在这里,我总结了本次项目的数据收集过程中遇到的反爬虫策略以及一些爬虫过程中容易出现问题的地方。
user-agent
简单的设置user-agent头部为浏览器即可:

爬取标签中带href属性的网页
对于显示岗位列表的页面,通常检查其源代码就会发现,相应的标签处存在一个a标签,其中存在href属性值:

于是可以选择,爬取出该网页中的所有的href属性,再依次对href属性中的所有的网址进行爬取,
current_job_links=browser.find_elements(by=By.XPATH,value='//li[@class="border-top"]//a[@target="_blank"]')
for link in current_job_links:
job_path = link.get_attribute("href")
job_url = urljoin(self.base_url, job_path)
job_links.append(job_url)
爬取使用js跳转的网页,进行选型卡管理
现在好多都是不存在href,而是使用javascript进行跳转,也就是点击卡片之后会新开一个选项卡,因此这里要使用selenium的选项卡管理来实现browser的url变化,从而获得新打开页面的url(如果不切换选项卡,即使模拟单击了卡片,也不能对打开的页面进行爬虫)
重点在于一定要记得切换选项卡!!
for card_element in card_elements:
# 单击卡片元素
browser.execute_script("arguments[0].click();",card_element)
# 等待新页面加载完成
wait.until(EC.number_of_windows_to_be(2))
# 切换到新的窗口
browser.switch_to.window(browser.window_handles[1])
# 获取新页面的URL
current_url2 = browser.current_url
current_url_list.append(current_url2)
browser.close()
分页爬取
url变化实现换页
大部分网页都是通过url的变化实现翻页的:

因此只需要修改相应网址的pageNo即可,
if self.page < 100:
self.page += 1
# 换url
url = 'https://zhaopin.meituan.com/web/position?hiringType=2_6&pageNo=' +str(self.page)
#再次调用爬虫
yield scrapy.Request(url=url, callback=self.parse, dont_filter=True)
time.sleep(3) # 设置3秒间隔
换页url不变
使用selenium模拟浏览器点击下一页按钮。所以需要在网页中定位到”下一页“按钮的位置
next_button = browser.find_element(by=By.XPATH,value='//[@id="target_list"]/div/div[2]/div[3]/button[2]')
if not next_button.is_enabled():
break
browser.execute_script("arguments[0].click();", next_button)
同时注意判断停止条件,当按钮不可用时表示到达最后
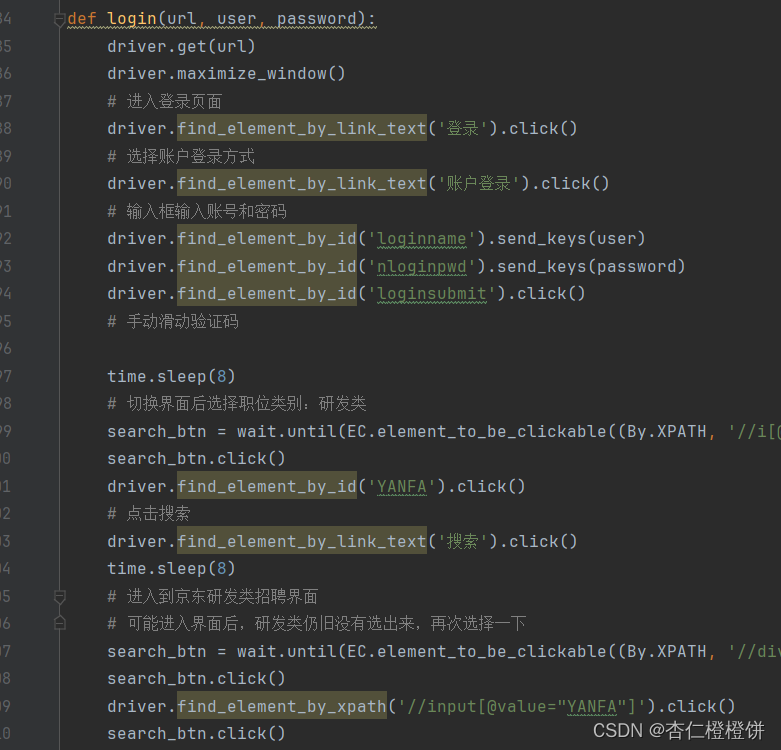
登录问题
在爬取京东招聘时需要首先进行登录
使用如下代码实现模拟登陆: