目录
- 1、Java的IO体系
- 2、IO的常用方法
- 3、Java中为什么要分为字节流和字符流
- 4、File和RandomAccessFile
- 5、Java对象的序列化和反序列化
- 6、缓冲流
- 7、Java 的IO流中涉及哪些设计模式
1、Java的IO体系
IO 即为 input 输入 和 output输出
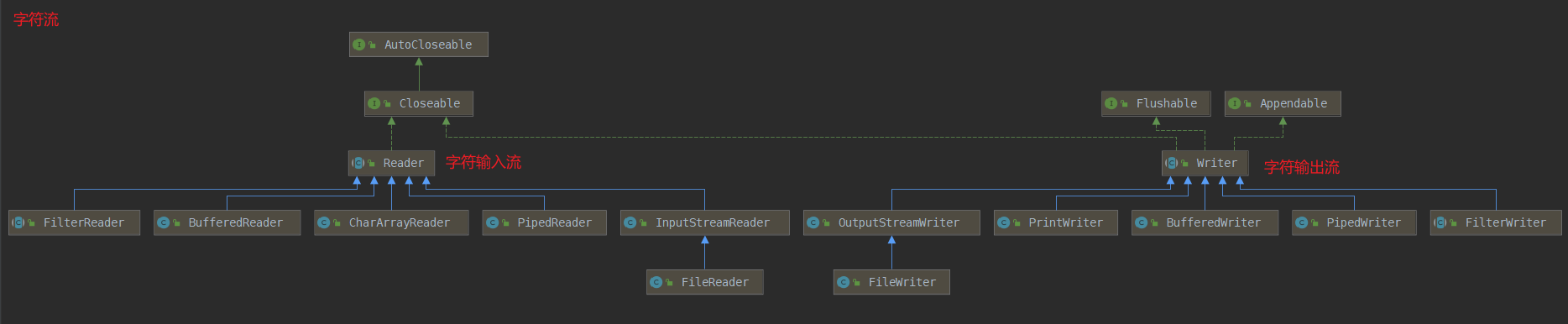
Java的IO体系主要分为字节流和字符流两大类
字节流又分为
字节输入流 InputStream 和 字节输出流 OutputStream
都实现了java.lang.AutoCloseable接口 所以在使用这些流资源时 可以使用 try-with-resource结构 自动关闭流

放大点看:


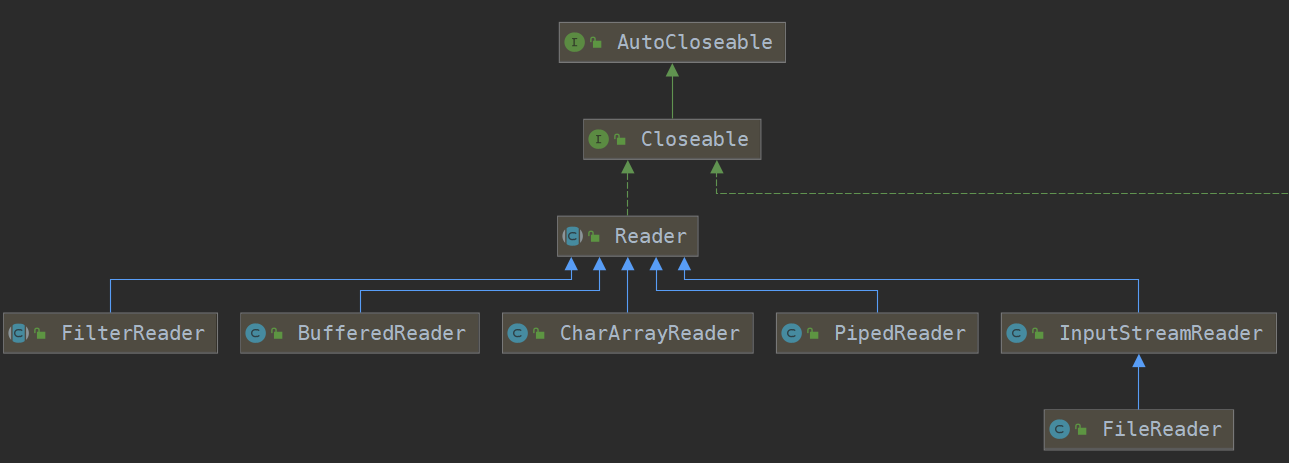
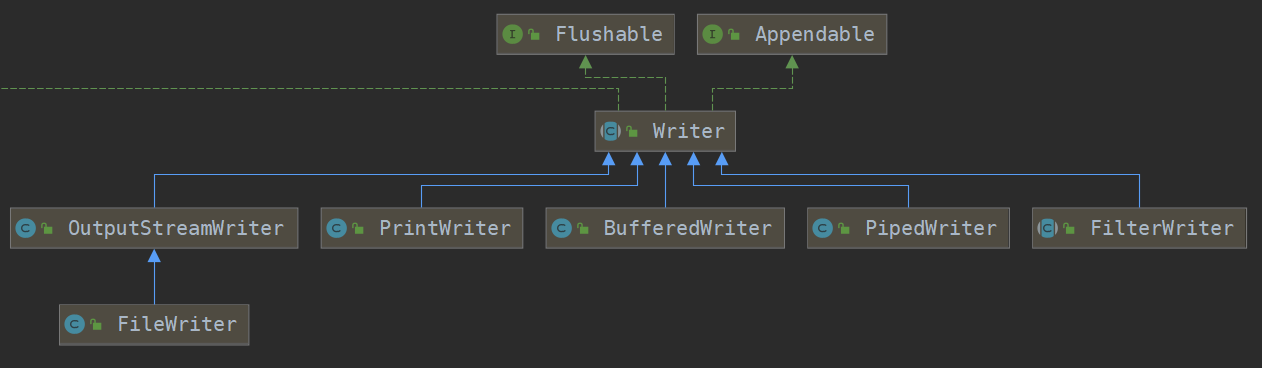
字符流又分为
字符输入流Writer 字符输出流 Reader
放大点看:
2、IO的常用方法
掌握IO的 InputStream 、 OutputStream、Reader 、Writer中的方法
IO中 其他的几十个类 都是基于 上面这四个类 设计的
InputStream抽象类中方法摘要

OutputStream抽象类中方法摘要

Reader 抽象类中方法摘要

Writer抽象类中方法摘要

3、Java中为什么要分为字节流和字符流
分为字节流和字符流的主要原因包括:
- 处理数据类型的不同:字节流以字节为单位进行读写操作,适用于处理二进制数据或者无需考虑字符编码的数据(如图像、音频、视频等文件),而字符流适用于处理文本数据。
- 字符编码的考虑:字符流能够处理字符编码的转换,从而能够更好地处理不同编码格式的文本数据。
- 文本处理的便捷性:使用字符流能够更方便地处理文本数据,如按行读取、字符缓冲等操作。
4、File和RandomAccessFile
在实际项目中我们使用流处理最多的就是文件
下面是File类的 字段和构造方法
一个 File 对象代表硬盘中实际存在的一个文件或者目录。

代码中建议使用 File.separator来表示 路径分隔符 这样程序会自动判断当前运行环境 来生成符合当前运行环境的分隔符 比如Windows的 \
或者 Linux 的 /
File类常用方法:
get类的方法




判断相关的方法



创建文件相关的方法

createNewFile 不存在则创建并且返回true 存在则不创建 返回false


mkdir 只创建一级目录 如果父目录不存在则创建失败

文件或者目录的遍历


遍历输出一个文件夹下的全部文件
public class ListFiles{
public static void main(String[] args) {
//根据给定的路径创建一个File对象
File srcFile = new File("E:\\test");
//调用方法
getAllFilePath(srcFile);
}
//定义一个方法,用于获取给定目录下的所有内容,参数为第1步创建的File对象
public static void getAllFilePath(File srcFile) {
//获取给定的File目录下所有的文件或者目录的File数组
File[] fileArray = srcFile.listFiles();
//遍历该File数组,得到每一个File对象
if(fileArray != null) {
for(File file : fileArray) {
//判断该File对象是否是目录
if(file.isDirectory()) {
//是:递归调用
getAllFilePath(file);
} else {
//不是:获取绝对路径输出在控制台
System.out.println(file.getAbsolutePath());
}
}
}
}
}
RandomAccessFile
RandomAccessFile 允许您跳转到文件的任何位置,从那里开始读取或写入。适用于需要在文件中随机访问数据的场景。
比如在文档的末位加几个字,或者在文档的开头加几个字等操作。

访问模式 mode 的值可以是:
“r”:以只读模式打开文件。调用结果对象的任何 write 方法都将导致 IOException。
“rw”:以读写模式打开文件。如果文件不存在,它将被创建。
"rws"模式:要求对内容或元数据的每个更新都被立即写入到底层存储设备。这意味着在使用"rws"模式打开文件时,不仅对文件内容的更新会被立即写入,还包括文件的元数据,比如文件属性、修改时间等。这种模式是同步的,可以确保在系统崩溃时不会丢失数据。
"rwd"模式:与“rws”类似,也是以读写模式打开文件,并且要求对文件内容的更新被立即写入。不同的是,"rwd"模式只要求对文件内容的更新被立即写入,而元数据可能会被延迟写入,这意味着文件的属性信息等可能不会立即更新到磁盘。
文件内容(File Content):
文件内容通常指的是文件中存储的实际数据,即由应用程序创建的、用户需要读取或操作的数据。对文件内容的更新包括写入新的数据,修改已有数据,或者删除数据等操作。
元数据(Metadata):
元数据是指关于文件的描述性数据,例如文件的名称、大小、创建时间、修改时间、权限信息等。在文件系统中,元数据通常是指文件的属性信息、目录结构、索引信息等。
如果需要确保对元数据的每次更新都被立即写入到存储设备,可以选择"rws"模式;如果对元数据的实时性要求不高,可以选择"rwd"模式以获得更好的性能。
RandomAccessFile常用方法

举个栗子:(使用 RandomAccessFile方法实现插入效果)
使用该类的write方法对文件写入时,实际上是一种覆盖效果,即写入的内容会覆盖相应位置处的原有内容。要实现插入效果
需要记录插入位置的后续内容,插入内容后,再把后续内容写入。
文件内容(来源于网络上吐槽平均工资的一个段子)

我们利用RandomAccessFile 来 在 “两个” 后面再插入点内容
public static void main(String[] args) {
File file = new File("D:\\123.txt");
try(RandomAccessFile randomAccessFile = new RandomAccessFile(file,"rws")) {
// 指定插入位置
randomAccessFile.seek(18);
//获取插入点后面的内容
StringBuffer sb = new StringBuffer();
byte[] b = new byte[100];
int len;
while( (len=randomAccessFile.read(b)) != -1 ) {
sb.append( new String(b, 0, len) );
}
System.out.println(sb);
randomAccessFile.seek(18); //重新设置插入位置
randomAccessFile.write( "睾丸".getBytes() ); //插入指定内容
randomAccessFile.write( sb.toString().getBytes() ); //恢复插入点后面的内容
} catch (Exception e) {
e.printStackTrace();
}
}
此时文件内容:

本质上想插入内容必须先定位到要插入的位置,然后保存此位置之后的内容,插入新内容后,再把保存的内容附加到新插入的内容之后。
使用RandomAccessFile 类的write方法对文件写入时,实际上是一种覆盖效果,即写入的内容会覆盖相应位置处的原有内容。
RandomAccessFile还有个比较重要的作用是实现大文件的断点续传功能
可以参考 https://blog.csdn.net/qq_37883866/article/details/137722103
5、Java对象的序列化和反序列化
基本概念:
序列化:将数据结构或对象转换成二进制字节流的过程
反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
什么时候需要用到序列化
对象在进行网络传输(比如远程方法调用 RPC 的时候)之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化。
例如通过Dubbo进行远程通信的POJO类 都需要实现Serializable接口
将对象存储到文件 也需要序列化 因为文件需要以字节流的形式传输
将对象存储到Redis之前需要用到序列化,将对象从Redis中读取出来需要反序列化;
比如:
@Bean("redisTemplate")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//设置value的序列化方式为Json
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
//设置key的序列化方式为String
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
注意事项:
一个对象要想序列化,该类必须实现java.io.Serializable 接口,否则会抛出NotSerializableException 。
对于不想进行序列化的变量,需要使用 transient 关键字修饰 例如: public transient int name;
静态变量不能被序列化 例如: public static int name;
transient 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 int 类型,那么反序列后结果就是 0。
实现Serializable接口的类 最好自定一个serialVersionUID
