前言:
我已经好久没写过博客了,这几天确实有点偷懒了,上次博客我们已经讲完了指针的部分内容,但我觉着没有习题是不够的,于是我出了这一篇番外篇,来让各位读者朋友们进行指针强化,这些题目都是小编在上课时老师讲过的,所以我写这一篇博客来回忆以前学过的内容,行了,废话不多说,进入正文喽!

目录:
1.数组与指针相关习题的讲解
1.1.一维数组
1.2.字符数组
1.3 .二维数组
正文:
1.数组与指针相关习题的讲解
1.1.一维数组
废话不多说,我们先把题目通过代码的方式展示一下,让读者朋友们了解完题目以后,自己思考一会,等会我直接给先解析一波,最后给上答案(代码运行之后的样子),后面每个题都是这么做的,小编就不一一叙述了,废话不多说直接上代码:
int main()
{
int a[] = { 1,2,3,4 };
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof(a + 0));
printf("%zd\n", sizeof(*a));
printf("%zd\n", sizeof(a + 1));
printf("%zd\n", sizeof(a[1]));
printf("%zd\n", sizeof(&a));
printf("%zd\n", sizeof(*&a));
printf("%zd\n", sizeof(&a + 1));
printf("%zd\n", sizeof(&a[0]));
printf("%zd\n", sizeof(&a[0] + 1));
}大家先思考一下,小编这里先直接解析了,首先我们先从第一行代码来看,对于第一行代码,小编在之前在一篇文章说过sizeof(数组名)怎么计算,下面小编附上链接,有兴趣的读者朋友可以去看看:深入理解并打败C语言难关之一————指针(3)-CSDN博客 。
这里小编也说一下,其实sizeof(数组名)计算的是整个数组所占用的内存(长度),所以第一行应该打印16;
再来看第二行,第二行的代码括号里面并不仅仅是数组名,加了0之后说明括号里面的应该是数组首元素的地址,这个和操作系统有关,所以是4 / 8个字节;
第三行中的sizeof里面同样也不是数组名,所以不是特殊情况,*a是对数组第一个元素的解引用,所以计算的应该是第一个元素的大小,所以是4个字节;
第四行其实和第二行是一个意思的,首先这个不是特殊情况,所以a是首元素的地址,加1后变成了第二个元素的地址,这个和操作系统有关,所以也是4 / 8个字节;
第五行也不是特殊情况,这个是指的数组第二个元素,所以计算的数组第二个元素的大小,所以应该是4个字节;
第六行同样也不是特殊的情况,那么直接看括号里面的,里面存放着整个数组的地址(这是数组名的第二个特殊的例子,等会我会细讲),对于地址的大小,就是取决于操作空间,所以应该是4 / 8个字节
第七行也不是特殊情况,括号里面是对整个数组的地址进行解引用操作,那么解引用完后对应着整个数组的大小,所以是16个字节,其实这里可以当作,&和*两个操作符进行了抵消,最后呈现的其实是数组名,对应着特殊情况,所以是16个字节!
第八行同样也不是特殊情况,首先,对数组名取地址代表的是取出了整个数组的地址,之后加一其实已经数组越界了,不过sizeof不管这些,反正越界后还是地址,所以应该是4 / 8个字节
第九行,取地址符也代表的不是数组名,所以这个其实就是首元素的地址,对于地址的大小,它们都是固定的,所以应该是4 / 8个字节
第十行,这个其实就是第九行的知识,然后加一后,变成了第二个元素的地址,本质还是地址,所以应该是4 / 8个字节!
这个便是这个题的解析,是不是感觉很有趣,这个其实涉及到了前面的知识点,下面废话不多说,展示一下这个题的运行结果


可以看出小编并没有说错,屏幕前的你全对了吗?没对也没关系,失败是人生中常有的是事,你每错一次,就会代表你有一个知识点没有记牢,早发现错误早改正,之后就会减少犯错,不要因为一次失败就否定自我 !废话不多说,进入下一个题:
1.2.字符数组
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr + 0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr + 1));
printf("%zd\n", sizeof(&arr[0] + 1));
}先从第一行开始说,这个很完美的符合特殊情况,所以它计算的是整个数组的大小,我们通过看字符数组里面存储的字节数来计算大小,一共是6个字符,一个字符一个字节,所以对应着6个字节 !
第二行可能很多读者朋友认为这个是特殊情况,但其实不是,特殊情况里面存放的仅仅是数组名,而这个存放着的是数组名 + 0,所以仅仅就是首元素的地址,对应地址,大小应该是取决于操作系统,大小是4 / 8个字节!
第三行同样也不是特殊情况,里面存放的是数组名的解引用,所以对应着的应该是首元素,也就是’a‘,大小应该是1个字节!
第四行一眼不是特殊情况,这个就是代表着第二个元素,也可以写成*(arr + 1),大小是1个字节!
第五行代表的是对于数组名进行取地址操作符,所以其实算另一个特殊情况,但是,无论怎么样,都改变不了整个是对于地址长度计算的事实,所以大小应该是4 / 8个字节!
第六个其实在上面那个题都体现了,总之,这个还是地址,地址的大小是固定的,取决于操作系统的,所以大小是 4 / 8个字节!
第七个上面也说过,大小还是4 / 8个字节!
下面直接放上运行结果的图片 读者朋友们是否做对了?如果有错一定要查阅相关知识点在复习一下,废话不多说,下面进入下入下一个字符数组的练习题
读者朋友们是否做对了?如果有错一定要查阅相关知识点在复习一下,废话不多说,下面进入下入下一个字符数组的练习题
int main()
{
char arr[] = "abcdef";
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr + 0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr + 1));
printf("%zd\n", sizeof(&arr[0] + 1));
}对于第一行代码,符合sizeof的特殊情况,所以计算的应该是整个arr数组的长度,这里会有个小坑,我们不难看出,sizeof此时里面存放的是字符串,字符串其实有一个隐藏字符'\0',这个代表着字符串的结尾,所以此时计算的应该是六加一个字节,也就是7个字节!
对于第二行代码,此时arr已经是加0了,所以不符合特殊情况,此时arr就是数组首元素的地址,对于地址的长度是跟操作系统有关的,所以大小应该是4 / 8个字节!
对于第三行代码,此时是对arr进行解引用,没有涉及到特殊的情况,所以此时就是计算第一个元素的长度,而我们不难发现,此时数组的类型是字符,所以是1个字节!
对于第四行代码,其实这个和第三行的代码是差不多的,这个更是指的数组对应下标的元素,所以大小应该也是1个字节!
对于第五行代码,这里也不是特殊情况,此时是对arr进行了取地址操作,这里是代表着的数组名第二个特殊情况,此时代码代表的是整个数组的地址,由于取到的是地址,所以还是4 / 8个字节!
对于第六行的代码,这个和上一行的代码也有很强的重复性,此时涉及到了指针加减整数的知识,我也写过类似的文章,下面放上链接,如果读者朋友有些不知道的可以看一下:深入理解并打败C语言难关之一————指针(1)-CSDN博客,所以这里其实已经指向了超出数组外的元素的地址了,不过sizeof是不考虑越界这种问题的,就像我上面所说的,这终究还是一个地址,所以大小依然是4 / 8个字节!
对于最后一行代码,同样这也不是特殊情况,这里对数组首元素进行了取地址操作,其实这样同样也可以写成数组名,因为数组名就是数组首元素的地址,此时进行了加一后,变成了第二个元素的地址,所以大小应该是4 / 8个字节!
以上便是对于这个题目详细的解释,下面来放运行情况:
 以上便是运行结果,读者朋友们一定要记着做完了在看答案,这样才会有自己的提高,要有自己的思考过程,废话不多说,下面进入字符数组的下一个练习题:
以上便是运行结果,读者朋友们一定要记着做完了在看答案,这样才会有自己的提高,要有自己的思考过程,废话不多说,下面进入字符数组的下一个练习题:
#include<stdio.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%zd\n", strlen(arr));
printf("%zd\n", strlen(arr + 0));
printf("%zd\n", strlen(*arr));
printf("%zd\n", strlen(arr[1]));
printf("%zd\n", strlen(&arr));
printf("%zd\n", strlen(&arr + 1));
printf("%zd\n", strlen(&arr[0] + 1));
return 0;
}再说这个之前,先来介绍一下strlen函数的作用,它是来计算’\0‘之前字符个数的,这个函数以后我会详细介绍的,读者朋友们可以先记住这个函数必须是从地址开始算个数,它读取的数据是地址,而不是通过数来进行运算,下面进入解释环节!

