HBase概述

1. Why we need HBase ?
-
在大数据时代来临之前,我们通常依赖传统的关系型数据库(如RDBMS)来处理数据存储和管理。然而,随着数据量的急剧增长和数据结构的多样化,传统数据库系统开始显露出其局限性。
-
针对这一挑战,我们引入了新的解决方案,其中包括熟悉的“大象”——
Hadoop。 -
然而,使用Hadoop存储大量数据并且试图从中检索少量记录存在一个显著问题:必须扫描整个Hadoop分布式文件系统(HDFS)才能获取这些记录。
-
HDFS能够高效地存储、处理和管理大量数据。但是,它只执行批处理,并且以顺序方式访问数据。

- 因此,需要一种解决方案,无论数据在集群中的顺序如何,都可以随时访问、读写数据。

-
Hadoop的这种限制导致了对数据库随机访问的不足,这也正是引入HBase的原因。
-
HBase类似于传统的数据库管理系统(DBMS),但它提供了能够以随机方式访问数据的能力,弥补了Hadoop的这一局限性。
2.What is Apache HBase?
-
HBase(
Hadoop Database)是一个开源的分布式、面向列存储的非关系型数据库系统。 -
HBase建立在
Apache Hadoop上,利用 Hadoop 的分布式文件系统HDFS存储数据。
-
HBase可以以表格格式存储大量数据,主要用于需要定期且一致地插入和覆盖数据以及需要极快读写场景。

-
HHBase采用了类似于Google的Bigtable的数据模型,这意味着它是基于列族(
column family)的分布式存储系统。 -
bigtable是一个结构化数据的分布式存储系统。bigtable利用了谷歌文件系统提供的分布式数据存储。
-
Apache hbase在hadoop和HDFS之上提供了类似bigtable的功能。
3.Characteristics of HBase
-
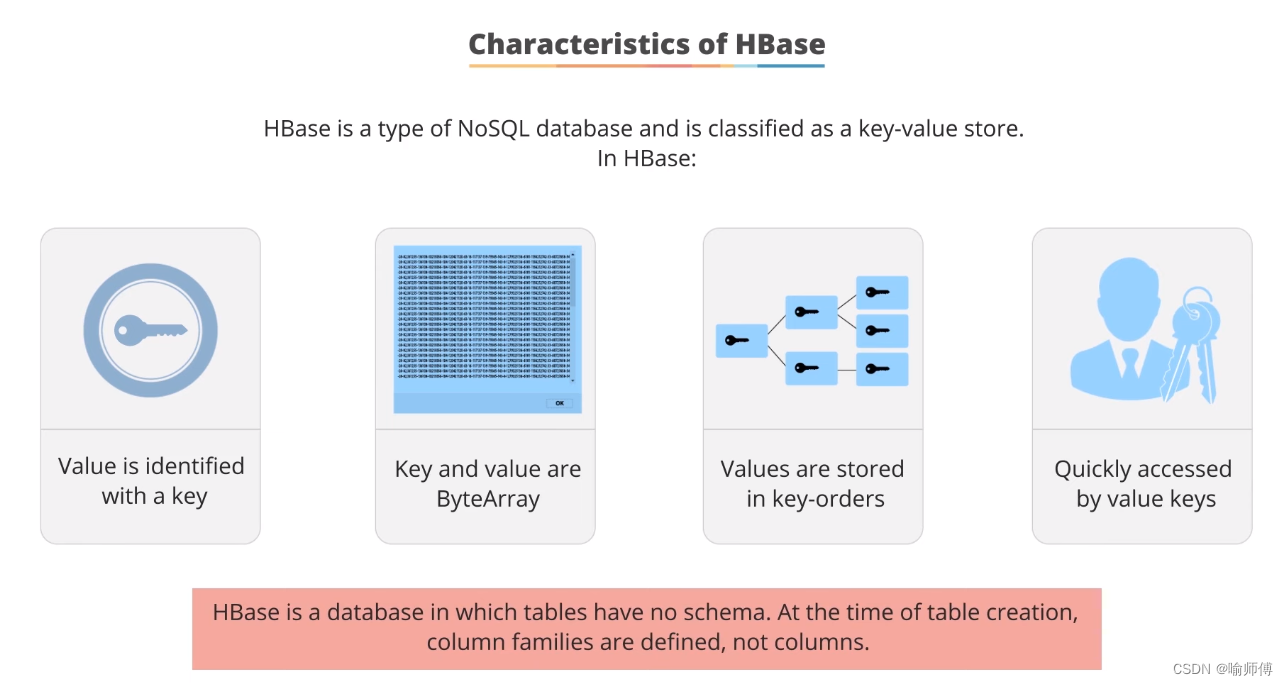
HBase is a type of NoSQL database and is classified as a key-value store.
HBase是一种被归类为键值存储的NoSQL数据库。 -
Value is identified with a key
- Every piece of data stored in HBase is associated with a unique key. This key serves as the identifier for the data and is used to store and retrieve values efficiently.
HBase 中的每条数据都与一个唯一的键相关联。这个键用于高效地存储和检索数据值。
- Every piece of data stored in HBase is associated with a unique key. This key serves as the identifier for the data and is used to store and retrieve values efficiently.
-
Key and values are byte array of type.
- 在HBase中,键(key)和值(value)都是以字节数组(byte array)的形式存储的。
- 可以轻松的存储二进制数据
-
Values are stored inkey orders and can be quickly accessed by their keys.
- HBase 值以键顺序存储,可以通过键快速访问。
-
HBase is a database in which tables have no schema. At the time of table creation,
column families are defined, not columns.-
HBase 其表在创建时没有严格的模式(
schema)。在创建表时,定义的是列族(column families),而不是列。 -
列族是逻辑上的概念,它们可以包含多个列。在实际存储数据时,列族的定义决定了数据在物理上的存储方式。每个列族可以包含多个动态列,这些列不需要在创建表时预先定义,可以根据需要动态添加。
-
因此,HBase 的表在创建时可以定义一个或多个列族,而具体的列是在数据写入时动态创建和管理的。这种设计使得HBase非常适合存储半结构化和非结构化数据,同时保持了高度的灵活性和扩展性。
-

-
线性可扩展性(Linearly Scalable):HBase 能够在大规模数据集上实现线性扩展,通过水平分割数据并在多台服务器上分布存储,以处理增加的负载而无需单点增强硬件性能。
-
与 Hadoop 集成(Hadoop Integration):HBase紧密集成于Hadoop生态系统,特别是与HDFS(Hadoop分布式文件系统)和MapReduce配合使用,支持在大数据处理流程中无缝存储和分析数据。
-
自动容错支持(Auto-Failure Support):HBase具备自动容错和恢复机制,能够在节点故障时自动将数据恢复到可用状态,保证系统的高可用性和持久性。
-
Java API 支持(Java API Support):HBase 提供了丰富的 Java API,使得开发人员可以轻松地通过 Java 编程语言进行数据的读取、写入和管理。
-
一致性读写(Consistent Read/Write):HBase 提供了一致性的读取和写入操作,确保数据的读取和更新操作在分布式环境下保持一致性,同时支持多版本数据访问。
-
数据复制(Data Replication):HBase 支持数据的复制,可以在不同的数据中心或节点之间复制数据,提高数据的可用性和容灾能力,同时支持异步复制和自定义复制策略。
4.Why NoSQL?
NoSQL是一种非结构化存储形式,这意味着NoSQL数据库没有固定的表结构。
左侧展示的结构化数据库严重依赖行、列和表。非结构化数据库则包含多种不同类型的数据。
With the explosion of social media sites, such as Facebook and Twitter ,the demand to manage large data has grown tremendously.

