数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。
ps:深度学习的数据集Dataset,可能相对于传统的开发中的表、字段、视图。而不仅仅是一张表,因为数据交换的缘故,可能是多张表经过计算后得来的结果集。
MindSpore暂不支持直接加载的数据集,可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。
GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器(generator)构造自定义数据集,下面分别对其进行介绍。
import numpy as np
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt
from download import download
import time
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
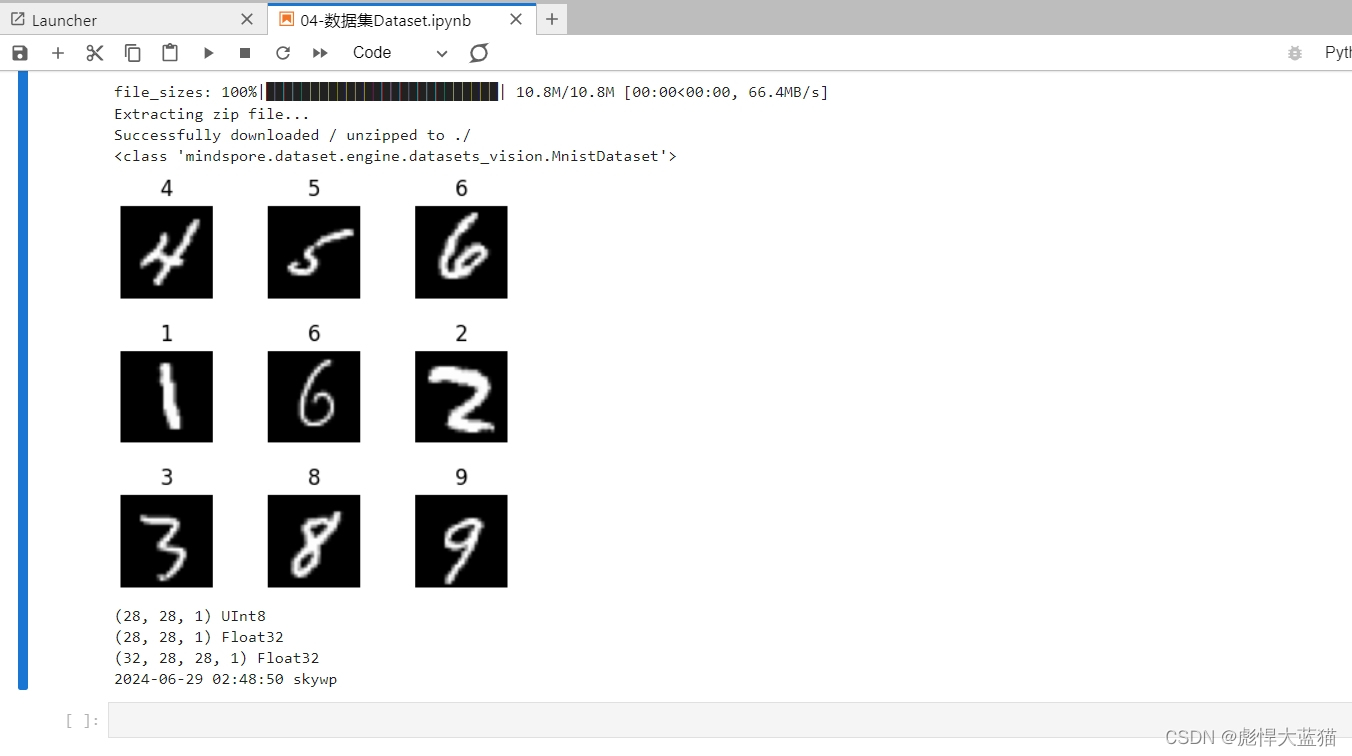
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
print(type(train_dataset))
# 迭代
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.6, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()
# visualize(train_dataset)
train_dataset = train_dataset.shuffle(buffer_size=64)
visualize(train_dataset)
#map
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
# batch
train_dataset = train_dataset.batch(batch_size=32)
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),'skywp')