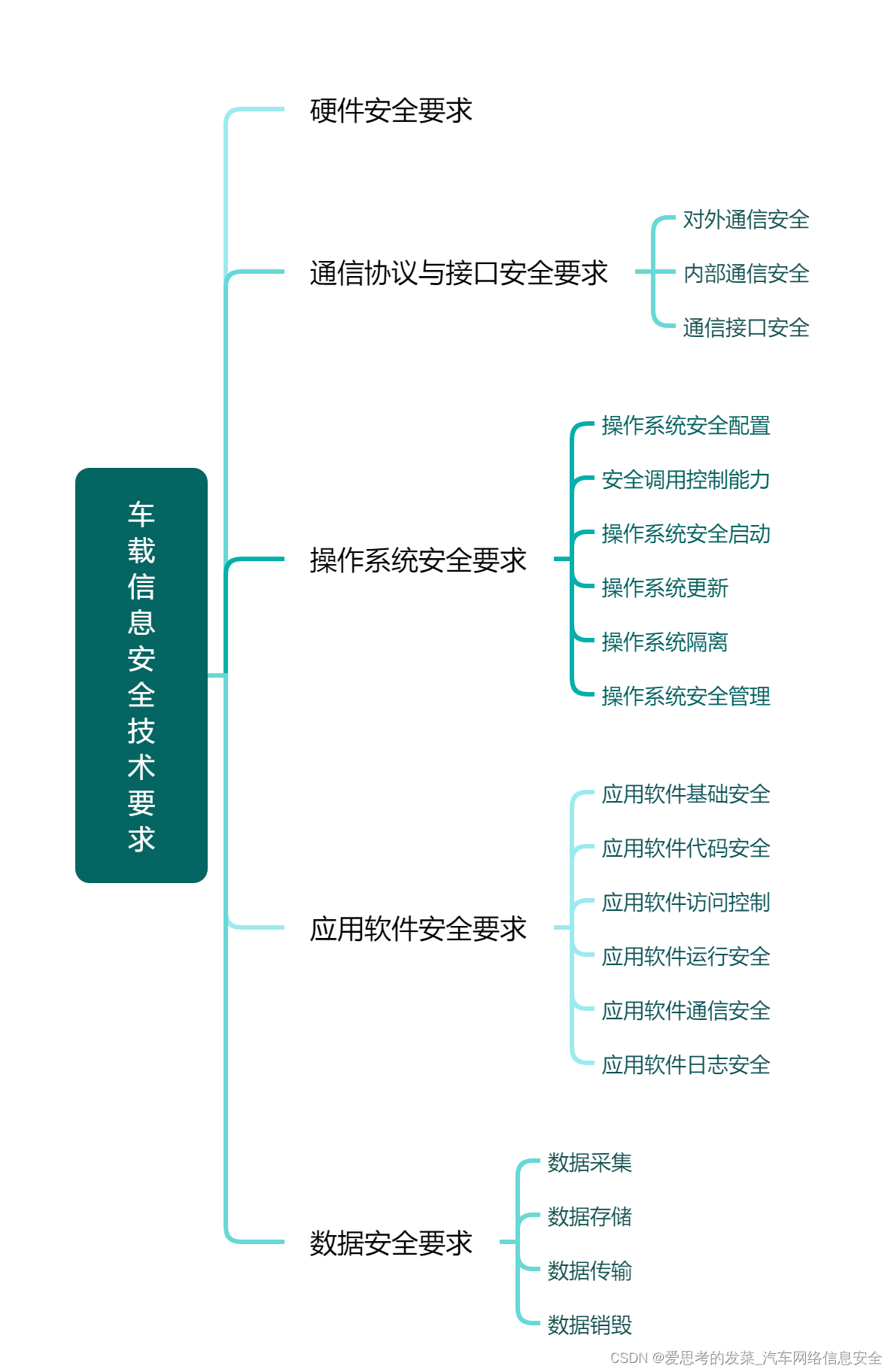
文章目录
- 1、前言
- 2、安装运行环境
- 3、下载v10s模型
- 4、代码实现
- 5、代码详读
- 5.1、导入必要的库
- 5.2、识别车辆
- 5.3、读取视频文件
- 5.4、创建视频写入器
- 5.5、车速计算
- 5.6、统计车辆
- 5.7、应用跟踪
- 5.8、视频处理
- 6、目标检测系列文章
1、前言
在智能交通系统(ITS)的快速发展中,对车辆进行精确的检测和跟踪是实现交通监控、流量分析和安全预警的关键技术。本项目是基于YOLOv10的车辆统计跟踪与车速计算。
主要功能:
(1)车辆类别检测
(2)车辆进出统计
(3)车辆速度检测
(4)车辆ID分配
(5)车辆跟踪
目标计数过程通常包括四个主要步骤:
- 图像预处理:该步骤通过去噪、过滤和增强等技术处理输入图像或视频帧,以提高计数准确性。
- 目标检测:此步骤旨在识别预处理图像或视频中的特定对象。流行的目标检测算法包括Faster R-CNN、YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)。
