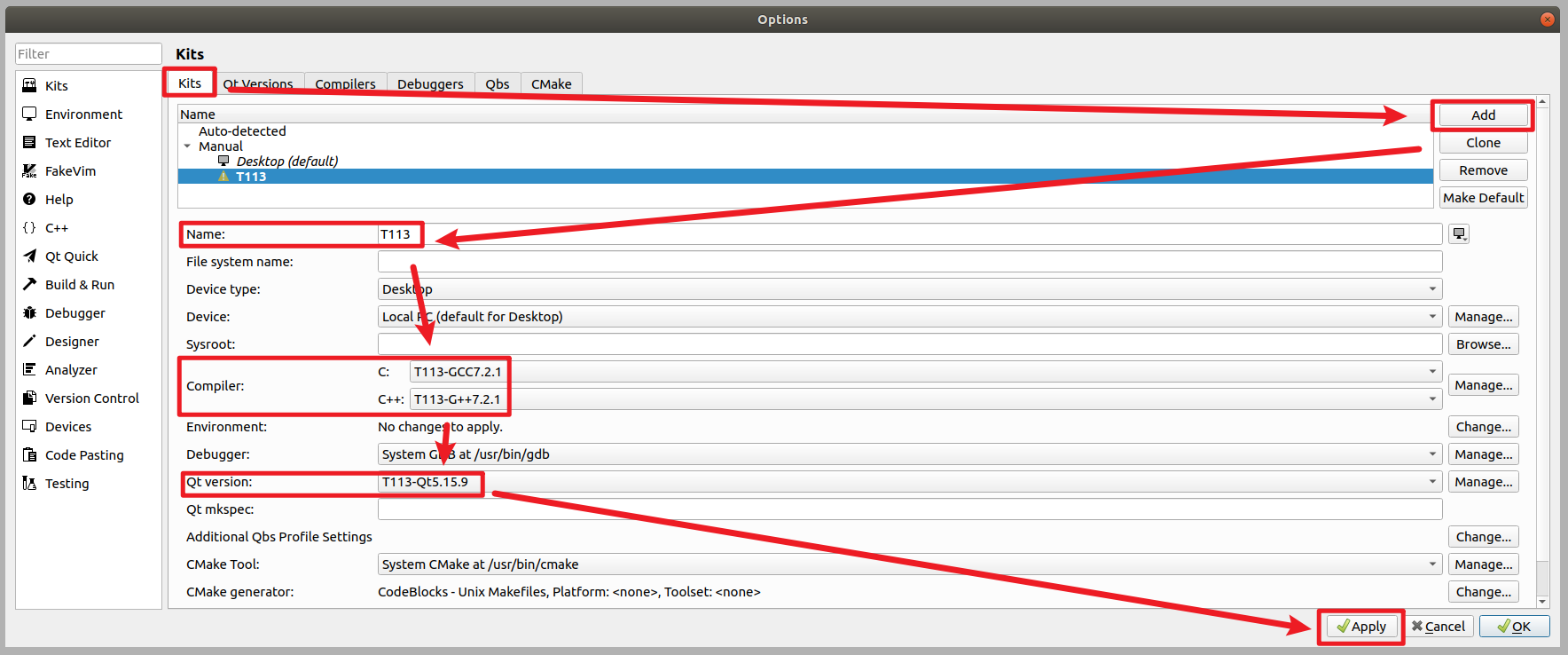
将单阶段检测器作为RPN
- 一、在 Faster R-CNN 中使用 `FCOSHead` 作为` RPNHead`
- 与原始配置的对比结果
- Neck (FPN)
- RPN Head
- ROI Head
- 学习率
- 使用单阶段检测器作为RPN的优势
- 1. 速度提升
- 2. 准确性
- 3. 简化架构
- 4. 灵活性
- 二、评估候选区域
- 三、用预先训练的 FCOS 训练定制的 Faster R-CNN

本文参考MMDetection将单阶段检测器作为RPN。候选区域网络 (Region Proposal Network, RPN) 作为 Faster R-CNN 的一个子模块,将为 Faster R-CNN 的第二阶段产生候选区域。在 MMDetection 里大多数的二阶段检测器使用 作为候选区域网络来产生候选区域。然而,任何的单阶段检测器都可以作为候选区域网络,是因为他们对边界框的预测可以被视为是一种候选区域,并且因此能够在 R-CNN 中得到改进。因此在 MMDetection v3.0 中会支持将单阶段检测器作为 RPN 使用。
接下来我们通过一个例子,即如何在 中使用一个无锚框的单阶段的检测器模型 作为 RPN ,详细阐述具体的全部流程。
主要流程如下:
- 在 Faster R-CNN 中使用
FCOSHead作为RPNHead - 评估候选区域
- 用预先训练的 FCOS 训练定制的 Faster R-CNN
一、在 Faster R-CNN 中使用 FCOSHead 作为 RPNHead
为了在 Faster R-CNN 中使用 FCOSHead 作为 RPNHead ,我们应该创建一个名为 configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py 的配置文件,并且在 configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py 中将 rpn_head 的设置替换为 bbox_head 的设置,此外我们仍然使用 FCOS 的瓶颈设置,步幅为[8,16,32,64,128],并且更新 bbox_roi_extractor 的 featmap_stride 为 [8,16,32,64,128]。相关配置如下:
_base_ = [
'../_base_/models/faster-rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
以下是../_base_/models/faster-rcnn_r50_fpn.py的原始父类模型model设置(节选)
model = dict(
# 从 configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py 复制
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5,
init_cfg = dict(
type='Kaiming', layer='Conv2d', distribution='uniform')),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=2,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
以下是configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py 的模型model复写设置
model = dict(
# 从 configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py 复制
neck=dict(
start_level=1,
add_extra_convs='on_output', # 使用 P5
relu_before_extra_convs=True),
rpn_head=dict(
_delete_=True, # 忽略未使用的旧设置
type='FCOSHead',
num_classes=1, # 对于 rpn, num_classes = 1,如果 num_classes > 1,它将在 TwoStageDetector 中自动设置为1
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
roi_head=dict( # featmap_strides 的更新取决于于颈部的步伐
bbox_roi_extractor=dict(featmap_strides=[8, 16, 32, 64, 128])))
与原始配置的对比结果
Neck (FPN)
在原始配置中,FPN的初始化参数被指定,并且没有提到start_level、add_extra_convs以及relu_before_extra_convs。而在修改后的配置中,我们看到了这些参数的添加:
start_level=1: 指定FPN从哪个级别的特征图开始融合,这里是从第二个级别开始(通常C2,即in_channels中的256通道那一层)。add_extra_convs='on_output': 表示在最后一个输入特征图之后添加额外的卷积层,以产生更多的输出特征图。这对于增加模型对小物体的检测能力是有帮助的。relu_before_extra_convs=True: 在额外的卷积层之前应用ReLU激活函数。
RPN Head
原始配置中使用的是传统的RPN Head,而在修改后的配置中,RPN Head被替换为了FCOS Head:
_delete_=True: 这意味着删除原配置中的RPN Head设置。type='FCOSHead': 使用FCOS Head代替RPN Head。FCOS是一种无锚框的目标检测方法,这意味着它不再依赖于预定义的锚框来生成候选区域。- 其他参数,如
num_classes=1、stacked_convs=4、feat_channels=256等,都是针对FCOS Head的具体配置,比如使用堆叠的卷积层、特征通道数等。 - 损失函数也从RPN的交叉熵损失和L1损失变更为FCOS的Focal Loss、IoU Loss以及Centerness Loss,这反映了FCOS与RPN在损失计算上的差异。
ROI Head
对于ROI Head,原始配置中没有明确提及featmap_strides的更新,但在修改后的配置中,bbox_roi_extractor的featmap_strides被显式设置为与Neck的strides相匹配,这是因为使用了FCOS Head,其步长与FPN的输出特征图步长一致。
学习率
为了避免损失变慢,我们在前1000次迭代而不是前500次迭代中应用预热,这意味着 lr 增长得更慢。相关配置如下:
以下是../_base_/schedules/schedule_1x.py的原始父类训练参数param_scheduler设置(节选)
# learning rate
param_scheduler = [
dict(
type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
dict(
type='MultiStepLR',
begin=0,
end=12,
by_epoch=True,
milestones=[8, 11],
gamma=0.1)
]
以下是configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py 的训练参数param_scheduler复写设置
param_scheduler = [
dict(
type='LinearLR', start_factor=0.001, by_epoch=False, begin=0,
end=1000), # 慢慢增加 lr,否则损失变成 NAN
dict(
type='MultiStepLR',
begin=0,
end=12,
by_epoch=True,
milestones=[8, 11],
gamma=0.1)
]
以下是configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py 完整代码
_base_ = [
'../_base_/models/faster-rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# 修改数据集相关配置
metainfo = {
'classes': ('cat', 'dog'),
'palette':
[(220, 20, 60), (110, 76, 0)]
}
# 自定义数据集中这一步很关键,这决定你的自定义类别映射是否正确且预测类别和预期一致
train_dataloader = dict(dataset=dict(metainfo=metainfo))
test_dataloader = dict(dataset=dict(metainfo=metainfo))
model = dict(
# copied from configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py
neck=dict(
start_level=1,
add_extra_convs='on_output', # use P5
relu_before_extra_convs=True),
rpn_head=dict(
_delete_=True, # ignore the unused old settings
type='FCOSHead',
