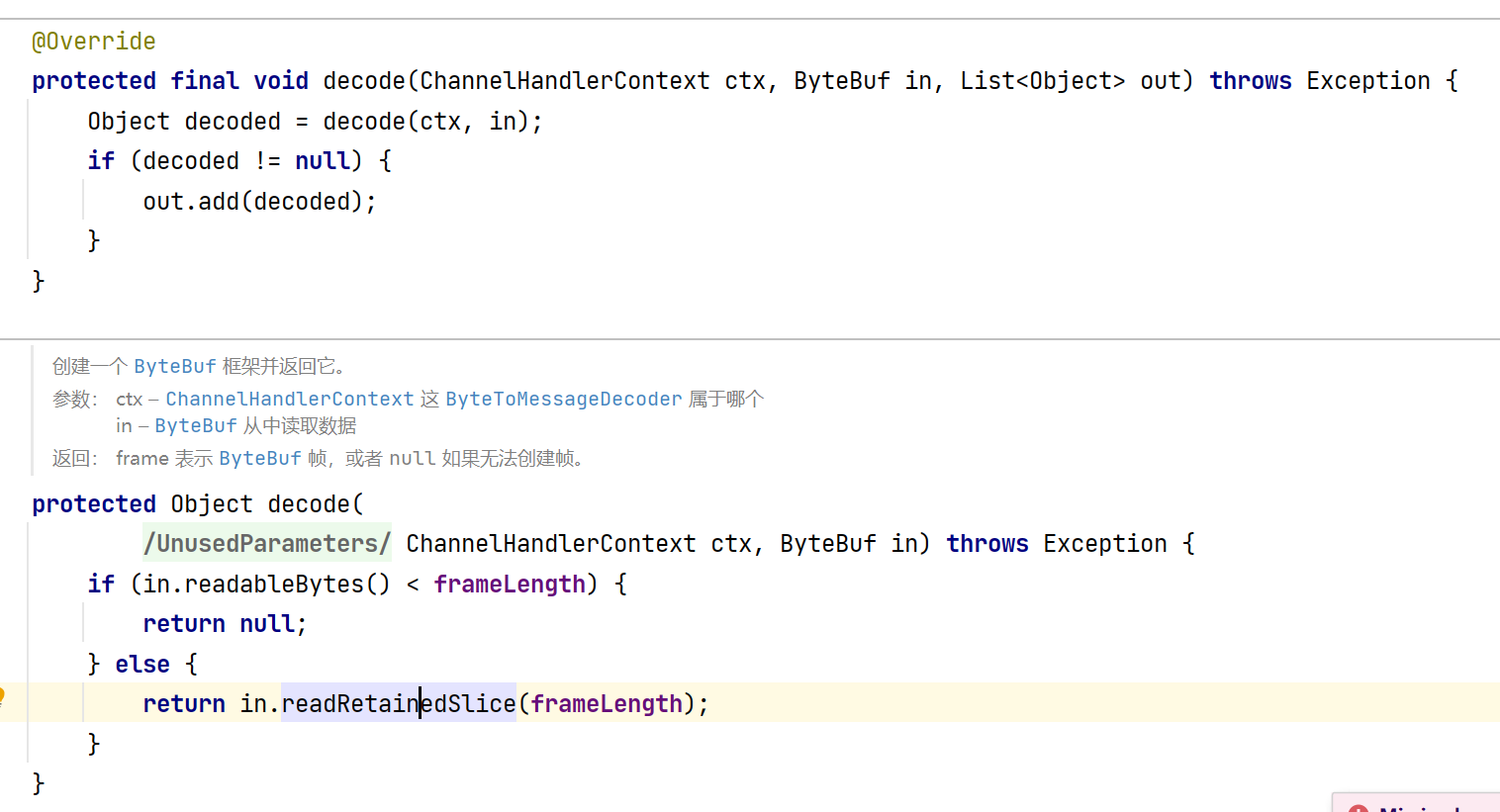
第二个decode方法是第一个的重载。如果当前可读取的字节数不足以形成一帧,会返回null并且等待数据到来直到满足一帧的大小。
例如目前固定大小为3,但是第一次只发来了A一个字节,会等待后续B,C的到来直到达到最大的长度才会发送。(这一点需要和上面在流水线中加入FixedLengthFrameDecoder 自动补齐不足长度的字符相区分,因为decode方法本身并没有设计成填充数据的逻辑,而是为了根据实际接收到的数据进行解码,而不是主动修改或填充数据。)
1.4.2、分隔符
在Netty中,使用分隔符解决半包粘包,是利用LineBasedFrameDecoder 处理器,默认以 \n 或 \r\n 作为分隔符。
需要在服务器的流水线上加入:
pipeline.addLast(new LineBasedFrameDecoder(1024));参数的含义是如果超出指定长度仍未出现分隔符,则抛出异常。
我们在客户端在每条消息之后,加入 \n 分隔符,以下是关键代码:
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
log.debug("sending...");
Random r = new Random();
char c = 'a';
ByteBuf buffer = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
for (int j = 1; j <= r.nextInt(16)+1; j++) {
buffer.writeByte((byte) c);
}
buffer.writeByte(10);
