1. 论文基本信息

2. 创新点
- 介绍了第一个状态空间模型 PointMamba,将其应用与点云分析。
- PointMamba 表现出令人印象深刻的能力,包括结构简单性(例如,vanilla Mamba)、低计算成本和知识可迁移性(例如,对自我监督学习的支持)。
3. 背景
由于 Transformer 的self-attention的计算公式为:
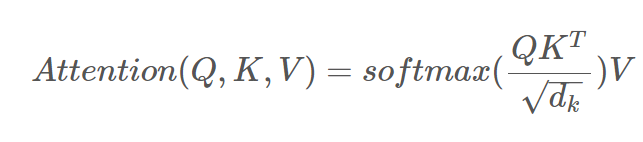
其中,Q是查询矩阵,K是键矩阵,V是值矩阵,d_k是键向量的维度。点积QK^T的计算需要O(n^2)次操作二次复杂度。导致随着注意力窗口的增大也就是 Q K V 的增大 Transformer 的计算复杂度骤增。于是乎文章便提出且关注以下问题:
- how to design a simple, elegant method that operates with linear complexity, thereby retaining the benefits of global modeling for point cloud analysis? 如何设计一种简单的、优雅的线性复杂度操作方法,从而保留了全局建模对点云分析的好处?
而如果直接将 Mamba 模型中的 Mamba Block 直接用于点云的处理效果不理想,这是由于 Mamba 中国的注意力(上下文)是通过压缩历史隐藏状态得到的,而不是通过每个元素之间的交互获得的(与Transformer 中注意力机制的不同)。
4. Pipeline
4.1. 结构化状态空间序列模型(S4)
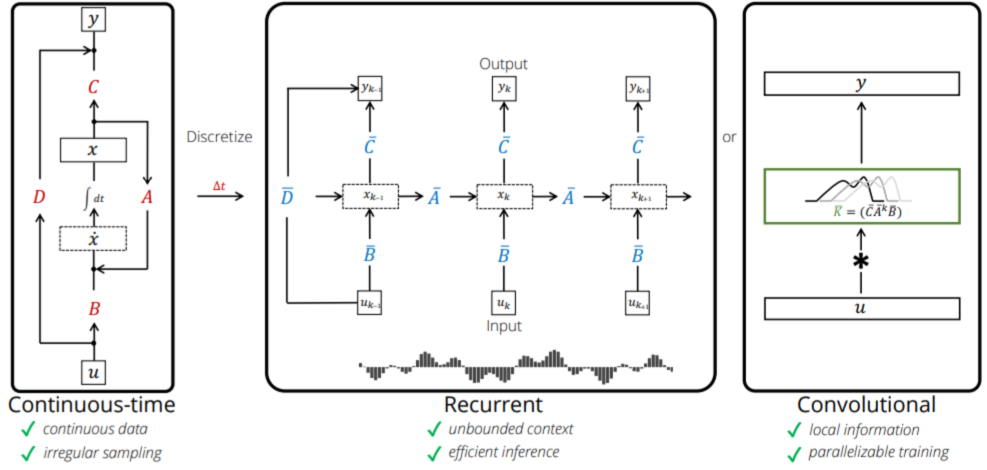
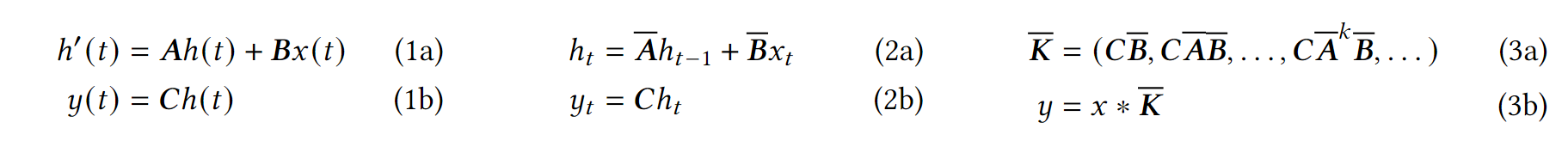
结构化状态空间序列模型(Structured State Space Sequence Models,简称S4)是一种新兴的深度学习序列模型,它与循环神经网络(RNNs)、卷积神经网络(CNNs)及经典的状态空间模型相关联。这些模型受到了一种将一维函数或序列映射到另一个一维函数或序列通过隐式潜在状态的特定连续系统的启发。