论文:Measuring Massive Multitask Language Understanding
⭐⭐⭐⭐
ICLR 2021, arXiv:2009.03300
Code: GitHub
论文速读
本文提出了一个 benchmark:MMLU,一个覆盖了 57 个 subjects 的多项选择题的数据集。
数据集的 question 数量:一共有 15908 个 questions,并被分为 dev、val、test 三个 split set:
- dev set:用于做 few-shots,每个 subject 有 5 个 questions
- val set:用于选择 hyper-parameters,由 1540 个 questions
- test set:包含 14079 个 questions,每个 subject 至少包含 100 个 test examples
数据集设计的 subjects:包含 57 个 subjects,涉及到 STEM、人文、社科等问题
- 人文:人文学科是一组运用定性分析和分析方法而不是科学实证方法的学科。包括法律、哲学、历史、道德等。
- 社科:社科包括研究人类行为和社会的分支。包括经济学、社会学、政治学、地理学、心理学等。
- STEM:包括 Science、Tenchnology、Engineering、Mathematics
- other:这些 long-tail subject 包含那些不符合以上三类或者数量不足的一些问题,包括专业医学、金融、会计等
为了能够解决这些问题,model 需要能够处理广泛的世界知识、发展 expert-level 的问题解决能力。
实验
在实验时,会加入 prompt:
The following are multiple choice questions (with answers) about [subject].
并在 zero-shot 和 few-shot 两种场景下进行评估,few-shot 的评估会使用 dev set 中的 demonstrations 作为 ICL 的上下文示例。如下是一个示例:

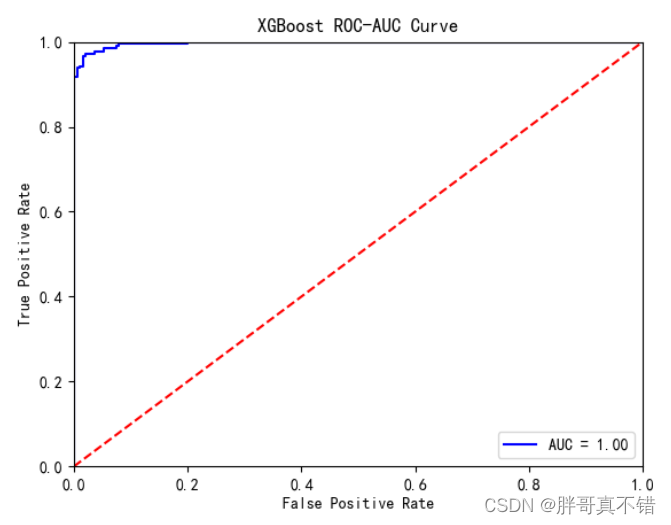
论文通过对多个模型测试,发现大部分 model 都表现,但在 GPT-3 上表现明显比其他更好。
同时论文发现 GPT-3 的表现是不平衡的:GPT-3 对其最佳科目的准确率接近 70%,但对其他几个科目的准确率几乎是随机的。
Question 示例
下面是几个数据集的示例:





![Mathematica训练课(45)-- 一些常用的函数Abs[],Max[]等函数用法](https://img-blog.csdnimg.cn/direct/9c79c770c8fd4304822e3b34c42e9d29.png)