c++;
}
ctx.writeAndFlush(buffer);
}
});客户端发送出的消息:

服务器接收到的消息,根据分隔符进行了拆分:

但是这样做也有弊端,如果要发出的消息中,本身就带有分隔符所使用的字符,这样就无法进行区分了。
同样的我们点进LineBasedFrameDecoder 简单的看一看:
类中同样有两个重载的decode方法:

寻找分隔符结尾的逻辑:
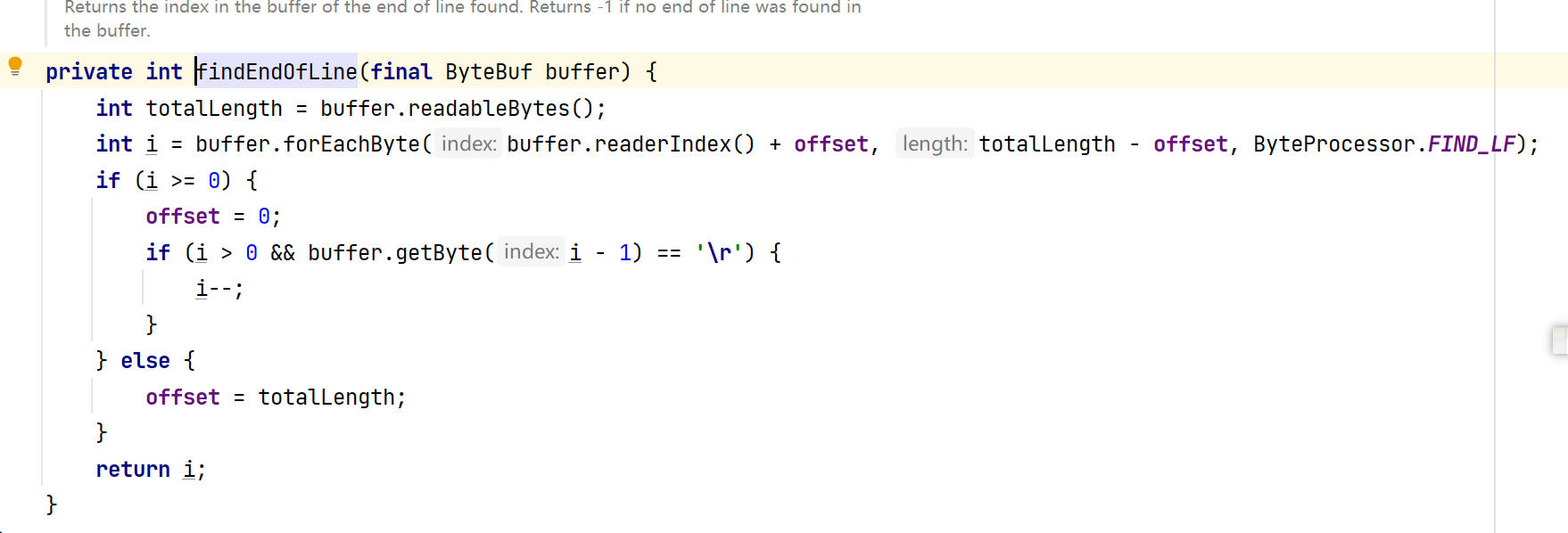
进行拆分的逻辑:
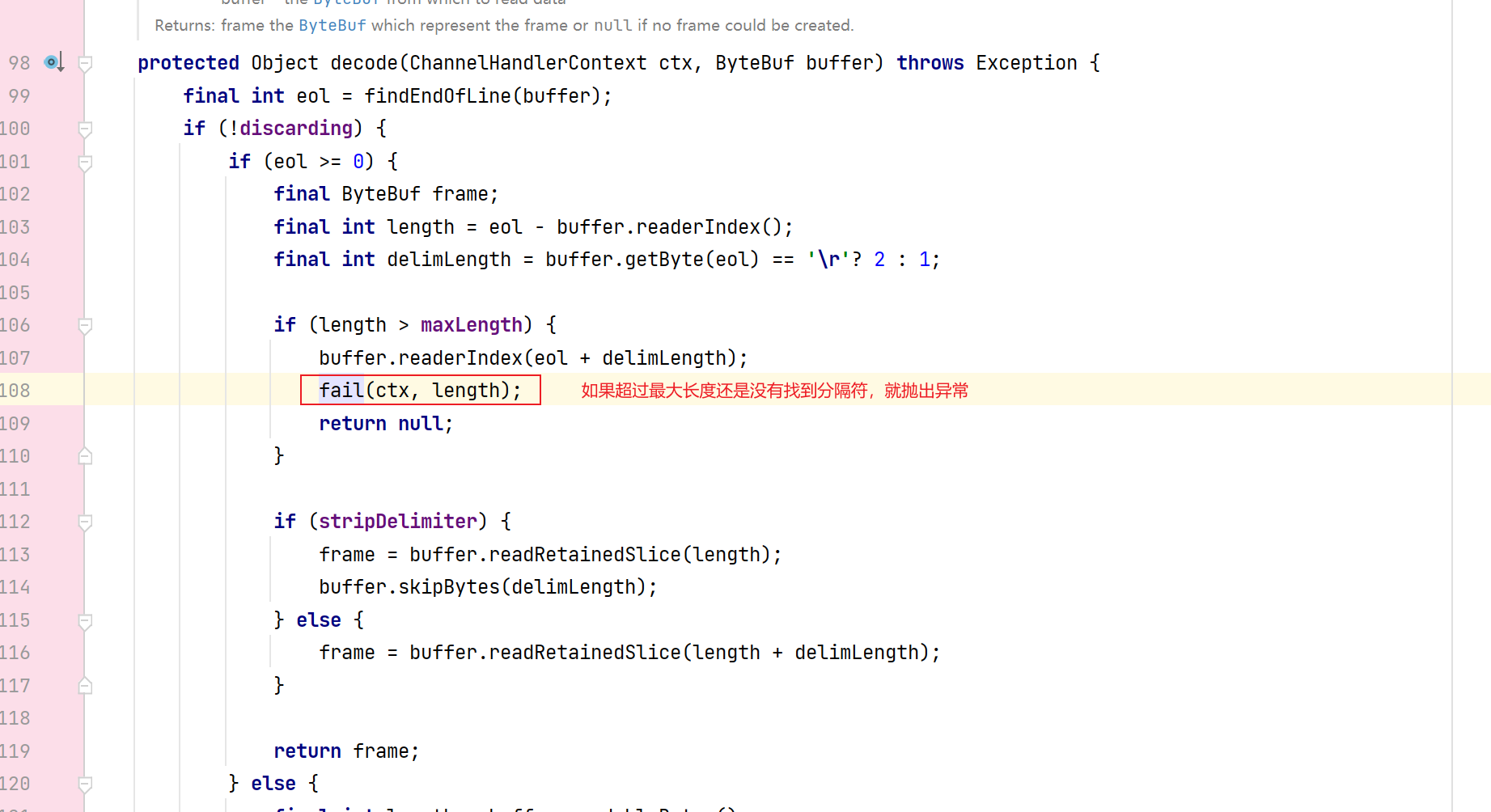
1.4.3、消息头+消息体
Netty中利用消息头+消息体的方式解决半包,粘包方式依靠的是LengthFieldBasedFrameDecoder 处理器,下面介绍一下它的参数:
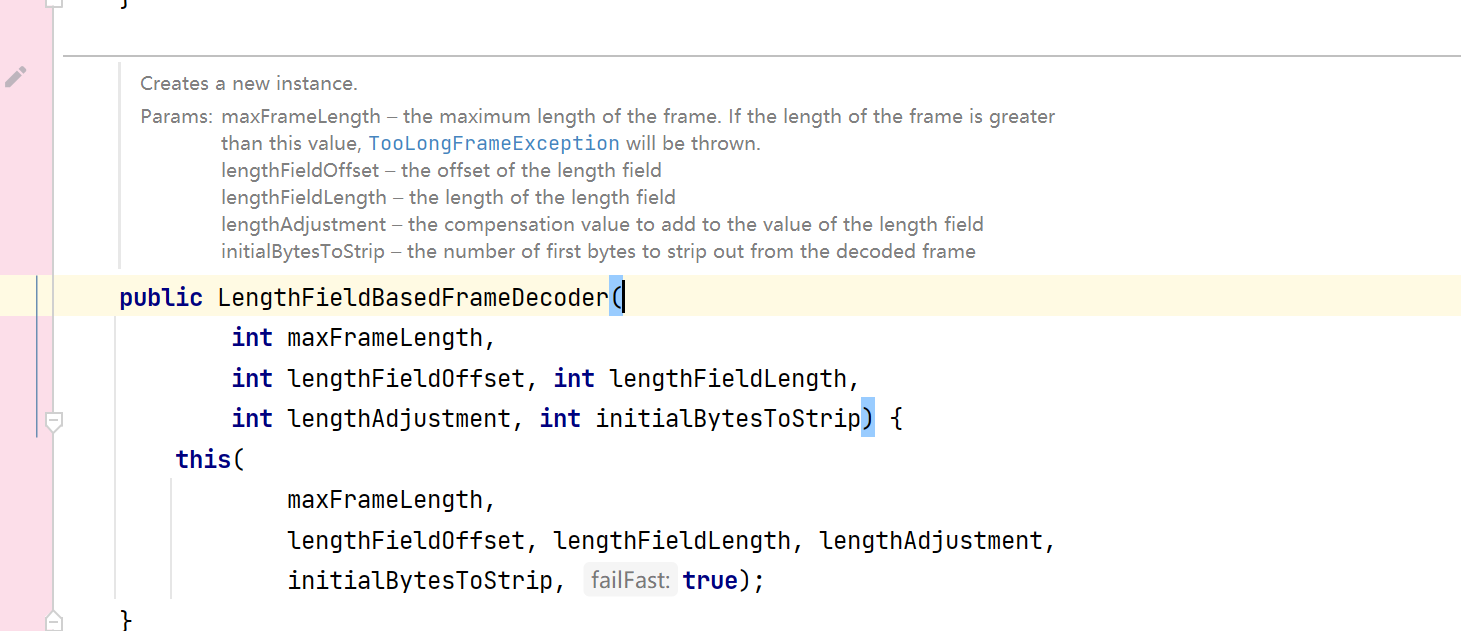
- maxFrameLength – 帧的最大长度。如果帧的长度大于此值, TooLongFrameException 则将被抛出(限定消息的最大长度)
- lengthFieldOffset – 长度字段的偏移量(这是长度字段在帧中的位置。通过这个参数,解码器知道从哪里开始读取长度信息。因为有可能长度信息不是存放在帧的头部)
- lengthFieldLength – 长度字段的长度(注意,是长度字段在帧中占用的字节数,不是长度字段实际的length,例如我长度字段占用了4个字节,但是长度字段的实际length是8)
- lengthAdjustment – 要添加到长度字段值的补偿值