private static final long serialVersionUID = 1L;
在 Java 中,序列化 ID(SerialVersionUID)是序列化版本标识符,它是为了在进行对象序列化和反序列化时确保版本的兼容性而存在的。
序列化 ID 的作用主要包括以下几个方面:
- 版本控制:当类的结构发生变化时(比如添加、删除或修改字段、方法等),序列化 ID 可以确保在反序列化时能够正确地恢复旧版本的对象。如果不指定序列化 ID,Java 编译器会根据类的结构自动生成一个序列化 ID,但是这样生成的序列化 ID 可能会受到类结构变化的影响,导致在反序列化时抛出版本不一致的异常。
- 兼容性:在分布式系统中,不同的 Java 虚拟机可能会使用不同的类版本。通过指定序列化 ID,可以确保不同版本的 Java 程序在进行对象序列化和反序列化时能够正确地识别和处理对象版本,从而保证了系统的兼容性。
- 安全性:序列化 ID 可以防止恶意攻击者通过修改类结构来篡改对象的字段值或方法行为,从而提高了系统的安全性。
Java 的序列化流(ObjectInputStream 和 ObjectOutputStream)可以将 Java 对象序列化和反序列化。
代码示例:
class User implements Serializable {
/*
* 版本控制:当类的结构发生变化时(比如添加、删除或修改字段、方法等),序列化 ID 可以确保在反序列化时能够正确地恢复旧版本的对象。
* 如果不指定序列化 ID,Java 编译器会根据类的结构自动生成一个序列化 ID,但是这样生成的序列化 ID 可能会受到类结构变化的影响,
* 导致在反序列化时抛出版本不一致的异常。
*
* 兼容性:在分布式系统中,不同的 Java 虚拟机可能会使用不同的类版本。通过指定序列化 ID,
* 可以确保不同版本的 Java 程序在进行对象序列化和反序列化时能够正确地识别和处理对象版本,从而保证了系统的兼容性。
*
* 安全性:序列化 ID 可以防止恶意攻击者通过修改类结构来篡改对象的字段值或方法行为,从而提高了系统的安全性。
*
* */
private static final long serialVersionUID = 1L;
private Integer age;
private String name;
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
// 测试序列化 和 反序列化