# num_classes = 1 for rpn,
# if num_classes > 1, it will be set to 1 in
# TwoStageDetector automatically
num_classes=1,
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
roi_head=dict( # update featmap_strides
bbox_roi_extractor=dict(featmap_strides=[8, 16, 32, 64, 128])))
# learning rate
param_scheduler = [
dict(
type='LinearLR', start_factor=0.001, by_epoch=False, begin=0,
end=1000), # Slowly increase lr, otherwise loss becomes NAN
dict(
type='MultiStepLR',
begin=0,
end=12,
by_epoch=True,
milestones=[8, 11],
gamma=0.1)
]
然后,我们可以使用下面的命令来训练我们的定制模型:
CUDA_VISIBLE_DEVICES=0,1,9 ./tools/dist_train.sh \
configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py \
3 \
--work-dir work_dirs/faster-rcnn_r50_fpn_fcos-rpn_1x_coco
训练结果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.806
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.988
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.938
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.752
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.823
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.843
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.843
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.843
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.779
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.858
06/27 20:38:47 - mmengine - INFO - bbox_mAP_copypaste: 0.806 0.988 0.938 -1.000 0.752 0.823
06/27 20:38:47 - mmengine - INFO - Epoch(val) [12][246/246] coco/bbox_mAP: 0.8060 coco/bbox_mAP_50: 0.9880 coco/bbox_mAP_75: 0.9380 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: 0.7520 coco/bbox_mAP_l: 0.8230 data_time: 0.0018 time: 0.0334
将单阶段检测器用作区域提议网络(RPN,Region Proposal Network)是一种常见的实践,尤其是在构建更复杂的检测系统时。传统上,RPN是在两阶段检测器(如Faster R-CNN)中使用的,用于生成潜在的物体边界框(候选区域)。
使用单阶段检测器作为RPN的优势
1. 速度提升
单阶段检测器通常设计为实时检测,具有较高的推理速度。将它们用作RPN可以显著提高整个系统的处理速度,因为它们能够快速生成大量高质量的候选区域。
2. 准确性
尽管单阶段检测器在小物体检测上可能不如两阶段检测器准确,但它们在大中型物体上的表现通常很好。这意味着它们可以有效地产生包含物体的候选区域,这对于后续的精确定位和分类步骤至关重要。
3. 简化架构
使用单阶段检测器作为RPN可以简化整体架构。传统的两阶段检测器需要一个RPN网络和一个后续的检测网络,而将单阶段检测器集成进来可以减少模型的复杂性,有时甚至可以实现端到端的训练和推理流程。
4. 灵活性
单阶段检测器的灵活性意味着它们可以容易地调整以适应不同的应用场景。例如,可以通过修改锚点大小、比例或特征图层来优化RPN的性能,以更好地适应特定的检测任务。
二、评估候选区域
