Android 高级面试-7:网络相关的三方库和网络协议等
1、网络框架
问题:HttpUrlConnection, HttpClient, Volley 和 OkHttp 的区别?
HttpUrlConnection 的基本使用方式如下:
URL url = new URL("http://www.baidu.com"); // 创建 URL
HttpURLConnection connection = (HttpURLConnection) url.openConnection(); // 获取 HttpURLConnection
connection.setRequestMethod("GET"); // 设置请求参数
connection.setConnectTimeout(5 * 1000);
connection.connect();
InputStream inputStream = connection.getInputStream(); // 打开输入流
byte[] data = new byte[1024];
StringBuilder sb = new StringBuilder();
while (inputStream.read(data) != -1) { // 循环读取
String s = new String(data, Charset.forName("utf-8"));
sb.append(s);
}
message = sb.toString();
inputStream.close(); // 关闭流
connection.disconnect(); // 关闭连接
HttpURLConnect 和 HttpClient 的对比:
- 功能方面:HttpClient 库要
丰富很多,提供了很多工具,封装了 http 的请求头,参数,内容体,响应,还有一些高级功能,代理、COOKIE、鉴权、压缩、连接池的处理。HttpClient 高级功能代码写起来比较复杂,对开发人员的要求会高一些,而 HttpURLConnection 对大部分工作进行了包装,屏蔽了不需要的细节,适合开发人员直接调用。另外,HttpURLConnection 在 2.3 版本增加了一些 HTTPS 方面的改进,4.0 版本增加一些响应的缓存。 - 稳定性上:HttpURLConnect 是一个通用的、适合大多数应用的轻量级组件。这个类起步比较晚,很容易在主要 API 上做稳步的改善。但是 HttpURLConnection 在 Android 2.2 及以下版本上
存在一些 bug,尤其是在读取 InputStream 时调用close()方法,可能会导致连接池失效。Android2.3 及以上版本建议选用 HttpURLConnection,2.2 及以下版本建议选用 HttpClient。 - 拓展方面:HttpClient 的 API 数量过多,使得我们很难在不破坏兼容性的情况下对它进行升级和扩展,所以,目前 Android 团队在提升和优化 HttpClient 方面的
工作态度并不积极。
OkHttp 和 Volley 的对比:
- OkHttp:现代、快速、高效的 Http 客户端,支持
HTTP/2 以及 SPDY. Android 4.4 的源码中可以看到 HttpURLConnection 已经替换成 OkHttp 实现了。OkHttp处理了很多网络疑难杂症:会从很多常用的连接问题中自动恢复。OkHttp 还处理了代理服务器问题和 SSL 握手失败问题。 - Volley:适合进行
数据量不大,但通信频繁的网络操作;内部分装了异步线程;支持 Get,Post 网络请求和图片下载;可直接在主线程调用服务端并处理返回结果。缺点是:1).对大文件下载 Volley 的表现非常糟糕;2).只支持 http 请求。Volley 封装了访问网络的一些操作,底层在 Android 2.3 及以上版本,使用的是 HttpURLConnection,而在 Android 2.2 及以下版本,使用的是 HttpClient.
问题:OkHttp 源码?
首先从整体的架构上面看,OkHttp 是基于责任链设计模式设计的,责任链的每一个链叫做一个拦截器。OkHttp 的请求是依次通过重试、桥接、缓存、连接和访问服务器五个责任链,分别用来:1).根据请求的错误码决定是否需要对连接进行重试;2).根据请求信息构建一个 key 用来从 DiskLruCache 中获取缓存,然后根据缓存的响应的信息判断该响应是否可用;3).缓存不可用的时候,使用连接拦截器建立服务器连接;4).最终在最后一个责任链从服务器中拿到请求结果。当从网络当中拿到了数据之后,会回到缓存连接器,然后在这里根据响应的信息和用户的配置决定是否缓存本次请求。除此默认的连接器,我们还可以自定义自己的拦截器。
OkHttp 的网络访问并没有直接使用 HttpUrlConnection 或者 HttpClient,而是直接使用 Socket 建立网络连接,对于流的读写,它使用了第三方的库 okio。在拿到一个请求的时候,OkHttp 首先会到连接池中寻找可以复用的连接。这里的连接池是使用双端队列维护的一个列表。当从连接池中获取到一个连接之后就使用它来进行网络访问。
问题:Volley 实现原理?
RequestQueue queue = Volley.newRequestQueue(this);
// 针对不同的请求类型,Volley 提供了不同的 Request
queue.add(new StringRequest(Request.Method.POST, "URL", new Response.Listener<String>() {
@Override
public void onResponse(String response) {
}
}, new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
}
}));
底层在 Android 2.3 及以上版本,使用的是 HttpURLConnection,而在 Android 2.2 及以下版本,使用的是 HttpClient. 当创建一个 RequestQueue 的时候会同时创建 4 条线程用于从网络中请求数据,一条缓存线程用来从缓存中获取数据。因此不适用于数据量大、通讯频繁的网络操作,因为会占用网络请求的访问线程。
当调用 add() 方法的时候,会先判断是否可以使用缓存,如果可以则将其添加到缓存队列中进行处理。否则将其添加到网络请求队列中,用来从网络中获取数据。在缓存的分发器中,会开启一个无限的循环不断进行工作,它会先从阻塞队列中获取一个请求,然后判断请求是否可用,如果可用的话就将其返回了,否则将请求添加到网络请求队列中进行处理。
网络请求队列与之类似,它也是在 run() 方法中启动一个无限循环,然后使用阻塞队列获取请求,拿到请求之后来从网络中获取响应结果。
问题:网络请求缓存处理,OkHttp 如何处理网络缓存的?
问题:Http 请求头中都有哪些字段是与缓存相关的?
问题:缓存到磁盘上的时候,缓存的键是根据哪些来决定的?
OkHttp 的缓存最终是使用的 DiskLruCache 将请求的请求和响应信息存储到磁盘上。当进入到缓存拦截器的时候,首先会先从缓存当中获取请求的请求信息和响应信息。它会从响应信息的头部获取本次请求的缓存信息,比如过期时间之类的,然后判断该响应是否可用。如果可用,或者处于未连网状态等,则将其返回。否则,再从网络当中获取请求的结果。当拿到了请求的结果之后,还会再次回到缓存拦截器。缓存拦截器在拿到了响应之后,再根据响应和请求的信息决定是否将其持久化到磁盘上面。
http 请求头中用来控制决定缓存是否可用的信息:
Expires:缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点;Cache-Control:相对时间,例如 Cache-Control:3600,代表着资源的有效期是 3600 秒,Cache-Control 与 Expires 可以在服务端配置同时启用或者启用任意一个,同时启用的时候Cache-Control 优先级高。Last-Modify/If-Modify-Since:Last-modify 是一个时间标识该资源的最后修改时间。ETag/If-None-Match:一个校验码,ETag 可以保证每一个资源是唯一的,资源变化都会导致ETag 变化。ETag 值的变更则说明资源状态已经被修改。服务器根据浏览器上发送的 If-None-Match 值来判断是否命中缓存。
客户端第一次请求的时候,服务器会返回上述各种 http 信息,第二次请求的时候会根据下面的流程进行处理:

问题:Retrofit 源码?
Retrofit 的源码的两个核心地方:
- 代理设计模式:JDK 动态代理,核心的地方就是调用
Proxy.newProxyInstance()方法,来获取一个代理对象,但是这个方法要求传入的类的类型必须是接口类型,然后通过传入的InvocationHandler接口对我们定义的 Service 接口的方法进行解析,获取方法的注解等信息,并将其缓存起来。 - 适配器设计模式和策略模式:设配器主要两个地方,也是 Retrofit 为人称道的地方,一个是对结果类型的适配,一个是对服务端返回类型的处理。前面的更像是适配器,后面的更像是策略接口。
- 以 RxJava 为例,当代理类的方法被调用的时候会返回一个 Observable. 然后,当我们对 Observable 进行订阅的时候将会调用
subscribeActual(),在该方法中根据之前解析的接口方法信息,将它们拼接成一个 OkHttp 的请求,然后使用 OkHttp 从网络中获取数据。 - 当拿到了数据之后就是如何将数据转换成我们期望的类型。这里 Retrofit 也将其解耦了出来。Retrofit 提供了
Converter用作 OkHttp 的响应到我们期望类型的转换器。我们可以通过自己定义来实现自己的转换器,并选择自己满意的 Json 等转换框架。
- 以 RxJava 为例,当代理类的方法被调用的时候会返回一个 Observable. 然后,当我们对 Observable 进行订阅的时候将会调用
2、网络基础
2.1 TCP 和 UDP
问题:TCP 与 UDP 区别与应用?
问题:TCP 中 3 次握手和 4 次挥手的过程:
TCP,传输控制协议,面向连接,可靠的,基于字节流的传输层通信协议;
UDP,用户数据报协议,面向无连接,不可靠,基于数据报的传输层协议。
应用场景:
TCP 被用在对不能容忍数据丢失的场景中,比如用来发送 Http;
UDP 用来可以容忍丢失的场景,比如网络视频流的传输。
具体区别:
- TCP 协议是
有连接的,有连接的意思是开始传输实际数据之前 TCP 的客户端和服务器端必须通过三次握手建立连接,会话结束之后也要结束连接。而 UDP 是无连接的。 - TCP 协议保证数据
按序发送,按序到达,提供超时重传来保证可靠性,但是 UDP不保证按序到达,甚至不保证到达,只是努力交付,即便是按序发送的序列,也不保证按序送到。 - TCP 协议
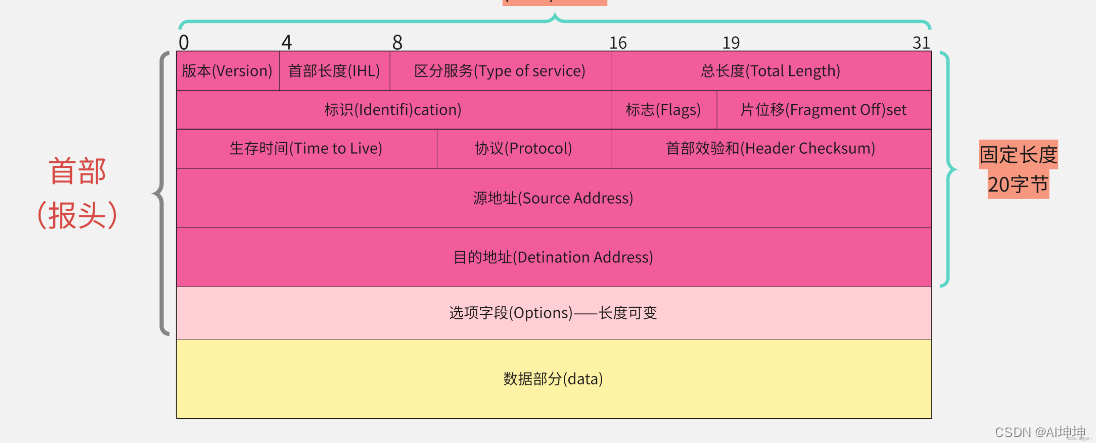
所需资源多,TCP 首部需 20 个字节(不算可选项),UDP 首部字段只需8个字节。 - TCP 有
流量控制和拥塞控制,UDP 没有,网络拥堵不会影响发送端的发送速率。 - TCP 是
一对一的连接,而 UDP 则可以支持一对一、多对多、一对多的通信。 - TCP 面向的是
字节流的服务,UDP 面向的是报文的服务。
TCP 握手过程:

- 客户端通过 TCP 向服务器发送
SYN 报文段。它不包含应用层信息,其中的SYN 标志位为 1,然后选择一个初始序号 (client_isn),并将其放置在报文段的序号字段中。 - 当 SYN 报文段到达服务器之后,服务器为该 TCP 连接分配 TCP 缓存和变量,并向该客户端发送
SYNACK 报文段。它不包含应用层信息,其中个的SYN 置为 1,确认号字段被置为client_isn+1,最后服务器选择自己的初始序号 (server_isn)放在序号字段中。 - 客户端收到 SYNACK 报文段之后,为连接分配缓存和变量,然后向服务器发送另一个报文段,其中将
server_isn+1放在确认字段中,并将SYN 位置为 0.
问题:为什么要三次握手?
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的:
- 第一次握手:Client 什么都不能确认;Server 确认了对方发送正常。
- 第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常。
- 第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送接收正常。

- 客户端向服务器发送关闭连接报文段,其中
FIN置为 1。 - 服务器接收到该报文段之后向发送方会送一个确认字段。
- 服务器向客户端发送自己的终止报文段。
- 客户端对服务器终止报文段进行确认。
问题:为什么要四次挥手?
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。举个例子:A 和 B 打电话,通话即将结束后,A 说“我要挂了”,B 回答 “我知道了”,但是 A 可能还会有要说的话,所以隔一段时间,B 再问 “真的要挂吗”,A 确认之后通话才算结束。
问题:三次握手建立连接时,发送方再次发送确认的必要性?
