目录
1. IP概述
2. Avalon-MM DMA Ports
3. 参数设置
3.1 系统设置
3.2 基址寄存器 (BAR) 设置
3.3 设备识别寄存器
3.4 PCI Express和PCI功能参数
3.4.1 Device Capabilities
3.4.2 Error Reporting
3.4.3 Link Capabilities
3.4.4 MSI and MSI-X Capabilities
3.4.5 Power Management
3.5 PCIe地址空间设置
4. IP核接口
4.1 Read Data Mover
4.2 Write DMA Avalon-MM Master Port
4.3 RX Master Module
4.4 Non-Bursing Slave Module
4.5 32-Bit Control Register Access (CRA) Slave Signals
4.6 Descriptor Controller Interfaces when Instantiated Internally
4.6.1 Read Descriptor Controller Avalon-MM Master interface
4.6.2 Write Descriptor Controller Avalon-MM Master Interface
4.6.3 Read Descriptor Table Avalon-MM Slave Interface
4.6.4 Write Descriptor Table Avalon-MM Slave Interface
4.7 Clock Signals
4.8 Reset, Status, and Link Training Signals
4.8.1 Reset Signals
4.8.2 Status and Link Training Signals
4.9 MSI Interrupts for Endpoints
4.10 Physical Layer Interface Signals
4.10.1 Transceiver Reconfiguration
4.10.2 Serial Data Signals
4.10.3 PIPE Interface Signals
4.11 Test Signal
5.Reset and Clocks
5.1 Reset Sequence for Hard IP for PCI Express IP Core and Application Layer
5.2 Clocks
5.2.1 Clock Domains
5.2.2 Clock Summary
1. IP概述
V系列指的是Intel的Arria V、Cyclone V、Arria V GZ和Stratix V,适用于PCI Express的V系列Avalon-MM DMA实现了完整的协议栈,包括事务层、数据链路层核物理层,并且支持Gen1 x8、Gen2 x4、Gen2 x8、Gen3 x2、Gen3 x4 和 Gen3 x8。
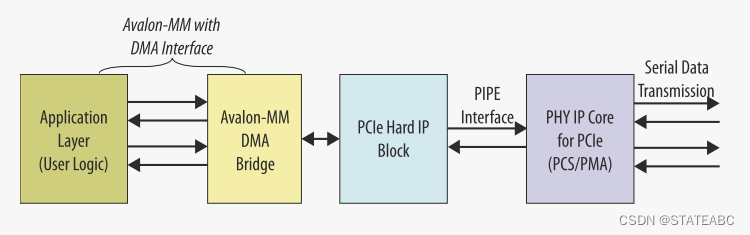
V-Series Avalon-MM DMA Interface for PCI Express Intel FPGA IP支持与DMA配合达到 Gen3 ×8数据速率的128位或256位Avalon-MM到应用层的接口。
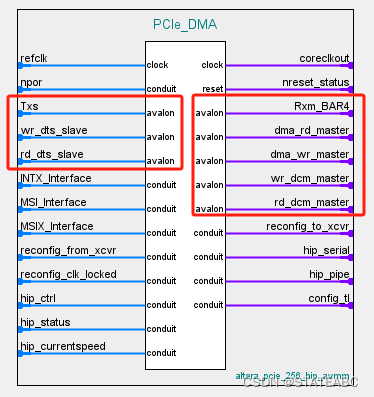
2. Avalon-MM DMA Ports
在V-Series Avalon-MM DMA for PCI Express Intel FPGA IP中有一些Avalon-MM DMA端口,这些端口实现了通过DMA读写数据的功能。
| Function | Port | Description |
| TXS | Txs | Avalon-MM从端口 Avalon-MM主设备使用该端口向PCIe发送内存读取或写入操作。 当DMA完成操作时,Descriptor Controller使用该端口将DMA状态写回PCIe中的描述符空间。Descriptor Controller还使用该端口向上游发送MSI中断。 |
| Read Data Mover | dma_rd_master | Avalon-MM主端口 在正常的读取DMA操作期间,Read Data Mover将数据从PCIe移动到片上存储器并且从PCIe域获取描述符,将它们写入Descriptor Controller中的FIFO。 dma_rd_master端口连接到wr_dts_slave端口,用于加载写入DMA描述符FIFO,而rd_dts_slave端口用于加载read |
| Write Data Mover | dma_wr_master | Avalon-MM 主端口 Write Data Mover从片上存储器读取数据,然后将数据写入PCIe域。 |
| Descriptor Controller FIFOs | wr_dts_slave rd_dts_slave | 用于描述符控制器FIFO的Avalon-MM从端口。 当Read Data Mover从系统内存获取描述符时,它使用该端口将描述符写入FIFO中。读取DMA描述符和写入DMA描述符有两个单独的描述符表,因此有两个端口。 写入DMA FIFO的地址范围为0x100_0000至0x100_1FFF。 读取DMA FIFO的地址范围为0x100_2000至0x100_3FFF。 |
| Control in the Descriptor Controller | wr_dcm_master rd_dcm_master | Control in the Descriptor Controller有一个用于读取DMA的传输端口和一个用于写入DMA的接收端口。 接收端口连接到RXM_BAR0,而传输端口连接到Txs。 来自RXM_BAR0的接收路径在内部连接,不在连接面板中显示。对于传输路径,读取和写入DMA端口都在连接面板中外部连接到Txs(即wr_dcm_master和rd_dcm_master都连接到Txs)。 |
| RXM_BAR0 | 不显示 | Avalon-MM主端口 它将来自PCIe主机的内存访问传递到PCIe BAR0。主机使用该端口来编程Descriptor Controller。 当使用了内部描述符控制器,端口连接不显示,连接在a10_pcie_hip_0模块内部进行。 |
| RXM_BAR4 | Rxm_BAR4 | Avalon-MM主端口。 它将来自PCIe主机的内存访问传递到PCIe BAR4。它连接到片上存储器。PCIe主机通过PCIe BAR4访问存储器。 在典型的应用中,系统软件控制该端口以在片上存储器中初始化随机数据。软件还读取数据以验证正确的操作。 |
根据Intel给的示例,NIOS中连接方式
3. 参数设置
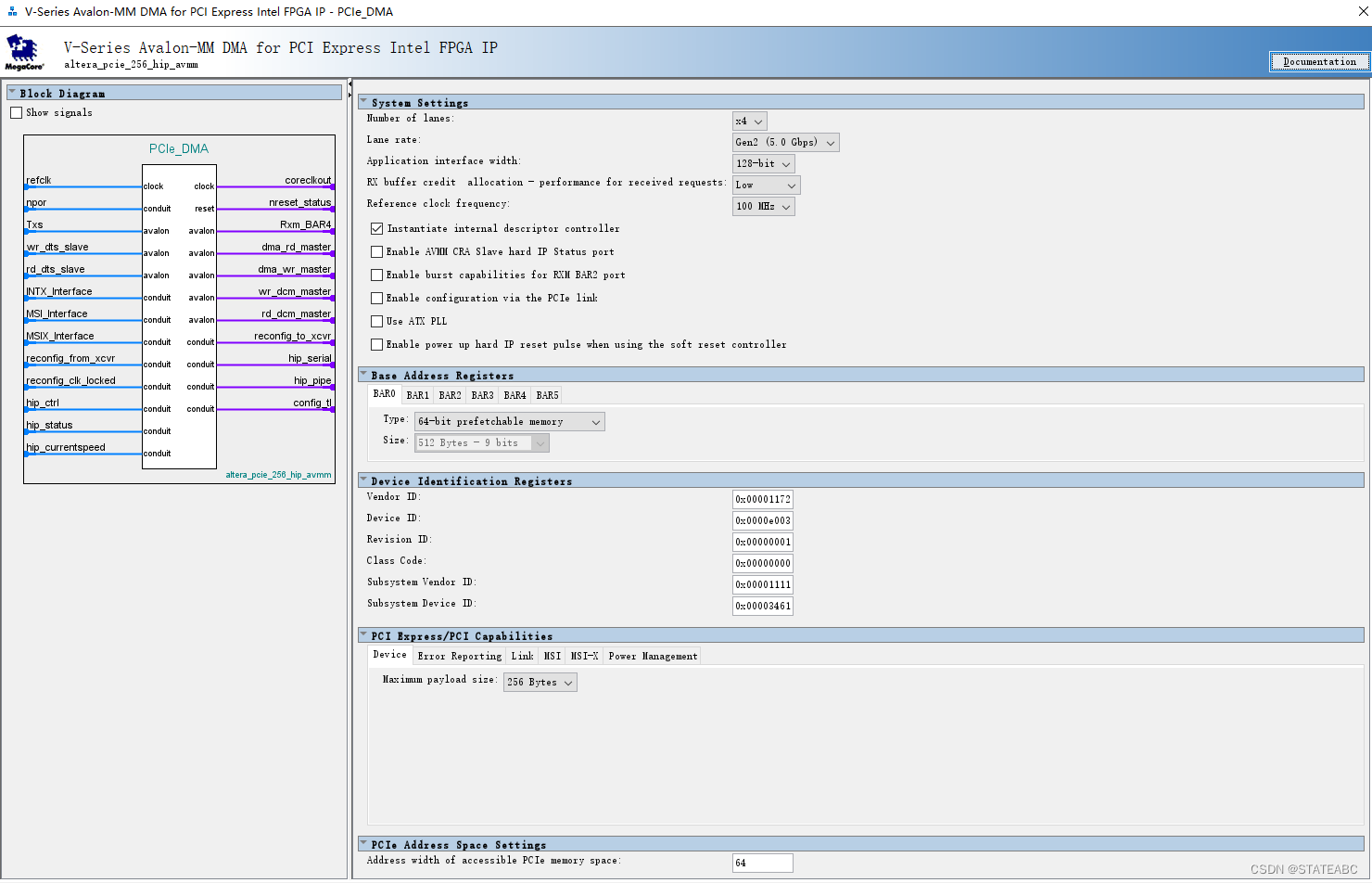
3.1 系统设置
- Number of lanes
通道数,有x1、x2、x4、x8四个选项,指定支持的最大通道数。 带DMA的Avalon-MM接口不支持x1配置。
- Lane Rate
通道速率,有Gen1 (2.5 Gbps)、Gen2 (2.5/5.0 Gbps)、Gen3 (2.5/5.0/8.0 Gbps)三个选项,指定链路可以运行的最大数据速率。
- Application interface width
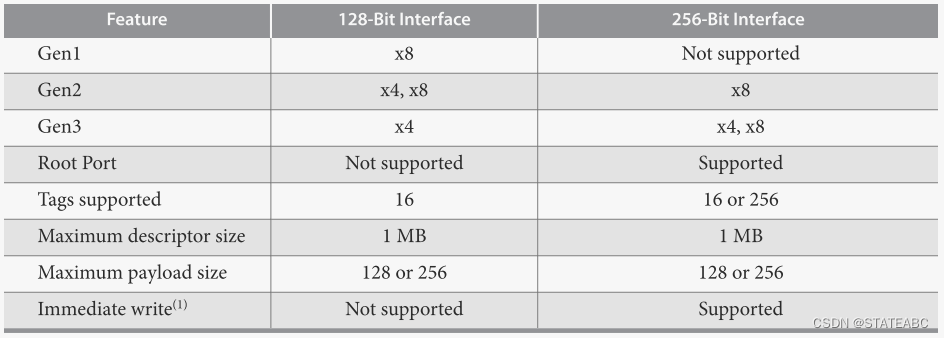
应用接口宽度,有128 bits、256bits两个选项。指定应用层接口的宽度。
可以组成以下组合:
| 应用接口宽度 | 配置 | 应用层时钟频率 |
| 128 bits | Gen1 x8 | 125 MHz |
| 128 bits | Gen2 x4 | 125 MHz |
| 128 bits | Gen2 x8 | 250 MHz |
| 256 bits | Gen2 x8 | 125 MHz |
| 128 bits | Gen3 x4 | 250 MHz |
| 256 bits | Gen3 x4 | 125 MHz |
| 256 bits | Gen3 x8 | 250 MHz |
- RX buffer credit allocation - performance for received requests
RX 缓冲区信用分配 - 接收请求的性能,有Minimum、Low、Balanced三个选项。确定在16KB的RX缓冲区中分配的posted header credits、posted data credits、non-posted header credits、completion header credits和completion data credits,调整信用分配以优化系统性能。更改此选项时,消息窗口会动态更新Posted、Non-Posted以及Completion的信用数量。

