Lseg
在clip后面加一个分割head,然后用分割数据集有监督训练。textencoder使用clip,frozen住。
group ViT
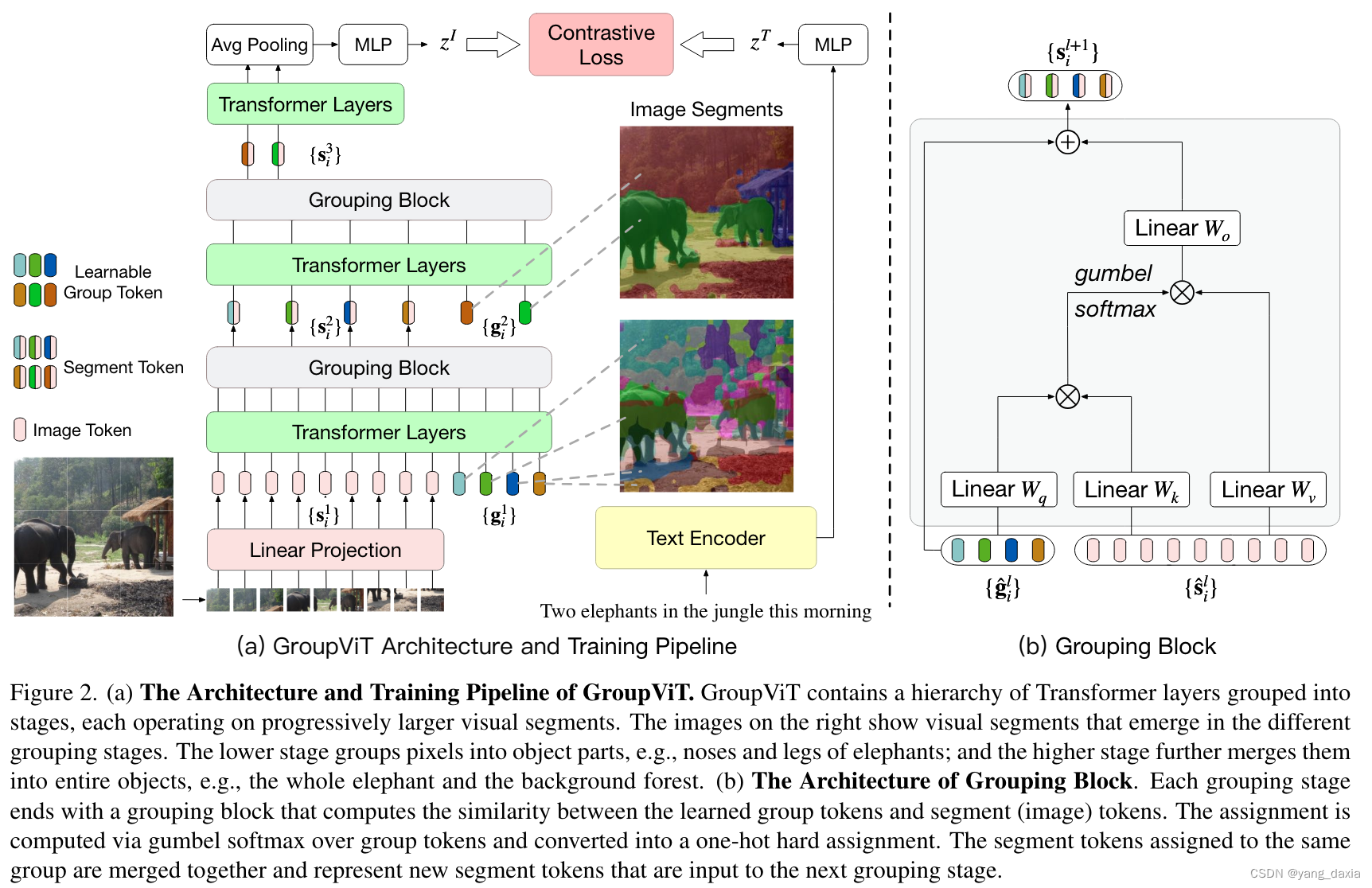
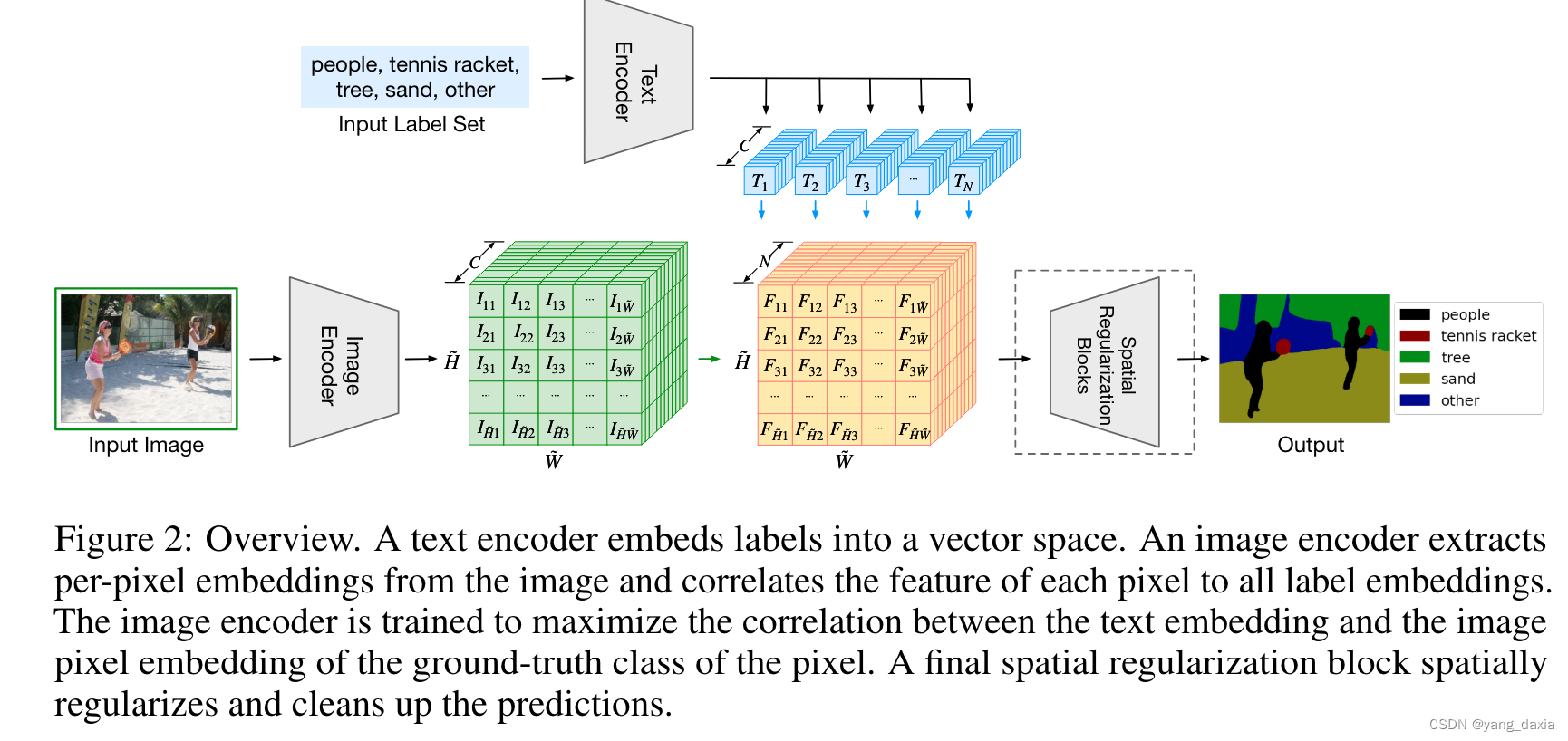
与Lseg不同,借鉴了clip做了真正的无监督学习。
具体的通过group block来做的。使用学习的N个group token(可以理解为聚类中心数量)与图像做attention。分别加入两次。一个为64个,一次为8个(粗聚类->精聚类),最后pooling后与文本做对比学习。
结果发现分割已经做的很好了。分类结果还差一些。
ViLD
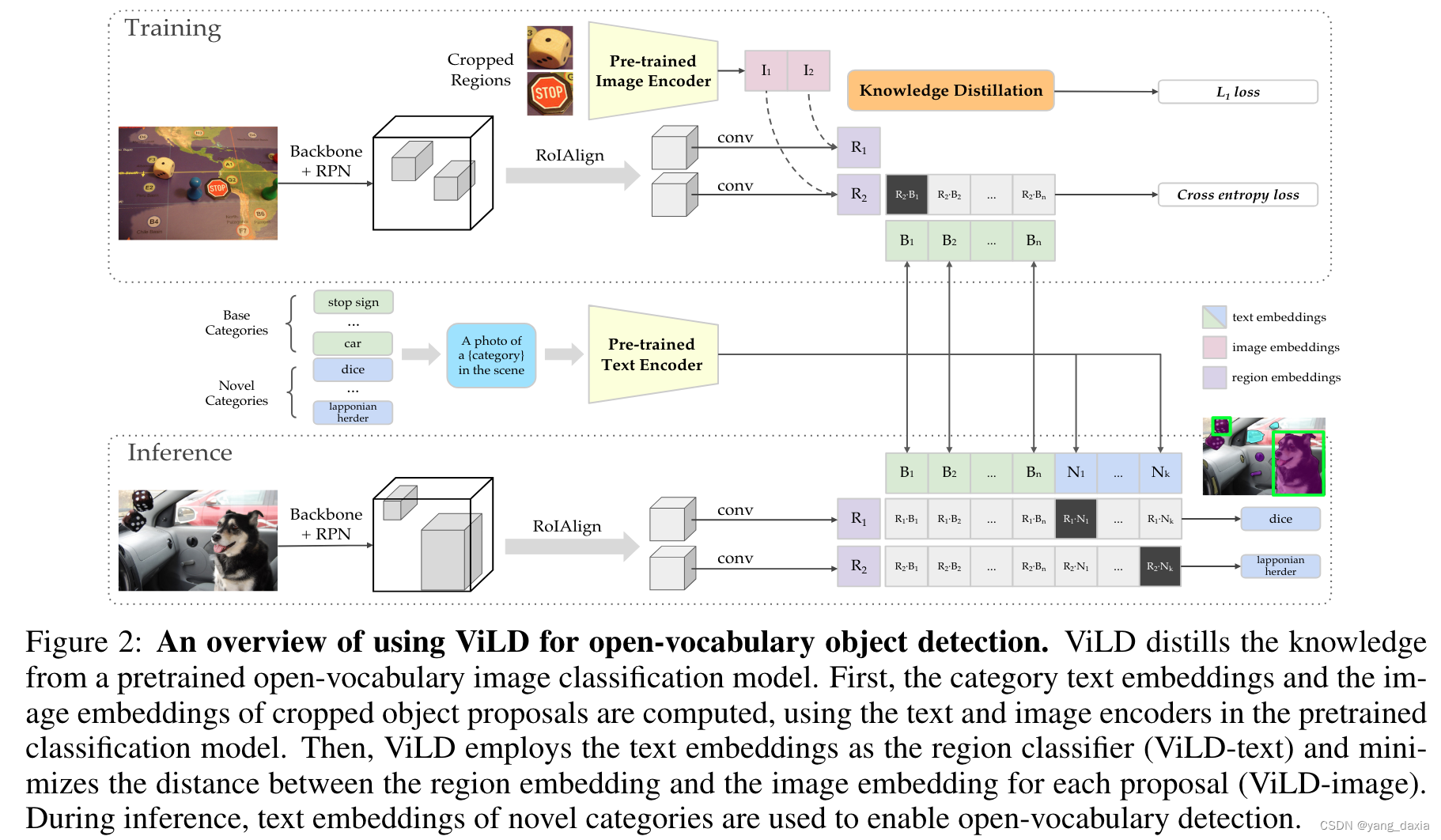
clip+目标检测
对N个proposal与text(open 类别)分别提特征,然后计算相似度。
然后额外增加一个分支,对M个proposal的图片(N里面取topM)使用clip的Image encoder提特征,与目标检测的图片特征做知识蒸馏。
Glip
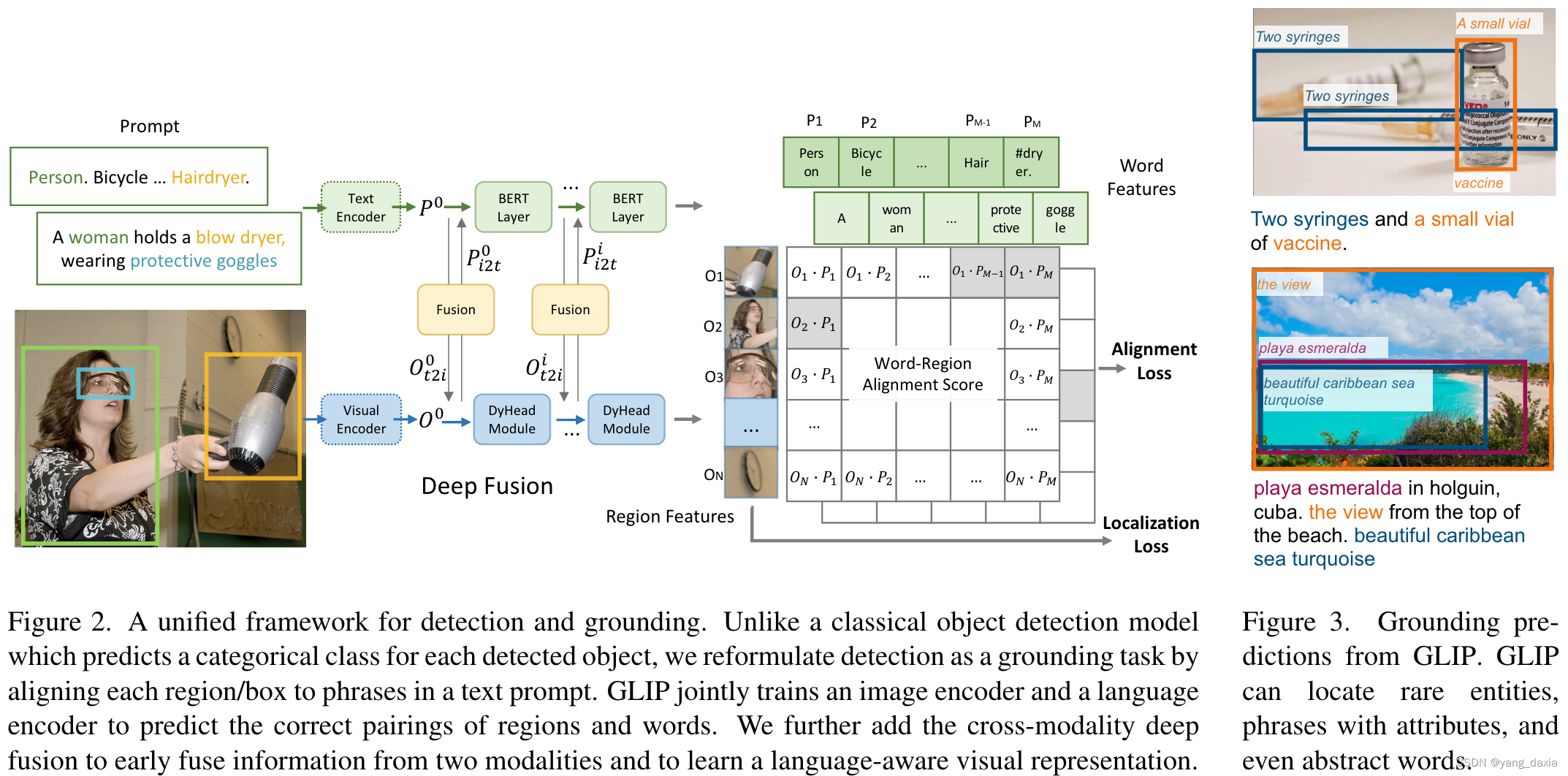
统一了检测和grounding(类似VQA),又使用了伪标签,引入了非常多的图像文本对,用于预训练,效果非常好。
具体做法和clip很像,文本分支,和图像分支算距离,然后求alignment loss(相当于分类分支),再加一个定位loss。
然后加入了一个文本图像的融合模块(使用cross-attention),整个框架和ViLD-text很像。