前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除

目录
一、数据库的分类
1.1、SQL
1.2、NoSQL
1.3、如何选择?
二、ORM魔法
三、使用Flask-SQLALchemy管理数据库
3.1、连接数据库服务器
3.2、定义数据库模型
3.3、创建数据库和表
四、数据库操作
4.1、CRUD
4.2、在视图函数里操作数据库
五、定义关系
5.1、配置Python Shell上下文
5.2、一对多
5.3、多对一
5.4、一对一
5.5、多对多
六、更新数据库表
6.1、重新生成表
6.2、使用Flask-Migrate迁移数据库
6.3、开发时是否要迁移?
七、数据库进阶实践
7.1、级联操作
7.2、事件监听
致谢
数据库是大多数动态Web程序的基础设施。常见的数据库管理系统(DBMS)有:MySQL、PostgreSQL、SQLite、MongoDB等。
一、数据库的分类
数据库一般分为两种,SQL(Structured Query Language,结构化查询语言)数据库和NoSQL(Not Only SQL,泛指非关系型)数据库
1.1、SQL
SQL数据库指关系型数据库,常用的SQL DBMS主要包括SQL Server、Oracle、MySQL、PostgreSQL、SQLite等。关系型数据库使用表来定义数据对象,不同的表之间使用关系连接。
| id | name | sex | occupation |
|---|---|---|---|
| 1 | Nick | Male | Journalist |
| 2 | Amy | Female | Writer |
在SQL数据库中,每一行代表一条记录(record),每条记录又由不同的列(column)组成。在存储数据前,需要预先定义表模式(schema),以定义表的结构并限定列的输入数据类型。
基本概念:
- 表(table):存储数据的特定结构
- 模式(schema):定义表的结构信息
- 列/字段(column/field):表中的列,存储一系列特定的数据,列组成表
- 行/记录(raw/record):表中的行,代表一条记录
-
标量(scalar):指的是单一数据,与之相对的是集合(collection)
1.2、NoSQL
NoSQL是初指No SQL或No Relational,现在NoSQL社区一般会解释为Not Only SQL。NoSQL数据库泛指不使用传统关系型数据库中的表格形式的数据库。近年来,NoSQL数据库越来越流行,被大量应用在实时Web程序和大型程序中。在速度和可扩展性方面有很大优势,除此之外还拥有无模式、分布式、水平伸缩等特点
最常用的两种NoSQL数据库如下:
1.2.1、文档存储(document store)
文档存储是NoSQL数据库中最流行的种类,它可作为主数据库使用。文档存储使用的文档类似SQL数据库中的记录,文档使用类JSON格式来表示数据。常见的文档存储DBMS有MongoDB、CouchDB等。1.1的身份信息表中的第一条记录使用文档可表示为:
{
id: 1,
name: "Nick",
sex: "Male",
occupation: "Journalist"
}1.2.2、键值对存储(key-value store)
键值对存储在形态上类似Python中的字典,通过键来存取数据,在读取上非常快,通常用来存储临时内容,作为缓存使用。常见的键值对DBMS有Redis、Riak等,其中Redis不仅可以管理键值对数据库,还可以作为缓存后端(cache backed)、图存储(graph store)等类型的NoSQL数据库。
1.3、如何选择?
- NoSQL 数据库不需要定义表和列等结构,也不限定存储的数据格式,在存储方式上比较灵活,在特定的场景下效率更高。
- SQL 数据库稍显复杂,但不容易出错, 能够适应大部分的应用场景
- 大型项目通常会同时需要多种数据库,比如使用MySQL作为主数据库存储用户资料和文章,使用Redis缓存数据,使用MongoDB存储实时消息。
大多情况,SQL数据库都能满足你的需求。为便于测试,我们使用SQLite作为DBMS。
二、ORM魔法
在Web应用程序里使用原生SQL语句操作数据库主要存在以下问题:
- 手动编写SQL语句比较乏味,而且视图函数中加入太多SQL语句会降低代码的易读性。另外还会有安全问题,如SQL语句注入
- 常见的开发模式是在开发时使用简单的SQLite,而在部署时切换到MySQL等更健壮的DBMS。但是对于不同DBMS需要使用不同的Python接口库,这让DBMS的切换变得不太容易。
ORM会自动处理参数的转义,尽可能地避免SQL注入的发生。另外还为不同的DBMS提供统一的接口,让切换工作变得简单。ORM扮演翻译的角色,将我们的Python语言转换为DBMS能够读懂的SQL指令,让我们能够使用Python来操控数据库。
ORM把底层的SQL数据库实体转化成高层的Python对象。ORM主要实现了三层映射关系:
- 表--Python类
- 字段(列)--类属性
- 记录(行)--类实例
比如,创建一个contacts表来存储留言,其中包含用户名称和电话号码两个字段。在SQL中:
CREATE TABLE contacts(
name varchar(100) NOT NULL,
phone_number varchar(32),
)如果使用ORM:
from foo_orm import Model, Column, String
class Contact(Model):
__tablename__ = 'contacts'
name = Column(String(100),nullable=False)
phone_number = Column(String(32))要向表中插入一条记录,需要使用下面的SQL语句:
INSERT INTO contacts(name,phone_number)
VALUES('Grey Li','12345678')使用ORM则只需要创建一个Contact类的实例,传入对应的参数表示各个列的数据即可。
contact = Contact(name="Grey Li",phone_number="12345678")除了便于使用,ORM还有下面这些优点:
- 灵活性好。既能使用高层对象来操作数据库,又支持执行原生SQL语句。
- 提升效率。从高层对象转换成原生SQL会牺牲一些性能,但这换取的是巨大的效率提升
- 可移植性好。ORM通常支持多种DBMS,只需要稍微改动少量配置
使用Python实现的ORM有SQLALchemy、Peewee、PonyORM等。其中SQLALchemy是Python社区使用最广泛的ORM之一
三、使用Flask-SQLALchemy管理数据库
扩展Flask-SQLALchemy集成了SQLALchemy,它简化了连接数据库服务器、管理数据库操作会话等各类工作,让Flask中的数据处理体验变得更加轻松。
pip install flask-sqlalchemy实例化Flask-SQLALchemy提供的SQLALchemy类,传入 程序实例app以完成扩展的初始化:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
db = SQLAlchemy(app)3.1、连接数据库服务器
DBMS通常会提供数据库服务器运行在操作系统中。要连接数据库服务器,首先要为我们的程序指定数据库URI(Uniform Resource Identifier,统一资源标识符)。数据库URI是一串包含各种属性的字符串,其中包含了各种用于连接数据库的信息。
常用的数据库URI格式示例:
| DBMS | URI |
|---|---|
| PostgreSQL | postgresql://username:password@host/databasename |
| MySQL | mysql://username:password@host/databasename |
| Oracle | oracle://username:password@host:port/sidname |
| SQLite(UNIX) | sqlite:absolute/path/to/foo.db |
| SQLite(Windows) | sqlite:///absolute\\path\\to\\foo.db或r'sqlite:///absolute\path\to\foo.db' |
| SQLite(内存型) | sqlite:///或sqlite:///:memory: |
在Flask-SQLALchemy中,数据库的URI通过配置变量SQLALCHEMY_DATABASE_URI设置,默认为SQLite内存型数据库(sqlite:///:memory:),SQLite是基于文件的DBMS,不需要设置数据库服务器,只需要指定数据库文件的绝对路径。我们使用app.root_path来定位数据库文件的路径,并将数据库文件命名为data.db:
import os
app.config['SQLALCHEMY_DATABASE_URI'] = os.getenv('DATABASE_URL','sqlite:///'+os.path.join(app.root_path,'data.db'))在生产环境下更换到其他类型的DBMS时,数据库URL会包含敏感信息,所有这里优先从环境变量DATABSE_URL获取。
SQLite的数据库URI在Linux或macOS系统下的斜线数量是4个;在Windows系统下的URI中的斜线数量为3个。内存型数据库的斜线固定为3个。文件名不限后缀,常用的命名方式有foo.sqlite,foo.db或是注明版本的foo.sqlite3
设置好数据库URI后,在Python Shell中导入并查看db对象会得到下面的输出
>>> from app import db
>>> db
<SQLAlchemy>3.2、定义数据库模型
用来映射到数据库表的Python类通常被称为数据库模型(model),一个数据库模型类对应数据库中的一个表。定义模型即使用Python类定义表模式,并声明映射关系。所有模型类都需要继承Flask-SQLALchemy提供的db.Model基类。下面定义一个Note模型类,用来存储笔记:
class Note(db.Model):
id = db.Column(db.Integer,primary_key=True)
body = db.Column(db.Text)表的字段(列)由db.Column类的实例表示,字段的类型通过Column类构造方法的第一个参数传入。常用的SQLALchemy字段类型:
| 字段 | 说明 |
|---|---|
| Integer | 参数 |
| String | 字符串,可选参数length可以用来设置最大长度 |
| Text | 较长的Unicode文本 |
| Date | 日期,存储Python的datetime.date对象 |
| Time | 时间,存储Python的datetime.time对象 |
| DateTime | 时间和日期,存储Python的datetime对象 |
| Interval | 时间间隔,存储Python的datetime.timedelta对象 |
| Float | 浮点数 |
| Boolen | 布尔值 |
| PickleType | 存储Pickle列化的Python对象 |
| LargeBinary | 存储任意二进制数据 |
字段类型一般直接声明即可,如果需要传入参数,也可以添加括号。对于类似String的字符串列,有些数据库会要求限定长度,因此最好为其指定长度。虽然使用Text类型可以存储相对灵活的变长文本,但从性能上考虑,我们仅在必须的情况下使用Text类型,比如用户发表的文章和评论等不限长度的内容。
一般情况字段的长度是由程序设计者自定的。但也有特殊约束:比如姓名(英语)的长度一般不超过70个字符,中文名一般不超过20个字符,电子邮件地址的长度不超过254个字符。(当在数据库模型类中限制了字段的长度后,在接收对应数据的表单类字段里,也需要使用Length验证器来验证用户的输入数据)。
默认情况下,Flask-SQLALchemy会限制模型类的名称生成一个表名称,生成规则如下:
Message --> message # 单个单词转换为小写
FooBar --> foo_bar # 多个单词转换为小写并使用下划线分隔Note类对应的表名称即note。若想自己指定名称,可以通过定义tablename属性来实现。字段名默认为类属性名,也可以通过字段类构造方法的第一个参数指定,或使用关键字name。根据我们定义的Note模型类,最终生成一个note表,表中包含id和body字段,
常用的SQLALchemy字段参数:
| 参数名 | 说明 |
|---|---|
| primary_key | 如果设为True,该字段为主键 |
| unique | 如果设为True,该字段不允许出现重复值 |
| index | 如果设为True,为该字段创建索引,以提高查询效率 |
| nullable | 确定字段值可否为空,值为True或False,默认值为True |
| default | 为字段设置默认值 |
(不需要在所有列都建立索引。一般来说,取值可能性多(比如姓名)的列,以及经常被用来作为排序参照的列(比如时间戳)更适合建立索引。)
3.3、创建数据库和表
创建模型类后,我们需要手动创建数据库和对应的表,也就是我们常说的建库和建表。这通过我们的db对象调用create_all()方法实现。
$ flask shell
>>> from app import db
>>> db.create_all()如果将模型类定义在单独的模块中,那么必须在调用db.create_all()方法前导入相应模块,以便让SQLALchemy获取模型类被创建时生成的表信息,进而正确生成数据表。
通过下面的方式可以查看模型对应的SQL模式(建表语句):
>>> from sqlalchemy.schema import CreateTable
>>> print(CreateTable(Note.__table__))
CREATE TABLE note (
id INTEGER NOT NULL,
body TEXT,
PRIMARY KEY (id)
)(我们数据库和表一旦创建后,之后对模型的改动不会自动作用到实际的表中。如要使改动生效,调用db.drop_all()方法删除数据库和表,然后再调用create_all()方法创建)。
我们也可以自定义flask命令完成这个工作:
import click
@app.cli.command()
def initdb():
db.create_all()
click.echo('Initialized database')在命令行输入flask initdb即可创建数据库和表:
$ flask initdb
Initialized database.四、数据库操作
数据库操作主要是CRUD,即Create(创建)、Read(读取/查询)、Update(更新)和Delete(删除)。
SQLALchemy使用数据库会话来管理数据库操作,这里的数据库会话也称事务(transaction)。Flask-SQLALchemy自动帮我们创建会话,可以通过db.session属性获取
数据库中的会话代表一个临时缓存区,对数据库做出的任何改动都会存放在这里。可以调用add()方法将新创建的对象添加到数据库会话中,或是对会话中的对象进行更新。只有当你对数据库会话对象调用commit()方法时,改动才会被提交到数据库,这确保了数据提交的一致性。另外数据库会话也支持回滚操作。当你对会话调用rollback()方法时,添加到会话中且未提交的改动都将被撤销。
4.1、CRUD
默认情况下,Flask-SQLALchemy会自动为模型生成一个__repr()方法。当在Python shell中调用模型的对象时,__reper()方法会返回一条类似“<模型类名 主键值>”的字符串,比如<Note2>。为了便于操作,本示例重新定义__repr__()方法,返回一些更有用的信息。
class Note(db.Model):
...
def __repr__(self):
return '<Note %r>' % self.body4.1.1、Create
添加一条新记录到数据库主要分为三步:
- 创建Python对象(实例化模型类)作为一条记录。
- 添加新创建的记录到数据库会话
- 提交数据库会话
# 下面示例向数据库中添加了三条留言
>>> from app import db,Note
>>> note1 = Note(body='remember Sammy Jankis')
>>> note2 = Note(body='SHAVE')
>>> note3 = Note(body='DON NOT BELIEVE HIS LIES, HE IS THE ONE, KILL HIM')
>>> db.session.add(note1)
>>> db.session.add(note2)
>>> db.session.add(note3)
>>> db.session.commit()除了依次调用add()方法添加多个记录,也可以使用add_all()方法一次添加包含所有记录对象的列表。
我们在创建模型类的时候并没有定义id字段的数据,这是因为主键由SQLALchemy管理。模型类对象创建后作为临时对象(transient),当你提交数据库会话后,模型类对象才会转换为数据库记录写入数据库中,这时模型类对象会自动获得id值。
4.1.2、Read
使用模型类提供的query属性附加调用各种过滤方法及查询方法即可从数据库中取出数据
一般来说,一个完整的查询遵循下面的模式:
<模型类>.query.<过滤方法>.<查询方法>从某个模型出发,通过在query属性对应的Query对象上附加的过滤方法和查询函数对模型类对应的表中的记录进行各种筛选和调整,最终返回包含对应数据库记录数据的模型类实例,对返回的实例调用属性即可获得对应的字段数据。
SQLALchemy提供了许多查询方法用来获取记录:
| 查询方法 | 说明 |
|---|---|
| all() | 返回包含所有查询记录的列表 |
| first() | 返回查询的第一条记录,如果未找到,则返回None |
| one() | 返回第一条记录,且仅允许有一条记录。如果记录数量大于1或小于1,则抛出错误 |
| get(ident) | 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回None |
| count() | 返回查询结果的数量 |
| one_or_none() | 类似one(),如果结果数量不为1,返回None |
| first_or_404() | 返回查询的第一条记录,如果未找到,则返回404错误响应 |
| get_or_404(ident) | 传入主键值作为参数,返回指定主键值记录,如果未找到,则返回404错误响应 |
| paginate() | 返回一个Pagination对象,可以对记录进行分页处理 |
| with_parent(instance) | 传入模型实例作为参数,返回和这个实例相关联的对象,后面会详细介绍 |
示例:all()返回所有记录:
>>> Note.query.all()
[<Note 'remember Sammy Jankis'>, <Note 'SHAVE'>, <Note 'DON NOT BELIEVE HIS LIES, HE IS THE ONE, KILL HIM'>]first()返回第一条记录:
>>> note1 = Note.query.first()
>>> note1
<Note 'remember Sammy Jankis'>
>>> note1.body
'remember Sammy Jankis'get()返回指定主键值(id字段)的记录:
>>> note2 = Note.query.get(2)
>>> note2
<Note 'SHAVE'>count()返回记录的数量:
>>> Note.query.count()
3SQLALchemy还提供许多过滤方法,使用这些过滤方法可以获取更精确的查询,比如获取指定字段值的记录。对模型类的query属性存储的Query对象调用过滤方法将返回一个更精确的Query对象(后面简称为查询对象)。因为每个过滤方法都会返回新的查询对象,所以过滤器可以叠加使用。
在查询对象上调用前面介绍的查询方法,即可获得一个包含过滤后的记录的列表。常用的过滤方法有:
| 查询过滤器的名称 | 说明 |
|---|---|
| filter() | 使用指定的规则过滤记录,返回新产生的查询对象 |
| filter_by() | 使用指定的规则过滤记录(以关键字表达式的形式),返回新产生的查询对象 |
| order_by() | 根据指定条件对记录进行排序,返回新产生的查询对象 |
| limit(limit) | 使用指定的值限制原查询返回的记录数量,返回新产生的查询对象 |
| group_by() | 根据指定条件对记录进行分组,返回新产生的查询对象 |
| offset(offset) | 使用指定的值偏移原查询的结果,返回新产生的查询对象 |
filter()方法是最基础的查询方法。它使用指定的规则来过滤记录,示例:在数据库中找出body字段值为"SHAVE"的记录:
>>> Note.query.filter(Note.body=='SHAVE').first()
<Note 'SHAVE'>直接打印查询对象或将其转换为字符串可查看对应的SQL语句:
>>> print(Note.query.filter_by(body='SHAVE'))
SELECT note.id AS note_id, note.body AS note_body
FROM note
WHERE note.body = ?在filter()方法中传入表达式时,除了"=="以及表示不等于的"!=",其他常用的查询操作符以及使用示例如下:
LIKE:
filter(Note.body.like('%foo%'))
IN:
filter(Note.body.in_(['foo','bar','baz']))
NOT IN:
filter(~Note.body.in_(['foo','bar','baz']))
AND:
# 使用and_()
from sqlalchemy import and
filter(and_(Note.body == 'foo',Note.title == 'FooBar'))
# 或在filter()中加入多个表达式,使用逗号隔开
filter(Note.body == 'foo',Note.title == 'FooBar')
# 或叠加调用多个filter()/filter_by()方法
filter(Note.body == 'foo').filter(Note.title == 'FooBar')
OR:
from sqlalchemy import or_
filter(or_(Note.body == 'foo',Note.body == 'bar'))和filter方法相比,filter_by()方法更易于使用。在filter_by()方法中,可以使用关键字表达式来指定过滤规则。更方便的是,可以在这个过滤器 中直接使用字段名字。
>>> Note.query.filter_by(body='SHAVE').first()
<Note 'SHAVE'>其他方法,后续使用时介绍。
4.1.3、Update
更新一条记录非常简单,直接赋值给模型类的字段属性就可以改变字段值,然后调用commit()方法提交给会话即可。示例:改变一条记录的body字段的值:
>>> note = Note.query.get(2)
>>> note.body
'SHAVE'
>>> note.body = 'SHAVE LEFT THING'
>>> db.session.commit()4.1.4、Delete
删除记录和添加记录很相似,不过要把add()方法换成delete()方法,最后都需要调用commit()方法提交修改。示例:删除id(主键)为2的记录:
>>> note = Note.query.get(2)
>>> db.session.delete(note)
>>> db.session.commit()4.2、在视图函数里操作数据库
在视图函数里操作数据库的方式和我们在Python Shell中练习的大致相同,只不过需要一些额外的工作。比如把查询结果作为参数传入模板渲染出来,或是获取表单的字段值作为提交到数据库的数据。
4.2.1、Create
为了支持输入笔记内容,我们先创建一个用于填写新笔记的表单:
from wtforms import TextAreaField
from flask_wtf import FlaskForm
from wtforms.validators import DataRequired
class NewNoteForm(FlaskForm):
body = TextAreaField('Body',validators=[DataRequired()])
submit = SubmitField('Save')我们创建一个new_note视图,这个视图负责渲染创建笔记的模板,并处理表单的提交:
@app.route('/new',methods=['GET','POST'])
def new_note():
form = NewNoteForm()
if form.validate_on_submit():
body = form.body.data
note = Note(body=body)
db.session.add(note)
db.session.commit()
flash('Your note is saved.')
return redirect(url_for('index'))
return render_template('new_note.html',form=form)逻辑:当form.validate_on_submit()返回True时,即表单被提交且验证通过时,获取表单body字段的数据,然后创建新的Note实例,将表单中body字段的值作为body参数传入,最后添加到数据库会话中并提交会话。这个过程接收用户通过表单提交的数据并保存到数据库中,最后我们使用flash()函数发送提示消息并重定向到index视图。
表单在new_note.html模板中渲染,这里使用前面介绍的form_filed宏渲染表单字段,传入rows和cols参数来定制<textarea>输入框的大小:
{% from 'macro.html' import form_field %}
{% block content %}
<h2>New Note</h2>
<form method="post">
{{ form.csrf_token }}
{{ form_field(form.body,rows=5,cols=50) }}
{{ form.submit }}
</form>
{% endblock %}index视图用来显示主页,目前它的所有作用就是渲染主页对应的模板:
@app.route('/')
def index():
return render_template('index.html')在对应的index.html模板中,我们添加一个指向创建新笔记页面的链接:
<h1>Notebook</h1>
<a href="{{ url_for('new_note') }}">New Note</a>4.2.2、Read
上面为程序添加了新笔记的功能,当在创建笔记的页面单击保存后,程序会重定向到主页,提示的消息告诉你刚刚提交的笔记已经成功保存,可却无法看到保存后的笔记。为了在主页列出所有保存的笔记,我们需要修改index视图:
@app.route('/index')
def index():
form = DeleteForm()
notes = Note.query.all()
return render_template('index.html',notes=notes,form=form)在模板中渲染数据库记录:
<h1>Notebook</h1>
<a href="{{ url_for('new_note') }}">New Note</a>
<h4>{{ notes|length }} notes:</h4>
{% for note in notes %}
<div class="note">
<p>{{ note.body }}</p>
</div>
{% endfor %}在模板中,我们迭代这个notes列表,调用Note对象的body属性获取body字段的值。另外,我们还通过length过滤器获取笔记的数量。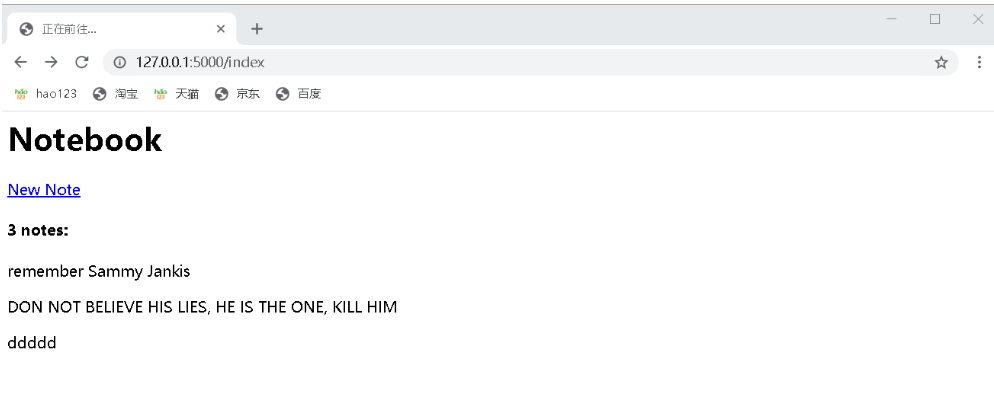
4.2.3、Update
更新一条笔记和创建一条新笔记的实现代码几乎完全相同,首先是编辑笔记的表单:
class EditNoteForm(FlaskForm):
body = TextAreaField('Body',validators=[DataRequired()])
submit = SubmitField('Update')发现这和创建新笔记NewNoteForm唯一的不同是提交字段的标签参数不同,因此这个表单的定义也可以通过继承来简化:
class EditNoteForm(NewNoteForm):
submit = SubmitField('Update')用来渲染更新笔记页面和处理更新表单提交的edit_note视图:
@app.route('/edit/<int:note_id>',methods=['GET','POST'])
def edit_note(note_id):
form = EditNoteForm()
note = Note.query.get(note_id)
if form.validate_on_submit():
note.body = form.body.data
db.session.commit()
flash('Your note is update.')
return redirect(url_for('index'))
form.body.data = note.body
return render_template('edit_note.html',form=form)逻辑:通过URL变量note_id获取要修改的笔记的主键值(id字段),然后我们就可以使用get()方法获取对应的Note实例。当表单被提交且通过验证时,我们将表单中body字段的值赋值给note对象的body属性,然后提交数据库会话,这样就完成了更新操作。最后重定向。
注意,在GET请求的执行流程中,我们添加了这行代码:
form.body.data = note.body因为要添加笔记内容的功能,那么当我们打开修改某个笔记的页面时,这个页面的表单中必然要包含笔记原有的内容。
如果手动创建HTML表单,那么可以通过将note记录传入模板,然后手动为对应字段填入笔记的原有内容:
<textarea name="body">{{ note.body }}</textarea>其他input元素则通过value属性来设置输入框中的值:
<input name="foo" type="text" value="{{ note.title }}">使用WTForms可以省略这些步骤,当我们渲染表单字段时,如果表单字段的data属性不为空,WTForms会自动把data属性的值添加到表单字段的value属性中,作为表单的值填充进去,我们不用手动为value属性赋值。
模板的内容基本相同,最后的工作是在主页笔记列表中的每个笔记内容下添加一个编辑按钮,用来访问编辑页面:
{% for note in notes %}
<div class="note">
<p>{{ note.body }}</p>
<a class="btn" href="{{ url_for('edit_note',note_id=note.id) }}">Edit</a>
</div>
{% endfor %}4.2.4、Delete
在程序中,删除的实现也非常简单,不过这里会有一个误区。大多数人通常会考虑在笔记内容下添加一个删除链接:
<a href="{{ url_for('delete_note',note_id=note.id) }}">Delete</a>这个链接用来指向删除笔记的detele_note视图:
@app.route('/delete/<int:note_id>')
def delete_note(note_id):
note = Note.query.get(note_id)
db.session.delete(note)
db.session.commit()
flash('Your note is deleted.')
return redirect(url_for('index'))虽然这看起来很合理,但这种处理方式会使程序处于CSRF攻击的风险之中。在前面强调过,防范CSRF攻击的基本原则是正确使用GET和POST方法。像删除这类修改数据的操作绝不能通过GET请求实现,正确的做法是为删除操作创建一个表单:
class DeleteNoteForm(FlaskForm):
submit = SubmitField('Delete')这个表单类只有一个提交字段,因为我们只需要在页面上显示一个删除按钮来提交表单:
@app.route('/delete/<int:note_id>',methods=['POST'])
def delete_note(note_id):
form = DeleteNoteForm()
if form.validate_on_submit():
note = Note.query.get(note_id) # 获取对应记录
db.session.delete(note) # 删除记录
db.session.commit() # 提交修改
flash('Your note is deleted.')
else:
abort(400)
return redirect(url_for('index'))逻辑:和编辑笔记的视图类似,这个视图函数接收note_id(主键值)作为参数。如果提交表单且通过验证(唯一需要被验证的是CSRF令牌),就使用get()方法查询对应的记录,然后调用db.session.delete()方法删除并提交数据库会话。如验证错误则使用abort()函数返回400错误响应。
因为删除按钮要在主页的笔记内容下添加,我们需要在index视图中实例化DeleteNoteForm类,然后传入模板。在index.html中:
{% for note in notes %}
<div class="note">
<p>{{ note.body }}</p>
<a class="btn" href="{{ url_for('edit_note',note_id=note.id) }}">Edit</a>
<form method="post" action="{{ url_for('delete_note',note_id=note.id) }}">
{{ form.csrf_token }}
{{ form.submit(class='btn') }}
</form>
</div>
{% endfor %}我们将表单的action属性设置为删除笔记的URL,URL变量note_id的值通过note.id属性获取,当单击提交按钮时,会将请求发送到action属性中的URL。添加删除表单的主要目的就是防止CSRF攻击,所以不要忘记渲染CSRF令牌字段form.csrf_token。
五、定义关系
在关系型数据库中,我们可以通过关系让不同表之间的字段建立联系。一般来说,定义关系需要两步:创建外键和定义关系属性。在更复杂的多对多关系中,我们还需要定义关联表来管理关系。
5.1、配置Python Shell上下文
在上面许多操作中,每一次使用flask shell命令启动Python Shell后都要从app模块里导入db对象和相应的模型类。我们可以使用app.shell_context_processor装饰器注册一个shell上下文处理函数。和模板上下文处理函数一样,也需要返回包含变量和变量值的字典:
@app.shell_context_processor
def make_shell_context():
return dict(db=db,Note=Note) # 等同于('db':db,'Note':Note)当使用flask shell启动Python Shell时,所有使用app.shell_context_processor装饰器注册的shell上下文处理函数都会被自动执行,这将db和Note对象推送到Python Shell上下文里:
$ flask shell
>>> db
<SQLAlchemy sqlite:///D:\Python Web\Pycharm-project\flask\data.db>
>>> Note
<class 'app.Note'>5.2、一对多
以作者和文章的关系来演示一对多关系:一个作者可以写作多篇文章。
...
class Author(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(70),unique=True)
phone = db.Column(db.String(20))
class Article(db.Model):
id = db.Column(db.Integer,primary_key=True)
title = db.Column(db.String(50),index=True)
body = db.Column(db.Text)我们将在这两个模型中建立一个简单的一对多关系,建立这个一对多关系的目的是在表示作者的Author类中添加一个关系属性articles,作为集合(collection)属性,当我们对特定的Author对象调用articles属性会返回所有相关的Article对象。
5.2.1、定义外键
定义关系的第一步是创建外键。外键是(foreign key)用来在A表存储B表的主键值以便和B表建立联系的关键字段。因为外键只能存储单一数据(标量),所以外键总是在"多"这一侧定义,多篇文章属于同一个作者,所以我们需要为每篇文章添加外键存储作者的主键值以指向对应的作者。
class Article(db.Model):
...
author_id = db.Column(db.Integer,db.ForeignKey('author.id'))使用db.ForeignKey类定义外键,传入关系另一侧的表名和主键字段名,即author.id。实际效果是将article表的author_id的值限制为author表的id列的值。它将用来存储author表中记录的主键值:
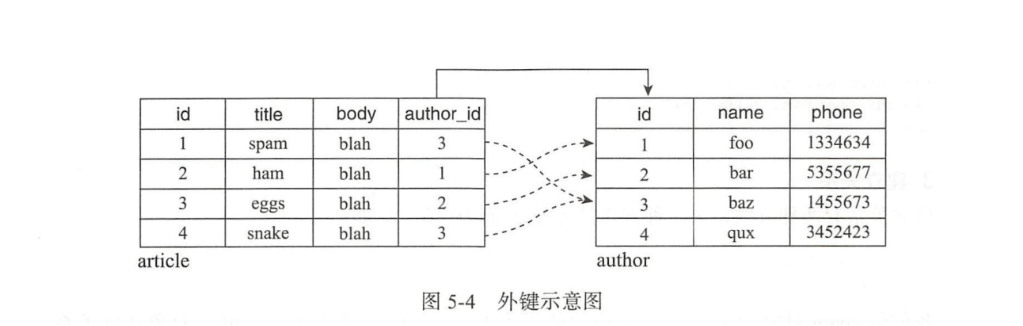 5.2.2、定义关系属性
5.2.2、定义关系属性
定义关系的第二步是使用关系函数定义关系属性。关系属性在关系的出发侧定义,即一对多关系的“一”这一侧。一个作者拥有多篇文章,在Author模型中,我们定义了一个articles属性来表示对应的多篇文章:
class Author(db.Model):
...
articles = db.relationship('Article')使用db.relationship()关系函数定义为关系属性,因为这个关系属性返回多个记录,我们称之为集合关系属性。relationship()函数的第一个参数为关系另一侧的模型名称,它会告诉SQLALchemy将Author类与Article类建立联系。
$ flask shell
>>> foo = Author(name='foo')
>>> spam = Article(title='Spam')
>>> ham = Article(title='Ham')
>>> db.session.add(foo)
>>> db.session.add(spam)
>>> db.session.add(ham) 5.2.3、建立关系
建立关系有两种方式,第一种方式是为外键字段赋值,比如:
>>> spam.author_id = 1
>>> db.session.commit()将spam对象的author_id字段的值设为1,这会和id值为1的Author对象建立关系。提交数据库改动后,如果我们对id为1的foo对象调用articles关系属性,会看到spam对象包括在返回的Article对象中:
>>> foo.articles
[<Article u'spam>,<Article u'Ham>]另一种方式是通过操作关系属性,将关系属性赋给实际的对象即可建立关系。集合关系属性可以像列表一样操作,调用append()方法来与一个Article对象建立关系:
>>> foo.articles.append(spam)
>>> foo.articles.append(ham)
>>> db.session.commit()和前面的第一种方式类似,为了让改动生效,我们需要调用db.session.commit()方法提交数据库会话。建立关系后,存储外键的author_id自动获得正确的值,调用author 实例的关系属性articles时,会获得所有建立关系的Article对象。
>>> spam.author_id
1
>>> foo.articles
[<Article u'Spam'>,<Article u'Ham'>](之后统一用第二种方式,即通过关系属性来建立关系)
和append()相对,对关系属性调用remove()方法可以与对应的Article对象解除关系:
>>> foo.articles.remove(spam)
>>> db.session.commit()
>>> foo.articles
[<Article u'Ham'>]常用的SQLALchemy关系函数参数
| 参数名 | 说明 |
|---|---|
| back_populates | 定义反向引用,用于建立双向关系,在关系的另一侧也必须显式定义关系属性 |
| backref | 添加反向引用,自动在另一侧建立关系属性,是back_populates的简化版 |
| lazy | 指定如何加载相关记录 |
| uselist | 指定是否使用列表的形式加载记录,设为False则使用标量(scalar) |
| cascade | 设置级联操作 |
| order_by | 指定加载相关记录时的排序方式 |
| secondary | 在多对多关系中指定关联表 |
| primaryjoin | 指定多对多关系中的一级联结条件 |
| secondaryjoin | 指定多对多关系中的二级联结条件 |
当关系属性被调用时,关系函数会加载相应的记录,下面列出控制关系记录加载方式的lazy参数的常用选项:
| 关系加载方式 | 说明 |
|---|---|
| select | 在必要时一次性加载记录,返回包含记录的列表(默认值),等同于lazy=True |
| joined | 和父查询一样加载记录,但使用联结,等同于lazy=False |
| immediate | 一旦父查询加载就加载 |
| subquery | 类似于joined,不过使用子查询 |
| dynamic | 不直接加载记录,而是返回一个包含相关记录的query对象,以便再继续附加查询函数对结果直接进行过滤 |
(dynamic选项仅用于集合关系属性,不可用于多对一,一对一或是在关系函数中将uselist参数设为False的情况)
(许多教程和示例使用dynamic来动态加载所有集合关系属性对应的记录,这是应该避免的行为。使用dynamic加载方式意味着每次操作关系都会执行一次SQL查询,这会造成潜在的性能问题。大多数情况下我们只需要使用默认值(select),只有在调用关系属性会返回大量记录,并且总是需要对关系属性返回的结果附加额外的查询才需要使用动态加载(dynamic))。
5.2.4、建立双向关系
我们在Author类中定义了集合关系属性articles,用来获取某个作者拥有的多篇文章记录。在某些情况下,你也许希望能在Article类中定义一个类似的author关系属性,当被调用时返回对应的作者记录,这类返回单个值的关系属性被称为标量关系属性。而这两侧都添加关系属性获取对方的关系称之为双向关系
双向关系并不是必须的,但在某些情况下会非常方便。双向关系的建立很简单,通过在关系的另一侧也创建一个relationship()函数,我们就可以在两个表之间建立双向关系。下面使用作家(Writer)和书(Book)的一对多关系进行演示:
class Writer(db.Model):
id = db.Column(db.Integer,primary_key= True)
name = db.Column(db.String(70),unique=True)
books = db.relationship('Book',back_populates='writer')
class Book(db.Model):
id = db.Column(db.Integer,primary_key=True)
title = db.Column(db.String(50),index=True)
writer_id = db.Column(db.Integer,db.ForeignKey('writer.id'))
writer = db.relationship('Writer',back_populates='books')逻辑:在“多”这一侧的Book(书)类中,我们新创建了一个writer关系属性,这是一个标量关系属性,调用它会获取对应的Writer(作者)记录;而在Writer(作者)类中的books属性则用来获取对应的多个Book(书)记录。在关系函数中,我们使用back_populates参数来连接对方,back_populates参数的值需要设为关系另一侧的关系属性名。
>>> king = Writer(name='Stephen King')
>>> carrie = Book(name='Carrie')
>>> it = Book(name='IT')
>>> db.session.add(King)
>>> db.session.add(carrie)
>>> db.session.add(it)
>>> db.session.commit()设置双向关系后,除了通过集合属性books来操作关系,也可使用标量属性writer来进行关系操作。比如将一个Writer对象赋值给某个Book对象的writer属性,就会和这个Book对象建立关系:
>>> carrie.writer = king
>>> carrie.writer
<Writer u'Stephen King'>
>>> king.books
[<Book u'Carrie'>]
>>> it.writer = writer
>>> king.books
[<Book u'Carrie'>,<Book u'IT'>]相对的,将某个Book的writer属性设为None,就会解除与对应Writer对象的关系:
>>> carrie.writer = None
>>> king.books
[<Book u'IT'>]
>>> db.session.commit()需要注意,我们只需要在关系的一侧操作关系。当为Book对象的writer属性赋值后,对应Writer对象的books属性的返回值也会自动包含这个Book对象。反之,当某个Writer对象被删除时,对应的Book对象的writer属性被调用时的返回值也会被置空(即NULL,会返回None)
5.2.5、使用backref简化关系定义
以一对多关系为例,backref参数用来自动为关系另一侧添加关系属性,作为反向引用,赋予的值会作为关系的另一侧的关系属性名称。
class Singer(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(70),unique=True)
songs = db.relationship('Song',backref='singer')
class Song(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(50),index=True)
singer = db.Column(db.Integer,db.ForeignKey('singer.id'))逻辑:在定义集合属性songs的关系函数中,我们将backref参数设为singer,这会同时在Song类中添加一个singer标量属性。这时我们仅需定义一个关系函数,虽然singer是一个“看不见的关系属性”,但在使用上和定义两个关系函数并使用back_populates参数的效果完全相同。
注意:backref允许我们仅在关系一侧定义另一侧的关系属性,但在某些情况下,我们希望可以对在关系另一侧的关系属性进行设置,这时需要使用backref()函数。backref()函数接收第一个参数作为在关系另一侧添加的关系属性名,其他关键字参数会作为关系另一侧关系函数的参数传入。比如:在关系的另一侧“看不见的relationship()函数”中将uselist参数设为False:
class Singer(db.Model):
...
songs = relationship('Song',backref=backref('singer',userlist=False))5.3、多对一
使用居民和城市演示:多个居民住在同一个城市。前面介绍:关系属性在关系模式的触发侧定义。当出发点在“多”这一侧时,我们希望在Citizen类中添加一个关系属性city来获取对应的城市对象,因为这个关系属性返回单个值,我们称之为标量关系属性。在定义关系时,外键总是在“多”这一侧定义,所以在多对一关系中,外键和关系属性都定义在“多”这一侧:
class Citizen(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(70),unique=True)
city_id = db.Column(db.Integer,db.ForeignKey('City.id'))
city = db.relationship('City')
class City(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(30),unique=True)逻辑:这时定义的city属性是一个标量属性(返回单一数据)。当Citizen.city被调用时,SQLALchemy会根据外键字段city_id对象并返回,即居民记录对应的城市记录。
当建立双向关系时,如果不使用backref,那么一对多和多对一关系模式在上完全相同,这时可以将一对多和多对一视为同一种关系模式。在后面我们通常都会为一对多或多对一建立双向关系,这时将弱化这两种关系的区别,一律称为一对多关系
5.4、一对一
使用国家和首都演示:每个国家只有一个首都。
一对一关系实际上是通过建立双向关系的一对多的基础上转换而来。我们要确保关系两侧的关系属性都是标量关系,都只返回单个值,所以要在定义集合属性的关系函数中将uselist参数设为False,这时一对多关系将被转换为一对一关系:
class Country(db.Model):
id = db.Column(db.Inyeger,primary_key=True)
name = db.Column(db.String(30),unique=True)
capital = db.relationship('Capital',uselist=False)
class Capital(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(30),unique=True)
country_id = db.Column(db.Integer,db.ForeignKey('country.id'))
country = db.relationship('Country')逻辑:”多“这一侧本身就是标量关系属性,不用做任何改动。而”一“这一侧的集合关系属性,通过将uselist设为False后,将仅返回对应的单个记录,而且无法再使用列表语义操作:
>>> china = Country(name='China')
>>> beijing = Captital(name='Beijing')
>>> db.session.add(china)
>>> db.session.add(beijing)
>>> db.sessiom.commit()
>>> china.captital = beijing
>>> china.captital
<Captital 1>
>>> beijing.country
u'China'
>>> tokyo = Capital(name'Tokyo')
>>> china.capital.append(tokyo)
Traceback (most recent call last):
File "<console>", line 1, in<module>
AttributeError: 'Captital' object has no attribute 'append'5.5、多对多
使用学生和老师演示多对多关系:每个学生有多个老师,而每个老师有多个学生。
在多对多关系中,每一个记录都可以与关系另一侧的多个记录建立关系,关系两侧的模型都需要存储一组外键。在SQLALchemy中,我们还需要创建一个关联表。关联表不存储数据,只用来存储关系两侧模型的外键对应关系:
association_table = db.Table('association', db.Column('student_id', db.Integer, db.ForeignKey('student.id')),
db.Column('teacher_id', db.Integer, db.ForeignKey('teacher.id')))
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
grade = db.Column(db.String(20))
teachers = db.relationship('Teacher', secondary=association_table, back_populates='students')
class Teacher(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
office = db.Column(db.String(20))关联表使用db.Table定义,传入的第一个参数是关联表的名称。在上述关联表中定义了两个外键字段:teacher_id字段存储Teacher类的主键,student_id存储Student类的主键。借助关联表中这个中间人存储的外键对,我们可以把多对多关系分化成两个一对多关系:
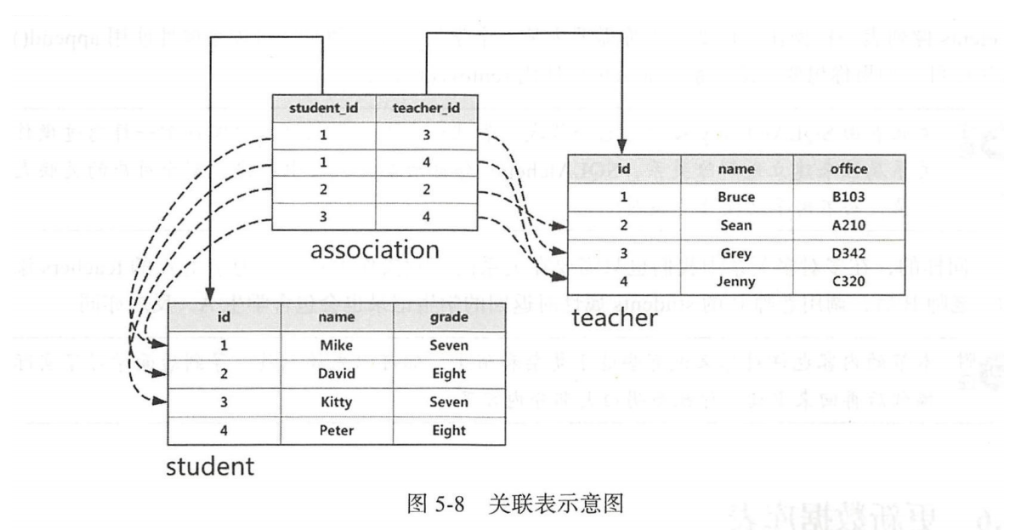 示例:当需要查询某个学生记录的多个老师时,先通过学生和管理表的一对多关系查询所有包含该学生的关联表记录,然后就可以从这些记录中再进一步获取每个关联表记录包含的老师记录。
示例:当需要查询某个学生记录的多个老师时,先通过学生和管理表的一对多关系查询所有包含该学生的关联表记录,然后就可以从这些记录中再进一步获取每个关联表记录包含的老师记录。
在Student类中定义一个teachers关系属性用来获取老师集合。在多对多关系中定义关系函数,除了第一个参数是关系另一侧的模型名称外,还需要添加一个secondary参数,把这个值设为管理表的名称。
为了便于实现真正的多对多关系,我们需要建立双向关系。在Student类上的teachers集合属性会返回所有关联的老师记录,而在Teacher类上的students集合属性会返回所有相关的学生记录:
class Student(db.Model):
...
teachers = db.relationship('Teacher',
secondary=association_table,
back_populates='students')
class Teacher(db.Model):
...
students = db.relationship('Student',
secondary=association_table,
back_populates='teachers')除了在声明关系模式在操作关系时和其他关系模式基本相同。调用关系属性student.teachers时,SQLALchemy会直接返回关系另一侧的Teacher对象,而不是关联表记录。和其他关系模式中的集合属性一样,我们可以将关系属性teachers和students像列表一样操作。比如,当需要为某一个学生添加老师时,对关系属性使用append()方法即可。解除关系使用remove()方法。
六、更新数据库表
6.1、重新生成表
使用drop_all()方法删除表以及其中的数据,然后使用create_all()方法重新创建:
>>> db.drop_all()
>>> db.create_all()为了便于开发,我们修改initdb命令函数的内容,为其增加一个--drop选项来支持删除表和数据库后进行重建:
@app.cli.command()
@click.option('--drop',is_flag=True,help='Create after drop.')
def initdb(drop):
"""Initialize the database."""
if drop:
click.confirm('This operation will delete the database,do you want to continue?',abort=True)
db.drop_all()
click.echo('Drop tables.')
db.create_all()
click.echo('Initialized database.')现在,执行下面的命令会重建数据库和表:
$ flask initdb --drop(当使用SQLite时,直接删除data.db文件和调用drop_all()方法效果相同,更直接不容易出错)
6.2、使用Flask-Migrate迁移数据库
不想要数据库中的数据被删除掉就使用数据库迁移来完成。
迁移工具--Alembic来帮我们实现数据库的迁移,数据库迁移工具可以在不破坏数据的情况下更新数据库表的结构。
扩展Flask-Migrate集成了Alembic,提供了一些flask命令来简化迁移工作:
pip install flask-migrate在程序中,我们实例化Flask-Migrate提供的Migrate类,进行初始化操作:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
...
db = SQLAlchemy(app)
migrate = Migrate(app,db)6.2.1、创建迁移环境
开始迁移数据库之前,需要使用下面的命令创建一个迁移环境:
$ flask db init迁移环境只需要创建一次。这会在项目根目录下创建一个migrations文件夹,其中包含了自动生成的配置文件和迁移版本文件夹
6.2.2、生成迁移脚本
使用migrate子命令可以自动生成迁移脚本:
$ flask db migrate -m "add note timestamp"这条命令:在flask里对数据库(db)进行迁移。-m选项用来添加迁移备注信息。生成内容示例:
"""add note timestamp
Revision ID: b27e0318b424
"""
from alembic import op
import sqlalchemy as sa
...
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.add_column('note',sa.Column('timestamp',sa.DateTime(),nullable=True))
# ### end Alembic commands ###
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.drop_column('note','timestamp')
# ### end Alembic commands ###迁移脚本主要包含了两个函数:upgrade()函数用来将改动应用到数据库,函数中包含了向表中添加timestamp字段的命令;而downgrade()函数用来撤销改动,包含了删除timesptamp字段的命令。
6.2.3、更新数据库
生成了迁移脚本后,使用upgrade子命令即可更新数据库:
>>> $ flask db upgrade若没有创建数据库和表,这个命令会自动创建;若已创建,则会在不损坏数据的前提下执行更新。
6.3、开发时是否要迁移?
