说明
先检查一下昨天启动的worker是否正常工作,然后做一些简单的清洗,存入clickhouse。
内容
1 检查数据
from Basefuncs import *
# 将一般字符串转为UCS 名称
def dt_str2ucs_blockname(some_dt_str):
some_dt_str1 =some_dt_str.replace('-','.').replace(' ','.').replace(':','.')
return '.'.join(some_dt_str1.split('.')[:4])
'''
dt_str2ucs_blockname('2024-06-24 09:30:00')
'2024.06.24.09'
'''
# 测试队列声明
qm = QManager(redis_agent_host = 'http://192.168.0.4:xx/',redis_connection_hash = None,q_max_len= 1000000, batch_size=10000)
qm.info()
target_stream_name = 'xxx'
qm.stream_len(target_stream_name)
2804
获取数据(使用单worker,模式比较简单且性能足够)
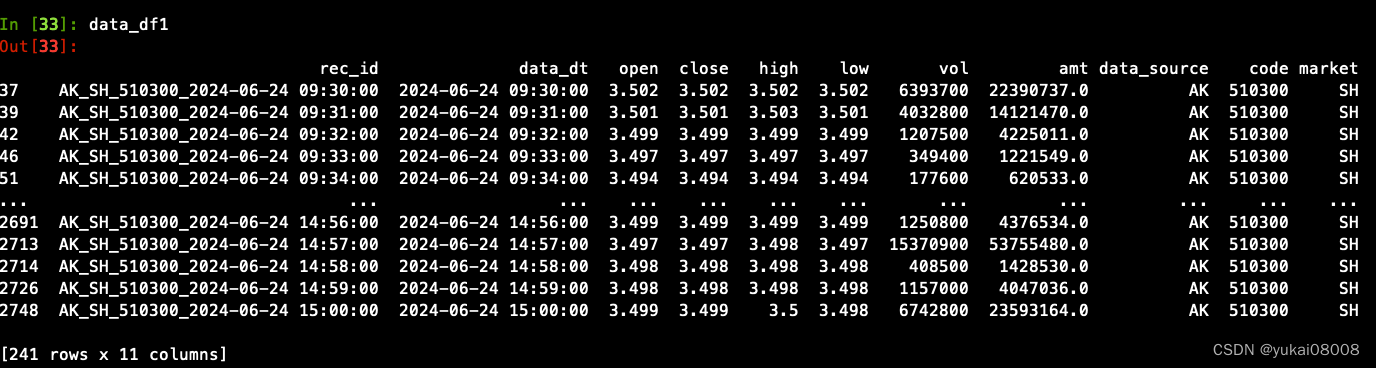
data = qm.xrange(target_stream_name)['data']
data_df = pd.DataFrame(data)
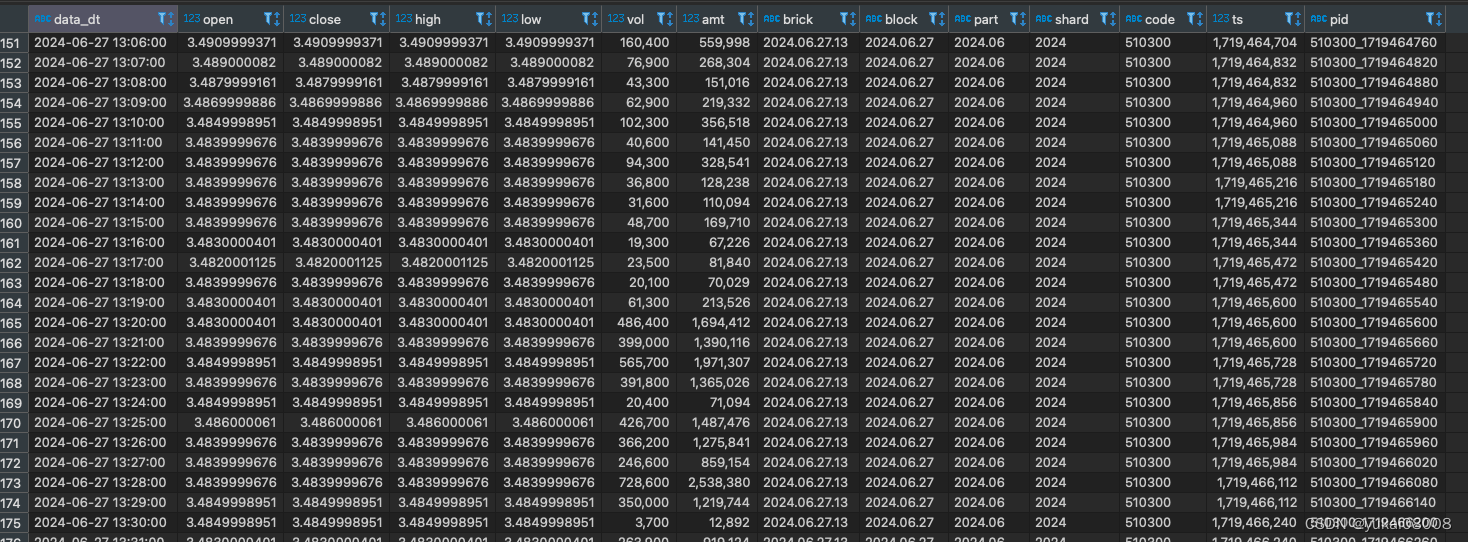
keep_cols = ['rec_id', 'data_dt','open', 'close','high','low','vol', 'amt', 'data_source','code','market']
data_df1 = data_df[keep_cols].dropna().drop_duplicates(['rec_id'])
# 第一次操作,把之前无关的数据删掉
data_df1 = data_df1[data_df1['data_dt'] >='2024-06-24 00:00:00']
向clickhouse发起query,请求每个etf的最大时间,之后要使得新增的数据大于这个时间,另外目标表的字段形如

这是之前做的设计,因为隔的时间有点久都有点忘了。不过这个设计是合理的,后面会看到。
要做的转换也很简单:
- 1 将时间字符转为时间戳
- 2 从日期中分解出shard、part、block和brick
转换段
import time
data_df1['ts'] = data_df1['data_dt'].apply(inverse_time_str).apply(int)
data_df1['brick'] = data_df1['data_dt'].apply(dt_str2ucs_blockname)
data_df1['block'] =data_df1['brick'].apply(lambda x: x[:x.rfind('.')])
data_df1['part'] =data_df1['block'].apply(lambda x: x[:x.rfind('.')])
data_df1['shard'] =data_df1['part'].apply(lambda x: x[:x.rfind('.')])
data_df1['pid'] = data_df1['code'].apply(str) + '_' + data_df1['ts'].apply(str)
keep_cols1 = ['data_dt','open','close','high','low', 'vol','amt', 'brick','block','part', 'shard', 'code','ts', 'pid']
data_df2 =data_df1[keep_cols1]

今天就到这里吧,明晚接着写。
Go on …
昨天疏忽了,数据不应该直接存库,而是应该整理好之后送到队列。然后由默认的worker将数据搬到clickhouse.
2 存数规则
第二步的输入队列BUFF.xxxstream_in,输出队列BUFF.xxx.stream_out。
第一次需要确保对应数据表的存在。clickhouse对数值的要求比较严格,为了避免麻烦,统一设置成Float32。(这样可以用统一的同步worker)。另外clickhouse不支持删除数据,这点倒是比较特别。
但可以支持全部删除数据(保留数据结构) TRUNCATE table market_data_v2
create_table_sql = '''
CREATE TABLE market_data_v2
(
data_dt String,
open Float32,
close Float32,
high Float32,
low Float32,
vol Float32,
amt Float32,
brick String,
block String,
part String,
shard String,
code String,
ts Float32,
pid String
)
ENGINE = MergeTree
ORDER BY (ts )
'''
click_para = gb.getx('sp_global.buffer.lan.xxx.xxx.para')
chc = CHClient(**click_para)
chc._exe_sql(create_table_sql)
chc._exe_sql('show tables')
[('market_data',), ('market_data_v2',)]
etl_worker.py
# 0 记录日志
import logging
from logging.handlers import RotatingFileHandler
logger = logging.getLogger('MyLogger')
handler = RotatingFileHandler('/var/log/workers.log', maxBytes=1024*1024*100, backupCount=5)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# ---------------------------------------- 设置日志
from Basefuncs import *
def tuple_list2dict(tuple_list):
"""
将包含三个元素的tuple列表转换为字典。
参数:
tuple_list (List[Tuple[K, V1, V2]]): 包含键和两个值的tuple的列表。
返回:
Dict[K, Tuple[V1, V2]]: 转换后的字典,其中值是包含两个元素的tuple。
"""
return {key:value1 for key, value1 in tuple_list}
# 将一般字符串转为UCS 名称
def dt_str2ucs_blockname(some_dt_str):
some_dt_str1 =some_dt_str.replace('-','.').replace(' ','.').replace(':','.')
