一、简介
PaddleOCR 旨在打造一套丰富、领先、且实用的 OCR 工具库,助力开发者训练出更好的模型,并应用落地。

支持多种 OCR 相关前沿算法,在此基础上打造产业级特色模型PP-OCR、PP-Structure和PP-ChatOCRv2,并打通数据生产、模型训练、压缩、预测部署全流程。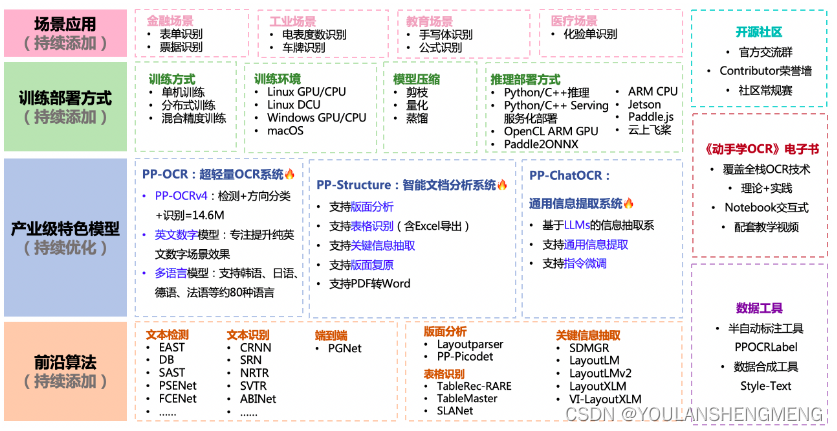
二、环境搭建
2.1 源码开发环境搭建方法
onda create -n paddle python=3.9.12 conda activate paddle python -m pip install paddlepaddle-gpu==2.5.1.post120 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html # 在Python解释器中顺利执行如下命令 >>> import paddle >>> paddle.utils.run_check() # 如果命令行出现以下提示,说明PaddlePaddle安装成功 # PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now. # 查看PaddlePaddle版本 >>> print(paddle.__version__) # 项目克隆 git clone https://github.com/PaddlePaddle/PaddleOCR ## 2. 安装第三方库 ``` cd PaddleOCR pip3 install -r requirements.txt ```
2.2 快速开始
1)环境搭建
参考链接:https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/quickstart.md
#GPU
pip install paddlepaddle-gpu
#CPU
pip install paddlepaddle
#安装paddleocr
pip install paddleocr2)快速执行应用
#快速测试效果
1)检测+方向分类器+识别全流程:--use_angle_cls true设置使用方向分类器识别180度旋转文字,--use_gpu false设置不使用GPU
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false
结果是一个list,每个item包含了文本框,文字和识别置信度
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)]
......2)单独使用检测:设置
--rec为false
paddleocr --image_dir ./imgs/11.jpg --rec false结果是一个list,每个item只包含文本框
