Meta发布了Meta 大型语言模型(LLM)编译器,这是一套强大的开源模型,旨在优化代码并彻底改变编译器设计。这项创新有望改变开发人员优化代码的方式,使代码优化更快、更高效、更具成本效益。
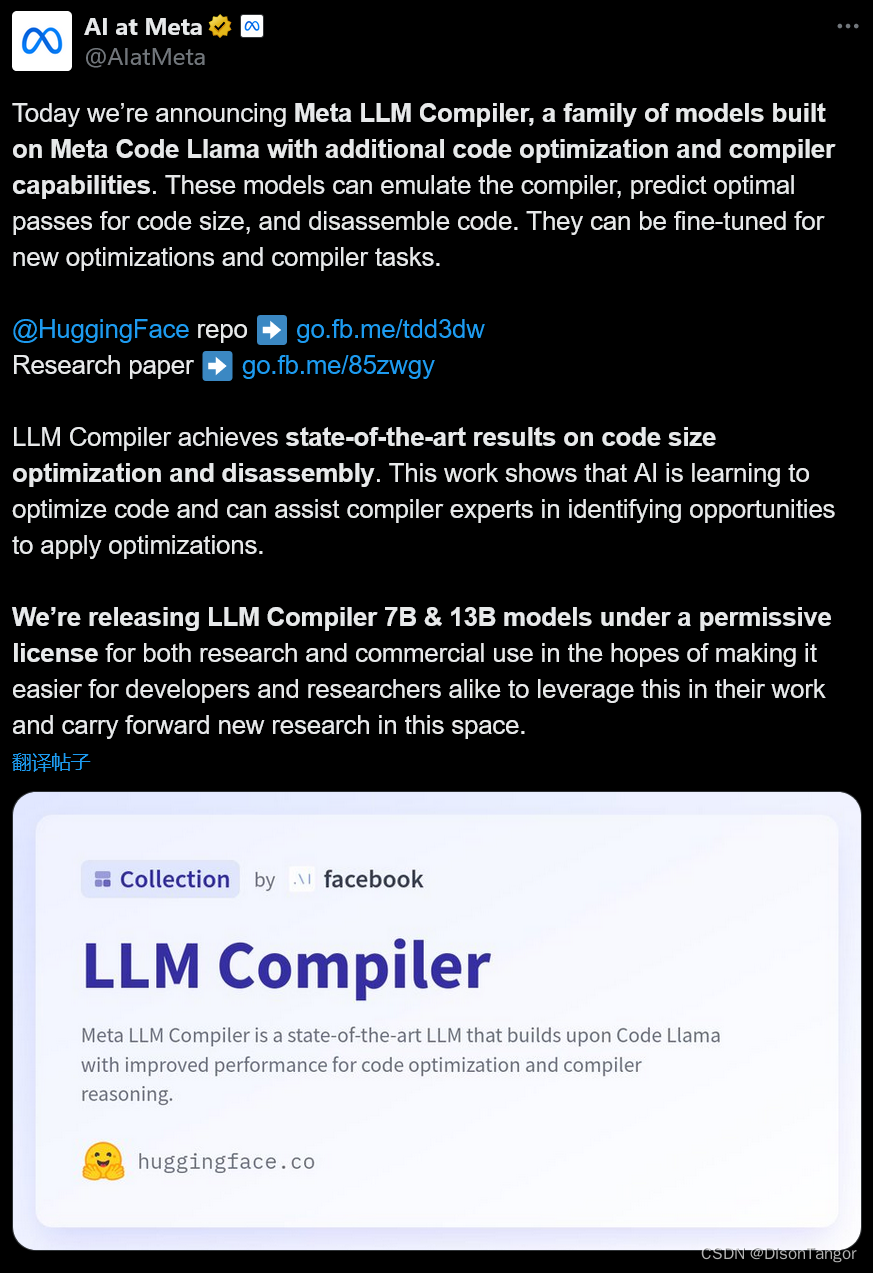
在将大型语言模型应用于代码和编译器优化方面,LLM 编译器背后的研究人员解决了一个尚未充分探索的重大空白。通过在包含 5460 亿条LLVM-IR和汇编代码的海量语料库上训练模型,他们使模型能够理解编译器中间表示、汇编语言和优化技术。
研究人员在论文中解释说:“LLM 编译器增强了对编译器中间表征(IR)、汇编语言和优化技术的理解。这种增强的理解能力使该模型能够执行以前由人类专家或专用工具完成的任务。”
LLM 编译器在代码大小优化方面取得了显著成果。在测试中,该模型的优化潜力达到了自动调整搜索的 77%,这一结果可以显著缩短编译时间,提高各种应用的代码效率。
事实证明,该模型的反汇编能力更令人印象深刻。在将 x86_64 和 ARM 汇编转换回 LLVM-IR 时,LLM 编译器显示了 45% 的往返反汇编成功率(14% 精确匹配)。这种能力对于逆向工程任务和遗留代码维护来说非常宝贵。
了解更多:
https://huggingface.co/collections/facebook/llm-compiler-667c5b05557fe99a9edd25cb
该项目的核心贡献者之一克里斯-卡明斯(Chris Cummins)强调了这项技术的潜在影响:他说:“通过提供两种规模(70 亿个参数和 130 亿个参数)的预训练模型,并通过微调版本展示其有效性,LLM 编译器为探索 LLM 在代码和编译器优化领域尚未开发的潜力铺平了道路。”
这项技术的影响深远而广泛。软件开发人员可以受益于更快的编译时间、更高效的代码以及用于理解和优化复杂系统的新工具。研究人员获得了探索人工智能驱动的编译器优化的新途径,有可能在软件开发方法上实现突破。
特别值得一提的是,Meta 决定以许可商业授权的方式发布 LLM 编译器。此举使学术研究人员和行业从业人员都能利用和改造这项技术,从而有可能加速该领域的创新。
然而,如此强大的人工智能模型的发布也引发了人们对软件开发不断变化的格局的质疑。随着人工智能处理复杂编程任务的能力越来越强,它可能会重塑未来软件工程师和编译器设计师所需的技能。
LLM 编译器代表的不仅仅是一种渐进式改进,而是我们在处理编译器技术和代码优化方面的根本性转变。通过这一版本,Meta 向学术界和工业界提出了挑战,以推动人工智能辅助编程的发展。
随着人工智能驱动的代码优化领域的不断发展,全球开发人员和研究人员如何采用、调整和改进这一开创性技术,将是一个引人入胜的话题。
我会定期在CSDN分享我的学习心得,项目经验和行业动态。如果你对某个领域感兴趣,或者想要了解更多技术干货,请关注我的账号,一起成长!







![[leetcode]insert-into-a-binary-search-tree](https://img-blog.csdnimg.cn/direct/e42854e6519b4c2caf3422ff48c63a28.png)