1. AI解读
1.1. 总体概要
本文探讨了大型语言模型(LLMs)如GPT-4在生成特定领域(如计算机科学中的自然语言处理NLP)教育调查文章方面的能力和局限性。研究发现,尽管GPT-4能够根据特定指导生成高质量的调查文章,与人类专家的作品相媲美,但在细节完整性和事实准确性方面仍存在不足。此外,GPT-4在评估机器生成文本时显示出对自身生成内容的偏好,表明在某些情况下,它可能不是人类判断的完美替代品。文章强调了LLMs在教育领域中的潜在变革作用,同时也指出了需要进一步验证和人工干预的必要性,以确保教育内容的准确性和丰富性。
1.2 核心要点
大型语言模型(LLMs)在特定领域教育材料生成中的应用探索:
- 本文探讨了LLMs在生成计算机科学领域,特别是自然语言处理(NLP)领域的教育调查文章的能力。通过自动化的基准测试,发现GPT-4在这一任务上超越了其前代模型如 GPT-3.5、PaLM2 和 LLaMa2。
GPT-4在生成调查文章中的表现:
- GPT-4 在生成调查文章时,尽管通常能提供出色的内容,但偶尔会出现遗漏细节或事实错误的情况。这表明,尽管 GPT-4 在自动化评估中表现优异,但在某些情况下仍需人工验证。
人类与GPT评估的一致性与差异:
- 本文比较了人类专家和 GPT-4 在评估生成的调查文章方面的评分行为,发现 GPT-4 在评估机器生成的文本时存在系统性偏差。这表明,尽管 GPT-4 在许多方面与人类评估者的意见一致,但在评估人类撰写的文本时,其判断可能不如人类准确。
LLMs在教育领域的潜力与局限性:
- 研究表明,LLMs,特别是 GPT-4,有能力生成高质量的教育调查文章,这些文章比人类撰写的更加现代化和易于理解。然而,也存在一定的局限性,如信息不完整和事实错误,这需要在教育材料的生成中加以注意。
未来研究方向与伦理考量:
- 本文提出了未来研究的方向,包括进一步探索 LLMs 在教育领域的应用,以及如何克服其在生成教育材料时的局限性。同时,也提出了伦理考量,包括对LLMs生成的内容的准确性和可靠性的关注,以及对人类专家角色的潜在影响。
1.3 段落概要
1.3.1 Introduction
文章在“Introduction”部分介绍了大型语言模型(LLMs)在通用自然语言处理(NLP)任务中的显著表现,特别是在GPT系列模型上的应用。尽管LLMs在许多通用任务上表现出色,但其在特定领域任务中的有效性仍受到质疑,特别是在科学教育领域自动生成调查文章方面。文章指出,自动调查生成旨在利用机器学习或NLP技术创建特定概念的结构化概述,这不仅减轻了手动工作量,还确保了成本效益和及时更新。然而,LLMs在撰写科学调查方面的有效性和局限性尚未得到充分研究。文章提出了三个研究问题(RQs),旨在探讨LLMs在生成NLP概念调查文章方面的熟练程度、LLMs模拟人类判断的能力,以及LLMs在评估机器生成文本与人类编写文本时是否引入显著偏差。通过实验,文章旨在深入了解LLMs在解释科学领域概念时的结构化表达能力。