候选区域的质量对检测器的性能有重要影响,因此,我们也提供了一种评估候选区域的方法。和上面一样创建一个新的名为 configs/rpn/fcos-rpn_r50_fpn_1x_coco.py 的配置文件,并且在 configs/rpn/fcos-rpn_r50_fpn_1x_coco.py 中将 rpn_head 的设置替换为 bbox_head 的设置。
_base_ = [
'../_base_/models/rpn_r50_fpn.py', '../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
val_evaluator = dict(metric='proposal_fast')
test_evaluator = val_evaluator
# 修改数据集相关配置
metainfo = {
'classes': ('cat', 'dog'),
'palette':
[(220, 20, 60), (110, 76, 0)]
}
# 自定义数据集中这一步很关键,这决定你的自定义类别映射是否正确且预测类别和预期一致
train_dataloader = dict(dataset=dict(metainfo=metainfo))
test_dataloader = dict(dataset=dict(metainfo=metainfo))
model = dict(
# 从 configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py 复制
neck=dict(
start_level=1,
add_extra_convs='on_output', # 使用 P5
relu_before_extra_convs=True),
rpn_head=dict(
_delete_=True, # 忽略未使用的旧设置
type='FCOSHead',
num_classes=1, # 对于 rpn, num_classes = 1,如果 num_classes >为1,它将在 rpn 中自动设置为1
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)))
假设我们在训练之后有检查点 ./work_dirs/faster-rcnn_r50_fpn_fcos-rpn_1x_coco/iter_5904.pth ,然后,我们可以使用下面的命令来评估建议的质量。
CUDA_VISIBLE_DEVICES=0,1,9 ./tools/dist_test.sh \
configs/rpn/fcos-rpn_r50_fpn_1x_coco.py \
work_dirs/faster-rcnn_r50_fpn_fcos-rpn_1x_coco/iter_5904.pth \
3 \
--out fcos-rpn-result.pkl
测试结果如下:
/home/miqi/mmdetection/mmdet/evaluation/functional/recall.py:39: RuntimeWarning: invalid value encountered in divide
recalls[:, i] = (_ious >= thr).sum(axis=1) / float(total_gt_num)
06/27 21:21:33 - mmengine - INFO -
+------+-----+------+-----+------+-----+------+-----+------+--------------------+------+
| | 0.5 | 0.55 | 0.6 | 0.65 | 0.7 | 0.75 | 0.8 | 0.85 | 0.8999999999999999 | 0.95 |
+------+-----+------+-----+------+-----+------+-----+------+--------------------+------+
| 100 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan |
| 300 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan |
| 1000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan |
+------+-----+------+-----+------+-----+------+-----+------+--------------------+------+
06/27 21:21:33 - mmengine - INFO -
AR@100 nan
AR@300 nan
AR@1000 nan
06/27 21:21:34 - mmengine - INFO - Results has been saved to fcos-rpn-result.pkl.