[[27.0, 459.0], [136.0, 459.0], [136.0, 479.0], [27.0, 479.0]]
[[28.0, 429.0], [372.0, 429.0], [372.0, 445.0], [28.0, 445.0]]
......3)单独使用识别:设置
--det为false
paddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.994467]
3)模型说明
版本说明 paddleocr默认使用PP-OCRv4模型(--ocr_version PP-OCRv4),如需使用其他版本可通过设置参数--ocr_version,默认的为最新的模型。
4)不同语言模型的设置
PaddleOCR目前支持80个语种,可以通过修改
--lang参数进行切换,对于英文模型,指定--lang=en。paddleocr --image_dir ./imgs_en/254.jpg --lang=en
2.3使用python代码快速调用
2.3.1 中英文与多语言使用
通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。
- 检测+方向分类器+识别全流程
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')2.3.2 大图像的OCR识别
要使用滑动窗口进行光学字符识别(OCR),可以使用以下代码片段:
from paddleocr import PaddleOCR
from PIL import Image, ImageDraw, ImageFont
# 初始化OCR引擎
ocr = PaddleOCR(use_angle_cls=True, lang="en")
img_path = "./very_large_image.jpg"
slice = {'horizontal_stride': 300, 'vertical_stride': 500, 'merge_x_thres': 50, 'merge_y_thres': 35}
results = ocr.ocr(img_path, cls=True, slice=slice)
# 加载图像
image = Image.open(img_path).convert("RGB")
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("./doc/fonts/simfang.ttf", size=20) # 根据需要调整大小
# 处理并绘制结果
for res in results:
for line in res:
box = [tuple(point) for point in line[0]]
# 找出边界框
box = [(min(point[0] for point in box), min(point[1] for point in box)),
