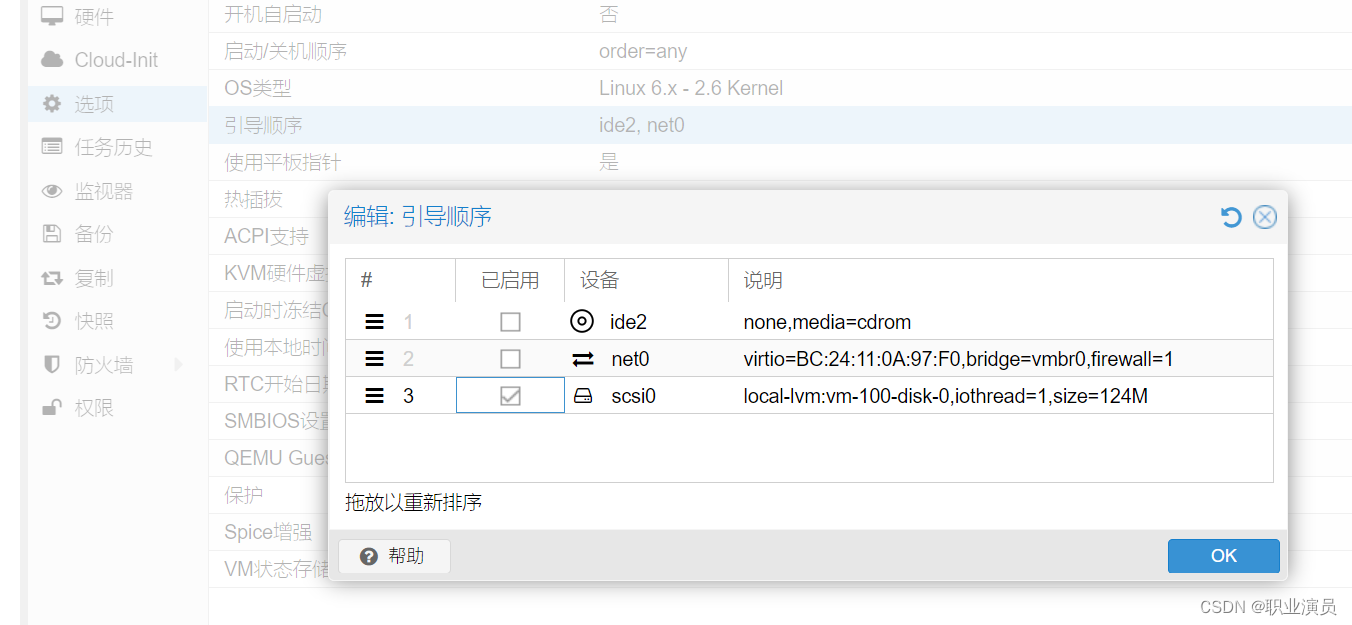
1.简介
1.1目的
在过去的一段时间里,对基于模型蒸馏技术的模型加速方案的方法在多个数据集上进行了一系列的实验。所谓的模型蒸馏技术,简单的来说就是利用一个设计简单的小网络去学习一个设计比较复杂的大网络。特别的有,本次实验针对每一个复杂的(teacher model)大模型,都设计了多个简单的(student model)小模型去学习,并且针对不同的超参数组合,本文给出了多组对比实验。详细的实验结果以及相应实验现象的分析和总结将在下文给出。
1.2范围
本文档描述的代码修改以及实验方法都是基于caffe框架进行的,添加的新层有SoftmaxWithLossWithSoftTargetLabel和SoftmaxWithLossWithLabelSmooth。主要的加速策略是利用参数少的(student model)小模型去学习参数多的(teacher model)大模型,所有的实验都在mnist数据集、cifar10数据集、以及年龄和性别属性相关数据集进行的,其中需要调节的超参数包括温度超参数T,loss比例超参数LAMDA。
1.3定义、首字母缩写词和缩略语
| 序号 | 术语或缩略语 | 说明性定义 |
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 |
1.4 参考资料
《基于模型蒸馏技术的模型加速方案实验设计v2.pdf》
Distill the Knowledge in a Neural Network
2.实验的方法——模型蒸馏
本文档中的实验是基于caffe框架进行的,修改了其中的源码,并添加了新的层,使得这个框架可以按照制定的模型加速方案进行运行和测试。
2.1 为什么需要模型蒸馏
一个很大的DNN往往训练出来的效果会比较好,并且多个DNN一起ensemble的话效果会更加的好,但是当用在实际的应用中的话,过于庞大的DNN ensemble在一起会增大计算量,从而影响应用。于是一个问题就被提出了:有没有一个方法,能使降低网络的规模,但是保持(一定程度上)精确度呢?