- initialBytesToStrip – 要从解码帧中剥离出的第一个字节数(在解码后,可以选择跳过帧头的某些字节数,直接传递帧数据。例如,如果长度字段位于帧头,并且在解码后的消息中不需要包含长度字段,可以设置这个值为长度字段的长度,以跳过该字段。)
上面是关于参数的大致解释,实际上在LengthFieldBasedFrameDecoder 类的文档上也有关于各种情况的注释说明:
这种情况是长度字段位于帧的头部位置,前面没有其他数据,所以偏移量为0,长度字段占了2个字节。
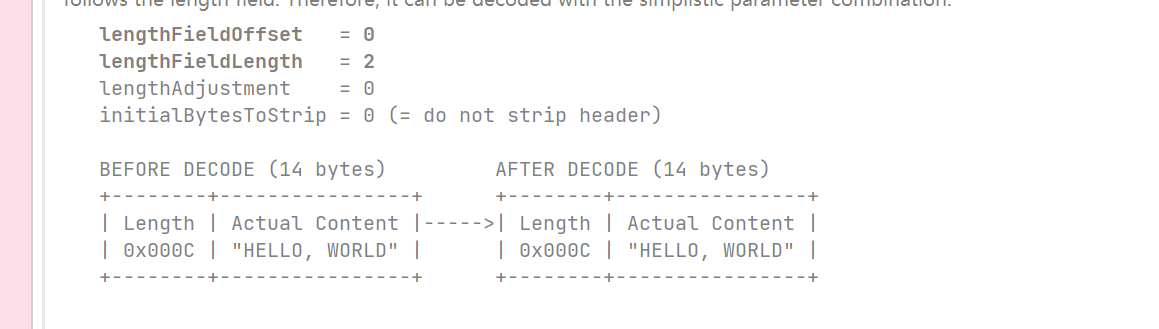
这种情况和上面类似,不同的是设置了从解码帧中剥离出的第一个字节数为2,也就是解码后将消息头去除。
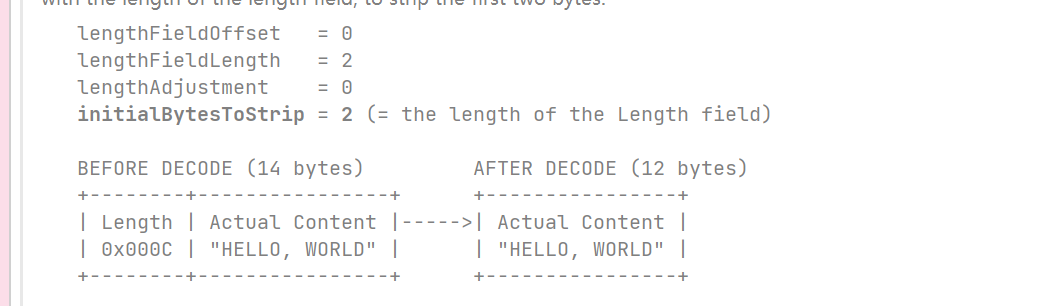
这种情况针对的是,消息头并非在帧的头部位置,它的前面有2个字节的其他数据,所以需要设置偏移量为2。
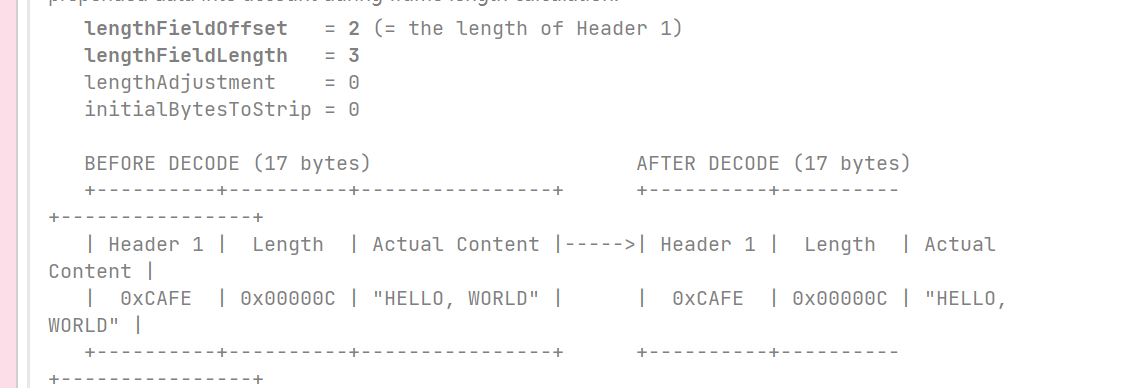
这种情况针对的是消息头在帧的头部位置,但是和消息体之间有2个字节的其他数据,所以要设置 lengthAdjustment 为2

上面列举了一些最常见的情况,还有更多的情况请自行阅读文档。
同样需要在服务器的流水线上加入:
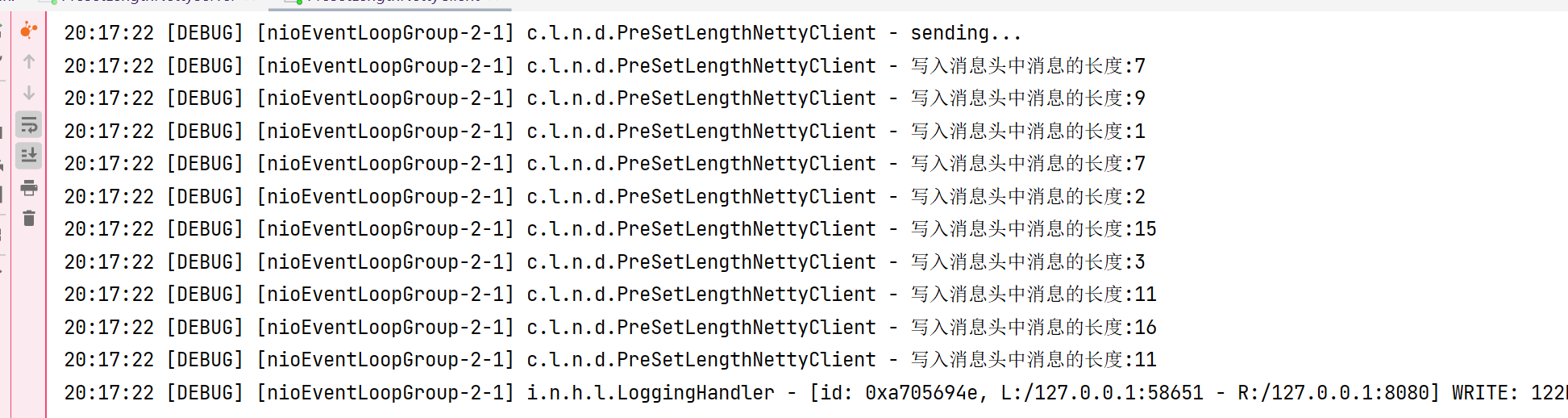
pipeline.addLast(new LengthFieldBasedFrameDecoder(1024, 0, 1, 0, 1));客户端中,在指定消息体之前,需要设置消息头,这里设置writeInt(4个字节)以下是关键代码:
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
log.debug("sending...");
