文章目录
- 4.使用kibana操作es
- 4.1.文档操作
- 1.put方式发送数据
- 2.post方式发送数据
- 3.查看索引文档 GET
- 4.更新文档 POST
- 5.删除文档&索引 DELETE
- 6.批量添加数据_bulk
- 4.2.Query DLS(查询领域对象语言)
- 1.url 检索数据语法
- 2.查询所有数据
- 3.查询全部数据并排序
- 4.查询全部数据排序并分页
- 5.区间查询
- 6.全文检索 match
- 7.短语匹配 match_phrase
- 8.multi_match 多字段匹配
- 9.bool复合查询 多个条件进行匹配查询
- 10.filter结果过滤
- 11.term 非全文检索
- 4.3.Mapping映射
- 1.创建索引和字段映射类型
- 2.查看该索引下的字段映射类型
- 3.新增映射字段类型
- 4.4.数据迁移
4.使用kibana操作es
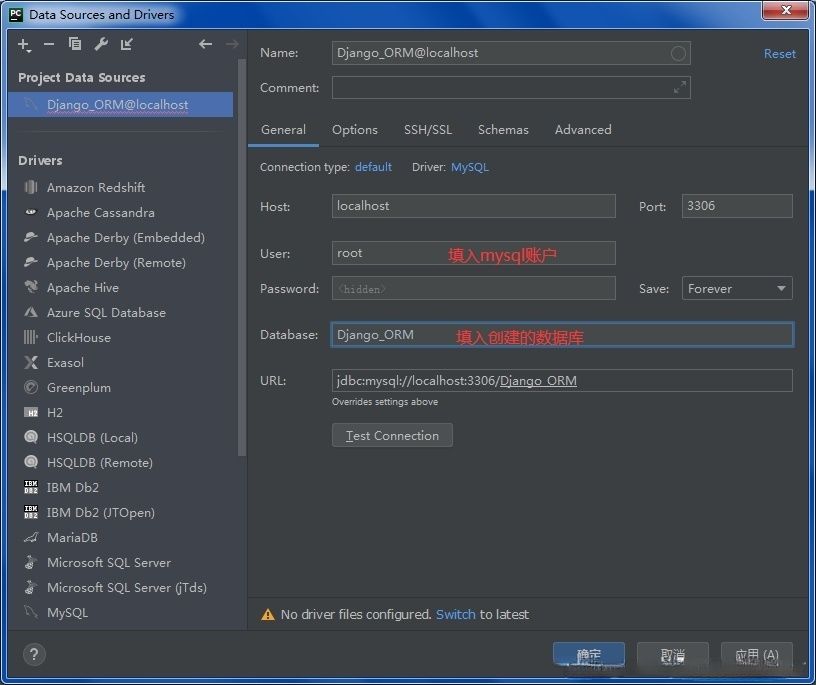
点击Dev Tools,进入操作控制台
4.1.文档操作
1.put方式发送数据
没有索引会自动创建并保存数据,如果id相同则会覆盖
PUT news/_doc/1
{
"username":"zhangsan",
"age":10
}
执行结果:
每次执行版本号**_version**加一
{
"_index" : "news",
"_type" : "_doc",
"_id" : "1",
"_version" : 6,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
2.post方式发送数据
POST news/_doc/2
{
"username":"lisi",
"age":19
}
执行结果:
{
"_index" : "news",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 8,
"_primary_term" : 1
}
3.查看索引文档 GET
GET news/_doc/2
执行结果:
{
"_index" : "news",
"_type" : "_doc",
"_id" : "2",
"_version" : 3,
"_seq_no" : 10,
"_primary_term" : 1,
"found" : true,
"_source" : {
"username" : "lisi",
"age" : 19
}
}
4.更新文档 POST
可更新指定字段
POST news/_doc/1/_update
{
"doc":{
"username":"aaa"
}
}
执行结果:
post的_update会有检查功能,如果执行的语句与数据没有变化时是不会更新数据而且任何版本号也不会更新.
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
{
"_index" : "news",
"_type" : "_doc",
"_id" : "1",
"_version" : 11,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 13,
"_primary_term" : 1
}
上面执行时会有该提示
Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
该方式也可以执行成功
POST news/_update/1
{
"doc":{
"username":"bbb"
}
}
5.删除文档&索引 DELETE
ElasticSearch执行删除操作时,标记文档为 deleted状态,而不是直接物理删除。当ES存储空间不足/工作空闲时,再进行删除。
ElasticSearch执行修改操作时,ES不会真的修改Document中的数据,而是标记ES中原有的文档为deleted状态,再创建一个新的文档来存储数据。
DELETE news/_doc/2
执行结果:
{
"_index" : "news",
"_type" : "_doc",
"_id" : "2",
"_version" : 4,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 14,
"_primary_term" : 1
}
删除文档
DELETE news/
执行结果:
{
"acknowledged" : true
}
6.批量添加数据_bulk
PUT news/_doc/_bulk
{"index":{"_id":1}}
{"username":"zhangsan1","address":"Beijing","age":1}
{"index":{"_id":2}}
{"username":"lisi","address":"Beijing aaa bbb","age":2}
{"index":{"_id":3}}
{"username":"wangwu","age":3}
执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
"took" : 53,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "news",
"_type" : "_doc",
"_id" : "1",
"_version" : 5,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 10,
"_primary_term" : 1,
"status" : 200
}
},
{
"index" : {
"_index" : "news",
"_type" : "_doc",
"_id" : "2",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 11,
"_primary_term" : 1,
"status" : 200
}
},
{
"index" : {
"_index" : "news",
"_type" : "_doc",
"_id" : "3",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 12,
"_primary_term" : 1,
"status" : 200
}
}
]
}
4.2.Query DLS(查询领域对象语言)
1.url 检索数据语法
需选择数字之类可以排序字段
GET news/_search?q=*&sort=age:asc
2.查询所有数据
GET news/_search
{
"query": {
"match_all": {}
}
}
3.查询全部数据并排序
#按年龄降序
GET news/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
4.查询全部数据排序并分页
from类似于mysql的offset,从第from个索引数据开始取size条
GET news/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
5.区间查询
#取出第二和第三条数据
GET news/_search
{
"query": {
"range": {
"age": {
"gte": 2,
"lte": 3
}
}
}
}
6.全文检索 match
match会针对text内容进行分词检索
GET news/_search
{
"query": {
"match": {
"address": "Beijing"
}
}
}
7.短语匹配 match_phrase
GET news/_search
{
"query": {
"match_phrase": {
"address": "Beijing aaa"
}
}
}
8.multi_match 多字段匹配
要查询的内容为Beijing 可以设置某几个字段是否包含该值
GET /news/_search
{
"query": {
"multi_match": {
"query": "Beijing",
"fields": ["username","address","city"]
}
}
}
9.bool复合查询 多个条件进行匹配查询
- must是必须满足
- must_not必须不满足
GET news/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "Beijing"
}},
{"match": {
"username": "lisi"
}}
],
"must_not": [
{"match": {
"age": "1"
}}
]
}
}
}
should 条件可以满足也可以不满足,在查询中如果有满足should的条件就会增加相关性得分.
GET news/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "Beijing"
}},
{"match": {
"username": "lisi"
}}
],
"must_not": [
{"match": {
"age": "1"
}}
],
"should": [
{"match": {
"age": "2"
}}
]
}
}
}
10.filter结果过滤
区间查询:
GET /news/_search
{
"query": {
"bool": {
"must": [
{"range": {
"age": {
"gte": 1,
"lte": 2
}
}}
]
}
},"from": 0,"size":2
}
GET /news/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 1,
"lte": 2
}
}
}
}
}
}
可以发现两个结果是一样的
11.term 非全文检索
对于数字型的值推荐使用term,但是如果是text进行分词检索的内容不要使用term,当使用term中进行文本内容的全量检索时term不会检索任何内容
查询内容只是为数字时 推荐使用term 进行检索 ,但是 text文本内容进行检索时不要使用term
GET /news/_search
{
"query": {
"term": {
"age": {
"value": "2"
}
}
}
}
#当检索的内容非数字的类型时:不会检索到任何结果
GET /news/_search
{
"query": {
"term": {
"address": {
"value": "Beijing"
}
}
}
}
4.3.Mapping映射
1.创建索引和字段映射类型
PUT news
{
"mappings": {
"properties": {
"title":{"type": "text"},
"author":{"type": "keyword"},
"readnum":{"type": "long"}
}
}
}
执行结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "news"
}
在创建映射类型时ES会默认给字段后加入index属性并设置为true,这样就是认为该字段会进行索引也就是能够对该字段进行全文检索,如果一个字段不需进行全文检索就显示的设置为false
2.查看该索引下的字段映射类型
GET news/_mapping
-
在ES中会根据数据自动猜测属性的类型(mapping)
-
同时可以在创建索引时手动的去维护创建映射的类型,Es如果是自动时 会将一些不需要进行全文检索的字段属性都映射为text
-
Es会根据索引的内容进行自动推断类型 ,给索引的数据字段设置类型
-
当es索引类型后不能更改 映射类型 ,如果需要变更 要新的数据迁移 将原有的index删除掉 在重新导入,
-
创建新的index设计映射类型 再去将数据进行迁移
3.新增映射字段类型
在新增字段映射类型时不能够在原有的语句上继续执行,需要额外编写新的语句
PUT news/_mapping
{
"properties":{
"admins":{"type":"keyword"}
}
}
4.4.数据迁移
将测试数据bank/account进行设置新的映射类型,将一些不需要全文检索的字段从新设置.
put /new_news{
"mappings":{
"properties":{
将原来的mapping放进来修改
}
}
}
数据迁移前先需要创建一个新的索引并且修改映射类型
POST _reindex
{
"source": {
"index": "news"
},
"dest": {
"index": "new_news"
}
}