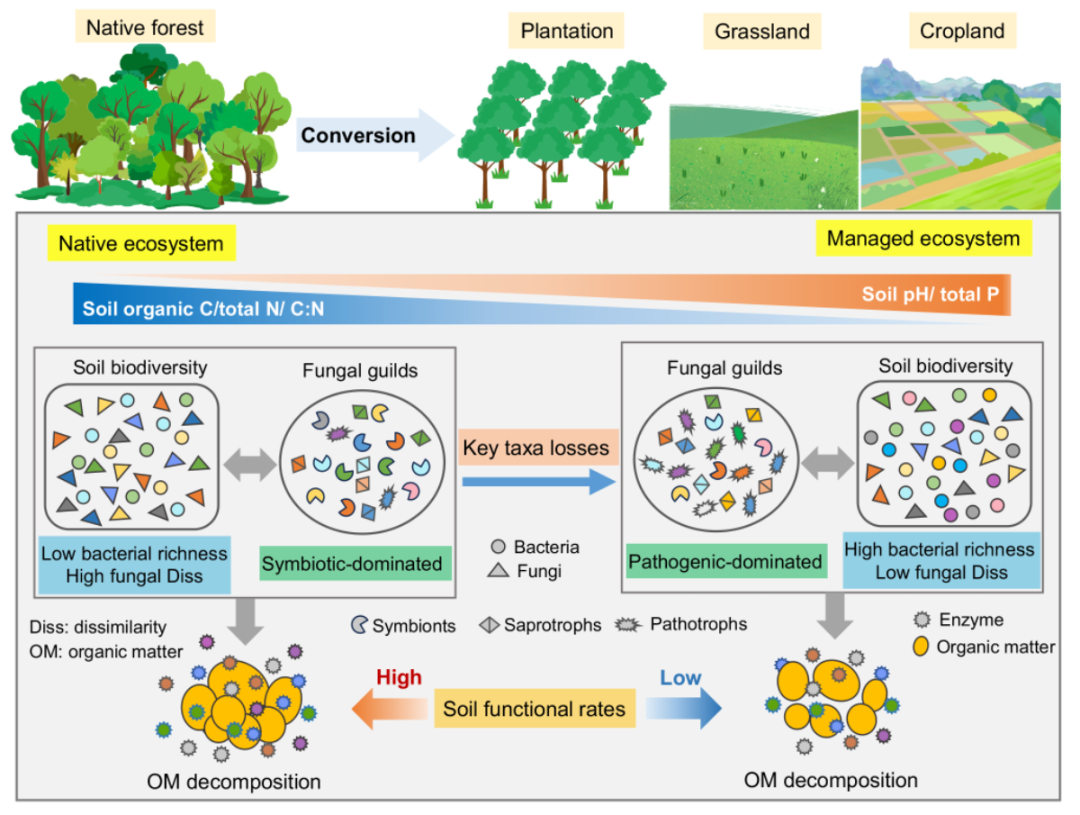
【时间序列+Transformer】在近年来的深度学习领域中备受关注,它通过将Transformer架构应用于时间序列数据,显著提升了模型在长时间依赖建模和复杂模式识别任务中的表现。时间序列+Transformer技术已经在金融预测、气象预报和健康监测等多个领域取得了显著成果,其独特的方法和有效的表现使其成为研究热点之一。
特别是该领域近期再次取得重大突破:iTransformer,在不修改任何模块的情况下,就实现了全面领先!实际上,对Transformer架构进行改进,提升预测效果,一直是迫切需求!主要在于Transformer在时序预测领域一直面临诸多挑战,比如Transformer 计算多头自注意力的方式:二次复杂度,在处理长序列时会产生计算瓶颈,经典的informer模型就由此诞生。
为了帮助大家全面掌握时间序列+Transformer的方法并寻找创新点,本文总结了最近两年【时间序列+Transformer】相关的20篇顶会顶刊的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望能为各位的研究工作提供有价值的参考。
需要的同学扫码添加我
回复“时序Transformer20”即可全部领取

1、Masked Jigsaw Puzzle: A Versatile Position Embedding for Vision Transformers

-这篇文章提出了一种名为Masked Jigsaw Puzzle (MJP) 的新型位置嵌入方法,用于改进视觉变换器(Vision Transformers,ViTs)在处理图像时的隐私保护和性能表现。ViTs在许多视觉任务中表现出色,但其使用的位置嵌入(Position Embeddings,PEs)可能暴露输入图像的空间信息,带来隐私泄露的风险。文章首先通过低维投影技术直观展示了PEs如何学习输入图像块的二维空间关系,从而解释了PEs对ViTs性能提升的原因。
-为了解决PEs带来的隐私问题,文章提出了MJP方法,该方法通过四个核心步骤实现:首先,使用块状随机拼图洗牌算法随机选择并打乱输入图像块;其次,对选中的图像块使用共享的未知位置嵌入,而非原始PEs;接着,为了加强未被打乱图像块的空间关系,引入了密集绝对位置回归(Dense Absolute Localization,DAL)约束;最后,通过这种方式,MJP在保持ViTs准确性的同时,增强了模型对图像块洗牌的一致性,并显著提高了在对抗性攻击下的隐私保护能力。
-实验结果表明,MJP方法在大规模数据集(如ImageNet-1K和ImageNet-C)上不仅提升了性能和鲁棒性,而且在典型的梯度攻击下,通过大幅度提高隐私保护能力,有效地缓解了PEs的隐私泄露问题。此外,文章还探讨了MJP方法在不同遮蔽比例下的准确性、差异性规范和一致性表现,并进行了消融研究,以验证MJP各个组成部分的有效性。