• Mininum—配置Non-Posted请求信用和Posted请求信用所允许的最小PCIe规范,将大部分RX缓冲区空间留给Completion的header和data。对于应用程序逻辑生成许多读取请求并且很少从PCIe链路接收单个请求的变体,请选择此选项。
• Low—配置更大一些的RX缓冲区空间用于Non-Posted请求信用和Posted请求信用,但仍将大部分空间用于Completion的header和data。对于应用程序逻辑生成许多读取请求并且很少从 PCIe 链路接收少量请求的变体,请选择此选项。此选项推荐用于典型的Endpoint应用程序,其中大部分的PCIe流量由位于端点应用层逻辑中的DMA引擎生成。
• Balanced—将大约一半的RX缓冲区空间配置给接收请求,另一半给接收完成。选择此选项适用于接收请求和接收完成大致相等的应用程序。
- Reference clock frequency
参考时钟频率,有100MHz、125MHz两个选项。PCI Express基础规范3.0要求100MHz ±300 ppm的参考时钟。提供125MHz参考时钟是为了方便包含125MHz 时钟源的系统。
对于Gen3,建议使用公共参考时钟 (0ppm),当使用单独的参考时钟(非0ppm)时,PCS 偶尔必须插入SKP符号,可能会导致PCIe链路进入恢复状态。 Gen1或Gen2模式不受此问题的影响。
- Instantitate internal descriptor controller
实例化内部描述符控制器,On/Off。当为On时,描述符控制器将包含在Avalon-MM桥中。 当为Off时,描述符控制器作为单独的外部组件。如果使用Altera提供的描述符控制器,则为On。 如果修改或替换设计中的描述符控制器逻辑,则为Off。
- Enable AVMM CRA Slave hard IP Status port
启用Avalon-MM CRA Slave硬件IP状态端口,On/Off。启用此选项允许对桥接寄存器进行读写访问,但Completer的单dword除外。该选项对Requester/Completer变量是必需的,对Completer Only变量是可选的。
- Enable burst capabilities for RXM BAR2 port
启用RXM BAR2端口的突发功能,On/Off。当为On时,BAR2 RX Avalon-MM主机支持突发。如果BAR2是32位且支持突发,则 AR3不可用于其他用途。如果BAR2是64位,则 BAR3 寄存器保存地址的高32位。
- Enable configuration via the PCIe link
启用配置通过PCIe链路,On/Off。打开时,Quartus软件将Endpoint放置在通过协议 (CvP) 配置所需的位置。
- Use ATX PLL
使用ATX PLL,On/Off。当打开此选项时,PCI Express的Hard IP使用 ATX PLL而不是CMU PLL。 对于其他配置,使用ATX PLL代替CMU PLL可减少所需的收发器通道数量。 此选项需要使用软复位控制器,并且不支持CvP流程。
- Enable power up hard IP reset pulse when using the soft reset controller
启用软复位控制器时在上电时启用硬件IP复位脉冲,On/Off。当打开此选项时,软复位控制器在上电时生成一个脉冲以复位硬件IP。这个脉冲确保在对设备进行编程后复位硬件IP,无论专用的PCI Express复位引脚perstn的行为如何。此选项适用于使用软复位控制器的Gen2和Gen3设计。
3.2 基址寄存器 (BAR) 设置
可用BAR的类型和大小取决于端口类型。
- Type
BAR的类型,有Disabled、64-bit prefetchable memory、32-bit non-prefetchable memory、32-bit prefetchable memory、I/O address space五个选项。
如果选择64位可预取内存,将合并2个连续的BAR以形成一个64位可预取BAR;必须将较高编号的BAR设置为Disabled。不支持非预取(non-prefetchable)的64位BAR,因为在典型系统中,Root Port Type 1配置空间将最大非预取内存窗口设置为32位。
将内存定义为prefetchable允许提前获取连续数据。当requestor者可能需要来自同一区域的比最初请求的更多的数据时,预取存储器是有利的。如果指定内存可预取,则它必须具有以下 2 个属性:
• 读取不会产生副作用,例如更改读取的数据值;
• 允许写入合并。
- Size
BAR的大小,连接组件后会自动计算所需的大小。
3.3 设备识别寄存器
- Vendor ID
设置供应商ID寄存器的只读值。根据PCI Express规范,此参数不能设置为0xFFFF。
地址偏移量:0x000。
- Device ID
设置设备ID寄存器的只读值。
地址偏移量:0x000。
- Revision ID
设置修订ID寄存器的只读值。
地址偏移量:0x008。
- Class Code
设置类别代码寄存器的只读值。
地址偏移量:0x008。
- Subsystem Vendor ID
在PCI Type 0配置空间中设置子系统供应商ID寄存器的只读值。根据PCI Express基本规范,此参数不能设置为0xFFFF。该值由PCI-SIG分配给设备制造商。
地址偏移量:0x02C。
- Subsystem Device ID
在PCI Type 0配置空间中设置子系统设备ID寄存器的只读值。
地址偏移量:0x02C。
3.4 PCI Express和PCI功能参数
定义了IP核的各种能力属性,其中一些参数存储在PCI配置空间—PCI 兼容配置空间中。 字节偏移量表示参数地址。
3.4.1 Device Capabilities