具体来说,S4模型使用四个参数(Δ(D), A, B, C)定义序列到序列的转换过程,分为两个阶段:
- 第一阶段(离散化):将“连续参数”(Δ(D), A, B)转换为“离散参数”
。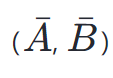
- 第二阶段:通过离散化后的参数计算序列转换,可以通过线性递归或全局卷积两种方式实现。
S4的基础表达:

4.2. 选择性 SSM
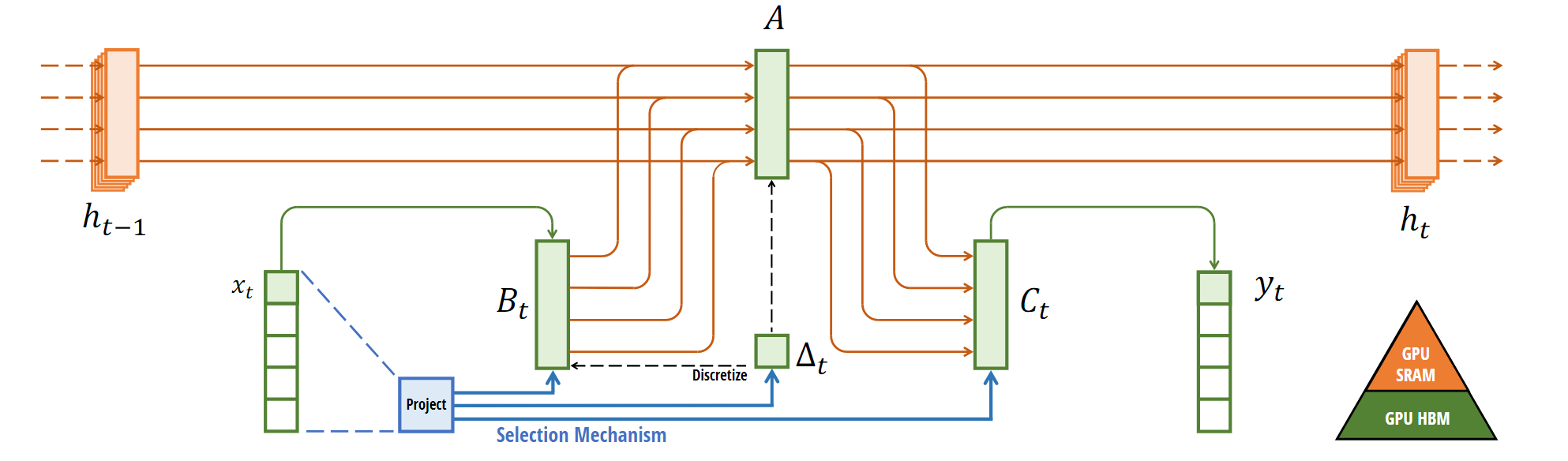
在框架图中,derta T 是通过 \tau(一种非线性激活函数), 因此delta T 是非线性的,所以 ABC 都是非线性时变的,系统的条件就放开了。


sB(x) = Linear(x) , sC(x) = Linearn(x) ,都是线性投影,这是种常见的神经网络操作,用于将输入数据转换到一个新的空间或维度。这里的 linear 表示是用线性层来学习这几个函数。
![]()
