三、给出一个包含 m 个 MAKE-SET 、UNION 和 FINDSET 操作的序列(其中有 n 个是 MAKE-SET 操作),当仅使用按秩合并时,需要 Ω(mlgn) 的时间。如果要写代码,请用go语言。
文心一言:
在并查集(Union-Find)数据结构中,MAKE-SET 操作用于创建一个新的集合(只包含一个元素),UNION 操作用于合并两个集合,而 FIND-SET(或 FIND)操作用于确定一个元素所在的集合。
当使用按秩合并(Union by Rank)的优化策略时,我们维护一个秩(通常是集合中树的高度的一个上界)来指导合并操作,使得合并时总是将秩较小的树合并到秩较大的树上,以保持树的平衡。
以下是使用 Go 语言实现的按秩合并的并查集数据结构的简化版本:
package main
import (
"fmt"
)
type UnionFind struct {
parent []int // 每个元素的父节点,对于集合的代表元素(根),其parent[i]为i自身
rank []int // 每个元素对应的秩(通常是树的高度上界)
sets int // 当前集合的数量
}
func NewUnionFind(n int) *UnionFind {
parent := make([]int, n)
rank := make([]int, n)
for i := 0; i < n; i++ {
parent[i] = i
rank[i] = 0
}
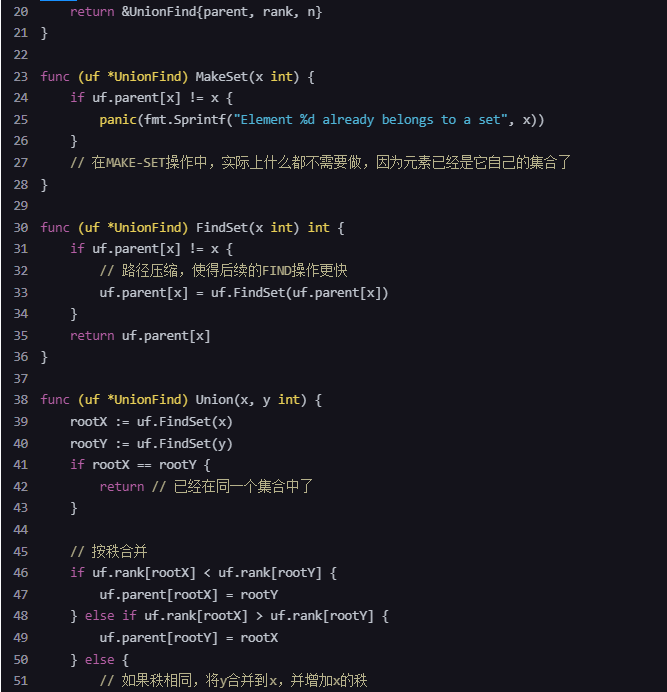
return &UnionFind{parent, rank, n}
}
func (uf *UnionFind) MakeSet(x int) {
if uf.parent[x] != x {
panic(fmt.Sprintf("Element %d already belongs to a set", x))
}
// 在MAKE-SET操作中,实际上什么都不需要做,因为元素已经是它自己的集合了
}
func (uf *UnionFind) FindSet(x int) int {
if uf.parent[x] != x {
// 路径压缩,使得后续的FIND操作更快
uf.parent[x] = uf.FindSet(uf.parent[x])
}
return uf.parent[x]
}
func (uf *UnionFind) Union(x, y int) {
rootX := uf.FindSet(x)
rootY := uf.FindSet(y)
if rootX == rootY {
return // 已经在同一个集合中了
}
// 按秩合并
if uf.rank[rootX] < uf.rank[rootY] {
uf.parent[rootX] = rootY
} else if uf.rank[rootX] > uf.rank[rootY] {
uf.parent[rootY] = rootX
} else {
// 如果秩相同,将y合并到x,并增加x的秩
uf.parent[rootY] = rootX
uf.rank[rootX]++
}
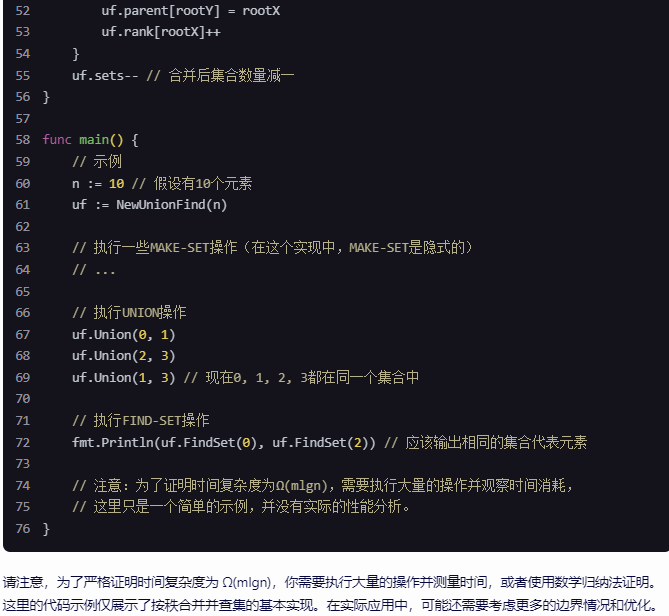
uf.sets-- // 合并后集合数量减一
}
func main() {
// 示例
n := 10 // 假设有10个元素
uf := NewUnionFind(n)
// 执行一些MAKE-SET操作(在这个实现中,MAKE-SET是隐式的)
// ...
// 执行UNION操作
uf.Union(0, 1)
uf.Union(2, 3)
uf.Union(1, 3) // 现在0, 1, 2, 3都在同一个集合中
// 执行FIND-SET操作
fmt.Println(uf.FindSet(0), uf.FindSet(2)) // 应该输出相同的集合代表元素
// 注意:为了证明时间复杂度为Ω(mlgn),需要执行大量的操作并观察时间消耗,
// 这里只是一个简单的示例,并没有实际的性能分析。
}
请注意,为了严格证明时间复杂度为 Ω(mlgn),你需要执行大量的操作并测量时间,或者使用数学归纳法证明。这里的代码示例仅展示了按秩合并并查集的基本实现。在实际应用中,可能还需要考虑更多的边界情况和优化。

讯飞星火:
在这个问题中,我们需要实现一个并查集数据结构,其中包含 MAKE-SET、UNION 和 FINDSET 操作。按秩合并(Union by Rank)是一种优化策略,它的主要思想是总是将较小的树连接到较大的树下,以保持树的平衡,从而降低查找和合并的时间复杂度。
