Databricks 是一个基于 Apache Spark 的统一数据分析平台,为数据工程师、数据科学家和商业智能专家提供了简化的开发、操作和协作体验。2023 的新闻上都已经说他价值 430 亿美元了,做到了大数据开发平台的天花板。
在这篇博客文章中,我们将深入介绍 Databricks 的主要功能,并通过详细的代码示例展示如何使用 Databricks 进行大数据开发。
目录
- Databricks 简介
- Databricks 的主要功能
- Databricks 的应用场景
- 代码示例
- 创建 Spark 会话
- 读取数据
- 数据处理
- 数据可视化
- 总结
Databricks 简介
Databricks 是由 Apache Spark 的创始团队创建的统一分析平台,它集成了 Spark 的强大计算能力,支持从数据处理、机器学习到流数据分析的各种需求。Databricks 提供了一个基于云的集成开发环境(IDE),简化了大数据应用的开发和部署过程。通过 Databricks,用户可以快速构建和管理大规模数据分析项目,显著提高工作效率。
Databricks 的主要功能

- 集成的工作环境:Databricks 提供了一个基于浏览器的笔记本环境,支持多人协作开发。用户可以通过共享笔记本实现实时协作,方便团队成员之间的交流和合作。
- 自动化集群管理:Databricks 简化了 Spark 集群的创建、管理和扩展,用户无需关注底层集群的配置和维护,可以专注于数据分析和应用开发。
- 优化的运行性能:Databricks 通过 Delta Lake 和 Databricks Runtime 对数据存储和计算性能进行了优化,提高了查询速度和处理效率,确保了数据的一致性和高可用性。
- 内置的机器学习支持:Databricks 集成了 MLflow,提供了从模型开发、训练到部署的完整解决方案。用户可以轻松管理和跟踪机器学习实验,提高模型开发效率。
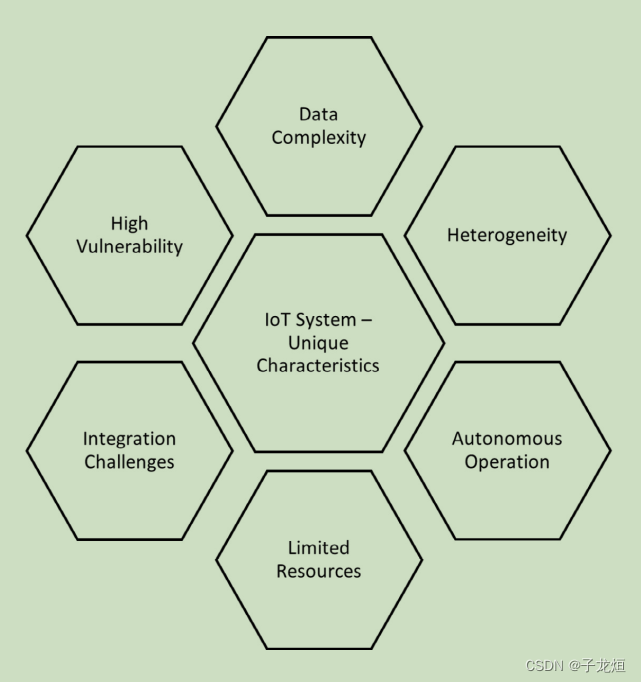
- 数据安全和治理:Databricks 提供了强大的数据安全和治理功能,包括细粒度的权限控制、数据加密和审计日志,确保数据的安全性和合规性。

Databricks 的应用场景
- 数据工程:ETL(Extract, Transform, Load)过程的自动化和优化。通过 Databricks,数据工程师可以轻松构建和管理复杂的数据管道,实现数据的清洗、转换和加载。

- 数据科学:支持从数据预处理到模型训练的完整工作流。数据科学家可以在 Databricks 上进行数据探索、特征工程和模型训练,快速迭代和验证模型。
- 流数据处理:实时数据分析和处理。Databricks 支持流数据处理框架,如 Spark Streaming 和 Structured Streaming,帮助用户构建高性能的流数据处理应用。
- 商业智能:大规模数据的探索和可视化分析。Databricks 提供了丰富的数据可视化工具,支持用户进行数据的探索和分析,生成各种图表和报告,辅助决策。
代码示例
下面的代码示例将展示如何在 Databricks 中创建 Spark 会话、读取数据、处理数据和进行数据可视化。
创建 Spark 会话
首先,我们需要创建一个 Spark 会话,这是进行任何 Spark 操作的基础。
from pyspark.sql import SparkSession
# 创建 Spark 会话
spark = SparkSession.builder \
.appName("Databricks Example") \
.getOrCreate()
print("Spark Session created successfully.")
读取数据
接下来,我们将读取一个 CSV 文件中的数据。在实际应用中,数据可以存储在各种格式中,如 JSON、Parquet、ORC 等。
# 读取 CSV 文件
file_path = "/path/to/data.csv"
df = spark.read.csv(file_path, header=True, inferSchema=True)
# 显示数据前 5 行
df.show(5)
print(f"DataFrame loaded successfully with {df.count()} rows.")
数据处理
我们将对数据进行一些基本的处理操作,包括过滤、聚合等。这里假设我们的数据包含 age 和 occupation 两个字段。

from pyspark.sql.functions import col
# 数据过滤:筛选出年龄大于 25 的记录
filtered_df = df.filter(col("age") > 25)
# 数据聚合:按职业统计人数
aggregated_df = filtered_df.groupBy("occupation").count()
# 显示聚合结果
aggregated_df.show()
print("Data processed successfully.")
数据可视化

最后,我们将处理后的数据转换为 Pandas DataFrame,并使用 Matplotlib 进行可视化。
import matplotlib.pyplot as plt
# 将 Spark DataFrame 转换为 Pandas DataFrame
pandas_df = aggregated_df.toPandas()
# 绘制柱状图
pandas_df.plot(kind='bar', x='occupation', y='count', legend=False)
plt.title("Occupation Count")
plt.xlabel("Occupation")
plt.ylabel("Count")
plt.show()
print("Data visualization generated successfully.")
总结
Databricks 提供了强大的工具和优化的性能,使得大数据开发变得更加高效和便捷。从数据处理到机器学习,Databricks 为开发者提供了一个完整的解决方案。如果你还没有尝试过 Databricks,现在就是开始的好时机!
希望这篇文章能帮助你更好地了解和使用 Databricks。如果你有任何问题或建议,欢迎在评论区留言。
希望你喜欢这篇关于 Databricks 的博客文章,并在你的大数据项目中获得灵感和帮助。