对于第一行代码,函数里面是数组名,并没有进行取地址操作,所以此时指的是数组第一个元素的地址,从数组第一个元素开始往后找'\0',细心的读者朋友可能已经发现了这个数组中我并还没有写'\0',所以此时strlen会一直往后计算个数,直到找到’\0‘为止,所以此时,字符的个数是随机的!(其实此时编译器也会报出警告,下面请看警告内容)
![]()
对于第二行代码,其实这个和第一行代码是一样的,只不过这个多了个+0,数组名加0后还会是数组名,所以没有改变,个数还是随机的!
对于第三行代码 ,这个就开始出现问题了,小编在刚开始说过,此函数是通过地址来找到相应的元素的,此时括号里面放着的是数组首元素,是一个数,所以此时代码会出问题,运行代码的时候会运行不完,无法计算个数!下面来看调试图:
 此时展示了调试的重要性,所以读者朋友平常代码出现问题的时候一定记着先自己调试,实在不会的时候才去咨询网络或者大佬。
此时展示了调试的重要性,所以读者朋友平常代码出现问题的时候一定记着先自己调试,实在不会的时候才去咨询网络或者大佬。
对于第四行代码,这个就和上一行的代码出现的同样的错误,此时指的是数组第二个元素的数,所以是会出问题的,无法计算个数!
对于第五行代码,此时括号里面是数组名另一个特殊情况,&arr代表的是取出了数组所有的地址,不过,此时还是指向数组首元素的地址的,所以还是从第一个元素开始读取字符的个数的,同样的,由于没有’\0‘,所以个数还是随机的!
对于第六行代码,此时对于整个数组地址进行加一处理了,此时其实已经越界了,不过strlen函数也不管你是否越界,它只是想读到'\0'然后停止,所以个数还是随机的!
对于第七行代码,此时取地址符的对象并不是数组名,而是数组中第一个元素的地址,所以可以把它看做成数组名,此时进行了加1处理,由于还是没有'\0',所以个数还是随机的!
下面小编通过两个编译器来给大家展示结果(VS2022,VS2010),并且小编还把无法进行运行的给注释掉了,为了展示其他的效果:
VS2022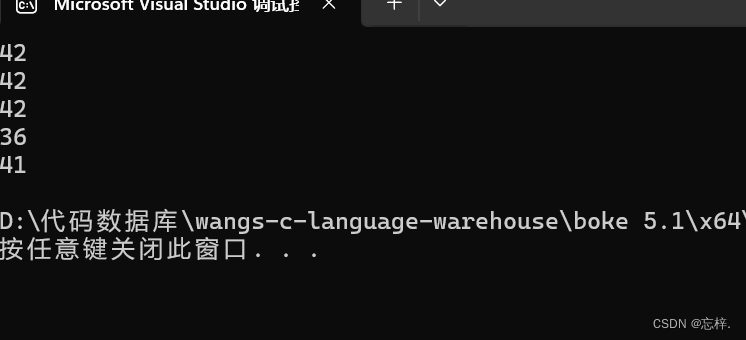
VS2010
 可以很清晰的看出两个编译器的结果并不相同,所以其实这些数都是随机的,读者朋友一定好好明白这个题的结果为什么这么出,至于strlen函数,我会在不久写一篇专属于字符以及字符串的函数详解,大家敬请期待,废话不多说,进入字符数组最后的题:
可以很清晰的看出两个编译器的结果并不相同,所以其实这些数都是随机的,读者朋友一定好好明白这个题的结果为什么这么出,至于strlen函数,我会在不久写一篇专属于字符以及字符串的函数详解,大家敬请期待,废话不多说,进入字符数组最后的题:
int main()
{
char arr[] = "abcdef";
printf("%zd\n", strlen(arr));
printf("%zd\n", strlen(arr + 0));
//printf("%zd\n", strlen(*arr));
//printf("%zd\n", strlen(arr[1]));
printf("%zd\n", strlen(&arr));
printf("%zd\n", strlen(&arr + 1));
printf("%zd\n", strlen(&arr[0] + 1));
return 0;
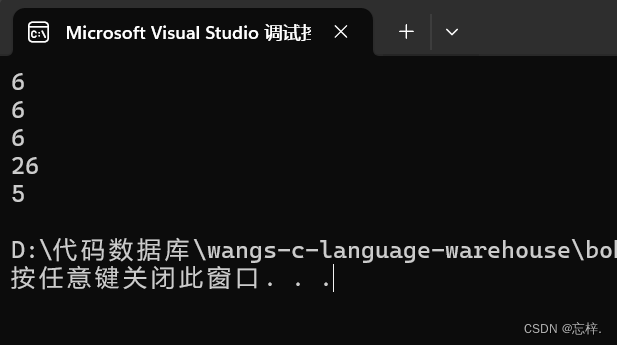
}对于第一行代码,其实解释和上面的都一样了,不过唯一和上面有区别的就是这个数组存放的是字符串,所以此时可以正常计算字符个数了,所以是 6个字符!
对于第二行代码,一个样的,我就不多说了,这个题的解释和上面的解释都一样了,不过同样的,此时数组里面存放的是字符串,所以现在不再是随机数了,此时应该是6个字符!
对于第三,第四行代码,请参考上题解释,都是一个类型的,这里我就不过多叙述了。
对于第五行代码,此时取地址符是取到整个数组的地址,不过此时还是指向的数组第一个元素的地址,所以此时这里和第一行代码其实是一个计算逻辑,最后得出来依旧是6个字符!
对于第六行代码,此时取地址符取到了整个数组的地址,加一后此时已经跳过了'\0'了,所以此时的大小是随机的,直到找到下一个'\0'为止!大家一定要记住这个特例 !
对于第七行代码,此时取地址操作符取到底是数组第一个元素的地址,所以近似可以看作为数组名,所以加一指向的元素成了第二个元素的地址,所以是减少了一个字符的读取,所以应该是5个字符!
下面直接进入最后结果的展示页:
读者朋友们一定要熟练的明白字符数组的应用,这些题都是一些基础题,大家一定要好好掌握,把基础给打牢了!下面我们进入本篇最后一节内容,关于二维数组练习题的说明!

