前提
最近在看Reduce(归约)的相关知识和代码,做个总结。这里默认大家已经明白了Reduce的基础概念。
Reduce
根据参考链接一,Recude常见的划分方法有两种:
-
相邻配对:元素和它们相邻的元素配对

-
交错配对:元素与一定距离的元素配对

相关代码
相邻匹配——CPU
相邻匹配的代码有两个值得注意的地方,一个是在这一次递归中我们要循环多少次,另一个是在循环中我们如何确定下标。下面这段代码已经经过验证,大家可以对照这个图方便理解。
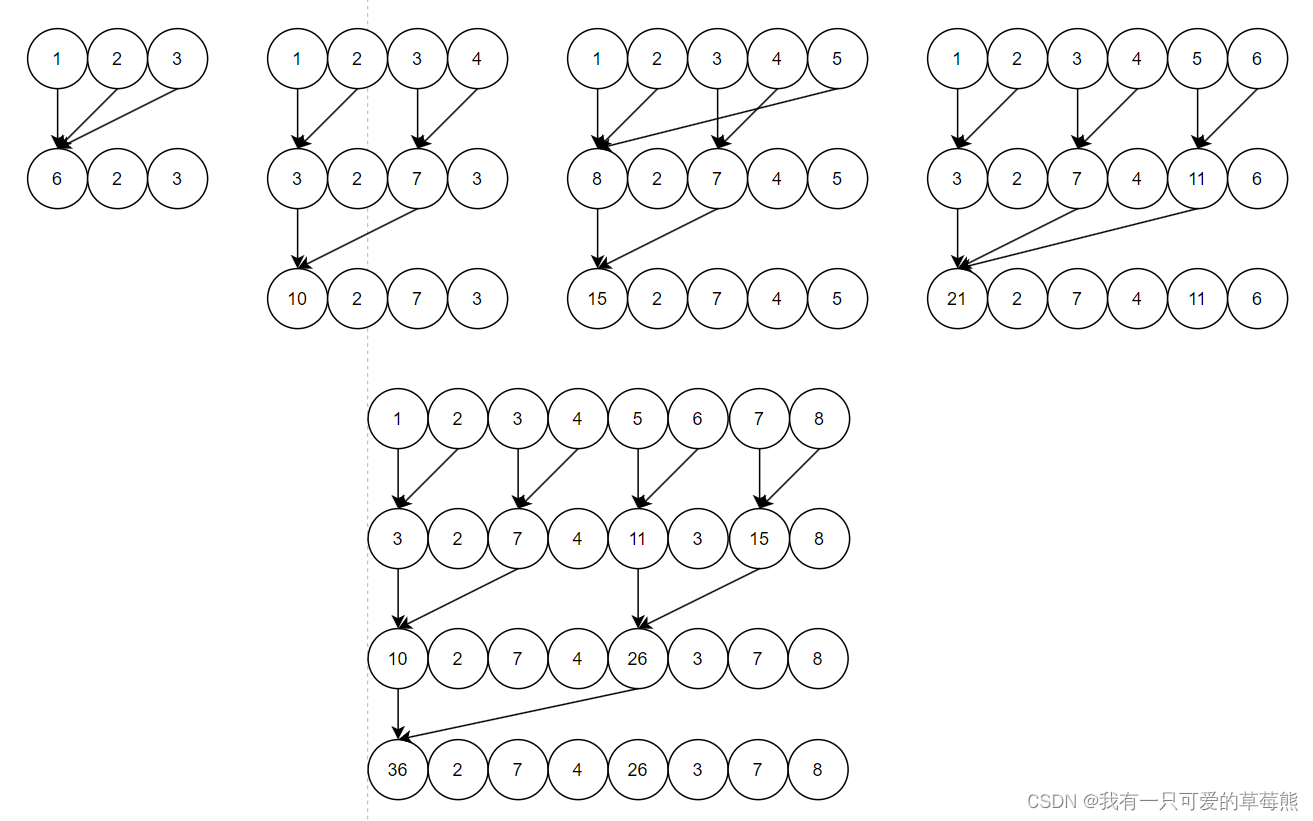
int traversal(vector<int> data, int size, int stride)
{
if(size == 1)
{
return data[0];
}
int loop = size / 2;
if(size % 2 == 0)
{
for(int i=0; i<loop; i++) //在这一次递归中循环的次数
{
data[i*(stride)] += data[i*(stride)+stride/2]; // 使用stride来确定下标
}
}
else{
for(int i=0; i<loop; i++)
{
data[i*(stride)] += data[i*(stride)+stride/2];
}
data[0] = data[0] + data[(size-1)*stride/2];
}
return traversal(data, size / 2, stride * 2);
}
int main()
{
vector<int>a{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17};
int res = traversal(a, a.size(), 2);
}
交错配对——CPU
int recursiveReduce(int *data, int const size)
{
// terminate check
if (size == 1)
return data[0];
// renew the stride
int const stride = size / 2;
if (size % 2 == 1)
{
for (int i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
data[0] += data[size - 1];
}
else
{
for (int i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
}
// call
return recursiveReduce(data, stride);
}
相邻匹配——GPU
__global__ void reduceNeighbored(int * g_idata,int * g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x*blockDim.x;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2 * stride)) == 0)
{
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
//int size = 1<<24;
//int blocksize = 1024;
//dim3 block(blocksize);
//dim3 grid((size + block.x - 1)/block.x);
要注意这里存在线程束的分化。也就是一个block内只有线程号为0,2,4…的线程在执行,因为属于一个warp,所以其余线程在等待。
优化版本:
__global__ void reduceNeighboredLess(int * g_idata,int *g_odata,unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x*blockDim.x + threadIdx.x;
// convert global data pointer to the local point of this block
int *idata = g_idata + blockIdx.x*blockDim.x;
if (idx > n)
return;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
//convert tid into local array index
int index = 2 * stride *tid;
if (index < blockDim.x)
{
idata[index] += idata[index + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
这个思路是:让warp的前几个线程跑满,而后半部分线程基本是不用执行的。当一个线程束内存在分支,而分支都不需要执行的时候,硬件会停止他们调用别人,这样就节省了资源。
交错匹配——GPU
__global__ void reduceInterleaved(int * g_idata, int *g_odata, unsigned int n)
{
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x*blockDim.x + threadIdx.x;
// convert global data pointer to the local point of this block
int *idata = g_idata + blockIdx.x*blockDim.x;
if (idx >= n)
return;
//in-place reduction in global memory
for (int stride = blockDim.x/2; stride >0; stride >>=1)
{
if (tid <stride)
{
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
参考链接
- CUDA基础3.4 避免分支分化
![[图解]建模相关的基础知识-19](https://img-blog.csdnimg.cn/direct/6c5b6ec4beb94e898d6933f8493dbc0d.png)