-文章还讨论了MJP方法在隐私保护方面的效果,通过对比分析攻击(Analytic Attack)来评估模型在隐私攻击中的抗攻击性能。结果表明,MJP方法能够显著降低从梯度更新中恢复原始图像的质量,从而提高隐私保护能力。此外,文章还提供了可视化的注意力图,展示了MJP方法如何使ViTs的注意力头呈现更多样化和内容感知的注意力模式,这可能是MJP提升准确性的原因之一。
-最后,文章总结了MJP方法的主要贡献,并指出其在保护用户隐私、提高模型鲁棒性和准确性方面的潜力。MJP方法的提出,为ViTs在处理视觉任务时提供了一种平衡准确性、隐私保护和一致性的新思路。
2、SegRefiner: Towards Model-Agnostic Segmentation Refinement with Discrete Diffusion Process
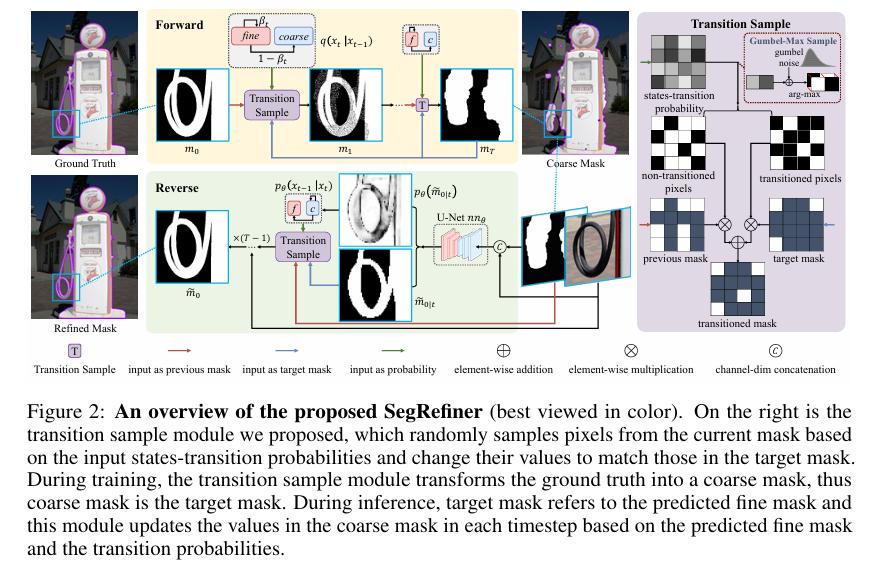
-这篇文章介绍了一种名为SegRefiner的模型无关的图像分割细化方法,该方法通过离散扩散过程来增强由不同分割模型产生的物体掩模的质量。SegRefiner的核心思想是将分割细化任务视为一个数据生成过程,并通过一系列去噪扩散步骤来实现。具体来说,SegRefiner接受粗糙的掩模作为输入,并通过预测每个像素的标签和相应的状态转换概率,以条件去噪的方式逐步细化这些掩模。
-文章首先指出,尽管图像和视频分割领域在过去几十年中已经得到了广泛研究,但获取准确和详细的分割掩模仍然是一个挑战,因为这需要模型同时捕获高级语义信息和细粒度的纹理信息。尤其是对于2K或更高分辨率的图像,这一挑战尤为突出,因为它们需要相当的计算复杂性和内存使用。现有的分割算法通常在较小的尺寸上预测掩模,这不可避免地导致了由于下采样过程中细粒度信息的丢失而导致的准确性下降。
-为了解决这个问题,SegRefiner采用了一种新颖的视角,将分割细化视为一个数据生成过程。在训练过程中,SegRefiner通过一个独特的离散扩散过程,逐渐将真实标签掩模转化为粗糙掩模。在推理过程中,该过程则用于从粗糙掩模中采样,并逐步细化掩模。这种方法允许SegRefiner在每次迭代中只关注修正一些“最明显的错误”,并逐步收敛到准确结果,从而降低了单次修正所有错误的难度,并使模型能够处理更具挑战性的例子。
-文章通过在各种分割任务上的广泛实验,展示了SegRefiner的有效性。实验结果表明,SegRefiner在多个方面优于以往的模型无关细化方法。首先,它在不同类型的粗糙掩模上一致地提高了分割度量和边界度量。其次,与以前的模型无关细化方法相比,SegRefiner有显著的性能提升。最后,当应用于高分辨率图像时,SegRefiner展现出强大的捕捉极细细节的能力。
-此外,SegRefiner的源代码和训练模型已在GitHub上公开,以便其他研究人员可以访问和使用。这项工作不仅为图像分割领域提供了一种新的细化策略,也为其他需要数据生成任务的领域提供了一种可能的解决方案。
需要的同学扫码添加我
回复“时序Transformer20”即可全部领取
3、ContiFormer: Continuous-Time Transformer for Irregular Time Series Modeling

-这篇文章提出了一种新型的连续时间变换器(ContiFormer),专为不规律时间序列建模而设计。在现实世界的应用中,如疾病预防、金融决策和地震预测等领域,经常会遇到不规律时间序列数据。这些数据的特点是观测值的生成时间间隔不固定,可能存在由于技术问题或数据质量问题导致的缺失数据。传统的时间序列分析技术在处理这类数据时面临挑战,因为它们通常假设数据是等间隔采样的。
-文章指出,现有的时间序列模型,包括循环神经网络(RNN)和变换器(Transformer)模型,尽管在捕捉复杂模式方面表现出色,但它们在处理连续时间数据范式时存在局限性。此外,神经常微分方程(Neural ODEs)及其变体虽然在处理不规律时间序列方面显示出了有希望的结果,但它们往往无法捕捉序列内部的复杂相关性。
-为了解决这些问题,文章提出了ContiFormer,这是一种将神经ODEs的连续动态建模能力与变换器的注意力机制结合起来的连续时间变换器。ContiFormer通过定义每个观测值的潜在轨迹来捕捉观测值的动态变化,并将变换器中的离散点积扩展到连续时间域,从而在连续动态之间计算注意力。
-文章的贡献可以总结为以下几点:
-
引入了一种新颖的连续时间变换器,据作者所知,这是首次将连续时间机制融入变换器的注意力计算中。
-
提出了一种新颖的参数化方法,允许在不同时间范围内并行执行连续时间注意力。
-
从理论上分析了ContiFormer的表达能力,并展示了多种专门用于不规律时间序列建模的变换器变体可以作为ContiFormer的特例。
-
在合成和真实世界数据集上进行了广泛的实验,证明了ContiFormer在不规律时间序列数据上的建模能力和预测性能优于现有模型。
-文章还对ContiFormer的计算复杂性进行了分析,展示了其在不同模型中的性能对比,并讨论了模型的表示能力,证明了ContiFormer能够扩展多种变换器变体。最后,文章通过一系列实验验证了ContiFormer在时间序列插值、分类、事件预测和预测等不同类型的不规律时间序列任务上的有效性,并与现有的强基线模型进行了比较,展示了其优越的性能。
需要的同学扫码添加我
回复“时序Transformer20”即可全部领取