- Maxinum payload size
最大有效负载大小,有128 bytes、256 bytes两个选项,默认值为 128 Bytes。指定支持的最大负载大小。 该参数设置设备功能寄存器(0x084[2:0])支持的最大有效负载大小字段的只读值。
地址:0x084。
3.4.2 Error Reporting
- Advanced error reporting(AER)
高级错误报告(AER),默认值为Off,打开时启用高级错误报告(AER)功能。
- ECRC checking
ECRC checking,默认值为Off,打开时启用ECRC检查。设置ECRC检查位的只读值在Advanced Error Capabilities and Control Register。此参数要求启用AER功能。
- ECRC generation
ECRC生成,默认值为Off,打开时,启用ECRC生成能力。设置ECRC生成位的只读值在Advanced Error Capabilities and Control Register。此参数要求启用AER功能。
- Enable ECRC forwarding on the Avalon-ST interface
启用ECRC转发在Avalon-ST接口,默认值为Off,当打开时启用ECRC 转发到应用程序层。 在Avalon-ST RX路径上,传入的TLP包含ECRC dword,并且如果存在ECRC,则设置TD位。
- Track RX completion buffer overflow on the Avalon- ST interface
跟踪AvalonST接口上的RX完成缓冲区溢出,默认值为Off,当打开时内核包含rxfx_cplbuf_ovf输出状态信号来跟踪 RX 发布完成缓冲区溢出状态
3.4.3 Link Capabilities
- Link port number
链接端口号,0x01,设置链接寄存器中端口号字段的只读值。
- Slot clock configuration
时隙时钟配置,On/Off,打开时,表示端点或根端口使用系统在连接器上提供的相同物理参考时钟。关闭时,IP核使用独立时钟,无论连接器上是否存在参考时钟。
3.4.4 MSI and MSI-X Capabilities

- Number of MSI messages requested
请求的 MSI 消息数,有1、2、4、8、16五个选项。指定应用层可以请求的消息数量。设置消息控制寄存器中的多消息能力字段的值。地址:0x050 [31:16]。
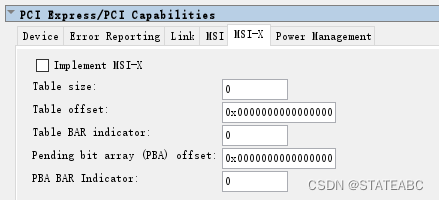
- Implement MSI-X
PBA BAR Indicator,On/Off,打开时添加MSI-X功能。
- Table size
表尺寸,范围为[10:0],系统读取此字段以确定MSI-X表大小 <n>,编码为 <n–1>。 例如,返回值2047表示表大小为2048。该字段是只读的。 合法范围为 0–2047 (211)。 地址偏移:0x068[26:16]。
- Table offset
表偏移,范围为[31:0],指向MSI-X表的基址。软件将表BAR指示器(BIR)的低3位设置为零,形成64位对齐的偏移量。此字段为只读。
- Table BAR indicator
表BAR指标,范围为[2:0],指定用于将MSI-X表映射到内存空间的函数的BAR之一,从配置空间中的0x10开始。此字段为只读。合法范围为0-5。
- Pending bit array (PBA) offset
待定位数组 (PBA) 偏移量,范围为[31:0],作为从函数的基址寄存器中包含的地址的偏移量,指向MSI-X PBA的基址。软件将PBA BIR的低3位设置为零,形成32位对齐的偏移量。此字段为只读。
- PBA BAR Indicator
PBA BAR指标,范围为[2:0],指定函数基址寄存器,从配置空间中的0x10开始,将MSI-X PBA映射到内存空间。此字段为只读,合法范围为0-5。
3.4.5 Power Management
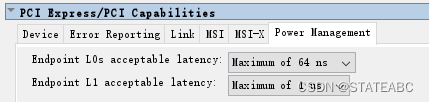
- Endpoint L0s acceptable latency
端点L0s可接受延迟,有Maximum of 64 ns、Maximum of 128 ns、Maximum of 256 ns、Maximum of 512 ns、Maximum of 1 us、Maximum of 2 us、Maximum of 4 us、No limit选项,默认值为64纳秒
此参数指定设备在与根复杂的链接之间退出L0s状态时可以容忍的最大延迟。它设置设备功能寄存器(0x084)中的只读Endpoint L0s可接受延迟字段的值。设置此参数允许系统配置软件读取系统中所有设备的可接受延迟和每个链接的退出延迟,以确定哪些链接可以启用主动状态电源管理(ASPM)。对于根端口,此设置被禁用。
- Endpoint L1 acceptable latency
端点L1可接受延迟,Maximum of 1 us、Maximum of 2 us、Maximum of 4 us、Maximum of 8 us、Maximum of 16 us、Maximum of 32 us、Maximum of 64 ns、No limit选项,默认值为1微秒。
此值指示端点在从L1状态过渡到L0状态时可以承受的可接受延迟。它是端点内部缓冲的间接度量。它设置设备功能寄存器中的只读Endpoint L1可接受延迟字段的值。设置此参数允许系统配置软件读取系统中所有设备的可接受延迟和每个链接的退出延迟,以确定哪些链接可以启用主动状态电源管理(ASPM)。对于根端口,此设置被禁用。
3.5 PCIe地址空间设置

