集群配置
| 项目 | 描述 |
|---|---|
| 数量 | 3台 |
| 规格 | 阿里云ECS 16C64G |
| Slot模式 | 静态50个 |
| ST内存配置 | -Xms32g -Xmx32g -XX:MaxMetaspaceSize=8g |
异常问题
4月份以来,出现了3次集群脑裂现象,均为某节点脑裂/自动关闭。
核心日志如下:
Master节点
出现Hazelcast监控线程打印的Slow Operation日志
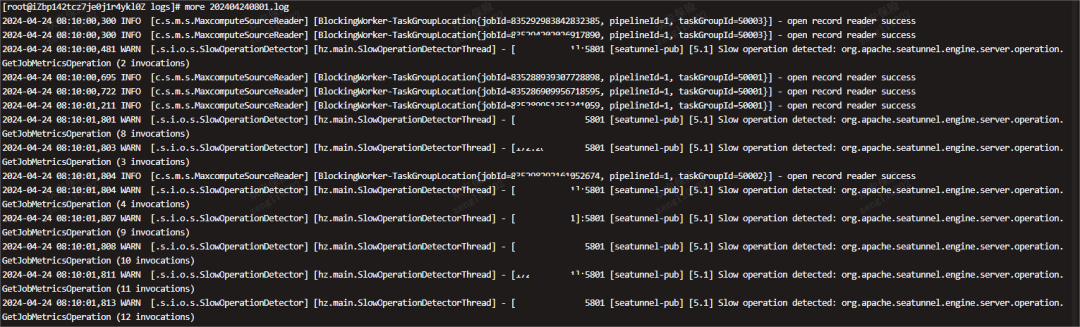
Hazelcast 心跳超时60s后,会看见198已经离开了集群
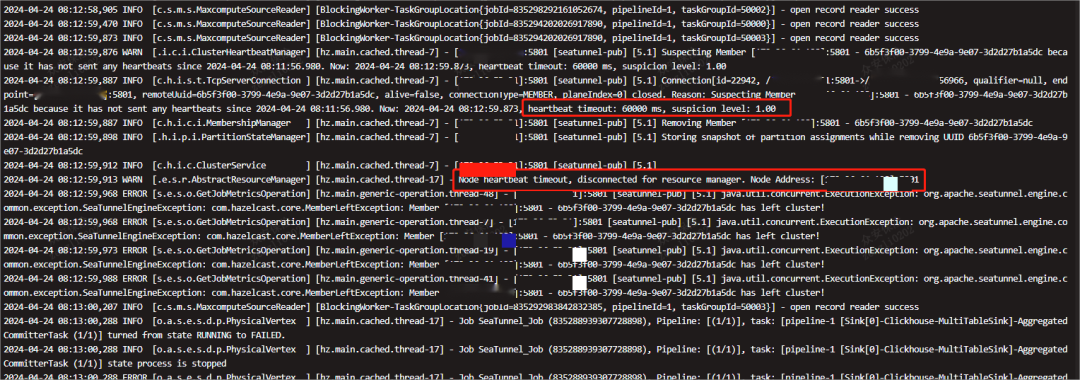
198 worker节点
我们可以看到,已经无法获得Hazelcast集群节点的心跳,且超时超过60000ms
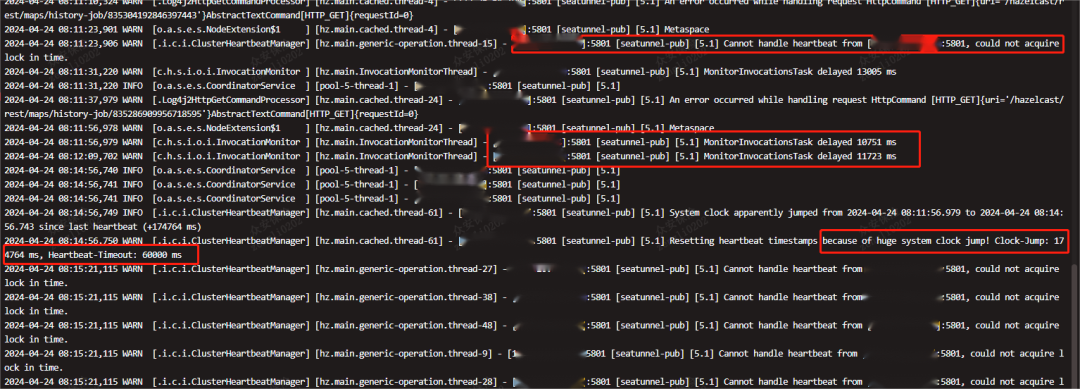
尝试重连到集群
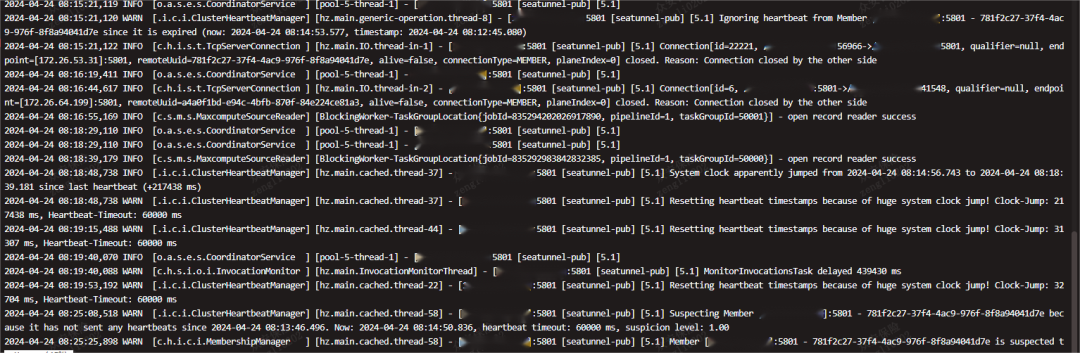
然后打到该节点上的状态查询、提交作业等请求,卡死无状态;
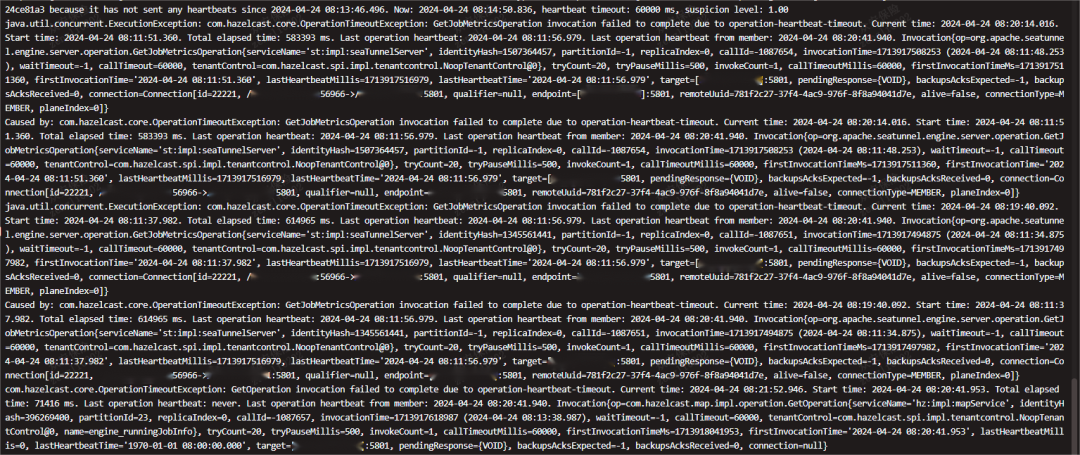
这时整个集群不可用,处于僵死状态,我们写的节点健康检查接口,均不可用, 早高峰时间出现了服务不可用,于是我们观察日志出现集群脑裂后,快速重启了集群。

后期调参后,甚至还出现过调参后节点自动关闭的问题


问题分析
可能出现Hazelcast集群脑裂组网失败的问题,有以下几个:
集群所在的ECS系统NTP不一致;
集群所在的ECS出现了网络抖动问题,访问不可用;
ST出现FULL GC导致JVM卡顿,导致组网失败;
前两个问题,我们通过运维同学,明确网络无问题,阿里云NTP服务正常三个服务器时间无间隔;
第三个问题,我们再198节点出现异常前最后一次hazelcast健康检查日志发现,cluster time的时间点为-100毫秒,看起来影响不大。

于是我们在后续启动时,添加了jvm gc日志参数,用以观察full gc的时间,我们观察过最多有观察到27s, 三个节点相互Ping监控,极易出现hazelcast 60s的心跳超时时间。
同时我们也发现,某个14亿CK表同步时,运行一定时间后,就容易FullGc异常问题。
问题解决方案
增加ST集群心跳时间
hazelcast集群故障检查器负责确定集群中的成员是否无法访问或崩溃。