Random r = new Random();
char c = 'a';
ByteBuf buffer = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
byte length = (byte) (r.nextInt(16) + 1);
log.debug("写入消息头中消息的长度:{}",length);
// 先写入长度
buffer.writeInt(length);
// 再写入数据
for (int j = 1; j <= length; j++) {
buffer.writeByte((byte) c);
}
c++;
}
ctx.writeAndFlush(buffer);
}
});客户端:
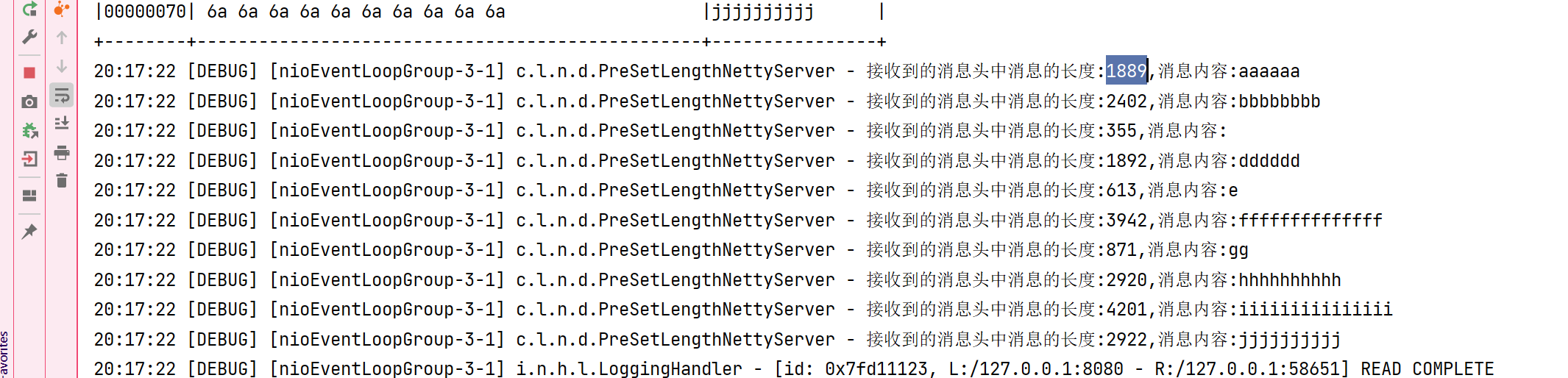
服务器端:
1.4.4、短连接
最后一种解决方案,是发送了一条消息之后,直接断开连接,然后重新建立连接发送下一条消息。很显然这种方案在实际开发中是不可能使用的。
2、自定义通信协议
我们常说的http协议,sftp协议等,实际上协议二字,指的是数据通信过程中,通信双方如何组织、传输和解释数据的约定和规范。
例如最常见的http协议,就是由以下几部分组成:
-
请求方法(Request Method):定义客户端希望服务器执行的操作,如 GET、POST、PUT、DELETE 等。
-
请求URL(Request URL):标识服务器资源的具体位置,客户端通过URL指定要访问的资源。
-
请求头部(Request Headers):包含关于请求的其他信息,如客户端类型、所支持的编码方式、允许的内容类型等。
-
