240620_昇思学习打卡-Day2-FCN图像语义分割
FCN图像语义分割
语义分割就是对图像中每个像素点进行分类,输入为图像,输出也是图像,输入输出同尺寸,下图是一些语义分割的示例:

其中Image是训练集的原图,GroundTruth是我们自己打的标签,或者从网上下的数据集中也会有打好的标签。FCN-8s和SDS[16]是两种网络预测的结果。
FCN是首次应用在图像语义分割的深度学习示例,因为丢弃所有全连接层,网络所有层都是卷积层,称为全卷积网络。
全卷积神经网络的三种主要技术:
1、卷积化(Convolutional)
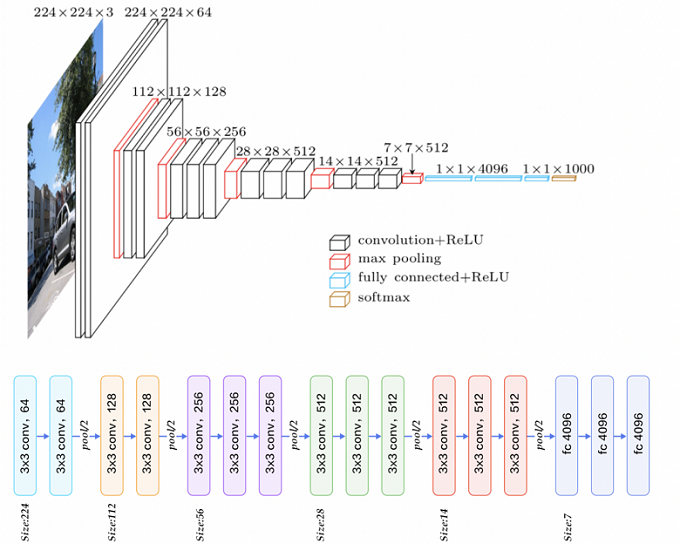
FCN使用VGG-16作为backbone(骨干网络),可以理解为是在VGG-16的基础上进行改进,把全连接层全部换成卷积层,使网络输出由一维非空间输出变为二维矩阵,利用输出能生成输入图片映射的heatmap。以下是VGG-16的结构:
2、上采样(Upsample)
上采样类似于一个卷积的过程,只不过在卷积之前将输入特征插值到一个更大的特征图然后进行卷积。

3、跳跃结构(Skip Layer)
利用上采样技巧对最后一层的特征图进行上采样得到原图大小的分割是步长为32像素的预测,称之为FCN-32s。由于最后一层的特征图太小,损失过多细节,采用skips结构将更具有全局信息的最后一层预测和更浅层的预测结合,使预测结果获取更多的局部细节。将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。 Skips结构将深层的全局信息与浅层的局部信息相结合。
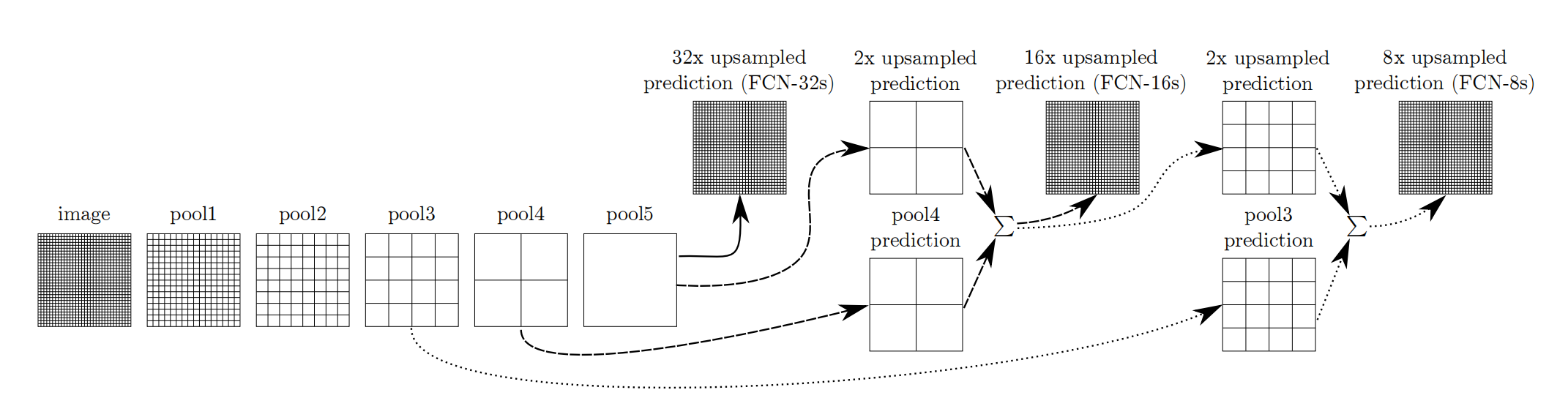
特点:适应任意尺寸输入,反卷积层能输出精细的结果、结合不同深度层结果的跳级(skip)结构,同时确保鲁棒性和精确性。
准备工作
首先安装本地MindSpore环境,笔者之前已经安装过了,这里采用新建一个虚拟环境执行win下cpu版本的安装,其他安装方式可参考昇思官网MindSpore官网
win+r打开cmd,新建一个虚拟环境,python版本为3.9,新建时把mindspore_py39更换为你自己的虚拟环境名字
conda create -n mindspore_py39 python=3.9
激活虚拟环境并进入
conda activate mindspore_py39
如果忘了刚新建的虚拟环境名,可以执行以下cmd命令进行查看
conda env list
激活成功后cmd会是如下样子:

在该虚拟环境中执行mindspore安装命令,我选的是py3.9,具体自己的安装命令在上面官网地址自行选择
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.2.14/MindSpore/cpu/x86_64/mindspore-2.2.14-cp39-cp39-win_amd64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后可检查是否成功安装,返回版本号说明安装成功
python -c "import mindspore;mindspore.set_context(device_target='CPU');mindspore.run_check()"

新建一个jupyter notebook,此处使用jupyter是为了方便我们观察,逐行逐步执行
执行以下命令安装我们本次学习需要用到的数据集
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar"
download(url, "./dataset", kind="tar", replace=True)
数据预处理
在训练过程中,我们需要保证图像分辨率大小一致,需做标准化处理
数据加载
将PASCAL VOC 2012数据集与SDB数据集进行混合。
import numpy as np
import cv2
import mindspore.dataset as ds
# 定义用于语义分割的数据集类
class SegDataset:
"""
用于语义分割任务的数据集类。
参数:
image_mean: 图像的均值,用于归一化。
image_std: 图像的标准差,用于归一化。
data_file: 数据集文件路径。
batch_size: 批处理大小。
crop_size: 图像裁剪的大小。
max_scale: 图像缩放的最大比例。
min_scale: 图像缩放的最小比例。
ignore_label: 在标签中忽略的值。
num_classes: 标签中的类别数。
num_readers: 读取数据的线程数。
num_parallel_calls: 并行处理的函数数。
"""
def __init__(self,
image_mean, # 图像的均值,用于归一化。
image_std, # 图像的标准差,用于归一化。
data_file='', # 数据集文件路径。
batch_size=32, # 批处理大小。
crop_size=512, # 图像裁剪的大小。
max_scale=2.0, # 图像缩放的最大比例。
min_scale=0.5, # 图像缩放的最小比例。
ignore_label=255, # 在标签中忽略的值。
num_classes=21, # 标签中的类别数。
num_readers=2, # 读取数据的线程数。
num_parallel_calls=4): # 并行处理的函数数。
# 初始化参数
self.data_file = data_file
self.batch_size = batch_size
self.crop_size = crop_size