但根据著名的FLP结果,在异步系统中不可能区分崩溃的成员和缓慢的成员。解决此限制的方法是使用不可靠的故障检测器。不可靠的故障检测器允许成员怀疑其他人已经失败,通常基于活性标准,但它可能会在一定程度上犯错误。
Hazelcast 具有以下内置故障检测器:Deadline Failure Detector 和 Phi Accrual Failure Detector。
默认情况下,Hazelcast 使用Deadline Failure Detector进行故障检测。
还有一个 Ping 故障检测器,如果启用,它会与上述检测器并行工作,但会识别 OSI 第 3 层(网络层)上的故障。该检测器默认处于禁用状态。
Deadline Failure Detector
对丢失/丢失的心跳使用绝对超时。超时后,成员将被视为崩溃/不可用并标记为可疑
相关参数及说明
hazelcast:
properties:
hazelcast.heartbeat.failuredetector.type: deadline
hazelcast.heartbeat.interval.seconds: 5
hazelcast.max.no.heartbeat.seconds: 120| 配置项 | 描述 |
|---|---|
hazelcast.heartbeat.failuredetector.type | 集群故障检查器模式:deadline. |
hazelcast.heartbeat.interval.seconds | 成员之间互相发送心跳消息的时间间隔。 |
hazelcast.max.no.heartbeat.seconds | 定义集群成员因未发送任何心跳而受到怀疑的超时时间。 |
Phi-accrual 计故障检测器
跟踪滑动时间窗口中心跳之间的间隔,测量这些样本的平均值和方差,并计算怀疑级别 (Phi) 值。
当自上次心跳以来的时间间隔变长时,phi 的值会增加。如果网络变得缓慢或不可靠,导致均值和方差增加,则怀疑该成员之前需要更长的时间没有收到心跳。
相关参数及说明
hazelcast:
properties:
hazelcast.heartbeat.failuredetector.type: phi-accrual
hazelcast.heartbeat.interval.seconds: 1
hazelcast.max.no.heartbeat.seconds: 60