NoSQL数据库解决了存储、管理、分析和归档大数据时面临的挑战。由于其高性能、高可扩展性和易于访问,这些数据库也因此获得了广泛的流行。
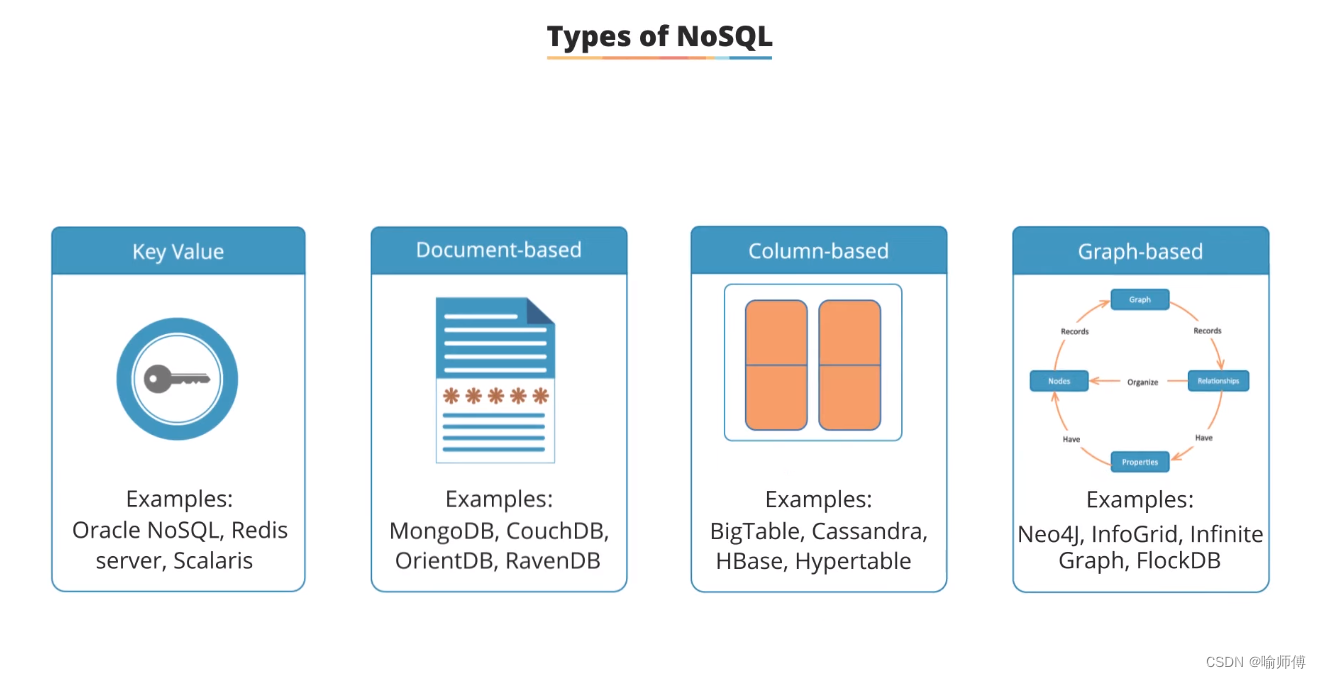
NoSQL数据库主要有四种类型:
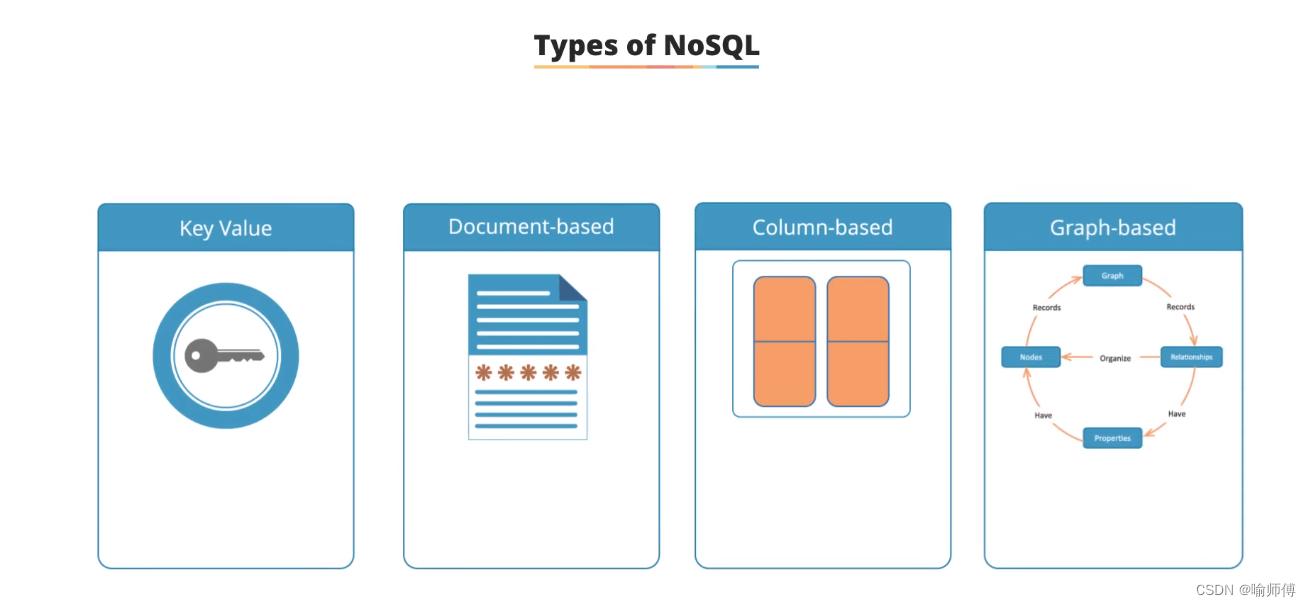
- 键值存储(Key-Value):数据以键值对形式存储,每个键唯一对应一个值,适合快速存取和简单查询的场景。
- 文档型存储(Document-based):数据以文档形式存储,文档可以是JSON、XML等格式,每个文档可以包含不同结构的数据,适合应用程序需要灵活数据模型的情况。

- 列族存储(Column-based):数据以列族(column family)存储,适合需要大量数据写入和复杂查询的场景,具有高效的读写性能。
- 图形数据库(Graph-based):数据以图的形式存储,包括节点(node)和边(edge),用于存储具有复杂关系和连接的数据,适合分析和处理复杂的关系网络。
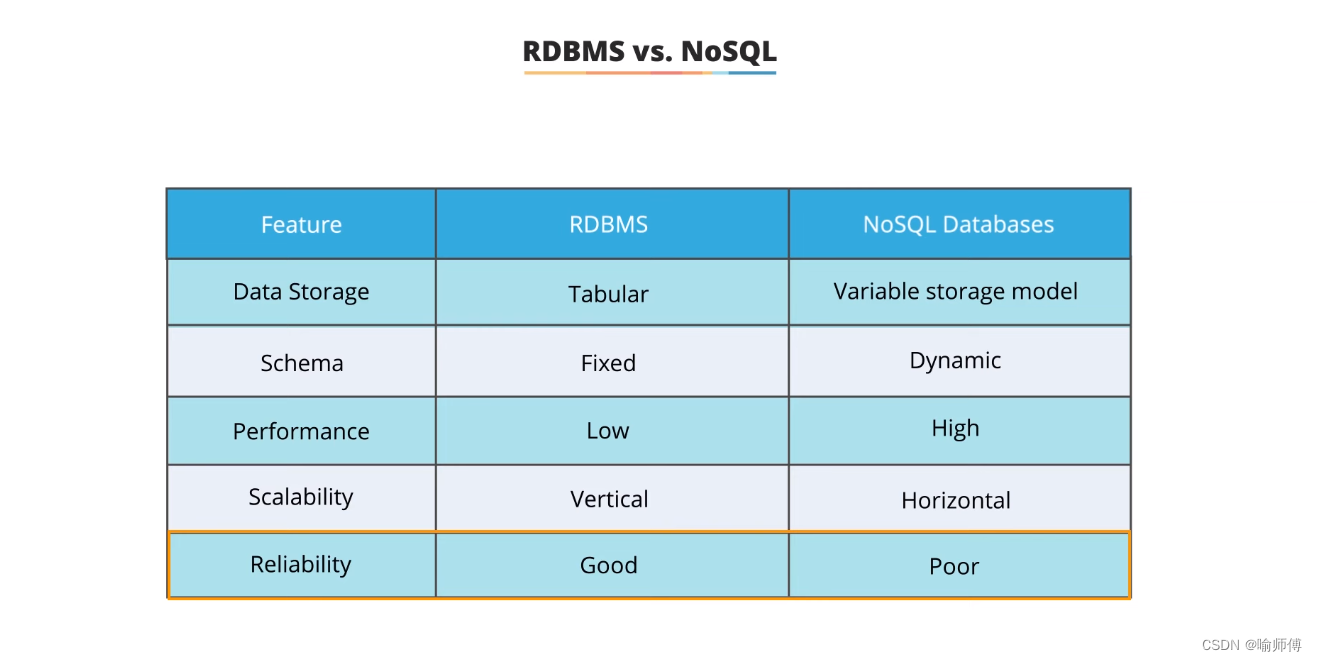
RDBMS 与 NoSQL数据库对比。
| 特征 | RDBMS | NoSQL数据库 |
|---|---|---|
| 数据存储 | 表格化(Tabular) | 可变存储模型(Variable storage model) |
| 数据模式 | 固定(Fixed) | 动态(Dynamic) |
| 性能 | 低(LOW) | 高(High) |
| 可扩展性 | 纵向扩展(Vertical) | 横向扩展(Horizontal) |
| 可靠性 | 良好(Good) | 较差(Poor) |
-
数据存储模型:
- RDBMS:采用表格化
Tabular的数据存储模型,数据以行和列的形式组织,每个表具有预定义的结构。 - NoSQL数据库:采用多样化的存储模型,可以是键值对、文档、列族或图形等形式,允许更灵活和动态的数据结构。
- RDBMS:采用表格化
-
数据模式:
- RDBMS:具有固定的数据模式,需要预先定义表的结构和关系,且数据必须符合这些结构。
- NoSQL数据库:通常具有动态的数据模式,可以根据需要动态调整数据结构,适应不同的数据格式和需求变化。
-
性能:
- RDBMS:在复杂的查询和事务处理方面通常表现较好,但在大规模数据处理和读取时性能相对较低。
- NoSQL数据库:在处理大量数据和简单查询时性能往往非常高,可以通过横向扩展来提升性能。
-
可扩展性:
- RDBMS:主要通过纵向扩展(增加硬件资源如CPU、内存)来提升性能,扩展性有限。
- NoSQL数据库:通过横向扩展(增加节点数目)来提升性能和容量,具有更好的可扩展性和弹性。
-
可靠性:
- RDBMS:因为事务处理和数据完整性的强调,通常具有较高的可靠性和数据一致性。