1.3.二维数组
二维数组同样也有着很多的重点,下面不多废话,直接上题:
int main()
{
int a[3][4] = { 0 };
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof(a[0][0]));
printf("%zd\n", sizeof(a[0]));
printf("%zd\n", sizeof(a[0] + 1));
printf("%zd\n", sizeof(*(a[0] + 1)));
printf("%zd\n", sizeof(a + 1));
printf("%zd\n", sizeof(*(a + 1)));
printf("%zd\n", sizeof(&a[0] + 1));
printf("%zd\n", sizeof(*(&a[0] + 1)));
printf("%zd\n", sizeof(*a));
printf("%zd\n", sizeof(a[3]));
return 0;
}对于第一行的代码,首先我们要清楚,二维数组的数组名是二维数组第一行的地址,而不是首元素的地址,这里要和一维数组的数组名区分开,不过此时符合了特殊情况,所以计算的应该是整个数组的长度,所以应该是3 * 4 * 4,48个字节!
对于第二行的代码,此时并不属于任何特殊的情况,所以我们先看内容,此时这里指的是首元素,所以我们仅仅计算首元素的长度就好了,所以大小应该是4个字节!
对于第三行的代码,首先这个并不是特殊情况,并且此时是a[0],很多读者朋友可能看到这里会有点疑惑,这么些它合理吗?这又是代表着什么意思,小编为了让各位读者朋友更好的理解,下面放上图解:

可以很清晰的看出a[0]代表的是数组首行,回想一下二维数组的模拟,我们是通过指针数组来进行对于二维数组的模拟,所以我们其实可以把二维数组看成由好几个一维数组合体拼接的数组,所以此时a[0]其实也代表的是特殊情况,此时是计算的首行的长度,所以大小应该是16个字节!
对于第四行的代码,其实这里是对于基于上述解释来写的,此时是指针进行加1,所以应该对应着的是第一行第二个元素的地址,由于此时sizeof内部并不是单独放置的数组名,所以此时算的是地址的大小,取决于操作系统,所以应该是4 / 8个字节的大小!
对于第五行的代码,此时是对于上面代码进行的解引用,我们直到此时指针指向了第二行元素整体的地址,不过,指针刚开始还是指向首元素的,所以进行了解引用操作后,其实是计算的第二行元素首元素的大小,所以是4个字节!
对于第六行的代码,并没有符合我们的特殊情况,其实这个和第四行的代码有异曲同工之妙,所以还是计算的地址,长度是4 / 8个字节!
对于第七行的代码,我们知道,a是二维数组的数组名,更是二维数组首行的地址,此时进行加一操作以后,会让指针指向第二行的元素,在进行解引用操作后其实是对第二行元素进行解引用操作,所以解引用后的应该是第二行数组的大小,所以大小是16个字节!
对于第八行的代码,此时我们是对a[0]先进行了取地址操作,此时的a[0]实则是第一行元素首元素的地址,在进行取地址操作的时候,符合特殊情况,取出了第一行元素的地址,在进行加一后变成了第二行数组的地址,由于是地址,所以是4 / 8个字节!
对于第九行的代码,基于上一行代码的解释,此时是对第二行数组的数组名进行解引用操作,所以此时取出来的应该是整行数组的大小,所以是16个字节!
对于第十行的代码,此时是存放的数组首行的地址,*a已经是第一行了,等同于a[0],此时是把第一行的数组名放入sizeof里面,属于特殊情况,所以应该是16个字节!
对于第十一行代码,此时是数组第四行首元素的地址,此时数组其实已经越界了,不过,sizeof可不管你越不越界,它只会进行默默的计算,所以sizeof里面放着数组名,大小是16个字节!
下面我们对结果进行展示:

可以看出小编并没有说错,所以读者朋友们一定要好好理解二维数组,这部分的知识很重要,以后我们在进行工作的时候可能会遇到相关的问题。

总结:
可算写完这一篇博客,这一篇博客我已经拖欠了一周多了,老实说小编上周就已经起草了,只是一直没有写,今天我痛定思痛,决定写完这篇博客,读者朋友们一定要好好理解其中的内容,由于本文是小编凌晨赶出来的,如果有错误,请在评论区指出,小编已经会认真听取大家的意见。那么,我们下篇博客见啦!