hazelcast.heartbeat.phiaccrual.failuredetector.threshold: 10
hazelcast.heartbeat.phiaccrual.failuredetector.sample.size: 200
hazelcast.heartbeat.phiaccrual.failuredetector.min.std.dev.millis: 100| 配置项 | 描述 |
|---|---|
hazelcast.heartbeat.failuredetector.type | 集群故障检查器模式:phi-accrual |
hazelcast.heartbeat.interval.seconds | 成员之间互相发送心跳消息的时间间隔 |
hazelcast.max.no.heartbeat.seconds | 定义集群成员因未发送任何心跳而受到怀疑的超时时间。由于故障检测器可适应网络条件,您可以定义低于截止时间故障检测器 hazelcast.max.no.heartbeat.seconds 中定义的超时时间 |
hazelcast.heartbeat.phiaccrual.failuredetector.threshold | 成员被视为无法访问并标记为可疑的 phi 阈值。计算出的 phi 超过此阈值后,成员将被视为无法访问并标记为可疑。较低的阈值允许您检测成员中的任何崩溃或故障,但可能会生成更多故障并导致错误的成员被标记为可疑。较高的阈值产生的故障较少,但检测实际崩溃/故障的速度较慢。例如,phi = 1 的情况下故障识别的错误率约为 10%,phi = 2 则约为 1%,phi = 3 约为 0.1%。默认情况下,phi 阈值设置为 10 |
hazelcast.heartbeat.phiaccrual.failuredetector.sample.size | 为历史保留的样本数量。默认情况下,此项设置为 200 |
hazelcast.heartbeat.phiaccrual.failuredetector.min.std.dev.millis | 正态分布中 phi 计算的最小标准差 |
配置参考文档:
- https://docs.hazelcast.com/hazelcast/5.1/system-properties
- https://docs.hazelcast.com/hazelcast/5.1/clusters/failure-detector-configuration