1.3.2 Method
文章的 Method 部分介绍了研究中采用的生成自然语言处理(NLP)概念调查文章的方法。研究使用了Surfer100数据集,并比较了零样本(ZS)、单样本(OS)、描述提示(DP)和单样本与描述提示结合(OSP)四种设置下的模型表现。此外,还引入了检索增强生成(RAG)设置(OS+IR),该设置链接至维基百科文章和网络数据。通过自动评估使用多种指标,如 ROUGE、BERTScore 等,结果显示 GPT-4 在大多数情况下表现最佳,尤其是在 OSP 设置下。然而,提示的丰富并不总是带来正面效果,不同模型对提示的响应不同。研究主要关注不使用外部数据的设置,以探究大型语言模型(LLMs)在此任务中的知识掌握程度。
1.3.3 Analysis
研究者深入探讨了大型语言模型(LLMs)在撰写自然语言处理(NLP)概念调查报告方面的内在知识能力,并比较了人类和LLM评估的分数。研究发现,尽管 LLMs,特别是 GPT-4,能够根据特定指导生成高质量的调查文章,但在某些方面如信息的完整性上存在不足。此外,GPT-4 在评估人类编写的文本时,显示出对机器生成文本的偏好,表明它可能不是人类判断的完美替代品。这一发现强调了在某些情况下,如手动内容事实核查,人类专家的不可替代性。总体而言,虽然LLMs在撰写调查报告方面表现出色,但仍需谨慎对待其在评估人类编写文本时的偏见。
1.3.4 Discussion and Conclusion
文章的“Discussion and Conclusion”部分总结了大型语言模型(LLMs)在撰写自然语言处理(NLP)概念调查方面的能力。研究发现,尽管 LLMs,特别是 GPT-4,能够根据特定指导原则编写高质量的调查报告,与人类专家相媲美,但仍存在信息不完整等不足。同时,GPT-4 在评估人类编写的文本时,显示出对机器生成文本的偏好和特定偏见,表明它尚不能完全替代人类的判断。尽管如此,这些先进的生成型LLMs在教育领域具有变革性的潜力,能够为普通学习者构建特定领域的知识结构,提供更加互动和个性化的学习体验,满足学生独特的学习需求和好奇心。
2. 个人解读
专业领域的调查文章和教材需要大量的专家投入,纂写和更新成本高昂。最近,大型语言模型(LLMs)在各种通用任务中取得了巨大成功。然而,它们在教育领域的有效性和局限性还有待充分探索。这项工作研究了 LLM 在生成计算机科学 NLP 细分领域特定的简明调查文章方面的能力,重点关注 99 个主题的策划列表。自动基准测试表明,GPT-4 超越了其前辈,如 GPT3.5、PaLM2 和 LLaMa2。我们比较了人类和基于 GPT 的评估分数,并进行了深入分析。虽然我们的研究结果表明,GPT 创建的调查报告比人类撰写的调查报告更具有时代感,更容易获得,但也发现了某些局限性。值得注意的是,GPT-4 尽管经常提供出色的内容,但偶尔也会出现失误,如细节缺失或事实错误。最后,我们比较了人类和 GPT-4 的评分行为,发现在使用 GPT 评估时存在系统性偏差。