public static void main(String[] args) {
User user = new User();
user.setName("秀逗");
user.setAge(10);
// 序列化
try (FileOutputStream fos = new FileOutputStream("D:\\user.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);) {
oos.writeObject(user);
} catch (Exception e) {
e.printStackTrace();
}
// 反序列化
String filename = "D:\\user.dat";
try (FileInputStream fileIn = new FileInputStream(filename);
ObjectInputStream in = new ObjectInputStream(fileIn)) {
// 从指定的文件输入流中读取对象并反序列化
Object obj = in.readObject();
// 将反序列化后的对象强制转换为指定类型
User user1 = (User) obj;
// 打印反序列化后的对象信息
System.out.println(user1);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
上面这种JDK自带的序列化方式会有一些问题:
- 可移植性差:只能通过Java语言实现 ,无法跨语言进行序列化和反序列化。
- 性能差:序列化后的字节体积大,增加了传输/保存成本。
- 安全问题:输入的反序列化的数据可被用户控制,如果攻击者恶意构造反序列化的数据,通Java的反序列化操作可能产生非预期对象,进而执行攻击者构造的恶意代码 造成严重后果
比如在序列化的对象中加下面一段代码:
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException{
ois.readObject();
Runtime.getRuntime().exec("calc");
}
就能打开window的计算器
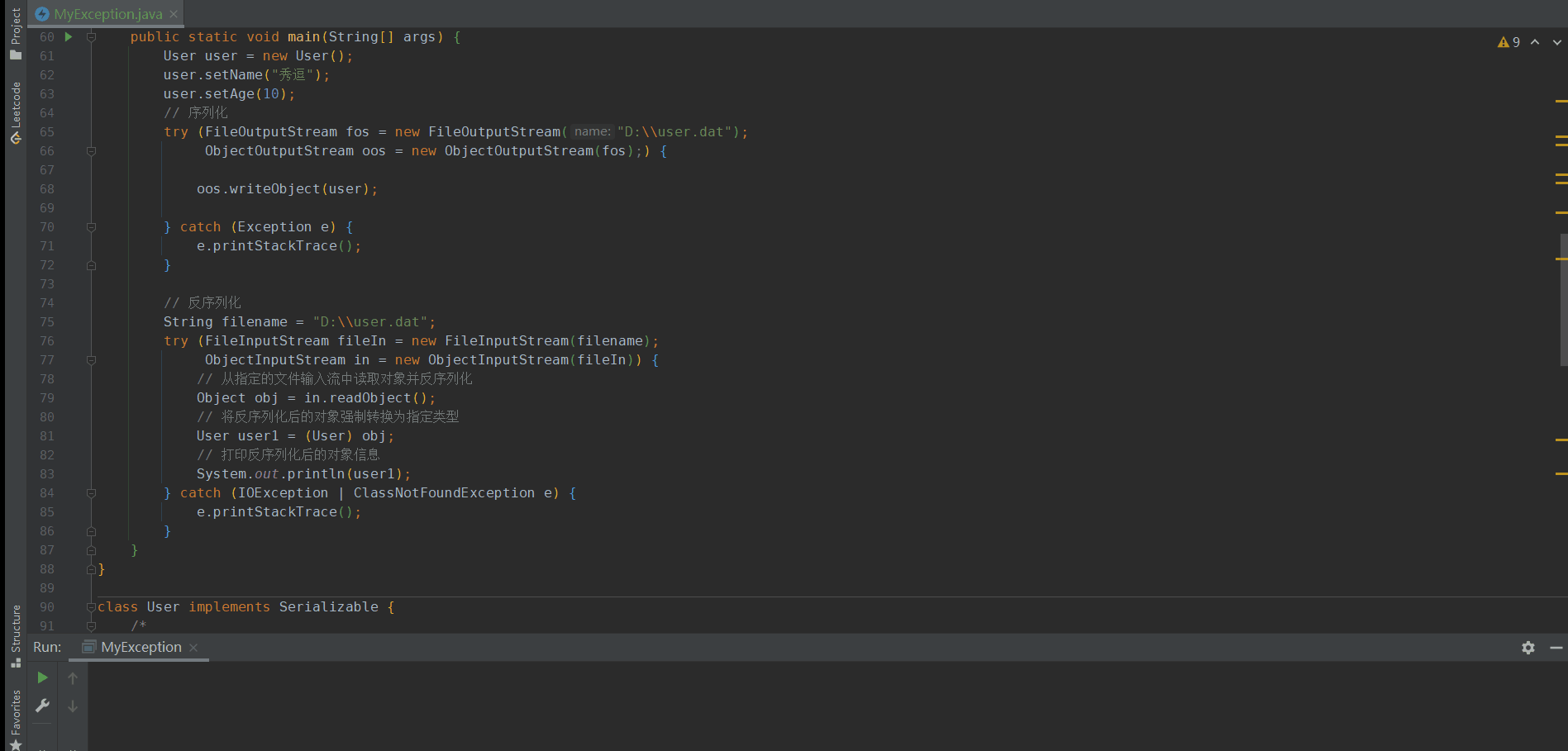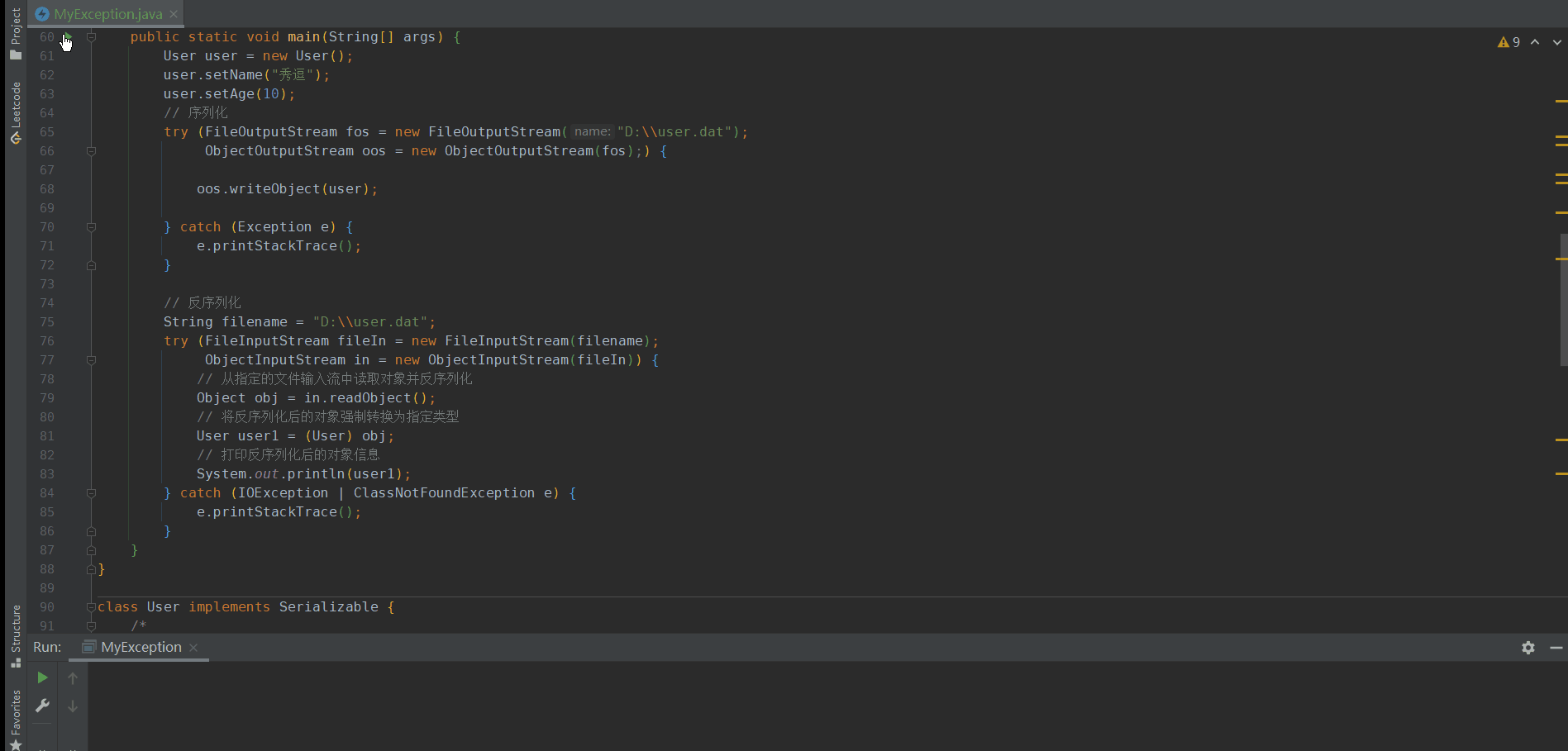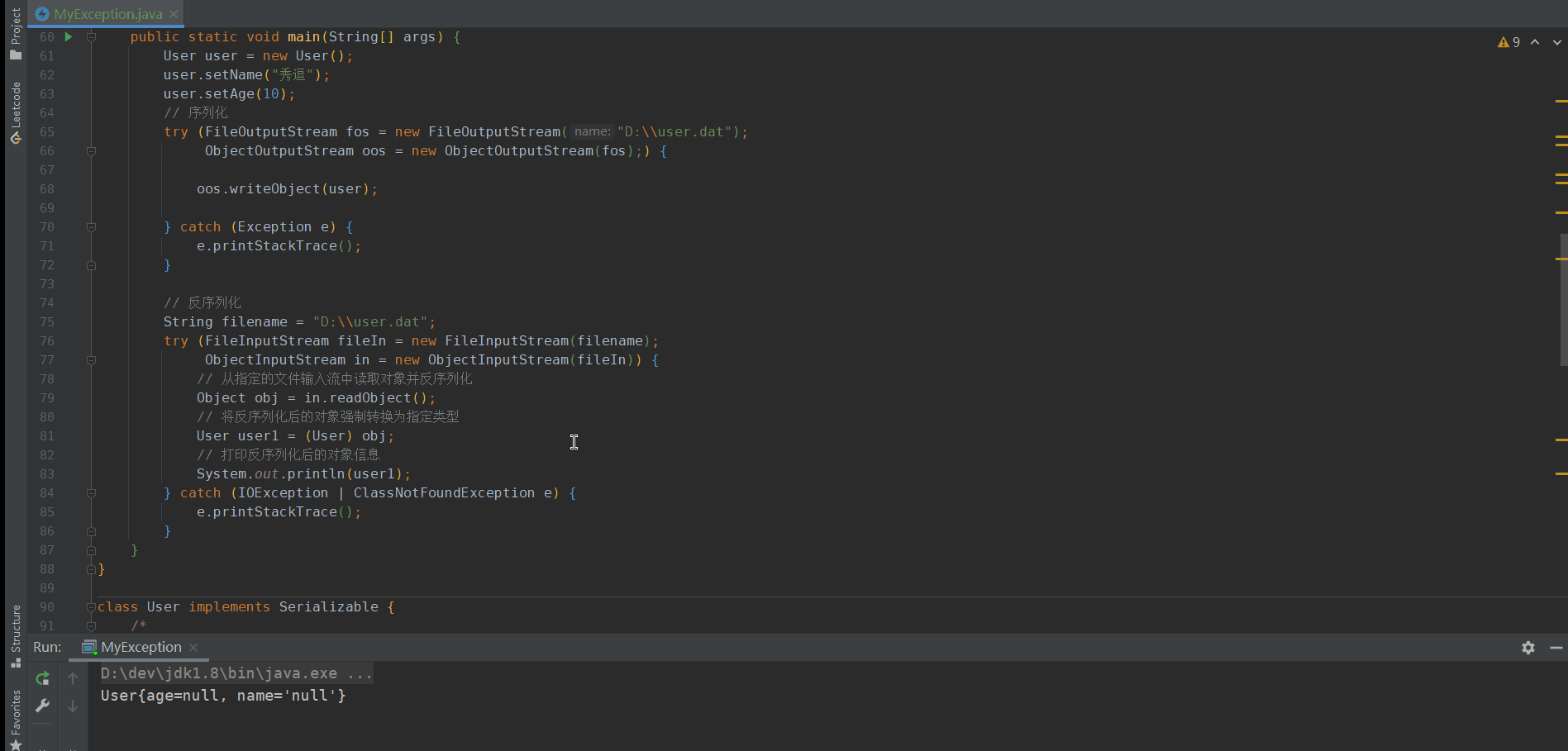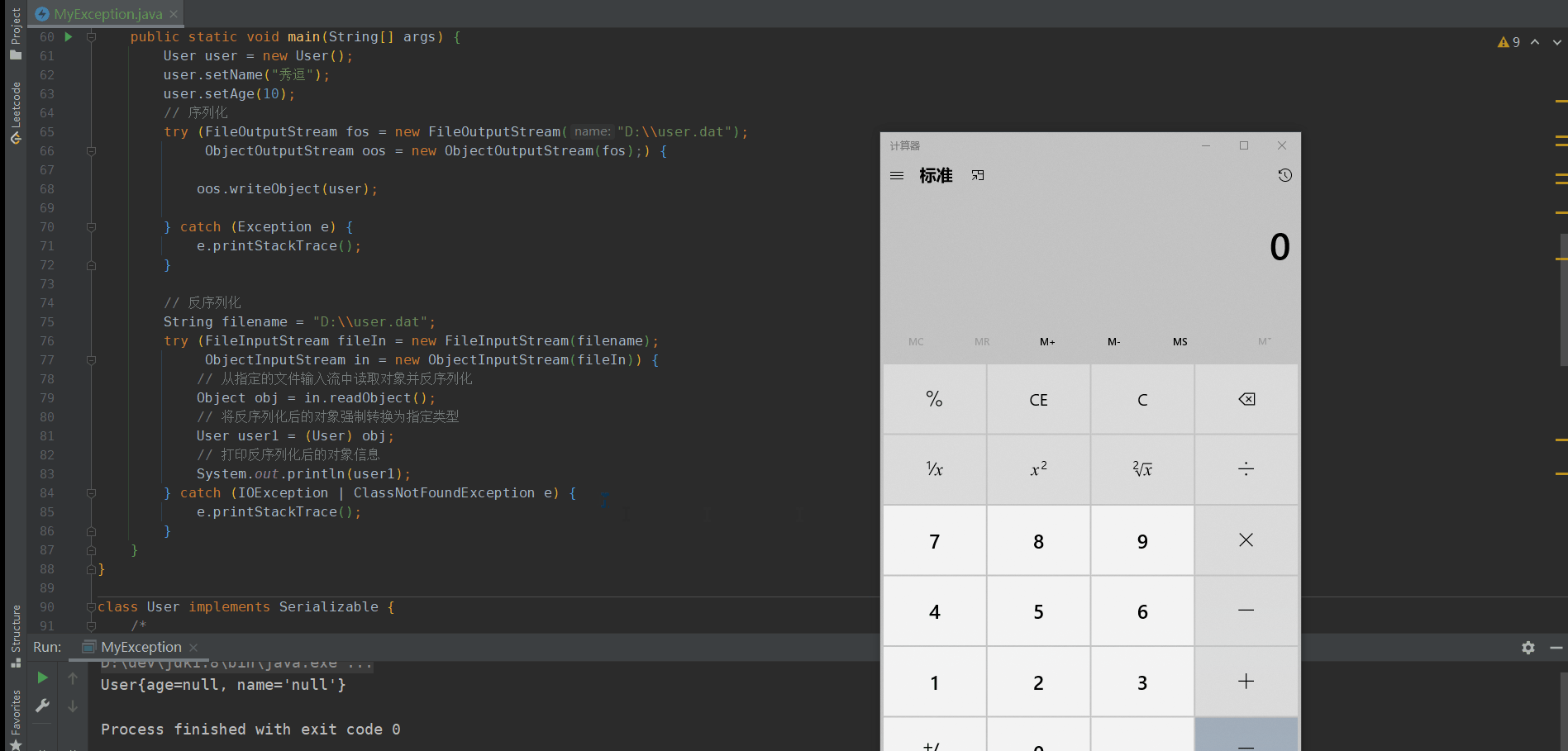