主要是为了防止已失效的连接请求报文段突然又传到了 B,因而产生错误。假定出现一种异常情况,即 A 发出的第一个连接请求报文段并没有丢失,而是在某些网络结点长时间滞留了,一直延迟到连接释放以后的某个时间才到达 B,本来这是一个早已失效的报文段。但 B 收到此失效的连接请求报文段后,就误认为是 A 又发出一次新的连接请求,于是就向 A 发出确认报文段,同意建立连接。假定不采用三次握手,那么只要 B 发出确认,新的连接就建立了,这样一直等待 A 发来数据,B 的许多资源就这样白白浪费了。
2.2 Http
2.2.1 Http 协议
- 全称
超文本传输协议**`; - HTTP使用
TCP作为它的支撑协议,TCP 默认使用80端口; - 它是
无状态的,就是说它不会记录你之前是否访问过某个对象,它不保存任何关于客户的信息; - 它有两种连接方式,
非持续连接和持续连接。它们的区别在于,非持续连接发送一个请求获取内容之后,对内容里的链接会再分别发送 TCP 请求获取;持续连接当获取到内容之后,复用之前的 TCP获取相关的内容。后者节省了建立连接的时间,效率更高。
2.2.2 HTTP 请求报文
GET /somedir/page.jsp HTTP/1.1 部分 1:请求方法-统一资源标识符(URI)-协议/版本
Accept: text/plain; text/html 部分 2:请求头
Accept-Language: en-gb
Connection: keep-Alive
Host: localhost
User-Agent: Mozilla/4.0
Content-Length: 33
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
lastName=Franks&firstName=Michael 部分 3:实体
- 请求方法共有
GET、POST、HEAD、PUT 和 DELETE等,其中GET大约占 90%;HEAD 类似 GET,但不返回请求对象;PUT 表示上传对象到服务器;DELETE 表示删除服务器上的对象。 URI是相应的URI的后缀,通常被解释为相对于服务器根目录的路径;- 请求头包含客户端和实体正文的相关信息,各个请求头之间使用
“换行/回车”符(CRLF)隔开; - 请求头和实体之间有一个空行,该空行只有 CRLF 符,对 HTTP 格式非常重要。
Host指明对象主机,它在 Web 代理高速缓存中有作用;Connection可取的值有 keep-Alive 和 close,分别对应持续连接和非持续连接;User-Agent指明向服务器发送请求的浏览器。
2.2.3 HTTP 响应报文
HTTP/1.1 200 OK 部分 1:协议-状态码-描述
Server: Microft-IIS/4.0 部分 2:响应头
Date: Mon, 5 Jan 2004 12:11:22 GMT
Content-Type: text/html
Last-Modified: Mon, 5 Jan 2004 11:11:11 GMT
Content-Length: 112
<html>.....</html> 部分 3:响应实体段
- 响应头和响应实体之间使用一个 CRLF 符分隔;
Last-Modified缓存服务器中有作用;- 状态码的五种可能取值:
1xx:指示信息–表示请求已接收,继续处理2xx:成功–表示请求已被成功接收、理解、接受3xx:重定向–要完成请求必须进行更进一步的操作4xx:客户端错误–请求有语法错误或请求无法实现5xx:服务器端错误–服务器未能实现合法的请求
- 常见的状态码:
200OK:请求成功;301Moved Permanelty: 请求对象被永久转移;302重定向只是暂时的重定向,搜索引擎会抓取新的内容而保留旧的地址,搜索搜索引擎认为新的网址是暂时的。而 301 重定向是永久的,搜索引擎在抓取新的内容的同时也将旧的网址替换为了重定向之后的网址。400Bad Request: 请求不被服务器理解;404Not Found: 请求的文档不在服务器;503Service Unavailable:服务器出错的一种返回状态;505HTTP Version Not Supperted: 服务器不支持的HTTP协议。
2.2.4 HTTP 1.0 与 2.0 的区别
- HTTP/2 采用
二进制格式而非文本格式; - HTTP/2 是完全
多路复用的,而非有序并阻塞的——只需一个连接即可实现并行(多路复用允许单一的 HTTP/2 连接同时发起多重的请求-响应消息); - 使用
报头压缩,HTTP/2 降低了开销(不使用原来的头部的字符串,比如 UserAgent 等,而是从字典中获取,这需要在支持 HTTP/2 的浏览器和服务端之间运行); - HTTP/2 让服务器可以将响应主动
推送到客户端缓存中(说白了,就是 HTTP2.0 中,浏览器在请求 HTML 页面的时候,服务端会推送 css、js 等其他资源给浏览器,减少网络空闲浪费)。
2.2.5 Http 长连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 HTTP 会话。
从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的 HTTP 协议,会在响应头加入这行代码 Connection:keep-alive。在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive 不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如 Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
长连接可以省去较多的 TCP 建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测 TCP 连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。在长连接的应用场景下,client 端一般不会主动关闭它们之间的连接,Client 与 server 之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server 早晚有扛不住的时候,这时候 server 端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致 server 端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个客户端连累后端服务。
2.3 Https
问题:Https 请求慢的解决办法?DNS,携带数据,直接访问 IP
问题:Http 与 Https 的区别以及如何实现安全性?
问题:Https 原理?
问题:Https 相关,如何验证证书的合法性,Https 中哪里用了对称加密,哪里用了非对称加密,对加密算法(如 RSA)等是否有了解?