广播是一个数组操作,它使得维度较小的数组能够与维度较大的数组进行算术操作。
![]()
,这是个平滑的非线性函数,通常用于网络中以添加非线性特征并帮助网络学习复杂的模式。
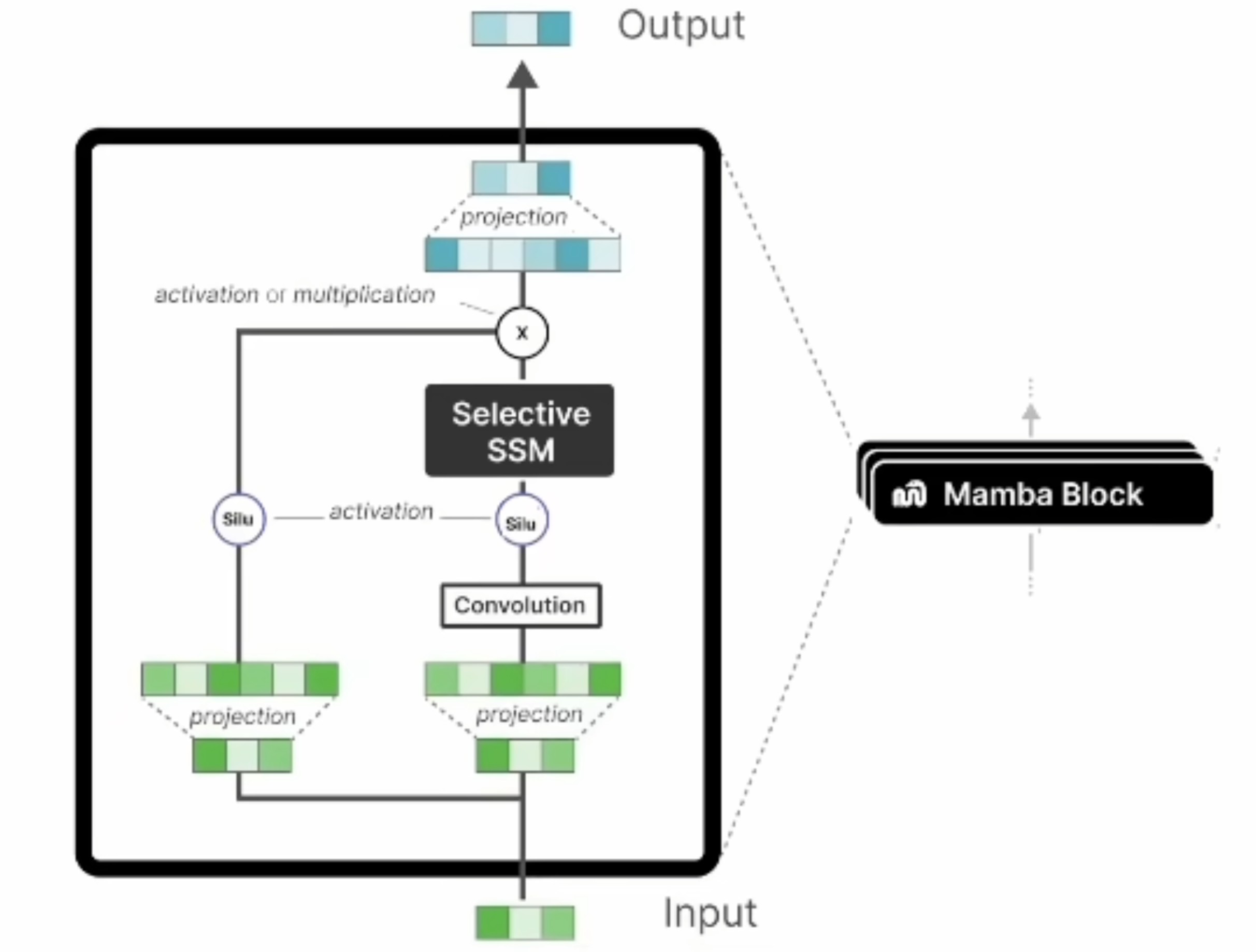
4.3. PointMamba

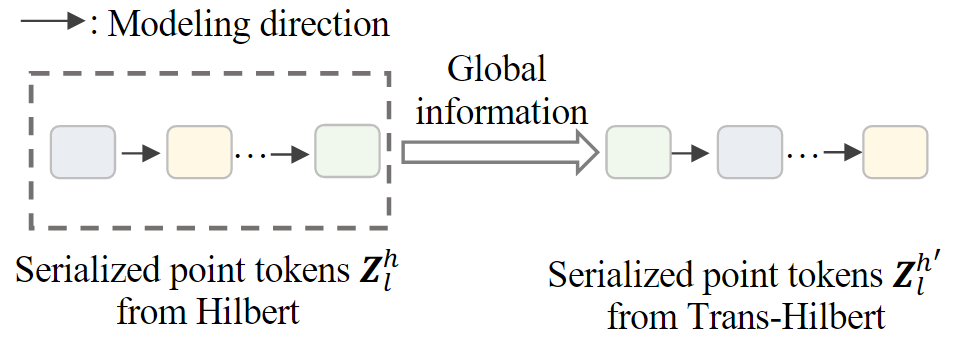
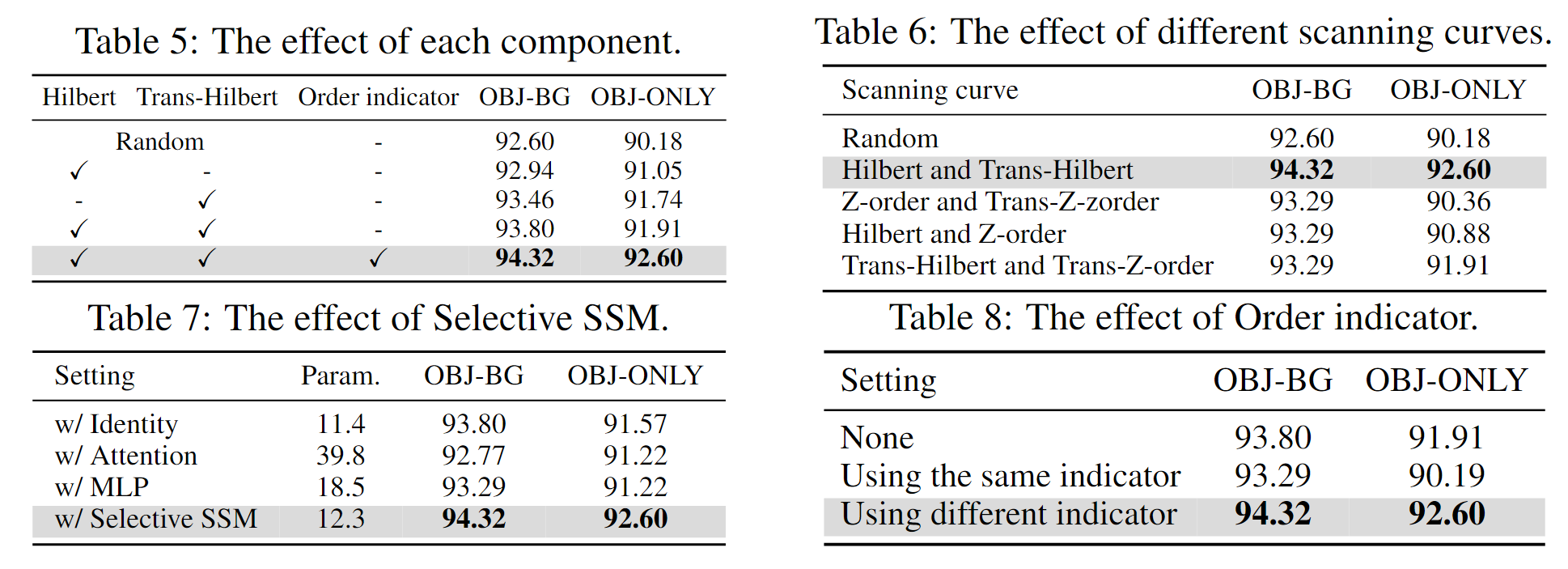
PointMamba 首先利用最远点采样(FPS)来选择关键点。然后利用两种类型的空间填充曲线,包括 Hilbert 和 Trans-Hilbert,来生成序列化的关键点。在此基础上,KNN 用于形成点块,将被馈送到令牌嵌入层以生成序列化的点标记。为了指示从哪个空间填充曲线生成的标记,提出了顺序指标。编码器非常简单,由 N × 普通和非分层 Mamba 块组成。
4.3.1. 点扫描策略
一般来说,采样关键点 p 的顺序是随机的,没有特定的顺序。这不是以前基于 Transformer 的方法的一个重要问题,因为 Transformer 在处理序列数据时是顺序不变的:在自注意力机制中,给定位置的每个元素都可以通过注意力权重与序列中的所有其他元素交互。然而,对于选择性状态空间模型,即 Mamba,我们认为由于单向建模(即下一个状态依赖于上一个状态的信息(时间中的上下文信息),对应与点云的 patch 可以理解成空间的相关性,下一个空间的信息依赖于上一个空间的信息),很难对非结构化点云进行建模。因此,PointMamba 利用空间填充曲线将非结构化点云转换为常规序列。因此文中采用下述方法重组点云序列。
空间填充曲线:
空间填充曲线是遍历高维离散空间中每个点的路径,同时保持一定程度的空间接近。在数学上,它们可以定义为点云的双射函数 Φ : Z → Z3。我们的 PointMamba 专注于希尔伯特空间填充曲线和它的转置变体(称为 Trans-Hilbert),以其有效的局部性保留而闻名。这意味着即使在转换为 Zc 后,Z 空间中彼此接近的数据点也保持接近。
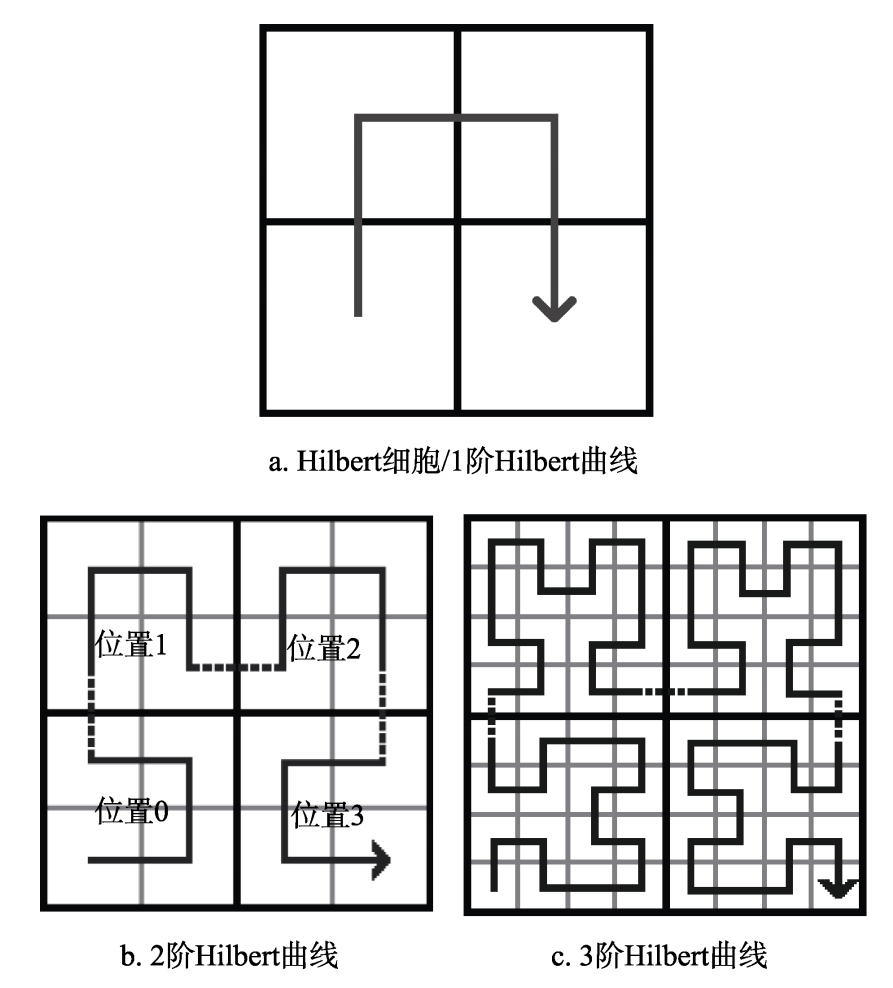
4.3.2. 点标记器
重组顺序完后的特征点先通过 KNN 分组,随后利用轻量级 PointNet 将点映射至特征空间。
4.3.3. 顺序指标
上述过程中通过两种不同的扫描策略生成点标记。虽然它们可能共享相同的中心点,但其顺序和生成方式不同。为了确保在将这两种不同的点标记输入 Mamba 编码器时,能够有效地区分它们的特征和生成策略,提出了一个简单的顺序指示器。
线性变换公式:引入顺序指示器,通过线性变换将每种扫描策略生成的点标记转换到不同的潜在空间中。具体地,公式如下所示:
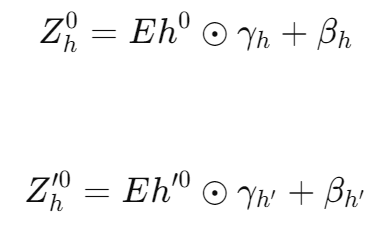
其中,
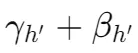
均为缩放和偏移因子,⊙ 表示按元素相乘(element-wise multiplication),最后将两个变换后的特征链接起来。
4.3.4. Manba encoder
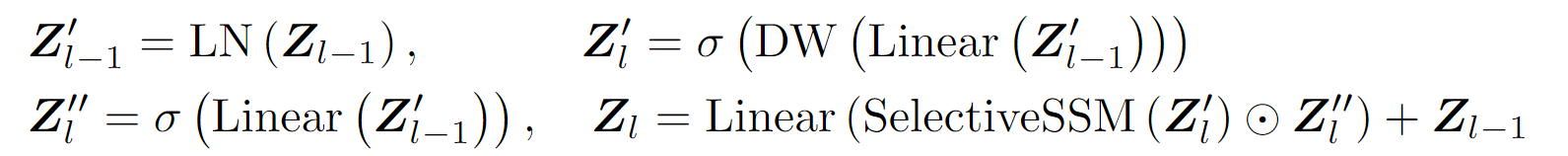
上述为一个 Manba encoder 的全部组件
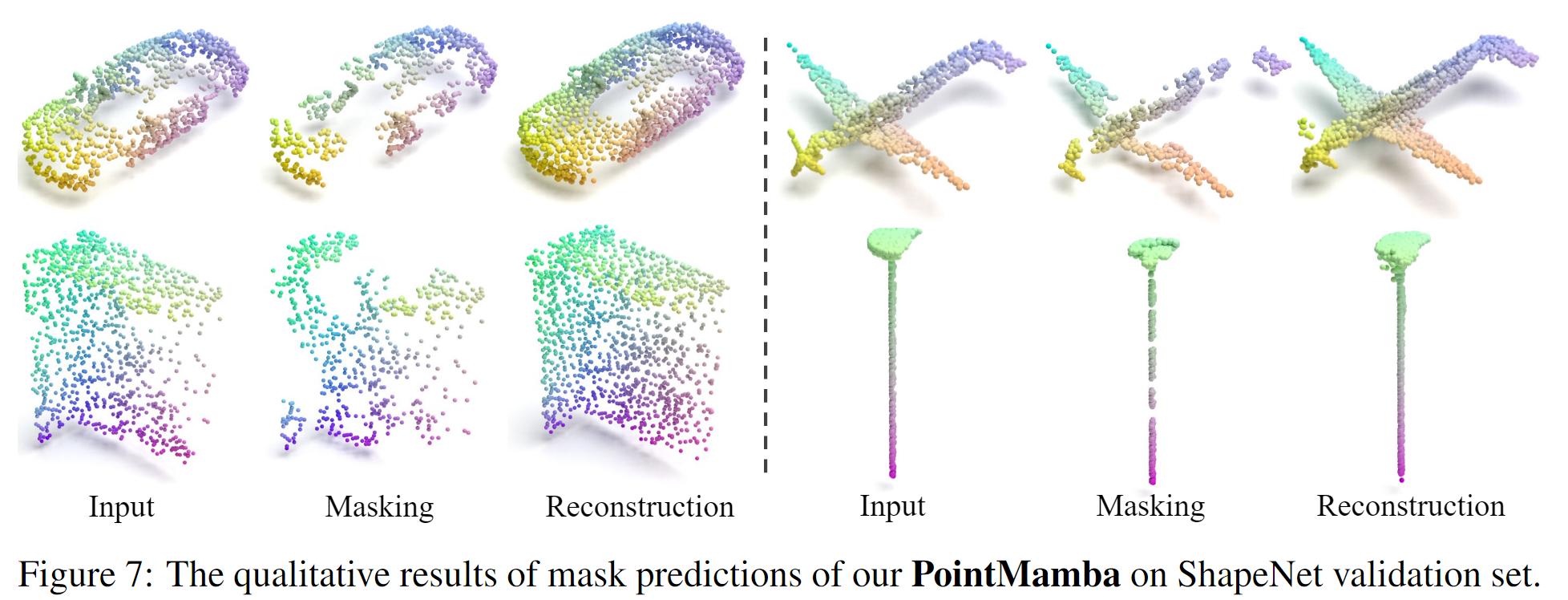
4.4. 预训练 (基于序列化的掩码建模)
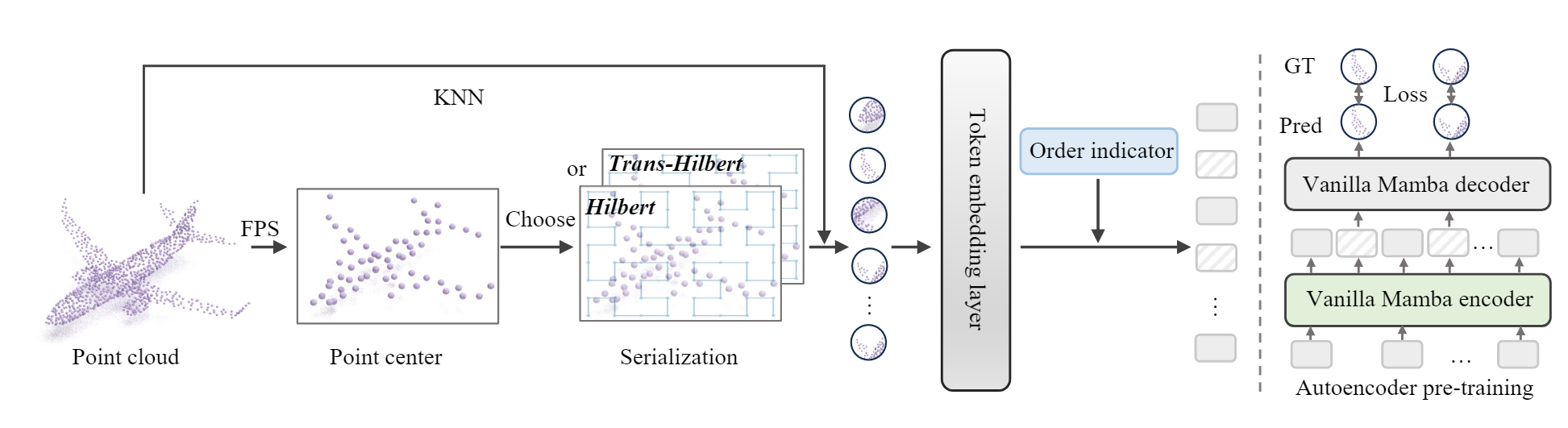
- 假设在点云数据集中有一组点,我们希望使用PointMamba模型进行预训练:
-
- 步骤1:选择第一轮迭代使用希尔伯特曲线序列化,获取 ph。
- 步骤2:对 ph 进行60%的随机遮罩,形成遮罩后的输入点块。
- 步骤3:使用非对称自编码器,利用Mamba块提取特征并通过线性头重构被遮罩的点块。
- 步骤4:通过计算Chamfer距离来评估重构的准确性,作为预训练过程中的损失函数。
5. 💎实验成果展示
GPU NVIDIA A800 80GB
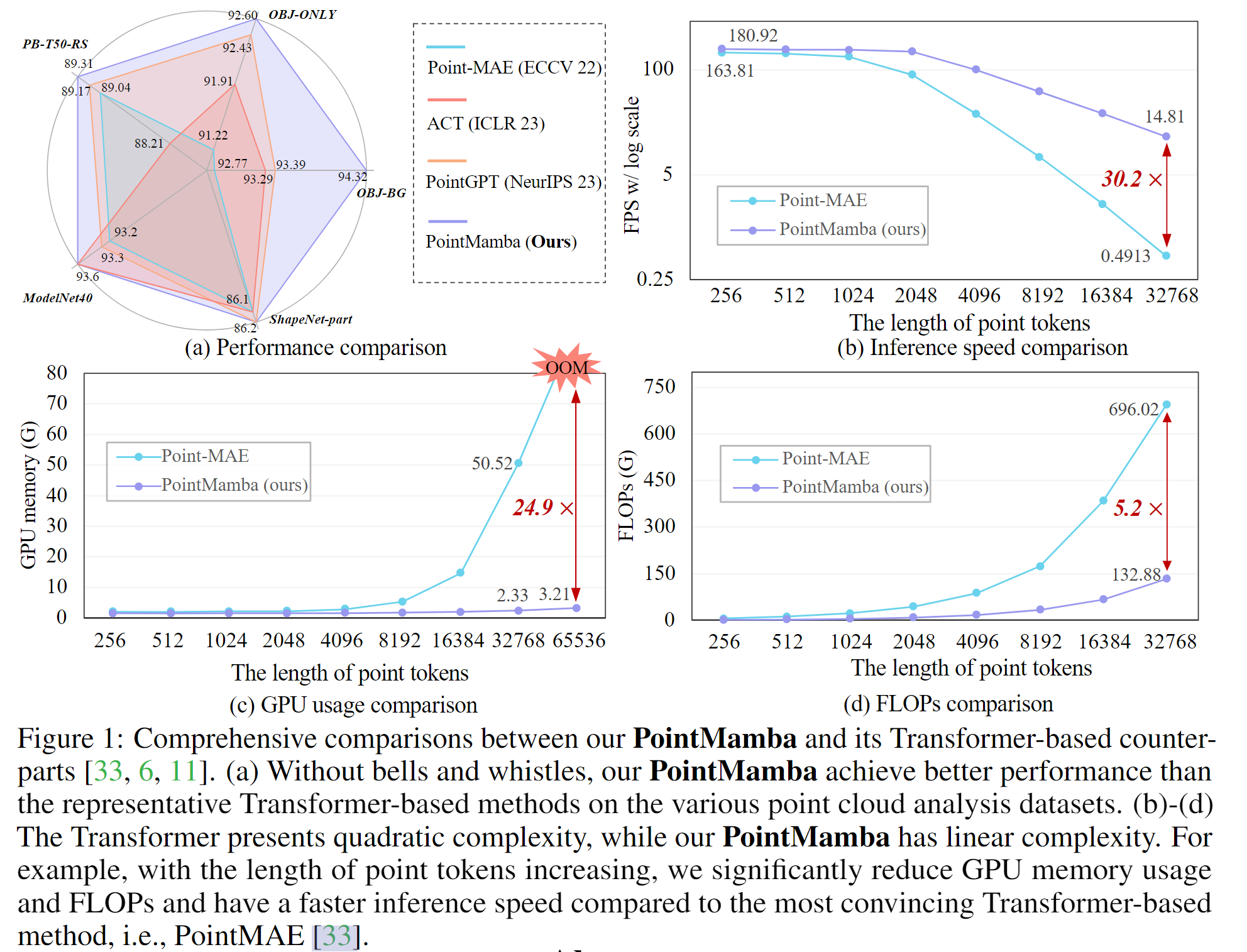
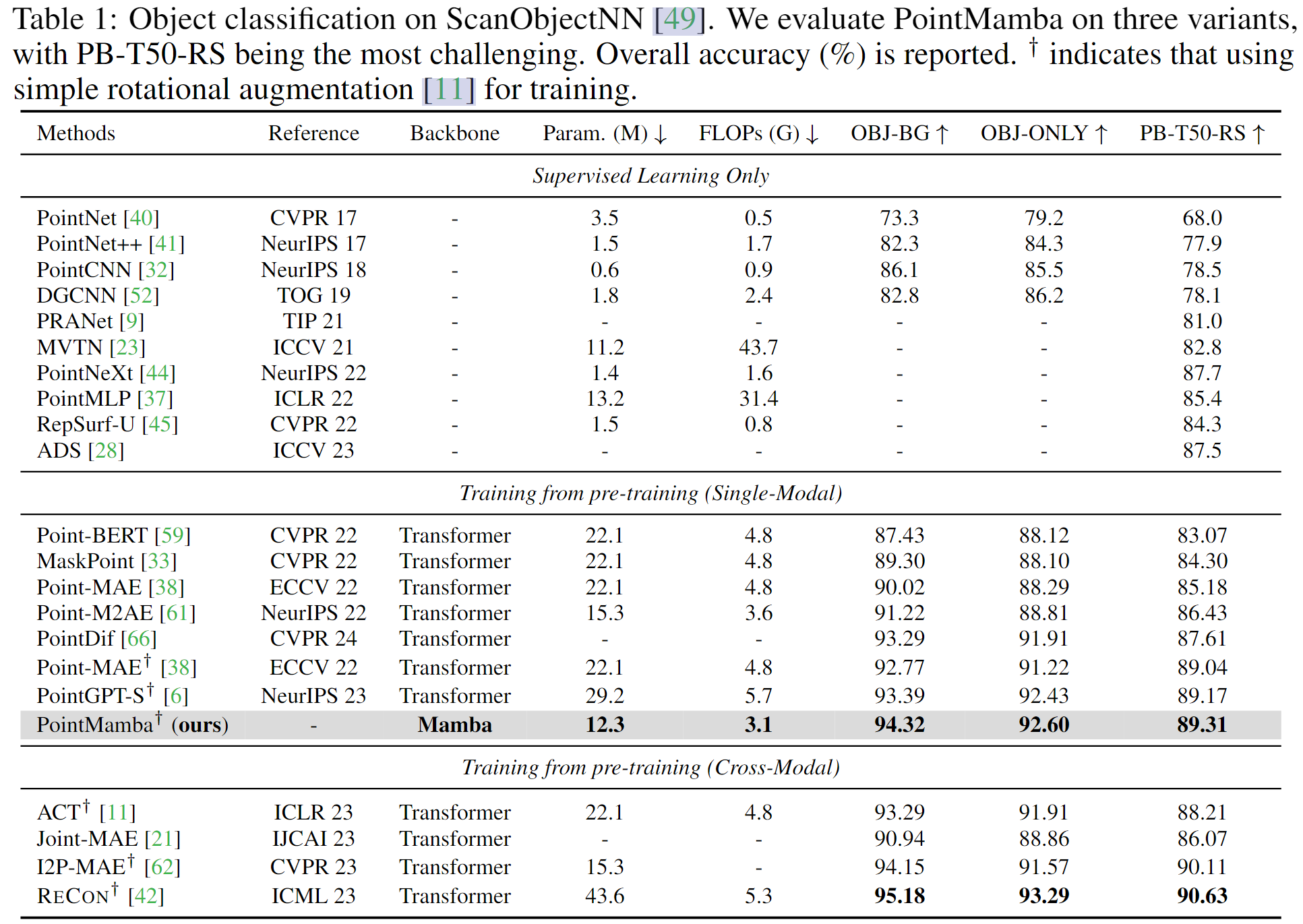