2.1. Introduction
由 LLM 生成的文本有时会出现制造虚假信息和幻觉等问题。 现有工作侧重于将 LLMs 应用于实际场景,包括辅助科学写作、科学论文问答、撰写论文评论,并回答测验或考试问题。我们的主要目标是了解 LLMs 是否可以用来以更结构化的方式解释概念。为此,我们旨在回答以下研究问题(RQ):
问题1:法学硕士生成有关 NLP 概念的调查文章的熟练程度如何?
问题2:在提供特定标准的情况下,LLM能否模仿人类的判断?
问题 3:与人类撰写的文本相比,LLM 在评估机器生成的文本时是否会产生明显的偏差?
我们在 LLaMa2、PaLM2、GPT-3.5 和 GPT-4 上进行了四种不同设置的实证实验。此外,我们还请人类专家提供定性维度,确保我们的结果不仅反映技术性能,而且还包含了人类的主观视角。
2.2. Method
2.2.1. Data & Generation prompt
采用了 Surfer100 数据集,其中包含 100 篇人工撰写的 NLP 概念调查文章。每篇调查文章包含五个部分:导言、历史、关键理念、用途/应用和变体。每个部分包括 50-150 个 tokens。然后,我们比较了三种设置:zero-shot(ZS)、one-shot(OS)和 description prompt(DP)。在 zero-shot 环节,我们通过提供以下提示直接要求模型生成文章:生成一份关于<主题>的调查。应该有五个小节:导言、历史、主要观点、变体和应用。每个小节应包含 50-150 个字。在 one-shot 环节,我们会添加一篇调查范文;在 description prompt 环节,我们会为每个小节添加详细说明,解释应包含哪些内容。例如,第 1 节:简介 描述主题是什么(一种方法、一个模型、一项任务、一个数据集),它属于哪个领域/子领域,概念和相关想法背后的应用和动机的快速概述)。为了进一步丰富所提供的信息,我们还引入了 one-shot 和 description prompt(OSP)的组合。完整的提示信息如下图所示。

通过采用单一基本事实进行单次学习,我们在每个设置中生成了 99 份调查问卷。此外,我们还评估了一种特殊的 RAG (OS+IR),它链接到维基百科文章和网络数据。
2.2.2. Automatic Evaluation
我们使用一系列自动指标对生成的调查进行评估,包括 ROUGE、BERTScore、MoverScore、UniEval 和 BARTScore。表 1 提供了以下 LLM 的结果概览:LLaMa2 (13B, 70B)、PaLM2 (text-bison)、GPT-3.5 (Turbo-0613) 以及 GPT-4 (0613) 在不同提示设置下的结果概览。
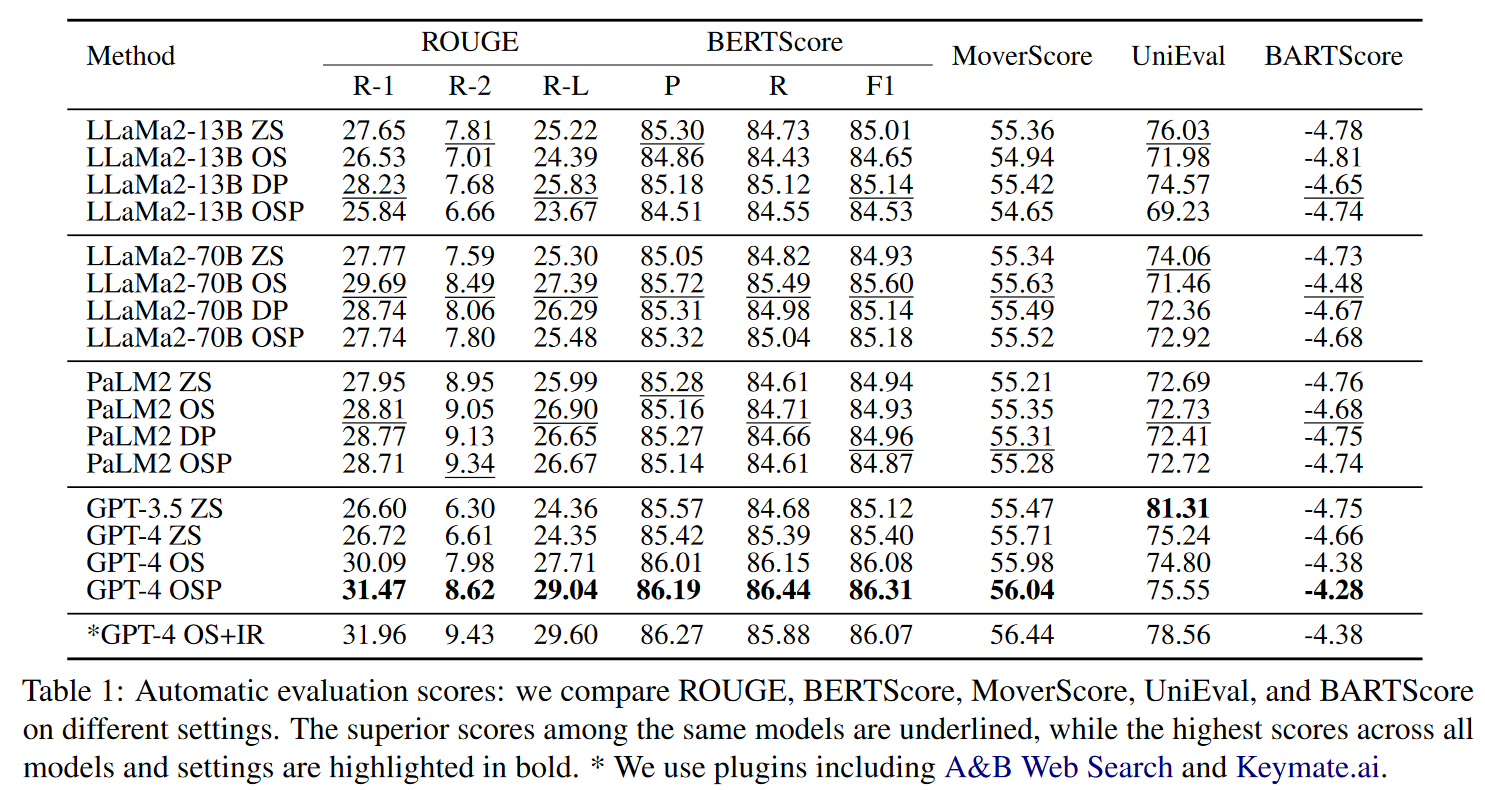