- https://docs.hazelcast.com/hazelcast/5.4/clusters/phi-accrual-detector
为了更准确,我们采用社区建议,在hazelcast.yml使用phi-accrual 故障检测器,并配置超时时间为180s:
hazelcast:
properties:
# 以下为追加的新参数
hazelcast.heartbeat.failuredetector.type: phi-accrual
hazelcast.heartbeat.interval.seconds: 1
hazelcast.max.no.heartbeat.seconds: 180
hazelcast.heartbeat.phiaccrual.failuredetector.threshold: 10
hazelcast.heartbeat.phiaccrual.failuredetector.sample.size: 200
hazelcast.heartbeat.phiaccrual.failuredetector.min.std.dev.millis: 100优化GC配置
SeaTunnel默认使用G1垃圾处理器,内存配置的越大,若YoungGC/MixedGC资源回收的不够多(多线程),从而频繁触发FullGC处理(JAVA8单线程处理,时间很长),若集群多节点一起FullGC,则会导致集群越有可能出现组网异常问题;
所以我们的目标就是YoungGC/MixedGC尽可能利用线程回收足够多的内存。
未优化的参数
-Xms32g
-Xmx32g
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/seatunnel/dump/zeta-server
-XX:MaxMetaspaceSize=8g
-XX:+UseG1GC
-XX:+PrintGCDetails
-Xloggc:/alidata1/za-seatunnel/logs/gc.log
-XX:+PrintGCDateStamps于是我们尝试增加GC暂停的时间
-- 该参数设置所需最大暂停时间的目标值。默认值为 200 毫秒。
-XX:MaxGCPauseMillis=5000Mixed Garbage Collections会根据该参数中该参数和历史回收耗时来计算本次要回收多少Region才能耗时200ms,假如回收了一部分远远没有达到回收的效果,G1还有一个特殊处理方法,STW后进行回收,然后恢复系统线程,然后再次STW,执行混合回收掉一部分Region,‐XX:G1MixedGCCountTarget=8 (默认是8次),反复执行上述过程8次。