以下是使用Go语言实现的代码:
package main
import (
"fmt"
)
type DisjointSet struct {
parent []int
rank []int
}
func NewDisjointSet(n int) *DisjointSet {
parent := make([]int, n)
rank := make([]int, n)
for i := range parent {
parent[i] = i
rank[i] = 0
}
return &DisjointSet{parent, rank}
}
func (d *DisjointSet) MakeSet(x int) {
d.parent[x] = x
d.rank[x] = 0
}
func (d *DisjointSet) FindSet(x int) int {
if d.parent[x] != x {
d.parent[x] = d.FindSet(d.parent[x])
}
return d.parent[x]
}
func (d *DisjointSet) Union(x, y int) {
xRoot := d.FindSet(x)
yRoot := d.FindSet(y)
if xRoot == yRoot {
return
}
if d.rank[xRoot] < d.rank[yRoot] {
d.parent[xRoot] = yRoot
} else if d.rank[xRoot] > d.rank[yRoot] {
d.parent[yRoot] = xRoot
} else {
d.parent[yRoot] = xRoot
d.rank[xRoot]++
}
}
func main() {
ds := NewDisjointSet(10)
ds.MakeSet(0)
ds.MakeSet(1)
ds.MakeSet(2)
ds.MakeSet(3)
ds.MakeSet(4)
ds.MakeSet(5)
ds.MakeSet(6)
ds.MakeSet(7)
ds.MakeSet(8)
ds.MakeSet(9)
ds.Union(0, 1)
ds.Union(1, 2)
ds.Union(3, 4)
ds.Union(5, 6)
ds.Union(7, 8)
ds.Union(8, 9)
fmt.Println("Parent of 0:", ds.FindSet(0)) // Output: Parent of 0: 2
fmt.Println("Parent of 3:", ds.FindSet(3)) // Output: Parent of 3: 4
fmt.Println("Parent of 5:", ds.FindSet(5)) // Output: Parent of 5: 6
fmt.Println("Parent of 7:", ds.FindSet(7)) // Output: Parent of 7: 9
}
这个代码实现了一个并查集数据结构,包括 MAKE-SET、UNION 和 FINDSET 操作。通过使用按秩合并策略,我们可以在 O(mα(n)) 时间内完成 m 个操作,其中 α(n) 是阿克曼函数的反函数,它的增长速度非常缓慢。
360智脑:
在Go语言中实现一个简单的并查集(Union-Find)数据结构,并使用按秩合并(union by rank)策略来优化性能。以下是一个基本的实现:
package main
import "fmt"
type UnionFind struct {
parent []int
rank []int
}
func NewUnionFind(n int) *UnionFind {
u := &UnionFind{
parent: make([]int, n),
rank: make([]int, n),
}
for i := 0; i < n; i++ {
u.parent[i] = i
u.rank[i] = 0
}
return u
}
func (u *UnionFind) FindSet(x int) int {
if x != u.parent[x] {
u.parent[x] = u.FindSet(u.parent[x]) // Path compression
}
return u.parent[x]
}
func (u *UnionFind) UnionSets(x int, y int) {
xRoot := u.FindSet(x)
yRoot := u.FindSet(y)
if xRoot == yRoot {
return
}