2.3.1 Https 连接的过程

SSL 协议的握手过程共分成 5 各步骤,
- 第一步,客户端给出
协议版本号、一个客户端生成的随机数,以及客户端支持的加密方法; - 第二步,服务器确认双方使用的
加密方法,并给出数字证书、以及一个服务器生成的随机数; - 第三步,客户端确认
数字证书有效,然后生成一个新的随机数,并使用数字证书中的公钥加密这个随机数,发给服务器。 - 第四步,服务器使用自己的
私钥,获取客户端发来的随机数。 - 第五步,客户端和服务器根据约定的
加密方法,使用前面的三个随机数,生成对话密钥来加密接下来的整个对话过程。
握手阶段有三点需要注意。
- 生成对话密钥一共需要
三个随机数,然后使用这三个随机数来最终确定通话使用的算法; - 握手之后的对话使用对话密钥,服务器的公钥和私钥只用于加密和解密对话密钥,无其他作用;(握手之后开启的正式对话使用的是
对称加密,即双方都能通过密钥进行解密;握手的过程中,协商最终使用哪种加密算法通话的时候是非对称加密,即私钥加密后的密文,只要是公钥,都可以解密,但是公钥加密后的密文,只有私钥可以解密。这样,服务端发送给客户端的消息不安全,但是客户端回复给服务端的消息是安全的。因为最后还要发送一个随机数用来确定最终的算法,所以这个过程安全就保证了最终的通话密钥是安全的。) - 服务器公钥放在服务器的数字证书之中。
然而直接使用非对称加密的过程本身也不安全,会有中间人篡改公钥的可能性,所以客户端与服务器不直接使用公钥,而是使用数字证书签发机构颁发的证书来保证非对称加密过程本身的安全。第三方使用自己的私钥对公钥进行加密,生成一个证书。然后客户端从该证书中读取出服务器的公钥。那么证书的合法性如何确认呢?我们可以使用浏览器或操作系统中维护的权威的第三方颁发机构的公钥,验证证书的编号是否正确。然后再使用第三方结构的公钥解密出我们服务器的公钥即可。
2.3.2 HTTPS 与 HTTP 的一些区别
- HTTPS 协议需要到 CA 申请证书,一般免费证书很少,需要
交费。 - HTTP 协议运行在
TCP之上,所有传输的内容都是明文,HTTPS 运行在SSL/TLS之上,所有传输的内容都经过加密的。 - HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是
80,后者是443。 - HTTPS 可以有效的
防止运营商劫持,解决了防劫持的一个大问题。
2.4 其他网络相关
问题:描述一次网络请求的流程?

浏览器输入域名之后,首先通过 DNS 查找该域名对应的 IP 地址。查找的过程会使用多级的缓存,包括浏览器、路由器和 DNS 的缓存。查找的 IP 地址之后,客户端向 web 服务器发送一个 HTTP 连接请求。服务器收到客户端的请求之后处理请求,并返回处理结果。客户端收到服务端返回的结果后将视图呈现给用户。
问题:WebSocket 相关以及与 Socket 的区别
问题:谈谈你对 WebSocket 的理解
问题:WebSocket 与 socket 的区别
WebSocket 是 HTML5 提供的一种在单个 TCP 连接上进行全双工通讯的协议,允许服务端主动向客户端推送数据。浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。WebSocket 的请求和响应报文的结构与 Http 相似。相比于 ajax 这种通过不断轮询的方式来从服务端获取请求的方式,它通过类似于推送的方式通知客户端,可以节省更多的网络资源。
跟 Socket 的区别:Socket 其实并非一个协议,是应用层与 TCP/IP 协议族通信的中间软件抽象层,它是一组接口。当两台主机通信时,让 Socket 去组织数据,以符合指定的协议。TCP 连接则更依靠于底层的 IP 协议,IP 协议的连接则依赖于链路层等更低层次。WebSocket 则是一个典型的应用层协议。总的来说:Socket 是传输控制层协议,WebSocket 是应用层协议。
参考:
- 《Volley使用及其原理解析》
- 《也许,这样理解HTTPS更容易》
另外
有什么技术问题欢迎加我交流 qilebeaf
本人10多年大厂软件开发经验,精通Android,Java,Python,前端等开发,空余时间承接软件开发设计、课程设计指导、解决疑难bug、AI大模型搭建,AI绘图应用等。
欢迎砸单# Android 高级面试-6:性能优化
1、内存优化
1.1 OOM
问题:OOM 的几种常见情形?
数据太大:比如加载图片太大,原始的图片没有经过采样,完全加载到内存中导致内存爆掉。内存泄漏内存抖动:内存抖动是指内存频繁地分配和回收,而频繁的 GC会导致卡顿,严重时还会导致 OOM。一个很经典的案例是 String 拼接时创建大量小的对象。此时由于大量小对象频繁创建,导致内存不连续,无法分配大块内存,系统直接就返回 OOM 了。
问题:OOM 是否可以 Try Catch ?
Catch 是可以 Catch 到的,但是这样不符合规范,Error 说明程序中发生了错误,我们应该使用引用四种引用、增加内存或者减少内存占用来解决这个问题。
1.2 内存泄漏
问题:常见的内存泄漏的情形,以及内存泄漏应该如何分析?
单例引用了 Activity 的 Context,可以使用Context.getApplicationContext()获取整个应用的 Context 来使用;静态变量持有 Activity 的引用,原因和上面的情况一样,比如为了避免反复创建一个内部实例的时候使用静态的变量;非静态内部类导致内存泄露,典型的有:- Handler:Handler 默认持有外部 Activity 的引用,发送给它的 Message 持有 Handler 的引用,Message 会被放入 MQ 中,因此可能会造成泄漏。解决方式是使用弱引用来持有外部 Activity 的引用。另一种方式是在 Activity 的
onDestroy()方法中调用mHandler.removeCallbacksAndMessages(null)从 MQ 中移除消息。 后者更好一些!因为它移除了 Message. - 另一种情形是使用非静态的 Thread 或者 AsyncTask,因为它们持有 Activity 的引用,解决方式是使用
静态内部类+弱引用。
- Handler:Handler 默认持有外部 Activity 的引用,发送给它的 Message 持有 Handler 的引用,Message 会被放入 MQ 中,因此可能会造成泄漏。解决方式是使用弱引用来持有外部 Activity 的引用。另一种方式是在 Activity 的
广播:未取消注册广播。在 Activity 中注册广播,如果在 Activity 销毁后不取消注册,那么这个刚播会一直存在系统中,同上面所说的非静态内部类一样持有 Activity 引用,导致内存泄露。资源:未关闭或释放导致内存泄露。使用 IO、File 流或者 Sqlite、Cursor 等资源时要及时关闭。这些资源在进行读写操作时通常都使用了缓冲,如果及时不关闭,这些缓冲对象就会一直被占用而得不到释放,以致发生内存泄露。属性动画:在 Activity 中启动了属性动画(ObjectAnimator),但是在销毁的时候,没有调用 cancle 方法,虽然我们看不到动画了,但是这个动画依然会不断地播放下去,动画引用所在的控件,所在的控件引用 Activity,这就造成 Activity 无法正常释放。因此同样要在 Activity 销毁的时候 cancel 掉属性动画,避免发生内存泄漏。WebView:WebView 在加载网页后会长期占用内存而不能被释放,因此我们在 Activity 销毁后要调用它的 destory() 方法来销毁它以释放内存。
1.3 内存优化相关的工具