- NoSQL数据库:由于强调分布式架构和大规模数据处理,可能在数据一致性和可靠性方面相对较弱,取决于具体实现和配置。
5.Real-Life Connect
Facebook的Messenger平台需要每月存储超过135万亿条消息。

它们选择了HBase作为存储这些数据的解决方案,原因在于需要处理两种类型的数据模式:
-
稀少访问的持续增长数据集:这些数据集包含了大量的消息数据,但通常很少被访问或者只在特定的情况下才会被查询和检索。(例如收件箱的信息,看一次,就很少再去查看了。)
-
高度易变的持续增长数据集:这些数据集则包含了频繁变化的消息数据,这些数据需要能够快速地更新和访问。
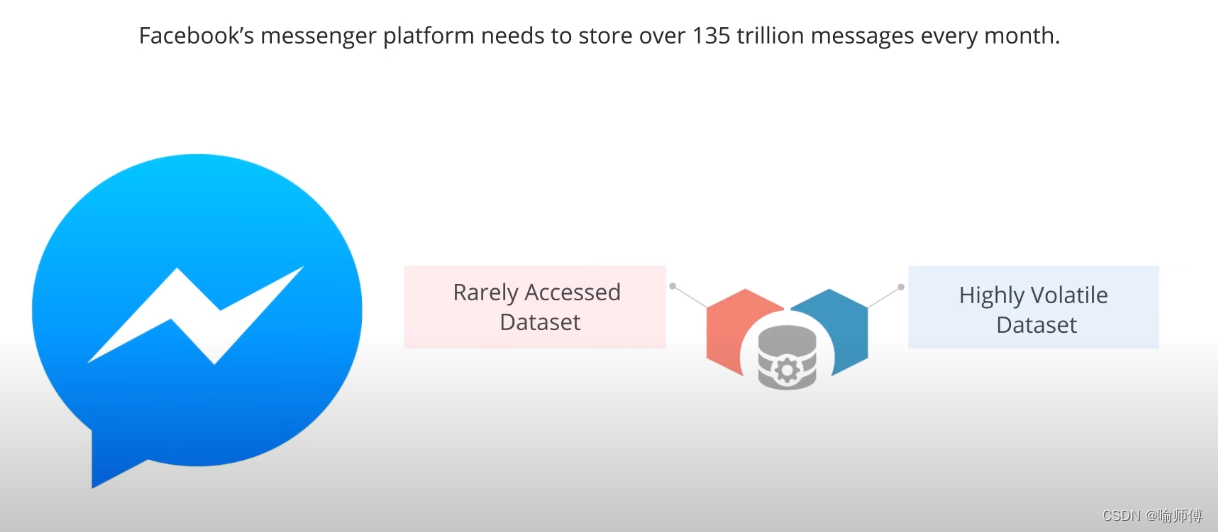
HBase特别适合处理大数据量和动态数据模式的场景。
对于像Facebook Messenger这样的大型即时通讯平台来说,选择HBase能够有效地应对其庞大的数据存储和处理挑战。
6.HBase Architecture
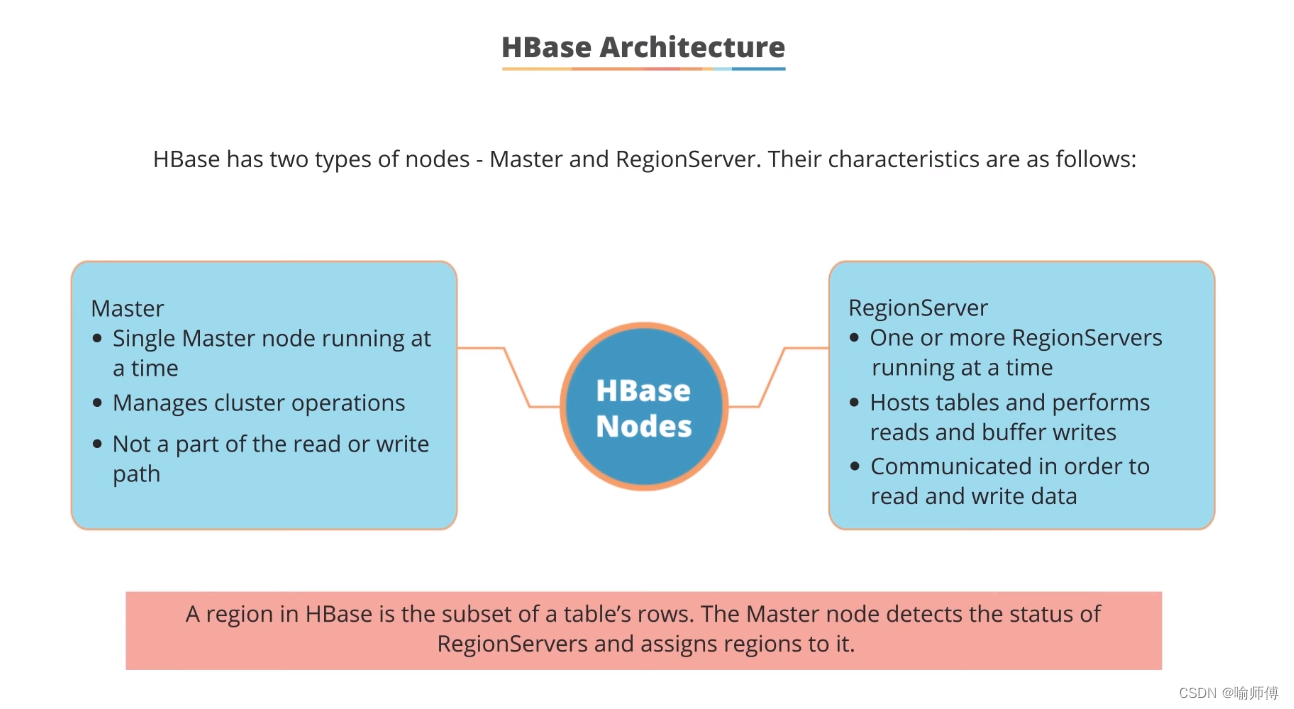
HBase拥有两种类型的节点:Master节点和RegionServer节点。
在HBase中,Master节点和RegionServer节点协同工作,共同构成一个高效的分布式存储和处理系统。
Master节点负责整个集群的管理和协调,而RegionServer节点则负责实际的数据存储和读写操作,通过分布式的方式处理大规模数据。
-
Master节点:
- 每次只有一个Master节点在运行。
- 负责管理整个HBase集群的操作,包括RegionServer的协调和管理。
- 不参与读取或写入数据的路径,主要负责集群的元数据管理和协调。
- 负责监测和管理RegionServer的状态,以及为RegionServer分配和重新分配数据区域(Regions)。
-
RegionServer节点:
- 可以同时运行一个或多个RegionServer节点。
- 主要负责托管HBase表中的数据区域(Regions),并执行数据的读取和缓冲写入操作。
- 在读取和写入数据时起到关键作用,处理客户端的数据请求。
- Region是HBase中表的行的子集,每个RegionServer可以托管多个Region。
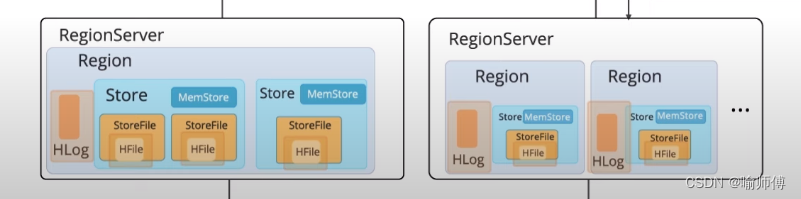
7.HBase Components
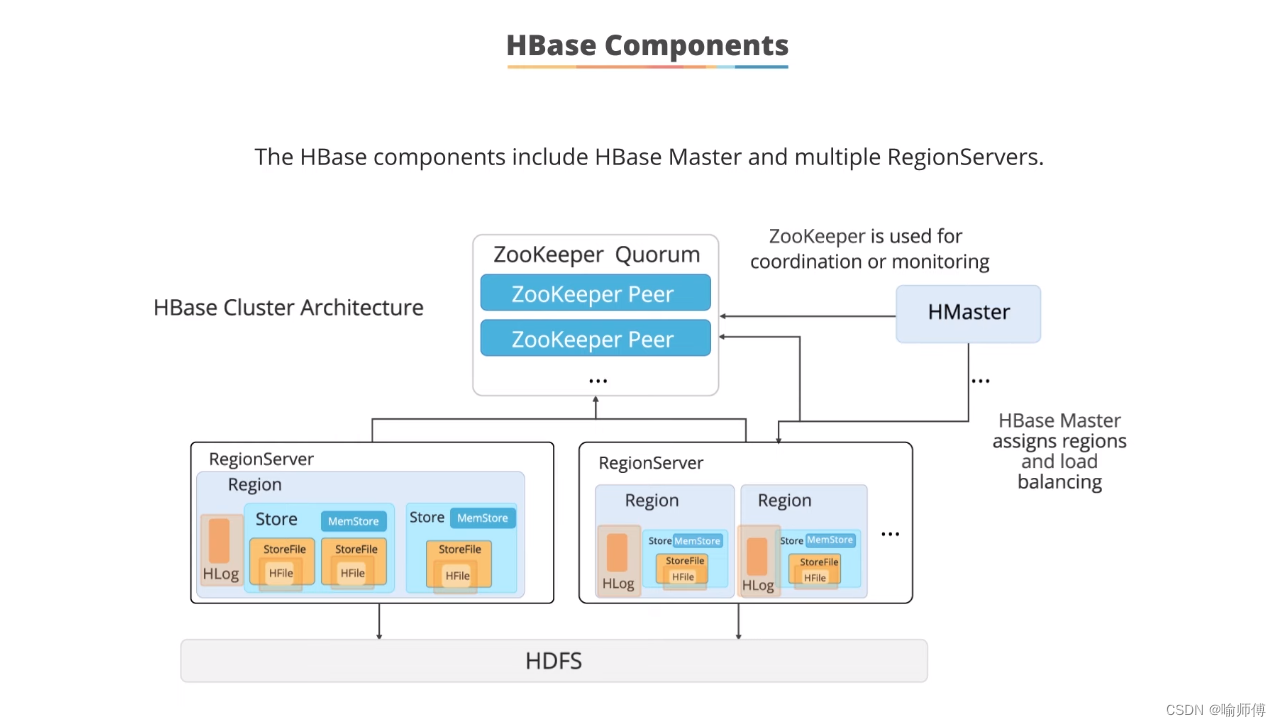
HBase的组件包括HBase Master和多个RegionServer。它的集群架构如下:
-
HBase Master:
- HBase的主节点,负责整个集群的管理和协调。
- 通过与ZooKeeper的通信来监控和管理RegionServer。