return '.'.join(some_dt_str1.split('.')[:4])
'''
dt_str2ucs_blockname('2024-06-24 09:30:00')
'2024.06.24.09'
'''
# ---------------------------------------- 基本函数
# 测试队列声明
qm = QManager(redis_agent_host = 'http://192.168.0.4:xx/',redis_connection_hash = None,q_max_len= 1000000, batch_size=10000)
qm.info()
source_stream_name ='stream_in'
target_stream_name ='stream_out'
source_stream_len = qm.stream_len(source_stream_name)
target_stream_len = qm.stream_len(target_stream_name)
print('source',source_stream_len)
print('target', target_stream_len)
# qm.ensure_group(target_stream_name)
cur_dt_str = get_time_str1()
if source_stream_len:
is_source_recs = True
else:
is_source_recs = False
logger.info('%s %s source No Recs' %(cur_dt_str,'etl_worker'))
# 获取数据(使用单worker,模式比较简单且性能足够)
# ---------------------------------------- 队列取数,有数据才执行下面
if is_source_recs:
# ---------------------------------------- 取数,取出消息列表和需要的列
# worker 30 秒启动一次
data = qm.xrange(source_stream_name)['data']
data_df = pd.DataFrame(data)
msg_id_list = list(data_df['_msg_id'])
keep_cols = ['rec_id', 'data_dt','open', 'close','high','low','vol', 'amt', 'data_source','code','market']
data_df1 = data_df[keep_cols].dropna().drop_duplicates(['rec_id'])
# 第一次操作,把之前无关的数据删掉
# data_df1 = data_df1[data_df1['data_dt'] >='2024-06-24 00:00:00']
import time
data_df1['ts'] = data_df1['data_dt'].apply(inverse_time_str).apply(int)
data_df1['brick'] = data_df1['data_dt'].apply(dt_str2ucs_blockname)
data_df1['block'] =data_df1['brick'].apply(lambda x: x[:x.rfind('.')])
data_df1['part'] =data_df1['block'].apply(lambda x: x[:x.rfind('.')])
data_df1['shard'] =data_df1['part'].apply(lambda x: x[:x.rfind('.')])
data_df1['pid'] = data_df1['code'].apply(str) + '_' + data_df1['ts'].apply(str)
keep_cols1 = ['data_dt','open','close','high','low', 'vol','amt', 'brick','block','part', 'shard', 'code','ts', 'pid']
data_df2 =data_df1[keep_cols1]
# ------------------------------------- 获取当前数据库已有的数据
# 获取各code最大值
click_para = {'database': 'xx',
'host': '192.168.0.4',
'name': 'xx',
'password': 'xx',
'port': xxx,
'user': 'xx'}
chc = CHClient(**click_para)
'''
这个 SQL 语句的作用是按照 `code` 分组,并为每个 `code` 找到对应的最新日期(`data_dt`),这个最新日期是基于 `ts` 字段的最大值来确定的。`argMax` 函数在这里用于找到每个分组中 `ts` 值最大时对应的 `data_dt` 值。
具体来说,`argMax(data_dt, ts)` 会返回每个 `code` 分组中使得 `ts` 达到最大值的 `data_dt` 值。这意味着对于每个 `code`,查询会找到 `ts` 字段的最大值,并返回对应的 `data_dt` 值,即每个 `code` 的最新数据日期。
最终,这个查询会返回一个结果集,其中包含每个 `code` 以及对应的最新数据日期(`last_data_dt`)。这对于分析每个代码的最新市场数据非常有用。
'''
latest_sql = '''
SELECT
code,
argMax(data_dt, ts) AS last_data_dt
FROM
market_data_v2
GROUP BY
code
'''
# 更新时
latest_date_tuple_list = chc._exe_sql(latest_sql)
latest_date_dict = tuple_list2dict(latest_date_tuple_list)
# ------------------------------------- 使用时间进行过滤
# 筛选新数据
data_df2['existed_dt'] = data_df2['code'].map(latest_date_dict).fillna('')
output_sel = data_df2['data_dt'] > data_df2['existed_dt']
output_df = data_df2[output_sel][keep_cols1]
output_data_listofdict = output_df.to_dict(orient='records')
output_data_listofdict2 = slice_list_by_batch2(output_data_listofdict, qm.batch_size)
for some_data_listofdict in output_data_listofdict2:
qm.parrallel_write_msg(target_stream_name, some_data_listofdict)
del_msg = qm.xdel(source_stream_name, msg_id_list)
logger.info('%s %s del source %s Recs' %(cur_dt_str,'etl_worker',del_msg['data'] ))
将该脚本发布为任务,30秒执行一次同步。
exe_qtv200_etl_worker.sh
#!/bin/bash
# 记录
# sh /home/test_exe.sh com_info_change_pattern running
# 有些情况需要把source替换为 .
# . /root/anaconda3/etc/profile.d/conda.sh
# 激活 base 环境(或你创建的特定环境)
source /root/miniconda3/etc/profile.d/conda.sh
#conda init
conda activate base
cd /home/workers && python3 etl_worker.py
存数成功,后续就自动运行了。