系列文章目录
MyBatis缓存原理
Mybatis plugin 的使用及原理
MyBatis+Springboot 启动到SQL执行全流程
数据库操作不再困难,MyBatis动态Sql标签解析
Mybatis的CachingExecutor与二级缓存
使用MybatisPlus还是MyBaits ,开发者应该如何选择?
巧用MybatisPlus的SQL注入器提升批量插入性能
从@Param注解开始,深入了解 MyBatis 参数映射的原理
- 系列文章目录
- 一、MyBatis 里 SQL执行的过程
- 1. 核心对象 BoundSql
- 2. 解析出 parameterMappings
- 3. 整理方法入参 parameterObject
- 4. 参数的代入
- 5. 动态SQL的特殊处理
- 二、@Param注解在各场景下的效果
- 1. 单个参数 - 简单类型
- (1)加@Param注解之前
- (2)加@Param注解之后
- 2. 单个参数 - 复杂对象
- (1)加@Param注解之前
- (2)加@Param注解之后
- 3. 多个参数
- (1)加@Param注解之前
- (2)加@Param注解之后
- 4. 集合参数与动态SQL
- (1)加@Param注解之前
- (2)加@Param注解之后
- 三、总结

前几天组内一名同事在项目中发现了一个报错:Parameter 'id' not found. Available parameters are [userId, param1],说白了也就是也就是在xml中使用'id'参数,但实际上Mapper层方法却用的@Param("userId"),这就是明显对MyBtais的参数映射不太了解了。相信这一部分内容同样有不少同学是疏忽的,那么本期我们来看一下@Param注解的使用与原理
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 MyBatis专栏 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis kafka docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、MyBatis 里 SQL执行的过程
1. 核心对象 BoundSql
我们之前其实多次讨论 MyBatis 里执行SQL的原理: MyBatis+Springboot 启动到SQL执行全流程,这里我们再简单复习。其简要步骤就是
获取会话-> 会话执行-> 执行器执行 -> statement -> jdbc
我们主要来看这一段:
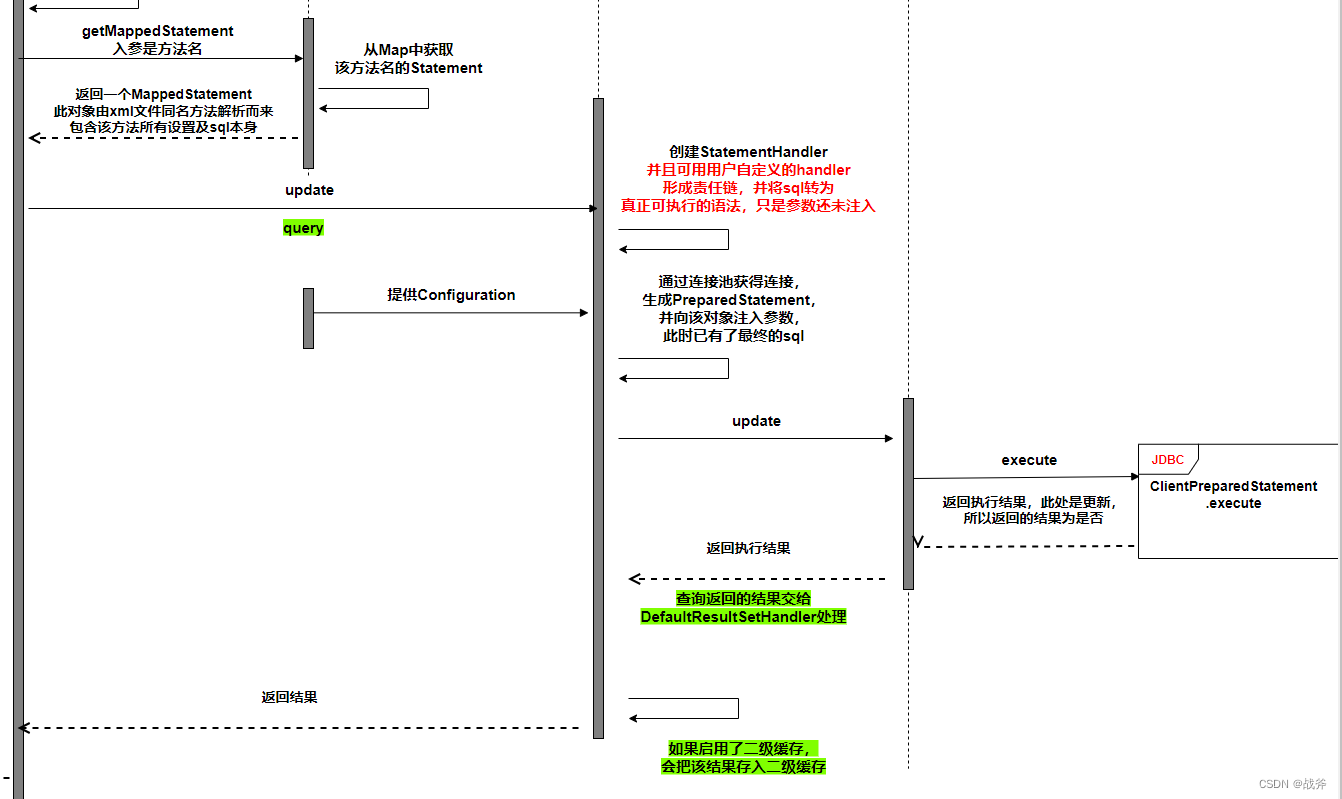
在真正执行SQL的时候,我们拿到了MapperStatement后,还需要做三步:
① 把可执行的语句准备好,注意此时SQL没有参数;
② 把外界提供的参数进行整理与保存
③ 把整理好的入参,按一定规则代入上述SQL的指定位置
其实前两步,它们会构成这样一个对象:
// StaticSqlSource.java
@Override
public BoundSql getBoundSql(Object parameterObject) {
// sql 就是缺参数的可执行SQL
// parameterMappings 是从xml解析出来的所需要的参数列表
// parameterObject 实际执行到该方法的参数内容
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}
public BoundSql(Configuration configuration, String sql, List<ParameterMapping> parameterMappings, Object parameterObject) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.parameterObject = parameterObject;
// additionalParameters 部分只有动态SQL才会用到
this.additionalParameters = new HashMap<>();
this.metaParameters = configuration.newMetaObject(additionalParameters);
}
这个对象中含有MyBatis配置、对应SQL,SQL中需要的参数,现在实际提供的参数,那么我们现在只需要关注 SQL中需要的参数 和 现在实际提供的参数 即可
2. 解析出 parameterMappings
parameterMappings 实际保存的就是 从xml解析出的关于SQL所需要的参数列表,这个所需参数的对象由下面几个属性构成:
List<ParameterMapping> parameterMappings;
public class ParameterMapping {
private String property;
private ParameterMode mode;
private Class<?> javaType = Object.class;
private JdbcType jdbcType;
private Integer numericScale;
private TypeHandler<?> typeHandler;
private String resultMapId;
private String jdbcTypeName;
private String expression;
}
在一般场景下,最核心的就是 property ParameterMode 和 jdbcType 三个字段了,比如说我们在xml里如果写了这样一段SQL
<select id="findUserById" resultType="com.zhanfu.springboot.demo.entity.User" parameterType="int">
SELECT * FROM user where id =#{idy}
</select>
此时我们只需要一个参数,因此解析出来只会有一个 ParameterMapping :
① 它的 property 就是我们设定的变量名 ‘idy’,
② ParameterMode 是参数模式,我们这里是入参,也就是 ‘IN’ ;除此以外还有 ‘OUT’ 和 ‘INOUT’
③ jdbcType 因为我们指定了参数的 parameterType, javaType 就是 Integer
3. 整理方法入参 parameterObject
刚刚我们说了,parameterObject 就是我们实际提供的参数,也就是我们实际调用Mapper方法时传入的参数组,直白的说,MyBatis会把我们传入的参数数组转化为一个参数Map对象,key是参数名,value是参数值。
// MapperMethod.java
// Mapper层代理类执行方法时调用的就是此类
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
// 将传入方法的arg数组,转为一个参数对象,实际上就是一个HashMap
public Object convertArgsToSqlCommandParam(Object[] args) {
return paramNameResolver.getNamedParams(args);
}
对于这个Map,参数值自然是我们传的参数值,而参数名是怎么获取的,又有什么规则呢? 我们来看下所谓的 name 是怎么设计的。
// ParamNameResolver.java
public ParamNameResolver(Configuration config, Method method) {
this.useActualParamName = config.isUseActualParamName();
final Class<?>[] paramTypes = method.getParameterTypes();
final Annotation[][] paramAnnotations = method.getParameterAnnotations();
final SortedMap<Integer, String> map = new TreeMap<>();
int paramCount = paramAnnotations.length;
// get names from @Param annotations
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
if (isSpecialParameter(paramTypes[paramIndex])) {
// skip special parameters
continue;
}
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
if (annotation instanceof Param) {
hasParamAnnotation = true;
name = ((Param) annotation).value();
break;
}
}
if (name == null) {
// @Param was not specified.
if (useActualParamName) {
name = getActualParamName(method, paramIndex);
}
if (name == null) {
// use the parameter index as the name ("0", "1", ...)
// gcode issue #71
name = String.valueOf(map.size());
}
}
map.put(paramIndex, name);
}
names = Collections.unmodifiableSortedMap(map);
}
从上述代码中,我们看到了所谓参数name的制取流程,对于每一个参数,其实都分为三个优先级:
①优先取@Param里的value值作为参数名;
②其次如果myBtais的配置里配置了 useActualParamName = true(默认是开启的), 则取方法中写的形参名;
③如果上述都没有值,最后取该参数在所有入参中的序号,从0开始,计值0,1,2…作为参数的名称
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
if (args == null || paramCount == 0) {
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
// 仅有一个参数,且该参数没有使用 @Param注解
Object value = args[names.firstKey()];
return wrapToMapIfCollection(value, useActualParamName ? names.get(0) : null);
} else {
// 对于一般场景,则会为参数提供两个名称,一个是我们上面获取的名称,一个是‘param+序号’的名称
final Map<String, Object> param = new ParamMap<>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
param.put(entry.getValue(), args[entry.getKey()]);
// add generic param names (param1, param2, ...)
final String genericParamName = GENERIC_NAME_PREFIX + (i + 1);
// ensure not to overwrite parameter named with @Param
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
// 如果参数是集合,则构建map,形成<参数名, 参数值>的map, 并且额外为参数补充如 ‘list’、‘collection’ 这样的的参数名;
// 如果不是集合,直接返回对象
public static Object wrapToMapIfCollection(Object object, String actualParamName) {
if (object instanceof Collection) {
ParamMap<Object> map = new ParamMap<>();
map.put("collection", object);
if (object instanceof List) {
map.put("list", object);
}
Optional.ofNullable(actualParamName).ifPresent(name -> map.put(name, object));
return map;
} else if (object != null && object.getClass().isArray()) {
ParamMap<Object> map = new ParamMap<>();
map.put("array", object);
Optional.ofNullable(actualParamName).ifPresent(name -> map.put(name, object));
return map;
}
return object;
}
通过对源码的分析,我们不难看出对参数的处理其实分成了两种逻辑:
(1) 整理结果1: 仅有一个参数,且该参数没有使用 @Param注解
- 此时,如果该参数是集合类型的,则还是构建一个<参数名,参数值>这样的map,把参数及其名称放入其中。而且还给他补充几个参数名, 如 ‘list’、‘collection’,当然参数值都是一样的。这样,该参数其实就有多个别名了。
- 如果该参数不是集合,就直接使用参数值本体,而不再使用map的形式
(2) 整理结果2:(即有多个参数,或者有参数使用了@Param注解)
- 构建一个<参数名,参数值>这样的map,使用我们上面获取到的参数名,同时为每一个参数添加一个别名,即param1, param2 等。
总结的说,就是如果你这个方法仅有一个参数,且参数不是集合,而我们也没有使用@Param,那它就会直接使用这个参数值。除此以外我们的参数值全部是以map的形式存储的,而参数名正是我们的@Param的值、方法形参名,或者单纯的次序号‘0’、‘1’、‘2’;除了这些参数名外,Mybatis还会为我们增加这些参数的别名,如param1, param2等。
4. 参数的代入
我们现在知道了需要的参数,也整理好了方法的入参,那接下来自然就是把参数代入SQL的指定位置了,它的核心方法如下:
// DefaultParameterHandler.java
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
不难看出,他就是遍历SQL里每一个需要参数的位置,然后再去我们整理的入参中去找合适的,把入参的值填入该位置:这一步其实含有不少细节,我们把它做个梳理,找参数值可以按照方法里的逻辑归纳为3个优先级:
- 代入场景1:优先去 AdditionalParameter 找有没有符合的参数,AdditionalParameter 是动态SQL的产物,它
- 代入场景2:直接使用 parameterObject 作为参数值 ,注意直接使用 parameterObject 仅会发生在方法仅有一个非集合参数的情况下,上面我们已经讲过,此时parameterObject 就是入参传的对象;① 若入参为 null 则 parameterObject 为 null ; ② 若 parameterObject 不为 null 且是简单类型,能直接被Mybatis 处理则直接将其处理,得到参数值
- 代入场景3:从 parameterObject 中找符合的参数,注意此种情况下,parameterObject 其实是一个复杂对象 或者是 map,需要根据所需参数名,在 对象 中或者 map 找到对应的参数值。
5. 动态SQL的特殊处理
我们上面说的其实是静态SQL的处理逻辑,而我们也曾介绍过动态SQL,可见《数据库操作不再困难,MyBatis动态Sql标签解析》。
静态SQL比较简单,给参数预留的位置与个数是一目了然,不会变的,只要从xml里写的SQL里进行解析就好了。
而动态SQL则不然,动态SQL直到执行前一刻,获取到了入参,结合了入参的情况才能确定SQL需要几个参数,以及参数的位置。
因此在获取了BoundSql 后,还需要对 BoundSql 做一步操作
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 结合xml的动态SQL标签,以及当前入参的情况,构造出动态SQL,
// 并整理SQL内需要的参数个数及位置,将信息保存在 上下文的binding 中
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
// 获取了 boundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 处理 boundSql ,将动态上下文的 binding 部分赋值给 boundSql 的 AdditionalParameters 中
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
比方说对于这样一个接口 及其 xml
boolean batchAddUser(List<User> userList)
<insert id="batchAddUser" parameterType="com.zhanfu.springboot.demo.entity.User">
insert into user(id,username,password) values
<foreach collection="list" item="user" separator=",">
(#{user.id}, #{user.username}, #{user.password})
</foreach>
</insert>
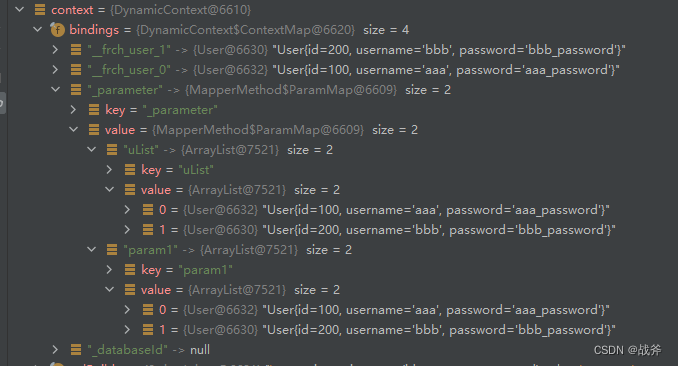
就利用了 动态标签,此时如果我们插入两条数据(list 长度等于2),上下文的bing 部分就会变成如下。我们主要关系上面的 __frch_user_0 以及 __frch_user_1 。这两条就是结合原SQL与入参情况产生的新SQL中,所需要储存着的参数名 - 参数值映射关系。
二、@Param注解在各场景下的效果
1. 单个参数 - 简单类型
(1)加@Param注解之前
此时 Mapper 层方法为:
User findUserById(int id)
此时xml语句为:
<select id="findUserById" resultType="com.zhanfu.springboot.demo.entity.User" parameterType="int">
SELECT * FROM user where id =#{id}
</select>
此时我们的入参是单个的简单对象,所以会使用整理结果1,导致 parameterObject 就直接是我们的 id 对象(基础类型会变为包装类型Integer), 而 parameterMappings 需要的参数为一个,即‘id’,所以最终走入代入场景2,直接把我们传入的id,放进SQL中的 #{id} 位置,值得一提的是,此时其实根本没有用到parameterMapping里的属性名,也就是说,即使xml中你的SQL写的是
<select id="findUserById" resultType="com.zhanfu.springboot.demo.entity.User" parameterType="int">
SELECT * FROM user where id =#{niuAAAAAA}
</select>
也没事,仍然能把外界传的id,放进 #{niuAAAAAA} 这个位置
(2)加@Param注解之后
此时 Mapper 层方法为:
User findUserById(@Param("id")int id);
此时xml语句为:
<select id="findUserById" resultType="com.zhanfu.springboot.demo.entity.User" parameterType="int">
SELECT * FROM user where id =#{id}
</select>
此时因为加入了@Param,所以会使用整理结果2,导致 parameterObject 成为了一个map,内含两个键值对,两个键值对的 value 值都是我们传入的 id 对象,而 key 值一个是我们设定的参数名 ‘idr’,一个是Mybatis 为我们加的别名 ‘param1’

所以此时会进入代入场景3,然后从 map 中以 ‘id’ 去取值。就取到了我们的传入的 id 对象。因此在这种情况下,我们的 #{id} 就不能写成 #{niuAAAAAA} 了,必须和 @Param 注解里写的参数名保持一致
2. 单个参数 - 复杂对象
(1)加@Param注解之前
此时 Mapper 层方法为:
boolean addUser(User user)
此时xml语句为:
<insert id="addUser" parameterType="com.zhanfu.springboot.demo.entity.User" >
insert into user(id,username,password) values (#{id},#{username},#{password})
</insert>
此时我们的入参是单个的对象,且没有使用@Param, 所以会使用整理结果1,导致 parameterObject 就直接是我们的 user 对象, 而 parameterMappings 需要的参数为三个,即‘id’ 、‘username’ 、 ‘password’,
所以最终则会循环走入代入场景3,然后从我们的入参对象中分别取出 ‘id’ 、‘username’ 、 ‘password’,更具体的,其获取值的方式自然是使用对象的get属性值的方法。注意,如果你使用的是@lombok来自动补足get set方法的话,需要注意里面的一些坑,详情见《【问题处理】—— lombok 的 @Data 大小写区分不敏感》
(2)加@Param注解之后
此时 Mapper 层方法为:
boolean addUser(@Param("user") User user);
此时xml语句为:
<insert id="addUser" parameterType="com.zhanfu.springboot.demo.entity.User" >
insert into user(id,username,password) values (#{id},#{username},#{password})
</insert>
此时我们的入参是单个的复杂对象,但因为加入了@Param,所以会使用整理结果2,导致 parameterObject 成为了一个map,内含两个键值对,两个键值对的 value 值都是我们传入的 user 对象,而 key 值一个是我们设定的参数名 ‘user’,一个是Mybatis 为我们加的别名 ‘param1’

此时同样的 parameterMappings 需要的参数为三个,所以还是会循环走入代入场景3,然后从 map 中以 ‘id’ 去取值。自然,我们都知道,map 里此时并没有一个key 值叫 ‘id’,所以这样的使用方式最终会报错 Parameter 'id' not found. Available parameters are [user, param1].如果这种场景下一定要使用@Param注解,则需要将xml语句写成
<insert id="addUser" parameterType="com.zhanfu.springboot.demo.entity.User" >
insert into user(id,username,password) values (#{user.id},#{user.username},#{user.password})
</insert>
MyBatis能自动以 . 为界进行分割,前面的部分作为对象,后面作为属性不断递归,此处就能获取 user 对象的 id 属性了。
3. 多个参数
(1)加@Param注解之前
此时 Mapper 层方法为:
User findUser(int id, String name)
此时xml语句为:
<select id="findUser" resultType="com.zhanfu.springboot.demo.entity.User">
SELECT * FROM user where id =#{id} and username =#{name}
</select>
此时我们的入参是多个对象, 所以会使用整理结果2,导致 parameterObject 成为了一个map,.内含四个键值对,如下:其中“name” 、“id” 键值对是来源于形参名, ‘param1’、 ‘param2’ 是MyBtais为我们添加的别名
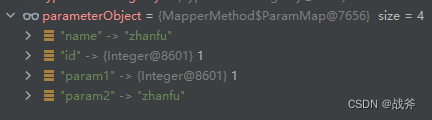
而 parameterMappings 需要的参数为三个,即‘id’ 、‘name’
所以最终则会循环走入代入场景3,然后从我们的map中分别取出 ‘id’ 、‘name’ ,放入对应的位置,因此此时必须要保证 #{id} 与方法的 User findUser(int id, String name) 形参名 id 是同样的,不能随便写。
(2)加@Param注解之后
此时 Mapper 层方法为:
User findUser(@Param("id")int id, @Param("name")String name)
此时xml语句为:
<select id="findUser" resultType="com.zhanfu.springboot.demo.entity.User">
SELECT * FROM user where id =#{id} and username =#{name}
</select>
此时我们的入参是多个对象, 所以会使用整理结果2,最终 parameterObject 成为了一个map,.内含四个键值对,如下:其中“name” 、“id” 键值对是来源于我们@Param里填的字符串, ‘param1’、 ‘param2’ 是MyBtais为我们添加的别名
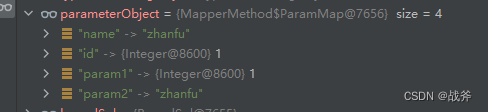
最终它的表现是和没加@Param一致的,同样会循环走入代入场景3,然后从 map 中以 ‘id’ 、‘name’ 去取值。
4. 集合参数与动态SQL
我们向集合中添加两个User元素,然后调用Mapper
(1)加@Param注解之前
此时 Mapper 层方法为:
boolean batchAddUser(List<User> userList);
此时xml语句为:
<insert id="batchAddUser" parameterType="com.zhanfu.springboot.demo.entity.User">
insert into user(id,username,password) values
<foreach collection="list" item="user" separator=",">
(#{user.id}, #{user.username}, #{user.password})
</foreach>
</insert>
此时我们的入参是个单独对象,没有@Param,所以会使用整理结果1,但因为对象是集合类型,最终 parameterObject 还是成为了一个map,需要注意的是,此时除了 还有了一个parameterObject ,还有 additionalParameters 如下:
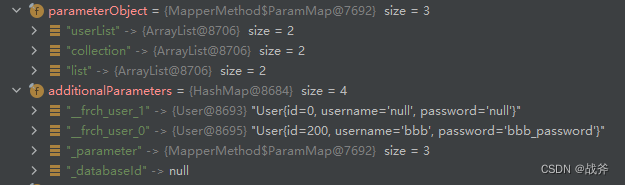
而从动态SQL中解析出的 parameterMappings 需要的参数为2 * 3 = 6个,如下:

因为有了 additionalParameters ,所以最终则会循环走入代入场景1,即从 additionalParameters 获取 __frch_user_0.username。这样也是可以取到的,和我们最开始取user.id是一样的。
需要注意的是,我们在 xml 中的动态SQL里使用了 collection=“list” ,这里也不是乱填的,list 正是parameterObject 的三个key 之一,因此此处还可以替换成 collection=“collection” 、collection = ”userList“
(2)加@Param注解之后
此时 Mapper 层方法为:
boolean batchAddUser(@Param("uList")List<User> userList);
此时xml语句为:
<insert id="batchAddUser" parameterType="com.zhanfu.springboot.demo.entity.User">
insert into user(id,username,password) values
<foreach collection="uList" item="user" separator=",">
(#{user.id}, #{user.username}, #{user.password})
</foreach>
</insert>
此时我们的入参是个单独对象,有@Param。所以会使用整理结果2,导致 parameterObject 成为了一个map,也还有 additionalParameters, 如下:

而从动态SQL中解析出的 parameterMappings 需要的参数还是一样的,为2 * 3 = 6个,如下:

因为有了 additionalParameters ,所以最终则会循环走入代入场景1,即从 additionalParameters 获取 __frch_user_0.username。
此时不同的因为parameterObject 里现在的key 只有 ‘ulist’ 和 ‘param1’ ,所以我们的动态SQL里使用的 collection=“ulist” ,就只能填这个或 collection=“param1” 了。
三、总结
本次的涉及的知识点比较琐碎,如果刨去动态SQL的那部分来说,我们其实可以归纳一下 @Param 注解的作用:就是对方法的参数名做一个重命名:
①使用了 @Param("AAA"),就需要在xml中使用到参数的部分,也与此保持一致,如#{AAA}
②特别的,对于方法仅有一个入参对象(如User对象)的情况,如果你使用了 @Param("AAA"),那么你在xml中,如果要使用对象的属性,如User对象的id属性,那就只能使用#{AAA.id}。如果你此时不使用 @Param 注解,在xml中反而能直接使用 #{id} 来表示入参的id属性




![[数据集][目标检测]城市街道井盖破损未盖丢失检测数据集VOC+YOLO格式4404张5类别](https://img-blog.csdnimg.cn/direct/a8a0b84e536e467985a676a0fb31b85f.png)