self.image_mean = np.array(image_mean, dtype=np.float32)
self.image_std = np.array(image_std, dtype=np.float32)
self.max_scale = max_scale
self.min_scale = min_scale
self.ignore_label = ignore_label
self.num_classes = num_classes
self.num_readers = num_readers
self.num_parallel_calls = num_parallel_calls
# 对数据集进行预处理
def preprocess_dataset(self, image, label):
"""
对单个样本进行预处理,包括图像和标签的缩放、归一化、填充和随机裁剪。
参数:
image: 图像数据。
label: 标签数据。
返回:
处理后的图像和标签数据。
"""
# 解码图像
image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)
# 解码标签
label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)
# 随机缩放图像和标签
sc = np.random.uniform(self.min_scale, self.max_scale)
new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])
image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)
# 归一化图像
image_out = (image_out - self.image_mean) / self.image_std
# 对图像和标签进行填充,确保其大小不小于crop_size
out_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)
pad_h, pad_w = out_h - new_h, out_w - new_w
if pad_h > 0 or pad_w > 0:
image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)
label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)
# 随机裁剪图像和标签
offset_h = np.random.randint(0, out_h - self.crop_size + 1)
offset_w = np.random.randint(0, out_w - self.crop_size + 1)
image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]
label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]
# 随机水平翻转图像和标签
if np.random.uniform(0.0, 1.0) > 0.5:
image_out = image_out[:, ::-1, :]
label_out = label_out[:, ::-1]
# 调整图像通道顺序并返回处理后的图像和标签
image_out = image_out.transpose((2, 0, 1))
image_out = image_out.copy()
label_out = label_out.copy()
label_out = label_out.astype("int32")
return image_out, label_out
# 获取处理后的数据集
def get_dataset(self):
"""
创建并返回经过预处理的数据集。
返回:
经过预处理和批处理的数据集。
"""
# 启用NUMA支持
ds.config.set_numa_enable(True)
# 加载数据集
dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],
shuffle=True, num_parallel_workers=self.num_readers)
# 定义预处理操作
transforms_list = self.preprocess_dataset
# 对数据集应用预处理操作
dataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],
output_columns=["data", "label"],
num_parallel_workers=self.num_parallel_calls)
# 打乱数据顺序
dataset = dataset.shuffle(buffer_size=self.batch_size * 10)
# 设置批处理大小
dataset = dataset.batch(self.batch_size, drop_remainder=True)
return dataset
# 定义创建数据集的参数
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 定义模型训练参数
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21
# 实例化数据集类并获取处理后的数据集
dataset = SegDataset(image_mean=IMAGE_MEAN,
image_std=IMAGE_STD,
data_file=DATA_FILE,
batch_size=train_batch_size,
crop_size=crop_size,
max_scale=max_scale,
min_scale=min_scale,
ignore_label=ignore_label,
num_classes=num_classes,
num_readers=2,
num_parallel_calls=4)
dataset = dataset.get_dataset()
训练集可视化
运行以下代码观察载入的数据集图片(数据处理过程中已做归一化处理)。
import numpy as np
import matplotlib.pyplot as plt
# 创建一个图形窗口,设置其大小为16x8英寸
plt.figure(figsize=(16, 8))
# 遍历数据集,展示8个样本
# 对训练集中的数据进行展示
for i in range(1, 9):
# 在当前图形窗口中创建一个子图,总共创建2行4列的子图,当前为第i个
plt.subplot(2, 4, i)
# 从数据集中获取下一个批次的数据
show_data = next(dataset.create_dict_iterator())
# 获取批次中的数据字段,并将其转换为numpy数组
show_images = show_data["data"].asnumpy()
# 将图像数据限制在0到1之间
show_images = np.clip(show_images, 0, 1)
# 调整图像的维度顺序为HWC,并显示图像
# 将图片转换HWC格式后进行展示
plt.imshow(show_images[0].transpose(1, 2, 0))
# 关闭子图的坐标轴显示
plt.axis("off")
# 调整子图之间的间距
plt.subplots_adjust(wspace=0.05, hspace=0)
# 显示所有子图
plt.show()

网络构建
网络流程
FCN网络的流程如下图所示:
- 输入图像image,经过pool1池化后,尺寸变为原始尺寸的1/2。
- 经过pool2池化,尺寸变为原始尺寸的1/4。
- 接着经过pool3、pool4、pool5池化,大小分别变为原始尺寸的1/8、1/16、1/32。
- 经过conv6-7卷积,输出的尺寸依然是原图的1/32。
- FCN-32s是最后使用反卷积,使得输出图像大小与输入图像相同。
- FCN-16s是将conv7的输出进行反卷积,使其尺寸扩大两倍至原图的1/16,并将其与pool4输出的特征图进行融合,后通过反卷积扩大到原始尺寸。
- FCN-8s是将conv7的输出进行反卷积扩大4倍,将pool4输出的特征图反卷积扩大2倍,并将pool3输出特征图拿出,三者融合后通反卷积扩大到原始尺寸。
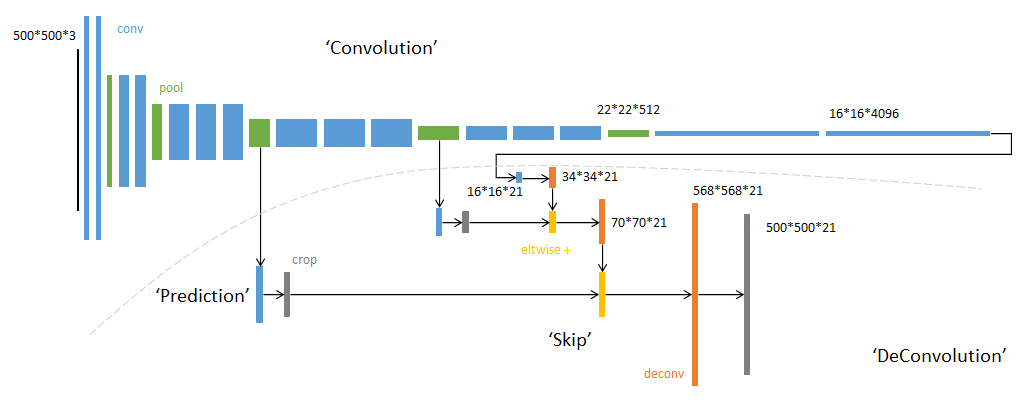
代码实现(FCN-8s)
# 导入mindspore.nn模块,用于构建神经网络组件
import mindspore.nn as nn
# 定义FCN8s类,继承自nn.Cell,实现FCN8s网络结构
class FCN8s(nn.Cell):
"""
FCN8s网络结构。
该网络是Fully Convolutional Networks的其中一个变体,用于像素级的分类任务。
参数:
- n_class: 类别的数量,用于定义网络输出的类别数。
"""
def __init__(self, n_class):
# 调用父类构造函数
super().__init__()
# 类别数量
self.n_class = n_class
# 构建卷积层1
self.conv1 = nn.SequentialCell(
nn.Conv2d(in_channels=3, out_channels=64,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(64),
nn.ReLU()
)
# 最大池化层1
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 构建卷积层2
self.conv2 = nn.SequentialCell(
nn.Conv2d(in_channels=64, out_channels=128,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(128),
nn.ReLU()
)
# 最大池化层2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 构建卷积层3
self.conv3 = nn.SequentialCell(
nn.Conv2d(in_channels=128, out_channels=256,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(256),
nn.ReLU()
)
# 最大池化层3
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
# 构建卷积层4
self.conv4 = nn.SequentialCell(
nn.Conv2d(in_channels=256, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU()
)
# 最大池化层4
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# 构建卷积层5
self.conv5 = nn.SequentialCell(
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU()