Address width of accessible PCIe memory space
可访问的 PCIe 内存空间的地址宽度,可能值为20-64,默认值为32。该参数指定了TX从模块Avalon-MM地址的宽度。该地址在作为PCIe地址时保持不变。
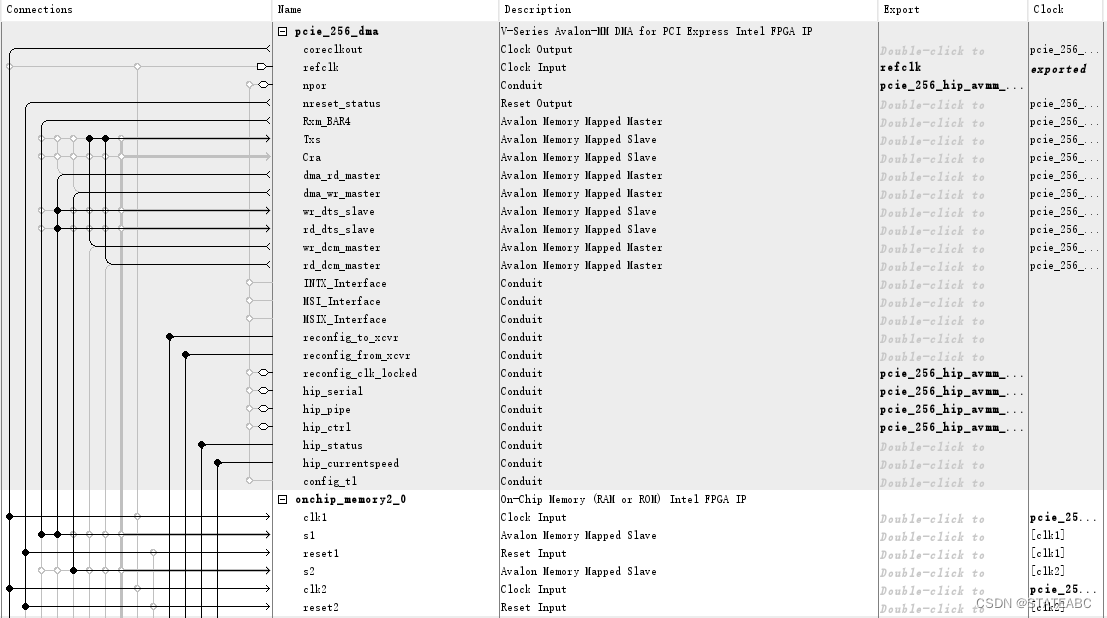
4. IP核接口
带有DMA的Avalon-MM的V系列PCI Express硬核IP的顶层信号,Avalon 内存映射接口 DMA 桥包括高性能、具有突发能力的Read DMA和Write DMA模块。 控制读DMA和写 DMA模块的 DMA 描述符控制器可以包含在Avalon 内存映射接口DMA桥中或单独实例化。
具有内部描述符控制器的Avalon-MM DMA:
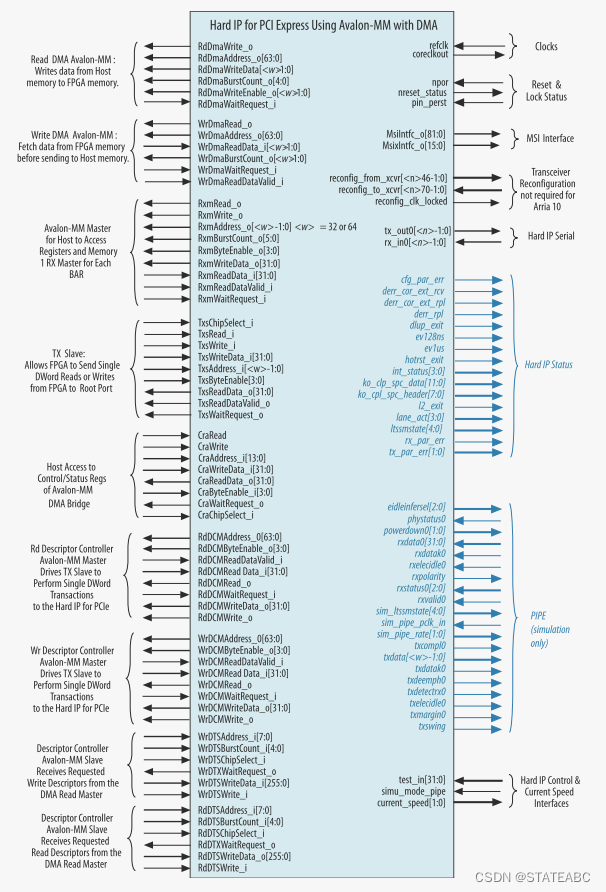
上图和Qsys中的IP相对应

4.1 Read Data Mover
即Qsys IP的dma_rd_master,Read Data Mover发送内存读取 TLP,通过Read Master端口将完成数据写入外部Avalon-MM接口。Read Data Mover根据IP核心从DMA描述符控制器接收到的描述符进行操作。 对于Read Data Mover,完成TLP的数据有效负载限制为最多256字节。
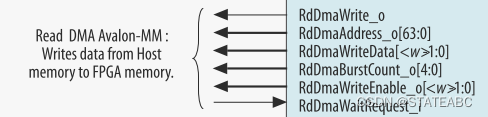
Read DMA Avalon-MM Master接口执行以下功能:
1. 提供Descriptor Table给Descriptor Controller
Read Data Mover发送PCIe系统内存读取请求,从PCIe系统内存中获取描述符表。然后,该模块使用Avalon-MM接口将返回的描述符条目写入Descriptor Controller FIFO。
2. 将数据写入位于Avalon-MM空间中的内存
在DMA读取完成后,从PCIe系统内存的源地址获取数据后,Read Data Mover模块通过该接口将数据写入Avalon-MM地址空间中的目标地址。
4.2 Write DMA Avalon-MM Master Port
即Qsys IP的dma_wr_master,Write Data Mover模块在发出内存写请求以将数据传输到 PCIe 系统内存之前,使用该接口从Avalon-MM地址空间获取数据。
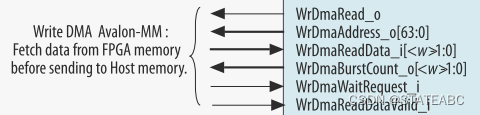
4.3 RX Master Module
即Qsys IP的Rxm_BAR,RX Master模块将从PCIe链路接收到的读写TLP转换为Avalon-MM请求。该模块允许其他PCIe组件(包括主机软件)访问Platform Designer系统中连接的其他 Avalon-MM 从设备。
如果未启用突发模式,RX Master模块仅支持32位读或写请求。 从PCIe链路收到的所有其他请求均被视为违反该设备的编程模型,以PCIe Completer Abort状态进行处理。
如果使用32位寻址启用BAR2的突发模式,或使用64位寻址启用BAR2和BAR3的突发模式,则该模块支持双字、突发读取或写入请求。当描述符控制器在内部实例化时,BAR0的RX Master设备在内部使用,不可用于其他用途。当启用BAR2的突发模式时,不支持刷新读取(即所有字节使能设置为0的读取)。