- 负责分配数据区域(Region)给不同的RegionServer,并进行负载均衡的操作。
-
RegionServer:
- 包含多个实例,每个实例称为一个RegionServer节点。
- 负责存储和处理实际的数据。
- 每个RegionServer可以托管多个数据区域(Region)。
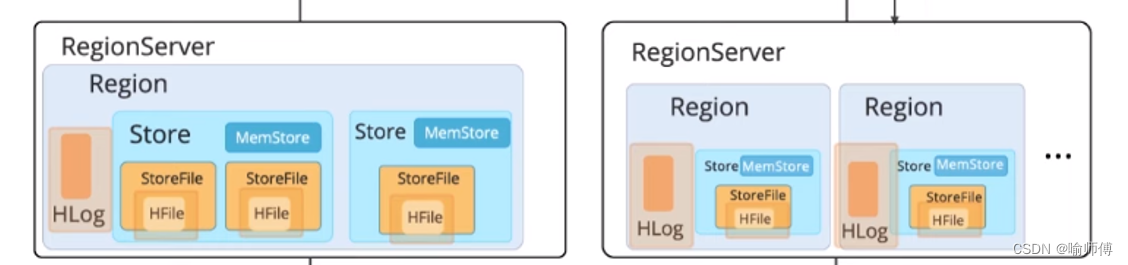
- 数据区域(Region)进一步包含数据存储单元(Store),每个Store包含存储文件(StoreFile)、内存存储(Memstore)和日志(HLog)等组件。
-
ZooKeeper:
- 用于协调和监控HBase集群的组件。
- 维护HBase集群中的元数据信息,如RegionServer的状态和分布情况。
-
HDFS:
- Hadoop分布式文件系统,作为HBase的底层存储层。
- 存储HBase表中的数据文件(HFile)和日志文件(HLog)。
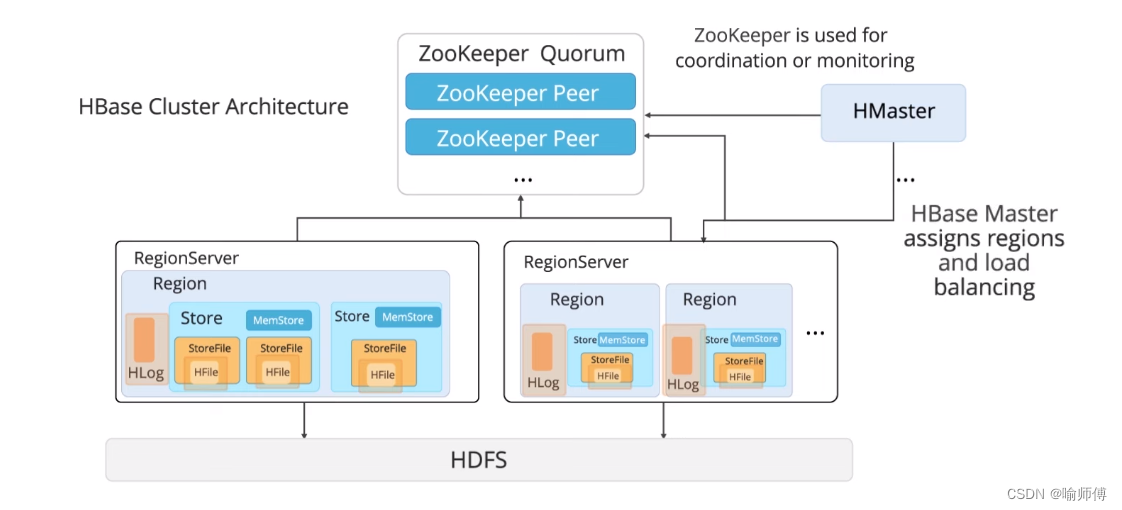
在HBase的架构中,Master节点和RegionServer节点通过ZooKeeper进行协调和通信,实现数据的高可用性和一致性。

Master节点负责管理集群的整体运行,包括Region的分配和负载均衡,而RegionServer节点则实际存储和处理数据,通过横向扩展来处理大规模数据和高并发访问的需求。
8.Storage Model of HBase
HBase的存储模型包括两个主要组成部分:分区和持久化及数据可用性。
- 分区:
- 分区是存储模型的一部分,用于水平划分表格成为多个区域(regions)。
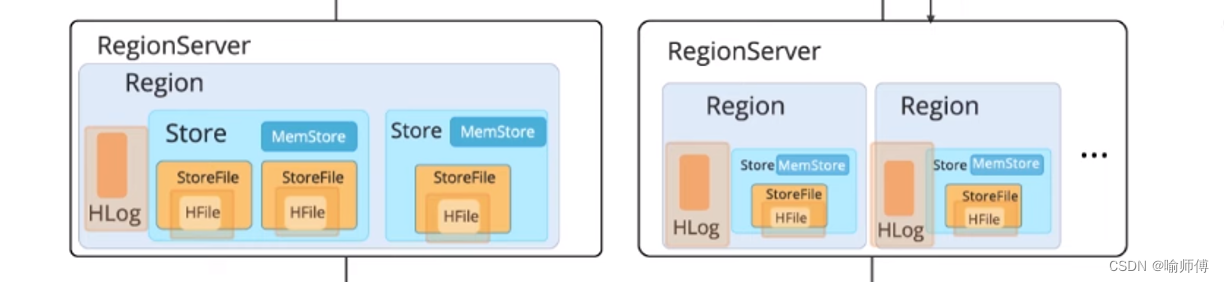
- 每个区域由一段连续的键范围组成,并由一个区域服务器(region server)管理。
- 区域服务器可以托管多个区域。
- 持久化及数据可用性:
-
数据存储在HDFS中:
-
HBase 将其数据存储在 Hadoop 分布式文件系统(HDFS)中。HDFS 提供了高可靠性、高扩展性和容错能力,非常适合存储大规模的数据。
-
依赖HDFS复制确保数据可用性:
-
HBase 依赖于 HDFS 的复制机制来确保数据的可用性和冗余。当数据写入 HBase 时,HDFS 负责将数据多次复制到不同的数据节点,以应对节点故障或数据损坏的情况,从而保证数据的可靠性和持久性。
-
区域服务器不进行复制:
-
HBase 中的区域服务器(region server)不进行复制。这意味着每个区域服务器负责管理一些区域(regions),这些区域是数据表水平分割后的部分。区域服务器负责处理对这些区域的读写请求。
-
Tips:
- 内存缓存(Memstore)
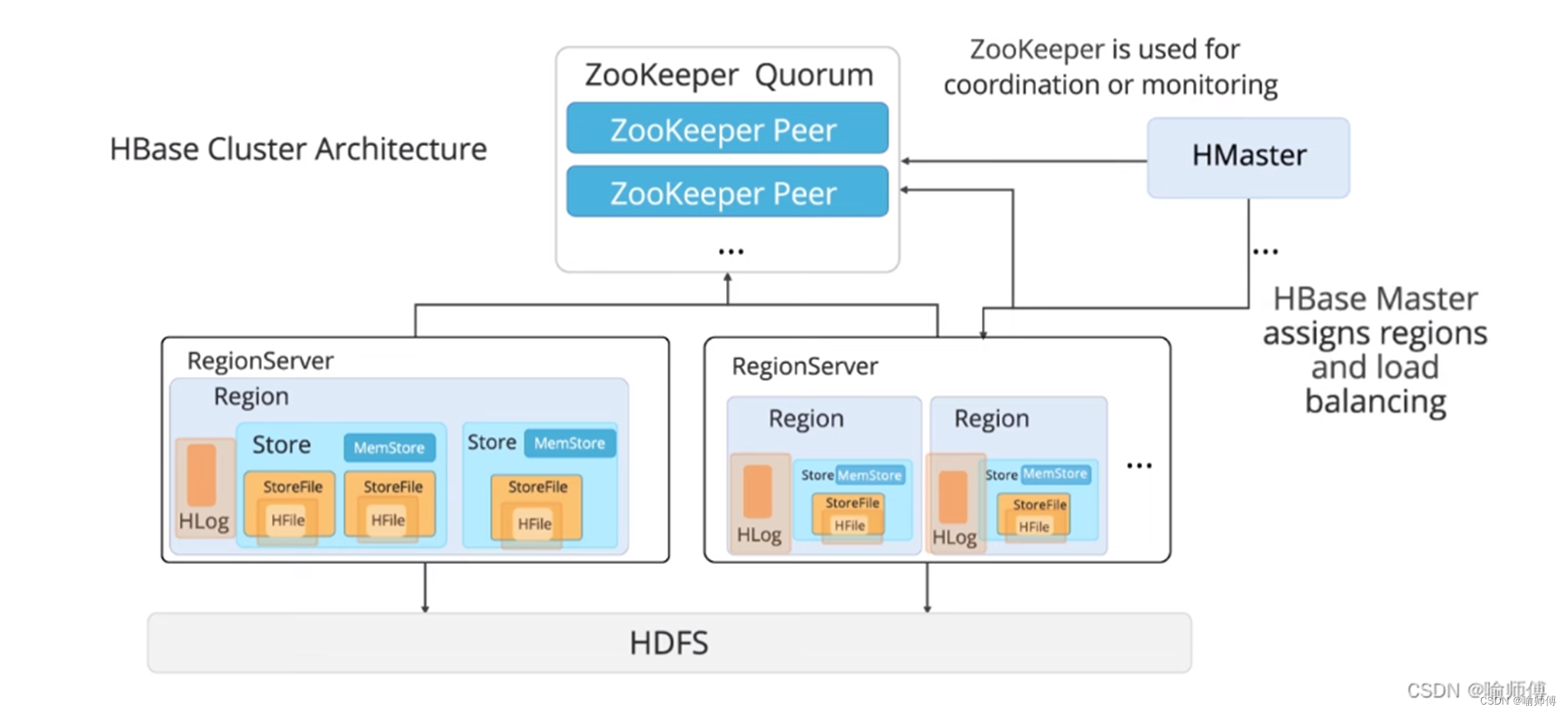