(max(point[0] for point in box), max(point[1] for point in box))]
txt = line[1][0]
draw.rectangle(box, outline="red", width=2) # 绘制矩形
draw.text((box[0][0], box[0][1] - 25), txt, fill="blue", font=font) # 在矩形上方绘制文本
# 保存结果
image.save("result.jpg")2.4 参数设定说明
参考博文的链接:
【Python】paddleocr快速使用及参数详解_paddleocr python-CSDN博客
1)使用默认路径下的模型
import cv2
from paddleocr import PaddleOCR
# 使用默认模型路径
paddleocr = PaddleOCR(lang='ch', show_log=False)
img = cv2.imread('ch2.jpg') # 打开需要识别的图片
result = paddleocr.ocr(img)
for i in range(len(result[0])):
print(result[0][i][1][0]) # 输出识别结果
2)设定模型路径
import cv2
from paddleocr import PaddleOCR
# 设定模型路径
paddleocr = PaddleOCR(lang='ch', show_log=False,
det_model_dir='.paddleocr\\whl\\det\\ch\\ch_PP-OCRv4_det_infer',
rec_model_dir='.paddleocr\\whl\\rec\\ch\\ch_PP-OCRv4_rec_infer') # 推理模型路径
img = cv2.imread('ch2.jpg') # 打开需要识别的图片
result = paddleocr.ocr(img)
for i in range(len(result[0])):
print(result[0][i][1][0]) # 输出识别结果
3)其他参数介绍
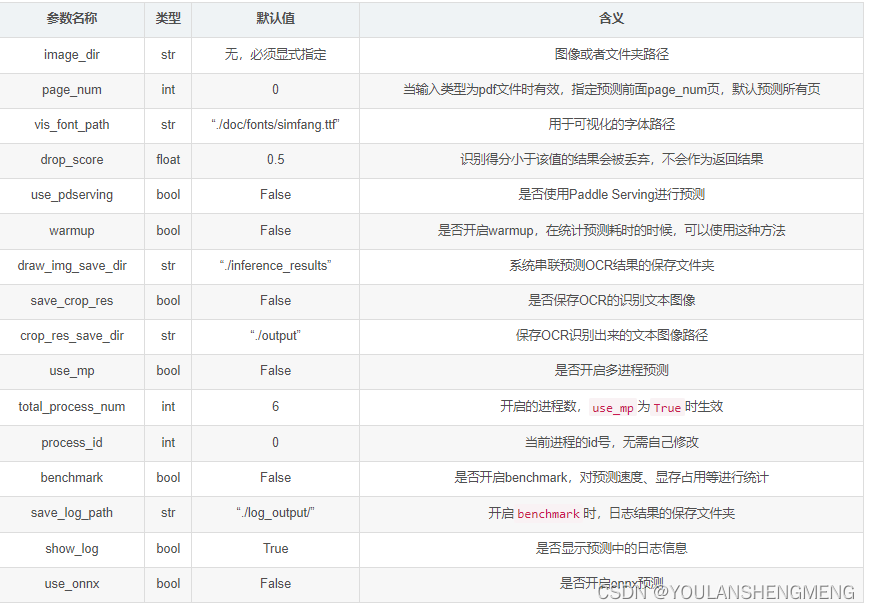
在使用PaddleOCR进行模型推理时,可以自定义修改参数,来修改模型、数据、预处理、后处理等内容,详细的参数解释如下所示。
- 全局信息
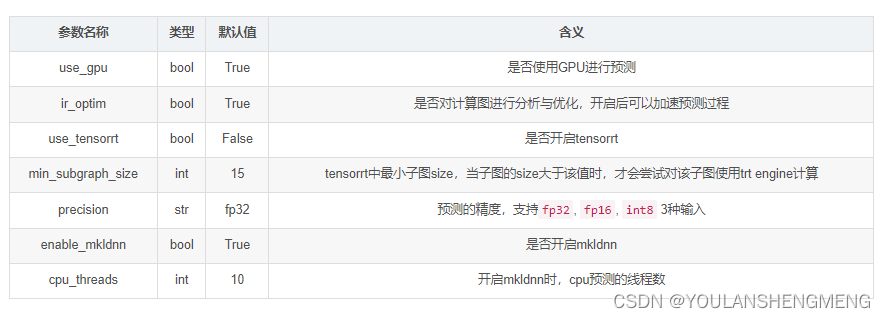
- 预测引擎相关
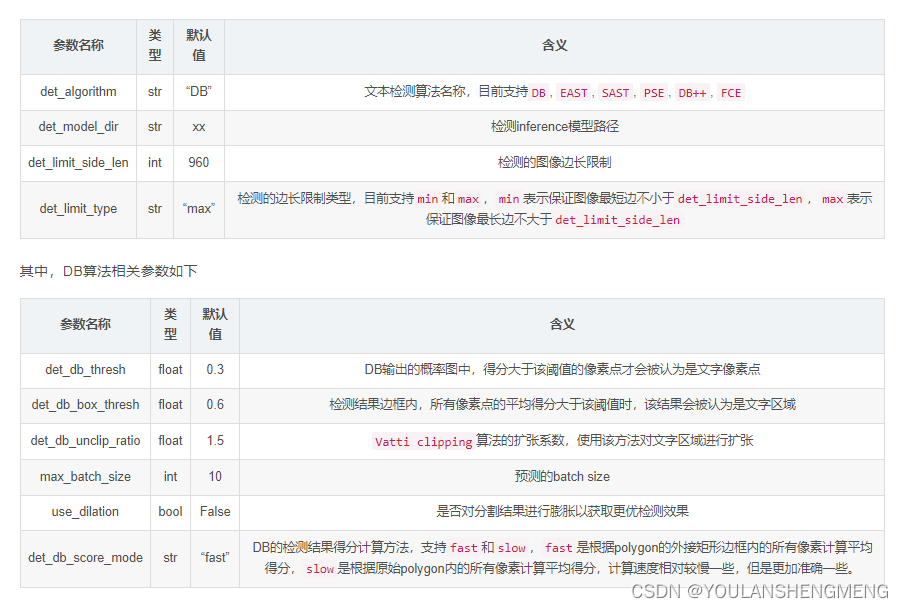
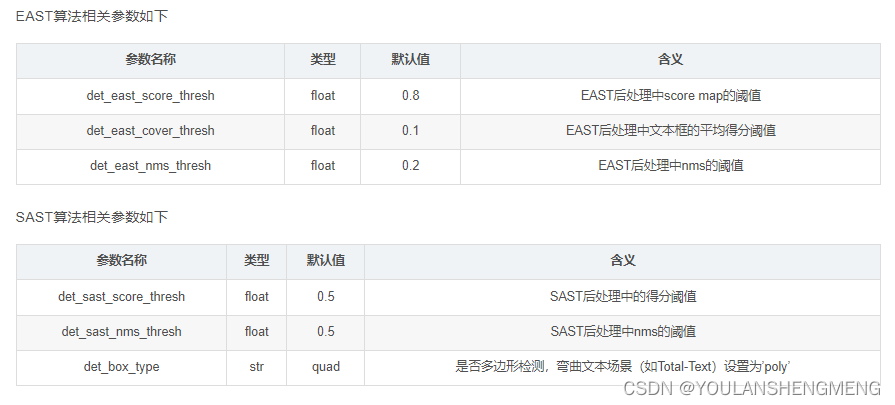
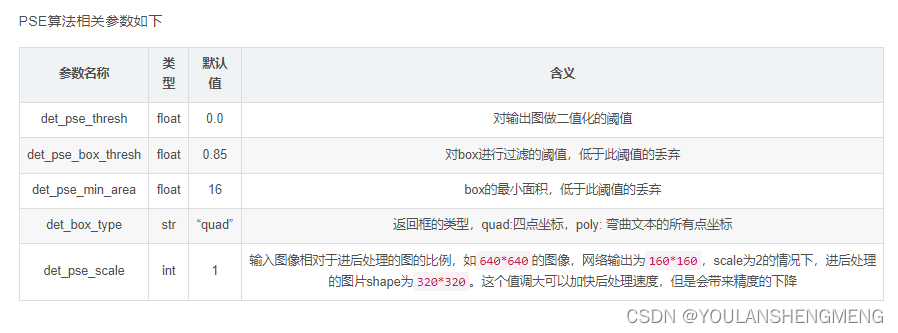
- 文本检测模型相关