4.4 Non-Bursing Slave Module
即Txs,一个32 位 Avalon-MM从接口,TX Slave模块将Avalon-MM读取和写入请求转换为PCI Express TLPs。该从模块支持单个未完成的非突发请求。通常,它向主机发送状态更新。
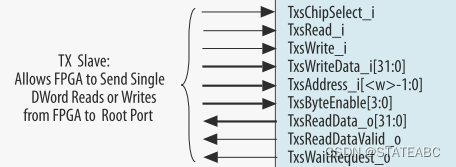
4.5 32-Bit Control Register Access (CRA) Slave Signals
即Cra,需要勾选Enable AVMM CRA Slave hard IP Status port。CRA接口提供对Avalon-MM桥的控制和状态寄存器的访问。
该接口为32位数据总线,支持一次单个事务、支持单周期事务(无突发)。当 Avalon-MM Hard IP for PCIe IP Core处于根端口模式时, 当应用程序逻辑通过CRA接口发出CfgWr或CfgRd时,需要将TLP Header中的Tag字段填充为0x10,以确保相应的Completion正确路由到CRA接口。 如果应用程序逻辑将Tag字段设置为某个其他值,则Avalon-MM Hard IP for PCIe IP Core 不会用正确的值覆盖该值。
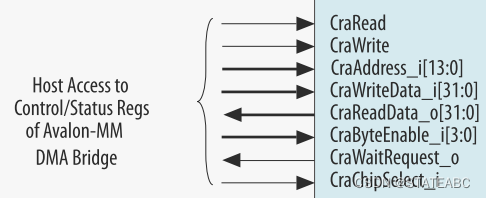
4.6 Descriptor Controller Interfaces when Instantiated Internally
内部实例化时的描述符控制器接口是勾选了Instantiate internal descriptor controller,描述符控制器控制读DMA和写DMA数据移动器。 它提供了一个32位Avalon-MM从接口来控制和管理从 PCIe系统存储器到Avalon-MM存储器以及相反方向的数据流。 描述符控制器包括两个128条目FIFO,用于存储读和写描述符表。 描述符控制器将描述符转发到读DMA和写DMA数据移动器。数据移动器将完成状态发送到读取描述符控制器和写入描述符控制器。 描述符控制器使用 TX 从端口将状态和 MSI 转发到主机。
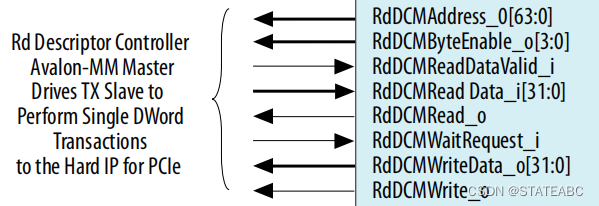
4.6.1 Read Descriptor Controller Avalon-MM Master interface
即rd_dcm_master,读描述符控制器的Avalon-MM主接口驱动非突发Avalon-MM从接口。读取描述符控制器使用此接口将描述符状态写入PCIe域,当启用 MSI 消息时还会写入 MSI。
4.6.2 Write Descriptor Controller Avalon-MM Master Interface
即wr_dcm_master,Avalon-MM描述符控制器主接口是一个 32 位单字主接口,支持等待请求。写描述符控制器使用此接口将状态写回PCI Express 域,当启用MSI消息时还会写入MSI。此 Avalon-MM主接口仅适用于内部实例化的描述符控制器。
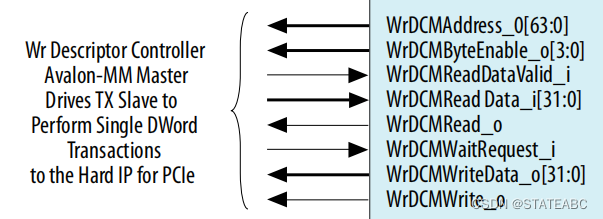
4.6.3 Read Descriptor Table Avalon-MM Slave Interface
即rd_dts_slave,读取描述符表Avalon-MM从接口,它接收由Read Data Mover获取的读取 DMA描述符。将接口连接到读取DMA Avalon-MM主接口。
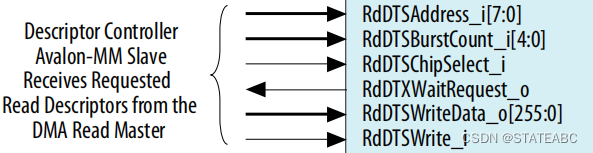
4.6.4 Write Descriptor Table Avalon-MM Slave Interface
即wr_dts_slave,写入描述符表Avalon-MM从接口,此接口接收由读取数据移动器获取的写入 DMA 描述符。将接口连接到读取DMA Avalon-MM主接口。
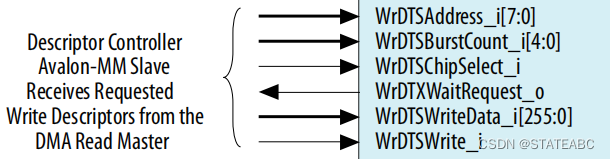
4.7 Clock Signals

- refclk
输入,IP核的参考时钟,在系统设置中指定的频率。
如果设计启用CVP且包括连接到同一Transceiver Reconfiguration Controller的additional transceiver PHY,则必须将refclk连接到Transceiver Reconfiguration Controller和additional transceiver PHY 的mgmt_clk_clk 信号。
- coreclkout
输出,数据链路和事务层使用的固定频率时钟。 为了满足 PCI Express 链路带宽限制,该时钟具有最低频率要求。
4.8 Reset, Status, and Link Training Signals
4.8.1 Reset Signals
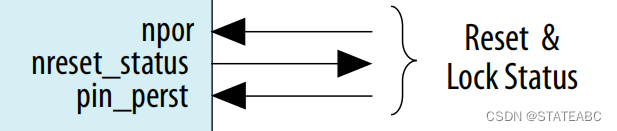
- npor
输入,异步低电平有效复位信号,重置整个IP核和收发器transceiver。 在Intel硬件示例设计中,npor是来自软件应用程序层的pin_perst 和 local_rstn的或。 如果不从应用层驱动软复位信号,则该信号必须源自pin_perst。
在使用硬复位控制器的系统中,该信号是边沿信号,对电平不敏感; 因此,您不能在此信号上使用较低的值来保持自定义逻辑处于复位状态
- nreset_status
输出,低电平有效复位信号。 它源自npor 或pin_perstn,可以使用此信号来重置应用层。
- pin_perst
输入,来自设备PCIe复位引脚的低电平有效复位。 pin_perst重置数据路径和控制寄存器。 通过协议配置 (CvP) 需要此信号。
PCI Express硬核IP每个实例都有自己的pin_perst信号,必须将每个Hard IP实例的pin_perst 连接到设备相应的nPERST引脚:

4.8.2 Status and Link Training Signals
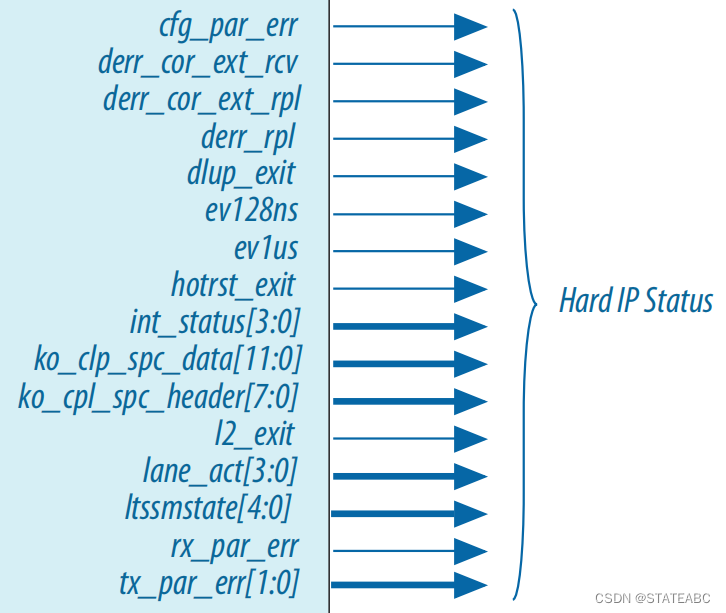
- cfg_par_err
输出,指示内部配置空间的TLP中的奇偶校验错误。此错误还会记录在供应商特定扩展功能内部错误寄存器中。 如果发生此错误必须重置硬 IP。
该信号不适用于Arria V和Cyclone V器件。
- derr_cor_ext_rcv
输出,指示RX缓冲区中已更正的错误。此信号仅用于调试。在RX缓冲区充满数据之前,它是无效的。是一个脉冲信号,而不是电平信号。
- derr_cor_ext_rpl
输出,指示重试缓冲区中已纠正的 ECC 错误。 该信号仅用于调试。
该信号不适用于Arria V和Cyclone V器件。
- derr_rpl
输出,指示重试缓冲区中存在不可纠正的错误。 该信号仅用于调试。
该信号不适用于Arria V和Cyclone V器件。
- dlup_exit
输出,当IP核退出DLCMSM DL_Up状态时,该信号在一个pld_clk周期内被置为低电平,表明数据链路层已失去与PCIe链路另一端的通信并离开Up状态。 当该脉冲被置位时,应用层应生成一个内部复位信号,该信号被置位至少32个周期。
- ev128ns
输出,每128ns置位一次以创建时基对齐活动。
- ev1us
输出,每1μs置位一次以创建时基对齐的活动。
- hotrst_exit
输出,热复位退出。当LTSSM退出热复位状态时,该信号将被置位1个时钟周期。 该信号低电平有效,能够复位应用层。当该脉冲被置位时,应用层生成一个内部复位信号,该信号被置位至少32个周期。
- int_status[3:0]
输出,驱动应用层中断:int_status[0]: interrupt signal A、int_status[1]: interrupt signal B、int_status[2]: interrupt signal C、int_status[3]: interrupt signal D。
- ko_cpl_spc_data[11:0]
输出,应用层可以使用该信号防止completion data的RX缓冲区溢出。ko_cpl_spc_data是一个静态信号,反映可以存储在完成RX缓冲区中的16字节completion data units的总数。
- ko_cpl_spc_ header[7:0]
输出,应用层可以使用该信号防止completion header的RX缓冲区溢出。ko_cpl_spc_header 是一个静态信号,指示可以存储在 RX 缓冲区中的completion header的总数。
- l2_exit
输出,L2出口。该信号低电平有效,否则保持高电平。在LTSSM从l2.idle转换为检测状态后,它会被置位一个周期(将值从1更改为0,然后再更改回1)。当该脉冲被置位时,应用层生成一个内部复位信号,该信号被置位至少32个周期。
- lane_act[3:0]
输出,通道激活模式:该信号指示链路训练期间配置的通道数。定义了以下编码:4'b0001: 1 lane、4'b0010: 2 lanes、4'b0100: 4 lanes、4'b1000: 8 lanes。
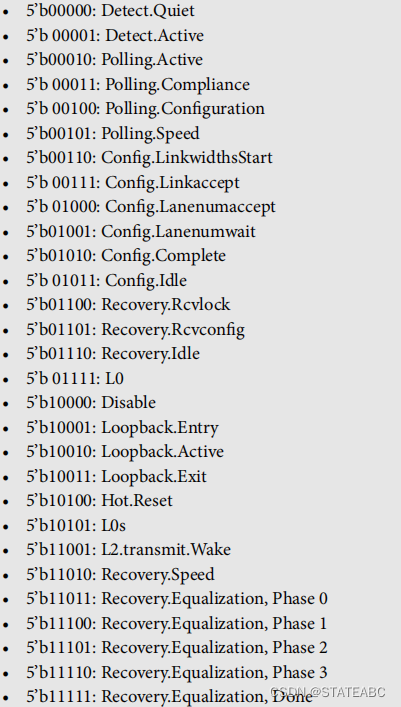
- ltssmstate[4:0]
输出,LTSSM状态。LTSSM状态机编码定义以下状态:


- rx_par_err
输出,当在单个周期内置位时,表示在RX缓冲区输入的TLP中检测到奇偶校验错误。 该错误在VSEC寄存器中记录为不可纠正的内部错误。如果发生此错误必须重置硬核 IP,因为奇偶校验错误可能会使硬核 IP 处于未知状态。
该信号不适用于Arria V和Cyclone V器件。
- tx_par_err[1:0]
输出,当在单个周期内置位时,指示TX TLP传输期间出现奇偶校验错误。 这些错误记录在 VSEC寄存器中。 定义了以下编码:
• 2’b10:TX事务层检测到奇偶校验错误。 TLP无效并作为不可纠正的内部错误记录在VSEC 寄存器中。 有
• 2’b01:一段时间后,TX数据链路层检测到奇偶校验错误,驱动2’b01指示错误。 检测到此错误时重置IP核。
该信号不适用于Arria V和Cyclone V器件。
4.9 MSI Interrupts for Endpoints
当DMA操作完成时,MSI中断会通知主机。主机收到此中断后,可以轮询DMA读或写状态表,以确定哪些条目设置了完成位。 这种机制允许主机软件避免连续轮询状态表完成位。 使用此接口接收通过TX从接口生成MSI或MSI-X根端口中断所需的信息。

- MSIIntfc_o[81:0]
输出,该总线提供以下 MSI 地址、数据和使能信号:

- MSIXIntfc_o[15:0]
输出,提供MSI-X的系统软件控制:

- MSIControl_o[15:0]
输出,提供MSI消息的系统软件控制:

4.10 Physical Layer Interface Signals
4.10.1 Transceiver Reconfiguration
动态重新配置可补偿由于工艺、电压和温度 (PVT) 造成的变化。 可以重新配置的模拟设置包括VOD、预加重和均衡。

- reconfig_from_xcvr[(<n>46)-1:0]
输出,发送至收发器重配置控制器的重配置信号。
- reconfig_to_xcvr[(<n>70)-1:0]
输入,来自收发器重配置控制器的重配置信号。
- reconfig_clk_locked
输出,置位后,表示提供收发器初始化所需固定时钟的PLL已锁定。 应用层应保持复位状态,直到reconfig_clk_locked被置位。
<n>是所需的接口数量。
4.10.2 Serial Data Signals
差分串行接口是根端口和端点之间的物理连接。PCIe IP核支持1、2、4或8个通道。每个通道包括一个TX和一个RX差分对。