eg:假设要回收400个Region,如果受限200ms,每次只能回收50个Region,反复8次刚好全部回收完毕,避免单次停顿回收STW时间太长。
第一次优化后参数
-Xms32g
-Xmx32g
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/seatunnel/dump/zeta-server
-XX:MaxMetaspaceSize=8g
-XX:+UseG1GC
-XX:+PrintGCDetails
-Xloggc:/alidata1/za-seatunnel/logs/gc.log
-XX:+PrintGCDateStamps
-XX:MaxGCPauseMillis=5000MixedGC 日志如下:
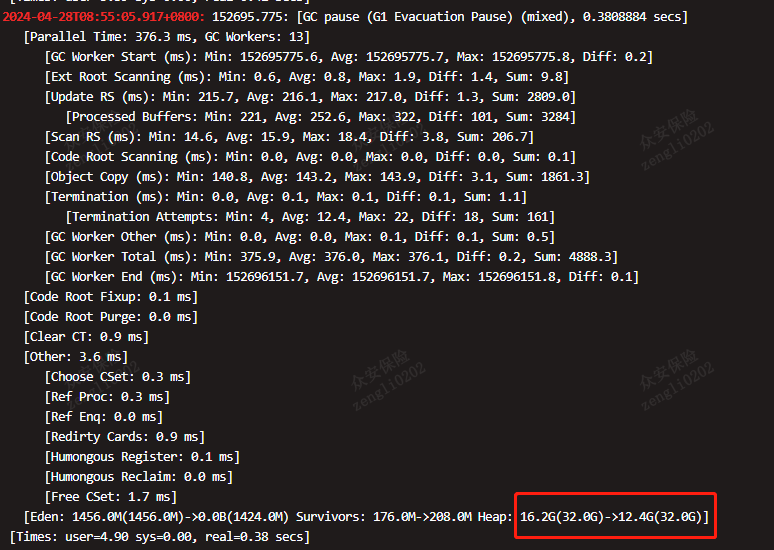
MixedGC 日志暂停耗时, 该参数仅是预期值,目前看返回结果的均在预期范围内;

full gc日志
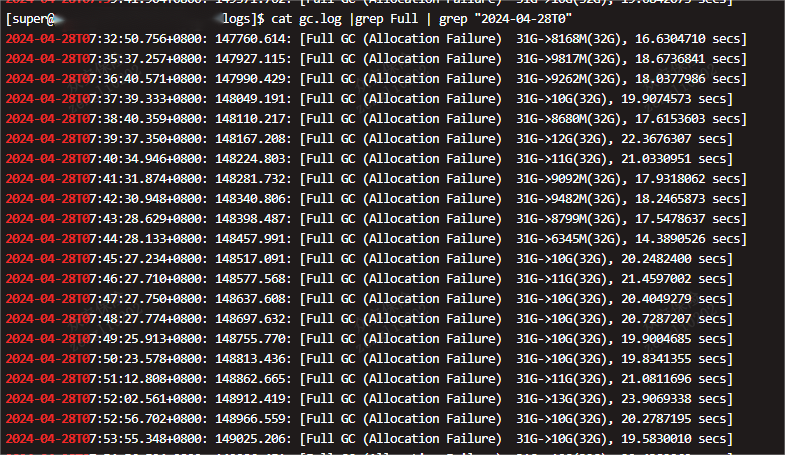
但是仍然无法避免FullGc,切耗时在20s左右,追加的参数只是少量优化GC性能。
我们通过观察日志,发现在MixedGC场景下,老年代没有被正常GC掉,有大量存留数据在老年代中未被清理。 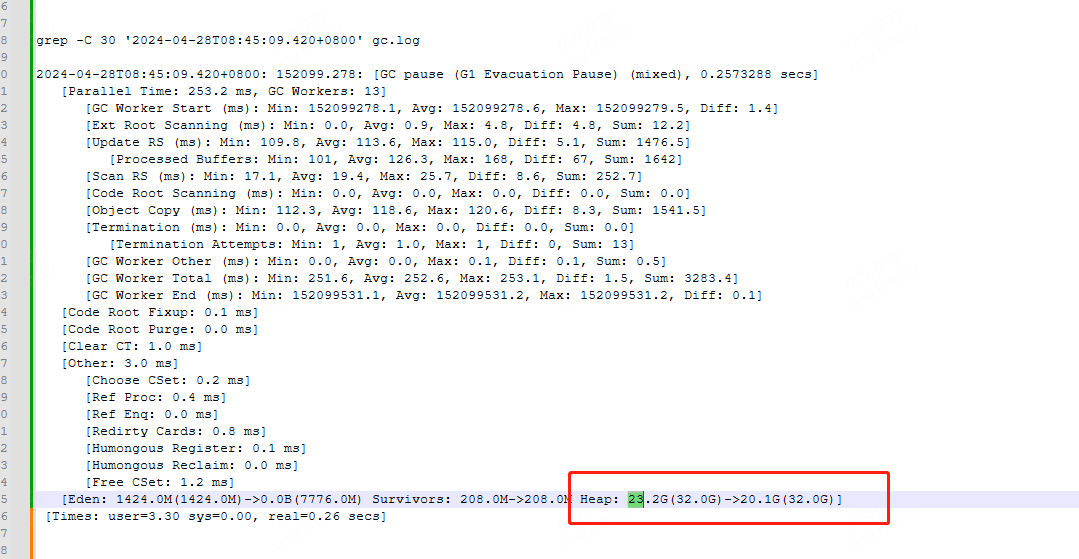 于是我们,我们尝试从增加老年代内存,以及G1垃圾回收器一些性能参数进行调参;
于是我们,我们尝试从增加老年代内存,以及G1垃圾回收器一些性能参数进行调参;
优化的参数如下:
-Xms42g
-Xmx42g
-XX:GCTimeRatio=4
-XX:G1ReservePercent=15
-XX:G1HeapRegionSize=32M堆内存(-Xms / -Xmx) 由32G->42G,变相增大了老年代区域的上限,理论上可以减少FullGC的次数;
GC占用的CPU和工作线程占用CPU时间比例(-XX:GCTimeRatio) 由10%->20%,计算公式为100/(1+GCTimeRatio),增加GC时占用时间;