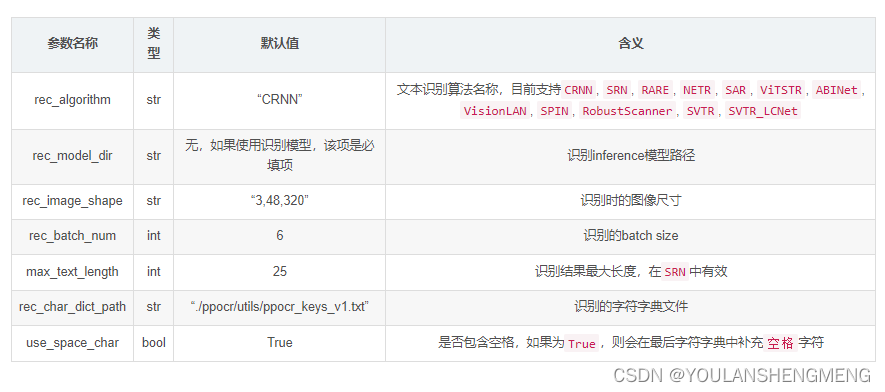
- 文本识别模型相关
- 端到端文本检测与识别模型相关

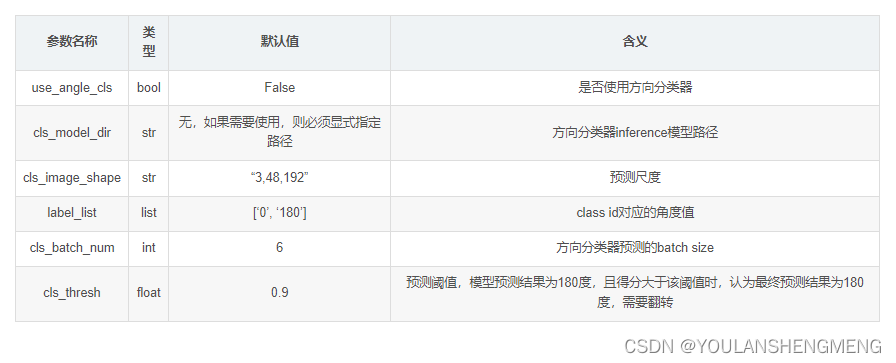
- 方向分类器模型相关
三、目前常用的开源OCR识别框架
参考博文:开源的OCR工具基本使用:PaddleOCR/Tesseract/CnOCR_cnocr 只支持cudn吗-CSDN博客
3.1 EasyOCR
EasyOCR官方仓库:https://github.com/JaidedAI/EasyOCR
安装EasyOCR:
pip install easyocr
测试例程:
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
result = reader.readtext('chinese.jpg')对正向的文本检测效果是可以的,但是对倒置的文本的检测效果不好。
图片越大,OCR耗时越长,如果你只需要识别图片特定部分,可以先把图片裁剪了,减少识别区域,加快OCR识别速度(我当时的需求,只需要识别图片上半部分,于是就将上半张图片另存为新图。识别半张图比完整图快2.6倍)
- 优点
- 支持pip安装,但需要自己手动下载模型
- ocr识别效果尚可,优于一般开源模型
- 缺点
- 速度很慢,900 * 1200像素图片平均需要30s左右
- 不支持补充训练
3.2 CnOCR
CnOCR官方仓库:https://github.com/breezedeus/CnOCR
CnOCR安装:
pip install cnocr
CnOCR的环境要求比较严格,其在requirements.txt写了非常多的依赖版本号,因此如果在现有环境中直接安装,它会将Pytorch等依赖卸载重装,比较坑,使用最好先单开新环境。
测试例程:
from cnocr import CnOcr
img_fp = 'img/output_2.png'
ocr = CnOcr() # 所有参数都使用默认值
out = ocr.ocr(img_fp)
print(out)实测在我的业务场景下,使用默认模型效果不太行。
- 优点
- 轻量模型,执行速度快,速度略快于paddle ocr
- 支持pip直接安装
- ocr识别效果好,识别效果比肩paddle ocr
- 支持训练自己的模型
- 缺点
- 部分符号识别效果差
- 部分场景下会出现空格丢失情况
- 模型补充训练没有paddle ocr方便
3.3 Tesseract
Tesseract官方仓库:https://github.com/tesseract-ocr/tesseract
Tesseract是用C++进行开发的,因此如果要在python中进行使用,需要借助第三方依赖pytesseract
首先需要在本机上安装Tesseract
安装包下载地址:https://digi.bib.uni-mannheim.de/tesseract/