)
# 最大池化层5
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
# 构建卷积层6
self.conv6 = nn.SequentialCell(
nn.Conv2d(in_channels=512, out_channels=4096,
kernel_size=7, weight_init='xavier_uniform'),
nn.BatchNorm2d(4096),
nn.ReLU(),
)
# 构建卷积层7
self.conv7 = nn.SequentialCell(
nn.Conv2d(in_channels=4096, out_channels=4096,
kernel_size=1, weight_init='xavier_uniform'),
nn.BatchNorm2d(4096),
nn.ReLU(),
)
# 分类得分层
self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,
kernel_size=1, weight_init='xavier_uniform')
# 上采样层2
self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=4, stride=2, weight_init='xavier_uniform')
# 分类得分层(来自pool4)
self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,
kernel_size=1, weight_init='xavier_uniform')
# 上采样层4
self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=4, stride=2, weight_init='xavier_uniform')
# 分类得分层(来自pool3)
self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,
kernel_size=1, weight_init='xavier_uniform')
# 上采样层8
self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=16, stride=8, weight_init='xavier_uniform')
# 定义前向传播方法
def construct(self, x):
# 经过卷积层1
x1 = self.conv1(x)
# 经过池化层1
p1 = self.pool1(x1)
# 经过卷积层2
x2 = self.conv2(p1)
# 经过池化层2
p2 = self.pool2(x2)
# 经过卷积层3
x3 = self.conv3(p2)
# 经过池化层3
p3 = self.pool3(x3)
# 经过卷积层4
x4 = self.conv4(p3)
# 经过池化层4
p4 = self.pool4(x4)
# 经过卷积层5
x5 = self.conv5(p4)
# 经过池化层5
p5 = self.pool5(x5)
# 经过卷积层6
x6 = self.conv6(p5)
# 经过卷积层7
x7 = self.conv7(x6)
# 获取最终分类得分
sf = self.score_fr(x7)
# 上采样得分层2
u2 = self.upscore2(sf)
# 获取pool4层的分类得分
s4 = self.score_pool4(p4)
# 合并pool4层和上采样得分层2的特征
f4 = s4 + u2
# 上采样得分层4
u4 = self.upscore_pool4(f4)
# 获取pool3层的分类得分
s3 = self.score_pool3(p3)
# 合并pool3层和上采样得分层4的特征
f3 = s3 + u4
# 最终上采样得分层8
out = self.upscore8(f3)
# 返回输出
return out
训练准备
导入VGG-16部分预训练权重
在训练模型时,最好还是有一个预训练权重,没有预训练权重的话训练效果比较差
此处FCN的骨干网络是VGG-16,所以可以使用VGG-16预训练模型的部分预训练权重。
# 这里就是下载及装载权重,不写过多注释
from download import download
from mindspore import load_checkpoint, load_param_into_net
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/fcn8s_vgg16_pretrain.ckpt"
download(url, "fcn8s_vgg16_pretrain.ckpt", replace=True)
def load_vgg16():
ckpt_vgg16 = "fcn8s_vgg16_pretrain.ckpt"
param_vgg = load_checkpoint(ckpt_vgg16)
load_param_into_net(net, param_vgg)
损失函数
语义分割是对图像中每个像素点进行分类,实质上仍然是分类问题,损失函数选择交叉熵损失函数作为预测和标签之间的交叉熵损失,这里使用mindspore.nn.CrossEntropyLoss()作为损失函数。
交叉熵损失函数思想距举例见笔者另一篇博客:[昇思学习打卡-Day1-损失函数_交叉熵损失函数-CSDN博客](https://blog.csdn.net/weixin_66378701/article/details/139827679?spm=1001.2014.3001.5501)
自定义评价指标
这一部分主要对训练出来的模型效果进行评估,为了便于解释,假设如下:共有k+1个类(从 L0 到 Lk, 其中包含一个空类或背景), p_{i j} 表示本属于i类但被预测为j类的像素数量。即p_{i i}表示真正的数量, 而 p_{i j} p_{j i}则分别被解释为假正和假负, 尽管两者都是假正与假负之和。
- Pixel Accuracy(PA, 像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
P A = ∑ i = 0 k p i i ∑ i = 0 k ∑ j = 0 k p i j P A=\frac{\sum_{i=0}^k p_{i i}}{\sum_{i=0}^k \sum_{j=0}^k p_{i j}} PA=∑i=0k∑j=0kpij∑i=0kpii
- Mean Pixel Accuracy(MPA, 均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
M P A = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j M P A=\frac{1}{k+1} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}} MPA=k+11i=0∑k∑j=0kpijpii
- Mean Intersection over Union(MloU, 均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之,在语义分割的问题中,这两个集合为真实值(ground truth) 和预测值(predicted segmentation)。这个比例可以变形为正真数 (intersection) 比上真正、假负、假正(并集)之和。在每个类上计算loU,之后平均。
M I o U = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i M I o U=\frac{1}{k+1} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}+\sum_{j=0}^k p_{j i}-p_{i i}} MIoU=k+11i=0∑k∑j=0kpij+∑j=0kpji−piipii
- Frequency Weighted Intersection over Union(FWIoU, 频权交井比):为MloU的一种提升,这种方法根据每个类出现的频率为其设置权重。
F W I o U = 1 ∑ i = 0 k ∑ j = 0 k p i j ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i F W I o U=\frac{1}{\sum_{i=0}^k \sum_{j=0}^k p_{i j}} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}+\sum_{j=0}^k p_{j i}-p_{i i}} FWIoU=∑i=0k∑j=0kpij1i=0∑k∑j=0kpij+∑j=0kpji−piipii
有时使用混淆矩阵可能更便于理解(以二分类问题举例):
| 预测的正例 | 预测的反例 | |
|---|---|---|
| 真实的正例 | TP(真实值) | FN(假反例) |
| 真实的反例 | FP(假正例) | TN(真反例) |

Pixel Accuracy(PA, 像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
P
A
=
T
P
+
T
N
T
P
+
F
N
+
F
P
+
T
N
PA=\frac{TP+TN}{TP+FN+FP+TN}
PA=TP+FN+FP+TNTP+TN
IOU:就是模型对某一类别预测结果和真实值的交集与并集的比值
I
O
U
=
T
P
T
P
+
F
P
+
F
N
IOU=\frac{TP}{TP+FP+FN}
IOU=TP+FP+FNTP
MIOU:模型对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果
M
I
O
U
=
1
2
[
(
T
P
T
P
+
F
P
+
F
N
)
+
(
T
N
T
N
+
F
N
+
F
P
)
]
MIOU=\frac{1}{2}[(\frac{TP}{TP+FP+FN})+(\frac{TN}{TN+FN+FP})]
MIOU=21[(TP+FP+FNTP)+(TN+FN+FPTN)]
# 导入必要的库
import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.train as train
# 定义像素准确率类,用于计算像素级别的准确率
class PixelAccuracy(train.Metric):
def __init__(self, num_class=21):
super(PixelAccuracy, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
"""
生成混淆矩阵
参数:
gt_image: 真实标签图像
pre_image: 预测标签图像
返回:
混淆矩阵
"""
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def clear(self):
"""
清除累积的混淆矩阵
"""