请求主体(Request Body):对于某些请求方法(如POST),可以包含需要发送给服务器的数据。
-
状态码(Status Code):服务器响应的状态码,指示请求是否成功、失败或其他特定情况。
-
响应头部(Response Headers):包含关于响应的信息,如服务器类型、响应时间等。
-
响应主体(Response Body):服务器返回给客户端的实际数据,如 HTML 页面内容、图片、JSON 数据等。
如果我们需要自定义通信协议,通常需要满足以下的要素:
-
魔数:为固定内容,用于消息校验。例如所有java的.class文件开头都有cafebabe
-
版本号:可以支持协议的升级
-
序列化算法:指定消息传输的序列化方式,例如利用JDK自带的序列化和反序列化,或者第三方的JSON字符串的解析和反解析
-
指令类型:区分不同的业务类型
-
请求序号:为了双工通信,提供异步能力
-
正文长度:作为消息头,解决半包、粘包问题
-
消息正文:作为消息体
同时需要编写解码和编码方法,这里的序列化方式使用的是jdk自带的。
@Slf4j
public class MessageCodec extends ByteToMessageCodec<Message> {
@Override
protected void encode(ChannelHandlerContext ctx, Message msg, ByteBuf out) throws Exception {
//指定模数 4字节
out.writeBytes(new byte[]{'1','2','3','4'});
//指定消息版本 1字节
out.writeByte(1);
//指定序列化方式 jdk0 json 1 1字节