Hinton举了一个仿生学的例子,就是昆虫在幼生期的时候往往都是一样的,适于它们从环境中摄取能量和营养;然而当它们成长到成熟期,会基于不同的环境或者身份,变成另外一种形态以适应这种环境。那么对于DNN是不是存在类似的方法?在一开始training的过程中比较的庞杂但是后来当需要拿去deploy的时候,可以转换成一个更小的模型。他把这种方法叫做Knowledge Distillation(KD)。
2.2模型蒸馏的基本原理
这里的distillation方法其实主要用的就是通过一个performance非常好的大网络(有可能是ensemble的)来教一个小网络进行学习。这里我们可以把大网络叫为:teacher network,小网络叫为:student network。至于为什么是希望通过大网络来教小网络而不是直接利用ground truth label来学习,hinton也给了一个例子:比如说在MNIST数据集中,有两个数字“2”,但是写法是不一样的:一个可能写的比较像3(后面多出了一点头),一个写的比较像7(出的头特别的短)。在这样的情况下,ground truth label都是“2”,然而一个学习的很好的大网络会给label “3” 和 “7” 都有一定的概率值,如图1所示。通常叫这种信息为 “soft targets”;相对的,ground truth label 是一种 “hard target” 因为它是one-hot label。总的来说就是,通过大网络的“soft targets”,能得到更加多的信息来更好的训练小网络。

图1 hard target vs. soft target
论文中所提出的上述soft target实际上就是已经训练好的复杂模型的softmax层的输出概率,而其中所提出的“蒸馏”方法在softmax层中引入了一个”温度”参数T,如公式(1)所示:
| qi=expzi/Tjexpzj/T | (1) |
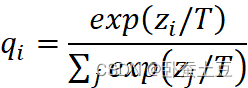
其中zi![]() 表示的是logit,即softmax层的输入;qi
表示的是logit,即softmax层的输入;qi![]() 表示经过softmax层计算后的每个类别的概率;T
表示经过softmax层计算后的每个类别的概率;T![]() 表示的就是上述的温度参数,通常设置为1。不过通过上述温度参数的调整,softmax层的映射曲线更加平缓,因而实例的概率映射将更为集中,便使得目标更加地"soft"。并且有论文中还指出,当transfer set中的标签可得时,将soft target和实际标签的两个目标共同使用作为目标函数将使得其性能更加提高。在训练过程中,作者将迁移样本集中样例输入原复杂模型并通过上述蒸馏softmax得到soft target,并将其作为目标,并在迭代过程中更新温度,训练出细粒度的模型。
表示的就是上述的温度参数,通常设置为1。不过通过上述温度参数的调整,softmax层的映射曲线更加平缓,因而实例的概率映射将更为集中,便使得目标更加地"soft"。并且有论文中还指出,当transfer set中的标签可得时,将soft target和实际标签的两个目标共同使用作为目标函数将使得其性能更加提高。在训练过程中,作者将迁移样本集中样例输入原复杂模型并通过上述蒸馏softmax得到soft target,并将其作为目标,并在迭代过程中更新温度,训练出细粒度的模型。
