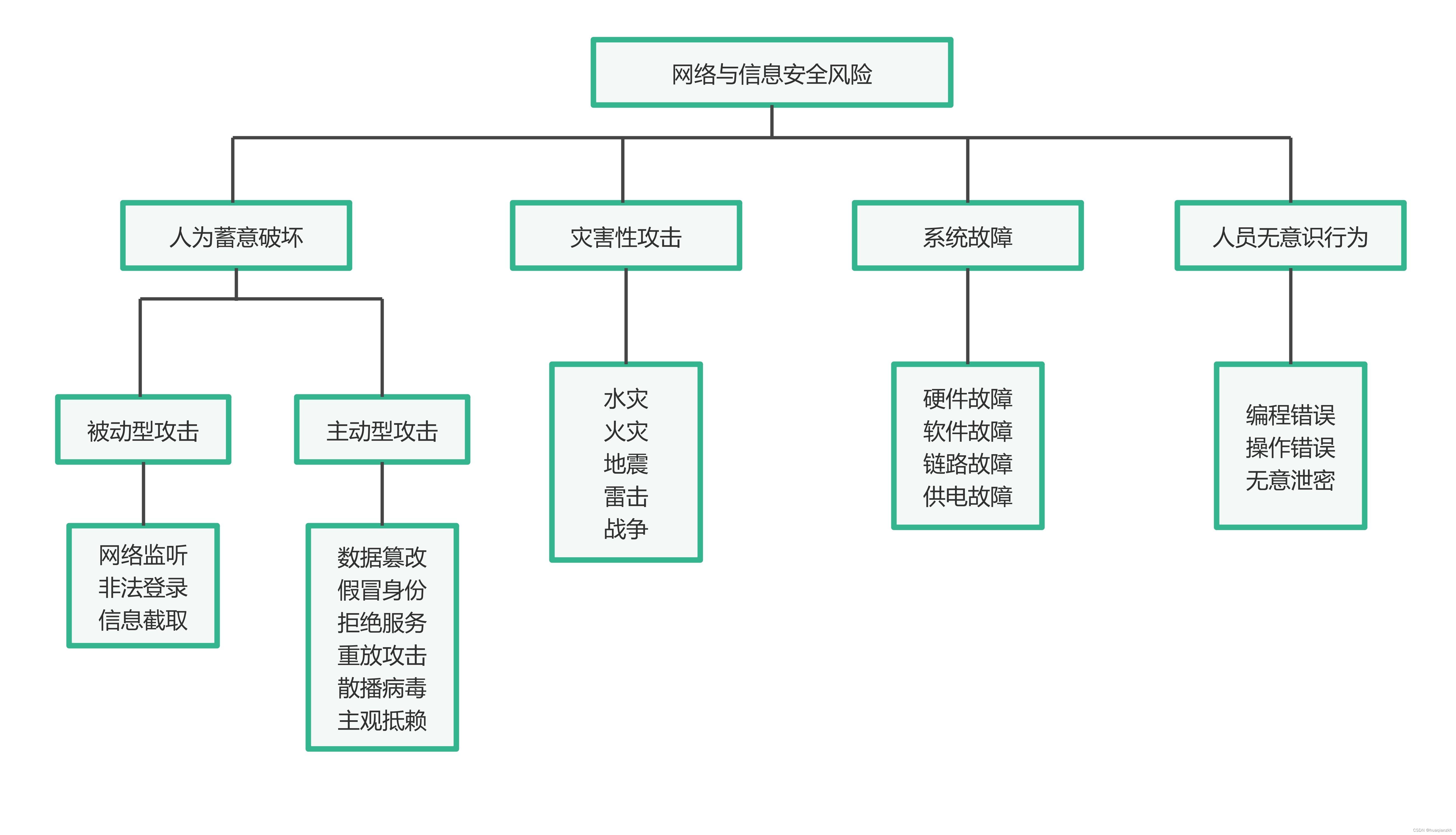
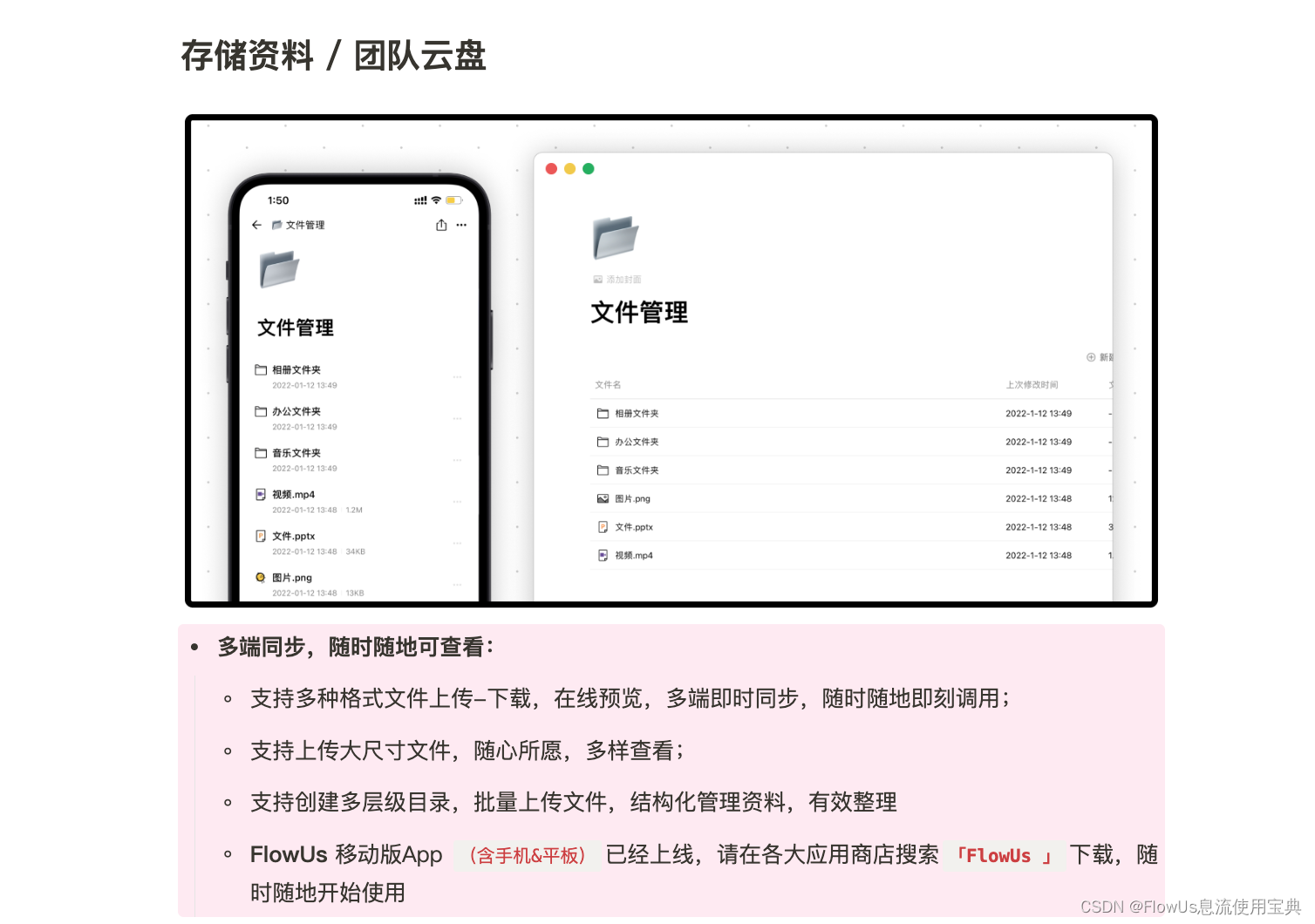
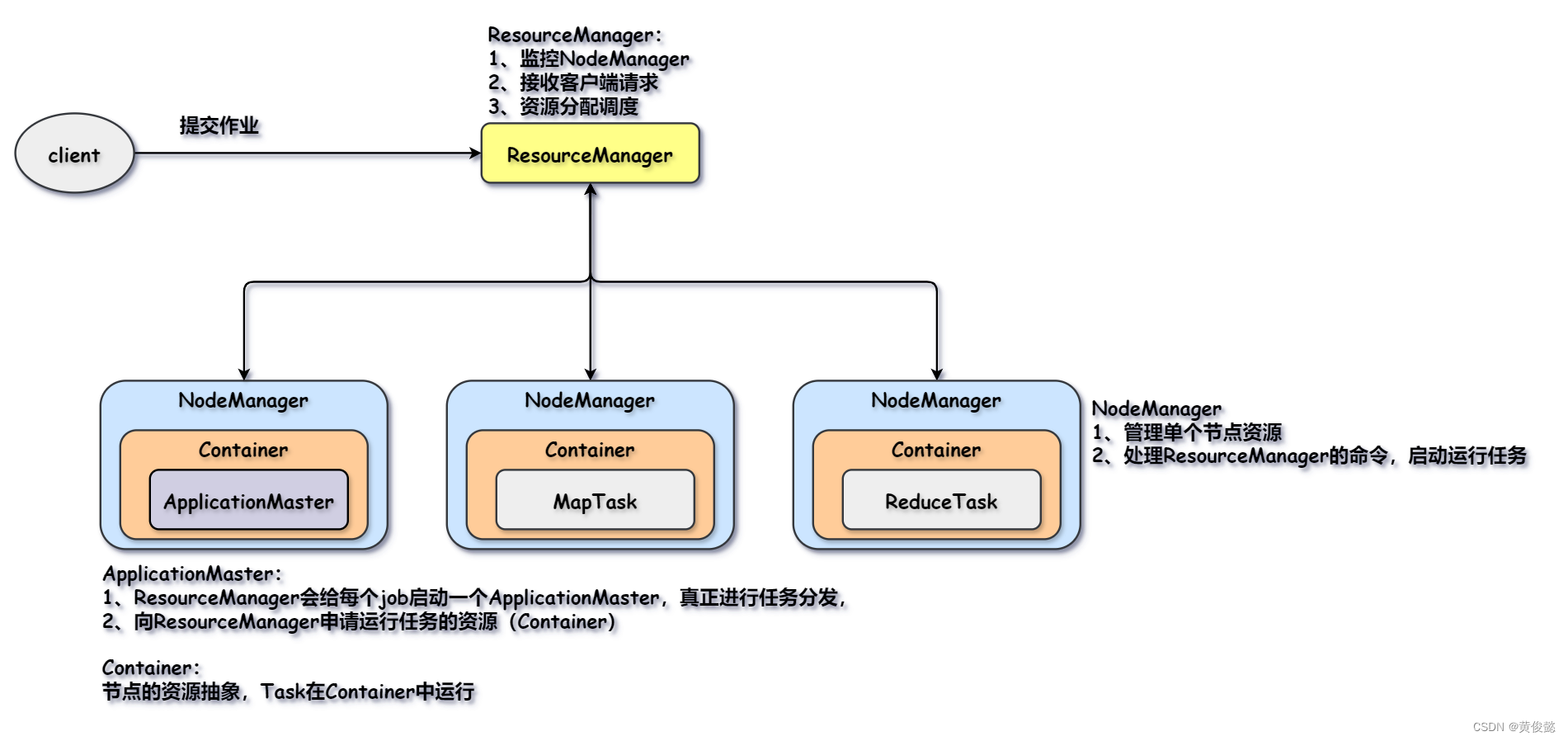
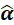Logistic Regression:
y
^
=
σ
(
w
T
x
+
b
)
\hat{y}=\sigma{(w^T x+b)}
y^=σ(wTx+b) using sigmoid function
σ
=
1
1
+
e
−
z
\sigma = \frac{1}{1+e^{-z}}
σ=1+e−z1.
【torch.sigmoid(x)】
Sigmoid
(
x
)
=
1
1
+
e
−
x
\text{Sigmoid}(x)=\frac{1}{1+e^{-x}}
Sigmoid(x)=1+e−x1
Logistic Regression loss function:
L
(
y
^
,
y
)
=
1
2
(
y
^
−
y
)
2
\mathcal{L}(\hat{y},y) = \frac{1}{2} (\hat{y}-y)^2
L(y^,y)=21(y^−y)2 × non-convex
L
(
y
^
,
y
)
=
−
(
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
)
\mathcal{L}(\hat{y},y) = -(y \log \hat{y} + (1-y) \log (1-\hat{y} ))
L(y^,y)=−(ylogy^+(1−y)log(1−y^)) √ convex
Logistic Regression cost function:
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
y
^
(
i
)
,
y
(
i
)
)
=
−
1
m
∑
i
=
1
m
(
y
(
i
)
log
y
^
(
i
)
+
(
1
−
y
(
i
)
)
log
(
1
−
y
^
(
i
)
)
)
J(w, b) = \frac{1}{m} \sum^m_{i=1} \mathcal{L}(\hat{y}^{(i)},y^{(i)}) = - \frac{1}{m} \sum^m_{i=1} (y^{(i)} \log \hat{y}^{(i)} + (1-y^{(i)}) \log (1-\hat{y}^{(i)} ))
J(w,b)=m1∑i=1mL(y^(i),y(i))=−m1∑i=1m(y(i)logy^(i)+(1−y(i))log(1−y^(i)))

![[OtterCTF 2018]Play Time](https://img-blog.csdnimg.cn/img_convert/4b5dd37a09b98fb65aa13c176bad5106.png)