我们首先注意到,GPT-4 的性能始终优于其他基线,在增强提示时可获得约 2% 至 20% 的显著改进。具体来说,GPT-4 OSP 在大多数情况下都取得了第一名的成绩。不过,这并不是说强化提示总是能产生积极的结果。例如,在 LLaMa2 中,一次性提示和描述性提示比 OSP 表现更好。至于 PaLM2,四种类型的提示都获得了相似的结果。
当我们添加外部知识(GPT-4 OS+IR)时,与 GPT-4 OS 相比会有一些改进。由于我们的主要目标是研究 LLM 在这项任务中掌握知识的程度,因此我们主要侧重于在没有外部数据的情况下进行分析。有关 OS+IR 环节的其他分析如下:
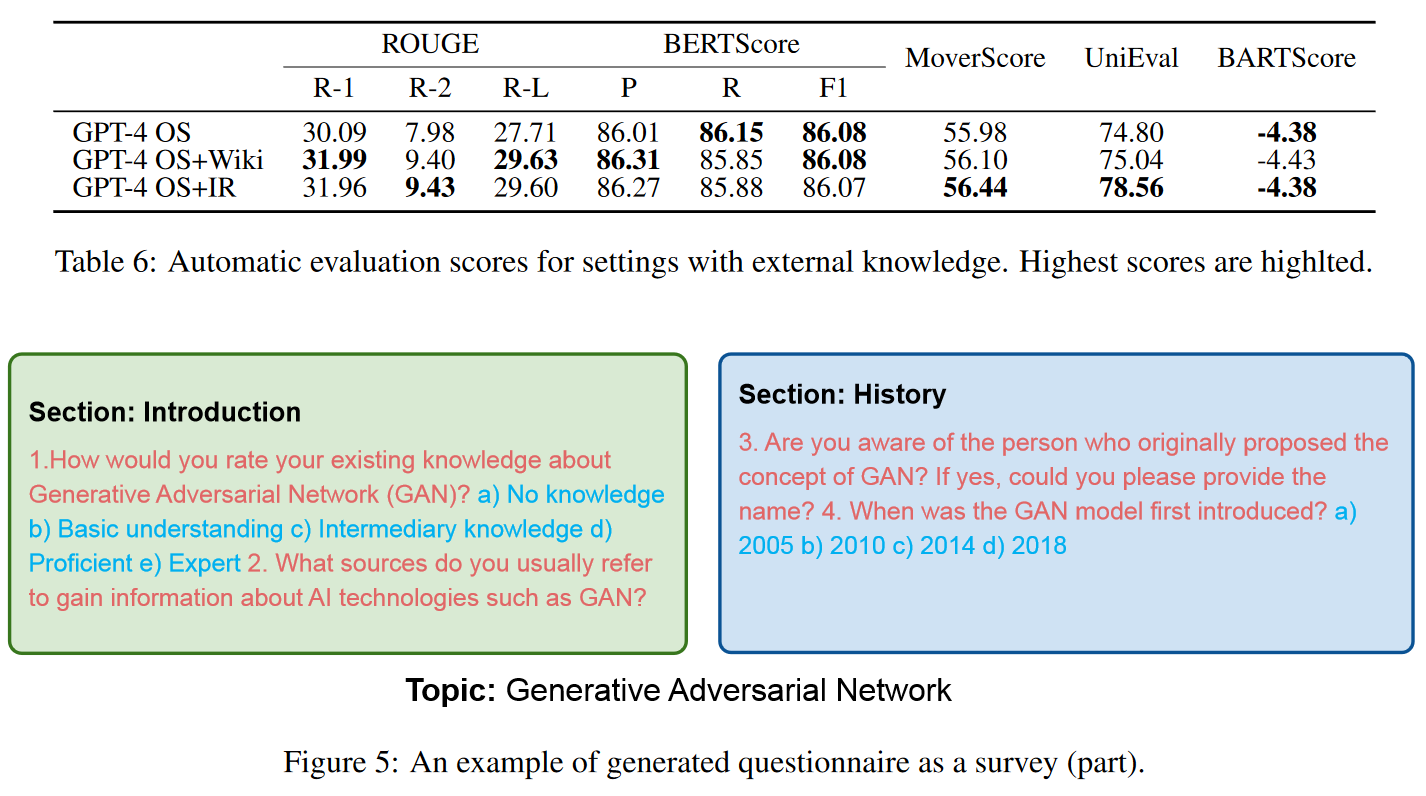
我们对①与维基百科文章进行链接(GPT-4 OS+Wiki)和②信息检索(GPT OS+IR)这两种方法进行了进一步评估。在 GPT-4 OS+Wiki 设置中,我们应用了 Embedchain。我们从维基百科文章中抓取 Surfer 100 数据集中的关键概念,得到 87 个有效链接。然后,我们提示 GPT-4 为相应的 87 个主题生成调查文章,并提供相应的维基百科链接和调查样本作为参考。至于 GPT-4 OS+IR 的设置,我们要求 GPT-4 在提示中 "在网络上搜索有用信息",并利用网络搜索 API。表 6 显示了有外部知识和无外部知识的 GPT-4 的比较结果。可以清楚地看到,这两种方案大大提高了 Rouge 分数。
值得注意的是,网络来源搜索有效地提高了 MoverScore 和 UniEval 分数。总之,与仅使用内部知识相比,外部知识有助于 GPT-4 生成更高质量的调查文章。这表明,LLMs 的学术搜索能力有限。
在文章中提到的ROUGE、BERTScore、MoverScore、UniEval和BARTScore是用于评估文本生成质量的自动化指标。这些指标通常用于比较生成的文本(如摘要、翻译或回答)与参考文本(如人工编写的摘要或正确答案)之间的相似度和质量。下面是对这些评估方法的详细介绍:
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- 定义:ROUGE是一组评估自动生成的摘要与参考摘要之间相似度的指标,主要用于文本摘要任务。
- 类型:包括ROUGE-N(N-gram重叠)、ROUGE-L(最长公共子序列)和ROUGE-S(跳跃N-gram匹配)等。
- 用途:通过计算生成的摘要与参考摘要之间的n-gram重叠来评估摘要的质量。
- 特点:ROUGE侧重于召回率,即生成的摘要中包含了多少参考摘要的内容。
BERTScore
- 定义:BERTScore利用预训练的BERT模型来计算生成的文本与参考文本之间的相似度。
- 原理:它通过计算每个文本的BERT嵌入之间的余弦相似度来评估相似度。
- 用途:广泛用于文本生成任务,如机器翻译、文本摘要和问答系统。
- 特点:BERTScore考虑了上下文信息,能够更准确地评估文本之间的语义相似度。
MoverScore
- 定义:MoverScore是一种基于距离的文本相似度评估方法,它使用预训练的词嵌入模型来计算文本之间的相似度。
- 原理:通过计算从生成的文本到参考文本的“移动距离”来评估相似度。
- 用途:适用于文本摘要、机器翻译等任务。
- 特点:MoverScore考虑了词序和语义信息,能够更全面地评估文本之间的相似度。
UniEval
- 定义:UniEval是一种多维度评估框架,用于评估文本生成的多个方面,包括流畅性、相关性、连贯性和信息性。
- 原理:它使用预训练的语言模型来为生成的文本打分。
- 用途:适用于多种文本生成任务,如文本摘要、问答和对话系统。
- 特点:UniEval提供了一个全面的评估框架,能够从多个维度评估文本生成的质量。
BARTScore
- 定义:BARTScore使用预训练的BART模型来评估生成的文本与参考文本之间的相似度。
- 原理:它通过计算BART模型在给定参考文本的情况下生成生成的文本的概率来评估相似度。
- 用途:适用于文本摘要、机器翻译等任务。
- 特点:BARTScore考虑了文本的生成过程,能够更准确地评估文本之间的相似度和质量。
2.2.3. Human and GPTs Evaluation
我们采用两个 NLP 专家 GPT-4 和 G-Eval 来评估由最佳 GPT-4 OSP 设置生成的调查,重点关注 6 个方面:
Readability(可读性)
- 1(差):文本非常难读,语法错误多,缺乏连贯性和清晰度。
- 5(好):文本易读,结构合理,流畅自然。
Relevancy(相关性)
- 1(差):生成的文本与给定的上下文或提示完全无关。
- 5(好):生成的文本高度相关,直接针对给定的上下文或提示。
Redundancy(冗余性)
- 1(差):文本过度重复,包含不必要的相同信息重复。例如,每个部分应包含 50-150 个 tokens。如果篇幅过长,我们应给予低分。
- 5(好):文本简明扼要,没有冗余,只提供基本信息。
Hallucination(幻觉)
- 1(差):生成的文本包含虚假或误导性信息,与上下文不符或与事实不符。
- 5(好):生成的文本没有幻觉,提供的信息准确且与上下文相符。
Completeness(完整性)
- 1(差):生成的文本不完整(缺少关键信息)、遗漏关键细节或提供的信息不准确。
- 5(好):生成的文本全面、准确,包含所有相关信息。
Factuality(事实性)
- 1(差):文本包含大量与事实不符或错误的陈述,尤其是在历史和主旨方面。例如,年份或人物有误。
- 5(好):文章事实准确,有证据支持,没有错误信息。
我们最初聘请了四位 NLP 专家,就表 4 中列出的 20 个精选主题对 GPT 制作的调查问卷进行评估。四种模型配置的评估得分见表 5。考虑到四位评委的评估结果存在较大的标准偏差,我们随后选择了两位评分一致性较高的评委对所有概念进行评估。

值得注意的是,我们在选择人类专家时实施了预选阶段。表 2 显示,人类专家和 GPT 都认为生成的内容在大多数方面都表现良好,但在完整性方面得分略低。
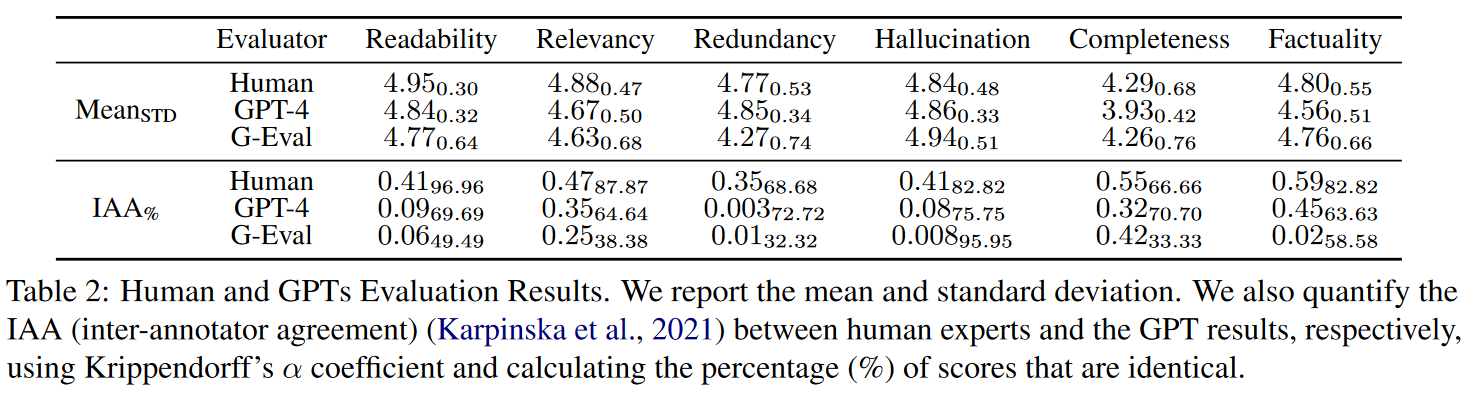
表 2:人类和 GPT 的评估结果。我们报告了平均值和标准偏差。我们还使用 Krippendorff's α 系数量化了人类专家与 GPT 结果之间的 IAA(注释者之间的一致性),并计算了相同分数的百分比(%)。
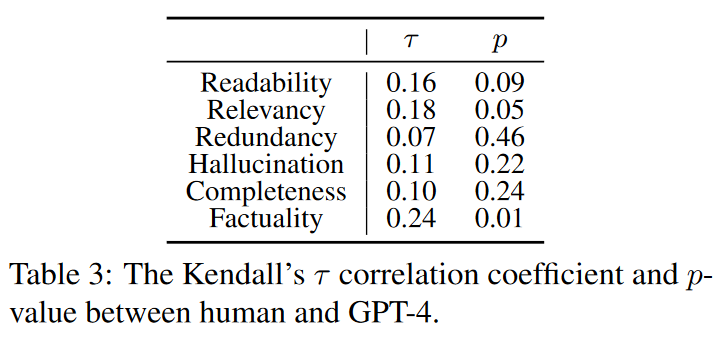
根据 IAA,我们可以发现人类专家对生成的调查表表现出较高的质量一致性,而 GPT-4 和 G-Eval 则有更多的随机性。为了更好地了解人类专家和 GPT-4 在评分上的一致程度,我们还计算了 Kendall's τ 和 p 值,如表 3 所示。
IAA (Inter-Annotator Agreement)
- 定义:IAA,即注释者间一致性,是衡量多个评估者(或注释者)对同一组数据进行评估时的一致性程度的指标。
- 用途:在文本生成评估中,IAA用于衡量不同人类评估者之间或人类评估者与机器评估者(如GPT-4)之间的评分一致性。
- 计算方法:常见的IAA计算方法包括 Krippendorff's alpha、Scott's pi 和 Cohen's kappa 等。
τ (Kendall's Tau)
- 定义:Kendall's Tau是一种非参数统计量,用于衡量两个有序变量之间的关联性或一致性。
- 用途:在文本生成评估中,Kendall's Tau用于衡量人类评估者与GPT-4在评估生成的文本时的评分一致性。
- 计算方法:Kendall's Tau通过计算两个评估者的评分排名之间的差异来衡量一致性。
π (Scott's Pi)
- 定义:Scott's Pi是一种注释者间一致性的度量,特别适用于分类数据。
- 用途:在文本生成评估中,Scott's Pi 用于衡量不同评估者对文本生成质量的分类评分的一致性。
- 计算方法:Scott's Pi 考虑了评估者之间的偶然一致性和实际一致性,通过比较这两者来计算一致性系数。
在分析表2和表3的结果时,可以关注以下几个方面:
- 一致性水平:通过IAA、τ和π的值,可以了解人类评估者与 GPT-4 之间的评分一致性水平。较高的值通常表示较高的一致性。
- 评估维度:表中可能列出了不同的评估维度,如流畅性、相关性、连贯性等。可以分析在不同维度上的一致性差异。
- 统计显著性:表3中的p-value用于检验Kendall's Tau的统计显著性。如果 p-value 小于显著性水平(如0.05),则可以认为一致性差异是统计显著的。
- 偏差分析:通过比较人类评估者和 GPT-4 的评分,可以分析 GPT-4 是否存在对机器生成文本的偏好或其他类型的评估偏差。
我们可以发现,事实性的相关程度最高。相比之下,冗余度的相关性最低,而其他方面的相关性水平相对较低。这种差异主要是因为事实性基于客观的基本事实,而冗余性则更依赖于主观判断。
值得注意的是,我们可以得出结论,在大多数情况下,GPT-4 与人类表现出相似的评价观点,尽管在不同的独立会话中表现出更高的可变性。关于 RQ1 和 RQ2,我们发现:1)LLM 可以生成高质量的调查文章;2)在特定指导下,GPT 输出与人类判断之间具有很强的一致性。
2.3. Analysis
在本节中,我们将深入分析 LLMs 关于调查报告撰写能力的知识储备量,并比较人类评估和 LLMs 评估的评价分数。
2.3.1. Error Types
我们已经证明,自动和人工评估都表明,LLMs 在撰写科学概念调查文章方面表现出色。我们分析了最佳设置 GPT-4 OSP,评估了两位专家发现的错误,并在图 1 中总结了错误类型和分布情况。我们将这些错误分为四类:冗长、错误事实、信息缺失和无差错(表示内容无瑕疵)。结果表明,大多数错误是信息缺失,其次是冗长和事实错误。此外,生成的文章中历史和导言部分的错误数量最多,而应用部分的表现最好。

2.3.2. Novel Entity Mention
为了进一步研究生成内容的有趣程度,我们按照(Lee 等人,2022 年)的方法研究了新颖实体的提及情况。具体来说,我们检查了调查内容,将其中的实体与 ground truth 中的实体并列起来。我们使用 Stanza(Qi 等人,2020 年)来识别 LLM 生成的文本和 ground truth 中所有类型的所有实体。
随后,我们量化了在 LLM 生成的内容中出现的独特实体的数量。为了进行公平比较,除了 GPT-3.5 的 zero-shot 外,我们还评估了 LLaMa2-13b、PaLM2 和 GPT-4 的 one-shot,如图 2 所示。我们的研究结果表明,PaLM2 在实体提及方面的变化最小,而 LLaMa2-13b 则最大。
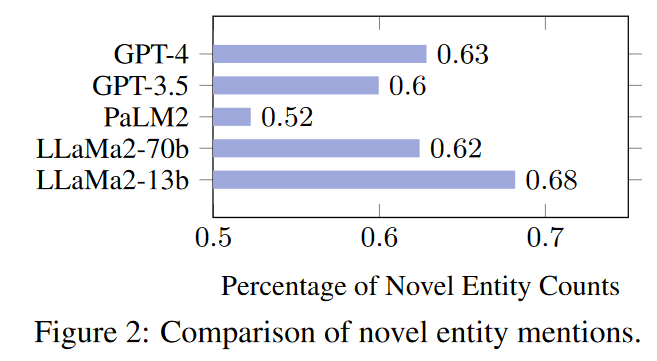
尽管 GPT-4 在自动和人工评估中都表现出色,但我们在其实体提及中并没有发现明显的新颖性。我们推测,这可能是在生成与 ground truth 相关的高保真内容时固有的妥协。到目前为止,关于 RQ1,虽然 LLMs 根据预定义的标准取得了值得称赞的结果,但不足之处显而易见。具体来说,我们发现了一些遗漏的细节,尤其是在 "导言 "和 "历史 "部分。虽然 LLM 经常引入新的实体,但我们并没有发现这种倾向与它们的性能之间存在明显的相关性。更多案例研究见附录 D。
2.3.3. LLM 与人类偏好
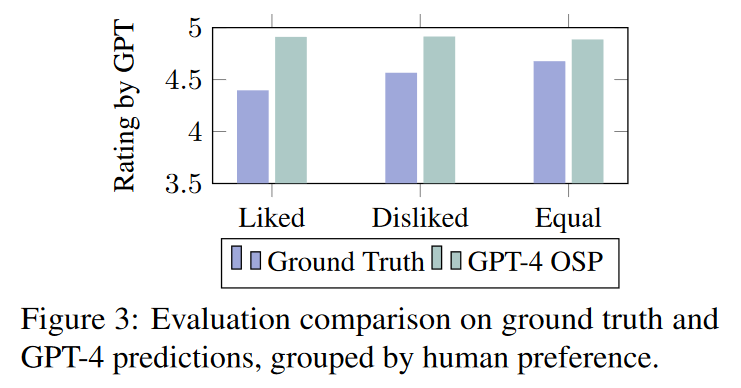
以前的研究表明,基于 LLM 的评估方法倾向于 LLM 生成的内容(Liu 等人,2023b)。为了在调查生成任务中检验这一论断的真实性,我们借此机会调查了在调查生成任务中是否也存在类似的观察结果。因此,我们招募了两名人类专家,对 ground truth 调查文章和使用最佳 GPT-4 设置生成的文章进行并排盲比,他们根据 "Likeability"对内容进行评估(Chiang 和 Lee,2023 年)。随后,我们将调查文章分为三类:a)(人类专家)喜欢;b)(人类专家)不喜欢;c)同等(同样好)。专家们的意见非常一致,科恩卡帕评分为 0.68(Cohen's Kappa,1960 年)。在出现分歧的情况下,我们随机抽取一个分数来达成最终共识。然后,我们对前四项标准进行 GPT-4 评估打分,排除了事实性和完整性,因为两者都无法进行盲测。
图 3 显示了所有 99 个概念的平均评分。一个主要的观察结果是,GPT-4 偏重于自己生成的文本,并一直给予较高的评分--这与其他研究的观察结果一致(刘等人,2023b)。在评估 ground truth 时,GPT-4 在所有三个类别中始终给予较低的评分。耐人寻味的是,在考虑 ground truth 时,GPT-4 显示出对人类 "不喜欢 "组的偏好,这种倾向与人类的倾向背道而驰。。这表明,在评估人类撰写的文本时,GPT-4 可能还不能完美地替代人类的辨别能力。因此,针对 RQ3,我们发现 GPT-4 对带有特定偏见的机器生成的文本表现出明显的偏好。此外,我们认为,GPT-4 完全取代人类专家是一个具有挑战性的问题,人工内容检查仍然离不开人类的专业知识。
2.4. Discussion and Conclusion
在这项工作中,我们评估了 LLM 撰写 NLP 概念调查的能力。我们发现,尽管存在信息不完整等缺陷,但 LLM(尤其是 GPT-4)可以按照特定的指导原则撰写调查报告,其质量可与人类专家相媲美。我们的研究结果还表明,在评估人类撰写的文本时,GPT-4 可能无法完全替代人类的判断,而且在要求它对机器生成的文本进行评分时,也存在一定的偏差。不过,这些结果表明,这些先进的生成式 LLM 可以在教育领域发挥变革性作用。它们有望为普通学习者量身定制有效的特定领域知识结构。这种适应性有可能带来更具互动性和个性化的学习体验,使学生能够参与查询驱动的学习,直接满足他们独特的好奇心和学习目标。
2.5. Limitations
虽然 GPT-4 可以制作符合时代并易懂的内容,但在某些情况下,讨论的话题的深度和细节会受到影响,从而导致潜在的信息缺口。GPT-4 偶尔会产生与事实不符的内容。这就需要额外的验证,尤其是对于准确性要求极高的教育材料。在比较人类专家和 GPT-4 的评分时,发现 GPT 评估存在系统性偏差(GPT-4在评估文本时倾向于给予机器生成的文本更高的评分,而不是人类编写的文本。这种偏差表明,尽管GPT-4在许多方面能够模拟人类的评估标准,但在某些情况下,它可能无法完全公正地评估不同来源的文本,特别是当评估对象包括它自己生成的文本时。)。这会导致结果偏差,并有可能误导对生成内容的质量感知。