out.writeByte(0);
//指定消息指令类型 1字节
out.writeByte(msg.getMessageType());
//指定请求序号 4字节
out.writeInt(msg.getSequenceId());
//写入一个空字节
out.writeByte(0Xff);
//消息正文
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(msg);
byte[] bytes = bos.toByteArray();
//消息长度 4个字节
out.writeInt(bytes.length);
//写入内容
out.writeBytes(bytes);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
//读取模数 4
int magicNum = in.readInt();
//读取消息版本 1
byte reversion = in.readByte();
//读取序列化方式 1
byte serial = in.readByte();
//读取消息指令类型 1
byte messageType = in.readByte();
//读取请求序号 4
int sequenceId = in.readInt();
//读取空字节 1
byte space = in.readByte();
//读取消息长度
int messageLength = in.readInt();
//读取消息正文
byte[] bytes = new byte[messageLength];
in.readBytes(bytes,0, bytes.length);
if (messageType == 0){
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
Message message = (Message) ois.readObject();
out.add(message);
}
log.debug("{},{},{},{},{},{}",magicNum,reversion,serial,messageType,sequenceId,messageLength);
}
}
同时需要配合LengthFieldBasedFrameDecoder 处理器使用,以下是测试类:
public class TestMessageCodec {
public static void main(String[] args) throws Exception {
EmbeddedChannel channel = new EmbeddedChannel(new MessageCodec(),new LoggingHandler(),
new LengthFieldBasedFrameDecoder(1024,12,4,0,0));
LoginRequestMessage message = new LoginRequestMessage("zhangsan", "123456");
channel.writeOutbound(message);
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();
new MessageCodec().encode(null,message,buf);
channel.writeInbound(buf);
}
}编解码后的信息是一致的: