说明
之前第二步是打算进入Clickhouse的,实测下来有一些bug
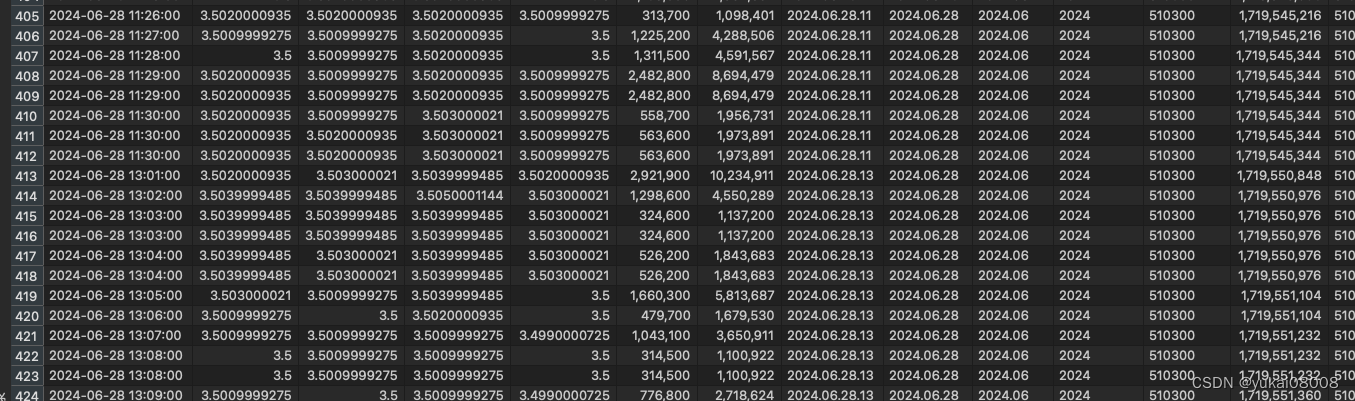
可以看到有一些分钟数据重复了。简单分析原因:
- 1 起异步任务时,还是会有两个任务重复的问题,这个在同步情况下是不会出现的
- 2 数据库没有upsert模式。clickhouse是最近刚应用的库,我还没有完善其操作模式。
解决思路:
- 1 既然采用了异步,就没有办法去控制其前置的依赖和顺序,否则就会退回到同步状态。而且从效率上,n次异步IO的cpu开销,可能也只相当于1次的同步开销。可以认为,异步是更轻松,但是更’粗心’的工作状态。所以在设计上,如果每次的操作都是“无害”的,那么就没问题。这里的数据同步任务,最重要的是不重不漏,所以只要能够确保数据不重不漏即可。
- 2 每次负责crawl的worker不直接操作数据库是对的,这可以避免过多的数据库操作开销。在同步结果的队列中,每个周期执行一次Mongo操作是完全没问题的。同步队列中可以有一些冗余的数据,在整合数据时就删除了。剩余的部分,可以直接采用upsert的方式存入。
结论:使用Mongo作为第一个数据节点的持久化。
反思点:
- 1 对于数据的集成,可能还是Mongo更合适。因为不必事先定义表结构,而且之前做了一些开发,Mongo的操作方式非常完善。擅长在记录级数据的复杂度操作。
- 2 clickhouse更适合用于在我的数据系统中直接输出的数据,特别是空间数据,按UCS方式规范。擅长在块级别数据的效率操作。
内容
1 目标数据库准备
采用m4.24086
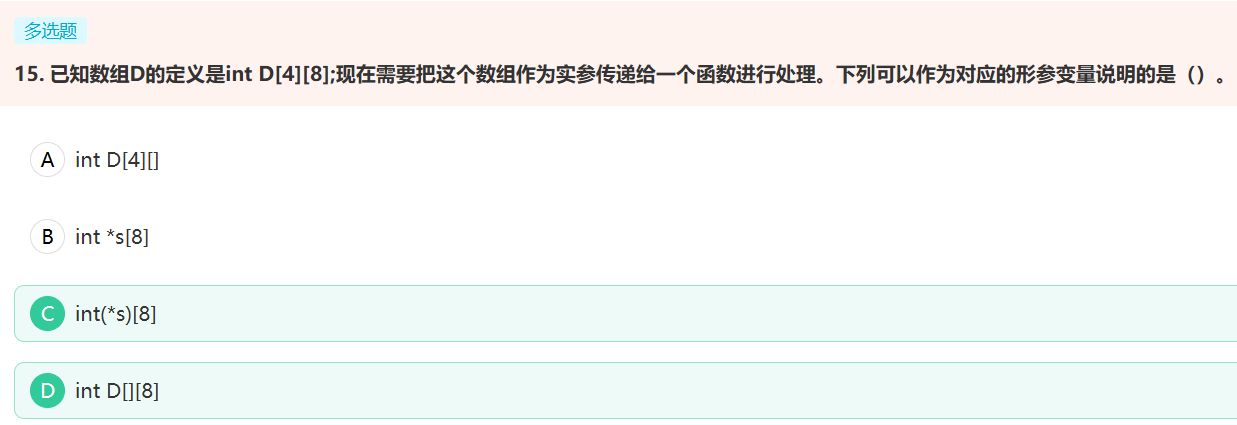
很巧,QTV102的数据也在这里,所以QTV200的数据可以继续放在这里 。
回顾一下WMongo的操作,有好一阵子没用了。
from Basefuncs import *
# analysis
target_server = 'm4.24086'
# machine_name = 'm4'
machine_name = get_machine_name()
# 在本地建立连接文件,避免每次都向mymeta请求数据。 随主机变化,这里有可能要修改(TryConnectionOnceAndForever)中关于mymeta的连接配置。
try:
target_w = from_pickle(target_server)
color_print('【Loading target_w】from pickle')
except:
w = WMongo('w')
target_w = w.TryConnectionOnceAndForever(server_name =target_server, current_machine_name = machine_name)
to_pickle(target_w, target_server)
有一些设计是好的,只要给出目标服务器名称,对象就会自动寻找合适的连接方式(local、lan、wan)来完成连接,对应的连接保存为本地文件。之后可以考虑通过GlobalBuffer来简化判断,还有neo4j来存储和管理关系。
进入队列的字段名,不允许有 _msg_id 字段
Wmongo_v9000.012
设置当前连接 local
>>> Switching To Mymeta
设置当前连接 local
在CN001访问mymeta,通用
当前机器的名称: m4
1.当前使用的MongeAgent:http://172.17.0.1:24011/
2.Tier1:meta, Tier2:servers
3.ConnectionHash:e8d1bc791049988d89465d5ce24d993b
4.FilterDict:{'my_server_pkey': 'm4.24086'}
5.Limits:1
6.Sort:
7.Skip:0
>>> Hit Records
当前机器的局网: my.cn001
【I】目标服务的机器:m4, 目标服务的机器局网:my.cn001
【I】采用local方式连接目标主机
Wmongo_v9000.012
设置当前连接 local
获取已有连接
target connection hash: d35632b63b77f17d4d12808fb707cb1f
data save to pickle: ./m4.24086.pkl
然后就可以通过对象操作了
target_w.cname_recs()
{'data': {'QTV102': {'log_monitor': 264276,
'log_sniffer': 792827,
'log_worker': 264276,
'stats': 5177,
'step1_mongo_in': 2895114,
'step1_mongo_meta': 2895114,
'step1_mongo_out': 2895114},
'QTV102_Capital_Data': {'capital_daily': 32787},
'QTV102_Model_Signal': {'log_monitor': 264277,
'log_sniffer': 792827,
'log_worker': 0,
'stats': 5218,
'step1_mongo_in': 2436678,
'step1_mongo_meta': 0,
'step1_mongo_out': 16860560},
'QTV102_Strategy': {'strategy_online': 58,
'trade_orders': 128,
'trade_strategy': 23},
'QuantData001': {'log_monitor': 264276,
'log_sniffer': 792830,
'log_worker': 264276,
'stats': 5178,
'step1_mongo_in': 460297,
'step1_mongo_meta': 460297,
'step1_mongo_out': 460297},
'QuantData_510500': {'log_monitor': 264277,
'log_sniffer': 792831,
'log_worker': 264278,
'stats': 5178,
'step1_mongo_in': 657702,
'step1_mongo_meta': 657702,
'step1_mongo_out': 657702},
'SmartQuant_512660': {'log_monitor': 264277,
'log_sniffer': 792830,
'log_worker': 0,
'stats': 5219,
'step1_mongo_in': 460297,
'step1_mongo_meta': 0,
'step1_mongo_out': 450098},
'Strategy_512660': {'capitals': 261,
'monthly_report': 66,
'orders': 130,
'slog': 430056,
'summary_report': 124,
'yearly_report': 8},
'test_for_mongo_engine': {'user': 2}},
'msg': 'ok',
'status': True}
很早前随便做的一版,看起来业务效果还是不错的。这部分内容,以后就不必放在mongo,在clickhouse里一个查询就好了。
仍然(在逻辑上)设置表的结构为:qtv200.market_data,需要的索引有:
- 1 pid: 主键。这个是确定的主键,对后续的基础操作来说是必须的。
- 2 UCS(shard、part、block、brick): 管理块级数据的键,在后续的块级任务来说非常重要。
- 3 code: 业务筛选字段
- 4 ts: 时间,排序字段
mongo方便之处就在于:当你的逻辑明确了,建立好索引,一切就好了
# 主键 pkey
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'pid')
# UCS
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'shard')
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'part')
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'block')
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'brick')
# 业务
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'code')
# 排序
target_w.set_a_index(tier1 = 'qtv200' ,tier2 = 'market_data', idx_var = 'ts')
Out[4]: {'data': {'ts_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}
改造1:修改获取最大最小值的部分 etl_worker
变的简单了,不需要关心数据库里有什么,只要把当前有重复的pid去掉就可以了
...
data_df1['pid'] = data_df1['code'].apply(str) + '_' + data_df1['ts'].apply(str)
keep_cols1 = ['data_dt','open','close','high','low', 'vol','amt', 'brick','block','part', 'shard', 'code','ts', 'pid']
data_df2 =data_df1[keep_cols1].drop_duplicates(['pid'])
output_df = data_df2
output_data_listofdict = output_df.to_dict(orient='records')
output_data_listofdict2 = slice_list_by_batch2(output_data_listofdict, qm.batch_size)
for some_data_listofdict in output_data_listofdict2:
qm.parrallel_write_msg(target_stream_name, some_data_listofdict)
在脚本里做相应修改
#conda init
conda activate base
cd /home/workers && python3 etl_worker_mongo.py
改造2:修改入库的部分 s2mongo
暂时先以脚本方式执行,不固化到接口中。
现在可以采用一些更好的方式来初始化队列。
from Basefuncs import *
import logging
from logging.handlers import RotatingFileHandler
def get_logger(name , lpath = '/var/log/' ):
logger = logging.getLogger(name)
fpath = lpath + name + '.log'
handler = RotatingFileHandler(fpath , maxBytes=100*1024*1024, backupCount=10)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
return logger
logger = get_logger('etf_raw_data')
# IO
machine_host = '192.168.0.4'
source_redis_agent_host = f'http://{machine_host}:24118/'
stream_cfg = StreamCfg(q_max_len = 1000000, batch_size = 10000, redis_agent_host = source_redis_agent_host)
qm = QManager(**stream_cfg.dict())
# qm.info()
# analysis
target_server = 'm4.24086'
target_w = from_pickle(target_server)
# machine_name = 'm4'
# machine_name = get_machine_name()
# # 在本地建立连接文件,避免每次都向mymeta请求数据。 随主机变化,这里有可能要修改(TryConnectionOnceAndForever)中关于mymeta的连接配置。
# try:
# target_w = from_pickle(target_server)
# color_print('【Loading target_w】from pickle')
# except:
# w = WMongo('w')
# target_w = w.TryConnectionOnceAndForever(server_name =target_server, current_machine_name = machine_name)
# to_pickle(target_w, target_server)
# target_w.cname_recs()
# Name
ss_name = 'xxx'
t_tier1 = 'xxx'
t_tier2 = 'xxx'
keep_cols =['data_dt','open','close','high','low', 'vol','amt', 'brick','block','part', 'shard', 'code','ts', 'pid']
num_cols = ['open','close','high','low', 'vol','amt','ts']
# Process
## 1 read source -- 这里本身也可以用pydantic
ss_data_list = qm.xrange(ss_name)['data']
if len(ss_data_list):
ss_data_df0 = pd.DataFrame(ss_data_list)
msg_id_list = list(ss_data_df0['_msg_id'])
ss_data_df = ss_data_df0[keep_cols].dropna()
for the_col in num_cols:
ss_data_df[the_col] = ss_data_df[the_col].apply(float)