检查内存泄漏:Square 公司开源的用于检测内存泄漏的库,LeakCanary.Memory Monitor:AS 自带的工具,可以用来主动触发 GC,获取堆内存快照文件以便进一步进行分析(通过叫做 Allocation Tracker 的工具获取快照)。(属于开发阶段使用的工具,开发时应该多使用它来检查内存占用。)Device Monitor:包含多种分析工具:线程,堆,网络,文件等(位于 sdk 下面的 tools 文件夹中)。可以通过这里的 Heap 选项卡的 Cause GC 按钮主动触发 GC,通过内存回收的状态判断是否发生了内存泄漏。MAT:首先通过 DDMS 的 Devices 选项卡下面的 Dump HPROF File 生成 hrpof 文件,然后用 SDK 的 hprof-conv 将该文件转成标准 hprof 文件,导入 MAT 中进行分析。
3、ANR
问题:ANR 的原因
问题:ANR 怎么分析解决
满足下面的一种情况系统就会弹出 ANR 提示
输入事件 (按键和触摸事件) 5s内没被处理;- BroadcastReceiver 的事件 ( onRecieve() 方法) 在规定时间内没处理完 (
前台广播为 10s,后台广播为 60s); - Service
前台 20s 后台 200s未完成启动; - ContentProvider 的
publish() 在 10s内没进行完。
最终弹出 ANR 对话框的位置是与 AMS 同目录的类 AppErrors 的 handleShowAnrUi() 方法。最初抛出 ANR 是在 InputDispatcher.cpp 中。后回在上述方法调用 AMS 的 inputDispatchingTimedOut() 方法继续处理,并最终在 inputDispatchingTimedOut() 方法中将事件传递给 AppErrors。
解决方式:
- 使用 adb 导出 ANR 日志并进行分析,发生 ANR的时候系统会记录 ANR 的信息并将其存储到 /data/anr/traces.txt 文件中(在比较新的系统中会被存储都 /data/anr/anr_* 文件中)。或者在开发者模式中选择将日志导出到 sdcard 之后再从 sdcard 将日志发送到电脑端进行查看
- 使用 DDMS 的
traceview进行分析:到 SDK 安装目录的 tools 目录下面使用 monitor.bat 打开 DDMS。使用 TraceView 来通过耗时方法调用的信息定位耗时操作的位置。 - 使用开源项目
ANR-WatchDog来检測 ANR:创建一个检测线程,该线程不断往 UI 线程 post 一个任务,然后睡眠固定时间,等该线程又一次起来后检測之前 post 的任务是否运行了,假设任务未被运行,则生成 ANRError,并终止进程。
常见的 ANR 场景:
I/O 阻塞网络阻塞多线程死锁由于响应式编程等导致的方法死循环由于某个业务逻辑执行的时间太长
避免 ANR 的方法:
- UI 线程尽量只做跟 UI 相关的工作;
- 耗时的工作 (比如数据库操作,I/O,网络操作等),采用
单独的工作线程处理; - 用
Handler来处理 UI 线程和工作线程的交互; - 使用
RxJava等来处理异步消息。
4、性能调优工具
5、优化经验
5.1 优化经验
虽然一直强调优化,但是许多优化应该是在开发阶段就完成的,程序逻辑的设计可能会影响程序的性能。如果开发完毕之后再去考虑对程序的逻辑进行优化,那么阻力会比较大。因此,编程的时候应该养成好的编码习惯,同时注意收集性能优化的经验,在开发的时候进行避免。
代码质量检查工具:
- 使用
SonarLint来对代码进行静态检查,使代码更加符合规范; - 使用
阿里的 IDEA 插件对 Java 的代码质量进行检查;
在 Android4.4 以上的系统上,对于 Bitmap 的解码,decodeStream() 的效率要高于 decodeFile() 和 decodeResource(), 而且高的不是一点。所以解码 Bitmap 要使用 decodeStream(),同时传给 decodeStream() 的文件流是 BufferedInputStream:
val bis = BufferedInputStream(FileInputStream(filePath))
val bitmap = BitmapFactory.decodeStream(bis,null,ops)
Java 相关的优化:
-
静态优于抽象:如果你并不需要访问一个对系那个中的某些字段,只是想调用它的某些方法来去完成一项通用的功能,那么可以将这个方法设置成静态方法,调用速度提升 15%-20%,同时也不用为了调用这个方法去专门创建对象了,也不用担心调用这个方法后是否会改变对象的状态(静态方法无法访问非静态字段)。 -
多使用系统封装好的 API:系统提供不了的 Api 完成不了我们需要的功能才应该自己去写,因为使用系统的 Api 很多时候比我们自己写的代码要快得多,它们的很多功能都是通过底层的汇编模式执行的。举个例子,实现数组拷贝的功能,使用循环的方式来对数组中的每一个元素一一进行赋值当然可行,但是直接使用系统中提供的System.arraycopy()方法会让执行效率快 9 倍以上。 -
避免在内部调用 Getters/Setters 方法:面向对象中封装的思想是不要把类内部的字段暴露给外部,而是提供特定的方法来允许外部操作相应类的内部字段。但在 Android 中,字段搜寻比方法调用效率高得多,我们直接访问某个字段可能要比通过 getters 方法来去访问这个字段快 3 到 7 倍。但是编写代码还是要按照面向对象思维的,我们应该在能优化的地方进行优化,比如避免在内部调用 getters/setters 方法。 -
使用 static final 修饰常量:因为常量会在 dex 文件的初始化器当中进行初始化。当我们调用 intVal 时可以直接指向 42 的值,而调用 strVal 会用一种相对轻量级的字符串常量方式,而不是字段搜寻的方式。这种优化方式只对基本数据类型以及 String 类型的常量有效,对于其他数据类型的常量无效。 -
合理使用数据结构:比如android.util下面的Pair<F, S>,在希望某个方法返回的数据恰好是两个的时候可以使用。显然,这种返回方式比返回数组或者列表含义清晰得多。延申一下:有时候合理使用数据结构或者使用自定义数据结构,能够起到化腐朽为神奇的作用。 -
多线程:不要开太多线程,如果小任务很多建议使用线程池或者 AsyncTask,建议直接使用 RxJava 来实现多线程,可读性和性能更好。 -
合理选择数据结构:根据具体应用场景选择 LinkedList 和 ArrayList,比如 Adapter 中查找比增删要多,因此建议选择 ArrayList. -
合理设置 buffer:在读一个文件我们一般会设置一个 buffer。即先把文件读到 buffer 中,然后再读取 buffer 的数据。所以: 真正对文件的次数 = 文件大小 / buffer大小 。 所以如果你的 buffer 比较小的话,那么读取文件的次数会非常多。当然在写文件时 buffer 是一样道理的。很多同学会喜欢设置 1KB 的 buffer,比如 byte buffer[] = new byte[1024]。如果要读取的文件有 20KB, 那么根据这个 buffer 的大小,这个文件要被读取 20 次才能读完。 -
ListView 复用,
getView()里尽量复用 conertView,同时因为getView()会频繁调用,要避免频繁地生成对象。 -
谨慎使用多进程,现在很多App都不是单进程,为了保活,或者提高稳定性都会进行一些进程拆分,而实际上即使是空进程也会占用内存(1M左右),对于使用完的进程,服务都要及时进行回收。 -
尽量使用系统资源,系统组件,图片甚至控件的 id.