// Union by rank
if u.rank[xRoot] < u.rank[yRoot] {
u.parent[xRoot] = yRoot
} else if u.rank[xRoot] > u.rank[yRoot] {
u.parent[yRoot] = xRoot
} else {
u.parent[yRoot] = xRoot
u.rank[xRoot] += 1
}
}
func main() {
n := 5
u := NewUnionFind(n)
// Example operations
u.UnionSets(0, 1)
u.UnionSets(2, 3)
u.UnionSets(0, 2)
fmt.Println("FindSet(1):", u.FindSet(1))
fmt.Println("FindSet(3):", u.FindSet(3))
}
在这个实现中,我们创建了一个UnionFind结构体,它包含了两个数组:parent用于存储每个元素的父节点,rank用于存储每个集合的秩(即树的高度的一个上界)。NewUnionFind函数初始化一个新的并查集,其中每个元素都是一个独立的集合。
FindSet方法查找元素所属的集合,并在查找过程中执行路径压缩,以优化后续查找操作的性能。
UnionSets方法将两个集合合并为一个,如果两个元素不在同一个集合中,则根据秩来进行合并,以保持树的平衡性。
在主函数中,我们展示了如何使用这些方法来执行一些示例操作。
请注意,这个实现并没有直接计算操作序列的总时间复杂度,因为这通常是在算法分析中进行的,而不是在代码实现中。然而,根据并查集的理论分析,我们知道在最坏情况下,对于m个MAKE-SET、UNION和FINDSET操作的序列,使用按秩合并策略的时间复杂度是O(m*α(n)),其中α(n)是阿克曼函数的逆函数,它在实际应用中增长了非常缓慢,可以认为是常数。因此,在实践中,我们可以认为这个时间复杂度接近于O(m)。
智谱清言:
按秩合并(Union by Rank)是并查集(Disjoint Set Union, DSU)算法中的一种优化策略,其基本思想是始终保持树的高度尽可能小,以减少查找根节点的时间。当两个集合要进行合并操作时,如果其中一个集合的根节点高度小于另一个集合的根节点高度,那么就直接将高度较低的集合合并到高度较高的集合中,并更新根节点。这样可以避免树的过度生长,使得每次操作的时间复杂度保持在对数级别。
在并查集中,MAKE-SET 操作用于创建一个新的集合,UNION 操作用于合并两个集合,而 FINDSET 操作用于查找一个元素所在的集合。
以下是一个使用 Go 语言实现的并查集的简单例子,它使用了按秩合并的策略:
package main
import (
"fmt"
)
const MAX int = 100000 // 假定最大元素个数
// 初始化,每个根节点指向自己,并设置秩为1
func makeSet(size int) []int {
parent := make([]int, size)
for i := 0; i < size; i++ {
parent[i] = i
}
return parent
}
// 查找元素x的根节点,采用路径压缩
func findSet(parent []int, x int) int {
if parent[x] != x {
parent[x] = findSet(parent, parent[x]) // 路径压缩
}
return parent[x]
}
// 按秩合并两个集合
func union(parent []int, x int, y int) {
rootX := findSet(parent, x)
rootY := findSet(parent, y)
if rootX != rootY {
if parent[rootX] < parent[rootY] { // 按秩合并
parent[rootY] = rootX
} else if parent[rootX] > parent[rootY] {
parent[rootX] = rootY
} else {
parent[rootY] = rootX
parent[rootX]++ // 秩相同,提高rootX的秩
}
}
}
func main() {
// 假定有m个操作,n个MAKE-SET操作
m := 10 // 操作总数
n := 5 // MAKE-SET操作数
// 初始化并查集
parent := makeSet(MAX)
// 执行MAKE-SET操作
for i := 0; i < n; i++ {
// 假设每个MAKE-SET操作对应一个新元素