- 目标跟踪:在该步骤中,在连续图像帧序列中跟踪相同的对象。常见的目标跟踪算法包括KCF(Kernelized Correlation Filter)、TLD(Tracking, Learning, and Detection)、MOSSE(Minimum Output Sum of Squared Error)和 DeepSORT、Botsort 和 Bytetrack。目标跟踪确保在动态视频的连续帧中不会多次计数相同的对象。
- 目标计数:最后一步涉及计算检测到的和跟踪到的对象数量。
实现效果
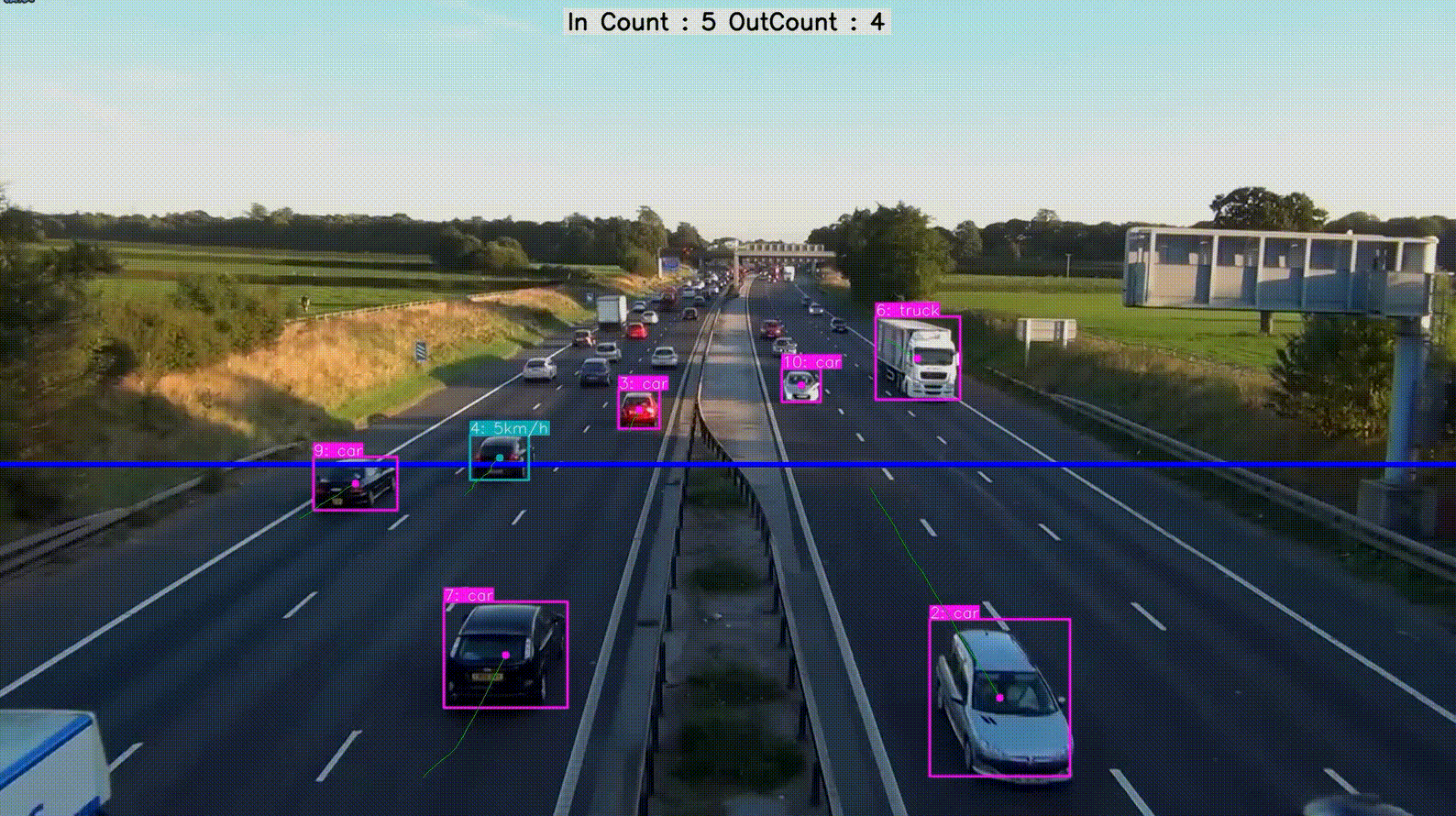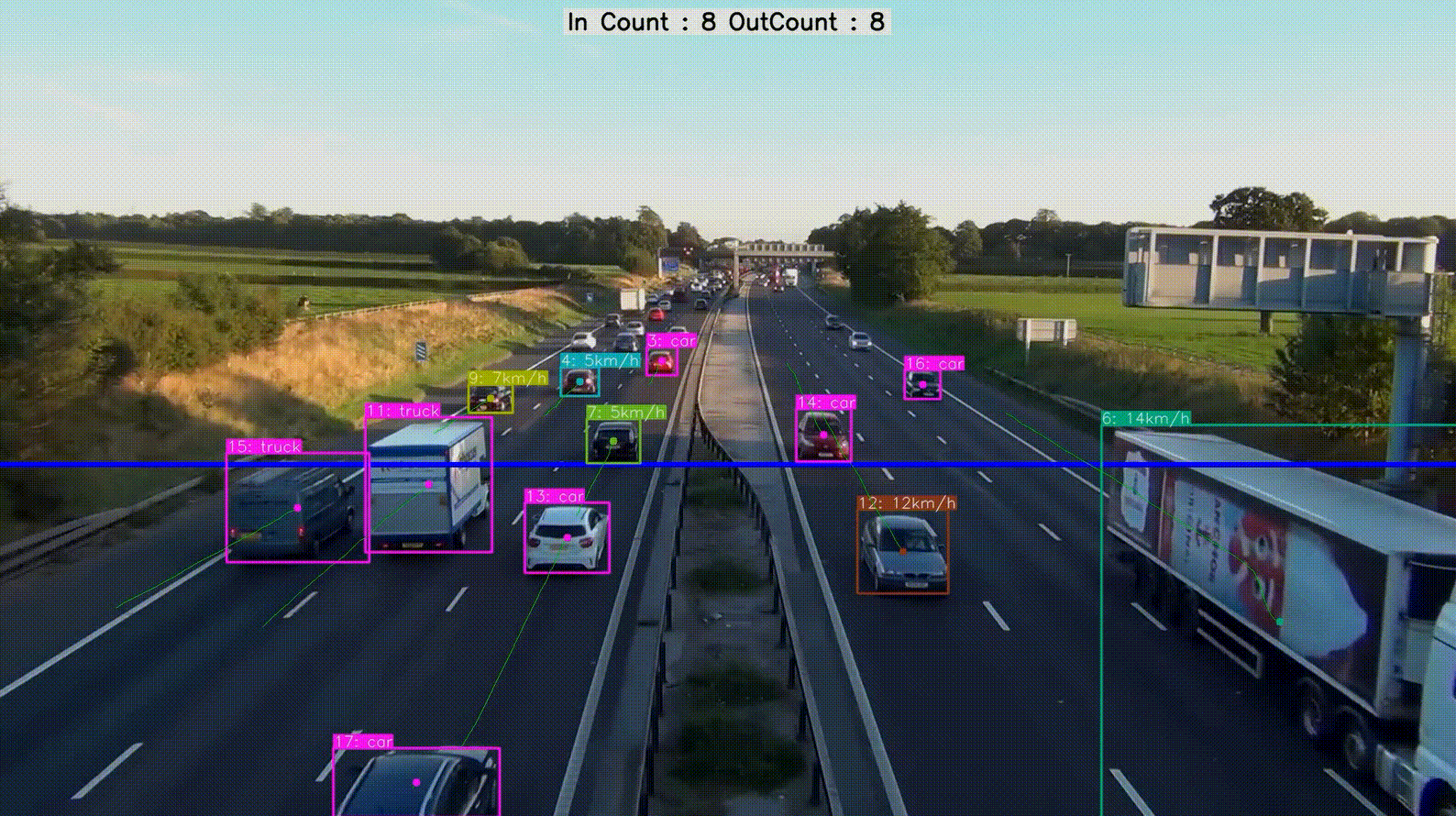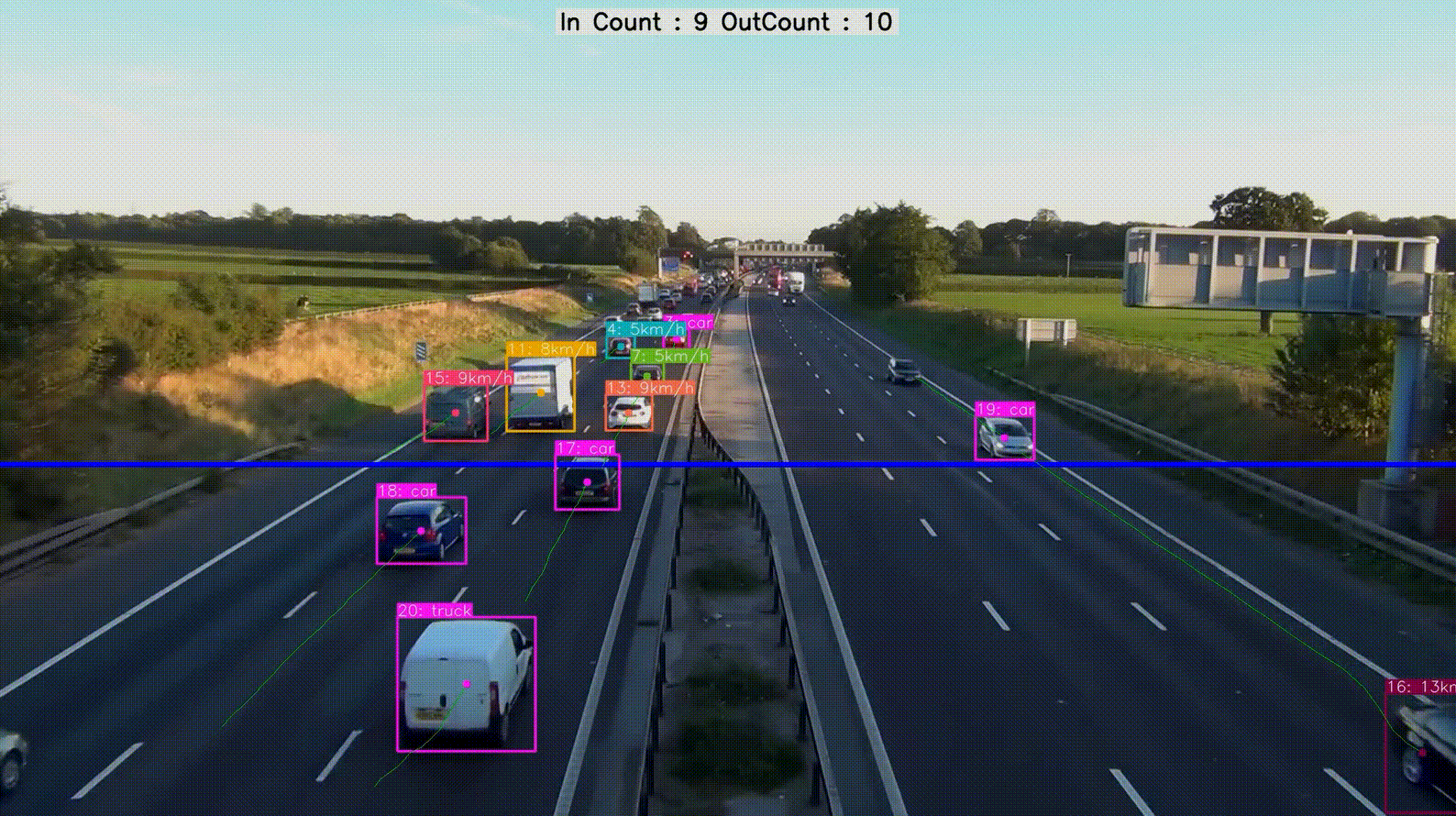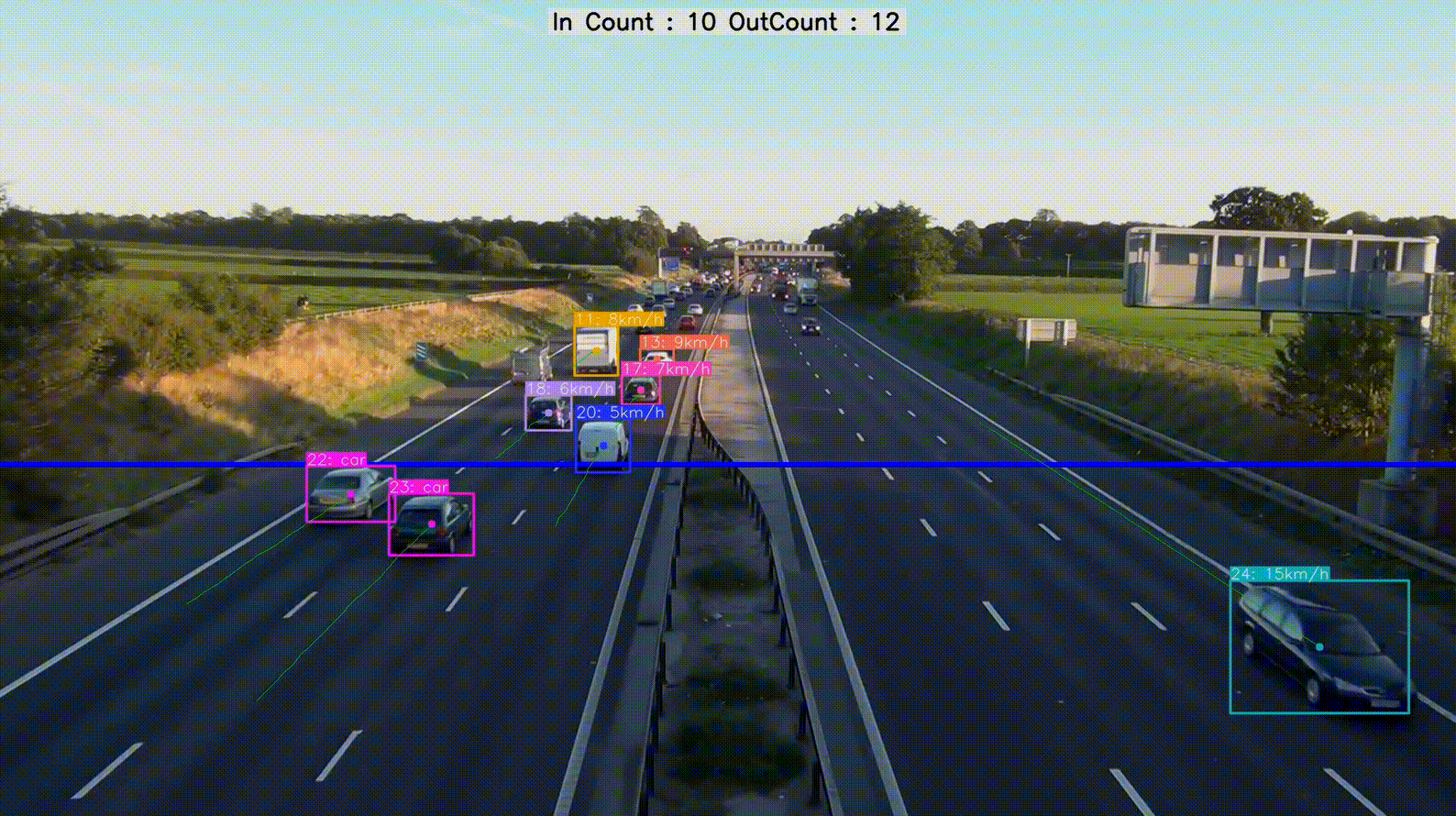
论文地址https://arxiv.org/pdf/2405.14458
项目地址(https://github.com/THU-MIG/yolov10
2、安装运行环境
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt
pip install -e .
3、下载v10s模型
下载官方提供的与训练模型,这里我们直接使用YOLOv10-S.pt。

模型下载
YOLOv10-N
YOLOv10-S
YOLOv10-M