蒸馏”最简单的形式就是:以从复杂模型得到的“软目标”为目标(这时T比较大),用“转化”训练集训练小模型。训练小模型时T不变仍然较大,训练完之后T改为1。
当“转化”训练集中部分或者所有数据都有标签时,这种方式可以通过一起训练模型使得模型得到正确的标签来大大提升效果。一种实现方法是用正确标签来修正“软目标”,但是论文中发现一种更好的方法是:对两个目标函数设置权重系数。第一个目标函数是“软目标”的交叉熵,这个交叉熵用开始的那个比较大的T来计算。第二个目标函数是正确标签的交叉熵,这个交叉熵用小模型softmax层的logits来计算且T等于1。论文中指出当第二个目标函数权重较低时可以得到最好的结果。整体的结构如图2所示:

图2 模型蒸馏的整体结构
2.3为什么使用soft target会有用

图3 soft target的用处
信息量:
hard target 包含的信息量(信息熵)很低,soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率。)
软化:
问题是像图3左侧的红色0.001这部分,在cross entropy的loss function中对于权重的更新贡献微乎其微,这样就起不到作用。把soft target软化(整体除以一个数值后再softmax),就可以达到右侧绿色的0.1这个数值,这样在后来权重的更新中就有一定的贡献了。
3. 模型蒸馏实验设计
3.1 蒸馏模型训练过程
实验步骤:
1.根据提出的目标问题设计一个或者多个复杂的网络结构(N1,N2,…,Nt)。
2.收集足够多的训练数据,按照常规CNN模型训练流程,训练好1中的一个或者多个复杂网络得到(M1,M2,…,Mt),记为原始网络。
3.收集简单模型训练数据,此处的训练数据可以是训练原始网络的有标签数据,也可以是额外的无标签数据。
4.修改原始模型(M1,M2,…,Mt)的softmax层中温度参数T为一个较大值如T=20,将3中收集到的样本输入到原始复杂模型中。每一个样本在每个原始模型可以得到其最终的分类概率向量,选取其中概率至最大即为该模型对于当前样本的判定结果。对于t个原始模型就可以得到t个概率向量。那么对这t个概率向量求取均值作为当前样本最后的概率输出向量,记为soft_target label,最后保存到文件中。
5.根据(N1,N2,…,Nt)重新创建一个精简的小网络N0,该网络最后有两个loss,一个是hard loss,即传统的softmaxloss,使用one shot label;另外一个是soft loss,即T>1的softmaxloss,使用我们第4步保存下来的soft target label。
6.设置精简的小网络N0的softmax层温度参数与原始复杂模型产生soft target label时所采用的温度一致,如T=20,按照常规模型训练精简的小网络得到模型M0。
7.训练完成之后,在实际应用中将精简的小模型中的softmax温度参数重置为1,即采用最原始的softmax,来走前向作为最后输出的小模型。
上述的训练过程可以用图4简单表示:
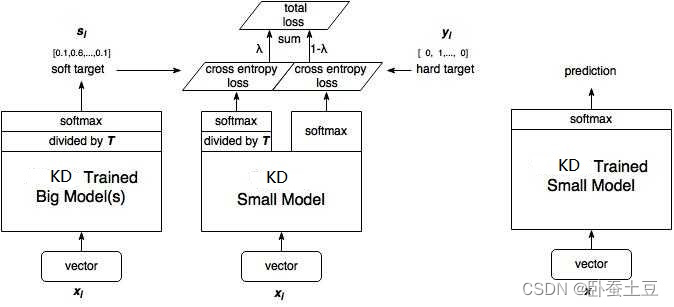
图4 模型蒸馏的训练过程
3.2 论文中的经验
论文中作者认为,由于soft target具有更高的熵,它能比hard target提供更加多的信息,因此可以使用较少的数据以及较大的学习率。将hard和soft的target通过加权平均来作为学生网络的目标函数,soft target所占的权重更大一些。 论文中作者同时还指出,T值取一个中间值时,效果更好,而soft target所分配的权重应该为T^2,hard target的权重为1。 这样训练得到的小模型也就具有与复杂模型近似的性能效果,但是复杂度和计算量却要小很多。
对于distilling而言,复杂模型的作用事实上是为了提高label包含的信息量。通过这种方法,可以把模型压缩到一个非常小的规模。模型压缩对模型的准确率没有造成太大影响,而且还可以应付部分信息缺失的情况。
4.实验结果及其分析
4.1 mnist
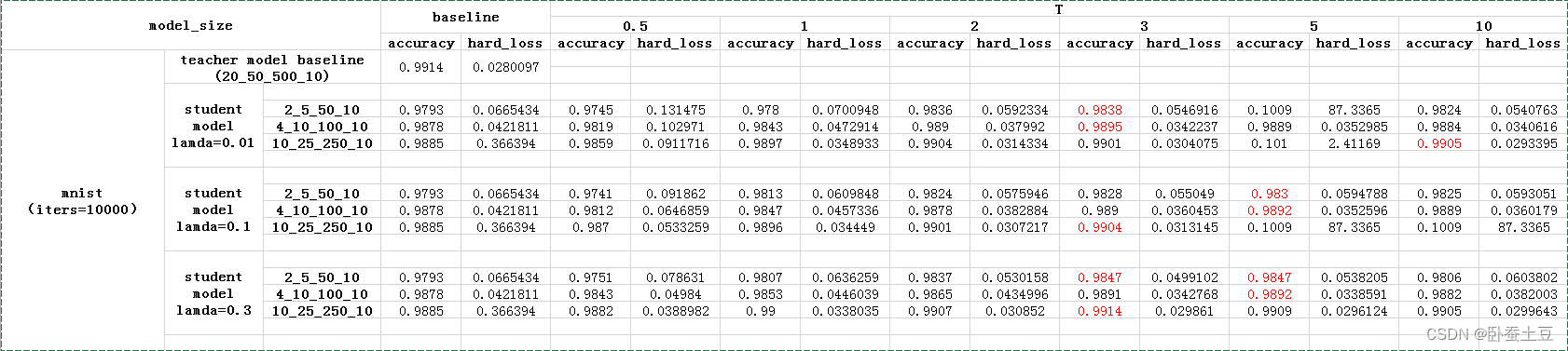
图5 mnist上模型蒸馏的实验结果
从图5中可以看出,teacher model一共有四层参数层,即两个卷积层以及两个全连接层,尺寸为20_50_500_10,其中的数字表示的为caffe中prototxt中每一层的num_output的大小。其精度可以达到很高的精度0.9914;student model这里设计了三组对比实验,相应的尺寸分别为10_25_250_10、4_10_100_10、2_5_50_10。
从图中可以看出:
- 在设置特定的T和lamda的超参时,train_smallnet_from_kd的实验结果都要优于train_smallnet_from_scratch的实验结果,前者表示的是模型蒸馏的结果,后者表示从头训练小模型的结果,即图中的红色部分和small net的baseline进行对比。
- 特别的有模型大小为10_25_250_10即尺寸为原始大模型的一半的时候,当lamda设置为0.3,T设置为3的时候,小模型经过对大模型的学习是可以达到大模型的精度的。
- 第三对于当前的实验对于mnist数据集可以看出,最优值的基本上是在T超参数设置为3左右的时候出现的。
综上所述,当大模型的精度很高的时候,模型蒸馏(知识提取)的效果可以达到很好,并且小模型经过学习是能够达到大模型的那种效果的。
4.2 cifar10

图6 cifar10数据集上模型蒸馏的实验结果
从图6中可以看出,teacher model一共有四层参数层,即两个卷积层以及两个全连接层,尺寸为32_32_64_10,其中的数字表示的为caffe中prototxt中每一层的num_output的大小。其精度不高只有0.7937;student model这里设计了三组对比实验,相应的尺寸分别为16_16_32_10、8_8_16_10、4_4_8_10。
从图中可以看出:
- 在设置特定的T和lamda的超参时,train_smallnet_from_kd的实验结果部分优于train_smallnet_from_scratch的实验结果。这个和mnist的实验结果有点差距。
- 所有的train_smallnet_from_kd的实验结果都达不到最初的大模型的效果。
- 对于当前的实验对于mnist数据集可以看出,最优值的基本上是在T超参数设置为1、2左右。