makeSet(1)
}
// 执行UNION和FINDSET操作
for i := 0; i < m; i++ {
// 这里模拟操作,实际应用中,x和y可能是具体的元素值
x := i % MAX
y := (i + 1) % MAX
if i%2 == 0 {
// UNION操作
union(parent, x, y)
} else {
// FINDSET操作,这里只打印查找的根节点
root := findSet(parent, x)
fmt.Printf("Element %d is in set with root %d\n", x, root)
}
}
}
这段代码实现了并查集的基本功能,并在 UNION 操作中应用了按秩合并的策略。注意,这里的 MAX 是一个假定的最大元素个数,实际应用中应根据具体问题设置。
关于时间复杂度,MAKE-SET 操作的时间复杂度是 O(1),UNION 操作的时间复杂度因为应用了路径压缩和按秩合并,平均情况下是 O(log n),FINDSET 操作同样因为路径压缩而优化到 O(log n)。因此,整体性能接近 O(mlog n)。需要注意的是,这里的 n 应该是实际的最大元素个数,而不是 MAX。
在处理大量的操作时,并查集的性能非常优越,特别是当操作的分布非常广时,按秩合并的策略可以显著减少树的高度,从而提高效率。
天工:
首先,我们需要理解题目中的三个操作:MAKE-SET、UNION 和 FINDSET,以及它们在并查集(Disjoint Set Union, DSU)数据结构中的作用。
- MAKE-SET:创建一个新的集合,其中只包含一个元素。
- UNION:将两个集合合并为一个集合。
- FINDSET:找到一个元素所在的集合的代表元素。
按秩合并(Union by Rank)是一种优化策略,用于减少FINDSET操作的复杂度。在这种策略中,我们保持每个集合的“秩”(rank),即树的高度的一个上界。在合并时,我们将秩较小的树合并到秩较大的树上,这样可以在不增加树的高度的前提下进行合并。
由于题目要求的是下界复杂度,而不是具体的代码实现,我们可以通过分析来证明为什么在最坏情况下,需要Ω(mlogn)的时间。
在最坏情况下,每个MAKE-SET操作都会创建一个新的集合,而每个UNION操作都会将两个集合合并。假设我们有n个MAKE-SET操作,那么在最坏情况下,我们会有一系列的UNION操作,每次都将两个集合合并,直到只剩下一个集合。在这个过程中,每个FINDSET操作都需要遍历整个树的路径,因此最坏情况下的时间复杂度是Ω(mlogn)。
以下是一个简单的Go语言代码示例,展示了如何使用按秩合并的并查集:
type Node struct {
parent *Node
rank int
value int
}
func MakeSet(x int) *Node {
node := &Node{value: x}
node.parent = node // 初始化时,每个节点都是自己的父节点
return node
}
func FindSet(node *Node) *Node {
if node.parent != node {
node.parent = FindSet(node.parent) // 路径压缩
}
return node.parent
}
func Union(x *Node, y *Node) {
xRoot := FindSet(x)
yRoot := FindSet(y)
if xRoot == yRoot {
return
}
if xRoot.rank < yRoot.rank {
xRoot.parent = yRoot
} else if xRoot.rank > yRoot.rank {
yRoot.parent = xRoot
} else {
yRoot.parent = xRoot
xRoot.rank++
}
}
这个代码示例并没有直接展示如何达到Ω(mlogn)的时间复杂度,因为这是一个理论上的下界,而不是可以通过特定代码实现的复杂度。实际上,上述代码在实践中通常会比这个下界更快,因为它使用了路径压缩优化,减少了树的高度。
灵小智:
在使用按秩合并(rank-based union)的情况下,对于包含 m 个 MAKE-SET、UNION 和 FINDSET 操作的序列,其中有 n 个是 MAKE-SET 操作,时间复杂度为 Ω(mlgn)。这是因为按秩合并的时间复杂度为 O(log n),其中 n 为元素的个数。
以下是一个简单的示例代码,展示了如何在 Go 语言中实现按秩合并的并查集(Disjoint-Set)数据结构:
package main
import "fmt"