YOLOv10-B
YOLOv10-L
YOLOv10-X
4、代码实现
from ultralytics import YOLOv10
from ultralytics.solutions import speed_estimation,object_counter
import cv2
import argparse
def parse_opt():
parser = argparse.ArgumentParser()
# person tracker params
parser.add_argument('--weight', type=str, default='yolov10s.pt')
parser.add_argument('--save_video', action = 'store_true')
parser.add_argument('--input_video_path', type=str, default='./video/car-test.mp4',help='source video path.')
parser.add_argument('--output_video_path', type=str, default='result_video.mp4',help='output video inference result storage path.')
opt = parser.parse_args()
return opt
def main():
#获取命令行参数
opt = parse_opt()
# 加载YOLOv10模型
model = YOLOv10(opt.weight)
# 获取模型中的对象名称
names = model.model.names
# 打开视频文件
cap = cv2.VideoCapture(opt.input_video_path)
assert cap.isOpened(), "Illegal or non-existing video file"
# 获取视频的宽度、高度和帧率
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# 创建视频写入器,用于输出处理后的视频
video_writer = cv2.VideoWriter(opt.output_video_path,
cv2.VideoWriter_fourcc(*'mp4v'),
fps,
(w, h))
# 设置测速线段的两个端点,一条直线,(x,y)
line_pts = [(0, 615), (1920, 615)]
# 初始化速度估计器
speed_obj = speed_estimation.SpeedEstimator()