尽可能让开发环境和生产环境保持一致。考虑直接在本地使用MySQL或PostgreSQL等性能更高的DBMS,然后设置迁移环境。
七、数据库进阶实践
7.1、级联操作
Cascade意为“级联操作”,就是在操作一个对象的同时,对相关的对象也执行某些操作。示例:
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(50), unique=True)
body = db.Column(db.Text)
comments = db.relationship('Comment', back_populates='post')
class Comment(db.Model):
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.Text)
post_id = db.Column(db.Integer, db.ForeignKey('post.id'))
post = db.relationship('Post', back_populates='comments')级联行为通过关系函数relationship()的cascade参数设置。我们希望在操作Post对象时,处于附属低位的Comment对象也被相应执行某些操作,这时应该在Post类的关系函数中定义级联参数。设置了cascade参数的一侧将被视为父对象,相关的对象则视为子对象。
cascade通常使用多个组合值,级联值之间使用逗号分隔:
class Post(db.Model):
...
comments = relationship('Comment',cascade='save-update,merge,delete')常用的配置组合如下所示:
- save-update、merge(默认值)
- save-update、merge、delete
- all
- all、delete-orphan
当没有设置cascade参数时,会使用默认值save-update、merge。上面的all等同于除了delete-orphan以为所有可用值的组合,即save-update、merge、refresh-expire、expunge、delete。下面我们会介绍常用的几个级联值:
7.1.1、save-update
save-update是默认的级联行为,当cascade参数设为save-update时,如果使用db.session.add()方法将Post对象添加到数据库会话时,那么与Post相关联的Comment对象也将被添加到数据库会话。
>>> post1 = Post()
>>> comment1 = Comment()
>>> comment2 = Comment()将post1添加到数据库会话后,只有post1在数据库会话中:
>>> db.session.add(post1)
>>> post1 in db.session
True
>>> comment1 in db.session
False
>>> comment2 in db.session
False如果我们让post1与两个Comment对象建立关系,那么这两个Comment对象也会自动被添加到数据库会话中:
>>> post1.comments.append(comment1)
>>> post1.comments.append(comment2)
>>> comment1 in db.session
True
>>> comment2 in db.session
True当调用db.session.commit()数据库会话时,这三个对象都会被提交到数据库中。
7.1.2、delete
如果某个Post对象被删除,那么按照默认的行为,该Post对象相关联的所有Comment对象都将与这个Post对象取消关联,外键字段的值会被清空。如果Post类的关系函数中cascade参数设为delete时,这些相关的Comment会在关联的Post对象删除时被一并删除。当需要设置delete级联时,我们会将级联值设为all或save-update、merge、delete,比如:
class Post(db.Model):
...
comments = relationship('Comment',cascade='all')示例:
>>> post2 = Post()
>>> comment3 = Comment()
>>> comment4 = Comment()
>>> post2.comments.append(comment3)
>>> post2.comments.append(commetn4)
>>> db.session.add(post2)
>>> db.session.commit()现在共有两条Post记录和四条Comment记录:
>>> Post.query.all()
[<Post 1>,<Post 2>]
>>> Comment.query.all()
[<Comment 1>,<Comment 2>,<Comment 3>,<Comment 4>]如果删除文章对象Post2,那么对应的两个评论对象也会一并被删除:
>>> post2 = Post.query2y.get(2)
>>> db.session.delete(post2)
>>> db.session.commit()
>>> Post.query.all()
[<Post 1>]
>>> Comment.query.all()
[<Comment 1>,<Comment 2>]7.1.3、delete-orphan
这个模式是基于delete级联的,必须和delete级联一起使用,通常会设为all、delete-orphan,因为all包含delete。因此当cascade参数设为delete-orphan时,它首先包含delete级联的行为:当某个Post对象被删除,所有相 Comment 都将被删除 delete 级联) 。除此之外, 当某个Post对象(父对象)与某Comment对象(子对象)解除关系时,也会删除该 Comment对象, 这个解除关系的对象被称为孤立对象(orphan object):
class Post(db.Model):
...
comments = relationship('Comment',cascade='all,delete-orphan')delete和delete-orphan通常会在一对多关系模式中,而且“多”这一侧的对象附属于“一”这一侧的对象时使用。尤其是如果“一”这一侧的“父”对象不存在了,那么“多”这一侧的“子“对象不再有意义的情况。比如,文章和评论。
虽然级联操作方便,但是容易带来安全隐患,因此要谨慎使用。默认值能够满足大部分情况,所以最好仅在需要的时候才修改它。
7.2、事件监听
SQLALchemy提供了一个listen_for()装饰器,可以用来注册事件回调函数。
listen_for()装饰器接收两个参数,target表示监听的对象,这个对象可以是模型类、类实例或类属性等。identifier参数表示被监听事件的标识符,比如,用于监听属性的事件标识符有set、append、remove、init_scalar、init_collection等。
# 创建一个Draft模型类表示草稿
class Draft(db.Model):
id = db.Column(db.Integer,primary_key=True)
body = db.Column(db.Text)
edit_time = db.Column(db.Integer,default=0)通过注册件监听函数,实现在body列修改时,自动叠加表示被修改次数的edit_ time字段。在SQLAlchemy中,每个事件都会有一个对应的事件方法,不同的事件方法支持不同的参数,被注册的监听函数需要接收对应事件方法的 所有参数,所以具体的监听函数用法因使用的事件而异。设置某个字段值将触发set事件:
@db.event.listens_for(Draft.body,'set')
def increment_edit_time(target,value,oldvalue,initiator):
if target.edit_time is not None:
target.edit_time += 1
# target参数表示触发事件的模型类实例,使用target.edit_time即可获取我们需要叠加的字段。value表示被设置的值,oldvalue表示被取代的旧值。当set事件发生在目标对象Draft.body上时,这个监听函数就会被执行,从而叠加Draft.edit_time列的值:
>>> draft = Draft(body='init')
>>> db.session.add(draft)
>>> db.session.commit()
>>> draft.edit_time
0
>>> draft.body = 'edited'
>>> draft.edit_time
1
>>> draft.body = 'edited again'
>>> draft.edit_time
2
>>> draft.body = 'edited agian again'
>>> draft.edit_time
3
db.session.commit()除了这种传统的参数接收方式,即接收所有事件方法接收的参数,还有一种:通过在listen_for()装饰器中将关键字参数name设为True,可以在监听函数中接收**kwargs作为参数(可变长关键字参数)。然后在函数中可以使用参数名作为键从kwargs字典中取出对应的参数值:
@db.event.listens_for(Draft.body,'set')
def increment_edit_time(**kwargs):
if kwargs['target'].edit_time is not None:
kwargs['target'].edit_time += 1SQLALchemy作为SQL工具集本身包含两大主要组件:SQLALchemy ORM和SQLALchemy Core。前者实现了前面介绍的ORM功能,后者实现了数据库接口等核心功能,这两类组件都提供了大量的监听事件,几乎覆盖了整个SQLALchemy使用的生命周期。
致谢
在此,我要对所有为知识共享做出贡献的个人和机构表示最深切的感谢。同时也感谢每一位花时间阅读这篇文章的读者,如果文章中有任何错误,欢迎留言指正。
学习永无止境,让我们共同进步!!