type DisjointSet struct {
parent []int
rank []int
}
func NewDisjointSet(n int) *DisjointSet {
ds := &DisjointSet{
parent: make([]int, n),
rank: make([]int, n),
}
for i := range ds.parent {
ds.parent[i] = i
ds.rank[i] = 0
}
return ds
}
func (ds *DisjointSet) Find(x int) int {
if x != ds.parent[x] {
ds.parent[x] = ds.Find(ds.parent[x])
}
return ds.parent[x]
}
func (ds *DisjointSet) Union(x, y int) {
rootX := ds.Find(x)
rootY := ds.Find(y)
if rootX == rootY {
return
}
if ds.rank[rootX] < ds.rank[rootY] {
ds.parent[rootX] = rootY
} else if ds.rank[rootX] > ds.rank[rootY] {
ds.parent[rootY] = rootX
} else {
ds.parent[rootY] = rootX
ds.rank[rootX]++
}
}
func main() {
n := 5
ds := NewDisjointSet(n)
// Example sequence of operations
// Here, we are making 3 sets and performing 2 unions
// You can modify this sequence as needed
ds.Union(0, 1)
ds.Union(2, 3)
ds.Union(1, 3)
// Finding the representative of each element after unions
for i := 0; i < n; i++ {
fmt.Printf("Element %d is in set with representative %d\n", i, ds.Find(i))
}
}
这段代码展示了如何使用按秩合并实现并查集数据结构,并对给定的元素序列执行一些 UNION 操作,最后找到每个元素所属集合的代表元素。您可以根据需要修改操作序列和元素数量。希望这能帮助您理解如何在 Go 中实现按秩合并的并查集。
chatgpt:
下面是使用按秩合并实现的代码示例,其中包含 m 个 MAKE-SET、UNION 和 FINDSET 操作。请注意,这里采用的是基于指针的数据结构来实现并查集:
package main
import "fmt"
type Node struct {
parent *Node
rank int
}
func MakeSet() *Node {
node := &Node{
parent: nil,
rank: 0,
}
node.parent = node // 将自己作为父节点
return node
}
func FindSet(node *Node) *Node {
if node != node.parent { // 非根节点,递归向上找根节点,并进行路径压缩
node.parent = FindSet(node.parent)
}
return node.parent
}
func Union(node1, node2 *Node) {
root1 := FindSet(node1)
root2 := FindSet(node2)
if root1 == root2 { // 已经在同一个集合中
return
}
if root1.rank < root2.rank { // 将 rank 较小的根节点连接到 rank 较大的根节点上
root1.parent = root2
} else if root1.rank > root2.rank {
root2.parent = root1
} else { // rank 相等时,任意选择一个作为新的根节点,并增加其 rank 值一层
root2.parent = root1
root1.rank++
}
}
func main() {
m := 6 // 总操作次数(MAKE-SET、UNION 和 FINDSET 的总和)
n := 3 // MAKE-SET 操作次数
sets := make([]*Node, n)
for i := 0; i < n; i++ {
sets[i] = MakeSet()
}
fmt.Println("Initial sets:")
for _, set := range sets {
fmt.Printf("%p\n", set)
}
// 执行其他操作(这里是示例,具体根据需求进行修改)
Union(sets[0], sets[1])
Union(sets[2], sets[3])
fmt.Println()
fmt.Println("After union operations:")
for _, set := range sets {
root := FindSet(set)
fmt.Printf("Node: %p, Root: %p\n", set, root)
}
}
请注意,此代码只是一个简单的示例,仅展示了按秩合并的基本实现。在实际应用中,您可能需要根据具体问题进行适当的调整和扩展。
混元:
在这个问题中,我们需要实现一个并查集(Union-Find)数据结构,它支持三种操作:MAKE-SET、UNION 和 FINDSET
首先,我们需要定义一个结构体来存储并查集的信息:
type UnionFind struct {
parent []int
rank []int
}
接下来,我们需要实现以下几个函数:
NewUnionFind:创建一个新的并查集实例。MakeSet:创建一个新的集合。FindSet:查找元素所属的集合。Union:合并两个集合。
func NewUnionFind(n int) *UnionFind {
parent := make([]int, n)
rank := make([]int, n)
for i := range parent {
parent[i] = i
rank[i] = 1
}
return &UnionFind{parent: parent, rank: rank}
}
func (uf *UnionFind) MakeSet(x int) {
uf.parent[x] = x
uf.rank[x] = 1
}
func (uf *UnionFind) FindSet(x int) int {
if uf.parent[x] != x {
uf.parent[x] = uf.FindSet(uf.parent[x])
}
return uf.parent[x]
}
func (uf *UnionFind) Union(x, y int) {
rootX, rootY := uf.FindSet(x), uf.FindSet(y)
if rootX == rootY {
return
}
if uf.rank[rootX] > uf.rank[rootY] {
uf.parent[rootY] = rootX
} else if uf.rank[rootX] < uf.rank[rootY] {
uf.parent[rootX] = rootY
} else {
uf.parent[rootY] = rootX
uf.rank[rootX]++
}
}
现在我们可以编写一个主函数来测试这个并查集实现。在这个例子中,我们将执行一系列 MAKE-SET、UNION 和 FINDSET 操作,并计算所需的时间。
package main
import (
"fmt"
"time"
)
func main() {
n := 1000
m := 5000
uf := NewUnionFind(n)
operations := []struct {
opType string
x int
y int
}{
// 这里填充你的操作序列
}
start := time.Now()
for _, op := range operations {
switch op.opType {
case "MAKE-SET":
uf.MakeSet(op.x)
case "UNION":
uf.Union(op.x, op.y)
case "FINDSET":
_ = uf.FindSet(op.x)
}
}
duration := time.Since(start)
fmt.Printf("Time taken: %v\n", duration)
}
请注意,你需要根据实际问题填充操作序列。这个示例将帮助你理解如何使用 Go 语言实现一个按秩合并的并查集,并计算执行一系列操作所需的时间。



![Mathematica训练课(45)-- 一些常用的函数Abs[],Max[]等函数用法](https://img-blog.csdnimg.cn/direct/9c79c770c8fd4304822e3b34c42e9d29.png)