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def update(self, *inputs):
"""
更新混淆矩阵
参数:
inputs: 包含预测结果和真实标签的元组
"""
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def eval(self):
"""
计算像素准确率
返回:
像素准确率
"""
pixel_accuracy = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()
return pixel_accuracy
# 定义每个类的像素准确率类,用于计算每个类的平均像素准确率
class PixelAccuracyClass(train.Metric):
def __init__(self, num_class=21):
super(PixelAccuracyClass, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
"""
生成混淆矩阵
参数:
gt_image: 真实标签图像
pre_image: 预测标签图像
返回:
混淆矩阵
"""
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
"""
更新混淆矩阵
参数:
inputs: 包含预测结果和真实标签的元组
"""
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
"""
清除累积的混淆矩阵
"""
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
"""
计算每个类的平均像素准确率
返回:
平均像素准确率
"""
mean_pixel_accuracy = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
mean_pixel_accuracy = np.nanmean(mean_pixel_accuracy)
return mean_pixel_accuracy
# 定义平均交并比(mIoU)类,用于计算类别间的平均交并比
class MeanIntersectionOverUnion(train.Metric):
def __init__(self, num_class=21):
super(MeanIntersectionOverUnion, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
"""
生成混淆矩阵
参数:
gt_image: 真实标签图像
pre_image: 预测标签图像
返回:
混淆矩阵
"""
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
"""
更新混淆矩阵
参数:
inputs: 包含预测结果和真实标签的元组
"""
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
"""
清除累积的混淆矩阵
"""
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
"""
计算平均交并比
返回:
平均交并比
"""
mean_iou = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
mean_iou = np.nanmean(mean_iou)
return mean_iou
# 定义频率加权交并比(fwIoU)类,用于计算考虑类别频率的交并比
class FrequencyWeightedIntersectionOverUnion(train.Metric):
def __init__(self, num_class=21):
super(FrequencyWeightedIntersectionOverUnion, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
"""
生成混淆矩阵
参数:
gt_image: 真实标签图像
pre_image: 预测标签图像
返回:
混淆矩阵
"""
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
"""
更新混淆矩阵
参数:
inputs: 包含预测结果和真实标签的元组
"""
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
"""
清除累积的混淆矩阵
"""
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
"""
计算频率加权交并比(Frequency Weighted Intersection over Union, FWIU)。
该指标用于评估分类器的性能,特别是在类别分布不均衡的情况下。
它通过将每个类别的交并比(Intersection over Union, IoU)乘以该类别的频率(即在真实标签中出现的次数)
来加权,然后将所有类别的加权IoU相加。
返回:
frequency_weighted_iou: 频率加权交并比的总和。
"""
# 计算每个类别的频率,即该类在所有预测中所占的比例
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
# 计算每个类别的交并比(IoU)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
# 计算频率大于0的类别的频率加权IoU,并将其相加
frequency_weighted_iou = (freq[freq > 0] * iu[freq > 0]).sum()