少样本学习:

Shape-Net 分割实验:
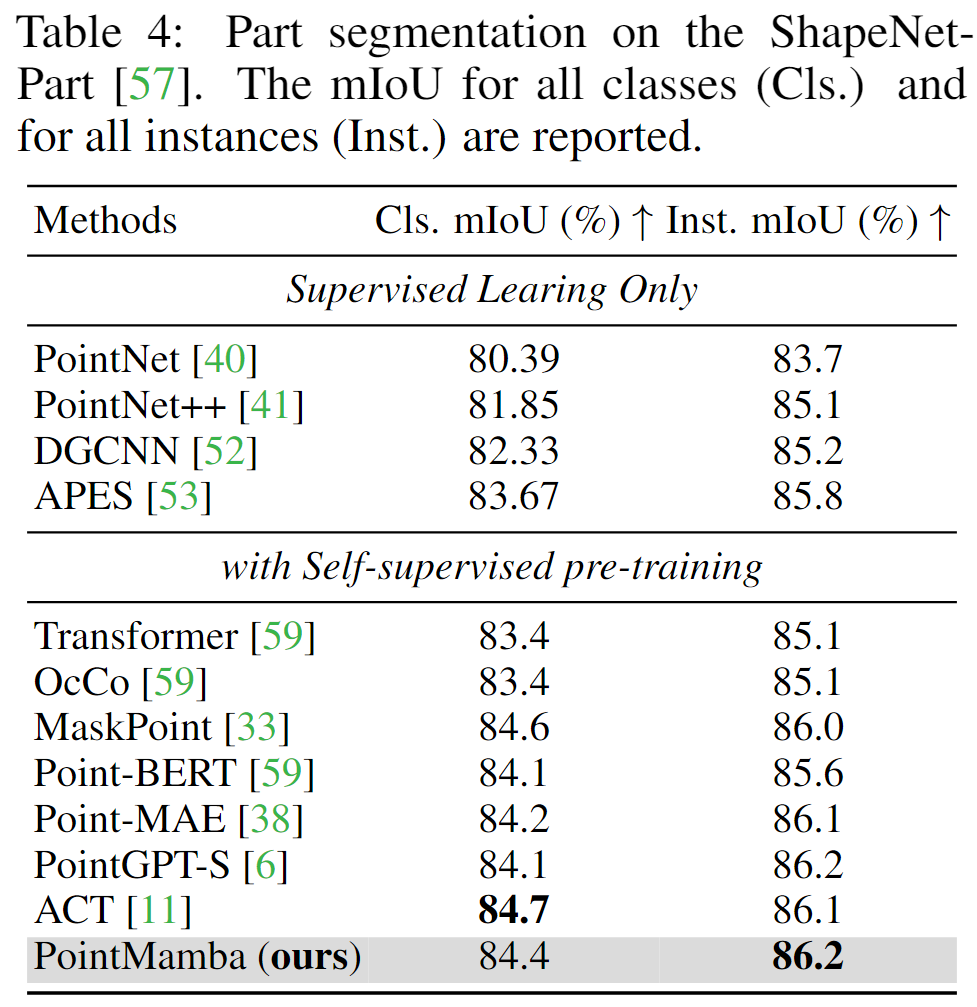
消融实验:
6. 🔍问题分析
采用 SSM 就必须关注于点云的空间序列化,这本身就对于压缩工作有优势,其次 Mamba 的效率高。
7. 源码环境配置:
论文源码:GitHub - LMD0311/PointMamba: PointMamba: A Simple State Space Model for Point Cloud Analysis



![[JS]DOM元素](https://img-blog.csdnimg.cn/img_convert/8a05104df19ec6eaecf99d50e9335e32.png)








![一招教你搞定Windows系统指定IP不变[固定IP地址方法]](https://img-blog.csdnimg.cn/direct/1289853e3bf34aee9f097113bc92b0ec.png)