因为Java 的序列化机制会通过反射在对象的反序列化过程中调用这个方法。这个方法的签名必须是private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException。
这个机制提供了一个对象被反序列化时执行特定逻辑的机会,例如对特定字段进行初始化或进行额外的安全性检查。然而,由于 readObject 方法可以执行自定义的逻辑,如果没有严格的限制,恶意用户就可能利用这一特性进行攻击,因此需要谨慎使用。
第三方Java 序列化和反序列化库
基于二进制的序列化协议
- Kryo
- Hessian
- Protobuf
- ProtoStuff
Kryo序列化举例:
<!-- maven 引入 Kryo-->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.4.0</version>
</dependency>
public static void main(String[] args) {
Kryo kryo = new Kryo();
kryo.register(User.class);
User user = new User();
user.setName("秀逗");
user.setAge(10);
try (Output output = new Output(new FileOutputStream("D:\\userKryo.dat"));){
kryo.writeObject(output, user);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try (Input input = new Input(new FileInputStream("D:\\userKryo.dat"));){
User user1 = kryo.readObject(input, User.class);
System.out.println(user1);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
比较下 相同对象 使用Java 的ObjectOutputStream 和使用Kryo 序列化后的文件大小
Kryo 比 ObjectOutputStream 小了20多倍

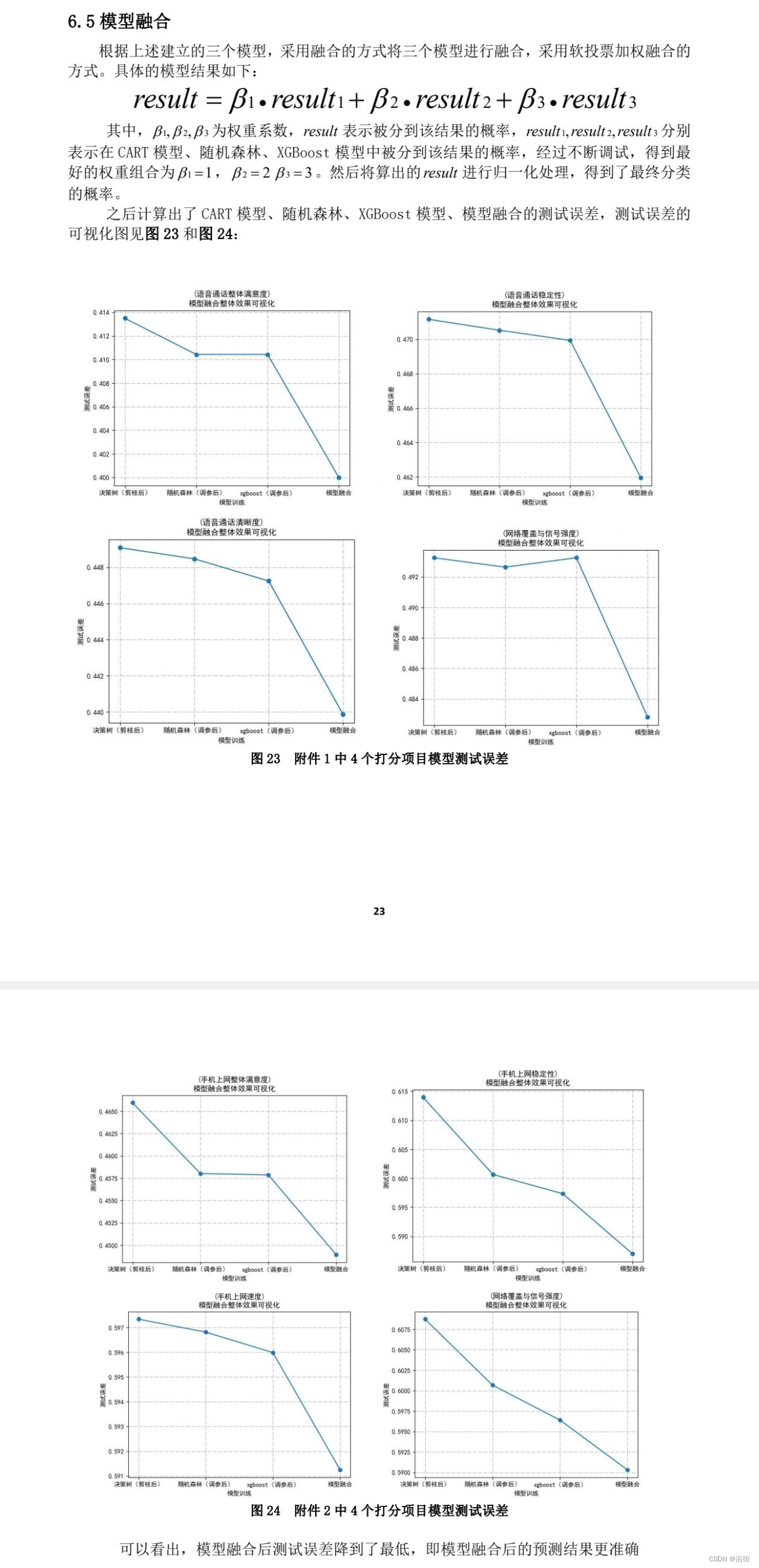
6、缓冲流
Java 的缓冲流是使用装饰器模式 对字节流和字符流的一种封装
目的是 使用缓冲区减少系统的 I/O 操作次数,从而提高系统的 I/O 效率
缓冲字节流:
对InputStream进行包装 得到 BufferedInputStream (字节缓冲输入流)
对OutputStream进行包装 得到 BufferedOutputStream (字节缓冲输出流)
缓冲字节流代码示例:
public static void main(String[] args) throws IOException {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("D:\\HRM_BETA.zip"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("D:\\HRM_BETA_COPY.zip"));
){
int b;
while ((b = bufferedInputStream.read()) != -1) {
bufferedOutputStream.write(b);
}
}catch (Exception e){
throw e;
}
}
使用普通的字节流配合字节数组读写 速度也还可以 (当然缓冲字节流也可以使用数组读写):
public static void main(String[] args) throws IOException {
try (InputStream inputStream = new FileInputStream("D:\\HRM_BETA.zip");
OutputStream outputStream = new FileOutputStream("D:\\HRM_BETA_COPY.zip");
){
int len;
byte[] bys = new byte[8*1024];
while ((len = inputStream.read(bys)) != -1) {
// 注意下后两个参数 第一个是指数组bys的起始偏移量 第二个参数是指写入数组bys的长度
outputStream.write(bys,0,len);
}
}catch (Exception e){
throw e;
}
}
缓冲字符流:
对Reader 进行包装得到 BufferedReader (字符缓冲输入流)
对Writer 进行包装得到 BufferedWriter(字符缓冲输出流)
缓冲字符流代码示例:
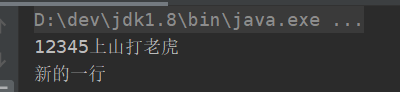
public static void main(String[] args) throws IOException {
try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("D:\\123.txt"))
){
bufferedWriter.write("12345上山打老虎");
bufferedWriter.newLine();
bufferedWriter.write("新的一行");
}catch (Exception e){
throw e;
}
try (BufferedReader bufferedReader = new BufferedReader(new FileReader("D:\\123.txt"))
){
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
}catch (Exception e){
throw e;
}
}
运行结果:
7、Java 的IO流中涉及哪些设计模式
设计模式可以参考:https://blog.csdn.net/qq_37883866/article/details/115580862
**装饰器模式:**动态地给一个对象添加一些额外的职责。提供了用子类扩展功能的一个灵活的替代,但比生成子类更为灵活。
在Java的IO体系中
FilterInputStream和FilterOutputStream 是两个非常重要的装饰器 他们分别继承了抽象类 InputStream和OutputStream
我们可以利用 继承 FilterInputStream或者FilterOutputStream 来动态地对输入流或者输出流添加一些功能 。比如添加缓冲、数据加密、计数等额外功能。
例如,BufferedInputStream 继承 FilterInputStream ,它提供了缓冲功能,通过将原始输入流包装在 BufferedInputStream 中,可以提高读取数据的性能。
我们也可以自定义一个流实现把输入流内的大写字母转换为小写字母:
public class LowerCaseInputStream extends FilterInputStream {
protected LowerCaseInputStream(InputStream in) {
super(in);
}
public int read() throws java.io.IOException {
int c = super.read();
return (c == -1 ? c : Character.toLowerCase((char)c));
}
public int read(byte[] b, int off, int len) throws java.io.IOException {
int c = super.read(b, off, len);
if (c != -1) {
for (int i = off; i < off + c; i++) {
b[i] = (byte)Character.toLowerCase((char)b[i]);
}
}
return c;
}
}
// 测试方法
public static void main(String[] args) {
String file = "C:\\Users\\Administrator\\Desktop\\123.txt";
int c;
try {
InputStream in =
new BufferedInputStream(
new FileInputStream(file));
while ((c = in.read()) >= 0) {
System.out.print((char) c);
}
in.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println();
try {
// 使用包装类
InputStream in =
new LowerCaseInputStream(
new BufferedInputStream(
new FileInputStream(file)));
while ((c = in.read()) >= 0) {
System.out.print((char) c);
}
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
效果:
文件
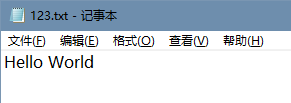
输出:

适配器模式:
将一个类的接口转换成客户希望的另外一个接口。使得原本不相容的接口可以协同工作。
InputStreamReader 和 OutputStreamWriter就是两个适配器
分别用来适配 InputStream和OutputStream
通过适配器,我们可以将字节流对象适配成字符流对象,这样我们可以直接通过字节流对象来读取或者写入字符数据。
InputStreamReader 和 OutputStreamWriter也就是常说的转换流
其中InputStreamReader将字节输入流转为字符输入流,继承自Reader。
OutputStreamWriter是将字符输出流转为字节输出流,继承自Writer。(注意是 字符输出流转为字节输出流)
字符编码和字符集 这部分内容参考:https://blog.51cto.com/u_16213662/7427967
计算机中使用二进制数字 0 1 存储数据,我们在电脑上看到的文字信息是通过将二进制转换之后显示的,两者之间的转换其实是编码与解码的过程。而编码和解码转换之间是需要遵循规则的,即编码和解码都遵循同一种规则才能将文字信息正常显示,如果编码跟解码使用了不同的规则,就会出现乱码的情况。
转换流,核心就是编码和解码过程:
编码:字符 、字符串 ( 能看懂的 ) -----------> 字节(看不懂的)
解码:字节( 看不懂的 ) -----------> 字符、字符串(能看懂的)
编码与解码的过程需要遵循的规则,其实就是不同的字符编码。我们最早接触的是ASCII码,它主要是用来显示英文和一些符号,到后面还有编码规则中常用的有:gbk,utf-8等。它们分别属于不同的编码集。
encoding是charset encoding的简写,即字符集编码,简称编码。
charset是character set的简写,即字符集。
得出编码是依赖于字符集的,一个字符集可以有多个编码实现
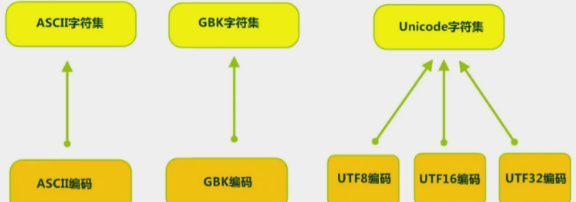
使用示例:
InputStreamReader(InputStream in):创建一个默认字符集字符输入流。
InputStreamReader(InputStream in, String charsetName):创建一个指定字符集的字符流。
InputStreamReader isr1 = new InputStreamReader(new FileInputStream("D:\\utf-8.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("D:\\utf8.txt"),"UTF-8");
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。
OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
OutputStreamWriter isr1 = new OutputStreamWriter(new FileOutputStream("gbk.txt""));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("gbk1.txt") , "GBK");
如果没有指定字符集,则默认会使用平台默认的字符编码。
在不同的操作系统上,平台默认的字符编码可能不同。在大多数情况下,Windows 系统上的默认字符编码是 Windows 系统默认的代码页(如GBK或Windows-1252),而在类 Unix 系统上通常是 UTF-8。
推荐指定字符集为 StandardCharsets.UTF_8
public static void main(String[] args) {
try (OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("123.txt"), StandardCharsets.UTF_8);
){
osw.write("中国");
} catch (IOException e) {
e.printStackTrace();
}
try (InputStreamReader isr = new InputStreamReader(new FileInputStream("123.txt"), StandardCharsets.UTF_8);){
//一次读取一个字符数据
int ch;
while ((ch = isr.read()) != -1) {
System.out.print((char) ch);
}
} catch (Exception e) {
e.printStackTrace();
}
}