-
数据相关:序列化数据使用 protobuf 可以比 xml 省 30% 内存,慎用 shareprefercnce,因为对于同一个 sp,会将整个 xml 文件载入内存,有时候为了读一个配置,就会将几百 k 的数据读进内存,数据库字段尽量精简,只读取所需字段。 -
dex优化,代码优化,谨慎使用外部库,有人觉得代码多少于内存没有关系,实际会有那么点关系,现在稍微大一点的项目动辄就是百万行代码以上,多 dex 也是常态,不仅占用 rom 空间,实际上运行的时候需要加载 dex 也是会占用内存的(几 M ),有时候为了使用一些库里的某个功能函数就引入了整个庞大的库,此时可以考虑抽取必要部分,开启 proguard 优化代码,使用 Facebook redex 使用优化 dex (好像有不少坑)。
常用的程序性能测试方法
-
时间测试:方式很简单只要在代码的上面和下面定义一个long型的变量,并赋值给当前的毫秒数即可。比如long sMillis = System.currentTimeMillis(); // ...代码块 long eMillis = System.currentTimeMillis();
然后两者相减即可得到程序的运行时间。
-
内存消耗测试:获取代码块前后的内存,然后相减即可得到这段代码当中的内存消耗。获取当前内存的方式是long total = Runtime.getRuntime().totalMemory(); // 获取系统中内存总数 long free = Runtime.getRuntime().freeMemory(); // 获取剩余的内存总数 long used = total - free; // 使用的内存数
在使用的时候只要在代码块的两端调用 Runtime.getRuntime().freeMemory() 然后再相减即可得到使用的内存总数。
5.2 布局优化
- 在选择使用 Android 中的布局方式的时候应该遵循:尽量少使用性能比较低的容器控件,比如 RelativeLayout,但如果使用 RelativeLayout 可以降低布局的层次的时候可以考虑使用。
- 使用
<include>标签复用布局:多个地方共用的布局可以使用<include>标签在各个布局中复用; - 可以通过使用
<merge>来降低布局的层次。<merge>标签通常与<include>标签一起使用,<merge>作为可以复用的布局的根控件。然后使用<include>标签引用该布局。 - 使用
<ViewStub>标签动态加载布局:<ViewStub>标签可以用来在程序运行的时候决定加载哪个布局,而不是一次性全部加载。 - 性能分析:使用
Android Lint来分析布局; - 性能分析:避免过度绘制,在手机的开发者选项中的绘图选项中选择显示布局边界来查看布局
- 性能分析:
Hierarchy View,可以通过 Hierarchy View 来获取当前的 View 的层次图 - 使用
ConstaintLayout:用来降低布局层次; - 性能分析:使用
systrace分析 UI 性能; - onDraw() 方法会被频繁调用,因此不应该在其中做耗时逻辑和声明对象
5.3 内存优化
-
防止内存泄漏:见内存泄漏; -
使用优化过的集合; -
使用优化过的数据集合:如SparseArray、SparseBooleanArray等来替换 HashMap。因为 HashMap 的键必须是对象,而对象比数值类型需要多占用非常多的空间。 -
少使用枚举:枚举可以合理组织数据结构,但是枚举是对象,比普通的数值类型需要多使用很多空间。 -
当内存紧张时释放内存:onTrimMemory()方法还有很多种其他类型的回调,可以在手机内存降低的时候及时通知我们,我们应该根据回调中传入的级别来去决定如何释放应用程序的资源。 -
读取一个 Bitmap 图片的时候,不要去加载不需要的分辨率。可以压缩图片等操作,使用性能稳定的图片加载框架,比如 Glide.
-
谨慎使用抽象编程:在 Android 使用抽象编程会带来额外的内存开支,因为抽象的编程方法需要编写额外的代码,虽然这些代码根本执行不到,但是也要映射到内存中,不仅占用了更多的内存,在执行效率上也会有所降低。所以需要合理的使用抽象编程。 -
尽量避免使用依赖注入框架:使用依赖注入框架貌似看上去把 findViewById() 这一类的繁琐操作去掉了,但是这些框架为了要搜寻代码中的注解,通常都需要经历较长的初始化过程,并且将一些你用不到的对象也一并加载到内存中。这些用不到的对象会一直站用着内存空间,可能很久之后才会得到释放,所以可能多敲几行代码是更好的选择。 -
使用多个进程:谨慎使用,多数应用程序不该在多个进程中运行的,一旦使用不当,它甚至会增加额外的内存而不是帮我们节省内存。这个技巧比较适用于哪些需要在后台去完成一项独立的任务,和前台是完全可以区分开的场景。比如音乐播放,关闭软件,已经完全由 Service 来控制音乐播放了,系统仍然会将许多 UI 方面的内存进行保留。在这种场景下就非常适合使用两个进程,一个用于 UI 展示,另一个用于在后台持续的播放音乐。关于实现多进程,只需要在 Manifast 文件的应用程序组件声明一个android:process属性就可以了。进程名可以自定义,但是之前要加个冒号,表示该进程是一个当前应用程序的私有进程。 -
分析内存的使用情况:系统不可能将所有的内存都分配给我们的应用程序,每个程序都会有可使用的内存上限,被称为堆大小。不同的手机堆大小不同,如下代码可以获得堆大小int heapSize = AMS.getMemoryClass()结果以 MB 为单位进行返回,我们开发时应用程序的内存不能超过这个限制,否则会出现 OOM。 -
节制的使用 Service:如果应用程序需要使用 Service 来执行后台任务的话,只有当任务正在执行的时候才应该让 Service 运行起来。当启动一个 Service 时,系统会倾向于将这个 Service 所依赖的进程进行保留,系统可以在 LRUcache 当中缓存的进程数量也会减少,导致切换程序的时候耗费更多性能。我们可以使用 IntentService,当后台任务执行结束后会自动停止,避免了 Service 的内存泄漏。 -
字符串优化:Android 性能优化之String篇
5.4 异常崩溃 & 稳定性
问题:如何保持应用的稳定性
问题:App 启动崩溃异常捕捉
- 使用热补丁
- 自己写代码捕获异常
- 使用异常收集工具
- 开发就是测试,自己的逻辑自己先测一边
5.5 优化工具
问题:性能优化如何分析 systrace?
下面将简单介绍几个主流的辅助分析内存优化的工具,分别是
- MAT (Memory Analysis Tools)
- Heap Viewer
- Allocation Tracker
- Android Studio 的 Memory Monitor
- LeakCanary
https://www.jianshu.com/p/0df5ad0d2e6a
MAT (Memory Analysis Tools),作用:查看当前内存占用情况。通过分析 Java 进程的内存快照 HPROF 分析,快速计算出在内存中对象占用的大小,查看哪些对象不能被垃圾收集器回收 & 可通过视图直观地查看可能造成这种结果的对象
- MAT - Memory Analyzer Tool 使用进阶
- MAT使用教程
Heap Viewer,定义:一个的 Java Heap 内存分析工具。作用:查看当前内存快照。可查看分别有哪些类型的数据在堆内存总以及各种类型数据的占比情况。
5.6 启动优化
问题:能优化,怎么保证应用启动不卡顿
问题:统计启动时长,标准
- 方式 1:使用 ADB:获取启动速度的第一种方式是使用 ADB,使用下面的指令的时候在启动应用的时候会使用 AMS 进行统计。但是缺点是统计时间不够准确:
adb shell am start -n {包名}/{包名}.{活动名} - 方式 2:代码埋点:在 Application 的 attachBaseContext() 方法中记录开始时间,第一个 Activity 的 onWindowFocusChanged() 中记录结束时间。缺点是统计不完全,因为在 attachBaseContext() 之前还有许多操作。
- 方式 3:TraceView:在 AS 中打开 DDMS,或者到 SDK 安装目录的 tools 目录下面使用 monitor.bat 打开 DDMS。通过 TraceView 主要可以得到两种数据:单次执行耗时的方法以及执行次数多的方法。但 TraceView 性能耗损太大,不能比较正确反映真实情况。
- 方式 4:Systrace:Systrace 能够追踪关键系统调用的耗时情况,如系统的 IO 操作、内核工作队列、CPU 负载、Surface 渲染、GC 事件以及 Android 各个子系统的运行状况等。但是不支持应用程序代码的耗时分析。
- 方式 5:Systrace + 插桩:类似于 AOP,通过切面为每个函数统计执行时间。这种方式的好处是能够准确统计各个方法的耗时。
TraceMethod.i(); /* do something*/ TraceMethod.o(); - 方式 6:录屏:录屏方式收集到的时间,更接近于用户的真实体感。可以在录屏之后按帧来进行统计分析。
启动优化
延迟初始化:一些逻辑,如果没必要在程序启动的时候就立即初始化,那么可以将其推迟到需要的时候再初始化。比如,我们可以使用单例的方式来获取类的实例,然后在获取实例的时候再进行初始化操作。但是需要注意的是,懒加载要防止集中化,否则容易出现首页显示后用户无法操作的情形。可以按照耗时和是否必要将业务划分到四个维度:必要且耗时,必要不耗时,非必要但耗时,非必要不耗时。然后对应不同的维度来决定是否有必要在程序启动的时候立即初始化。防止主线程阻塞:一般我们也不会把耗时操作放在主线程里面,毕竟现在有了 RxJava 之后,在程序中使用异步代价并不高。这种耗时操作包括,大量的计算、IO、数据库查询和网络访问等。另外,关于开启线程池的问题下面的话总结得比较好,除了一般意义上线程池和使用普通线程的区别,还要考虑应用启动这个时刻的特殊性,特定场景下单个时间点的表现 Thread 会比 ThreadPoolExecutor 好:同样的创建对象,ThreadPoolExecutor 的开销明显比 Thread 大。布局优化:如,之前我在使用 Fragment 和 ViewPager 搭配的时候,发现虽然 Fragment 可以被复用,但是如果通过 Adapter 为 ViewPager 的每个项目指定了标题,那么这些标题控件不会被复用。当 ViewPager 的条目比较多的时候,甚至会造成 ANR.使用启动页面防止白屏:这种方法只是治标不治本的方法,就是在应用启动的时候避免白屏,可以通过设置自定义主题来实现。
其他借鉴办法
- 使用 BlockCanary 检测卡顿:它的原理是对 Looper 中的 loop() 方法打处的日志进行处理,通过一个自定义的日志输出 Printer 监听方法执行的开始和结束。(更加详细的源码分析参考这篇文章:Android UI卡顿监测框架BlockCanary原理分析)
- GC 优化:减少垃圾回收的时间间隔,所以在启动的过程中不要频繁创建对象,特别是大对象,避免进行大量的字符串操作,特别是序列化跟反序列化过程。一些频繁创建的对象,例如网络库和图片库中的 Byte 数组、Buffer 可以复用。如果一些模块实在需要频繁创建对象,可以考虑移到 Native 实现。
- 类重排:如果我们的代码在打包的时候被放进了不同的 dex 里面,当启动的时候,如果需要用到的类分散在各个 dex 里面,那么系统要花额外的时间到各个 dex 里加载类。因此,我们可以通过类重排调整类在 Dex 中的排列顺序,把启动时用到的类放进主 dex 里。目前可以使用 ReDex 的 Interdex 调整类在 Dex 中的排列顺序。
- 资源文件重排:这种方案的原理时先通过测试找出程序启动过程中需要加载的资源,然后再打包的时候通过修改 7z 压缩工具将上述热点资源放在一起。这样,在系统进行资源加载的时候,这些资源将要用到的资源会一起被加载进程内存当中并缓存,减少了 IO 的次数,同时不需要从磁盘读取文件,来提高应用启动的速度。
5.7 网络优化
- Network Monitor: Android Studio 内置的 Monitor工具中就有一个 Network Monitor;
- 抓包工具:Wireshark, Fiddler, Charlesr 等抓包工具,Android 上面的无 root 抓包工具;
- Stetho:Android 应用的调试工具。无需 Root 即可通过 Chrome,在 Chrome Developer Tools 中可视化查看应用布局,网络请求,SQLite,preference 等。
- Gzip 压缩:使用 Gzip 来压缩 request 和 response, 减少传输数据量, 从而减少流量消耗.
- 数据交换格式:JSON 而不是 XML,另外 Protocol Buffer 是 Google 推出的一种数据交换格式.
- 图片的 Size:使用 WebP 图片,修改图片大小;
- 弱网优化
- 界面先反馈, 请求延迟提交例如, 用户点赞操作, 可以直接给出界面的点赞成功的反馈, 使用JobScheduler在网络情况较好的时候打包请求.
- 利用缓存减少网络传输;
- 针对弱网(移动网络), 不自动加载图片
- 比方说 Splash 闪屏广告图片, 我们可以在连接到 Wifi 时下载缓存到本地; 新闻类的 App 可以在充电, Wifi 状态下做离线缓存
- IP 直连与 HttpDns:DNS 解析的失败率占联网失败中很大一种,而且首次域名解析一般需要几百毫秒。针对此,我们可以不用域名,才用 IP 直连省去 DNS 解析过程,节省这部分时间。HttpDNS 基于 Http 协议的域名解析,替代了基于 DNS 协议向运营商 Local DNS 发起解析请求的传统方式,可以避免 Local DNS 造成的域名劫持和跨网访问问题,解决域名解析异常带来的困扰。
- 请求频率优化:可以通过把网络数据保存在本地来实现这个需求,缓存数据,并且把发出的请求添加到队列中,当网络恢复的时候再及时发出。
- 缓存:App 应该缓存从网络上获取的内容,在发起持续的请求之前,app 应该先显示本地的缓存数据。这确保了 app 不管设备有没有网络连接或者是很慢或者是不可靠的网络,都能够为用户提供服务。
5.8 电量优化
5.9 RV 优化
- 数据处理和视图加载分离:从远端拉取数据肯定是要放在异步的,在我们拉取下来数据之后可能就匆匆把数据丢给了 VH 处理,其实,数据的处理逻辑我们也应该放在异步处理,这样 Adapter 在 notify change 后,ViewHolder 就可以简单无压力地做数据与视图的绑定逻辑。比如:
mTextView.setText(Html.fromHtml(data).toString());这里的 Html.fromHtml(data) 方法可能就是比较耗时的,存在多个 TextView 的话耗时会更为严重,而如果把这一步与网络异步线程放在一起,站在用户角度,最多就是网络刷新时间稍长一点。 - 数据优化:页拉取远端数据,对拉取下来的远端数据进行缓存,提升二次加载速度;对于新增或者删除数据通过 DiffUtil 来进行局部刷新数据,而不是一味地全局刷新数据。
- 减少过渡绘制:减少布局层级,可以考虑使用自定义 View 来减少层级,或者更合理地设置布局来减少层级,不推荐在 RecyclerView 中使用 ConstraintLayout,有很多开发者已经反映了使用它效果更差。
- 减少 xml 文件 inflate 时间:xml 文件 inflate 出 ItemView 是通过耗时的 IO 操作,尤其当 Item 的复用几率很低的情况下,随着 Type 的增多,这种 inflate 带来的损耗是相当大的,此时我们可以用代码去生成布局,即 new View() 的方式。
- 如果 Item 高度是固定的话,可以使用 RecyclerView.setHasFixedSize(true); 来避免 requestLayout 浪费资源;
- 如果不要求动画,可以通过
((SimpleItemAnimator) rv.getItemAnimator()).setSupportsChangeAnimations(false);把默认动画关闭来提升效率。 - 对 TextView 使用 String.toUpperCase 来替代
android:textAllCaps="true"; - 通过重写 RecyclerView.onViewRecycled(holder) 来回收资源。
- 通过 RecycleView.setItemViewCacheSize(size); 来加大 RecyclerView 的缓存,用空间换时间来提高滚动的流畅性。
- 如果多个 RecycledView 的 Adapter 是一样的,比如嵌套的 RecyclerView 中存在一样的 Adapter,可以通过设置 RecyclerView.setRecycledViewPool(pool); 来共用一个 RecycledViewPool。
- 对 ItemView 设置监听器,不要对每个 Item 都调用 addXxListener,应该大家公用一个 XxListener,根据 ID 来进行不同的操作,优化了对象的频繁创建带来的资源消耗。
6.0 APK 优化
- 开启混淆:哪些配置?
- 资源混淆:AndRes
- 只支持 armeabi-v7 架构的 so 库
- 手动 Lint 检查,手动删除无用资源:删除没有必要的资源文件
- 使用 Tnypng 等图片压缩工具对图片进行压缩
- 大部分图片使用 Webp 格式代替:可以给UI提要求,让他们将图片资源设置为 Webp 格式,这样的话图片资源会小很多。如果对图片颜色通道要求不高,可以考虑转 jpg,最好用 webp,因为效果更佳。
- 尽量不要在项目中使用帧动画
- 使用 gradle 开启
shrinkResources ture:但有一个问题,就是图片 id 没有被引用的时候会被变成一个像素,所以需要在项目代码中引用所有表情图片的 id。 - 减小 dex 的大小:
- 尽量减少第三方库的引用
- 避免使用枚举
- 避免重复功能的第三方库
- 其他
- 用 7zip 代替压缩资源。
- 删除翻译资源,只保留中英文
- 尝试将
andorid support库彻底踢出你的项目。 - 尝试使用动态加载 so 库文件,插件化开发。
- 将大资源文件放到服务端,启动后自动下载使用。
6、相机优化
参考相机优化相关的内容。
Bitmap 优化
https://blog.csdn.net/carson_ho/article/details/79549382
-
使用完毕后 释放图片资源,优化方案:
- 在 Android2.3.3(API 10)前,调用 Bitmap.recycle()方法
- 在 Android2.3.3(API 10)后,采用软引用(SoftReference)
-
根据分辨率适配 & 缩放图片
-
按需 选择合适的解码方式
-
设置 图片缓存
另外
有什么技术问题欢迎加我交流 qilebeaf
本人10多年大厂软件开发经验,精通Android,Java,Python,前端等开发,空余时间承接软件开发设计、课程设计指导、解决疑难bug、AI大模型搭建,AI绘图应用等。
欢迎砸单
![一招教你搞定Windows系统指定IP不变[固定IP地址方法]](https://img-blog.csdnimg.cn/direct/1289853e3bf34aee9f097113bc92b0ec.png)



![[渗透测试] 任意文件读取漏洞](https://img-blog.csdnimg.cn/direct/440dc721b9004c80b6b3d3fade0ce0ad.png#pic_center)