保留空间(-XX:G1ReservePercent)由10%->15%,转移失败(Evacuation Failure)是指当G1无法在堆空间中申请新的分区时,G1便会触发担保机制,执行一次STW式的、单线程的Full GCG。可以保留空间增加,但是调高此值同时也意味着降低了老年代的实际可用空间,于是我们增大了堆内存,提升该参数可以缓解下列场景的出现:
- 从年轻代分区拷贝存活对象时,无法找到可用的空闲分区。
- 从老年代分区转移存活对象时,无法找到可用的空闲分区。
- 分配巨型对象时在老年代无法找到足够的连续分区。
堆内存Region大小(-XX:G1HeapRegionSize)—大小调整至32MB,优化对大对象的回收;
第二次优化后参数
-Xms42g
-Xmx42g
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/seatunnel/dump/zeta-server
-XX:MaxMetaspaceSize=8g
-XX:+UseG1GC
-XX:+PrintGCDetails
-Xloggc:/alidata1/za-seatunnel/logs/gc.log
-XX:+PrintGCDateStamps
-XX:MaxGCPauseMillis=5000
-XX:GCTimeRatio=4
-XX:G1ReservePercent=15
-XX:G1HeapRegionSize=32M优化后我们发现当天整体的FullGC数量有一定下降,但是仍未达到无FullGC的预期


继续观察日志,发现并行交集阶消耗了大量的时间,并出现很多次abort记录。
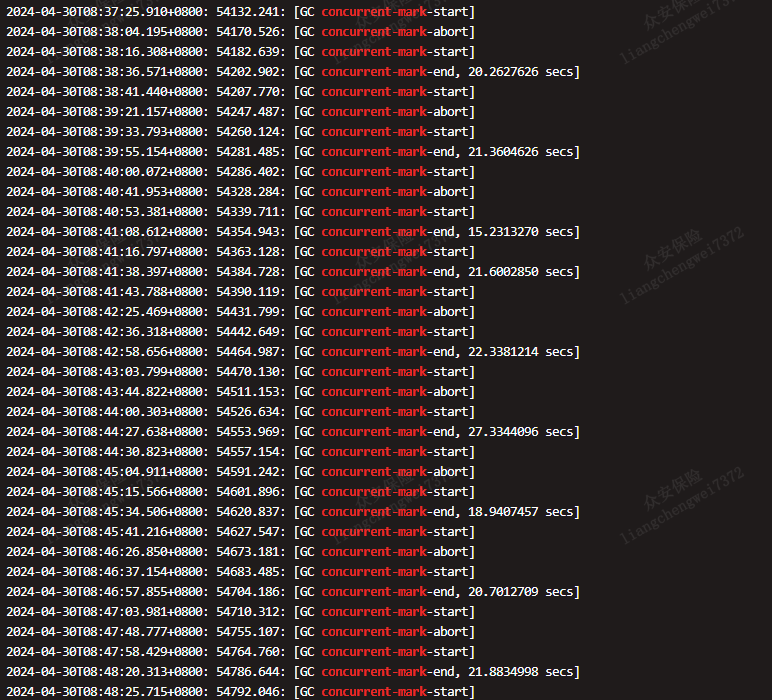
优化的参数如下:
-XX:ConcGCThreads=12
-XX:InitiatingHeapOccupancyPercent=50与应用一起执行的GC线程数量(-XX:ConcGCThreads) 由4->12,该值越低则系统的吞吐量越大,但过低会导致GC时间过长。当并发周期时间过长时,可以尝试调大GC工作线程数,但是这也意味着此期间应用所占的线程数减少,会对吞吐量有一定影响,对于离线数据同步场景,避免FullGC这个参数很重要。
老年代并发标记比率(-XX:InitiatingHeapOccupancyPercent)由 45%->50%,提早进行并发标记处理,提升MixedGC性能;
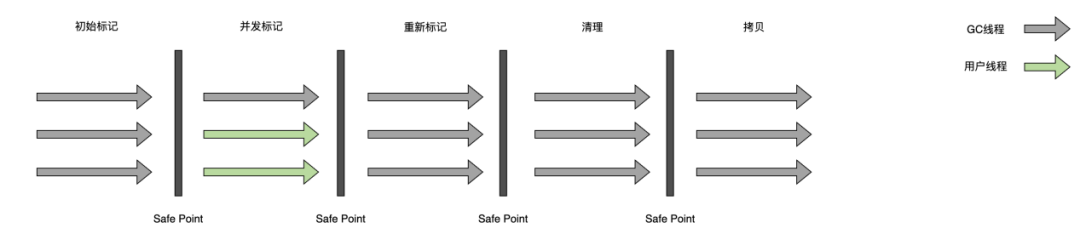
第三次优化后参数
-Xms42g
-Xmx42g