在 HBase 中,每个区域服务器(Region Server)维护内存中的一个 mem store,用于临时存储数据更新操作的结果。
当客户端发送写请求时,数据首先被写入到这个内存缓存中。这样做的主要目的是提高写入性能和响应速度,因为内存访问比磁盘访问要快得多。
流程:
-
写入操作: 当客户端发送写请求时,区域服务器将数据更新操作追加到内存中的 mem store 中。
-
读取操作: 读取请求首先检查 mem store 是否包含所需数据,如果有则直接返回,否则继续查找数据文件(如 HFiles)。
-
内存使用和管理: 内存中的 mem store 不是无限的,当达到预设阈值时,HBase 将会触发内存刷新操作(flush),将 mem store 中的数据持久化到磁盘上的 HFiles 中,以释放内存空间。
虽然 mem store 提供了高性能的写入和读取速度,但内存中的数据不是持久化的,如果区域服务器发生故障或重启,内存中的数据将会丢失。
为了解决这个问题,HBase 定期将 mem store 中的数据刷新到 HDFS 上的 HFiles 中,从而保证数据的持久性和可恢复性。
流程:
-
Flush 操作触发: 当 mem store 中的数据达到预定的阈值或者定期时间到达时,HBase 触发一个 flush 操作。
-
数据写入 HFiles: 在 flush 过程中,mem store 中的数据被写入到 HFiles 中,这些 HFiles 是持久化存储在 HDFS 上的文件,它们包含了最新的数据更新操作。
-
写入确认: 在将数据写入 HFiles 后,HBase 确认操作成功完成,并更新相应的元数据,以反映最新的数据状态。
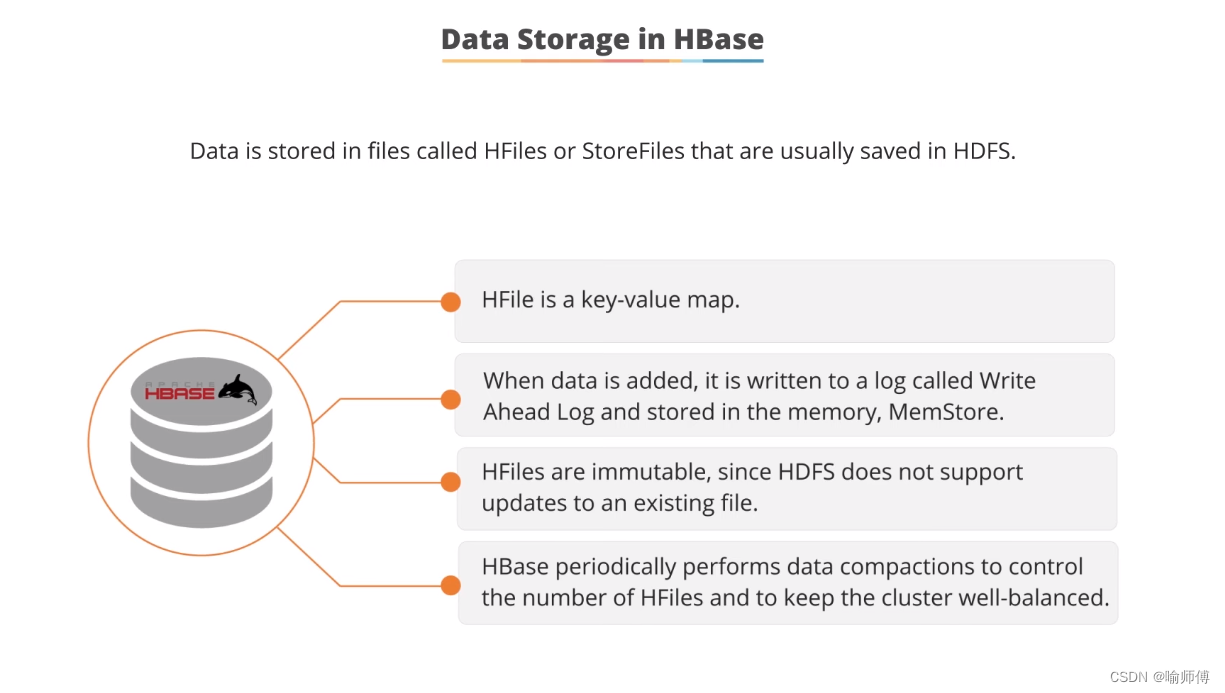
- WAL(Write-Ahead Log,预写式日志)的使用
WAL 是 HBase 用来确保数据更新操作持久性的关键机制。
所有的数据更新操作(如写入、更新、删除)首先被记录到 WAL 中,然后再写入 mem store。
这样做的目的是在发生系统崩溃或故障时,通过重新应用 WAL 中的记录来恢复数据,确保不会丢失已提交的更新操作。
流程:
-
数据更新操作: 当客户端发送写请求时,区域服务器首先将数据更新操作追加到 WAL 中。WAL 文件通常存储在 HDFS 上,这样可以保证数据在写入 mem store 之前已经持久化。
-
数据写入 mem store: 数据在写入 WAL 后,再被写入内存中的 mem store。这个过程中,如果区域服务器发生故障,数据可以通过重新应用 WAL 来恢复,确保数据的一致性和持久性。
-
WAL 的定期刷写: WAL 文件不会无限增长,HBase 定期将 WAL 文件刷写(flush)到磁盘上的永久存储中,以确保即使在系统崩溃时,也能最大程度地恢复数据。