# 设置速度估计器的参数,包括测速线段、对象名称和是否实时显示图像
# 计数区域或线。只有出现在指定区域内或穿过指定线的对象才会被计数。
speed_obj.set_args(reg_pts=line_pts,
names=names,
view_img=True)
# 初始化计数器
counter_obj = object_counter.ObjectCounter()
counter_obj.set_args(reg_pts = line_pts,
classes_names = names,
view_img = False)
# 循环读取视频帧
while cap.isOpened():
# 读取一帧
success, im0 = cap.read()
# 如果读取失败,则退出循环
if not success:
break
tracks = model.track(im0, persist=True, show=False)
im0 = counter_obj.start_counting(im0, tracks)
im0 = speed_obj.estimate_speed(im0, tracks)
# 将处理的结果保存为视频
if opt.save_video is not None:
video_writer.write(im0)
# 释放视频读取器和写入器
cap.release()
video_writer.release()
# 销毁所有OpenCV窗口
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
5、代码详读
5.1、导入必要的库
from ultralytics import YOLOv10
from ultralytics.solutions import speed_estimation
import cv2
这段代码导入了ultralytics库中的YOLOv10模型和速度估计模块,以及OpenCV库,用于视频处理。
5.2、识别车辆
为了识别物体,我们使用了可以从ultralytics库中获得的预训练 YOLO模型。该算法可以实时识别感兴趣的物体,并且准确率很高。这里加载了预训练的YOLOv10模型,用于识别车辆。
model = YOLOv10("yolov10n.pt")
names = model.model.names
5.3、读取视频文件
# 要处理的视频
parser.add_argument('--input_video_path', type=str, default='./video/car-test.mp4',help='source video path.')
# 打开视频文件
cap = cv2.VideoCapture(opt.input_video_path)
assert cap.isOpened(), "Illegal or non-existing video file"
# 获取视频的宽度、高度和帧率
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
这段代码读取名为"car-test.mp4"的视频文件,并获取视频的宽度、高度和帧率。
5.4、创建视频写入器
parser.add_argument('--input_video_path', type=str, default='./video/car-test.mp4',help='source video path.')
video_writer = cv2.VideoWriter(opt.input_video_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
这里创建了一个视频写入器,用于将处理后的视频帧写入新的视频文件。
5.5、车速计算
line_pts = [(0, 615), (1920, 615)]
speed_obj = speed_estimation.SpeedEstimator()
speed_obj.set_args(reg_pts=line_pts, names=names, view_img=True)
im0 = speed_obj.estimate_speed(im0, tracks)
这段代码设置了用于速度估计的参考线line_pts,并初始化了速度估计器,同时设置了相关参数,view_img实时获取处理完的帧。
| Name | Type | Default | Description |
|---|---|---|---|
| names | dict | None | Dictionary of class names. |
| reg_pts | list | [(20,400),(1260,400)] | List of region points for speed estimation. |
| view_img | bool | False | Whether to display the image |
| line_thickness | int | 2 | Thickness of the lines for drawing boxes and tracks. |
| region_thickness | int | 5 | Thickness of the region lines. |
| spdl_dist_thresh | int | 10 | Distance threshold for speed calculation. |
速度计算的基本原理:
SpeedEstimator函数通过存储随时间推移的跟踪位置来处理帧,因此通过比较当前位置与定义区域内的先前位置来计算每个检测到的物体的速度,从而可以通过物体在该区域内移动所需的时间来估算物体的速度,这遵循了物理学中一个非常著名的术语:v = Δs/Δt, 其中,v为速度,Δs为位移(距离),Δt为时间间隔。
5.6、统计车辆
# 初始化计数器
counter_obj = object_counter.ObjectCounter()
counter_obj.set_args(reg_pts = line_pts,
classes_names = names,
view_img = False)
im0 = counter_obj.start_counting(im0, tracks)
通过实例化object_counter.ObjectCounter()类 得到一个车辆统计器,调用start_counting()函数开启车辆统计。
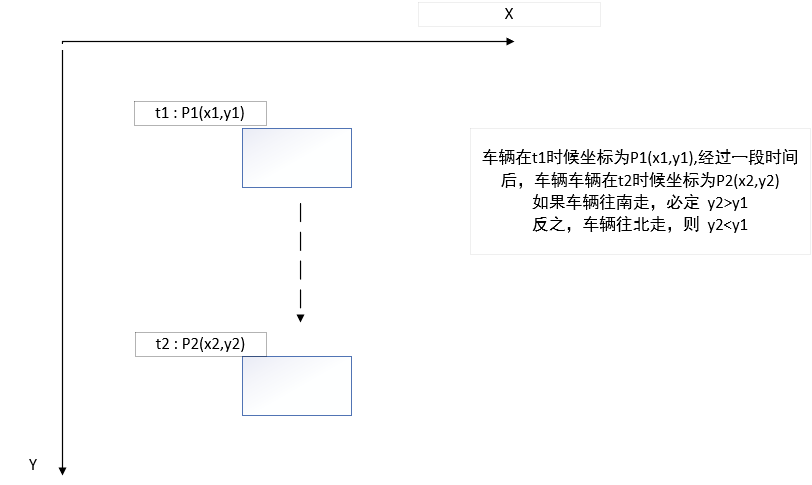
其中车辆进出方向可以通过根据两个点的相对位置计算出移动方向。
def get_direction(point1, point2):
"""
根据两个点的相对位置计算出移动方向, point1和point2都是左上角坐标
即point1=x1,y1
point1,point2只是时间点不同的坐标。
"""
direction_str = ""
# 根据两个点在y轴上的相对位置,确定是向南还是向北移动
if point1[1] < point2[1]:
direction_str += "In"
elif point1[1] > point2[1]:
direction_str += "Out"
else:
direction_str += ""
# 根据两个点在x轴上的相对位置,确定是向东还是向西移动
if point1[0] < point2[0]:
direction_str += "East"
elif point1[0] > point2[0]:
direction_str += "West"
else:
direction_str += ""
return direction_str
5.7、应用跟踪
YOLO模型中还包含一个跟踪算法,旨在通过连续帧连续监视和跟踪特定对象的运动。它的实现很简单,如下所示:
# 由于需要跨帧对象跟踪(避免在不同帧中多次计数同一个人或车辆),需要保留所有先前帧的检测结果。
tracks = model.track(im0, persist=True, show=False)
| Name | Type | Default | Description |
|---|---|---|---|
| source | im0 | None | source directory for images or videos |
| persist | bool | False | persisting tracks between frames |
| tracker | str | botsort.yaml | Tracking method ‘bytetrack’ or ‘botsort’ |
| conf | float | 8.3 | Confidence Threshold |
| iou | float | 0.5 | lOU Threshold |
| classes | list | None | filter results by class, i.e. classes=0, or classes=[0,2,3] |
| verbose | bool | True | Display the object tracking results |
5.8、视频处理
通过cv2中VideoCapture()获取cap对象,对视频进行处理。
# 视频帧处理循环:
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
tracks = model.track(im0, persist=True, show=False)
im0 = counter_obj.start_counting(im0, tracks)
im0 = speed_obj.estimate_speed(im0, tracks)
video_writer.write(im0)
在这个循环中,代码逐帧读取视频,使用YOLOv10模型进行对象跟踪,然后使用速度估计器估计对象的移动速度,并将结果写入新的视频文件。
# 释放资源:
cap.release()
video_writer.release()
cv2.destroyAllWindows()
最后,释放视频读取器和写入器的资源,并关闭所有OpenCV创建的窗口。
6、目标检测系列文章
- YOLOv5s网络模型讲解(一看就会)
- 生活垃圾数据集(YOLO版)
- YOLOv5如何训练自己的数据集
- 双向控制舵机(树莓派版)
- 树莓派部署YOLOv5目标检测(详细篇)
- YOLO_Tracking 实践 (环境搭建 & 案例测试)
- 目标检测:数据集划分 & XML数据集转YOLO标签
- DeepSort行人车辆识别系统(实现目标检测+跟踪+统计)
- YOLOv5参数大全(parse_opt篇)
- YOLOv5改进(一)-- 轻量化YOLOv5s模型
- YOLOv5改进(二)-- 目标检测优化点(添加小目标头检测)
- YOLOv5改进(三)-- 引进Focaler-IoU损失函数
- YOLOv5改进(四)–轻量化模型ShuffleNetv2
- YOLOv5改进(五)-- 轻量化模型MobileNetv3
- YOLOv5改进(六)–引入YOLOv8中C2F模块
- YOLOv5改进(七)–改进损失函数EIoU、Alpha-IoU、SIoU、Focal-EIOU
- YOLOv5改进(八)–引入Soft-NMS非极大值抑制
- YOLOv5改进(九)–引入BiFPN模块