安装过程可参考:https://blog.csdn.net/weixin_51571728/article/details/120384909
配置完成后,在命令行输入tesseract -v打印出版本信息则表示安装成功。
之后安装pytesseract:
pip install pytesseract
测试例程:
img_path = 'img/img_1.png'
# 添加tesseract的路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Users\zxy\AppData\Local\Programs\Tesseract-OCR\tesseract.exe'
"""
image_to_string():如果识别英文或数字可以不必额外参数,如果识别其他语言则需要加上lang参数
lang='chi_sim'表示要识别的是中文简体
没有识别出来时,返回空白
"""
text = pytesseract.image_to_string(Image.open(img_path), lang='chi_sim')
print(text)实测这个效果在我的场景也表现一般,并且tesseract对于中英文有不同的模型,泛用性不是很好。
- 优点
- 支持补充训练
- 缺点
- 安装使用困难,不支持pip安装
- 中文识别效果差
3.4 chinese_lite OCR
环境配置方法参考博文:
chinese_lite OCR使用教程_chineseliteocr-CSDN博客
- 优点
- 轻量模型,执行速度快,速度优于CnOCR和Paddle OCR
- ocr识别效果尚可,优于一般开源模型,但比不上CnOCR和Paddle OCR
- 作者提供了多种语言下的Demo
- 缺点
- 不支持pip安装
- 文本位置识别略差
- 不支持补充训练
- 类手写字体识别效果一般
- 部分场景下会出现误识别竖版文字的情况
例如:

3.4 PaddleOCR
根据PP-OCRv4的介绍文档,PP-OCRv4在训练时以(32,320), (48,320), (64,320)三个不同尺度上进行训练。
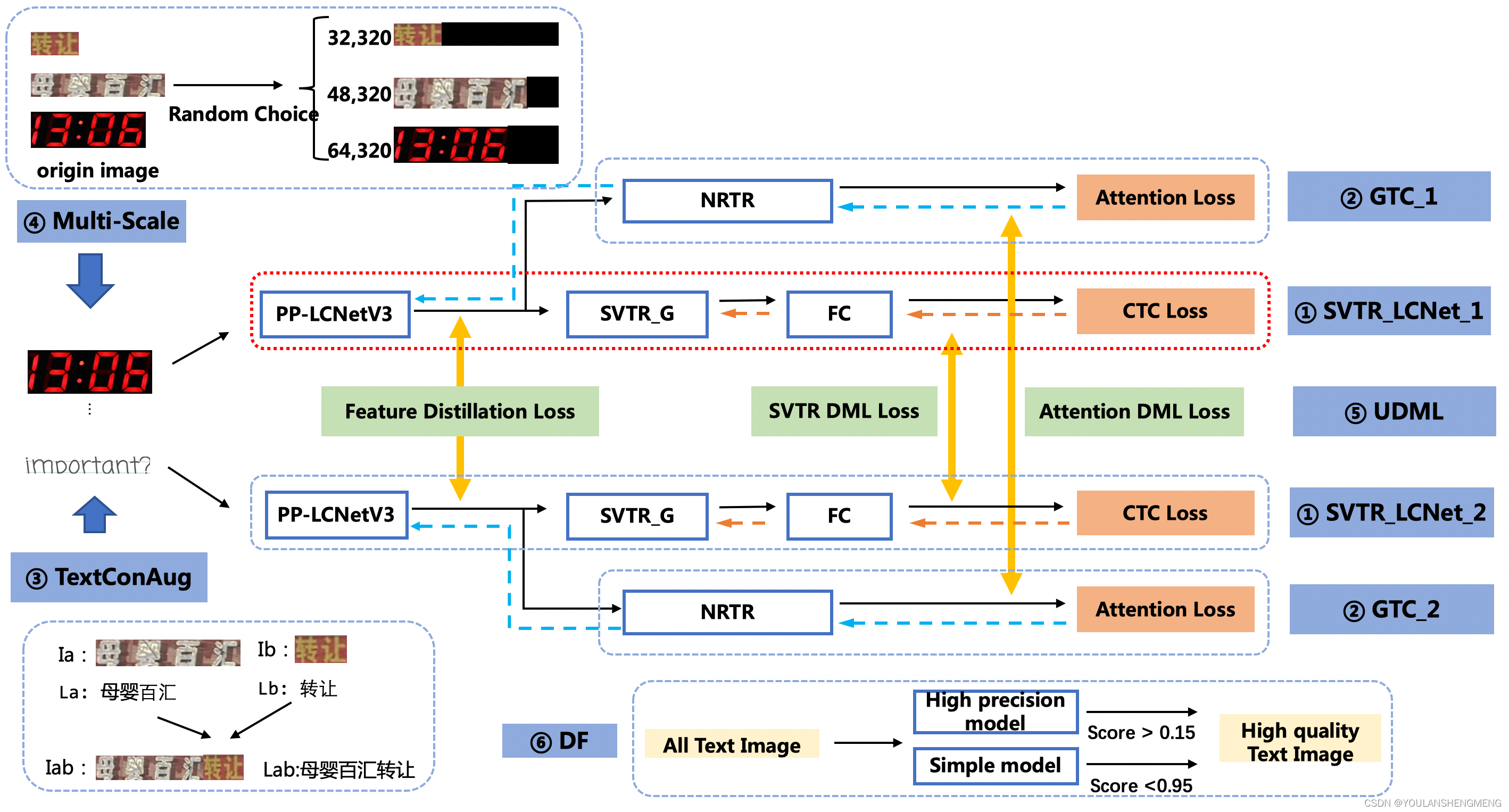
实测发现当文字区域小于这个范围时,效果会受到影响,因此,可以引入padding策略,即在文字区域范围周边加一圈白边,使输入模型的图片分辨率提升。
import cv2
from paddleocr import PaddleOCR
def add_padding_to_image(image, output_size=(640, 640), color=(255, 255, 255)):
h, w = image.shape[:2]
# 计算需要添加的padding大小
delta_w = max(output_size[0] - w, 0)
delta_h = max(output_size[1] - h, 0)
top, bottom = delta_h // 2, delta_h - (delta_h // 2)
left, right = delta_w // 2, delta_w - (delta_w // 2)
# 添加padding
padded_image = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return padded_image
if __name__ == '__main__':
ocr = PaddleOCR(use_angle_cls=True, lang="ch", ocr_version='PP-OCRv4')
image_input_fullname = 'img/output_5.png'
img = cv2.imread(image_input_fullname)
padded_img = add_padding_to_image(img)
result = ocr.ocr(img, cls=True)
print(result)在我的业务场景中,PaddleOCR的表现最好,基本能达到80%以上的识别准确率,如果还需要提升,还可以根据自己的数据再训练。
标注工具:PPOCRLabelv2
使用文档:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/PPOCRLabel/README_ch.md
训练文档:https://aistudio.baidu.com/modelsdetail/270?modelId=270
优缺点:
- 优点
- 轻量模型,执行速度快
- 支持pip直接安装
- ocr识别效果好,效果基本可以比肩大厂收费ocr(非高精版)
- 支持表格和方向识别
- 支持补充训练且很方便
- 缺点
- 部分符号识别效果一般,如 '|‘识别为’1’
- 对于部分加粗字体可能出现误识别,需要自己补充训练
- 偶尔会出现部分内容丢失的情况
3.5 总结
整体来看推荐使用paddle ocr和cnocr,某些场景下,如小图片且对速度要求较高可以尝试使用chinese_lite ocr.
四、特殊场景下新出的模型的总结
4.1 弧状文本检测
参考博文:
DPText-DETR: 基于动态点query的场景文本检测,更高更快更鲁棒 | 京东探索研究院_querydetr-CSDN博客

【论文】https://arxiv.org/abs/2207.04491
【代码】https://github.com/ymy-k/DPText-DETR




![[leetcode hot 150]第一百二十二题,买卖股票的最佳时机Ⅱ](https://img-blog.csdnimg.cn/direct/3333a1aa25c34a05a96d91f557599220.png)