1.绪论
在工作中,我们经常需要根据msgKey查询到某条日志。但是,通过前面对commitLog分析,producer将消息推送到broker过后,其实broker是直接消息到达broker的先后顺序写入到commitLog中的。我们如果想根据msgKey检索一条消息无疑大海捞针,所以们需要像数集一样建立一个目录,我们其实可以想到的是构建一个Map,key存储msgKey,value存储msg在commitLog中的物理偏移量。而这个目录其实就是indexFile。
2.indexFile的组成和原理
indexFile主要由两部分组成,分别是indexFile文件头和index的文件内容。
2.1 indexFile文件头 - IndexHeader
indexHeader占据40个字节,其中最重要的是他记录了整个索引文件的最开始插入的索引的时间和最后一条数据插入的时间,主要是为了支持根据时间进行范围搜索。以及第一条和最后一条日志的索引位置。还有一个就是已经插入了多少条索引IndexCount。
public class IndexHeader {
//index文件头占4个字节
public static final int INDEX_HEADER_SIZE = 40;
private static int beginTimestampIndex = 0;
private static int endTimestampIndex = 8;
private static int beginPhyoffsetIndex = 16;
private static int endPhyoffsetIndex = 24;
private static int hashSlotcountIndex = 32;
private static int indexCountIndex = 36;
private final ByteBuffer byteBuffer;
//开始的时间戳
private final AtomicLong beginTimestamp = new AtomicLong(0);
//结束时间戳
private final AtomicLong endTimestamp = new AtomicLong(0);
//开始的物理偏移量
private final AtomicLong beginPhyOffset = new AtomicLong(0);
//结束的物理偏移量
private final AtomicLong endPhyOffset = new AtomicLong(0);
//hash槽的数量
private final AtomicInteger hashSlotCount = new AtomicInteger(0);
//index的数量
private final AtomicInteger indexCount = new AtomicInteger(1);
}2.2 indexFile的组成
idnexFile的内容包括:
1. 40个字节的indexFile头
2. 4* 500w个字节hash槽,每个槽记录的其实是:根据key取hash值%槽数在当前hash槽的索引的序号(也即当前有多少条索引)
3. 20*2000w个自己的索引数,每条索引20个字节,包含4个字节索引key的hash值+8个字节的物理偏移量+4个字节的当前索引的插入时间距离该索引文件第一条索引的插入时间的差值+4个字节的上一个在当前hash槽的索引的序号。
我们可以画图来描述一下:
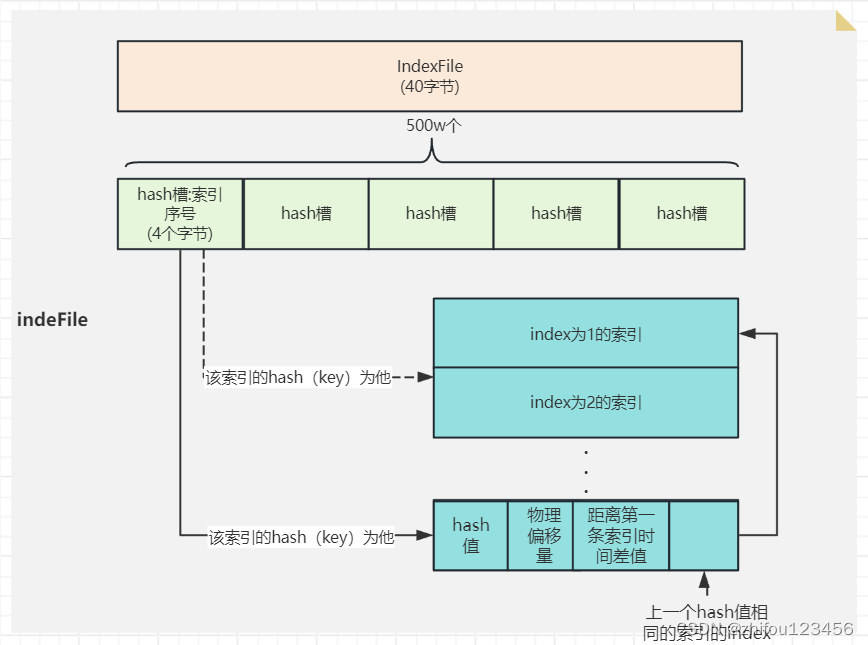
可以看出idnexFile是采用链地址法解决hash冲突的,每个索引存储有上一条拥有相同hash值索引的index值,相当于通过链表将这些hash冲突的索引串起来。
public class IndexFile {
private static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
//一个hash槽的大小为4个字节
private static int hashSlotSize = 4;
//一条索引的大小为20字节
private static int indexSize = 20;
private static int invalidIndex = 0;
//hash槽的数量
private final int hashSlotNum;
//index的总数量
private final int indexNum;
//index也是存储在mappedFile中的
private final MappedFile mappedFile;
private final MappedByteBuffer mappedByteBuffer;
//index文件的头
private final IndexHeader indexHeader;
public IndexFile(final String fileName, final int hashSlotNum, final int indexNum,
final long endPhyOffset, final long endTimestamp) throws IOException {
//文件总大小 = 头部所占40个字节 + hash槽数量(默认为500w) * 4个字节 + index数量 * 20个字节
int fileTotalSize =
IndexHeader.INDEX_HEADER_SIZE + (hashSlotNum * hashSlotSize) + (indexNum * indexSize);
//新建mappedFile
this.mappedFile = new MappedFile(fileName, fileTotalSize);
//获取到与文件建立映射关系的buffer
this.mappedByteBuffer = this.mappedFile.getMappedByteBuffer();
//hash槽数量
this.hashSlotNum = hashSlotNum;
//索引文件的数量
this.indexNum = indexNum;
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
//index文件的头部
this.indexHeader = new IndexHeader(byteBuffer);
if (endPhyOffset > 0) {
//够级整个索引文件的开始的物理偏移量和结束的偏移量
this.indexHeader.setBeginPhyOffset(endPhyOffset);
this.indexHeader.setEndPhyOffset(endPhyOffset);
}
if (endTimestamp > 0) {
//够级整个索引文件的开始时间戳和结束时间戳
this.indexHeader.setBeginTimestamp(endTimestamp);
this.indexHeader.setEndTimestamp(endTimestamp);
}
}
}3.向indexFile插入一条索引数据
主要的步骤如下:
1.获取msgKey的hash值;
2.通过hash值对总的hash槽数取模得到对应第几个槽;
3.40个字节的index头大小+第几个槽*4个字节寻得hash槽的物理地址;
4.40个字节的索引头大小+hash槽总数*4个字节+现在存储了多少条索引*20个字节得到最新一条数据写入的物理偏移量;
5.分别写入索引内容:hash值,commitLog的物理偏移量,距离第一条索引的时间戳+上一条指向同一个hash槽的索引的序号(也即当前hash槽中存储的值);
6.将最新一条的索引序号写入到hash槽中。
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
if (this.indexHeader.getIndexCount() < this.indexNum) {
//1.获取msgKey的hash值
int keyHash = indexKeyHashMethod(key);
//2.通过hash值对总的hash槽数取模得到对应第几个槽
int slotPos = keyHash % this.hashSlotNum;
//3.40个字节的index头大小+第几个槽*4个字节寻得hash槽的物理地址
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
try {
//获取到上一个hash槽的所指向的索引序号
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
//获取当前索引与第一条索引的差值
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
//40个字节的索引头大小+hash槽总数*4个字节+现在存储了多少条索引*20个字节得到最新一条数据写入的物理偏移量
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
//分别写入索引内容:hash值,commitLog的物理偏移量,距离第一条索引的时间戳+上一条指向同一个hash槽的索引的序号
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//将最新一条的索引序号写入到hash槽中
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
//更新idnex中的最后一条索引的时间戳和物理偏移量
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
if (invalidIndex == slotValue) {
this.indexHeader.incHashSlotCount();
}
//增加indexheader索引序号
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
}4.从indexFile中读取一条索引数据
1.获取索引key的hash值;
2.hash值对槽总数取模获得第几个槽;
3.40个字节的index头大小+第几个槽*4个字节寻得hash槽的物理地址;
4.从槽中读取到该槽所指向的最新的一条索引序号;
5.40个字节的索引头大小+hash槽总数*4个字节+hash槽中存储的索引序号*20个字节得到最新一条数据写入的物理偏移量;
6.如果hash值相等,并且时间匹配,证明匹配到数据,跳出循环;
7.如果不匹配,便根据链表寻找到拥有相同hash值并且时间匹配的日志;
public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum,
final long begin, final long end) {
if (this.mappedFile.hold()) {
//获取索引key的hash值
int keyHash = indexKeyHashMethod(key);
//hash值对槽总数取模获得第几个槽
int slotPos = keyHash % this.hashSlotNum;
//40个字节的index头大小+第几个槽*4个字节寻得hash槽的物理地址
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
try {
//从槽中读取到该槽所指向的最新的一条索引序号
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {
} else {
for (int nextIndexToRead = slotValue; ; ) {
if (phyOffsets.size() >= maxNum) {
break;
}
// 40个字节的索引头大小+hash槽总数*4个字节+hash槽中存储的索引序号*20个字节得到最新一条数据写入的物理偏移量
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
//获取索引的hash值
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
//获取到该索引的物理偏移量
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
//获取到时间戳差值
long timeDiff = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
//获取到拥有相同槽数的上一条索引序号
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
//如果hash值相等,并且时间匹配,证明匹配到数据,跳出循环
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
//如果上一条索引非法,证明已经到达链表头部,跳出循环,证明该条索引就是需要寻找的索引
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
nextIndexToRead = prevIndexRead;
}
}
} catch (Exception e) {
log.error("selectPhyOffset exception ", e);
} finally {
this.mappedFile.release();
}
}
}