return frequency_weighted_iou
模型训练
模型训练遵从“设定参数-实例化网络-实例化损失函数、优化器-初始化模型-训练”的顺序
此处训练仅作演示,真实训练需要修改train_epochs参数以及数据集
这里埋个坑,后续更新余弦退火学习率算法讲解
6月21填坑:240621_昇思学习打卡-Day3-余弦退火+周期性重启+warm up
# 导入mindspore库,用于深度学习框架
import mindspore
from mindspore import Tensor
import mindspore.nn as nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, Model
# 设定运行设备目标,此处为Ascend
device_target = "Ascend"
# 设置运行模式为PyNative模式,并指定设备目标
mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target=device_target)
# 定义训练批次大小和类别数量
train_batch_size = 4
num_classes = 21
# 初始化FCN8s网络结构,用于语义分割
# 初始化模型结构
net = FCN8s(n_class=21)
# 加载vgg16预训练参数
# 导入vgg16预训练参数
load_vgg16()
# 定义最小学习率、基础学习率和训练轮数
# 计算学习率
min_lr = 0.0005
base_lr = 0.05
# 此处训练仅作演示,为了速度设置epoch为1,实际训练需要修改
train_epochs = 1
# 获取数据集大小,用于计算总步数
iters_per_epoch = dataset.get_dataset_size()
total_step = iters_per_epoch * train_epochs
# 使用余弦退火策略设置学习率调度器
lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,
base_lr,
total_step,
iters_per_epoch,
decay_epoch=2)
lr = Tensor(lr_scheduler[-1])
# 定义交叉熵损失函数,忽略索引为255的标签
# 定义损失函数
loss = nn.CrossEntropyLoss(ignore_index=255)
# 定义动量优化器
# 定义优化器
optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.0001)
# 如果设备目标为Ascend,使用动态损失缩放管理器
# 定义loss_scale
scale_factor = 4
scale_window = 3000
loss_scale_manager = ms.amp.DynamicLossScaleManager(scale_factor, scale_window)
# 根据设备目标初始化模型
# 初始化模型
if device_target == "Ascend":
model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={
"pixel accuracy": PixelAccuracy(),
"mean pixel accuracy": PixelAccuracyClass(),
"mean IoU": MeanIntersectionOverUnion(),
"frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()
})
else:
model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={
"pixel accuracy": PixelAccuracy(),
"mean pixel accuracy": PixelAccuracyClass(),
"mean IoU": MeanIntersectionOverUnion(),
"frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()
})
# 设置训练过程中的回调函数,包括时间监控和损失监控
# 设置ckpt文件保存的参数
time_callback = TimeMonitor(data_size=iters_per_epoch)
loss_callback = LossMonitor()
callbacks = [time_callback, loss_callback]
# 设置保存模型的步骤间隔和最大保存数量
save_steps = 330
keep_checkpoint_max = 5
config_ckpt = CheckpointConfig(save_checkpoint_steps=save_steps,
keep_checkpoint_max=keep_checkpoint_max)
ckpt_callback = ModelCheckpoint(prefix="FCN8s",
directory="./ckpt",
config=config_ckpt)
callbacks.append(ckpt_callback)
# 开始训练模型
model.train(train_epochs, dataset, callbacks=callbacks)
模型评估(纸上谈兵)
查看模型的纸面数据