06/27 21:21:34 - mmengine - INFO - Epoch(test) [246/246] coco/AR@100: nan coco/AR@300: nan coco/AR@1000: nan data_time: 0.0021 time: 0.0469
尚不清楚为什么出现nan问题,可能与数据集训练结果 Average Recall(AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000有关。Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000这一结果表明在评估模型在检测小尺寸目标时的召回率性能时遇到了异常。具体而言,这通常意味着计算召回率的标准化过程中出现了问题,导致无法得到一个有效的量化指标。在目标检测的标准评估中,AR值应该是一个介于0和1之间的数值,表示在考虑最多1000个检测结果的前提下,模型能够召回所有实际存在的小目标(根据IoU阈值从0.5到0.95)的比例。
出现-1.000这样的非正常值,可能的直接原因包括但不限于:
- 评估逻辑错误:代码中处理召回率计算的部分可能存在逻辑错误,特别是在处理边界情况(如分母为零时尝试做除法运算)时。
- 数据异常:数据集中可能存在的问题,比如小尺寸目标的标注极其稀少或完全缺失,或者这些目标的标注质量不高,导致在计算召回率时无法匹配到任何预测结果。
- 评估配置错误:评估设置中可能有误,比如不正确地设置了IoU阈值范围、最大检测数或其他参数,影响了召回率的正确计算。
三、用预先训练的 FCOS 训练定制的 Faster R-CNN
预训练不仅加快了训练的收敛速度,而且提高了检测器的性能。因此,我们在这里给出一个例子来说明如何使用预先训练的 FCOS 作为 RPN 来加速训练和提高精度。假设我们想在 Faster R-CNN 中使用 FCOSHead 作为 rpn_head,并加载预先训练权重来进行训练 fcos_r50-caffe_fpn_gn-head_1x_coco。 配置文件 configs/faster_rcnn/faster-rcnn_r50-caffe_fpn_fcos- rpn_1x_copy .py 的内容如下所示。注意,fcos_r50-caffe_fpn_gn-head_1x_coco 使用 ResNet50 的 caffe 版本,因此需要更新 data_preprocessor 中的像素平均值和 std。
_base_ = [
'../_base_/models/faster-rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# 修改数据集相关配置
metainfo = {
'classes': ('cat', 'dog'),
'palette':
[(220, 20, 60), (110, 76, 0)]
}
# 自定义数据集中这一步很关键,这决定你的自定义类别映射是否正确且预测类别和预期一致
train_dataloader = dict(dataset=dict(metainfo=metainfo))
test_dataloader = dict(dataset=dict(metainfo=metainfo))
model = dict(
data_preprocessor=dict(
mean=[103.530, 116.280, 123.675],
std=[1.0, 1.0, 1.0],
bgr_to_rgb=False),
backbone=dict(
norm_cfg=dict(type='BN', requires_grad=False),
style='caffe',
init_cfg=None), # the checkpoint in ``load_from`` contains the weights of backbone
neck=dict(
start_level=1,
add_extra_convs='on_output', # 使用 P5
relu_before_extra_convs=True),
rpn_head=dict(
_delete_=True, # 忽略未使用的旧设置
type='FCOSHead',
num_classes=1, # 对于 rpn, num_classes = 1,如果 num_classes > 1,它将在 TwoStageDetector 中自动设置为1
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
roi_head=dict( # update featmap_strides due to the strides in neck
bbox_roi_extractor=dict(featmap_strides=[8, 16, 32, 64, 128])))
load_from = 'https://download.openmmlab.com/mmdetection/v2.0/fcos/fcos_r50_caffe_fpn_gn-head_1x_coco/fcos_r50_caffe_fpn_gn-head_1x_coco-821213aa.pth'
训练命令如下:
CUDA_VISIBLE_DEVICES=0,1,9 ./tools/dist_train.sh \
configs/faster_rcnn/faster-rcnn_r50-caffe_fpn_fcos-rpn_1x_coco.py \
3 \
--work-dir work_dirs/faster-rcnn_r50-caffe_fpn_fcos-rpn_1x_coco
训练结果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.829
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.984
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.954
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.761
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.848
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.865
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.865
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.865
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.793
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.883
06/28 00:31:26 - mmengine - INFO - bbox_mAP_copypaste: 0.829 0.984 0.954 -1.000 0.761 0.848
06/28 00:31:26 - mmengine - INFO - Epoch(val) [12][246/246] coco/bbox_mAP: 0.8290 coco/bbox_mAP_50: 0.9840 coco/bbox_mAP_75: 0.9540 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: 0.7610 coco/bbox_mAP_l: 0.8480 data_time: 0.0018 time: 0.0331





![World of Warcraft [CLASSIC] Level 70 Dire Maul (DM)](https://i-blog.csdnimg.cn/direct/8218db7bc55e45fb8da902c5739148ec.png)