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/seatunnel/dump/zeta-server
-XX:MaxMetaspaceSize=8g
-XX:+UseG1GC
-XX:+PrintGCDetails
-Xloggc:/alidata1/za-seatunnel/logs/gc.log
-XX:+PrintGCDateStamps
-XX:MaxGCPauseMillis=5000
-XX:InitiatingHeapOccupancyPercent=50
-XX:+UseStringDeduplication
-XX:GCTimeRatio=4
-XX:G1ReservePercent=15
-XX:ConcGCThreads=12
-XX:G1HeapRegionSize=32MJVM调优参考:
- https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc_tuning.html#sthref56>
- https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc.html#pause_time_goal>
- https://zhuanlan.zhihu.com/p/181305087>
- https://blog.csdn.net/qq_32069845/article/details/130594667>
优化效果
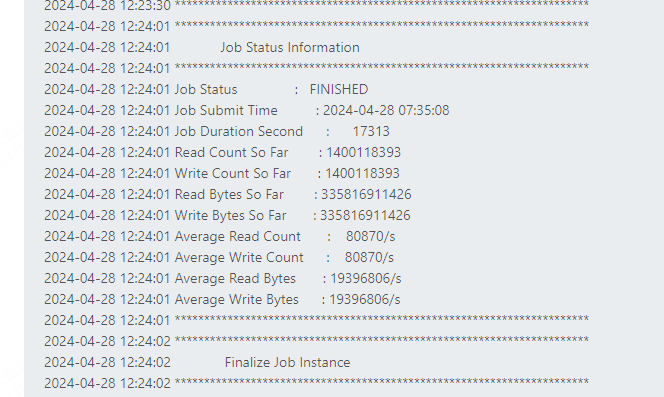
自4月26日配置优化修改后,未再出现集群脑裂问题,服务可用性监控显示,集群均可恢复正常。
自4月30日Jvm参数调优后,五一假期内,我们实现了3台节点FullGC数量为0的优化目标,系统健康检查接口未再出现任何卡顿异常。
虽然一定程度上牺牲了应用线程处理的吞吐量,但是我们保证了集群的稳定性,使zeta在内部大规模推广得到了保证。



本文由 白鲸开源科技 提供发布支持!

![[JS]DOM元素](https://img-blog.csdnimg.cn/img_convert/8a05104df19ec6eaecf99d50e9335e32.png)








![一招教你搞定Windows系统指定IP不变[固定IP地址方法]](https://img-blog.csdnimg.cn/direct/1289853e3bf34aee9f097113bc92b0ec.png)


