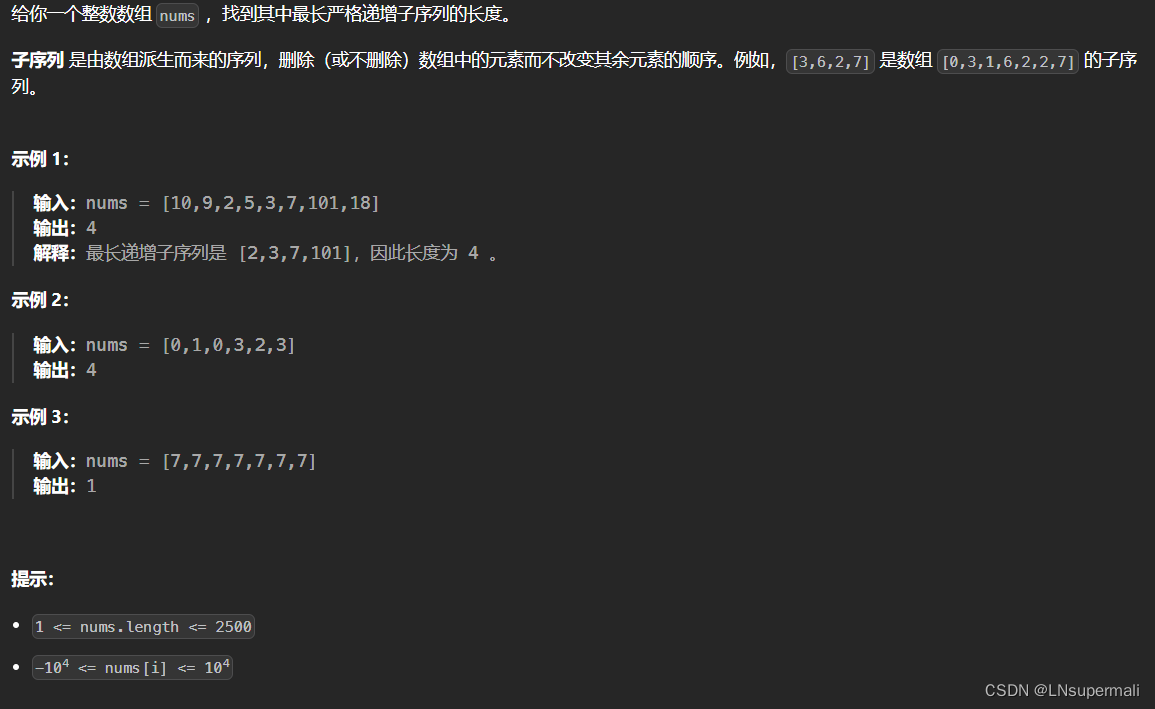
| 题目:TextGrad: Automatic “Differentiation” via Text |
|---|
| 作者: Mert Yuksekgonul; Federico Bianchi; Joseph Boen; Sheng Liu; Zhi Huang; Carlos Guestrin; James Zou |
| DOI: 10.48550/arXiv.2406.07496 |
| 摘要: AI is undergoing a paradigm shift, with breakthroughs achieved by systems orchestrating multiple large language models (LLMs) and other complex components. As a result, developing principled and automated optimization methods for compound AI systems is one of the most important new challenges. Neural networks faced a similar challenge in its early days until backpropagation and automatic differentiation transformed the field by making optimization turn-key. Inspired by this, we introduce TextGrad, a powerful framework performing automatic ``differentiation’’ via text. TextGrad backpropagates textual feedback provided by LLMs to improve individual components of a compound AI system. In our framework, LLMs provide rich, general, natural language suggestions to optimize variables in computation graphs, ranging from code snippets to molecular structures. TextGrad follows PyTorch’s syntax and abstraction and is flexible and easy-to-use. It works out-of-the-box for a variety of tasks, where the users only provide the objective function without tuning components or prompts of the framework. We showcase TextGrad’s effectiveness and generality across a diverse range of applications, from question answering and molecule optimization to radiotherapy treatment planning. Without modifying the framework, TextGrad improves the zero-shot accuracy of GPT-4o in Google-Proof Question Answering from $51\%$ to $55\%$, yields $20\%$ relative performance gain in optimizing LeetCode-Hard coding problem solutions, improves prompts for reasoning, designs new druglike small molecules with desirable in silico binding, and designs radiation oncology treatment plans with high specificity. TextGrad lays a foundation to accelerate the development of the next-generation of AI systems. |
| GitHub: https://github.com/zou-group/textgrad |
📜 研究核心
⚙️ 内容
方法描述
该论文提出了一种名为TEXTGRAD的方法,用于优化基于文本反馈的人工智能系统。它通过构建计算图来表示系统的结构,并使用类似于自动微分的算法来计算梯度。与传统的自动微分不同的是,TEXTGRAD能够处理复杂的黑盒AI系统,并将其转化为可微分的形式。此外,TEXTGRAD还提供了一个抽象层,使得用户可以像使用PyTorch一样方便地定义和操作模型。
方法改进
TEXTGRAD的主要改进在于其使用了文本反馈来进行梯度计算。这种方法允许用户通过自然语言输入来指定目标函数和约束条件,从而更加灵活地定义问题和优化目标。此外,TEXTGRAD还提供了一些优化技术,如批量优化、受约束优化和动量优化等,以提高优化效率和稳定性。
解决的问题
TEXTGRAD主要解决了两个问题:一是如何在复杂的黑盒AI系统中实现有效的梯度计算;二是如何更好地利用自然语言输入来定义和优化问题。通过将这些问题转化为计算图的形式并使用文本反馈来进行梯度计算,TEXTGRAD提供了一种通用而灵活的优化框架,可以在各种人工智能应用中得到广泛的应用。
💡 创新点
TEXTGRAD的创新点主要体现在以下几个方面:
-
自动“微分”通过文本反馈:TEXTGRAD的核心创新在于它能够将大型语言模型(LLMs)产生的自然语言文本反馈转化为对复合AI系统各组成部分的优化信号,这一过程可类比于数学中的自动微分在神经网络优化中的应用。这标志着自动优化方法的一个重要拓展,从数值计算领域跨越到文本和语言处理领域,为AI系统优化提供了新的思路。
-
跨领域应用的灵活性:该框架不仅适用于代码优化、逻辑推理问题的解答,还能扩展到分子结构设计、放射治疗规划等高度专业化的领域,展现了其强大的通用性和跨界应用能力。这表明TEXTGRAD能够理解并优化不同领域的复杂问题,不受限于特定的任务类型或数据格式。
-
无缝集成与即插即用性:用户仅需提供目标函数,无需调整框架内部组件或优化提示,TEXTGRAD即可直接应用于多种任务,大大降低了使用门槛和定制化需求。这种设计简化了复合AI系统开发的流程,使得非专业人士也能利用强大的语言模型进行系统优化。
-
基于自然语言的反馈机制:区别于传统的数值型梯度,TEXTGRAD通过自然语言描述反馈,如提出具体的修改建议或指出错误的原因,这使得优化过程更加直观且易于理解。这种形式的反馈更容易为人所接受,也为模型之间的交互和解释性提供了新的路径。
-
优化效率与性能提升:TEXTGRAD在实际应用中显示出了显著效果,如在未作任何框架修改的情况下,将GPT-4o在特定问答任务的零样本准确率从51%提高到55%,以及在优化编程问题解决方案时获得20%的性能增益。这些实证结果证明了TEXTGRAD在提升模型性能方面的有效性和实用性。
-
促进复合AI系统发展:TEXTGRAD的出现为下一代AI系统的开发奠定了基础,特别是那些由多个复杂组件(如LLMs、模拟器、搜索引擎等)组成的系统。它不仅能够加速这些系统的构建过程,还能通过持续反馈循环促进它们的自我优化,推动AI技术的边界不断向前推进。
综上所述,TEXTGRAD的创新点在于它开创性地将文本和自然语言反馈整合进自动优化过程,展现了跨领域的应用潜力,简化了复合AI系统的优化流程,并在实践中取得了实质性的性能提升,为AI领域带来了新的优化范式。
🧩 不足
尽管TEXTGRAD是一个创新且功能强大的框架,旨在通过文本实现自动“微分”以优化复合AI系统,但它也存在一些潜在的不足和局限性:
-
依赖于语言模型的质量与限制:TEXTGRAD的性能和有效性在很大程度上取决于所使用的大型语言模型(LLMs)的质量。如果LLMs无法准确理解任务上下文、给出高质量的优化建议,或者在特定领域知识上存在盲区,这将直接影响到TEXTGRAD的输出质量。此外,当前的LLMs可能无法完全理解或生成涉及高度专业或复杂的数学、科学表述,限制了其在某些领域的应用。
-
主观性与解释性问题:由于TEXTGRAD依赖于自然语言反馈,这种反馈可能包含主观性,特别是在没有具体量化指标的领域。自然语言的模糊性和多义性可能导致优化建议的解释和实施不够明确,增加了优化过程的不确定性。
-
数据隐私与安全:在使用TEXTGRAD进行优化时,尤其是涉及敏感数据如医疗记录或专有代码时,必须考虑数据隐私和安全问题。语言模型的训练数据可能包含用户信息,而文本反馈机制可能暴露敏感信息,因此需要严格的数据保护措施。
-
优化目标的明确性:TEXTGRAD要求用户提供清晰的目标函数,但在实际应用中,定义一个全面且准确的目标函数可能是具有挑战性的,特别是在复杂多目标优化场景下。目标函数的不明确或不完整可能会导致优化结果偏离预期。
-
反馈格式标准化:为了使TEXTGRAD有效工作,需要有一个清晰、结构化的反馈格式,但自然语言的自由形式可能导致格式不一,增加处理难度。虽然TEXTGRAD设计了特定的提示格式,但在实际应用中保持一致性和高效处理各种反馈仍然是一个挑战。
-
内外循环优化的复杂性:在治疗计划优化等应用场景中,TEXTGRAD采用的内外循环优化策略增加了系统的复杂性。内外层参数的相互作用和平衡可能难以调整,且对算法设计和调优提出了更高要求。
-
模型可解释性与透明度:由于TEXTGRAD的决策过程涉及到自然语言理解和处理,其决策路径可能不如基于数值的优化方法透明。提高模型的可解释性,让最终用户或开发者理解优化决策背后的原因,是未来改进的方向之一。
综上所述,TEXTGRAD虽在多个领域展示出巨大潜力,但仍需在确保模型准确度、提高反馈质量、增强数据安全、优化目标明确性、处理格式多样性、简化复杂性以及增强可解释性等方面进行持续改进。
🔁 研究内容
💧 数据
研究中使用了多个数据集进行验证,包括Google-proof QA、MMLU-Machine Learning、Object Counting、Word Sorting、GSM8k等,涵盖了逻辑推理、物理、数学等多个领域。
👩🏻💻 方法
- 初始化系统提示: TEXTGRAD首先需要一个可训练的系统提示,这个提示定义了LLM如何理解和响应特定任务。系统提示是一个变量,标记为需要梯度计算(
requires_grad=True),并且包含角色描述,比如指导LLM如何思考和回应。 - 模型集成: 通过
tg.BlackboxLLM类,TEXTGRAD将系统提示与LLM绑定。这个模型对象参数化了系统提示,使得提示成为模型行为的一部分,可以对其进行优化。 - 优化流程: 使用
tg.TextualGradientDescent优化器来调整系统提示。在每次迭代中,优化器会处理一批训练样本,执行前向传播,计算损失,并应用反向传播。zero_grad()清零梯度,然后通过计算损失并调用backward()方法来累积梯度。最后,step()函数依据累积的文本梯度更新系统提示。 - 损失计算与累积: 损失函数(