- tx_out[-1:0]
传输输出,通道<n>-1–0的串行输出。
- rx_in[-1:0]
接收输入,通道<n>-1–0的串行输入。
4.10.3 PIPE Interface Signals
PIPE信号可用于Gen1、Gen2 和 Gen3,以便使用串行或PIPE接口进行模拟,使用PIPE接口进行仿真速度更快。Intel Arria 10和 Intel Cyclone 10 GX器件不支持Gen3 PIPE接口。 默认情况下,Gen1和Gen2的PIPE接口为8位,Gen3的PIPE接口为32位。
包含通道号0的信号也存在于通道1-7中。 这些信号仅用于模拟。 对于Quartus软件编译,这些管道信号可以悬空。 在Platform Designer中,属于 PIPE 接口一部分的信号具有前缀 hip_pipe。用于模拟PIPE接口的信号具有前缀hip_pipe_sim_pipe
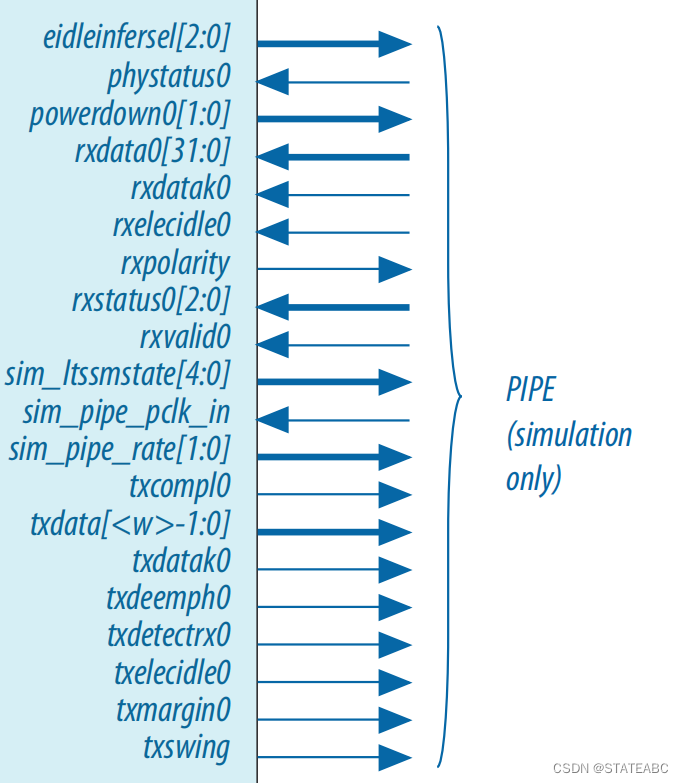
- eidleinfersel0[2:0]
输出,电气空闲进入推理机制选择。 定义了以下编码:
• 3'b0xx:当前LTSSM状态中不需要电气空闲推理
• 3'b100:在Gen1或Gen2的128us窗口中缺少COM/SKP有序集
• 3'b101:1280中缺少TS1/TS2有序集Gen1或Gen2的UI间隔
• 3'b110:Gen1的2000UI间隔和Gen2的16000UI 间隔内不存在电气空闲退出
• 3'b111:Gen1在128us窗口内不存在电气空闲退出
- phystatus0
输入,PHY状态<n>,该信号传达多个PHY请求的完成情况。
- powerdown0[1:0]
输出,关闭<n>电源,该信号请求PHY将其电源状态更改为指定状态(P0、P0s、P1或P2)。
- rxdata0[31:0]
输入,接收数据,该总线在通道<n>上接收数据。
- rxdatak0[3:0]
输入,接收数据符号的数据/控制位。 位0对应rxdata的最低位字节,依此类推。 值0表示一个数据字节。 值1表示控制字节。 仅适用于Gen1和Gen2。
- rxelecidle0
输入,接收电气空闲<n>。置位后,表示检测到电气空闲。
- rxpolarity0
输出,接收极性<n>,该信号指示PHY层反转8B/10B接收器解码块的极性。
- rxstatus0[2:0]
输入,接收状态<n>,该信号对接收数据流和接收器检测的接收状态和错误代码进行编码。
- rxvalid0
输入,接收有效的<n>。 该符号指示rxdata<n>和rxdatak<n>上的符号锁定和有效数据。
- sim_pipe_ltssmstate0[4:0]
输入输出,LTSSM状态。LTSSM状态机编码定义以下状态:
- sim_pipe_pclk_in
输入,该时钟仅用于PIPE模拟,并且源自refclk,它是用于PIPE模式仿真的PIPE接口时钟。
- sim_pipe_rate[1:0]
输入,指定数据速率。2位编码的含义如下:2'b00: Gen1 rate (2.5 Gbps)、2'b01: Gen2 rate (5.0 Gbps)、2'b1X: Gen3 rate (8.0 Gbps)。
- txcompl0
输出,传输合规性<n>。 该信号强制合规模式下的运行差异为负值(负 COM 字符)。
- txdata0[31:0]
输出,传输数据。 该总线在通道<n>上传输数据。
- txdatak0[3:0]
输出,传输数据控制<n>。该信号用作txdata<n>的控制位。位0对应于rxdata的最低位字节,依此类推。 值0表示一个数据字节。值1表示控制字节。仅适用于Gen1和Gen2。
- txdataskip0
输出,适用于Gen3操作。允许MAC指示TX接口在一个时钟周期内忽略TX数据接口。 定义了以下编码:1'b0:TX数据无效、1'b1:TX数据有效。
- txdeemph0
输出,发送去加重选择。该信号的值是根据训练序列 (TS) 期间从链路另一端接收到的指示来设置的。 不需要更改该值。
- txdetectrx0
输出,发送检测接收<n>。该信号告诉PHY层开始接收检测操作或开始环回。
- txelecidle0
输出,传输电气空闲<n>。该信号强制TX输出处于电气空闲状态。
- txmargin0[2:0]
输出,传输VOD余量选择。该信号的值基于Link Control 2 Register的值。仅可用于模拟。
- txswing0
输出,置位后,表示发送器电压满摆幅。当无效时表示半摆动。
- txsynchd0[1:0]
输出,适用于Gen3操作,指定块类型。定义了以下编码:2'b01:有序集块、2'b10:数据块
4.11 Test Signal
test_in总线提供运行时控制和IP核内部状态的监控。

- test_in[31:0]
输入,test_in 总线的位具有以下定义:
• [0]:模拟模式。可以将该信号设置为1,以通过减少许多初始化计数器的值来加速初始化。
• [1]:保留。必须设置为 1'b0。
• [2]:解扰模式禁用。 该信号必须在初始化期间设置为1,以禁用数据加扰。 可以在Gen1和Gen2端点和根端口的模拟中使用该位来观察链路上的解扰数据。 解扰数据不能在开放系统中使用,因为链路伙伴通常会对数据进行加扰。
• [4:3]:保留。必须设置为2’b01。
• [5]:一致性测试模式。禁用/强制合规模式。设置后,将阻止LTSSM进入合规模式。 切换该位可控制合规状态的进入和退出,从而启用Gen1、Gen2和Gen3合规模式的传输。
• [6]:当在polling.active状态下达到超时并且并非所有通道都检测到其退出条件时,强制进入合规模式。
• [7]:禁用低功耗状态协商。建议设置该位。
• [31:8]:保留。设置为全0。
- simu_pipe_mode
输入,当1'b1时,计数器值减少到速度模拟。
- currentspeed[1:0]
输出,指示PCIe链路的当前速度。 定义了以下编码:2b'00:未定义、2b'01:Gen1、2b'10:Gen2、2b'11:Gen3。
5.Reset and Clocks
用于PCI Express IP核的V系列硬核IP包括软复位控制器和硬复位控制器。 软件根据指定的配置选择适当的复位控制器。 两个复位控制器都会复位IP核,并提供示例复位逻辑。
下图提供了实现两个复位控制器的逻辑的简化视图。 来自FPGA输入引脚的pin_perst信号会重置PCI Express IP核的硬核IP。 该信号也是硬核IP复位控制器的输入,驱动复位状态输出,该输出可用作应用层逻辑的复位信号。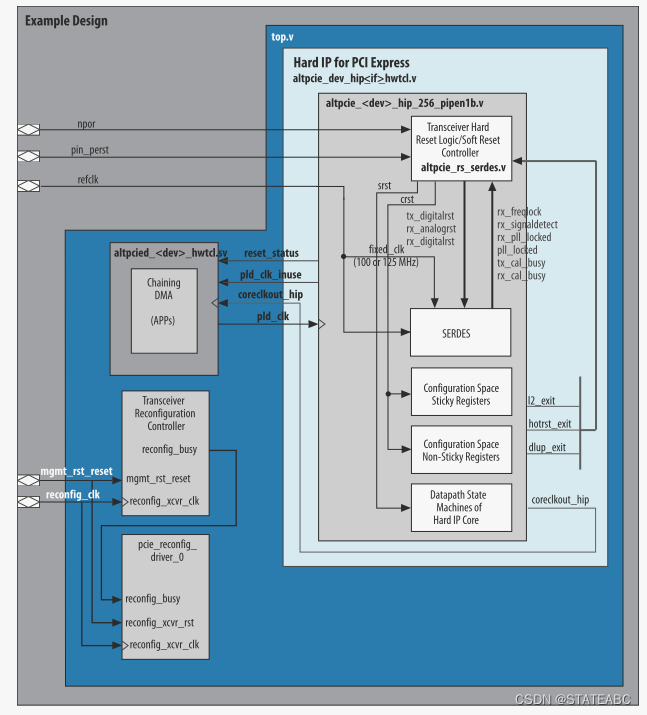
5.1 Reset Sequence for Hard IP for PCI Express IP Core and Application Layer
释放pin_perst或npor后,Hard IP复位控制器将置低reset_status,应用程序层逻辑解除重置并开始运行。
- RX 收发器复位序列
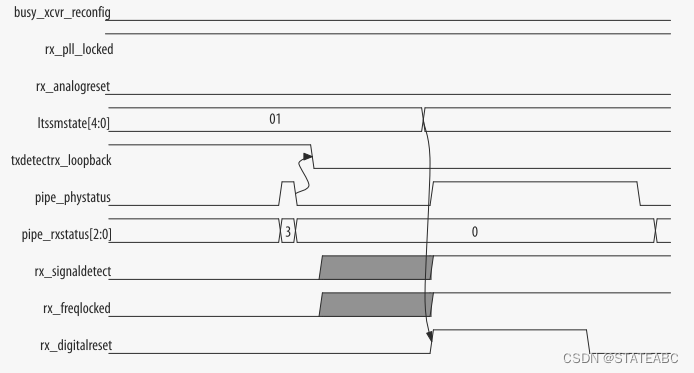
RX 收发器复位序列包括以下步骤:
1. rx_pll_locked置位后,LTSSM状态机从Detect.Quiet状态转换为Detect.Active状态。
2. 当pipe_phystatus脉冲置位并且pipe_rxstatus[2:0]=3时,接收器检测操作已完成。
3. LTSSM状态机从Detect.Active状态转换到Polling.Active状态。
4. PCI Express硬核IP置位rx_digitalreset。 rx_signaldetect稳定至少3ms后,rx_digitalreset信号将被置低。
- TX 收发器复位序列
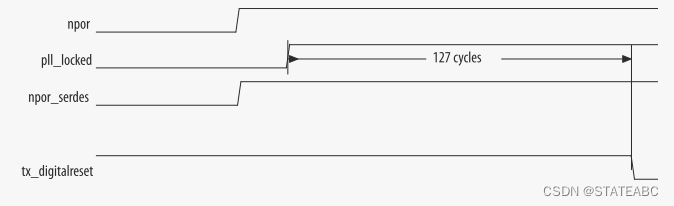
TX 收发器复位序列包括以下步骤:
1. npor置低后,IP核将TX收发器的npor_serdes输入置低。
2. SERDES复位控制器等待pll_locked稳定至少127个pld_clk周期,然后再置低tx_digitalreset。
5.2 Clocks
硬核IP在PHY/MAC和DLL层之间的接口处包含一个时钟域交叉 (CDC) 同步器。 同步器允许数据链路和事务层以独立于PHY/MAC的频率运行。CDC同步器为用户时钟接口提供了更大的灵活性。根据指定的参数,内核选择适当的coreclkout_hip。 根据PCI Express基本规范,必须提供直接连接到收发器的100MHz参考时钟,还可以使用125 MHz输入参考时钟作为TX PLL的输入。
5.2.1 Clock Domains
下面说明了使用coreclkout_hip驱动应用层和IP核的pld_clk 时的时钟域。 Intel提供的示例设计将coreclkout_hip连接到pld_clk。 但这种连接不是强制性的。 在PCI Express硬核IP内部,白色显示的块位于pclk域中,而黄色显示的块位于coreclkout_hip域中。
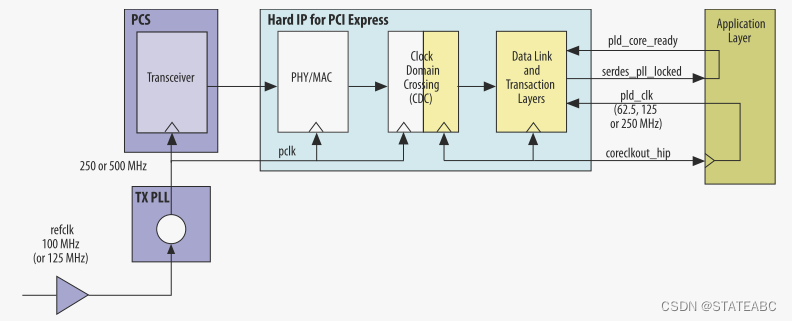
如图所示,IP核包括以下时钟域:pclk、coreclkout_hip和pld_clk。
- pclk
PCI Express基本规范要求refclk信号频率为100 MHz±300PPM。
- coreclkout_hip
coreclkout_hip信号源自 pclk,可以驱动应用层时钟以及IP核的pld_clk输入。适用于链路宽度、数据速率和应用层接口宽度的所有组合的应用层时钟频率如下
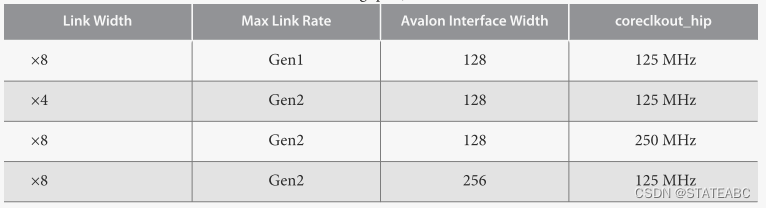
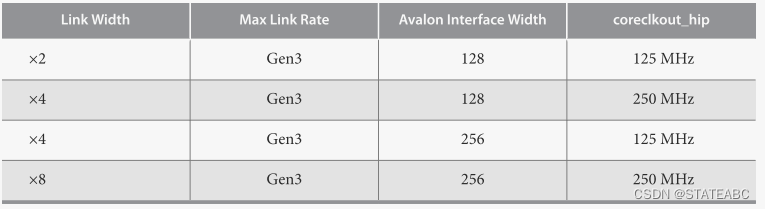
- pld_clk
pld_clk可以选择由与coreclkout_hip不同的时钟提供源,但最小频率不能低于coreclkout_hip 频率。 根据特定的应用层约束,可以使用PLL来导出所需的频率。
对于 Gen3,建议使用通用参考时钟 (0ppm),因为使用单独的参考时钟(非0ppm)时,PCS 有时必须插入SKP符号,这可能会导致PCIe链路进入恢复状态。Gen1或Gen2模式不受此问题的影响。
5.2.2 Clock Summary
| 名称 | 频率 | 时钟域 |
| coreclkout_hip | 62.5, 125 or 250 MHz | 事务层和应用层之间的Avalon-ST接口 |
| pld_clk | 125 or 250 MHz | 应用层和事务层 |
| refclk | 100 or 125 MHz | SERDES(收发器)的专用自由运行输入时钟 |
| reconfig_xcvr_clk | 100 –125 MHz | 收发器重配置控制器 |



![[Redis]主从模式](https://img-blog.csdnimg.cn/direct/bc6902fb2d7446109d6e9993c6dda1f3.png)