HBase 通过内存缓存(mem store)、定期刷新到 HDFS 和 WAL 的结合使用,确保了高性能的数据写入和持久化存储,同时在系统故障或崩溃时能够快速恢复数据,保证了数据的一致性和可靠性。
9.Row Distribution of Data between Region Servers
-
数据分区和Region:
- 当你创建一个表(table)时,HBase会将其分成多个区域(regions),每个区域负责存储表中特定范围的行(rows)数据。
- 这些区域是按照表的行键(row key)的范围来划分的,通常是一段连续的行键范围分配给一个区域。
-
Region Server:
- 每个Region都会被分配到不同的Region Server上进行管理和存储。
- Region Server是HBase集群中的工作节点,负责处理和响应来自客户端的数据读写请求。
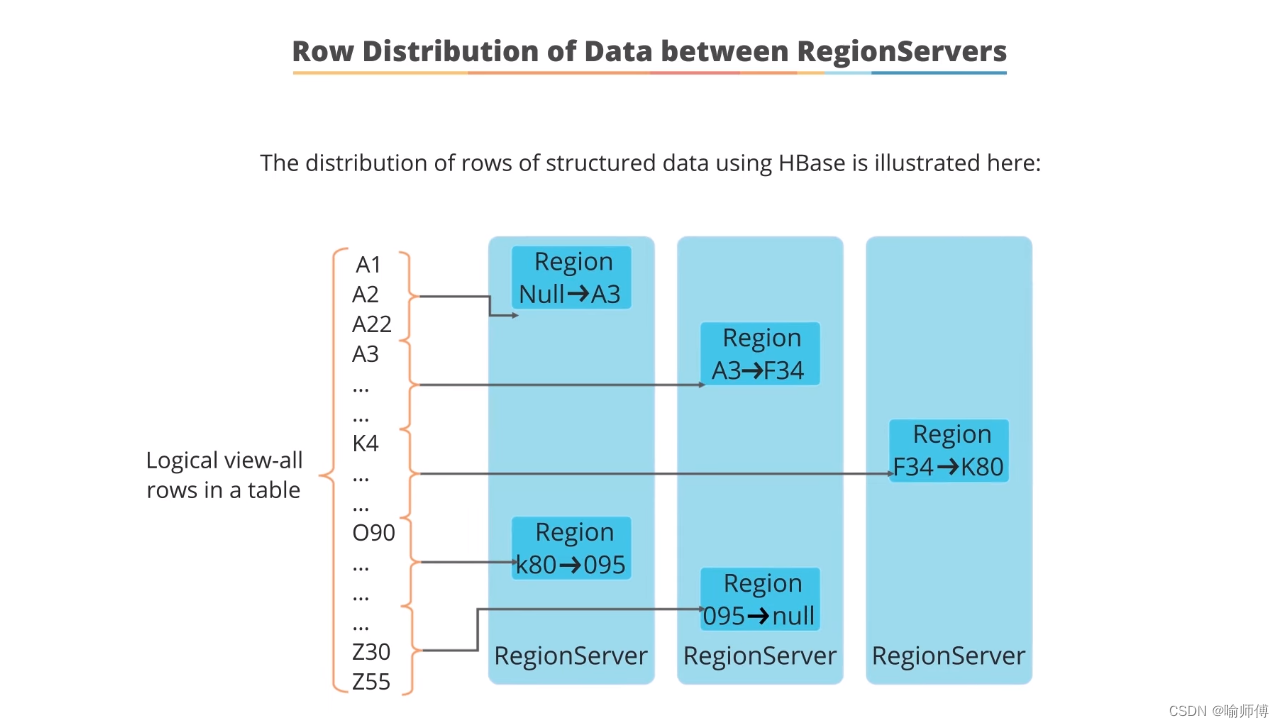
- 数据行的分布:
- 数据行(rows)在HBase中根据其行键(row key)进行分布和存储。
- 行键经过哈希处理后,决定了数据存储在哪个具体的Region中。这确保了相似行键的数据分布均匀,避免了热点(hotspotting)现象,即数据请求集中在少数几个Region上的情况。
10.Data Model
HBase的数据模型特点:
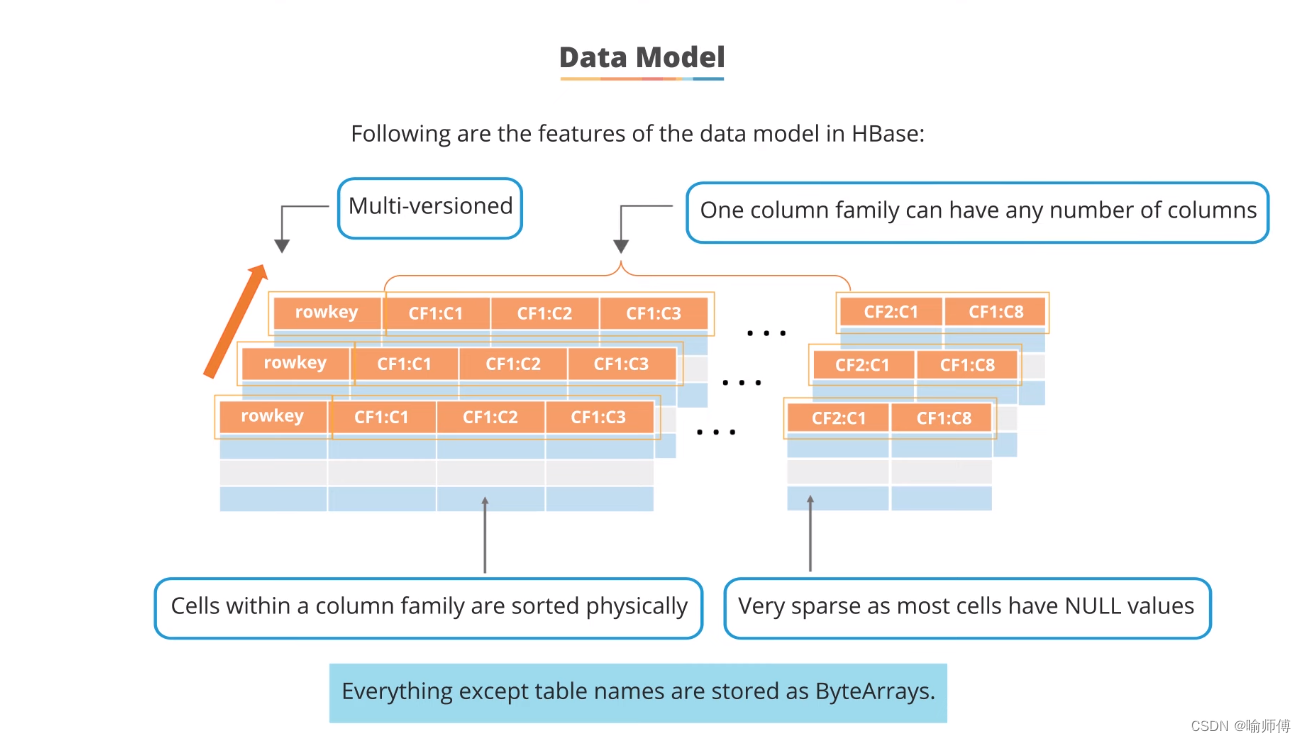
- 多版本支持:
- 每个行键(rowkey)可以存储多个版本的数据。这意味着同一个行键下的不同版本数据可以被保留和访问,每个版本可以带有时间戳来表示其存储时点。
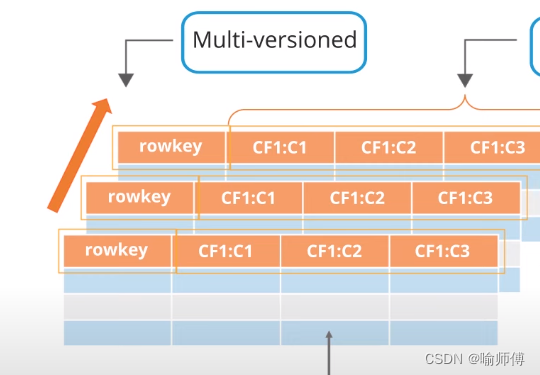
-
行键(rowkey)的作用:
- 行键是HBase中数据的唯一标识符,用于唯一标识每一行数据条目。它们通常设计为能够有效支持快速查询和分布式存储的方式。
-
列族和列:
- 数据存储在列族(Column Family)中,每个列族可以包含多个列。例如,列族 CF1 可以包含列 C1、C2 和 C3。
- 列族内的所有单元格(cells)都按照列名排序并物理存储在一起,这种存储方式有助于快速检索和访问相关数据。
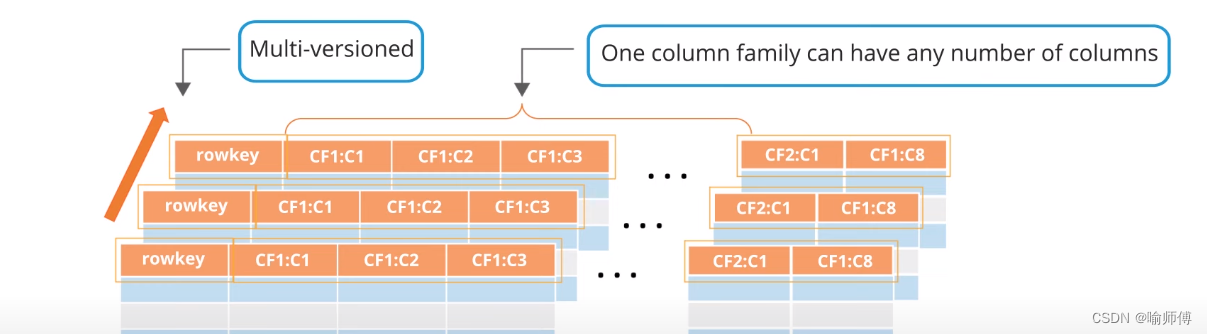
-
列族间的数据存储:
- 不同列族的数据是分开存储的,这种设计允许在不同的列族中存储不同类型或结构的数据,从而支持灵活的数据模型和查询需求。
-
稀疏数据特性:
- HBase中的数据通常非常稀疏,大部分单元格包含空值(NULL)。这是因为HBase设计用于大规模数据集,其中大多数情况下,每行数据只包含少量列的值,而其他列保持为空。
-
数据存储格式:
- HBase存储的所有数据,除了表名之外,都以字节数组(ByteArrays)的形式存储。这种存储格式的选择使得HBase能够支持多种数据类型和结构,从简单的文本到复杂的二进制数据。
-
列的重复性:
- 在不同的行中,同一个列可以重复出现,例如列族 CF2 中的列 C1。这种重复性允许存储和检索具有相似结构的数据,同时保持高效的存储和查询性能。
-
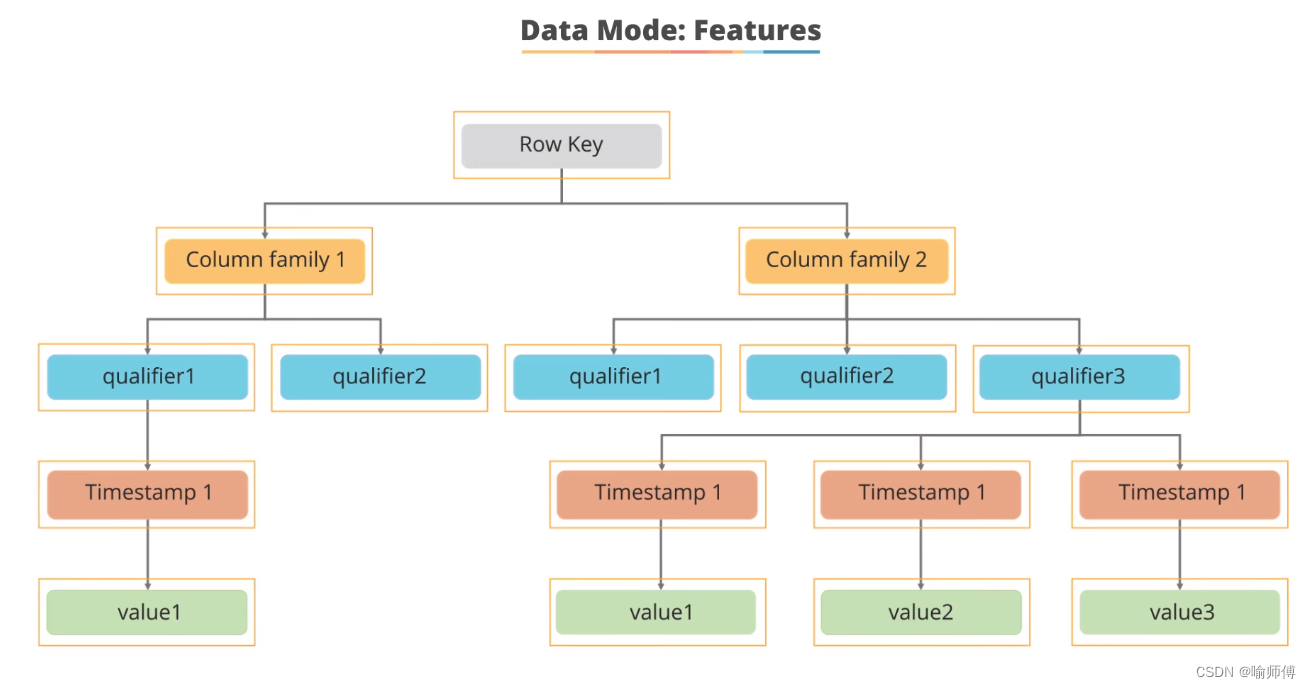
行键(Row Key)是唯一标识每行数据的键值。它用于在HBase表中快速定位和访问特定行的数据。
-
列族(Column Family)是逻辑上的分组单元,它可以包含多个列限定符。在这个示例中,数据被组织成两个列族:Column Family 1 和 Column Family 2。
-
列限定符(Qualifier)是列族中的具体列,用于存储数据的名称或标签。
-
版本(Version)是指数据在某个时间点上的不同值。HBase允许存储同一行键下同一列限定符的多个版本,每个版本都有一个关联的时间戳(
Timestamp),表示数据的写入时间。
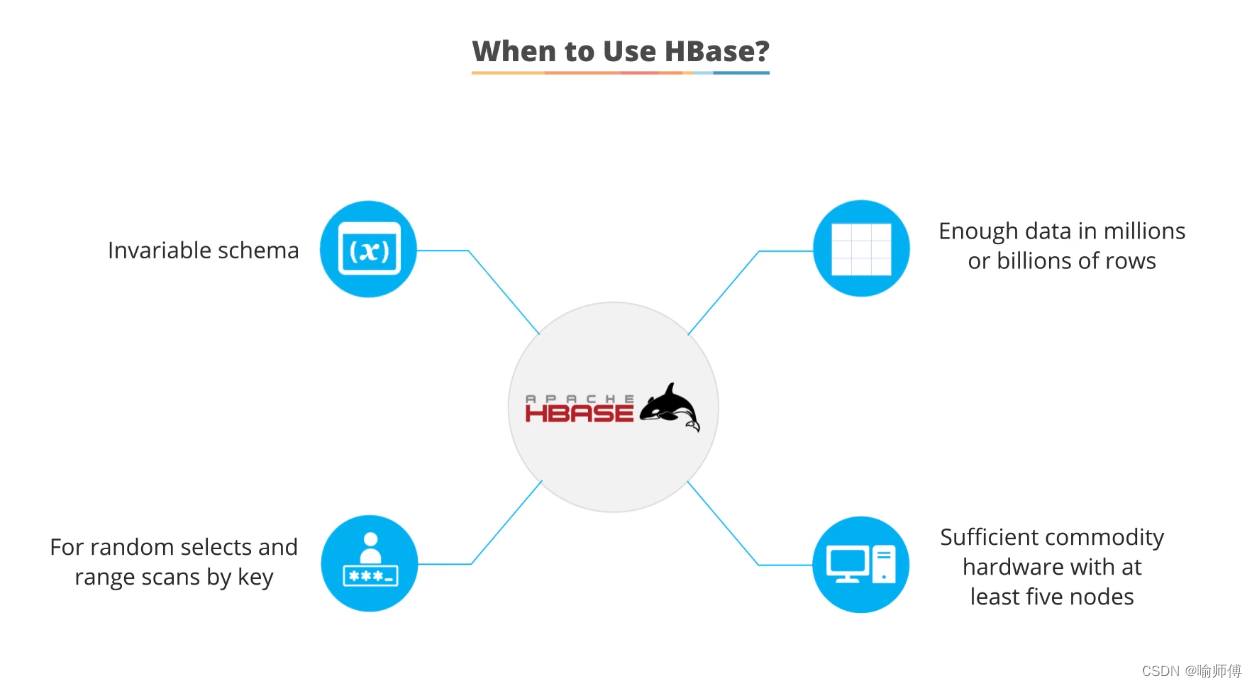
11.When to use HBase?
-
当数据模式灵活演变而无需严格约束时,适合使用HBase。
- Invariable schema: When the data schema can evolve flexibly over time without strict constraints, HBase is suitable.
-
适合处理数百万甚至数十亿行数据的场景,传统数据库可能无法处理。
- Enough data in millions or billions of rows: Suitable for scenarios that involve handling millions or even billions of rows of data, where traditional databases may struggle.
-
HBase在需要快速随机访问和按键范围扫描数据时表现出色。
- For random selects and range scans by key: HBase excels in scenarios where fast random access and range scans by key are required.
-
HBase设计用于在廉价硬件上运行,通常至少需要五个节点来形成集群。
- Sufficient commodity hardware with at least five nodes: HBase is designed to operate on commodity hardware, typically requiring at least five nodes to form a cluster.
12.HBase vs RDBMS
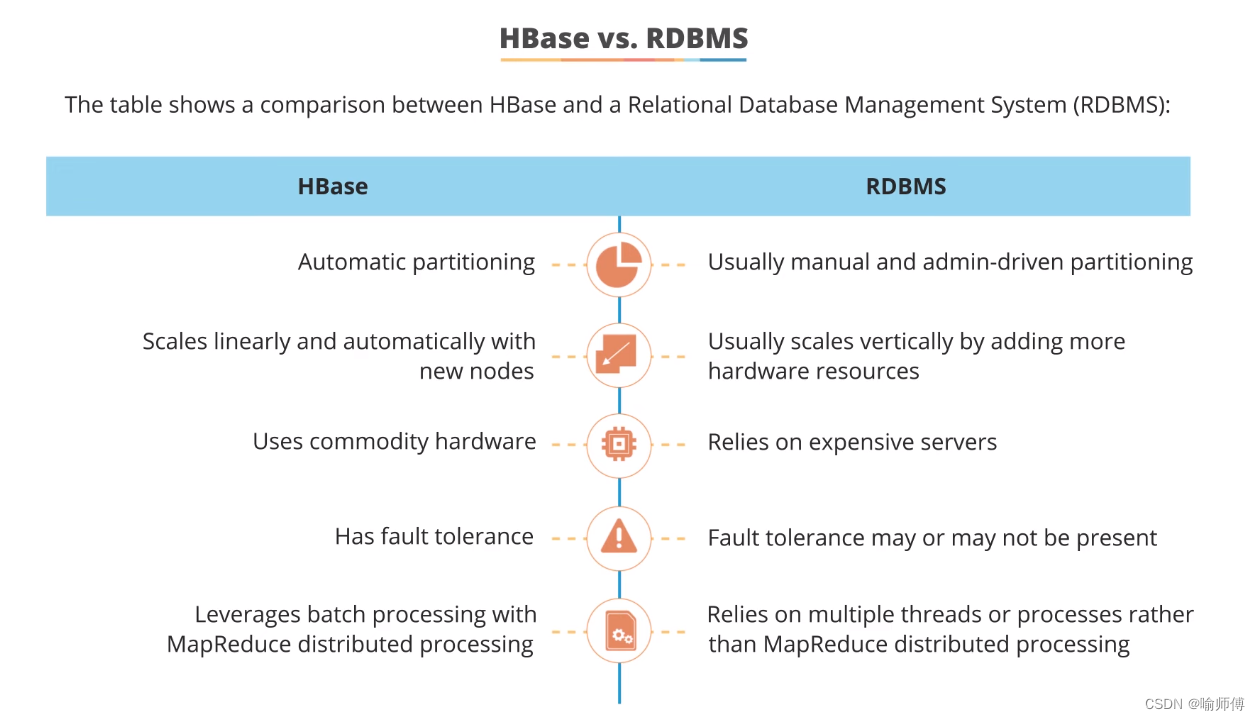
| 特点 | HBase | RDBMS |
|---|---|---|
| 自动分区 | Automatic partitioning | 通常需要手动分区 |
| 线性扩展和自动扩展新节点 | Scales linearly and automatically with new nodes | 通常通过添加更多硬件资源来垂直扩展 |
| 使用廉价硬件 | Uses commodity hardware | 依赖昂贵的服务器 |
| 具有容错性 | Has fault tolerance | 容错性可能存在也可能不存在 |
| 利用MapReduce分布式处理 | Leverages batch processing with MapReduce distributed processing | 利用多线程或进程而非MapReduce分布式处理 |
13.Connecting to HBase
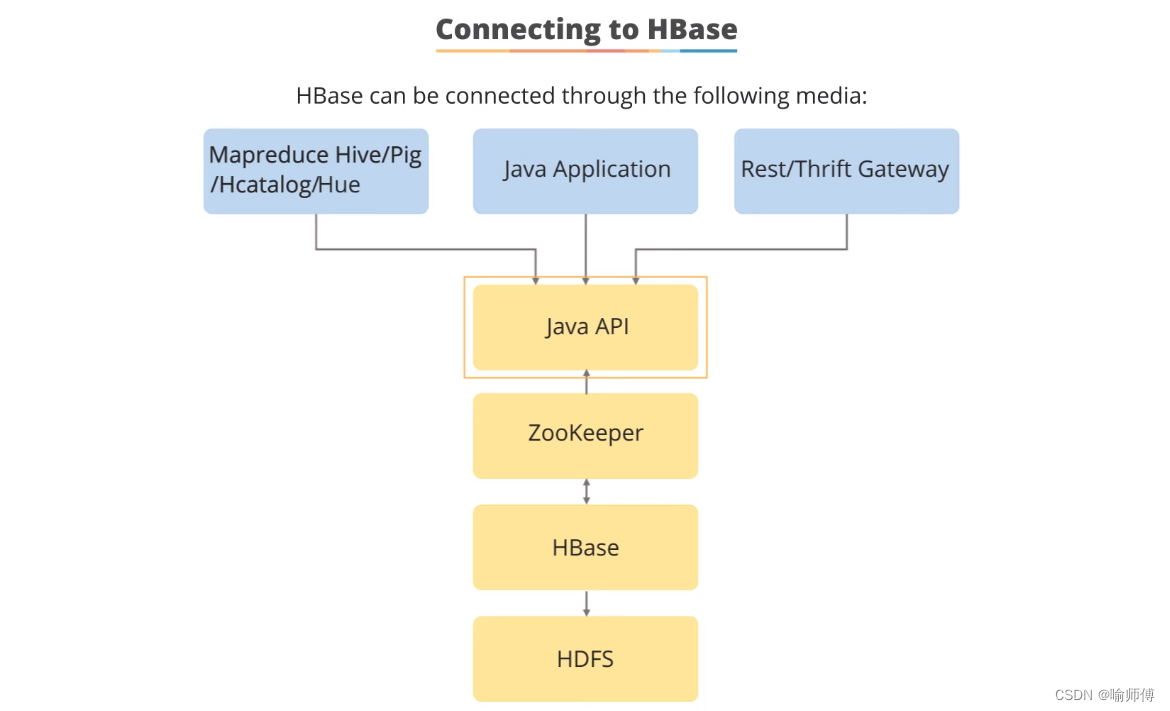
连接到HBase并进行通常操作(如get、scan、put和delete)的一些方式:
-
Java应用程序编程接口(API):用于通过Java应用程序执行操作,如get、scan、put和delete等。
-
Thrift和REST服务:非Java客户端可以使用这些服务来进行操作。
-
Hive、Pig、HCatalog或Hue:这些工具也可以用来执行操作,特别是通过命令行界面进行管理功能。
14.HBase Shell Commands

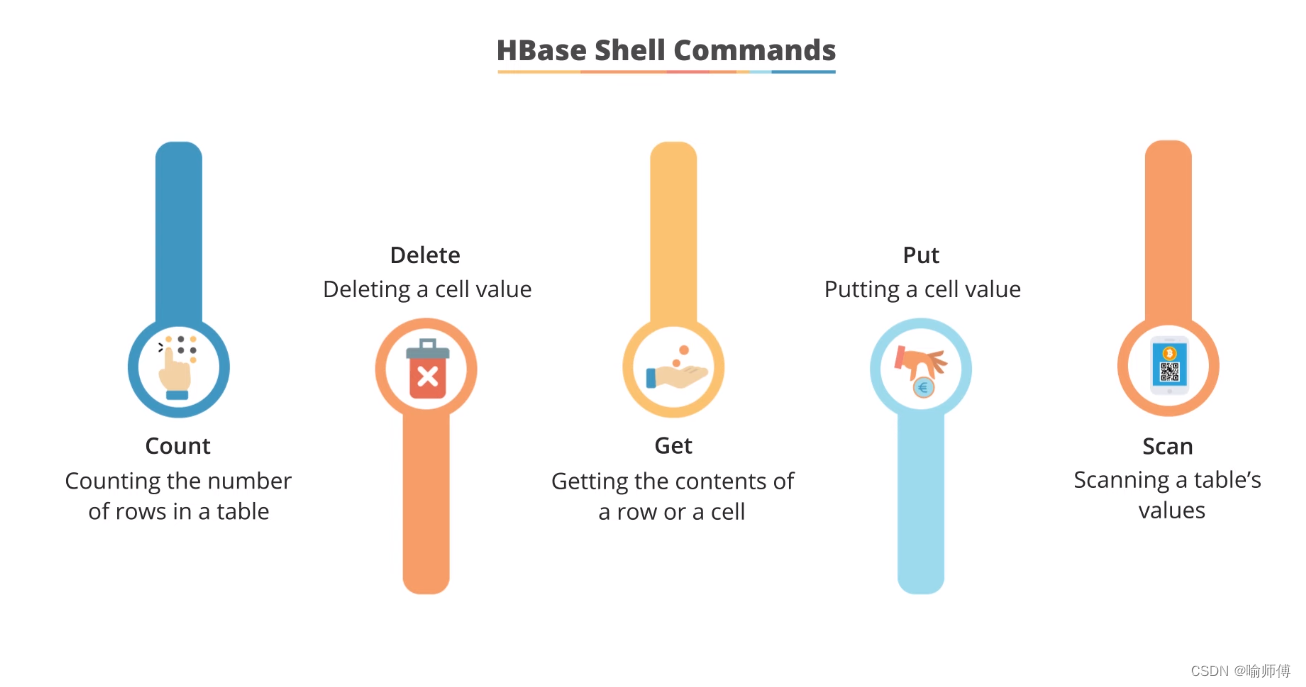
-
Create Table: 创建表
create 'tablename', 'columnfamily1', 'columnfamily2'创建一个名为
tablename的表,并定义列族columnfamily1和columnfamily2。 -
List Tables: 列出所有表
list列出所有已经存在的表。
-
Describe Table: 描述表结构
describe 'tablename'显示表
tablename的结构信息,包括列族和版本信息。 -
Put Data: 插入数据
put 'tablename', 'rowkey', 'columnfamily:column', 'value'在
tablename表中的rowkey行中插入指定列族和列的值。 -
Get Data: 获取数据
get 'tablename', 'rowkey'获取指定
tablename表中rowkey行的所有数据。 -
Scan Table: 扫描表
scan 'tablename'扫描并显示
tablename表中的所有行和列族。 -
Delete Data: 删除数据
delete 'tablename', 'rowkey', 'columnfamily:column', ts删除指定
tablename表中rowkey行中指定列族和列的数据,可以指定时间戳 (ts)。 -
Disable Table: 禁用表
disable 'tablename'禁用
tablename表,停止对其的写入和读取操作。 -
Enable Table: 启用表
enable 'tablename'启用
tablename表,允许对其进行写入和读取操作。 -
Drop Table: 删除表
drop 'tablename'删除
tablename表及其所有数据。



![Mathematica训练课(45)-- 一些常用的函数Abs[],Max[]等函数用法](https://img-blog.csdnimg.cn/direct/9c79c770c8fd4304822e3b34c42e9d29.png)