loss_fn)用于量化模型响应与真实标签之间的差异。对于每个批次,TEXTGRAD会独立计算每个样本的损失,然后使用类似PyTorch中torch.sum的tg.sum函数来累加这些损失。 - 约束优化: TEXTGRAD支持使用自然语言表达的约束条件来引导优化过程。例如,可以通过指示LLM在响应的结尾按照特定格式输出答案,来确保输出符合预期格式。
- 动量机制: 类似于传统梯度下降中的动量概念,TEXTGRAD在更新变量时可以考虑之前迭代的信息,这有助于加速收敛并可能提高稳定性。
- 灵活性与易用性: TEXTGRAD设计遵循PyTorch的语法和抽象,使得用户只需提供目标函数,而无需深入调整框架的组件或提示。它支持开箱即用,适用于多种任务场景。
🔬 实验
本文介绍了作者使用自然语言处理技术实现的文本梯度下降(TEXTGRAD)框架,并将其应用于多个领域的优化问题中。具体来说,作者将TEXTGRAD显著提高了GPT-4o在Google-proof QA任务上的零样本准确率(从51%提升至55%),并在分子优化和治疗计划优化等领域也取得了显著进展。
- 代码优化:作者通过将一些编程任务转换为求解最优参数的问题,使用TEXTGRAD对代码进行了优化。实验结果表明,使用TEXTGRAD可以显著提高代码的正确率和运行效率。
- 解决方案优化:作者将TEXTGRAD用于解决科学问题,通过对问题进行建模并生成解决方案,然后使用TEXTGRAD对解决方案进行优化。实验结果表明,使用TEXTGRAD可以显著提高解决方案的质量。
- 提高语言模型表现:作者使用TEXTGRAD对语言模型进行优化,以提高其性能。实验结果表明,使用TEXTGRAD可以使语言模型在各种任务中的表现得到显著提升。
- 化学结构优化:作者使用TEXTGRAD对化学分子进行优化,以同时提高其与蛋白质结合的能力和药用性质。实验结果表明,使用TEXTGRAD可以设计出具有高度竞争力的化合物。
- 放射治疗计划优化:作者使用TEXTGRAD对放射治疗计划进行优化,以平衡肿瘤靶向和器官保护的需求。实验结果表明,使用TEXTGRAD可以显著提高治疗计划的质量。
📜 结论
TEXTGRAD成功地展示了通过文本反馈进行复合AI系统优化的能力,不仅提升了模型性能,还降低了运行成本。它为复杂AI系统的自动化优化提供了一种新的、有效的途径,证明了自然语言作为优化媒介的有效性和潜力。
🤔 个人总结
文章优点
- 提出了一种新的自动优化框架TEXTGRAD,通过将AI系统转化为计算图,并使用自然语言反馈来实现自动优化。
- 在多个领域进行了广泛的应用,包括编程问题解决、科学问题回答、推理任务优化、化学分子设计以及医学治疗计划优化等。
- 获得了与现有方法相比显著的性能提升,例如在LeetCode编程问题上提高了20%的相关性能。
方法创新点
- 利用了大型语言模型(LLM)的能力,将它们作为系统的组成部分,并利用它们提供丰富的自然语言反馈来进行优化。
- 将系统的各个部分抽象为计算图中的变量和函数调用,然后通过自然语言反馈来调整这些变量以改善系统性能。
- 该方法具有很高的灵活性,可以应用于各种不同的领域和任务。
未来展望
- 可以进一步扩展TEXTGRAD框架,使其能够处理更多类型的组件和工具,如搜索引擎、代码解释器等。
- 可以探索更多的算法优化方向,如使用方差减少技术、自适应梯度或自我验证等来提高优化的稳定性。
- 进一步研究实验和临床评估的结果,以验证TEXTGRAD的实际效果并发现潜在的问题。





![[OtterCTF 2018]Graphic‘s For The Weak](https://img-blog.csdnimg.cn/img_convert/c0a13197becf2dd5b17b407afdd28634.png)