# 写入mongo
resp = target_w.insert_or_update_with_key(tier1 = t_tier1, tier2 = t_tier2, data_listofdict = ss_data_df.to_dict(orient='records'), key_name ='pid')
qm.xdel(ss_name,msg_id_list)
logger.info(get_time_str1() + 'efl_s2mongo insert recs %s' % len(ss_data_df))
else:
logger.info(get_time_str1() + 'efl_s2mongo insert not recs')
以上,规定了几部分。
- 1 IO部分。队列和数据的handler现在通过pydantic的对象,可以非常简洁的定义。然后约定好入队列和目标数据库表的必要信息。
- 2 处理。主要就是将需要保留的字段,以及需要转数值的字段明确。然后就是读取,保留,转换,插入,最后删除。
在测试中,就一次的数据反复插了几次,数据是不会重复的。
对应的日志可以看到一开始插入过n次,后面加入了定时任务,然后就转入运行了
└─ $ cat /var/log/etf_raw_data.log
2024-06-29 18:38:27efl_s2mongo insert recs 12
2024-06-29 18:40:53efl_s2mongo insert recs 12
2024-06-29 18:41:31efl_s2mongo insert recs 12
2024-06-29 18:41:42efl_s2mongo insert recs 12
2024-06-29 18:43:27efl_s2mongo insert recs 12
2024-06-29 18:44:31efl_s2mongo insert recs 12
2024-06-29 18:46:49efl_s2mongo insert recs 12
2024-06-29 18:47:01efl_s2mongo insert not recs
2024-06-29 18:47:01efl_s2mongo insert not recs
2024-06-29 18:47:31efl_s2mongo insert not recs
2024-06-29 18:48:01efl_s2mongo insert not recs
2024-06-29 18:48:31efl_s2mongo insert not recs
2024-06-29 18:49:01efl_s2mongo insert not recs
2024-06-29 18:49:02efl_s2mongo insert not recs
2024-06-29 18:49:31efl_s2mongo insert not recs
2024-06-29 18:49:32efl_s2mongo insert not recs
2024-06-29 18:50:01efl_s2mongo insert not recs
2024-06-29 18:50:02efl_s2mongo insert not recs
2024-06-29 18:50:31efl_s2mongo insert not recs
2024-06-29 18:50:32efl_s2mongo insert not recs
2024-06-29 18:51:01efl_s2mongo insert not recs
2024-06-29 18:51:02efl_s2mongo insert not recs
2024-06-29 18:51:31efl_s2mongo insert not recs
2024-06-29 18:51:32efl_s2mongo insert not recs
关于定时任务
我偷了个懒,就是把这脚本和etl脚本放在一起。这两个任务被绑在一起串行了。主要是懒的再去定一个定时任务。
└─ $ cat exe_qtv200_etl_worker.sh
#!/bin/bash
# 记录
# sh /home/test_exe.sh com_info_change_pattern running
# 有些情况需要把source替换为 .
# . /root/anaconda3/etc/profile.d/conda.sh
# 激活 base 环境(或你创建的特定环境)
source /root/miniconda3/etc/profile.d/conda.sh
#conda init
conda activate base
cd /home/workers && python3 etl_worker_mongo.py
cd /home/workers && python3 etf_raw_data_s2mongo.py
对于后续其他的etl,每一个还是应该另起一个任务,这样才能利用异步来确保多个etf的数据及时获取。
【调整完毕】