综上所述,当大模型的精度不高的时候,在特定的小模型尺寸、温度参数T以及lamda参数设置后的模型蒸馏(知识提取)也可以达到一定效果,但是最终达不到原始大模型的精度。
4.3 年龄和性别属性

图7 年龄和性别属性数据集上模型蒸馏的实验结果
从图7中可以看出,teacher model是一个具有12个卷积层CaffeNetConv网络,年龄和性别属性的精度都挺高分别为0.912161和0.98991。而student model分成了三种。第一种为 具有6个卷积层的CaffeNetConv网络,仅对年龄的属性进行模型蒸馏(知识提取);第二种还是具有12个卷积层的CaffeNetConv,但是其每层的num_output的大小减半,仅对年龄的属性进行模型蒸馏(知识提取);第三种的网络结构和第二种的网络结构一致,并且对年龄和性别两个属性同时进行模型蒸馏(知识提取)。其中12layers_half表示的是只对age进行模型蒸馏,12layers_half_both表示的是对age和gender同时进行模型蒸馏。
从图中可以看出:
- 在设置特定的T和lamda的超参时,train_smallnet_from_kd的结果都要优于train_smallnet_from_scratch的结果。这个和mnist的实验结论一样。
- 6层小网络模型在经过多组对比实验中都不能达到原始12层大网络的效果,然而在保持原始深度12层,将参数量减半的小网络在经过模型蒸馏(知识提取)后,却可以达到甚至超过原始12层大网络的精度。比如,当lamda设置为0.3,T设置为3的时候的第二种小网络以及lamda设置为0.1,T设置为3的时候的第三种小网络。
- 对于当前的实验对于年龄以及性别属性数据集可以看出,最优值的基本上是在T超参数设置为3左右。
- 从第二种小网络的实验结果可以看出,随着相应T和lamda超参数的设定,会使得年龄属性的精度上升,但是相反会导致未进行模型蒸馏的另一个分类任务精度的下降。
- 从第三种小网络的实验结果可以看出,将年龄和性别的分类任务都进行模型蒸馏,可以解决上一个问题,性别精度的都有所提高,但是有可能会使得年龄的精度有些许下降(很少)。
原本的年龄属性识别网络中就已经引入了label smooth的思想,这个和模型蒸馏(知识提取)的思想很类似,所以本身年龄属性识别模型蒸馏的效果可能会被弱化。
5.总结
在经过三个数据集上对模型蒸馏(知识提取)的方法进行实验,都表明模型蒸馏方法的有效性。当原始模型精度很高的时候,模型蒸馏的效果往往都会很好,并且在特定的模型T和lamda超参数的组合下,小的student model可以很好的学习到大的teacher model,甚至会超过原始大的网络的精度。相反,当原始teacher model的精度就不高,如cifar10中的实验效果一样,模型蒸馏的效果要差些,可能达不到原始teacher model的精度,甚至差距还挺大。特别的在属性数据集上的实验中可以看出,同样参数量的两种student网络,保持深度缩小宽度的小网络要比缩小深度保持宽度的小网络模型蒸馏的效果会更好。特别的有当原始的teacher model是一个多分类任务的时候,我们的实验表明如果仅对一个任务进行模型蒸馏,会使得其他分类任务的精度下降,而对多个分类任务都进行模型蒸馏的话,虽然没有单独模型蒸馏的效果那么好,但是所有模型的精度都会上升。