# 定义图像的平均值和标准差,用于图像预处理中的归一化
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
# 数据集文件路径
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 从指定URL下载预训练的模型权重文件
# 下载已训练好的权重文件
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/FCN8s.ckpt"
download(url, "FCN8s.ckpt", replace=True)
# 初始化FCN8s网络结构
net = FCN8s(n_class=num_classes)
# 加载预训练模型的权重
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
# 根据设备类型(Ascend或GPU)配置模型评估指标
if device_target == "Ascend":
model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={
"pixel accuracy": PixelAccuracy(),
"mean pixel accuracy": PixelAccuracyClass(),
"mean IoU": MeanIntersectionOverUnion(),
"frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:
model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={
"pixel accuracy": PixelAccuracy(),
"mean pixel accuracy": PixelAccuracyClass(),
"mean IoU": MeanIntersectionOverUnion(),
"frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
# 初始化数据集,用于模型的评估
# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,
image_std=IMAGE_STD,
data_file=DATA_FILE,
batch_size=train_batch_size,
crop_size=crop_size,
max_scale=max_scale,
min_scale=min_scale,
ignore_label=ignore_label,
num_classes=num_classes,
num_readers=2,
num_parallel_calls=4)
dataset_eval = dataset.get_dataset()
model.eval(dataset_eval)
模型推理(实战检验)
预测环节,练了那么久,是骡子是马拉出来遛遛了
# 导入计算机视觉库OpenCV和绘图库Matplotlib
import cv2
import matplotlib.pyplot as plt
# 初始化FCN8s网络模型,用于语义分割
net = FCN8s(n_class=num_classes)
# 设置超参
ckpt_file = "FCN8s.ckpt"
# 加载预训练模型的检查点
param_dict = load_checkpoint(ckpt_file)
# 将检查点的参数加载到网络模型中
load_param_into_net(net, param_dict)
# 设置评估批次大小
eval_batch_size = 4
# 初始化用于存储图像、掩码和结果的列表
img_lst = []
mask_lst = []
res_lst = []
# 设置绘图大小
# 推理效果展示(上方为输入图片,下方为推理效果图片)
plt.figure(figsize=(8, 5))
# 从数据集中获取一个批次的数据用于展示
show_data = next(dataset_eval.create_dict_iterator())
# 提取输入图像和对应的掩码
show_images = show_data["data"].asnumpy()
mask_images = show_data["label"].reshape([4, 512, 512])
# 将图像值限制在0到1之间
show_images = np.clip(show_images, 0, 1)
# 将图像和掩码添加到对应的列表中
for i in range(eval_batch_size):
img_lst.append(show_images[i])
mask_lst.append(mask_images[i])
# 对输入图像进行语义分割预测
res = net(show_data["data"]).asnumpy().argmax(axis=1)
# 遍历批次中的每个图像,显示输入图像和分割结果
for i in range(eval_batch_size):
# 设置子图,显示原图
plt.subplot(2, 4, i + 1)
plt.imshow(img_lst[i].transpose(1, 2, 0))
plt.axis("off")
# 设置子图,显示分割结果
plt.subplot(2, 4, i + 5)
plt.imshow(res[i])
plt.axis("off")
# 调整子图之间的间距
plt.subplots_adjust(wspace=0.05, hspace=0.02)
# 显示所有子图
plt.show()
代码很多是官方代码,仅添加个人理解和部分注释
打卡截图: