文章目录
- 服务器规划
- 服务器环境准备
- 1. 网络测试
- 2. 安装额外软件包
- 3. 安装基础工具
- 4. 关闭防火墙
- 5. 创建用户并配置权限
- 6. 创建目录并设置权限
- 7. 卸载JDK
- 8. 修改主机名
- 9. 配置hosts文件
- 10. 重启服务器
- 配置免密登录
- 安装Java
- 安装Hadoop
- 1. Hadoop部署
- 2. 配置Hadoop
- 3. 格式化Hadoop文件系统
- 4. 启动Hadoop集群
- 5. 验证Hadoop集群
- 注意事项
- 参考文件

搭建一个Hadoop集群涉及到多个步骤,包括服务器规划, 服务器环境准备,配置SSH无密码登录,安装Java,安装Hadoop,配置Hadoop,以及格式化和启动Hadoop集群。以下是在三台CentOS系统服务器上搭建Hadoop集群的必要步骤和详细的描述:
服务器规划
- 准备三台服务器(Hadoop101、Hadoop102、Hadoop103), 确保都已经安装了
CentOS 7.9操作系统。 - 为每台服务器配置静态IP地址,确保它们在同一子网内,并且子网掩码、网关和DNS设置正确。
- 使得三台服务器之间可以互相ping通。
- 确保三台服务器都能够访问互联网。
- 角色规划
Hadoop101作为NameNode和ResourceManager,负责集群的文件系统命名空间和资源管理。Hadoop102作为SecondaryNameNode,辅助NameNode进行元数据备份,不直接处理客户端读写请求。Hadoop101、Hadoop102、Hadoop103作为DataNode和NodeManager,存储实际的数据块并提供计算能力
| Hadoop101 | Hadoop102 | Hadoop103 |
|---|---|---|
| NameNode | SecondaryNameNode | - |
| DataNode | DataNode | DataNode |
| ResourceManager | - | - |
| NodeManager | NodeManager | NodeManager |
服务器环境准备
对每台服务器做如下检查和配置, 下面是在root用户下进行操作。
1. 网络测试
- 确保虚拟机可以正常上网。
ping www.baidu.com
2. 安装额外软件包
- 安装
epel-release以获取更多软件包。yum install -y epel-release
3. 安装基础工具
- 如果是最小系统版,需要安装以下工具:
net-tools:包含ifconfig等网络配置命令。yum install -y net-toolsvim:文本编辑器。yum install -y vim
4. 关闭防火墙
- 停止并禁用防火墙服务。
systemctl stop firewalld systemctl disable firewalld.service
5. 创建用户并配置权限
- 创建
bigdata用户并设置密码。useradd bigdata passwd bigdata - 配置
bigdata用户具有root权限,无需密码即可执行sudo命令。vim /etc/sudoers- 在
/etc/sudoers文件中添加:bigdata ALL=(ALL) NOPASSWD:ALL
- 在
6. 创建目录并设置权限
- 在
/opt目录下创建module和software文件夹。mkdir /opt/module mkdir /opt/software - 修改文件夹的所有者和所属组为
bigdata。chown bigdata:bigdata /opt/module chown bigdata:bigdata /opt/software - 查看文件夹的所有者和所属组。
ls -al /opt
7. 卸载JDK
- 如果服务器预装了JDK,执行以下命令卸载:
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
8. 修改主机名
- 登录到目标服务器:使用SSH或其他远程登录方式登录到需要修改主机名的服务器。
- 编辑主机名配置文件:使用文本编辑器(如
vim)编辑/etc/hostname文件。sudo vim /etc/hostname - 设置新的主机名:在文件中输入新的主机名,例如
hadoop101,然后保存退出。 - 更新系统识别的主机名:使更改立即生效,可以使用以下命令:
sudo hostname -F /etc/hostname
9. 配置hosts文件
- 打开
hosts文件:编辑/etc/hosts文件,以将IP地址映射到相应的主机名。sudo vim /etc/hosts - 添加或更新条目:在文件中添加或更新映射关系,每条映射占一行,格式为
IP地址 空格 主机名。例如:
这里的IP地址替换为自己服务器的IP地址。192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.102 hadoop103 - 确保无重复条目:检查
hosts文件以确保没有重复或冲突的条目,这可能会导致网络解析问题。 - 保存并关闭文件:完成编辑后,保存更改并关闭文本编辑器。
10. 重启服务器
- 完成配置后,重启服务器以应用更改。
reboot
配置免密登录
为了方便管理,需要在服务器之间使用bigdata用户配置SSH无密码登录。
-
切换到
bigdata用户su bigdata -
hadoop101生成SSH密钥对:ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa该命令会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。
-
hadoop101上执行命令ssh-copy-id, 将hadoop101公钥复制到每台服务器的~/.ssh/authorized_keys:ssh-copy-id hadoop101 ssh-copy-id hadoop102 ssh-copy-id hadoop103
安装Java
下面的操作使用bigdata 用户在 hadoop101上进行操作。
-
切换到
/opt/software目录cd /opt/software -
使用
wget下载 Java 1.8 版本wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz请检查链接是否有效,因为Oracle的下载链接可能会变化。
-
使用
tar解压文件到/opt/module目录tar -xzvf jdk-8u301-linux-x64.tar.gz -C /opt/module/ -
生成软链接
ln -s /opt/module/jdk1.8.0_301 /opt/module/jdk -
设置 JDK 的环境变量
-
新建
/etc/profile.d/bigdata_env.sh文件touch /etc/profile.d/bigdata_env.sh -
添加如下内容,然后保存(:wq)退出
#JAVA_HOME export JAVA_HOME=/opt/module/jdk export PATH=$PATH:$JAVA_HOME/bin -
让环境变量生效
source /etc/profile.d/bigdata_env.sh
-
-
验证安装
java -version echo $JAVA_HOME -
分发软件和环境变量
- 将
JAVA软件,JAVA软连接,环境变量配置文件分发到hadoop102和hadoop103上
# 分发到 hadoop102 rsync -av "/opt/module/jdk1.8.0_202" "hadoop102:/opt/module" rsync -av "/opt/module/jdk" "hadoop102:/opt/module" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop102:/etc/profile.d" # 分发到 hadoop103 rsync -av "/opt/module/jdk1.8.0_202" "hadoop103:/opt/module/" rsync -av "/opt/module/jdk" "hadoop103:/opt/module/" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop103:/etc/profile.d" - 将
安装Hadoop
1. Hadoop部署
下面的操作使用bigdata 用户在 hadoop101上进行操作。
-
进入Hadoop安装包路径
- 打开终端,使用命令
cd /opt/software/进入包含Hadoop安装包的目录。
- 打开终端,使用命令
-
下载Hadoop
从华为镜像下载Hadoop的tar.gz包,并解压到合适的目录。# 下载hadoop3.3.1 wget https://mirrors.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz -
解压Hadoop安装文件
- 将Hadoop压缩包解压到
/opt/module/目录。tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 将Hadoop压缩包解压到
-
验证解压结果
- 通过执行命令
ls /opt/module/hadoop-3.1.3来检查Hadoop目录是否存在,以确认解压操作是否成功。
- 通过执行命令
-
创建Hadoop软连接
- 如果解压成功,创建软连接
hadoop,以简化路径。ln -s /opt/module/hadoop-3.1.3 /opt/module/hadoop
- 如果解压成功,创建软连接
-
编辑环境变量配置文件
-
首先,使用
pwd命令获取当前Hadoop安装目录的完整路径。 -
接着,使用
sudo vim /etc/profile.d/bigdata_env.sh命令以超级用户权限打开环境变量配置文件进行编辑。 -
在打开的配置文件中,滚动到文件末尾(使用
Shift + G)。 -
添加以下行来设置Hadoop的环境变量:
# HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
这些行将Hadoop的bin和sbin目录添加到系统的PATH环境变量中,使得可以在任何位置调用Hadoop的命令。
-
在Vim编辑器中,使用
:wq命令保存更改并退出编辑器。
-
-
使环境变量生效
- 在
hadoop101上执行下面的命令source /etc/profile.d/bigdata_env.sh
- 在
-
验证安装
- 通过下面命令验证安装是否成功,以及环境变量是否生效。
hadoop version echo $HADOOP_HOME
- 通过下面命令验证安装是否成功,以及环境变量是否生效。
-
分发软件和环境变量
- 将
Hadoop软件,Hadoop软连接,环境变量配置文件分发到hadoop102和hadoop103上# 分发到 hadoop102 rsync -av "/opt/module/hadoop-3.1.3" "hadoop102:/opt/module" rsync -av "/opt/module/hadoop" "hadoop102:/opt/module" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop102:/etc/profile.d" # 分发到 hadoop103 rsync -av "/opt/module/hadoop-3.1.3" "hadoop103:/opt/module/" rsync -av "/opt/module/hadoop" "hadoop103:/opt/module/" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop103:/etc/profile.d"
- 将
2. 配置Hadoop
进入hadoop配置目录cd /opt/module/hadoop/etc/hadoop/, 修改Hadoop配置文件core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml, workers ,设置集群模式和相关参数。
-
文件
core-site.xml配置:<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为bigdata --> <property> <name>hadoop.http.staticuser.user</name> <value>bigdata</value> </property> <!-- 配置该bigdata(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.bigdata.hosts</name> <value>*</value> </property> <!-- 配置该bigdata(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.bigdata.groups</name> <value>*</value> </property> <!-- 配置该bigdata(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.bigdata.users</name> <value>*</value> </property> </configuration> -
文件
hdfs-site.xml配置:<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop101:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop102:9868</value> </property> <!-- 测试环境指定HDFS副本的数量1 --> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> -
文件
yarn-site.xml配置<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop101</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!--yarn单个容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> -
文件
mapred-site.xml配置<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
文件
workers配置hadoop101 hadoop102 hadoop103 -
分发配置文件
- 将配置文件分发到
hadoop102和hadoop103上# 分发到 hadoop102 rsync -av "/opt/module/hadoop/etc/hadoop" "hadoop102:/opt/module/hadoop/etc/" # 分发到 hadoop103 rsync -av "/opt/module/hadoop/etc/hadoop" "hadoop103:/opt/module/hadoop/etc/"
- 将配置文件分发到
3. 格式化Hadoop文件系统
-
在NameNode服务器上(
hadoop101)格式化Hadoop文件系统。hdfs namenode -format
4. 启动Hadoop集群
-
启动Hadoop集群的所有守护进程。
start-dfs.sh start-yarn.sh
5. 验证Hadoop集群
-
使用
jps命令检查Java进程,确认Hadoop守护进程是否启动。jps # hadoop101 上启动以下进程 6084 DataNode 6552 NodeManager 6426 ResourceManager 5935 NameNode # hadoop102 上启动以下进程 30834 ResourceManager 28487 SecondaryNameNode 28695 NodeManager 28379 DataNode # hadoop103 上启动以下进程 2466 NodeManager 2340 DataNode -
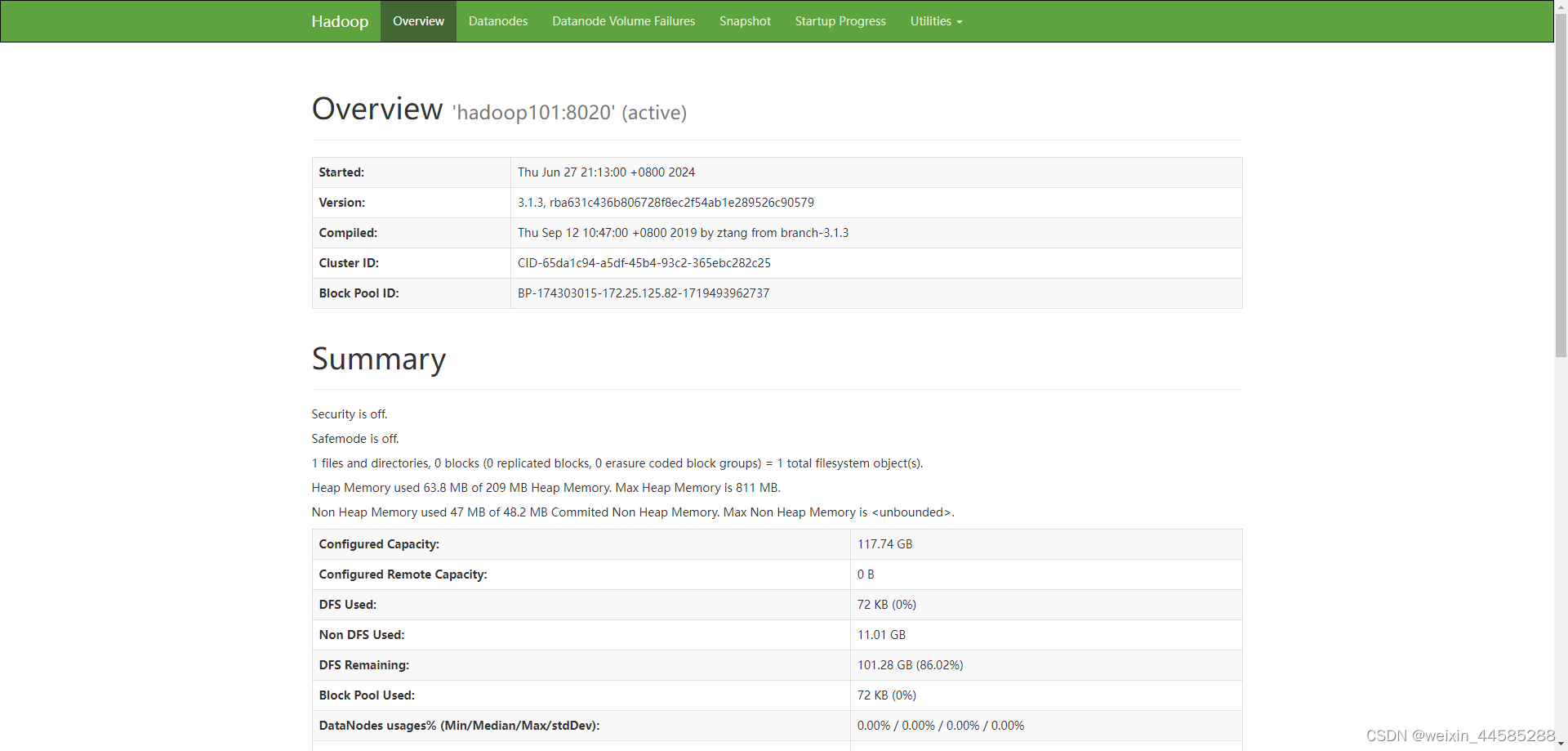
页面查看
-
hdfs 页面地址
http://hadoop101:9870
-
yarn 页面地址
http://hadoop101:8088

-
注意事项
- 企业开发中,单个服务器的防火墙通常是关闭的,但公司整体会设置安全的防火墙。
参考文件
Java | 华为镜像仓库